Fast k Nearest Neighbor Search using GPU
The recent improvements of graphics processing units (GPU) offer to the computer vision community a powerful processing platform. Indeed, a lot of highly-parallelizable computer vision problems can be significantly accelerated using GPU architecture.…
Authors: Vincent Garcia, Eric Debreuve, Michel Barlaud
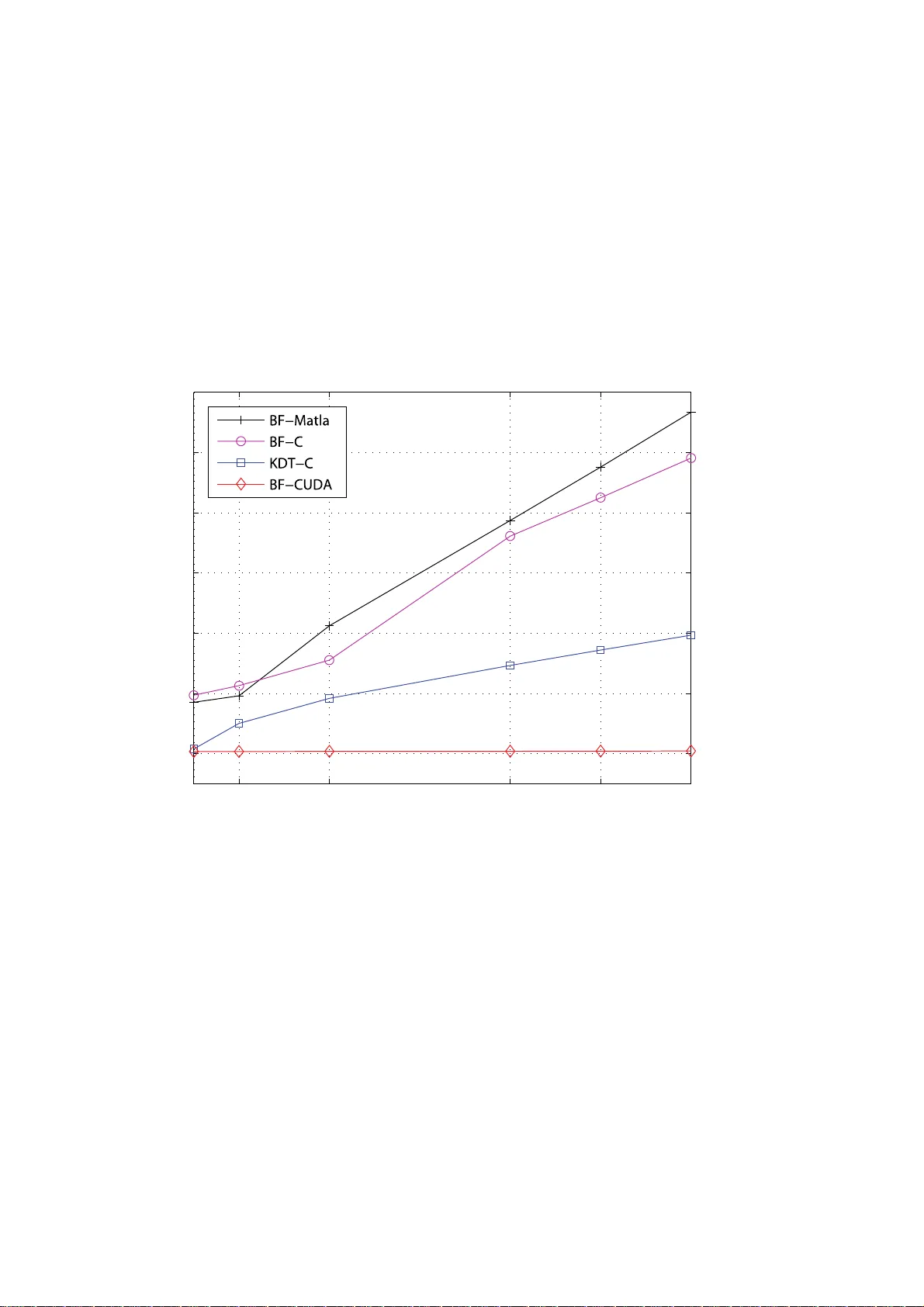
Fast k Nearest Neighbor Search using GPU V incent Garcia and Eric Debreuve and Michel Ba rlaud November 26, 2024 2 The rec ent impro v ements of graphi cs process ing units (GPU) of fer to th e com- puter vision community a po werful process ing pl atform. Indeed , a lot of high ly- paralle lizabl e compu ter vis ion proble ms can be si gnificant ly acceler ated using GPU archite cture. Among these algorithms, the k nearest neighb or search (KNN) is a well-kno w n proble m linked with many applicati ons such as classification , estima- tion of statisti cal prope rties, etc. T he main drawba ck of this task lies in its compu- tation b urde n, as it gro ws poly nomially with the data size. In this paper , w e show that the use o f the NVIDIA CUD A API acc elerate s the sear ch for the KNN u p to a fact or of 120. 0.1 Introd uction A graphics processing unit (also called GPU) is a dedic ated graphi cs render ing de vice for a perso nal computer , work station , or game console. GP U is highly spe- cialize d for paral lel computing . T he recent impro vemen ts of GPU s offe r a power - ful process ing platform for both grap hics and non-grap hics applicat ions. Indeed, a lar ge proportion of computer vision algorithms are parall elizabl e and can great ly be accelerated using GPU. The use of GPU was, uptil recently , not easy for non- graphi cs application s. The introductio n of the NVIDIA CUD A (Compute Unified Dev ice Architecture ) brought, through a C-based A PI, an easy way to tak e adv an- tage of the high performan ce of GPUs for paral lel computing. The k nearest neighbo r search problem (KNN) is encounter ed in many differ ent fields. In statist ics, one of the first dens ity estimate [LQ65] was indeed formu- lated as a k nearest neighbo r problem. It has since appeared in many application s such as KNN-based class ification [Das91, SDI06] and image filtering [Y ar85]. More recently , some effect i ve estimates of high-dime nsiona l stati stical measures ha ve been prop osed [KL87]. These works ha ve some compute r visi on applica- tions [BWD + 06, GBDB07]. The KNN search i s usu ally slo w be cause it i s a heavy pro cess. The co mputatio n of the distanc e between two poin ts requires m any b asic operatio ns. The resolutio n of the KNN search polynomia lly gro ws with the size of the poin t sets. In this paper , we show ho w GP U can accelera te the process of the K NN search using NVIDIA CUD A. Our CUDA implementatio n is up to 120 times faste r than a similar C implementation . Moreo ver , we show that the space dimension has a neg ligible impact on t he co mputatio n time fo r the CUD A implement ation contrary to the C implementatio n. These two improv ements allo w to (1) decrease the time of computat ion, (2) red uce the size rest riction gen erally nec essary to solve KNN in a reason able time. 0.2. K NEARES T NEIGHBORS SEARCH 3 0.2 k Near est Neighbors Search 0.2.1 Pr oblem definition Let R = { r 1 , r 2 , · · · , r m } be a set of m reference points in a d dimensional space, and let Q = { q 1 , q 2 , · · · , q n } be a set of n query points in the same space. The k neares t neighb or search problem consist s in searching the k neares t neighb ors of each query point q i ∈ Q in the reference set R giv en a specific distance. Com- monly , the E uclide an or the Manhattan distan ce is used b ut any other distance can be used instead such as infinity norm distance or Mahalan obis distan ce [Mah36]. Figure 1 illustrates the KNN problem with k = 3 and for a set of points in a 2 dimensio nal space. One wa y to se arch the KNN is the “brut e force” algorithm (noted BF), also called Figure 1: Ill ustrati on of the KNN search problem for k = 3 . The blue points corres pond to the re ferenc e points a nd the red cros s cor respon ds to the query point. The circle giv es the distance between the query point and the third closest reference point. “ex hausti ve search” . For eac h query point q i , the BF algori thm is the follo w ing: 1. Compute all the distanc es between points q i and r j with j in [1 , m ] . 2. Sort the computed distanc es. 3. Select the k reference points prov iding to the smallest distances. 4. Repeat steps 1. to 3. for all query points. The main issu e of this algorithm is its huge complex ity: O ( nmd ) for the nm distan ces compute d (approximatel y 2 nmd addition s/sub tractions and nmd multi- plicati ons) and O ( nm log m ) for the n sorts performed (mean number of compar - isons) . 4 Sev era l KN N algorith ms hav e been proposed in order to reduce the computat ion time. They genera lly seek to reduce the number of distances computed. For in- stance , some algorith ms [AMN + 98] partition the space using a KD-tree [B en75, Ind04], and only comput e distanc es within specific nearby vo lumes. W e show in sectio n 0.3 that, according to our exper iments, the use of such a method is 3 times fast er than a BF method. The BF m ethod is by nature highly-p arallel izable. Indeed, all the distance s can be compute d in parallel. Like wise, the n sorts can be done in parallel. This proper ty makes the BF method perfectly suitable for a GPU implementation. Accordin g to our e xperimen ts, w e sho w in section 0.3 that the use of CU D A is 120 times faste r than a similar C implementa tion and 40 times fa ster than a kd-tree based method. 0.2.2 Ap plications The KNN sear ch is a problem encoun tered in man y graph ics and non-graph ics ap- plicati ons. Frequen tly , this problem is the bottlen eck of these appli cation s. T here- fore, p roposi ng a fas t KNN search ap pears cr ucial. In this section , we presen t three importan t applications using KNN search . Entro py estimation In informatio n theory , the Shannon entrop y [CT 91, Sha48] or informat ion entro py is a measure of the uncertai nty associa ted with a rando m varia ble. It quan tifies the informat ion containe d in a message, usually in bits or bits/sy mbol. It is the mini- mum message length necessar y to communica te information . T his also repre sents an absolut e limit on the best possible lossless compressi on of any c ommunicat ion: treatin g a message as a series of symbols, the shortest possible representat ion to transmit the mes sage is the Shannon entrop y in bits/symbol multip lied by the nu m- ber of symbols in the original message. The entropy estimati on has se v eral applications like tomography [Gzy02], motion estimatio n [BWD + 06], or object trackin g [GBDB07]. The Shannon entrop y of a random variab le X is H ( X ) = E ( I ( X )) (1) = − Z p ( x ) log p ( x ) dx (2) where I ( X ) is the information content or self-inf ormation of X , w hich is itself a random va riable, and p is the probab ility densi ty function of X . Giv en a set of point Y = { y 1 , y 2 , · · · , y n } in a d -dimension al space, K ozac henk o and Leonenk o propose in [KL87] an entrop y estimator based on the distan ce be- tween each point of the set and its nearest neighbo r . Goria et al. propose in [GLMI05] a general ization using the distance, noted ρ k ( y i ) , between y i and its k -th nearest neighb or . 0.2. K NEARES T NEIGHBORS SEARCH 5 The estimate d entropy b H n,k ( Y ) dependin g on n and k is gi ve n by b H n,k ( Y ) = 1 n n X i =1 log(( n − 1) ρ k ( y i )) + log( c 1 ( d )) − Ψ( k ) (3) where Ψ( k ) is the digamma funct ion Ψ( k ) = Γ ′ ( k ) Γ( k ) = Z ∞ 0 e − t t − e − k t (1 − e − t ) dt (4) and c 1 ( d ) = 2 π d 2 d Γ( d 2 ) (5) gi ve s the v olume of the unit ball in R d . Classificati on and clustering The class ification is the act of orga nizing a dataset by classe s such as color , age, locatio n, etc. Giv en a training dataset (pre vi ously called refere nce set) where each item belong s to a class, sta tistica l classification is a procedure in whic h a class pre- sented in the traini ng dataset is assi gned to each item of a giv en query datas et. For each item of the query dataset , th e classificatio n based on KNN [Das91, S DI06] locate s the k closest members (KNN), generally using the Euclidean distance, of the training dataset. The catego ry mostly repres ented by the k closes t members is assign ed to the considered item in the query dataset becaus e it is statistic ally the most probable categ ory for this item. Of course, the computing time goes up as k goes up, b ut the adv antage is that higher valu es of k provi de smoothing that re- duces vulne rability to noise in the trainin g data. In pr actica l applicatio ns, typicall y , k is in unit s or tens rathe r than in hundreds or thousand s. The term “classificatio n” is synonymou s with what is commonly kno wn (in m a- chine learnin g) as clustering. Statistical c lassificat ion algorit hms are typically used in patte rn recognition systems. Content-based image r etrie va l Content- based imag e retrie v al (CBIR) [LSD J06, Low03] is the applic ation of com- puter vision to the image retrie v al problem, that is, the problem of search ing for digita l images in large databa ses. “Content-base d” means that the search will an- alyze the actual conten ts of the image. The term “content” in this conte xt might refer colors, shapes, textu res, or any other infor mation that can be deri v ed from the i mage itself . The techni ques, tools, and al gorithms that a re used o rigina te from fields such as statis tics, pattern recogn ition, signa l proce ssing, and computer vi- sion. Giv en an image databas e and a q uery imag e, Schmid and Mo hr pr opose in [SM96] a simple KNN-based CBIR algori thm: 6 1. Extract ke ypoin ts [HS88, MS04, SMB98] in the que ry image. 2. Compute the de script ion vect or fo r eac h e xtract ed ke ypo int [Lo w03, M S05]. Each vector , also called descripto r , is a set a v alues describ ing the local neighb orhoo d of the con sidere d key point . 3. For each descrip tor , search in the image databa se the k closest descriptors accord ing to a distance (typically Euclidean or Mahalanobis di stance ). Then, a v oting algorith m determin es the most likely image in the referenc e image databa se. The search of the k closest descripto rs is a KNN search problem. The main issue of CBIR is the computation time. In his contex t, the descriptor size is generall y restric ted to insure a reaso nable computati onal time. A typica l valu e is between 9 and 128 . 0.3 Experiments The initi al goal of our work is to spee d up the KNN search proc ess in a Mat- lab program. In order to speed up computa tions, Matlab allo ws to use external C functi ons (Mex func tions). Like wise, a recent Matlab plug-in allo ws to use ex - ternal CUD A functio ns. In this section, we sho w , through a comput ation time comparis on, that CUD A gr eatly accelera tes the KNN search process . W e compare three differ ent i mplementat ions of the BF method and one method based o n kd-tree (KDT) [AMN + 98]: • BF method implemente d in Matlab (note d BF -Matlab) • BF method implemente d in C (not ed BF -C) • BF method implemente d in CUD A (noted BF-CUD A) • KDT method implemen ted in C (note d K DT -C) The KDT method used is the A NN C library [AMN + 98]. This method is com- monly used because it is faster than a BF method. The computer used to do this comparis on is a Pentium 4 3.4 GHz with 2GB of D DR memory and a NVID IA GeForce 880 0 GTX graphic card. The table 1 presents the computat ion time of the KNN search process for each method and implementati on listed before. This time depen ds both on the size of the point sets (referenc e and query sets) and on the space dimension. For the BF method, the parameter k has not ef fect on this time. Indeed , the access to any ele- ment of a sor ted array is done in a consta nt time. O n the c ontrary , the co mputatio n time of the KDT method in creases with the parame ter k . In th is paper , k was set t o 20 . 0.3. EXPE RIMENTS 7 Methods N=1200 N=2400 N=480 0 N =9600 N=1920 0 N=38400 D = 8 BF-Matlab 0.53 1.93 8.54 37.81 154.82 681.05 BF-C 0.55 2.30 9.73 41.35 178.32 757.29 KDT -C 0.15 0.33 0.81 2 .43 6.82 18.38 BF-CUD A 0.02 0.10 0.38 1.71 7.93 31.41 D=16 BF-Matlab 0.56 2.34 9.62 53.64 222.81 930.93 BF-C 0.64 2.70 11.31 47.73 205.51 871.94 KDT -C 0.28 1.06 5.04 23.97 91.33 319.01 BF-CUD A 0.02 0.10 0.38 1.78 7.98 31.31 D=32 BF-Matlab 1.21 3.91 21.24 87.20 359.25 1446.36 BF-C 0.89 3.68 15.54 65.48 286.74 1154.05 KDT -C 0.43 1.78 9.21 39.37 166.98 688.55 BF-CUD A 0.02 0.11 0.40 1.81 8.35 33.40 D=64 BF-Matlab 1.50 9.45 38.70 153.47 626.60 2521.50 BF-C 2.14 8.54 36.11 145.83 587.26 2363.61 KDT -C 0.78 3.56 14.66 59.28 242.98 1008.84 BF-CUD A 0.03 0.12 0.44 2.00 9.52 37.61 D=80 BF-Matlab 1.81 11.72 47.56 189.25 761.09 3053.40 BF-C 2.57 10.20 42.48 177.36 708.29 2811.92 KDT -C 0.98 4.29 17.22 71.43 302.44 1176.39 BF-CUD A 0.03 0.12 0.46 2.05 9.93 39.98 D=96 BF-Matlab 2.25 14.09 56.68 230.40 979.44 3652.78 BF-C 2.97 12.47 49.06 213.19 872.31 3369.34 KDT -C 1.20 4.96 19.68 82.45 339.81 1334.35 BF-CUD A 0.03 0.13 0.48 2.07 10.41 43.74 T able 1: Comparis on of the computa tion time, gi v en in seconds, of the methods (in each cell respecti v ely for top to bottom) BF -Matlab, BF-C, KDT -C, and BF - CUD A. BF-CUD A is up to 120 times faster than BF-Matlab , 100 times faster than BF-C, and 40 times faste r than KD T -C. 8 In the table 1, N corresp onds to the numbe r of reference and query points, and D corres ponds to the space dimension. The computation time gi ven in seconds, cor - respon ds respecti v ely to the m ethods BF-Matlab, BF-C, KDT -C , and BF-CUDA. The chosen v al ues fo r N and D are typica l v alu es that can be found in papers usi ng the KNN search. The main result of this paper is that, in most of cases, CUD A all o ws to greatly reduce the time needed to resolve the KNN search problem. BF-CUD A is up to 120 times faster than BF-Matlab, 100 times faster than BF-C, and 40 times faster than KDT -C. For instan ce, with 3840 0 referenc e and query points in a 96 dimen- sional space, the computation time is approxi mately one hour for BF -Matlab and BF-C, 20 minutes for the KDT -C, and only 43 second s for the BF -CUD A. The consid erable speed up we obtai n comes from the highly-para llelizable propert y of the BF method. The table 1 rev eals another important result. L et us consider the case where N = 4800 . The computati on time seems to increase linea rly with the d imensio n of the points (see figure 2). The major differe nce between these methods is the slope of the increas e. Indeed, the slope is approximatel y 0 . 56 for BF -Matlab method, 0 . 48 for BF-C method, 0 . 20 for KDT -C method, and quasi-n ull (actu ally 0 . 00 1 ) for BF-CUD A m ethod. In other word s, the meth ods BF-Malab, BF-C, a nd KDT -C are all sensi ti ve to the spa ce dimension in term of computa tion time (KDT method is less sensi ti ve than BF methods). On the contrary , the space dimension has a neg ligible impact on the computatio n time for the CUD A implementation. This beha vi or is more important for N = 38400 . In this case, the slope is 34 for BF-C, 31 for BF-Matlab, 14 for KDT -C, and 0 . 14 for BF-CU D A. T his character istic is particu larly useful for applicat ions like KNN-based content- based image retrie v al (see section 0.2.2): the descriptor size is genera lly limited to allo w a fast retrie v al proces s. W ith our CU D A implemen tation , this size can be much higher bringing more precisio n to the local desc riptio n and conseque ntly to the retrie v al process . The table 1 prov ides further interesting results . First, w e said before that, in most of c ases, BF-CUD A is the faste st meth od to resolve the KNN se arch problem. Let us no w consi der the cases where D = 8 and N = 19200 or N = 3840 0 . In these cases, the f astest method is the KDT -C. The e xp lanatio n of why BF-CUDA is not the fastest method is inheren t in CUD A. W it h D = 8 , there are few operat ions needed to compute the distance between two points and the most of the time is spent in data copie s between CPU memory and GP U memory (accordin g to the CUD A profiler). O n the contrar y , KDT -C does not require this data transfer . W ith D > 8 , e ve n if the most of the comput ation time is still spent in memory transfer , BF-CUD A be comes the most interest ing implementat ion. This tab le sho w s also t hat t he KDT implementation is gene rally 3 times f aster tha n BF implementa tion. 0.3. EXPE RIMENTS 9 8 16 32 64 80 96 0 10 20 30 40 50 60 Dimensio n Computation time in seconds b Figure 2: Ev olut ion of the computatio n time as a functio n of the point dimensio n for method s BF -Matlab, BF-C, BF-CUDA, and KDT -C. The compu tation time in- crease s linearly with the dimensi on of the poin ts whate v er the method used. How- e ver , the increa se is quas i-null with the B F-CUD A. 10 0.4 Conclusion In this pape r , we propose a fast k near est neighbors search (KNN) implement ation using a graphics processing units (GPU). W e sho w that the use of the NVIDIA CUD A API accelerates the resolut ion of KNN up to a fact or of 120. In particu - lar , this improv emen t allows to reduce the size restric tion generally necessa ry to search KNN in a reasonab le time in KNN -based con tent-b ased image retrie v al ap- plicati ons. Bibliograph y [AMN + 98] S. A RY A , D. M . M O U N T , N. S. N E T A N Y A H U , R. S I L V E R M A N et A. Y . W U : An optimal a lgorith m for ap proximat e nearest neigh bor search - ing fixed di mensions . Journ al of the A CM , 45( 6):891 –923, 1998. [Ben75] J. L. B E N T L E Y : Multidi mension al binary search trees used for asso- ciati v e searching. Comm unicat ions of the ACM , 18(9):509– 517, 1975. [BWD + 06] S. B O L T Z , E. W O L S Z T Y N S K I , E. D E B R E U V E , E. T H I E R RY , M. B A R - L AU D et L. P R O N Z A TO : A minimum-entro py procedure for rob ust motion estimation. In IEEE Internation al Confer en ce on Image P r o- cessin g , page s 1249–12 52, Atlanta, USA, 2006. ICIP’06. [CT91] T . C OV E R et J. T H O M A S : Elements of Informatio n Theory . W ile y , New Y ork , 1991. [Das91] B. V . D A S A R A T H Y : N ear est Neighbor (NN ) Norms: NN P attern Classific ation T echn iques . IEEE Compu ter Soci ety Pres s, Los A lami- tos, CA, 1991 . [GBDB07] V . G A R C I A , Sylv ain B O L T Z , E. D E B R E U V E et M. B A R L AU D : Outer- layer based tracking using entrop y as a similarity m easure. In IEEE Intern ationa l Confer enc e on Imag e Pr o cessing (ICIP) , S an A ntonio , T exas , USA, September 2007. [GLMI05] M.N. G O R I A , N.N. L E O N E N K O , V .V . M E R G E L et P .L. N ovi I N V E R - A R D I : A new class of rando m vect or entrop y estimators and its ap- plicati ons in testing statis tical hypot heses. Jou rnal of Nonpar ametric Statis tics , 17(3):277 –297, 2005. [Gzy02] H. G Z Y L : T omographic reconstruct ion by m aximum entrop y in the mean: uncons trained reconst ruction s. Applied Mathematics and Com- putati on , 129(2-3):1 57–16 9, 2002. [HS88] C. H A R R I S et M. S T E P H E N S : A combined corner and edge detect or . In P r oceedings of T he F ourth A lve y V ision C onfer ence , pages 147– 151, Manchest er , UK, 1988. 11 12 BIBLIOGRA PHY [Ind04 ] P . I N DY K : Nearest neighbors in high- dimensio nal spaces . In Jacob E. G O O D M A N et Joseph O ’ R O U R K E , éditeurs : Handbook of D iscr ete and Computation al G eometry , chapter 39 , chapit re 39. CRC Press, 2004. [KL87] L. K O Z A C H E N K O et N. L E O N E N K O : O n statistic al estimati on of entrop y of random vec tor . Pr oblems of Information T r ansmiss ion , 23(2): 95–10 1, 1987 . [Lo w03] D. L O W E : Distincti ve image features from scale-in v ariant k ey- points . IEEE T ransactio ns P attern Analysis Machin e Intelligen ce , 20:91 –110, 2003. [LQ65] D. L O F T S G A A R D E N et C. Q U E S E N B E R RY : A nonparametr ic es- timate of a multiv ariate density function . A nnals Math. Statistic s , 36:10 49–10 51, 1965. [LSDJ06] M. S. L E W , N. S E B E , C. D J E R A B A et R. J A I N : Conte nt-base d mul- timedia information retrie v al : State of the art and challen ges. ACM T ransact ions on Multimedia Computing, Communications, and Ap- plicat ions , 2(1) :1–19, 2006. [Mah36] P .C. M A H A L A N O B I S : On the genera lized distance in statistics. In National Institu te of Scien ce of India , 1936. [MS04] K. M I K O L A J C Z Y K et C. S C H M I D : Scale & af fine in v arian t interest point detectors. IEEE T ransa ctions P attern Analys is Mach ine Intelli- gen ce , 60(1):63–8 6, 2004. [MS05] K. M I K O L A J C Z Y K et C. S C H M I D : A perfor mance ev alu ation of local descript ors. IEE E T ransacti ons P attern Analysis Machine Intel- lige nce , 27(10):16 15–16 30, 2005. [SDI06] G. S H A K H N A RO V I C H , T . D A R R E L L et P . I N DY K : Near est -Neighbo r Methods in Learni ng and V ision: T heory and P rac tice (Neur al Infor - mation Pr ocessing) . T he MIT Press, 2006 . [Sha48] C. E. S H A N N O N : A mathematic al theory of communicatio n. Bell System T echnical Journ al , 27:379–4 23, 623– 656, July , Octobe r 1948. [SM96] C. S C H M I D et R. M O H R : Image retrie v al using local characteri zation . In IEEE Internation al C onfer ence on Imag e Pr oces sing , v olu me 2, pages 781–78 4, September 1996 . [SMB98] C. S C H M I D , R. M O H R et C. B A U C K H AG E : Compa ring and ev al- uating inter est points. In IEEE Interna tiona l Confer enc e on Image Pr ocessing , Bombay , India, January 1998. BIBLIOGRA PHY 13 [Y ar85 ] Leonid P . Y A R O S L A V S K Y : Digital Pictur e Pr ocessing . S pringer - V er lag New Y ork, Inc., 1985. 0 50 100 150 200 250 300 0 0. 2 0. 4 0. 6 0. 8 1 1. 2 1. 4 k Computation time in seconds Comb sort Insertion sort 0 500 1000 1500 2000 2500 3000 3500 4000 4500 0 20 40 60 80 100 120 Number of point s k 0
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment