An efficient methodology for modeling complex computer codes with Gaussian processes
Complex computer codes are often too time expensive to be directly used to perform uncertainty propagation studies, global sensitivity analysis or to solve optimization problems. A well known and widely used method to circumvent this inconvenience co…
Authors: Am, ine Marrel, Bertr
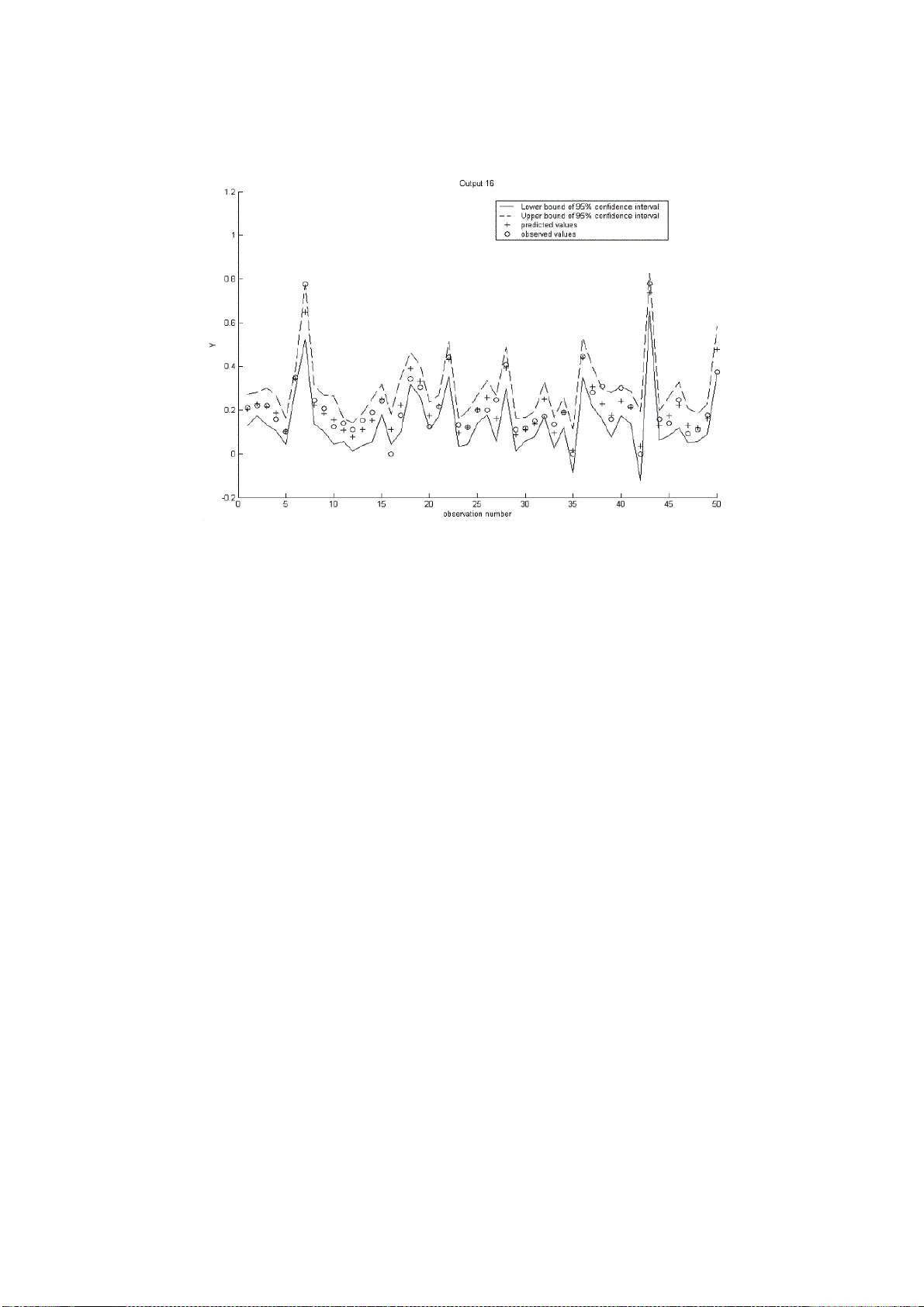
An efficien t metho dology for mo deling complex computer co des with Gaussian pro cesses Amandi n e MARREL ∗ , 1 , Bertran d IOOSS † , F ran¸ cois V AN DORPE ⋆ , Elena V OLK OV A ‡ ∗ CEA Cadarac he, D EN/DTN/SMT M/LMTE † CEA Cadarac he, DEN/DER/SESI/LCFR ⋆ CEA Cadarac he, DEN/D2S/ SPR ‡ Kurc hato v Institute, Russia Abstract Complex computer codes are often too time exp ensive to b e directly used to p erform uncertaint y propagatio n studies, global sensitivity analysis or to solv e op- timizatio n problems. A well known and w idely u sed metho d to circumv ent this inconv enience consists in replacing the complex computer co de b y a reduced m odel, called a metamod el , or a resp onse surface that repr esen ts the computer code and requires acceptable calculation time. One p articular class of metamod els is stud- ied: the Gaussian p r ocess model that is c haracterized by its m ea n and co v ariance functions. A sp ecific estimation pro cedure is developed to adjust a Gaussian pro- cess model in complex cases (non linear relations, highly disp ersed or discontin uous output, high dimensional inp u t, inadequate sampling designs, etc.). T he efficiency of this algo rithm is compared to the efficie ncy of other existing algorithms on an analyt- ical test case. The pr oposed metho dology is also illus tr at ed for the ca se of a complex hydrogeo logical compu ter code, simulat ing r adion uclide transp ort in groundwater. Keyw ords: Gaussian pro cess, kriging, resp onse su r face , uncertaint y , cov ariance, v ariable s election, computer cod es. 1 Corresp onding a uthor: A. Mar rel DEN/DTN/SMTM/LMTE, 13108 Saint Paul lez Durance , Cedex, F rance Phone: +3 3 (0)4 42 2 5 26 52, F ax : +33 (0)4 42 25 62 72 Email: ama ndine.marrel@cea.fr 1 1 INTR ODUCTION With the adv ent of computing technology and n umerical method s, inv estigatio n of computer code experiments r emains an imp ortan t challenge. Complex computer mod els calculate sev eral output v alues (scalars or fu nctio ns) whic h can d epend on a high number of input p arameters and physical v ariables. T hese compu ter models are used to make s im u lat ions as well as predictions or sensitivit y studies. Imp or- tance measures of eac h uncertain inp u t v ariable on the resp onse v ariability provide guidance to a better un d erstanding of the mod eling in ord er to reduce the resp onse uncertaintie s most effec tively (Saltelli et al. (2000), Kleijnen (1997), He lton et al. (2006)). Ho wev er, complex computer codes are often to o time exp ensive to b e directly used to conduct uncertaint y propagation studies or global sensitivity analysis based on Mon te Carlo m et ho ds. T o av oid the p roblem of huge calculatio n time, it can be useful to replace the complex compu ter code by a mathematical approximat ion, called a resp onse surface or a surrogate mo del or also a metamodel. The resp onse surface method (Bo x and Draper (198 7 )) consists in constructing a fun cti on that sim ulates the b ehavio r of real phenomena in th e v ariation range of the influential parame- ters, starting from a certain n umb er of experiments. Similarly to th is theory , some method s h a ve b een devel op ed to build surrogates for long ru nning computer cod es (Sac ks et al. (1989), Osio and Amon (1996), Kleijnen and S argent (2000), F ang et al. (2006)). Several m eta mo dels are classically used : p olynomials, s plines, generalized linear mo dels, or learning statistic al mod els suc h as n eural net works, supp ort vec tor mac hines, . . . (Hastie et al. (2002), F ang et al. (200 6 )). F or sensitivit y analysis and uncertaint y p ropagat ion, it wo uld b e usefu l to obtain an analytic predictor f orm u la for a m eta mo del. Indeed, an analytical f ormula often allo w s the d irect calculation of sensitivity in d ices o r output uncertainties. Moreo ver, engineers and physicists prefer inte rpr eta ble mod els that give some u n derstanding of the simulat ed physical phenomena and parameter interact ions. Some metamod- els, suc h as p olynomial s (Jourd an and Zabalza-Mezghani (200 4 ), Kleijnen (2005), Iooss et al. (2006)), are ea sily interpretable bu t not alwa ys v ery efficien t. Oth ers, for instance neural netw orks (Alam et al. (200 4 ), F ang et al. (2006)), are more efficien t but do not provide an analytic predictor formula. 2 The kriging method (Matheron (1970), Cressie (1993)) has been d ev elop ed for spatial int erp olatio n problems; it takes into account spatial statistica l structure of the estimated v ariable. Sac ks et al. (19 89 ) h a ve extended the kriging principles to com- puter exp eriment s by considering the correlation b et ween t wo resp onses of a computer code dep ending on the distance b et ween inp ut v ariables. The kriging model (also called Gaussian pr ocess mo del), c haracterized by its mean and cov ariance functions, presents several adv antag es, especially the interpolation and in terpretability proper- ties. Moreo ver, n umerous auth ors (for example, Currin et al. (1991), S antner et al. (2003) and V azquez et al. (2005)) sho w that this model can p r o vide a statistical framework to compute an efficien t p redictor of cod e resp onse. F rom a practical standp oi nt, constructing a Gaussian pro cess mo del implies es- timation of sev eral hyp erparameters included in the cov ariance fu nction. T his opti- mization problem is particularly difficult for a mo del with m an y inp uts and inade- quate s amp ling designs (F ang et al. (2006), O’Hagan (2006)). In th is pap er, a sp ecial estimation pro ce du r e is develo p ed to fit a Gaussian pro ce ss mo del in complex cases (non linear relatio ns, highly disp ersed output, high dimensional inpu t, inadequate sampling designs). O ur purp ose includes dev eloping a pro cedure for parameter esti- mation via an essential step of input parameter selection. Note that w e do n ot deal with the design of experiments in compu ter code simulatio ns (i.e. c ho osing v alues of input parameters). Indeed, we wo rk on data obtained in a previous study (the hydrogeo logical mo del of V olk ov a et al. (2008)) and try to adapt a Gauss ian p rocess mod el as well as p ossible to a non-optimal sampling design. In s u mmary , th is study presents tw o main ob jectiv es: developing a method ology to implemen t and adapt a Gaussian pr ocess m o del to complex data while studying its prediction capabilities. The next section br iefly explains the Gaussian p rocess mo deling from theoretica l expression to pr edict or formulati on and model p aramet erization. In section 3, a parameter estimation pro cedure is introd uced from the numerical standp oin t an d a global methodology of Gaussian pro cess mo deling implementat ion is presented. Section 4 is d ev oted to applications. First, the algorithm efficiency is compared to other algorithms for the example of an analytic al test case. Secondly , the alg orithm is applied to the data set (20 in puts and 20 outp u ts) coming from a h ydr og eologica l transp ort mo del based on wate rflow an d diffusion disp ersion equations. The last 3 section pr o vides some p ossible extensions and concluding remarks. 2 GA USS IAN PR OCESS MODELING 2.1 Theoretical mo del Let us consider n realizat ions of a computer code. Each r ea lization y ( x ) of the com- puter code output corresp onds to a d -dimensional input v ector x = ( x 1 , ..., x d ). Th e n p oin ts corresp onding to the co de runs are called an exp erimental design and are denoted as X s = ( x (1) , ..., x ( n ) ). The outputs will b e denoted as Y s = ( y (1) , ..., y ( n ) ) with y ( i ) = y ( x ( i ) ) , i = 1 , ..., n . Gaussian process (Gp) mo deling trea ts the determin- istic resp onse y ( x ) as a r ealization of a r andom function Y ( x ), including a regression part and a cente red stochastic pr ocess. Th is model can b e written as: Y ( x ) = f ( x ) + Z ( x ) . (1) The deterministic f unction f ( x ) pro vides the mean app ro ximation of the computer code. Our study is limited to the parametric case where the function f is a linear com bination of elemen tary functions. Under this assumption, f ( x ) can b e wr itte n as follo ws: f ( x ) = k X j =0 β j f j ( x ) = F ( x ) β , where β = [ β 0 , . . . , β k ] t is the regression p aramet er vector and F ( x ) = [ f 0 ( x ) , . . . , f k ( x )] is the regression matrix, with eac h f j ( j = 0 , . . . , k ) an elemen tary function. In the case of the one-degree p olynomial r eg ression, ( d + 1) elemen tary fu nctions are used: f 0 ( x ) = 1 , f i ( x ) = x i for i = 1 , . . . , d. In the f ol lowing, we u s e this one-degree p olynomia l f or the regression part, wh ile our methodology can b e extended to other b ases of regression functions. T he r eg res- sion part allows th e addition of an external drift. Without p rior inform ation on the relation b et ween the model output and the in p ut v ariables, th is qu ite simple choice app ears reasonable. In deed, adding this simple external d rift allo ws f or a nonstation- 4 ary glo bal mod el even if the sto c h astic part Z is a stationary pro cess. Moreov er, on our tests of section 4, this simple m odel does not affect our prediction performan ce. This simplification is also reported by S ac ks et al. (198 9 ). The sto c hastic part Z ( x ) is a Gaussian centered p rocess fu lly characterized by its co v ariance fun cti on: Co v( Z ( x ) , Z ( u )) = σ 2 R ( x , u ) , where σ 2 denotes the v ariance of Z and R is the correlation f unction that provides interpolation and sp ati al correlation prop erties. T o simplify , a stationary pro cess Z ( x ) is considered, which means that correlation b et wee n Z ( x ) and Z ( u ) is a fu nction of the difference b et ween x and u . Our study is focused on a particular f amily of correlation functions that can b e written as a pro duct of one-dimensional correlation fu nctions: Co v( Z ( x ) , Z ( u )) = σ 2 R ( x − u ) = σ 2 d Y l =1 R l ( x l − u l ) . Abrahamsen (1994), Sacks et al. (1989), Ch il ` es and Delfiner (199 9 ) and Rasmussen and Williams (2006) give lists of correlation functions w ith their adv antages and drawbac ks. Among all these fu nctions, we choose to u se the generalized exp on ential correlation fu nction: R θ , p ( x − u ) = d Y l =1 exp( − θ l | x l − u l | p l ) w ith θ l ≥ 0 and 0 < p l ≤ 2 , where θ = [ θ 1 , . . . , θ d ] t and p = [ p 1 , . . . , p d ] t are the correlation parameters. Our mo- tiv ations stand on the deriv ation and regularity pr operties of th is fun ct ion. Moreo ve r, different c hoices of co v ariance parameters allow a w id e spectrum of p ossible shap es (Figure 1); p = 1 give s the exp onen tial correlatio n function and p = 2 the Gaussian correlation fun ct ion. Eve n for deterministic computational co des (i.e. outputs corresp onding to th e same inputs are identical ), the outputs ma y b e sub ject to noise (e.g. numerical noise). In this case, an indepen d en t w hite noise U ( x ) is added in the stoc hastic part of the mod el: Y ( x ) = f ( x ) + Z ( x ) + U ( x ) , (2) where U ( x ) is a cente red Gaussian v ariable w ith v ariance ε 2 = σ 2 τ . In terms of co v ariance function, this white n oise introd uces a discontin uity at the origin called 5 0 0.5 1 1.5 2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Exponential correlation function (1D) for different correlation parameter (power parameter p=1) d=|x−u| correlation R(d) θ = 0.5 θ = 1 θ = 3 0 0.5 1 1.5 2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 Generalized exponential correlation function (1D) for different power parameter ( θ = 1) d=|x−u| correlation R(d) power parameter = 0.5 power parameter = 1 power parameter = 2 Figure 1: Generalized exponen tial correlation function for differen t p o w er and correlation parameters. the nugget effect (Matheron (1970)): Co v( Y ( x ) , Y ( u )) = σ 2 R θ , p ( x − u ) + τ δ ( x − u ) , where δ ( v ) = 1 if v = 0 , 0 otherwise. 2.2 Join t and conditional distributions Under the hyp othesis of a Gp m odel, the learning samp le Y s follo ws the m ultiv ariate normal distrib ution p ( Y s | X s , β , σ, θ , p , τ ) = N ( F s β , Σ s ) , where F s = [ F ( x (1) ) t , . . . , F ( x ( n ) ) t ] t is the regression matrix and Σ s = σ 2 R θ , p x ( i ) − x ( j ) i,j =1 ...n + τ I n is the co v ariance matrix with I n the n-dimen s io nal iden tity m at rix. 6 If a new p oin t x ∗ = ( x ∗ 1 , ..., x ∗ d ) is considered, the joint probabilit y distribution of ( Y s , Y ( x ∗ )) is : p ( Y s , Y ( x ∗ ) | X s , x ∗ , β , σ, θ , p , τ ) = N F s F ( x ∗ ) β , Σ s k ( x ∗ ) k ( x ∗ ) t σ 2 (1 + τ ) , (3) with k ( x ∗ ) = ( Co v( y (1) , Y ( x ∗ )) , . . . , Cov( y ( n ) , Y ( x ∗ )) ) t = σ 2 ( R θ , p ( x (1) , x ∗ ) + τ δ ( x (1) , x ∗ ) , . . . , R θ , p ( x ( n ) , x ∗ ) + τ δ ( x ( n ) , x ∗ ) ) t . (4) By conditioning this joint distribu tion on the learning sample, we can readily obtain the conditional distribu tion of Y ( x ∗ ) w hic h is Gaussian (von Mises (196 4 )): p ( Y ( x ∗ ) | Y s , X s , x ∗ , β , σ , θ , p , τ ) = N ( I E [ Y ( x ∗ ) | Y s , X s , x ∗ , β , σ, θ , p , τ ] , V ar [ Y ( x ∗ ) | Y s , X s , x ∗ , β , σ , θ , p , τ ]) , (5) with I E [ Y ( x ∗ ) | Y s , X s , x ∗ , β , σ, θ , p , τ ] = F ( x ∗ ) β + k ( x ∗ ) t Σ − 1 s ( Y s − F s β ) , V ar[ Y ( x ∗ ) | Y s , X s , x ∗ , β , σ , θ , p , τ ] = σ 2 (1 + τ ) − k ( x ∗ ) t Σ − 1 s k ( x ∗ ) . (6) The conditional mean (equation (6)) is used as a predictor. The v ariance formula corresp onds to the mean squared error (MSE) of this p redicto r and is also kno wn as the kriging v ariance. Th is analytical form ula for MSE gives a local indicator of the prediction accuracy . More generally , Gp mo del pro vides an analytical f ormula for the distribu tio n of the output v ariable at an arbitrary new p oin t. This distribu tio n formula can b e us ed for sensitivity and u ncertain ty analysis, as well as for quanti le ev aluation (O’Hagan (2006)). Its use can b e completely or partly analytical and a voids costly method s based for example on a Monte Carlo algorithm. The v ariance expression can also b e used in samplin g strategies (Scheidt and Zabalza-Mezghani (2004)). All these considerations and p ossible extensions of Gp modeling represent significant adv an tages (Cu rrin et al. (1991), Rasmussen and Williams (2006 )). 7 2.3 P arameter estimation T o compute the mean and v ariance of a Gp mo del, estimation of several parameters is needed. Indeed, the Gp model (2) is c h arac terized by the regression parameter ve ctor β , the correlation parameters ( θ , p ) and the v ariance paramete rs ( σ 2 , τ ). Th e maximum likelihoo d metho d is commonly used to estimate these parameters. Given a Gp mod el, the log-lik elihoo d of Y s can b e wr itt en as: l Y s ( β , θ , p , σ, τ ) = − n 2 ln(2 π ) − n 2 ln( σ 2 ) − 1 2 ln(det( R θ , p + τ I n )) − 1 2 σ 2 ( Y s − F s β ) t ( R θ , p + τ I n ) − 1 ( Y s − F s β ) . Giv en the correlation parameters ( θ , p ) and the v ariance parameter τ , the maximum lik eliho od estimator of β is the generalized least squares estimator: ˆ β = ( F s t ( R θ , p + τ I n ) − 1 F s ) − 1 F s t ( R θ , p + τ I n ) − 1 Y s , (7) and the maxim um likelihoo d estimator of σ 2 is: c σ 2 = 1 n ( Y s − F s ˆ β ) t ( R θ , p + τ I n ) − 1 ( Y s − F s ˆ β ) . (8) R emark 2.1 If we c onsider the pr e dictor built on the c onditional me an (e quation (6)), we r eplac e β b y its estimator b β . The pr e dictor writes now \ Y ( x ∗ ) | Y s ,X s , x ∗ ,σ, θ , p ,τ = F ( x ∗ ) b β + k ( x ∗ ) t Σ − 1 s ( Y s − F s b β ) and its M S E has c onse quently an additional c omp onent (Santner et al. (2003)): V ar [ \ Y ( x ∗ ) | Y s , X s , x ∗ , σ, θ , p , τ ] = σ 2 (1+ τ ) − k ( x ∗ ) t Σ − 1 s k ( x ∗ )+ u ( x ∗ )( F s t Σ − 1 s F s ) − 1 u ( x ∗ ) t with u ( x ∗ ) = F ( x ∗ ) − k ( x ∗ ) t Σ − 1 s F s . Matrix R θ , p dep ends on θ and p . C onsequen tly , ˆ β and c σ 2 dep end on θ , p a nd τ . Substituting ˆ β an d c σ 2 into the log-li kelihoo d , we obtain the optimal choic e ( b θ , b p , b τ ) which maximizes: φ ( θ , p , τ ) = − 1 2 h n ln( c σ 2 ) + ln( | R θ , p + τ I n | ) i where | R θ , p + τ I n | = det( R θ , p + τ I n ) . 8 Thus, estimation o f ( θ , p ) and τ consists in numerical optimization of the function ψ defined as follo ws : ( b θ , b p , b τ ) = arg min θ , p ,τ ψ ( θ , p , τ ) with ψ ( θ , p , τ ) = | R θ , p + τ I n | 1 n c σ 2 . Our study is fo cused on complex cases with large d imensions d for the input v ector x ( d = 20 in our second example in section 4), where the sampling design has not b een chosen as a uniform grid. In this setting, minimizing fun cti on ψ ( θ , p , τ ) is an optimization p roblem that is numerically costly and hard to solv e. Several difficulties guide the choice of the alg orithm. First, a large num b er of parameters imp oses the use of a sequential algorithm, w here different parameters are int ro duced step by step. Second, a large parameter domain d ue to the number of parameters and th e lac k of prior b ounds requires an exploratory algorithm able to explore the domain in an optimal wa y . Finally , the observ ed irregularities of ψ ( θ , p , τ ) due, for instance, to a conditioning problem induce local minima, wh ic h recommend the use of a stochastic algorithm rather than a d esce nt algorithm. Seve ral algorithms h a ve b een pr op osed in previous papers. W elc h et al. (1992) use the simplex searc h method and introduce a kind of forw ard selection algorithm in whic h correlation parameters are added step by step to reduce fun ct ion ψ ( θ , p , τ ). In Kenn edy an d O’Hagan’s GEM-SA soft ware (O’Hagan (2006)), which uses th e Ba yesia n formalism, the p osterio r distr ib ution of hyperparameters is maximized via a conjugate gradient metho d (the P ow el metho d is used as the numerical recip e). T h e D ACE Matla b free to olbox (Loph a ven et al. (2002)) introdu ces a p owe rfu l sto c has- tic algorithm based on the Hooke & Jeev es method (Bazaraa et al. (1993)), which unfortun at ely requires a starting point and some b ounds to constrain the optimiza- tion. In complex app lica tions, W elch’s alg orithm reve als some limitations and for high dimensional input, GEM-SA and D ACE s oft ware ca nnot b e applied directly on data includ ing all th e inp ut v ariables. T o solv e this problem, we pr opose a sequential ve rsion (inspired by W elch’s algo rithm) of the D ACE algo rithm. It is based on the step by step inclus ion of inp ut v ariables (previously sorted). Our methodology allo ws progressive parameter estimation by input v ariables selectio n both in the regression part and in the co v ariance function. The complete description of this method ology is the sub ject of the next section. 9 R emark 2.2 O ne of the pr oblems we have to acknow le dge in the evaluation of ψ ( θ , p , τ ) is the c ondition numb er of the prior c ovarianc e matrix. This c ondition numb er affe cts the numeric al stability of the line ar system for the ˆ β determina tion and for the evalu- ation of the determinant. The de gr e e of il l-c onditioning not only dep ends on sampling design but is also sensitive to the underlying c ovarianc e mo del. Ab ab ou et al. (1994) showe d, for example, that a Gaussian c ovarianc e ( p = 2 ) implies an il l-c onditione d c ovarianc e matrix (which le ads to a numeric al ly u nsta ble system), while an exp onen- tial c ovarianc e ( p = 1 ) gives mor e stability. Mor e over, in our c ase, the exp erimental design c annot b e c ho sen and nu meric al p ar ameter estimation is often damage d by the il l-c onditioning pr oblem. The nugget effe ct r e pr esente d by τ solves this pr oblem. Alth ough the outputs of the le arning samp le ar e no longer i nterp olate d, this nugge t effe ct impr oves the c orr elation mat rix c ondition numb er and incr e ases r obustness of our estimation algorithm. 3 MODELING METHODOLOGY Let u s first d eta il the procedu r e used to v alidate our model. Since th e Gp p redictor is an exact interp ola tor (except wh en a nugget effect is includ ed), residu al s of the learning d ata cannot b e used directly . S o, to estimate the mean squ ared error in a non-optimistic wa y , w e us e either a K -fold cross v alidation pro cedure (Hastie et al. (2002)) or a test sample (consisting of n ew d ata , unused in the bu ilding p rocess of the Gp mo del). In b oth cases, the predictivity coefficient Q 2 is computed. Q 2 corresp onds to the classica l coefficient of determination R 2 for a test sample, i.e. for prediction residu als: Q 2 ( Y , ˆ Y ) = 1 − P n test i =1 Y i − ˆ Y i 2 P n test i =1 ¯ Y − Y i 2 , where Y denotes the n test observ ations of the te st set and ¯ Y is their empirical mean. ˆ Y repr esen ts the Gp mod el predicted v alues, i.e. the conditional mean (equation (6)) compu te d which the estima ted v alues of parameters ( b β , b σ , b θ , b p , b τ ). Other simp le v alidation criteria can b e used: the absolute err or, the mean and standard deviatio n of the relativ e residuals, . . . (see, for example, Kleijnen and Sargent (200 0 )), wh ic h are all global measures. Some statistical and graphical analyses of residuals can 10 provide more detailed diagnostics. Our metho dology consists in seve n su cc essive steps. A formal algorithmic defi ni- tion is sp ecified for eac h step. F or i = 1 , . . . , d , let e i denote the i th input v ariable. M 0 = n e (0) 1 , . . . , e (0) d o denotes the complete initial mo del (i.e. all the inpu ts in their initial r anking). M 1 = n e (1) 1 , . . . , e (1) d o and M 2 = n e (2) 1 , . . . , e (2) d o refer to the inputs in new rankings after sorting by differen t criteria (correlatio n coefficient or v ariation of Q 2 ). Finally , M cov and M r eg denote the cu r ren t cov ariance mo del and the cur- rent regression mo del; i.e. the list of selecte d inputs appearing in the co v ariance and regression fun ctio ns. Step 0 - Standardizat ion of input v aria ble s The appr op r iat e procedur e to construct a metamodel requires space filling designs with go od optimality and orthogonalit y pr operties (F ang et al. (2006)). How ever, we are not alw ays able to choose the exp erimenta l d esig n, esp ecially in ind ustrial studies wh en the data h a ve b een generated a long time ago. F u rthermore, other restrictions can b e im p osed; for example, a samp ling d esig n taking into accoun t the prior distribution of inp ut v ariables. T his can ha ve preju dicial consequences for hyperparameter estimation and metamod el quality . So, to increase the robustn ess of our parameter estimatio n algorithm and to opti- mize the meta mo del qualit y , we reco mmend to transform all the inputs in to uniform v ariables. In order to get eac h transformed inpu t v ariable following an u niform dis- tribution U [0 , 1], th e th eo retical d istribution (if kno w n) or th e empirical ones after a piecewise linear approxima tion is applied to the original in puts. This approximat ion is r equired to a void transformin g a future un sampled x ∗ to one of the transformed training sites, eve n if no element of x ∗ is equal to the corresp onding element of any of the untransformed training sites. W e empir ica lly observed that this un iform transfor- mation of the inpu ts s eems well adapted to correctly estimate correlation parameters. Choices of b ou n ds and starting points are also simplified by this stand ardizati on. Step 1 - Initial input v ariables ranking by dec reasing co efficien t of correlation b e tw een e i and Y Sorting input v ariables is necessary to reduce the number of p ossible mo dels, esp e- cially to disso cia te regression and co v ariance models. F u rthermore, direct estimation 11 of all p aramet ers without an efficient starting p oint giv es bad results. So, as a sort criterion, we c ho ose the co efficien t of correlation betw een the input v ariable and the output v ariable under consideration. The correlation coefficien ts b et ween the inpu t parameters an d the outpu t v ariable are the simp lest measures of th e infl uence of inputs on the output (Saltelli et al. (2000)). They are v alid in the linear r ela tion con text, while in the nonlinear con text, they give a fi r st idea of the hierarchy among input v ariables, in terms of their influence on the outp u t. Finally , this simple and intuitiv e choice does not require an y mo deling and app ears a goo d initial method to sort the inputs when no other inf ormatio n is av ailable. F or a strongly n onlinear computer co de, it could b e in teresting to use a qualitativ e method , indep endent of the mod el complexity , in order to s ort the inputs by in fluence order (Helton et al. (200 6 )). Another p ossibilit y would b e to fit an initial Gp m o del with an in tercept only regression part and al l comp onen ts of p equal to 1 o r 2. Only the corr elation coefficients ve ctor θ has to b e estimated. Then, sensitivity measures such as th e Sob ol indices (S altelli et al. (2000), V olk ov a et al. (2008)) are computed and u sed to sort the inputs by influ ence ord er. Algorithm M 0 = n e (0) 1 , . . . , e (0) d o = ⇒ M 1 = n e (1) 1 , . . . , e (1) d o M r eg = M 1 M cov = M 1 Step 2 - Initialization of the correlation paramet er b ounds and st a rting p oin ts for the estimation pro cedure T o constrain the ψ optimization, th e DA CE estimation pro cedure requires three follo wing v alues for each correlat ion p aramete r: a lo wer bound , an u p per b ound and a starting point. These v alues are crucial for the success of the estimation algorithm, when it is used d irect ly for all th e in put v ariables. Ho wev er, using sequen tial esti- mation based on progressive introd uction of input v ariables, we limit the problems associated with these thr ee v alues, esp ecia lly with the starting p oint v alue. Another wa y to reduce the imp ortance of starting p oint and boun ds is to increase the num b er of iterations in D ACE estimation algo rithm. How eve r, in the case of a high num b er of inpu ts, increasing the number of iterations in DA CE can become extremely time exp ensiv e; a compromise has to b e found. As the inp u t v ariables ha ve b een p r evio usly 12 transformed into standardized uniform v ariables, the initia lization and the b ounds of the correlation parameters can be the same for all th e inputs: ✸ lo wer b ounds for eac h component of θ and p : l ob θ = 10 − 8 , l ob p = 0, ✸ upp er b ounds for eac h comp onen t of θ and p : upb θ = 100 , upb p = 2, ✸ starting p oin ts for estimation of each comp onent of θ and p : θ 0 = 0 . 5 , p 0 = 1. Step 3 - Successiv e inclusion of input v ariables in the co v ariance function F or eac h set of inpu ts included in the co v ariance fun ctio n, all the in puts f rom the ordered set in the regression function are ev aluated. Correlation and regression parameters are estima ted by the DA C E mo d ified algorithm, with the v alues, esti- mated at th e ( i − 1) th step for the same regression mo del, used as a starting p oin t. More precisely , at step i , input v ariables numbered f rom 1 to i are included in th e co v ariance fun ct ion and the algorithm estimates pairs of the correlation parameters ( θ l , p l ) for l = 1 , . . . , i . As the starting point, the algorithm uses correlation parame- ters obtained at the ( i − 1) th step for the starting v alues of (( θ 1 , p 1 ) , . . . , ( θ i − 1 , p i − 1 )). First s ta rting v alue of ( θ i , p i ) is fixed to an arbitrary reference v alue. Then, at each step, selection of v ariables in the r eg ression part is also made. Hoeting et al. (2006) recommends the corrected Ak aike information criterion (AICC) for inp u t selectio n in the regression mod el in order to take sp at ial correla tions into accoun t. Therefore, after the estimation of corr elation and regression parameters, the AICC is computed: AICC = − 2 l Y s ˆ β , ˆ θ , ˆ σ + 2 n m 1 + m 2 + 1 n − m 1 − m 2 − 2 , where m 1 denotes the number of inpu t v ariables in the r egressio n fun ction, m 2 those in the co v ariance function and l Y the log-like liho od of the sample Y . The required mod el is the one minimizing this criterion. Algorithm F or i = 1 . . . d ✸ Step 3.1: V ariables in cov ariance fun ctio n M i,cov = M cov (1 , . . . , i ) 13 ✸ Step 3.2: Su cce ssive inclusion of input v ariables in regression function F or j = 1 . . . d • Regression Model: M j,r eg = M r eg (1 , . . . , j ) • Paramete r estimatio n: θ init = ( θ 1 ( i − 1) ,j , . . . , θ i − 1 ( i − 1) ,j , θ 0 ) t p init = ( p 1 ( i − 1) ,j , . . . , p i − 1 ( i − 1) ,j , p 0 ) t [ θ i,j , p i,j ] = D ACE estimation( M i,cov , M j,r eg , [ θ init , p init ] , [ l ob θ , l ob p ] , [ upb θ , upb p ]) • AICC C r iterio n computation AICC( i, j ) = AICC ( M i,cov , M j,r eg ) End ✸ Step 3.3: Op timal regression mod el selection: j optim ( i ) = arg min j (AICC( i, j )) ✸ Step 3.4: Q 2 ev aluation by K -fold cross v alidatio n or on test d ata (with current correlati on mo del and op timal regression model) Q 2 ( i ) = Q 2 ( M i,cov , M j optim ( i ) ,reg ) End This ord er (correlation outer, regression inner) can b e ju s tified by minimizing th e computer time required for optimization. The selec tion pro cedure for the regression part is made by the minimization of AICC criterion wh ich requires, at each step, only one parameter estimation. On the other han d , the cov ariance selection is made by the m aximiz ation of Q 2 which is often compu ted by a K -fold cross v alidation. This pro cedure requ ires, at eac h step, K estimatio n pro cedures. So, the lo op on cov ariance selection is the more exp ensiv e, and consequently has to b e outer. The c hoice of K dep ends on the n umber of observ ations of the data set, on the co nstraints in term of computer time and on the influence of the learning sample size on pred iction qualit y . If few data are a v ailable, a leav e-one-out cross-v alidation could b e p referred to a K -fold pro ce du r e to a void an und esirably negativ e effect of small learnin g sets on prediction quality . R emark 3.1 T o avoid some biases on the choic e of the optimal c ovarianc e mo del in the next two steps, the c o efficient Q 2 has to b e c ompute d on a test sample (or by a 14 cr oss validatio n pr o c e dur e), differ ent fr om the one use d f or the final validation of the Gp mo del at step 7. Other criteria often u sed in the optimization of the compu ter exp eriment designs (Sac ks et al. (1989), Santner et al. (2003)) could b e considered to select the optimal regression an d cov ariance model. Th ese criteria are b ased on the v ariance of Gp mod el: they pro duce a model that m in imize s the maximum or the integral of predic- tiv e v ariance o ver input sp ac e. Ho wev er , in the case of a high number of inp uts, the optimization of these criteria can b e very computer time expen s iv e. The adv anta ge of the Q 2 statistic is its relativ ely fast ev aluatio n, while pr oducing a fin al mod el that optimizes the predictiv e p erformance. Step 4 (optional) - New input v ariables ranking in the co v ariance f unction based on the evolution of Q 2 (inputs sorted by decreasing “jumps” of Q 2 ) This optional step improv es the selection of inp uts, particularly in the co v ariance function. F or each input X i , the increase of th e Q 2 coefficient (denoted ∆ Q 2 ( i )) is computed wh en this i th v ariable is added to the cov ariance fu nctio n. This v alue is an indicator of the con tribution of the i th input to the accuracy of the Gp mo del. F or this reason, it can b e jud icious to use v alues ∆ Q 2 (1) , . . . , ∆ Q 2 ( d ) to sort the inputs included in the correlat ion fu nctio n. The inputs are sorted by decreasing of v alues ∆ Q 2 ( i ) and the procedur e of parameter estimation is r epeated with this new ranking of inpu ts for the co v ariance function (step 3 is rerun). Algorithm • Ev aluation of Q 2 increase for each input v ariable in clud ed in the cov ariance function: ∆ Q 2 ( k ) = Q 2 (1) F or k = 2 . . . d ∆ Q 2 ( k ) = Q 2 ( k ) − Q 2 ( k − 1) end • Sorting input v ariables b y decreasing of ∆ Q 2 M 1 = ⇒ M 2 Step 5 (optional) - Algorithm for parameter estimation with new ranking 15 of input v ariables in the co v ariance function This optional step improv es the selection of inp uts, particularly in the co v ariance function. The pro cedure of parameter esti mation (step 3 ) is r ep eated with the inpu ts sorted by decreasing v alues of ∆ Q 2 ( i ) in the cov ariance f unction. Consequently , correlation parameters r ela ted to the in puts that are the most influential for the increase of the Gp m o del accuracy are estimated in the first place. F urthermore, w e can also hop e that the use of this n ew ranking allo ws a decrease in the number of inputs includ ed in the cov ariance function and an optimal input selectio n. Th e us e of this new ranking app ears more judicious and justifiable for the cov ariance function than sorting b y decreasing correlati on coefficien t (cf. step 1). Ho wev er, the ranking of step 1 is k ept for the regression function. Algorithm M r eg = M 1 M cov = M 2 Step 6 - Opt imal co v ariance mo del selection F or eac h set of inputs in the cov ariance fun ctio n, the optimal regression model is selected based on min im ization of the AICC criterio n (cf. step 3.3 ). Then, the predictivit y co efficie nt Q 2 is computed either by cross v alidation or on a test sample (cf. step 3.4). Finally , the selected cov ariance mod el is the one corresp onding to the highest Q 2 v alue. Algorithm i optim = arg max i ( Q 2 ( i )) M optim cov = M cov (1 , . . . , i optim ) M optim r eg = M r eg (1 , . . . , j optim ( i optim )) Step 7 - Final v alidation of the optimal Gp mo del After building and selec ting the optimal Gp mod el, a final v alidation is neces- sary to ev aluate the pr edictiv e perform ance and to ev entually compare it to other metamodels. T o do this, coefficient Q 2 is ev aluated on a n ew test sample (i.e. data not u sed in the bu ilding pro ce dur e). If only f ew data are av ailable, a cross v alidation pro cedure can b e considered. So, t wo cross v alidation pro cedures are ov erlapp ed; one 16 for bu ilding the mod el and one for its v alidation. Algorithm Q f inal 2 = Q 2 ( M optim cov , M optim r eg ) After all the steps of our algo rithm (including th e step 5), we can often lin k the inputs app earing in the co v ariance and r eg ression functions with the nature of their effects on the outp ut. Indeed, we can generally observed 4 cases: the inputs w ith only a linear effect whic h are supp osed to appear only in th e regression and excluded from the cov ariance with the step 5, the inp uts with only a non-linear effect which are excluded from the r eg ression and can then appear in the co v ariance with the re- ordering of M cov at step 5, the inp uts with b oth effect s appearing in the regression and co v ariance fu nctio ns and, finally , the inactive input v ariables excluded from b oth. 4 APPLICA TIONS 4.1 Analytical test case First, an analytic al fun ction called the g-function of Sobol is used to illustrate and justify our metho dolog y . The g-function of Sob ol is defined for d inputs uniformly distributed on [0 , 1] d : g Sob ol ( X 1 , . . . , X d ) = d Y k =1 g k ( X k ) where g k ( X k ) = | 4 X k − 2 | + a k 1 + a k and a k ≥ 0 . Because of its complexit y (strongly nonlinear and non-monotonic relationship) and the a v ailabilit y of analytical sensitivity ind ices, the g-function of Sob ol is a we ll known test example in the studies of global sensitivity analysis algorithms (Saltelli et al. (2000)). Th e contribution of each input X k to the v ariability of the model output is represented by the w eight ing co efficien t a k . The lo wer this coefficien t a k , the more 17 significant the v ariable X k . F or example: a k = 0 → X k is very imp ortan t, a k = 1 → X k is relative ly imp ortan t, a k = 9 → X k is non imp orta nt, a k = 99 → X k is non significan t. F or our analytical test, we c h oose a k = k . Applying our methodology to the g-fun ctio n of Sob ol, we illustrate its different steps, esp eci ally the imp ortance of r erunning the estimation pro cedure after sorting the inpu ts by decreasing ∆ Q 2 (cf. steps 4 and 5). At the same time, comparisons are made with other reference softw are like, for example, th e GEM-SA softw are (O’Hagan (2006), fr ee ly a v ailable at http ://www.ctc d.gr oup.shef.ac.uk/gem.html ). T o do this, different dimensions of inp uts are considered, from 4 to 20: d = 4 , 6 , . . . , 20. F or each dimension d , we generate a learnin g sample formed by N LS = d × 10 simulatio ns of the g-function of Sob ol follo w ing th e Latin Hyp ercub e Samp lin g (LHS) m ethod (McKay et al. (1979)). Using these learning d ata , tw o Gp mod els are built: one follo wing our metho dolog y and one u sing the GEM-SA softw are. F or eac h metho d, the Q 2 coefficient is computed on a test sample of N T S = 1000 points. F or each dimension d , t his procedur e is repeated 50 times to obtain an a ve rage p erformance in terms of the prediction capabilities of eac h m ethod (mean of Q 2 ). The standard d evia tion of Q 2 is also a goo d indicator of the robustness of eac h method . F or each dimension d , the mean and standard deviatio n of Q 2 computed on the test sample using differen t methods are presente d in T able 1. Three methods are compared: the GEM-SA softw are, our metho d olo gy without steps 4 and 5, and our method olo gy with steps 4 and 5. F or the v alues of d h ig her than 6, our metho dology including doub le selection of inp uts (with steps 4 and 5) cle arly outp erforms the others. More precisely , th e p ertinence of reru nning th e estimation pro cedu re after sorting th e inputs by decreas- ing ∆ Q 2 is obvious. The p r edictio n accuracy is muc h more robust (low er standard deviation of Q 2 ). The drawbac k of our metho dology lies in the somewhat costly steps 4 and 5. 18 g-Sobol GEM-SA softw are Gp metho dology Gp metho dology simulat ions without steps 4 and 5 with steps 4 and 5 d N LS Q 2 sd Q 2 sd Q 2 sd 4 4 0 0.82 0.08 0.60 0.21 0.86 0.07 6 6 0 0.67 0.24 0.59 0.16 0.85 0.05 8 8 0 0.66 0.13 0.61 0.10 0.85 0.04 10 100 0.59 0.25 0.63 0.13 0.83 0.05 12 120 0.57 0.16 0.61 0.15 0.84 0.05 14 140 0.60 0.17 0.61 0.14 0.83 0.03 16 160 0.62 0.11 0.67 0.06 0.86 0.04 18 180 0.66 0.09 0.67 0.05 0.84 0.03 20 200 0.64 0.09 0.72 0.07 0.86 0.02 T a ble 1: Mean Q 2 and standard deviation sd of the predictivit y co efficien t Q 2 for sev eral implemen tations of the g-function of Sob ol. Indeed, sequential estimati on and rerunnin g of the pr ocedure r equire man y executions of the Hook e & Jeeves algorithm, particularly in the case of a double cross v alidation (cf. steps 3.4 and 7 of th e algorithm). Consequently , this app roac h is muc h more computer time exp ensive than th e GEM-SA soft ware. F or example, for a simulation with d = 10 and N LS = 100, the computing time of our appr oa ch is on a verage ten times larger than that of the GEM-SA soft ware. F or a p racti tioner, a compromise is usually made b et ween the time to obtain the sampling design p oint s and the time to b uild a metamodel. As a conclusion of this section, our m etho dology is int eresting f or high d imensional input mo dels (more than ten), f or inadequ at e or small sampling designs (a few hundreds) and when simpler method olo gies hav e failed. The data p resen ted in the next section fall into this scope. R emark 4.1 The Gp mo del use d in the GEM-SA softwar e has a gaussian c ovarianc e function. Our mo del uses a gener alize d exp onential c orr elation function even if it r e quir es the estimation of twic e as many hyp erp ar ameters. Inde e d, the se quential appr o ach al lows to estimate a lar ge numb er of hyp erp ar ameters. 19 4.2 Application on an h ydrogeologic transp ort co de Our metho dolog y is now applied to the data obtained from the modeling of strontium 90 (noted 90 Sr) transp ort in satur ated p orou s media using the MAR T HE soft ware (deve lop ed by BRGM , the F r enc h Geological Sur v ey). The MAR THE computer cod e mod els flo w and tr ansport equatio ns in three-dimensional p orous formations. In the con text of an environmen tal impact study , th is code is used to m o del 90 Sr transp ort in saturated media for a radwaste temporary storage site in Ru ssia (V olko v a et al. (2008)). On e of the fin al purp oses is to determine the short-term ev olution of 90 Sr transp ort in soils in order to help r ehabilita tion decision making. Only a partial c haracterization of the site h as b een m ade and , consequent ly , v alues of the mo del input parameters are not kno wn p recisel y . One of the first goals is to identify the m ost influential parameters of the co mpu ter co de in order to improv e the characteriza tion of the site in an optimal w ay . Beca use of large computing time of the MAR THE code, V olk ov a et al. (2 008) propose to constru ct a metamo d el on the basis of the fi rst learning sample. I n the following, our Gp m etho dology is applied and its results are compared to the previous ones obtained with b o osti ng regression trees and linear regression. 4.2.1 Da ta presen t ation Data simulated in this s tu dy are comp osed of 300 obs er v ations. Each simulati on consists of 20 inpu ts and 20 outputs. The 20 uncertain mo del parameters are p erme- abilit y of different geolo gical lay ers composing the simulated field (parameters 1 to 7), longitudinal disp ersivity co efficie nts (parameters 8 to 10), transverse dispers ivity coefficients (parameters 11 to 1 3), sorption coefficients (parameters 14 to 16), poros- it y (parameter 17) and meteoric w ater infiltration intensities (parameters 18 to 20). T o stud y sensitivit y of the MAR THE code to these parameters, simulations of these 20 parameters ha ve been made by the LHS method . F or eac h simulated set of parameters, MAR THE cod e computes transp ort equa- tions of 90 Sr and predicts the evol ution of 90 Sr concen tration. Initial and boun dary conditions for the flow and transp ort mo dels are fixed at the s ame v alues for all simulat ions. So, for an initial map of 90 Sr concentration in 2002 and a s et of 20 input parameter v alues, MAR THE code computes a map of predicted co ncentrations 20 in 2010. F or eac h simulation, the 20 outputs considered are v alues of 90 Sr concen- tration, p redicted for year 2010 , in 20 piezometers lo ca ted on the wa ste rep ository site. 4.2.2 Com parison of three differen t mo dels F or eac h output, we choose to compare and analyze the r esults of three mod els: ⊲ Linear r eg ression: it represent s a mo del that provides a referen ce for the con tribution of the Gp mo del sto c h astic component to modeling qual- it y . In deed, comparison b et ween simple linear regression and Gp mod el will show if considering spatial correlatio ns has significan t impact on the mod eling results. Moreo ver, a selectio n based on the AICC criterion is implemente d to optimize the results of the linear regression. ⊲ Boosting of regression trees: this mo d el wa s u sed in the previous study of the data (V olko v a et al. (2008)). The b oosting trees metho d is based on sequential construction of wea k mo dels (here regression trees with lo w inte raction depth), that are then aggregated. The MAR T algorithm (Mul- tiple Additive Regression T rees), describ ed in Hastie et al. (2002), is used here. The b oosting trees method is relatively complex, in the sense that, as with neur al netw orks, it is a blac k b o x mo del, efficient b ut quite d iffi- cult to in terpret. It is interesting to see if a Gp mod el, that is easier to inte rpr et and offers a quickly computable predictor, can comp ete with a more complex method in terms of m odeling and prediction qu ali ty . Note that the b oosting trees algorithm also makes its pr op er inpu t s election. ⊲ Gaussian pro cess: to implement this model, the method ol ogy previously describ ed in th is pap er is applied, with the input selection p r ocedure. 4.2.3 Resul ts T o compare prediction qualit y of th e three different mo dels presented ab o ve, th e coefficient of p redictivit y Q 2 is estimated by a 6-fold cross v alidation. Note that for each mo del the results corresp ond to the op timal set of inputs included in the mod el. T o a vo id some bias in the results, the cross v alidation used to selec t v ariables in the Gp model (see step 6) differs fr om the cross v alidation used to v alidate and 21 compare prediction capabilities of the three mod els. Indeed, at eac h cross v alidation step (used to v alidate), d at a are divid ed into a learnin g samp le (denoted LS 1) of 250 observ ations and a test sample ( T S 1) of the 50 remaining observ ations. F or the Gp mo del, the procedu r e of v ariable selectio n is then p erformed by a second cross v alidation on LS 1 (for example: a 4-fold cr oss v alidation, dividing LS 1 into a learning set LS 2 of 210 data and a test set T S 2 of the 40 others). Then, an optimal set of v ariables is determined and a Gp m o del is built based on the 250 data of LS 1 (with this optimal set of inputs previously selec ted). Finally , the model is v alidated on the test set T S 1 that has n ever b een used f or the Gp model construction. The results are presented in T able 2 and are tak en up in a barplot (see Figure 2). Results obtained for the output 8 (piezomete r p 110 ) are not considered b ecause of physically in significan t concen tration v alues. F or most outputs, the Gp p erformance is sup erior to linear r egression and b oosting, in many cases substant ially so. Con- cerning the outp uts 11 ( p 27 k ) and 19 ( p 4 a ), th e perf orm ances of the Gp model are wo rse than the linear regression ones. Ho wev er, for th ese t wo outputs, the p redictio n errors are v er y high and consequent ly the difference of p erformance b et ween the tw o mod els can b e consid ered as non-significant. As exp ected, for most of the outputs, the linear regression presents the worst results. When this mo del is successfully adap ted, the tw o others are also efficien t. When linea r regression fails (for example, for o utpu t num b er 12), Gp model presen ts a real interest, since it gives results as goo d as those of the b oosting trees metho d. In fact, this is verified f or all the oup uts and r esults are significantly better for s everal outputs (outputs 1, 2, 4, 9, 12, 13 and 16). T o illustr at e this, the Figure 3 sh o ws the predicted v alues vs r eal v alues for the outp ut 16, for the Gaussian process and b oosting trees mo dels. It clearly sh o ws a b etter repartition of the Gp mo del r esiduals than the bo osting trees mod el ones. F urthermore, the estimator of MS E , that is expressed analyticall y (see Equation (6)), can b e used as a local p r edictio n interv al. T o illustrate th is, w e consider 50 observ ations of the outp ut 16. Figure 4 shows the observe d v alues, the predicted v alues and the upp er and lo wer b ounds of the 95% pred iction interv al based on the MSE lo cal estimator. It confirms th e goo d adequacy of th e Gp mo del for this ou tp ut b eca use all the obs erv ed v alues (except one p oint) are ins id e the prediction interv al 22 Output Linear regression b o osting trees Gaussian pro cess Denomination Num b er Q 2 Q 2 Q 2 p1-76 1 0.31 0.59 0 .84 p102K 2 0.48 0.64 0.78 p103 3 0.10 0.43 0.5 p104 4 0.69 0.83 0.96 p106 5 0.17 0.29 0.45 p107 6 0.40 0.78 0.86 p109 7 0.40 0.45 0.5 p2-76 9 0.19 0.58 0 .86 p23 10 0.74 0.94 0.935 p27K 11 0.52 0.60 0 .43 p29K 12 0.55 0.80 0 .93 p31K 13 0.27 0.51 0 .69 p35K 14 0.26 0.55 0 .56 p36K 15 0.54 0.60 0 .60 p37K 16 0.59 0.62 0 .90 p38 17 0.25 0.43 0 .52 p4-76 18 0.67 0.95 0.96 p4a 19 0.16 0.17 0 .09 p4b 20 0.39 0.27 0.37 T a ble 2: Predictivit y co efficien ts Q 2 for the three differen t mo dels of the MAR THE data. curves. 4.2.4 Ana lysis These results confirm the p otenti al of the Gp mod el and justify its application for computer codes. Application of our method olo gy to complex data also confirms the efficiency of our input selection pro ce du r e. F or a fixed set of inputs in the cov ariance function, w e can v erify that this p rocedure selects the best set of inputs in regression part. F urthermore, the necessity of condu ct ing sequ ential and ordered pro cedure estimation h as b een demonstrated. Indeed, if all the Gp parameters (i.e. considering the 20 inp uts) are directly and simultaneously estimated with the D ACE alg orithm, they are not correctly determined and p oor results in terms of Q 2 are obtained. So, 23 0 0,2 0,4 0,6 0,8 1 p1-76 p102K p103 p104 p106 p107 p109 p2-76 p23 p27K p29K p31K p35K p36K p37K p38 p4-76 p4a p4b Piezometers Q 2 Linear regression Boosting Gaussian process Figure 2: Barplot of the predictivit y co efficien t Q 2 for the three differen t mo dels. Figure 3 : Plot of predicted v alues vs real v alues for b o osting trees (left) and Gaussian pro cess (righ t). in case of a complex mo del with a large number of inputs, we recommend u sing a selection p rocedure such as th e algo rithm of section 3. The stu d y of these data ha ve moti v ated the choice of this methodology . At first, W elch’s algo rithm (see section 2.3) h as b een tried. C on s idering th e p oor results 24 Figure 4: Plot of observ ed and G aussian process predicted v alues for the output 16 with the 95% prediction interv al based on \ M S E formula. obtained, our method olo gy based on the DA C E estimation algorithm has b een de- ve lop ed. T o illustrate this, let us detail the different results obtained on the output num b er 9. With our methodology based on the D ACE estimation, the Q 2 coefficient (alw ays co mpu ted b y a 6-fold cross v alidation) is 0 . 86 , while with W elc h’s algo rithm (used in its basic version), Q 2 is clo se to zero. The difference in the results b etw een the t wo metho ds can be explained by the v alue of estimated correlatio n parameters which are significant ly d ifferen t. T o minimize the num b er of correlation p aramet ers and consequ ently r educe com- puter time required f or estimatio n, the p ossible v alues of p o wer parameters p i ( i = 1 , . . . , d ) can b e limited to 0 . 5, 1 and 2. It can b e a solution to optimize computer time. It allows an exhaustiv e, qu ic k and optimal representation of different kin ds of correlation fun ctions (t wo kin ds of inflexion are repr esen ted). F ur thermore, in many ca ses, estimation of p o wer parameter with generaliz ed exp onen tial corr elation con verges to exp onen tial ( p i = 1) or Gaussian ( p i = 2) correlation. 25 5 CONCLUSION The Gaussian pro ce ss model presents some real ad v anta ges compared to other meta- mod els: exact in terp olat ion prop ert y , simple analytical formulat ions of the p redic- tor, a v ailabilit y of the mean squared error of the predictions and the pr o ved ef- ficiency of th e mod el. The ke en inte rest in this method is testified by the p ub- licatio n of the r ec ent monographs of Santner et al. (2003), F ang et al. (2006) and Rasmussen and Williams (2006 ). Ho wev er, for its application to complex indu strial problems, developing a robust implementa tion metho dology is required. In this paper, we ha ve outlined some dif- ficulties arising from th e p aramete r estimatio n procedu re (instability , high n umber of parameters) and the necessit y of a pr og ressive mo del construction. Moreov er , an a priori c hoice of regression function and, more imp ortan t, of co v ariance fu nctio n is essent ial to parameterize the Gaussian pro cess model. Th e generalize d exp onential co v ariance function app ears in our exp erience as a judicious and r ecommend ed choic e. Ho wev er, this co v ariance fu nctio n requires the estimation of 2 d correlation parame- ters, where d is th e inpu t space dimension. In this case, the sequ en tial estimation and selection pro cedures of our m et ho dology are more app ropriate. This method olo gy is inte resting when the computer m o del is rather complex (non linearities, thr eshold effects, etc.), with high d imensional in puts ( d > 10) an d for small size samples (a few hundreds). Results obtained on the MAR T HE computer code are very encouraging and place the Gaussian process as a go od and j udicious alternative to efficient bu t non-explicit and complex metho ds such as b oosting trees or neural n et works. It h as the adv antag e of being easily ev aluated on a new parameter set, indep endently of the metamodel complexit y . Moreo ver, sev eral statistical tools are av ailable b ec ause of the analytical formulatio n of the Gaussian m odel. F or example, the MSE estimato r offers a go od indicator of the mo del’s lo cal accuracy . In the same wa y , inference studies can b e deve lop ed on parameter estimato rs and on the choice of the experimental in p ut de- sign. Finally , one p ossible imp ro vement in our construction algorithm is based on the sequentia l app roac h of the choic e of input design, whic h remains an activ e researc h domain (Scheidt and Zab alza-Mezghani (2004) for example). 26 A CKNO WLEGMENTS This work was supp orted by the MRIMP pro ject of the “Risk Control Do main” that is managed by CEA/Nuclear Energy Division/Nuclea r Dev elopment and In n o v ation Division. W e are grateful to the tw o referees for their comments wh ic h significant ly improv ed the pap er. References Abab ou, R., Ba gtzoglou, A., W oo d, E., 199 4. On the co ndition num b er of cov ariance matrices in kriging, estimation, and simulation of random fields. Mathematical Geolog y 26, 99–13 3. Abrahamsen, P ., 199 4. A review of ga ussian random fields and co rrelation fu nctions. T ech. Rep. 878, Norsk Regnesentral. Alam, F., McNaught, K., Ringrose, T., 2004. A comparison of exp eriment al d esigns in the d ev elopment of a neural net work simulati on metamodel. Simula tion Modelling Practice and Theory 12, 559–5 78. Bazaraa , M., Sherali, H., Shetty , C., 1993. Nonlinear programming. John Wiley & Sons, In c. Bo x, G., Draper, N., 1987. Empirical mo del building and r esponse su rfaces. Wiley Series in Probabilit y and Mathematical Statistics. Wiley . Chil ` es, J.-P ., Delfiner, P ., 1999. Geo statistics: Mod eli ng sp ati al uncertaint y . Wiley , New-Y ork. Cressie, N., 1993. Statistics for spatial data. Wiley S eries in Probability a nd Mathe- matical Statistics. Wiley . Currin , C ., Mitc hell, T., Morris, M., Ylvisaker, D., 1991. Bay esian pr ed ict ion of deterministic functions with applications to the design and analysis of compu te r exp erimen ts. Journ al of the American Statistical Asso ciati on 86 (416), 953–963 . F ang, K.-T., Li, R., Su djian to, A., 2006. Design an d modeling for compu ter experi- ments. Chapman & Hall/ CRC. Hastie, T., Tib shirani, R., F riedman, J., 2002 . The elements of statistical learning. Springer. Helton, J., J ohnson, J., Salab erry , C., Storlie, C., 2006. Survey of sampling-based method s for un certa int y and sensitivit y analysis. Reliabilit y Engineering and S ys- tem S afet y 91, 1175– 1209. 27 Hoeting, J., Davis, R., Merton, A., Thomps on, S., 2006 . Mo del selection for geo sta- tistical mo dels. Ecological Applications 16, 87–98. Iooss, B., V an Dorp e, F., Devicto r, N., 2006 . Resp onse surfaces and sensitivit y anal- yses for an environmen tal mo del of dose calculati ons. Relia bility En gineering and System S afety 91, 1241 –1251. Jourdan, A., Zabalza-Mezg hani, I., 2004. Resp onse su rface d esig ns for scenario mangement and uncertaint y quantificat ion in reservoi r prod uction. Mathematical Geolog y 36 (8), 965–985 . Kleijnen, J., 1997. S ensitivit y analysis and related analyses: a review of some statis- tical techniques. Journ al of Statistical C omputation and Simulation 57, 111–142. Kleijnen, J., 2005. An ov erview of the design and analysis of simulatio n exp eriments for sensitivity analysis. E u ropean Journal of O perational Research 164, 287 –300. Kleijnen, J., Sargent, R., 200 0. A methodology for fitting and v alidating metamo dels in simulation. Eur opean Journ al of Op eratio nal Researc h 120, 14–29. Lophav en, S., Nielsen, H., Sondergaard, J., 20 02. D ACE - A Mat- lab kriging toolbox, v ersion 2 .0. T ech. Rep. IMM-TR-2002 -12, In for- matics and Mathematical Modelling, T echnical Un iv ers ity of Denmark, < http:// www .imm m.dtu.dk/ ∼ hbn/dace > . Matheron, G., 197 0. La Th´ eorie des V ariables R ´ egionalis ´ ees, et ses Applications. Les Cahiers du Centre d e Morph ol ogie Math ´ ematique de F ontaineblea u, F ascicule 5. Ecole d es Mines de P aris. McKa y , M., Beckman, R., Conov er, W., 1979. A comparison of three metho ds for selecting v alues of input v ariables in the analysis of output from a computer code. T echnometrics 21, 239–245. O’Hagan, A., 2006 . Ba yesian analysis of computer co de outputs: A tutorial. Relia - bilit y Engineering and System Safety 91, 1290–1 300. Osio, I., Amon, C., 1996 . An engineering design methodology w ith m u ltista ge bay esian sur roga tes and optimal sampling. Researc h in En gineering Design 8, 1 89– 206. Rasmussen, C., Williams, C., 2006. Gaussian p rocesses for machine learning. MIT Press. Sac ks, J., W elch, W., Mitchell , T., Wynn, H., 19 89. Design and analysis of compu ter exp erimen ts. Statistical Science 4, 409 –435. Saltelli, A., Ch an, K., S co tt, E. (Eds.), 2000. Sensitivity analysis. Wiley S eries in Probability and Statistics. Wiley . 28 Santner, T., Will iams, B., Notz, W., 2003. The d esig n and analysis of computer exp erimen ts. Sp r inger. Scheidt, C., Zabalza-Mezg hani, I., August 2004 . Assessing uncertaint y and optimiz- ing p roduction sc hemes: Exp erimental designs for non-linear pro duction resp onse mod eling. an application to early wate r breakthrough pr ev ention. In: ECMOR IX. Cannes, F r ance . V azquez, E ., W alter, E., Fleury , G., 2005. In trinsic kriging and pr ior information. Applied S toc hastic Models in Business and In dustry 21, 215–22 6. V olk ov a, E., Iooss, B., V an Dorp e, F., 2008. Global sen sitivit y analysis for a numerical mod el of radionuclide migration from the RRC ” Kur c hatov Institute” radwa ste disp osal site. S toc hastic Envi ronmental Researc h and Risk Assesment 22 , 17–31. vo n Mises, R., 19 64. Mathematical Theory of Probability and Statistics. Academic Press. W elch, W., Buc k, R., S ac ks, J., Wynn, H., Mitchell, T., Mo rris, M., 1992. Screening, predicting, and computer exp eriments. T echnometrics 34 (1), 15–25. 29
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment