Exploring Human Factors in Spreadsheet Development
In this paper we consider human factors and their impact on spreadsheet development in strategic decision-making. This paper brings forward research from many disciplines both directly related to spreadsheets and a broader spectrum from psychology to…
Authors: Simon Thorne, David Ball
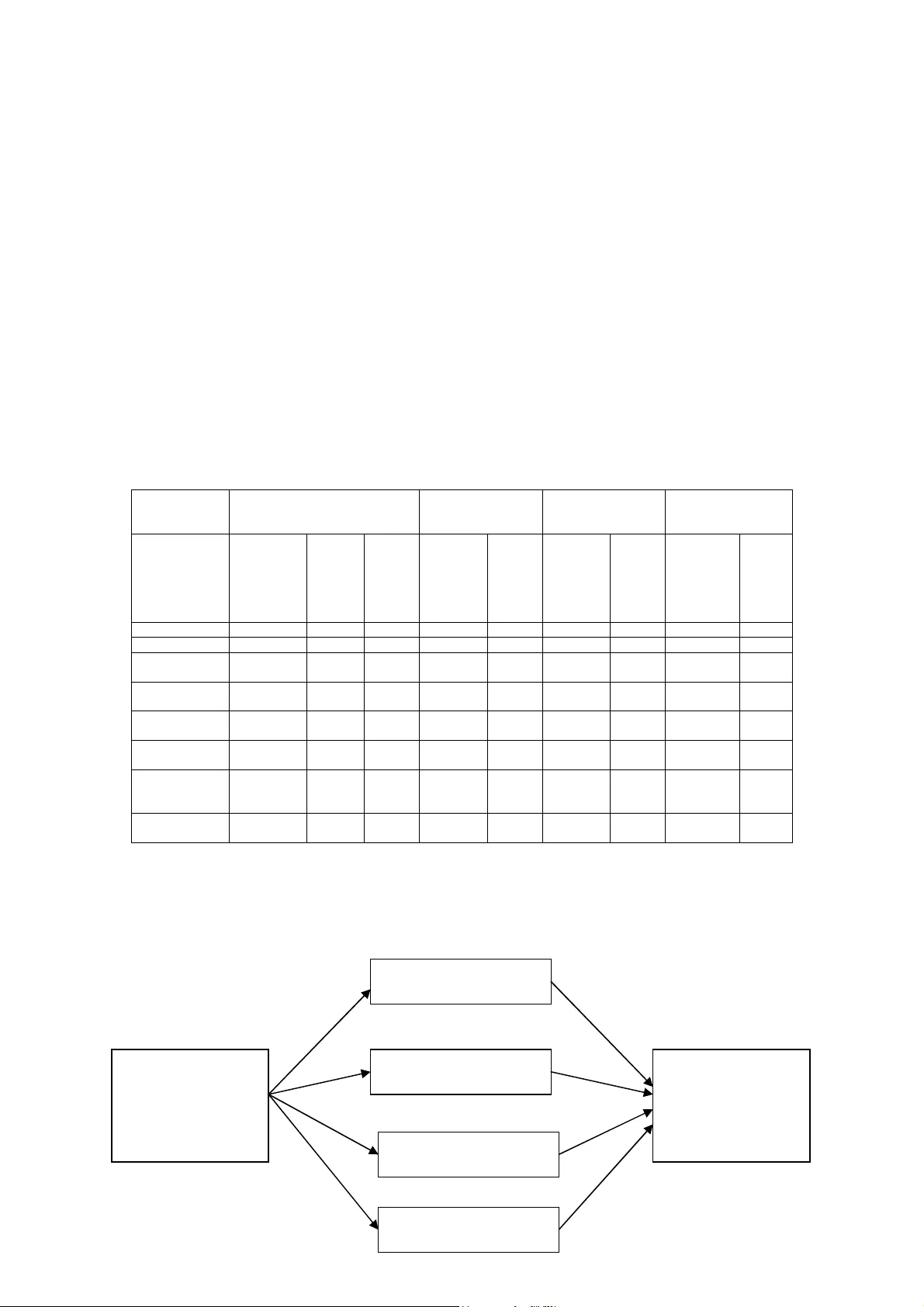
Exploring Human Facto rs in Spre adsheet Develo pment Simon Thorne, David Ball University of Wales Institute Cardiff Sthorne@uwic.ac.uk Dball@uwic.ac.uk ABSTRACT In this paper we consider h uman factors and their im pact on spreadsheet develop ment in strategic decision-m aking. This paper brings forward research from m any disciplines both directly related to spreadsh eets and a broader spectrum from psychology to industrial processing. We investig ate how human factors affect a simplified development cyc le and what the potential conseque nces are. 1.0 INTRODUCTION Human factors are present i n every activity that hum ans undertake. Hum an factors really describe the frailties of inte raction and interface betwe en man and the world. I n this paper we focus on how these factors affect spreadsheet m odellers. The choice of spreadshee ts is not arbitrary, recent research (F ernandez, 2002 and Gosling , 2003) has shown that org anisations rely heavily on the use of s preadsheets to make strategic deci sions and that many business critical processes are im plemented using spreadsheet a pplications. This sort of reliance o n spreadsheets is tactically dangerous, considering the iss ues that arise from Human Factor research. Consider a simplistic developm ent cycle consisting of: Plan, Bu ild and Test as shown in figure 1. Throughout this c ycle there are a number o f different hum an factors that will impact on the quality and integrity of the model developed. Th is paper will explore the factors that effect the development cycle. Figure 1 Plan Test Simplistic developm ent cycle Build 2.0 PLANNING STAGE The effective planning of a n information system is par amount to its success. I n order to effectively plan an inform ation system, one would hav e to be a trained information system professional. This leads us l ogically to examine the pro file of the people developin g spreadsheets and asses the skills they have in planning spreadsheet development. 2.1 SPREADSHEET DEVEL OPERS There is no typical spreadsheet developer in the moder n business world. The reaso n for this is the great flexibility that spr eadsheets offer, allowing a range of professionals to d evelop them. Most spreadsheet dev elopers are end user developer s by definition. End User Dev elopment (EUD) is the process of all owing end users to dev elop applications, using end use r tools, to enhance business in som e way. As end users, they w ill not necessarily be trained I S professionals. Indeed, m any end users use computers as a necessity to perform their job satisfactorily, and EUD p rovides an enhancem ent to normal activities. EUD as an activity is paramount to inform ation systems development and even so ftware development. A s end users, spreadsheet dev elopers are not trained as software eng ineers and hence they hav e no knowledge of structured m ethodologies or processes that constitute software dev elopment. The consequences of dev eloping software with no m ethodology cam e to a head in the 1980’s with the ‘Software Cris is’. There was a large upheaval of proce sses and standards by the industry to improv e the quality of software using st ructured design techniques. Up take of these methods has been wid espread in the software ind ustry. The same standards were not applied to EUD, althoug h there was research publishe d in the 1980’s that propose d frameworks for the m anagement of EUD (Brown and B ostrom, 1989 Munro et al. , 1987 and Alavi et al. , 1987). As was observed by Gosling (2003), there has been little uptake on these managem ent str ategies and hence spreadsheet develop ment is ad-hoc and chaotic. Fig ure 2 highlights this problem . The graph is the response to the question “Do you app ly a methodology w hen developing your spreadsheet?” 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100% C l i n. D e ntal E x ec . F acil s . M ed. Surg. W& C T otal Se r vice g r o up R e s po ns e b y % D on't k now N o Y es Figure 2 (Gosling, 2003) This is further reflected by t he findings of a larg e-scale investigation in to End User Computing in 34 UK org anisations (Taylor et al., 19 98) This study highlighted the lack of training giv en to End Users in formal information sy stems m ethodological approaches. Application of such m anagement strategies, as Alavi e t al. propose, is proven to im prove the quality of the end product; t he improvem ent in s oftwar e quality after the software crisis is strong evidence of this as observ ed by Yourdon (1997). The fu ndamental problem is that the developers of software are humans and humans m ake mistakes especially when they are not trained properly. I n a ddition overconfidence plays a role. Overconfident m odellers under time pressure feel no need to pl an, since that would take t ime. 2.2 OVERCONFIDENCE ‘Often wrong but never dou bt ing’ - Anon Overconfidence in hum an activity is prolific; research s hows that in relatively complex problems, hum ans are consistently overconfident. I n par ticular Russo and Sc hoemaker (1992) examine the costs and caus es of overconfidence in dec ision making. This overcon fidence does not just apply to novic e or inexperienced professi onals. The same rules apply to ‘experts’ as Lusted (1977) and Oskamp (1965) demonstrated wi th physicians and clinical psychologists respectively . Overconfidence, when seen from a spreadsheet developm e nt point view, is really conce rned with all stages of the plan, build, and test developm ent cycle. An overconfiden t spreadsheet developer will not plan, te st or even question the valid ity of the work they hav e produced. This results in poorly des igned, untested applications t hat are potentially full of e rrors. This practice is obviously risk y in normal circumstances but consider more strategic application s and this practice becom es critical. Research into spreadsheet modellers and overconfiden ce has shown that both individuals and groups demonstrate chronic o verconfidence (Pank o, 2003). Panko found tha t overconfidence ranged from 80% to 100% wit h the emphasis o f overconfidence with individual modellers. Panko also extended his res e arch to measure the eff ect of presenting the participants of the experiment with evidence that all spreadsheet devel opers were overconfident in their efforts. This resulted in a slig ht improvement in percentage a ccuracy of spreadsheet m ode ls developed and reduced the overconfidence of participa nts. This minor improvem e nt after stark and blatant warning demonstrates the pervasiv eness and severity of the problem . Burnett et al. (2003) also re c ognised overconfidence as a problem and dem onstrated how software engineering principles could improve the accuracy and efficiency of spreadshe et developer models. Burne tt’s experiment applied a t esting methodology to a number of participant created spreadsh eets. The results showed th at the participants m anaged to correct 92-96% of errors found i.e. they audited their work and discovered errors, which they corrected. This is clearly an effective method of catchi ng and correcting errors. What this study does not reveal is th e number of errors that th e participants did not detect, wh ich, according to reported statist ics could be between 80- 100%. Burnett also provided an extensive testing m ethodology (Burnett et al. , 2001) based u pon software engineering techniques which im proved the quality of spreadshee ts by considering them in terms of executable and non-execu table programs. Utilising thi s method, participants achie ved between 0 and 31% (detect ed) error on a select num ber of problems. The testing m ethodologies proposed by Burnett et al. a re accurate and effective m ethods of catching errors. However, we return to the original qu estion, if the end users a re overconfident in the first pl ace, will they consider the need for testing? 3.0 BUILD STAGE At the build stage there is t he greatest opportunity for human factors to im pact on the quality and integrity of the spreads heet. In this segment we ex plore several fundamental cog nitive human issues that affect ac curacy in development and even how we interact with spreadsheet programs. 3.1 HUMAN LEARNING AND MEMORY As Gross (2001) observes, hum an l earning is a hypoth etical construct that cannot be obs erved directly but is implied in the im pr ovem ent of cognitive and mechanical skills. According to Howe (1980), learning invo l ves perception and m emory. I t is well accepted by the psychological comm uni ty that learning and m emory are essentially the sam e thing. The actual mechanical process of learn ing is based on principles of pa ttern matching and learning from experience, that is to say ad justing behaviour based up on p revious experien ce to gain some more desirable result. The ‘cognitive load’ (the de mand of cognitive tools for a specific task ) is also important. According to Kruck et a l. (2003) the cognitive load is based upon four interlocking supersets: Skill Character; Working m emory; Long- ter m m emory and Task Demand. Within these supersets there are sev eral subsets such as problem sol ving, memory load and accuracy. Assessing each subset in each superset allows one to b ui ld a picture of the cognitive load for a given task. Kruck et al. app lied this method to a num ber of different everyday tasks that ranged from ty ping to routine medical diagnostics. He also applied this method to spreadsh eet tasks, the results of this underline s the high cognitive dem and on spreadsheet m odellers, see table 2. Skill Character Working memory Long term memory Task demands Tasks Problem solving Perceptual motor Planning Unit task structure Memory load Input to LTM Retrieval from LTM Pacing Accuracy Typing Low High Low Low Low Low Low Low Int. Driving a car Low High Int. Low Int. Low L ow High High Mental multiplication Int. Low Low High High Low Int. Low High Balancing check book High Low Int. High High Int. Int. Low High Writing a business letter High Low High High Int. Int. Int. Low Int. CPA doing income tax High Low High High Int. Int. High Low High Routine medical diagnostics High Low High High High High High Int. High Spreadsheet tasks High High High High High Low High Low High Table 2 (Kruck et al. , 2003) Kruck et al. were experim ent ing to determine if training spreadsheet us ers would affect their accuracy. Kruck concentra ted on four elements of cog nition that was labelled a f ramework for cognitive skills, see fig ure 3. Spreadsheet Training Spreadsheet Errors Logical reaso ning ability Spatial Visualisation ability Mnemonic Skill Sequencing Ability Figure 3 (Kruck et al. 2003) It was found that the only e lement that improv ed significantly after training was lo gical deduction. Kruck et al. fou nd that by improving the part icipant’s logical reasoning skills, the quality of the spreadshee ts they developed was higher i.e. they had fewer errors. From a cognitive point of v iew, developing spreadsheets is a m ethod of developing s oftware using syntax and log ical constructs in much the sam e way writing a program in C++ or Visual Basic. In the latter two, the developer will have to lea rn the syntax and const ructs over a period of time before the prog r am will achieve what is required. Spreadsheets were des igned to be a tool that could be util ised by non-information sy stems professionals. This has both advantages and disadvant ages, while the user can dev elop a spreadsheet with no fo rmal training; the probability of novice developers m aking mistakes is heightened. Co nsider a novice user modelling a sp readsheet; the interface is intuitive and logical and the use of complicated syntax is ini tially limited. Once some lev el of problem complexity is breached, the user will have to begin using more complicated statem e nts. In spreadsheet app lications, the syntax of argum ents is often complicated and th e flexible intuitive interface is rep laced with a single line of code fo r a formula. Consideri ng the user is not a softw are engineer or a programmer, this interface has serious implications on h ow effective the user wi ll be at manipulating the environm ent to best suit their needs. R esearch has shown that a lim ited natural language interface impacts on the effective programm ing and le arn- ability of an application (Napier et a l. , 1989). There is also a neg ative effect on the users progr amming ability, where the user has l ittle knowledge of the com mands involved in the envir onment (Napier et al., 1992). I n Particular the users will cons istently mak e mistakes when developing spreadsheet applications be yond some level of comple xity (Thorne et al. 2004). That is no t to say only Nov ices make errors, indeed there is strong evidence to the contrary (Osk amp, 1965) Human work ing memory is also an area that has been under investigated in EUD. The principles of ‘Miller’s thres hold’ (Miller, 1956) state that when considering a probl em, the subject will start to m ake errors after they are manipula ting greater than 9 concepts simultaneously. I f we consider this in term s of spreadsheet applications, th ese sort of complex and abstract formulae are com mon. Considering the pr oblematic syntax and the ab stract nature of programm i ng formulae in spreadsheets, M iller’s concept danger lim it is particularly important. Whilst it is di fficult to interpret Millers u se of concepts into the sp readsheet paradigm, one could view c oncepts on a cell- by-cell basis. Using that analogy, con cepts would be elements of a for mula in a cell. Considering t he complex argum e nt structure of spreadsheet applications, sp readsheet modellers m ust routinely breach Miller’s threshold. I f we apply the principles of Halstead’s difficulty (Halst ead, 1977) to a spreadsheet formula, the complexity becom es apparent as this method breaks do wn formulae into operands and operators thus providing us with the concepts used in a n argument (Thorne et al. , 2004). Added to Miller is the work of Michie (Michie et al. , 1 989) who demonstrated the poor link between the pairing of hum an and machine strengths b ased upon an appreciation o f human learning and cognitive processe s. Michie argued that the hum an computer interacti on was fundamentally lim ited due to the way in which hum ans interact with the computer. Michie essentially argued that the r oles of machine and hum a n in interaction did not exp loit either’s strengths. His points are still relevant today, as the met hod in which we interact has not changed significantly since the paper was written. 3.2 HUMAN ERROR Human error, unlike som e of the other topics in th is paper, is sourced from many different disciplines. Psychology i nitially started the intere st but since there have been m a ny disciplines interested in this phenom ena. Reason (1990) produced the ‘Generic Error Modelling System’ (GEMS) based upon an un derstanding of human error taken from many disciplines. Reason proposed that errors are m ade on one of three levels: Knowledge based, Rule based or Sk ill based. Rasmussen (1986 ) laid the foundations of this w hen investigating hum an error in industrial processing plants. Using these paradigm s we can classify EUD error and thus target counter measures to m anage EUD activities more e ffectively. Further, Frase r and Smith (1992) investigated the erro rs created when comparing human behaviour to the nor ms of probability, casual connection and logical deduction. This res earch yielded evidence of humans m aking mistakes in simple and repetitive task s , known as Base Error Ra te (BER). This concept states that reg ardless of the simplicity an d repetitive nature of a task, there will always be base level of erro r present. This phenomenon was observed in an experi ment where participants were required to match colours with co lour names correctly. R eason (1990) also found evidence of this ph enomena and was bought to a ttention in EUD by Pank o (1998). There are other num erous examples that include BER in spelling and gramm a r, calculation tasks, prediction and interp retation. Evidence gathe red by Panko (2005) demonstra tes a wide range of quantities, which v ary significantly depending on the task. For exam ple a typical rate observed in spelling BER r anges from 0.5% to 2.4% ( errors per word). I ndeed Panko concludes that a reasonabl e estimate for BER in any simple activity is 0.5%. I n comparison more complex tasks such a s programming yield a BER of around 5%. This sug gests a fairly a relationship between com plexity of task and BER – th e more dem anding a task is, the higher the level of BER. 3.4 MODELS AND PARADIGMS OF HUMAN COM PUTER INTERACTION Human Com puter Interaction is a wide discipline that includes physical, biological and technical aspects of I nteraction between user and com puter. There are several m odels of interaction that exist, the m os t popular being exe cution- evaluat ion cycles, Norm an (1988), this method breaks interac tion into seven stages. These s tages describe the sequen tial process of a user planning, implem enting and evaluating their work. This model represen ts the process of interaction be tween the computer and user, w hen the user has a specific task in mind, i.e. Print out the repo r t. It can howev er, be applied to EUD, since the us er will follow the model to produce a spre adsheet or a database using approx imately the same ste ps. In examining the stages, it is s u ggested that som e of the processes are not followed in EUD. The lack or misinterpretation o f certain stages, i.e. evalu ating the system state in respe ct to the goals and intentions is one of the ca uses of poor qualit y in EUD systems. I ndeed, the above statement is open to all k inds of interpretation, whet her it is the bias, as desc ribed by Fraser and Smith (2003), that caus es the user to incorrectly interpret results or the failure to adequately test the system due to a lack of knowledge of structured methodologie s. An alternative way of interpreting human computer int eraction, even spreadsheet development, is centred on problem driven modelling . Put simply, the user utilises the computer and their own cog ni tive faculties to solve a problem. The spreadshee t application is essentially the im plementation of the cognitive m odel developed beforehand by the user. Problem solving in hum a ns can be viewed as problem space searching as Newell and Sim on (1972) suggested. Problem s state space searching is the process of forming a g oal state (what the user wants to create) a c urrent state (the point that the user currently reside s at) and the valid operators to change the current state to the g oal state. The goal state in this context could be general or spec ific. It could be to create a sp readsheet that represents a bu siness problem or m ore specifically the sum of two cells in a spre adsheet to produce a tot al. Consider the latter exam pl e, the goal state is a form ula that sums two cells; the cur rent state is nil (there is no part of the f ormula produced). The v alid operators could be mathem ati cal symbols (+ - / *), cell nam es and addresses (C1, B1 etc ) and the applications specific operators (SUM). In this instan ce the problem space allows m or e than one valid g oal state, there are several way s of writing a formula that wil l sum two cells. It is now at the users discretion to decide on the goal state that they des ire. Selecting the best goal state presents the user with some significant problems. How does the user decid e which is the best solution to the problem or are they even aware that there are o ther valid goal states. This paradigm of problem solving is utilised in machine learning tech niques since this model of pro blem solving lends itself to the ar ea. When machines are pre sented with multiple goal st ates, the machine will asses accordi ng to efficiency, this m ay take the form of the goal stat e that is the most compact or requires th e least processing power. For a human to ass es the goal states in the same way would be problematic. In this simple exam ple the human could m ake the decision but in larger probl ems where there may be te ns or hundreds of valid goal states, it would take the user a sig nificant amount of time to res olve to the best solution. I t is this kind of problem that humans a re weak at, evaluating large a mounts of data in terms of effic iency, which contains large am ounts of replication; a com puter on the other hand is natu rally good at this. When we consider the way in which a user interacts with a com put er, in light of problem space searching, to create a n application that is a repr esentation of a system , there are several fundamental processes. The first element is matching patterns in real–world examples and realising trends in those pa tterns that form som e r ule or judgement. The second is then manipulation of mathem atics to represent that system accurately and lastly using logical deduction to classify the re sults accordingly. Now if we consider table 1, the natu ral strengths of the average human and the typical conventional co mputer some discrepancies arise. Tab le 1 From this table we can ded u ce that hum ans are strong at generating real- world examples and pattern matching but weak at mathematical manipulati on and logical deduction. Conv ersely, computers are strong at m anipulating mathem atics and logical deduction but weak at generating real- world examples and pattern m atchin g. I f we then apply this to EU D and spreadsheets in particular w e can see that the current pa radigm places strain on the natural weaknesses of the hum a n and doesn’t exploit the com put ers full poten tial. Table 2 shows the current paradigm in spreadsheet development. Producing formulae Generating real world examples Human Weak Current Strong Proposed Computer Strong Weak Tab le 2 As can be seen in table 2, the hum an i s charged with p roviding the computer with the formulae, at which they ar e naturally weak. The com put er then uses the formulae in the spreadsheet but does not ex ploit the massive potenti al that it has in terms of m athematics; it merely calculates data. A n ew paradigm that exploits the merits of both the user a nd computer would allow greater intera ction. Ideally a m ethod that would play on the strength s of both human and computer woul d improve the way in wh ich the two interact. One such al ternative novel solution would requ ire the human to produce exam ple s of attribute classifications and the machine would then de duce the function of those exam pl es and generalise to n ew unseen examples. This approach ha s been coined ‘Exam ple Driven Modelling ’ (EDM) (Thorne et al. , 2004) which uses machine learning techniques to p roduce a more accurate system of creating Y Y N N Computer ? ? Y Y Human Logical deductio n Manipulating mathema tics Generating real- world examples Pattern ma tchin g representative system s. Machine learning, in the cont ext of EDM, is best desc ribed as the ability to adapt and extrapo late patterns in data as defi ned by Russel and Norvig (2003). To be more specific, the particula r branch of machine learnin g that interests the researcher is Neu ral Networks and their use in exam pl e attribute classificati ons of data. For example, t he user provides simple exam ples of the problem data. This da ta is then fed into the learnin g machine and it produces an equiv alent model of the problem. Thorne et al. (2003) discussed an experiment to test the rela tive levels of accuracy gained from both traditionally model ling a formulae and utilising an E DM approach, over success ively more difficult written problems. The results of this study found that producing the fo rmulae with the traditiona l method was error prone (80% of m o dels with error). The resul ts of the EDM method yielded a much lower error rate (2% of m odels with error). These findings ar e reinforced by Michie et al. (1989 ) who compared human and machine learning over a ser ies of experiments. A learning machine and human were given info rmation regarding the leg ality of Rook – King m o ves in Chess. Both participants were giv en the same information and then Human and Machine learning was determined and com pared. This experimentation r e vealed that m achine learning can be more effective and effic ient than human learning; the machine was consistently more accurate making better use of the information made available to it. Much of Michie’s work throughout the 1970’s to 90’s was conc erned with Machine Learn ing Techniques (MLT) and the comparison of those techn iques with equivalent hum an ab ilities (Mich ie, 1979 and Michie, 1990). He also revealed in sights into the hum an learning process through his wor k, which he tried to represent through MLT (Michie, 1982). By summarising Michie’s work, the gene ral goal of his research was to exploit human learning concepts via symbolic artificial sy stems to provide some m achine or method that could learn m ore effectively. Michie found t hat machine learning was highl y accurate, when compared to hum a n learning, but that it was often too specialised. The machines could only ever p erform a small number of t asks satisfactorily and beyond th eir domain, there were usel ess. In contrasts humans hav e greater generalised skill than spec ialised skill, affording them ‘graceful degradation’ in skills and knowledge. It is perceived t hat a novel approach such as ED M could greatly im prove accuracy by delegating much of the work to the comp uter rather than the user. 4.0 TESTING STAGE The testing stage is the fina l point before the user deci des that the model they have produced is adequate for the task it was designed for. In addi tion to lack of formal testing methodologies that is im plied since most spreadsheet d evelopers aren’t IS professionals, bi as is considered in testing. Gilovitch et al. (2002) cons iders the heuristic methods and bias implicit in everyda y life. The most relevant parts of this text refer to the bias present in seemingly objective judgements. For example, the trend tow a rds predicting an outcome favourably due to the fact that the subject has a vested inte rest in the outcome (Arm or and Taylor , 2000). Further, Fra ser and Smith (1992) also discuss es the concept of hypothesis f ixation where once a hypothesis i s formed about a decision, th e subject will m isinterpret the results to show th at their hypothesis was correct. Fraser also exa mines confirmation bias, w hich is closely linked with hypothesis fixation. Confirm ation bias is the tendency for ind ividuals to test their own wo rk with conditions that favour a po sitive response. Conside r the flexibility and variab le accuracy of End User Developed sprea dsheet applications and the above factors becom e critical. The issue of bias becom es critical once the user is required to evaluate their work. Pry or (2004) theorised that End Users te st their spreadsheets by using the ‘sniff’ test. That is to say, if the figures roughly m atch what they are expecting then the spreadsh eet is valid. If we consider hypothesis fixation, conf irmation bias (Fraser and Sm ith, 2002) or optim istic bias (Armor and Taylor , 2002) in this con text, the little testing that is ap plied can be rendered invalid. 5.0 CONCLUSIONS Although this paper has co nsidered the fundamental issues in Human Factors, it is not exhaustive. There may be other equally important factors that this paper has not cov ered that impact on spreadsheet dev elopment. If we re-v isit the original Pl an Build Test analogy (see section 1.0), we can dem onstrate at which stage the particula r human factors play a sig nificant role. Figure 3 shows th e modified diagram. Figure 3 This diagram shows the pa rticular issues that arise at each stage of developm ent. For Example the greatest threat to in tegrity at the plan stage is the l ack of structured developm ent methods knowledge. In addition to the stage spe cific threats, there are ov erarching issues that di scretely affect each stage. The two overarching factors are Overconfidence and Base Error Rate. For ex a mple a modeller may be ov erconfident in planning their mod el, they m ay spend a minimal amount of time constructing a plan i f at all. The same applies to testing; they m ay test their m odel inadequately due to the fact that they are confident that their model is accurate , indeed the plan stage may well be dismissed altogether if the m odeller is overconfident. Bas e Error Rate (BER) plays a sim ilar role, a user will be pre disposed to BER whilst they are building the spreadsheet but also when testing it. In conclusion, Hum an Factors play a significant role t hroughout the spreadsheet development cycle. Further, Hum an Factors should be investigated f urther to allow the spreadsh eet- modelling world to build a pplications and processes t hat are sympathetic to such issues. Plan Build Test Development cycle Threats to Integrity Lack of structured deve lopment methodologies knowledge State Space Searching, HWM, Cognitive lo ad Hypothesis F ixation, Optimism Bias, Confirmation Bias. Over confidence and Base Error Rate References Alavi. M, Nelson.R, Weiss, (1987), ‘ S trategies for End User Computing: An integrative framework’ , Journal o f Management Information systems, 4 , (3), pp 28-50 Alavi.M and Weiss.I, (1985), ‘ Managing the risks associated with End User Computing’ , Journal of Management Information Systems, 2, (3), pp 16-21 Armor. D and Taylor. S, (2000), ‘Mindset, prediction and performance: self regulation in deliberative and implemental frames of mind’ , Not published, Yale University Brown and Bostrom, (1989) , ‘ Effective management of End User Computing: A total organisa tion perspective’ , Journal of Management Information sys tems, 6 , (2 ), pp 183-212 Brown and Bostrom, (1994) , ‘ Organization designs for the management of End User Computing: re-examini ng the contingencies’ , Journ al of Manageme nt In formation Systems, 10 , (4), pp 183-112 Brown. P and Gould. J, (1989 ), ‘An experimental study of people creating spreadsheets’ , ACM transactions on information systems, 5 (3), pp253-272 Burnett. M. Rothermel. G. Lixin. L. Dupis. C, Sheretov. A., (2001), ‘A methodology for testing spreadsheets’, ACM transactions on software engineering and methodology, 10 (1), pp 110-147 Burnett. M. Cook. C. Pendse. P . Rotherme l.G. Su mme t. J. Wallac e. C, (2003), ‘ End User Soft ware Engineering with assertions in the spread sheet paradigm’ , Proceedings of International conference on so ftw are engineering, May 2003, Corvallis Oregon, pp33-59 Fernandez, K. (2003 ), ‘Investigation and Management of End User Computing Risk’ , Not published, MSc thesis April 2003. Available from University of Wales Instit ute Cardiff (UWIC) Business School Fraser.J and Smith.P, (1992), ‘A catalogue of errors’ , International Journal of man-machine studi es, 37 , (3), pp 265-307 Gilovitch. T, Griffin. D, Kahneman. D, (2002), ‘Heuristics and biases, the psycholog y of intuitive judgement’ , Cambridge University Press, New York, ISBN 0 -521-79679 Gosling. C, (2003), ‘ To what extent are systems design and development techniques used in the production of non clinical corporate spreadsheets a t a large NHS trust’ , Not published, MBA thesis May 2003, available fro m: University of Wales Institute Cardi ff (UWIC) Busin ess School. Gross. R, (2001), ‘Psychology: The science of mind and Behaviour’ , fourth edition, Hodder and Stoughton, London, ISBN 0-340-79061-X Halstead. M, (1977), ‘ Elements of Software Science’, Operating, and Programming Systems Series, Elsevier, New York Hicks and Panko, (1995), ‘Capital Budgeting Spreadsheet Code Inspection at NYNEX’ , Internet http://panko.cba.hawaii.edu/ssr/Hicks/HICKS.HTM , 12. 1.05, 12.00, Available. Howe. M, (1980), ‘The psycho logy of human learning’ , London, Harper and Rowe Janvrin. D and Morrison. J, (1996), ‘Factors Influencing Risks and Outcomes in End-User Development’ Proceedings of the Twenty-Ninth Ha waii International Conference on Systems Sciences , Vol. II, Haw aii , IEEE Computer Society Press, pp. 346-355. Janvrin. D and Morrison. J, (2000), ‘Using a structured design approach to reduce risks in End User Spreadsheet development’ , Information & management, 37, pp 1-12 Kruck. S. Maher.J. Barkhi. R , (2003), ‘A Framework for Cognitive Skill acquisition and spread sheet training’ , Journal of End User Computin g, 15 (1), pp 20-37. KPMG, 1997, ‘Supporting the Decision Maker - A Guide to the Value of Business Modeling’ press release, July 30, 1997. http://www.kpmg.co.uk/uk/services/manage/press/970605a.h tml , Unavailable Lusted. L, (1977), ‘A study of the efficien cy of diagnostic radiological procedures: Final report on diagnostics efficiency’ , Chicago: Efficacy Study Committee of the American College of Radiology. Michie. D, (1979), ‘ Machine models o f perceptual and intellectual skills’ , Scientific models and man, Herbert Spencer Lectures, Oxford Science Pub lications, 0-19857168-2 Michie. D, (1979), ‘Human and machin e learning concepts’ , ICOT, March, pp11-20 Michie. D, (1982), ‘Mind like capabil ities in computers’, Cognition, 12 (1), pp97-108 Michie. D, Muggleton. S, Bain. M, Hayes-Michie.J, (1989), ‘An experimental comparison of human and machine learning formalisms’ , P rocedings of the 6 th International conference of machine learn ing, pp113-118 Miller.G. A, (1956), ‘The magical nu mber seven, plus or minus two’, Psychological review, 63 , pp 81-97. Munro.M, Huff.S, Moore.G., (1987 ), Expansion and control of End User Computing’ , Journal o f management information systems, 4 , (3), pp 23-28 Napier. A. Batsell. R. Lane. D. Guad agno. N., (1992), ‘Knowledge of command usage in a spreadsheet program’ , Database, 23 (1), pp 13-21. Napier. A. Lane. D. Batsell. R. Guad ango. N., (1989), ‘Impact of restricted natural languag e interface on ease of learning and productivity’ , Co mm unication s of the ACM, 32 (10), pp 1190-1198 Newell.A and Simon.H, (1972), ‘Human problem solving’ , Englewood Cliffs, New Jersey, Prentice-Hall publishers Oskamp, (1965), ‘ overconfid ence in case-study judgements’ , The journal of consulting psychology, 29 , pp 261- 265 Panko. R, (1998), ‘What we know abou t spreadsheet errors’ , Journal of End User Computing, Special issue: Scaling up End User Development, pp 15-22 Panko. R, (2003), ‘Reducing o verconfidence in spreadsheet development’ , EUSPRIG Building better spreadsheets from the ad-hoc to the quality engin eered’, pp 49-57, 1-86166-199-1 Panko. R, (2005), ’Ba sic Error Rates’ , Internet http://panko.cba.h awaii.edu/Hu manErr/Index.ht m , Available, accessed on 1 0.6.05 1 2.34pm Panko. R and Halverson. R, (1997), ‘ Are Two Heads Better than One? (At Reducing Errors in Sp readsheet Modelling?’ Office Systems Research Journal, 15 ( 1), pp. 21-32. Rasmussen. J, (1986), In formation processing and Human-Machine interaction, an approach to cognitive engineering’ , North Holland series in system science and en gineering, 12 , 0-444-00987-6 Reason. J, (1990), ‘Human E rror’ , Cam bridge Universit y Press, Cambridge, ISBN 0-521-31419 -4 Russel. S and Norvig. P, (2003), ‘Artificial Intelligence – A Modern Approach ’ , 2 nd Edition, Pearson education inc., New Jersey, ISBN 0-13-08030 2-2 Russo. J and Shoemaker. P, (1989 ), ‘Decision traps’ , Simon and Schuster, New York. Taylor. M, Moynihan. P, Wood-Harper. T, (1998), ‘End User Computing and information systems methodologi es’ , Information systems Journal, 8 , pp 85-96 Thorne. S. Ball. D. Lawson. Z., (2004), ‘ A novel approach to spreadsheet formulae p roduction and overconfidence measurement to reduce risk in sp readsheet modelling’, Proceedings of EUSPRIG 2004 – Risk reduction in End User Computing, Klagenfurt, pp 71-85, ISBN 1 902724 94 1 Yourdon. E, (1998), ‘Ri se and resurrection of the American Programmer’ , Yourdon Press, New Jersey, ISBN 0- 13-956160-9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment