An Adaptive-Parity Error-Resilient LZ77 Compression Algorithm
The paper proposes an improved error-resilient Lempel-Ziv'77 (LZ'77) algorithm employing an adaptive amount of parity bits for error protection. It is a modified version of error resilient algorithm LZRS'77, proposed recently, which uses a constant a…
Authors: Tomaz Korosec, Saso Tomazic (Faculty of Electrical Engineering, University of Ljubljana
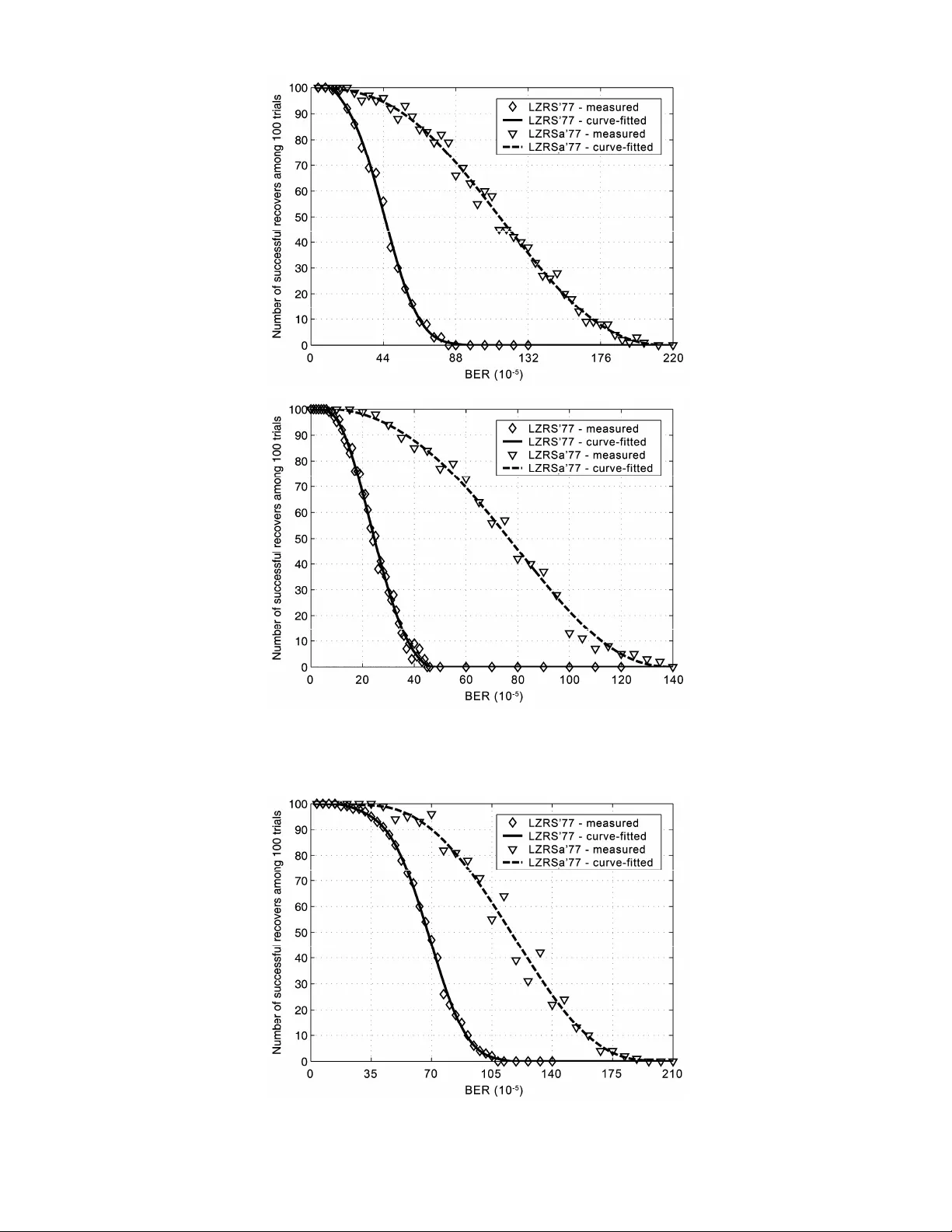
1 Abstract —The paper proposes an improved error-resilient Lemp el-Ziv'77 (LZ '77) algorithm employin g an adaptive amount of parity b its for error prot ection. It is a modified version of error resilient algorithm LZRS'77, p roposed recently, which uses a con stant amount of parity over all of the encoded blocks of data. The constant amount of parity is bounded by the lowe st-redundancy par t of the encoded string, whereas the adaptive parity more efficien tly utilizes the available redundancy of the encoded string, and can be on average much h igher. The proposed algorithm th us provides better error protection of encoded data. The performance of both algorithms was measured. The comparison showed a noticeab le improvement by use of adaptive pa rity. The proposed algorithm is cap able of correcting up to a few times as many errors as the original algorith m, while the compression performance remains practically unchanged. Index Terms —Adaptive parity, error resilience, joint sou rce-ch annel coding, Lempel-Z iv'77 (LZ'77) coding, multiple matches, Ree d-Solomon (RS) coding. I. I NTRODUCTION Lossless data compression algorithm s, such as the Lempel-Ziv'77 (LZ' 77) [1] algorithm and its variations, are nowadays quite comm on in different applicat ions and compression schem es (GZIP, GIF, etc.). However, one of their m ajor disadvant ages is their lack of resistance to errors. In practice, even a single error can propagate and cause a large amount of errors in the decodi ng process. One possible solution for this problem is to use a channel coding schem e succeeding the source coding, which adds addit ional parity bits , all owing error correction and detection i n the decoding process. However, such a solution is undesirabl e in bandwidth-limi ted system s, where the amount of bits required to carry som e inform ation s hould be as sm all as possible. A separate use of source and channel coding is not optimal, since it does not utilize inherent redundancy left by the source coding. This redundancy coul d be expl oited for protection agai nst errors. Therefore, joint source-channel coding seems to be a better soluti on. Several joint source-channel coding algori thms have been proposed in the past, e.g., [2], [3], and [4]. The redundancy left in LZ'77 and LZW encoded data an d the possibility o f using it to embed ad ditional information has b een considered and investigated in [5], [6] , [7], and [8]. The LZRS'77 al gorithm, proposed in [8] , exploits the redundancy left by the LZ' 77 encoder to embed pa rity bits of t he Reed-Solomon (RS) code. Embedded parity bits allow detecti on and correction of errors with practicall y no degradation of the compression perform ance. However, due to the lim i ted redundancy left i n the encoded data, the ability to detect and correct errors is limited to a lim ited number of successfully corrected errors. To successfully correct e errors, 2 e parity bits shoul d be embedded. In the above-m entioned schem e, the number of parity bits embedded in each encoded block is constant and e qual for all blocks, thus e is lim ited by the redundancy of the bl ock with the lowest redundancy. In this paper, we propose an im provement t o LZR S'77. Instead of keeping e const ant, we change it adaptively in accord ance with the redundancy pres ent in the encoded blocks. In this way, we increase the average number of parity bits per block and thus also i ncrease the total num ber of errors that can be successfully corrected. We named this new al gorithm LZRSa' 77. The paper is organized as follows. In Section II, we briefly describe the LZRS' 77 algorithm, which is the basis of the proposed adapti ve-parity algorithm LZRSa'77 described in Section III. T. Korosec and S. Tomazic are with the Faculty of Electrical Engineering, Univer sity of Ljubljana, L jubljana, Slovenia, (email: tom az.korosec@fe.uni-lj.si). An Adaptive-Parity Error -Resilient LZ'77 Compression Algorithm Tomaz Korosec and Saso Tomazic, Member, IEEE 2 Experimental results compari ng both algorithm s are presented in Section IV. Some concludi ng remarks are given in Secti on V. II. P ROTECTION A GAINST E RRORS E XPLOITING LZ'77 R EDUNDANCY The basic principle of the LZ'77 algorithm is to replace sequences of symbols that occur repeatedly in the encoding string X = ( X 1 , X 2 , X 3 , …) with pointers Y = ( Y 1 , Y 2 , Y 3 , …) to previous occurrence of the same sequence. The algorit hm looks in the sequence of past sym bols E = ( X 1 , X 2 , …, X i -1 ) to find the longest m atch of the prefix ( X i , X i +1 , …, X i + l -1 ) of the currently encoding string S = ( X i , X i +1 , …, X N ). The pointer is written as a triple Y k = ( p k , l k , s k ), where p k is the position (i.e., starting index) of the longest m atch relative to t he current index i , l k is the length of the longest mat ch, and s k = X i + l is the first non-matching sy mbol foll owing the mat ching sequence. The symbol s k is needed to proceed in cases when there is no match for the current sym bol. An example of encoding the sequence at position i that m atches the sequence at position j is shown in Fig. 1. To avoid overly large values of position and length param eters, the LZ' 77 algorithm em ploys a principle called the sl iding window. The algorithm looks for the longest matc hes only in data within the fixed-size window. Fig. 1. An example of a pointer record for a repeated pa rt of a string in the LZ' 77 algorithm. The sequence of length l = 6 at position j is repeated at position i , i.e., the current position. Often, there is more than one longest match for a given sequence or phrase, whi ch means m ore than one possible pointer. Usually, the algori thm chooses the lat est pointer, i.e., the one with t he smallest position value. However, selection of a nother poi nter would not affect the decom pression process. Actually, the multiplicity of matches re presents some kind of redundancy and could be exploited for embedding additi onal information bi ts almost without degradation in t he compression rate. A small decrease in compression perform ance c ould be noti ced only in case when pointers are additionally Huffman encoded, as for example in GZ IP algorithm, specified in [9]. With appropriate selection of one am ong M possible pointers, we can encode up to d = ⎣ log 2 M ⎦ additional bits. These additional b its can be enco ded with pro per selection of po inters with multiplicity M > 1, as shown in Fig. 2. The algorithm LZS' 77 that exploits the above-described principl e in LZ'77 scheme was proposed and fully described i n [5], [6], [7], and [8]. Since di fferent pointer selecti on does not affect the decoding process, the proposed algorithm is complet ely backward compati ble with the LZ'77 decoder. Fig. 2. An example of the longest m atch with multiplicity M = 4. With a choice of one of four possible pointers, we can encode two redundant bits. The additional bits can b e utilized to embed parity bits for error detection and correction. In [6 ] and [8], a new algorithm called LZRS'77 was proposed. It uses the additional bits in LZ'77 to embed parity bits of R S code originally proposed i n [10]. In LZRS'77, an i nput string X is first encoded using the standard LZ'77 algori thm. Encoded data Y are then split into blocks of 255–2 e byt es, which are processed in reverse order starting wit h the last block. When processing bl ock B n , 2 e parity bits of block B n+1 are computed first using RS(255, 255–2 e ) code and then those bits are 3 embedded in the point ers of block B n using the previously mentioned LZS' 77 scheme. Parity bits of the first block can be stored at the beginning of the file if we also wish to protect the first block. Otherwise, to assure back ward compatibility with the LZ'77 deco der, protection o f the first block should be omitted. In the decoding process, the procedure is perform ed in the opposite order. The first block is corrected (only in the case when the first block is protected as well) using parity bit s appended at the beginning of the file . Then it is decom pressed using the LZS' 77 decompressi on algorithm , which reconstructs the first part of t he original string and also recovers pari ty bits of the second block. The algorithm then corrects and decompresses the second block and continues in this manner till the end of the file. The desired maximum number of errors e to be effectively correct ed in each block during the decoding process is given as an input parameter of t he algorithm. Thi s number is upward-li mite d by the ability to embed bits in the poi nter selection, i.e., by the redunda ncy of the encoded data. In the LZRS'77 algorithm , e is constant o ver all blocks; thu s its value is limited by the blo ck with the lowest redundancy. III. T HE LZRS A '77 A LGORITHM WITH A DAPTIVE P ARITY A constant e over all encodi ng blocks, as in LZRS'77, is not optim al, since redundancy in different parts of data stri ng can differ significantly . If there is just one part of the string that has very low redundancy, it will dictate the maximum value of e for the whole string. Such low- redundancy blocks are usually at the beginning of the encoded data, since there are not yet m any previous matches that would contribute to redundancy. Better utilization of overall redundancy would be possible with an adapti ve e , changing from one block to a nother according to availability of redundancy bits in each block. In that case, low-redundancy parts of the string would affect the error protection performance just of these parts, whereas the rest of the string could be better protected according to its redundancy ava ilability. As a result, the value of e is still upward-limited by the overall redundancy but its average value can be higher, resulting in bette r resistance to errors. On the basis of the above-described assumpt ions, we propose an improved version of the LZRS'77 algorithm , named LZRSa'77, where ' a' refers to adaptive e . The input string X is first encoded u sing the stand ard LZ'77 algor ithm, when the multiplicity M k of each pointer is also recorded. The encoded data is then divided into bl ocks of different lengths , according to the locally available redundancy. First ly, 255–2 e 1 bytes are put in the first block B 1 , where e 1 is given as an input parameter of the algorit hm. Then, the num ber of parity bits 2 e 2 of the second block B 2 is calculated, where e 2 is given as: 1 22 log / 16 k kB eM ∈ = ⎢ ⎥ ⎢⎥ ⎣⎦ ⎢ ⎥ ⎣ ⎦ ∑ . (1) If, for example, the number of addition al bits that could be embedd ed in the pointers multiplicity of the first block ( 2 log i M ∑ ) is 43, then the number of parity bits of the second block woul d be 2 e 2 = 2 ⎣ 43/16 ⎦ = 4. According to the obtained value, the second block length is 255–2 e 2 = 251 bytes. The process is then re peated until the end of the input data is reached. We obtain b blocks of different lengths 255–2 e n . After dividing al l the data into bl ocks of di fferent lengths, t he process of RS coding and embedding of parit y bits is perform ed. The blocks ar e processed in reverse order, from the very last to the first, as with the LZRS'77 alg orithm. The number of parity b its 2 e n for RS coding varies for each block. The sequence of operations of the encoder is illustrated in Fig. 3. As mentioned above, the desired error correction capability of the first block e 1 is given as an input paramet er of an algorithm , whereas e n for all the other blocks are obtained from the redundancy of their preceding blocks and are as high as the redundancy permits. As in the LZRS'77 algorithm, parity b its of th e first block are append ed at the beginn ing of the enco ded data, or omitted if we want to p reserve backward compatibility with th e standard LZ'77 deco der. In the last case, e 1 is equal to zero. The decoding process is sim ilar to that used in the LZRS' 77 decoding algori thm. Each block B n is first error-corrected using 2 e n parity bits known from the previous block B n -1 , then decoded using 4 the LZS'77 decoder to decom press some of the original st ring and obtain 2 e n +1 parity bit s of the next block. The amount of parity bi ts is used to determ ine the length of t he next block B n +1 , whereas the parity bits themselves are used to correct the block. The process is continued to the last block. A high-level descripti on of the encoding and decoding algorit hms is shown in Fi g. 4. Fig. 3. The sequence of operations on the com pressed data as processed by the LZRSa’ 77 encoder. Here RS n are parity bits of the block B n . IV. E XPERIMENTAL R ESULTS To evaluate the performance of t he proposed algorithm, we performed several tests with different files from t he Calgary corpus [11]. We im plement ed our proposed algorithm in the Matlab 6.5.1 Release 13 program t ool. For the basic LZ'77 encoding, the LZ'77 algorit hm with a sliding-window length of 32 ki lobytes was used. It was i mplem ented in Mat lab as well. Maxim um le ngth of point ers was chosen to be 255 bytes. LZRS A '77_E NCODER ( X , e 1 ) let b , j ← 1, 0 [ P , p ] ← LZ'77_C OMPRESS ( X ) while j < | P | do append ( j + 1 )…( j + 255 – 2 e b ) bytes of P to B b let j ← j + 255 – 2 e b let b ← b + 1 evaluate e b by counting possible pointers in p for B b -1 for n ← b ,…,2 do let RS n ← RS_E NCODER ( B n , e n ) embed in the block B n- 1 the bits RS n using LZS'77 let RS 1 ← RS_E NCODER ( B 1 , e 1 ) let B ← ( B 1 , B 2 ,…, B b ) return e 1 , RS 1 , B LZRS A '77_D ECODER ( e 1 , RS 1 , B ) D ← empty str ing let B 1 ← first 255 – 2 e 1 bytes of B let j ← 255 – 2 e 1 + 1 let n ← 2 if RS_D ECODER ( B 1 + RS 1 , e 1 ) = errors then correct B 1 append LZ'77_D ECOMPRESS ( B 1 ) to D while j < | B | do recover RS n from the pointers in B n -1 using LZS'77 let e n ← half a number of RS n bytes let B n ← next 255 – 2 e n bytes of B from index j on let j ← j + 255 – 2 e n let n ← n + 1 if RS_D ECODER ( B n + RS n , e n ) = errors then correct B n append LZ'77_D ECOMPRESS ( B n ) to D return D Fig. 4. The error-resilient LZ'77 algorithm with adaptive parity 2 e n . Here X is the input string, e 1 is the maxim um num ber of errors that can be correct ed in the first block, P is the LZ'77 encoded string of pointers, p is a vector of possible positions for each pointer, B n are blocks of encoded da ta of variable length 255–2 e n , RS n are RS parity bits of the block B n , and D is the recovered string. 5 In the experiment, we fi rst compared the m axima l value of constant e and average value of an adaptive e (E( e n )) in different test strings . For this purpose, we encoded different file s from the Calgary corpus using the LZRS' 77 and LZRSa'77 algorit hms. For m aximal e observation, we performed tests only on strings of 10,000 by tes length, since t he lowest-redundancy parts proved to be in the first blocks of the encoded strings, b ecause there are not so many past sym bols. Thus, different string lengt hs do not affect the m aximal e , as long as the beginning of t he string is the same. For this reason, we rather perform ed tests fo r different substrings of the sam e length within each file starting at differe nt positions. Average maxim al e obtained over all tested substri ngs for each file is given in the second co lumn of Table I, whereas maxima l e of the first substring of each file (and thus that correspondi ng to the whole file) is gi ven in the thi rd column. Even if, in an unexpected case, the lowest redundancy part of the whol e file is not wit hin the first 10,000 sy mbols, the obtained results were still relevant, sin ce we made additional experiments on error-correction performance on the first 3000 and 30,000 sy mbols wit h the same constant parity used. When observing E( e n ), we performed m easurements on two different lengths of source strings, i.e., 3000 bytes and 30,000 byt es, and we again perform ed the tests on different substrings within each file for both lengths. The value of e 1 was in all cases equal to 1. Resu lts are shown in fourth and fifth columns of Tabl e I. The experiment resul ts showed that the m aximal const ant e that could be em bedded in the redundancy of the encoded string is in the best case equal to 3, whereas average adaptive e over large number of bl ocks could be from 4.5 up to 8. These results already jus tify the use of adaptive e . To justify it further, we performed another expe riment. We tested the ability of each algorithm to correct random errors. TABLE I V ALUES OF MAXIMAL CONSTANT AND AVERAGE ADAPTIVE e FOR DIFFERENT LENGTH ( L ) SUBSTRINGS OF THE C ALGARY CORPUS FILES file name E( e max ) over substrings with L =10,000 e max of the whole file E[E( e n )] over substrings with L =3000 E[E( e n )] over substrings with L =30,000 bib 2.00 2 4.79 5. 29 book1 2.38 2 4.75 4. 94 book2 2.18 1 4.64 5. 04 geo 2.40 3 5.48 8. 32 news 1.92 1 5.05 5. 93 obj1 2.50 2 5.05 / obj2 1.46 1 4.68 6. 77 paper1 2.00 1 4.64 5. 14 paper2 1.88 1 4.65 4. 80 paper3 1.75 1 4.62 4. 87 paper4 1.00 1 4.70 / paper5 1.00 1 4.75 / paper6 1.67 1 4.81 5. 14 progc 2.00 2 4.65 5. 70 progl 2.00 2 4.48 6. 21 progp 2.25 2 4.96 5. 69 trans 1.22 2 4.82 6. 26 When testing error correction performance, we pe rform ed measurem ents on three different files from Calgary corpus, i.e., news , progp , and geo , which allow m aximal values of constant e equal to 1, 2, and 3 respectively, as shown in Tabl e I. Measurement s were made on the first 3000 and 30,000 bytes of each file respectively. When using the LZRSa'77 algorithm, e 1 could be an arbitrary value. However, we chose values that approximat ely correspond to E( e n ) for each of the tested files. Thus, we chose e 1 = 5 for the news and progp test strings, and e 1 = 8 for the geo test string. We tested the resilience to errors by introduci ng different number of erro rs random ly distributed over the wh ole encoded string. Fo r error generation, we used a built-in Matlab functio n, called randerr , which generates patterns of geom etrically distributed bit errors. Results for the three test strings, all in two di fferent length variati ons , and for both described algorithms used (LZR S'77 and LZRSa'77) are shown in the graphs in Fig. 5 to Fig. 7. Each case of string type, string length and al gorithm used was t est ed with different numbers of injected errors. 6 For each number of errors, 100 trials with different random ly distributed erro rs were performed and number of successful data recovers t ested. In the graphs in Fig. 5 to Fig. 7, the m easured results are plotted wi th discrete poi nts, whereas continuous curves represent a polynomial-fitte d approxima tion. The results show quite an improvement in error correction capability when usin g the LZRSa'77 alg orithm instead of LZRS'77, which is a direct consequence of the larger am ount of parity used in t he first algorithm . The performance improvem ent decreases with increasing constant e from 1 to 3, but is still noticeable also in the last case, which is pr actically the best we could ach ieve with the LZRS'77 alg orithm. As can be seen from the results, the performance im prove ment also som ewhat in creases with increasing length of the string. This is probably due to the increasing E( e n ) with increasing lengt h of the string, as evident from Table I, whereas constant e rem ains the same. The performance of the LZRSa' 77 algorithm could be slightly furt her improved using higher value of e 1 , which would, however, im prove only the protecti on of the first block. a) b) Fig. 5. The number of successful recovers am ong 100 trials for two different length ( L ) substr ings of the file news , for increasing number of bit errors geom etrically distributed over the encoded strings, represented as Bit Err or Rate (BER), end different algorithm used (LZRS'77 and LZRSa'77). a) L = 3000 bits; b) L = 30,000 bits. 7 a) b) Fig. 6. The number of successful recovers am ong 100 trials for two different length ( L ) substr ings of the file progp , for increasing number of bit er rors geometrically distributed ove r the encoded strings, re presented as BER, end different algorithm used (L ZRS'77 and LZRSa'77). a) L = 3000 bits; b) L = 30,000 bits. a) 8 b) Fig. 7. The number of successful recovers am ong 100 trials for two different length ( L ) substr ings of the file geo , for increasing number of bit er rors geometrically distributed ove r the encoded strings, re presented as BER, end different algorithm used (L ZRS'77 and LZRSa'77). a) L = 3000 bits; b) L = 30,000 bits. V. C ONCLUSION An improved version of the error-resilient LZ'77 data com pression scheme was presented. It allows use of adaptive number of parity bits ove r different blocks of en coded data according to available redundancy in the blocks. Compared to the recently proposed LZRS'77 scheme allowing only constant number of parity bits along the whole string, the new solution better utilizes available redundancy in the string, resulting in a larger numbe r of errors that can be effectively corrected. Such an improvement does not practically degrade t he compression rate com pared to the LZRS'77 algorithm. Even though the parity of each block has to be calculated each time from the redundancy of the previous block, the tim e complexit y of the new algorithm remains on the order of t hat of the LZRS'77 algorithm . However, some legacy from the LZRS'77 algorithm still remains in the new algorithm and represents two unsolved problems. The first is a question of an online encodi ng process, which could not be achieved due to the reverse order of block processing. The second is protecti on of the first block while maintaining back ward compatibility. R EFERENCES [1] J. Ziv and A. Lem pel, “A universal al gorithm for sequential data compression, ” IEEE Trans. Inf. Theory , vol. IT-23, no. 3, May 1977, pp. 337–343. [2] M. E. Hellm an, “On using natural redundancy for err or detection”, IEEE Trans. on Commun. , vol. 22, October 1974, pp. 1690–1693. [3] K. Sayood and J. C. Borkenhagen, “U se of residual r edundancy in the desi gn of joint source/channel coders,” IEEE Trans. on Commun. , vol. 39, June 1991, pp. 838–846. [4] K. Sayood, H. Otu, and N. Dem ir, “Joint s ource/channel coding for va riable length codes,” IEEE Trans. Commun. , vol. 48, no. 5, May 2000, pp. 787–794. [5] M. J. Atallah and S. Lonardi, “Authe ntication of LZ-77 compr essed data,” SAC 2003 , Melbourne, FL, 2003, pp. 282– 287. [6] S. Lonardi and W. Szpankowski, “Joi nt source- channel LZ’77 coding,” in Proc. IEEE Data Compression Con f. , Snowbird, UT, 2003, pp. 273–282. [7] Y. Wu, S. Lonardi, and W. Szpankowski, “Error-resilient LZW data compression,” in IEEE Data Compression Conf. , Snowbird, UT, 2006, pp. 193–202. [8] S. Lonardi, W. Szpankowski, and M. D. Ward, “Error re silient LZ’77 data compression: algorithms, analy sis, and experiments,” IEEE Trans. Inf. Theory , vol. 53, no. 5, May 2007, pp. 1799–1813. [9] RFC 1951: DEFLATE compressed data format specification version 1.3 , P. Deutsch, Aladdin Enterpr ises, May 1996. Available: http://www.ie tf.org/rfc/rfc1951.txt [10] I. S. Reed and G. Solomon, “Polynom ial codes over certain finite fields,” J. SIAM , vol. 8, 1960, pp. 300–304. [11] The Calgary corpus . Available: http://corpus.canter bury.ac.nz/descriptions/#calgary
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment