Incremental Topological Ordering and Strong Component Maintenance
We present an on-line algorithm for maintaining a topological order of a directed acyclic graph as arcs are added, and detecting a cycle when one is created. Our algorithm takes O(m^{1/2}) amortized time per arc, where m is the total number of arcs. …
Authors: Bernhard Haeupler, Siddhartha Sen, Robert E. Tarjan
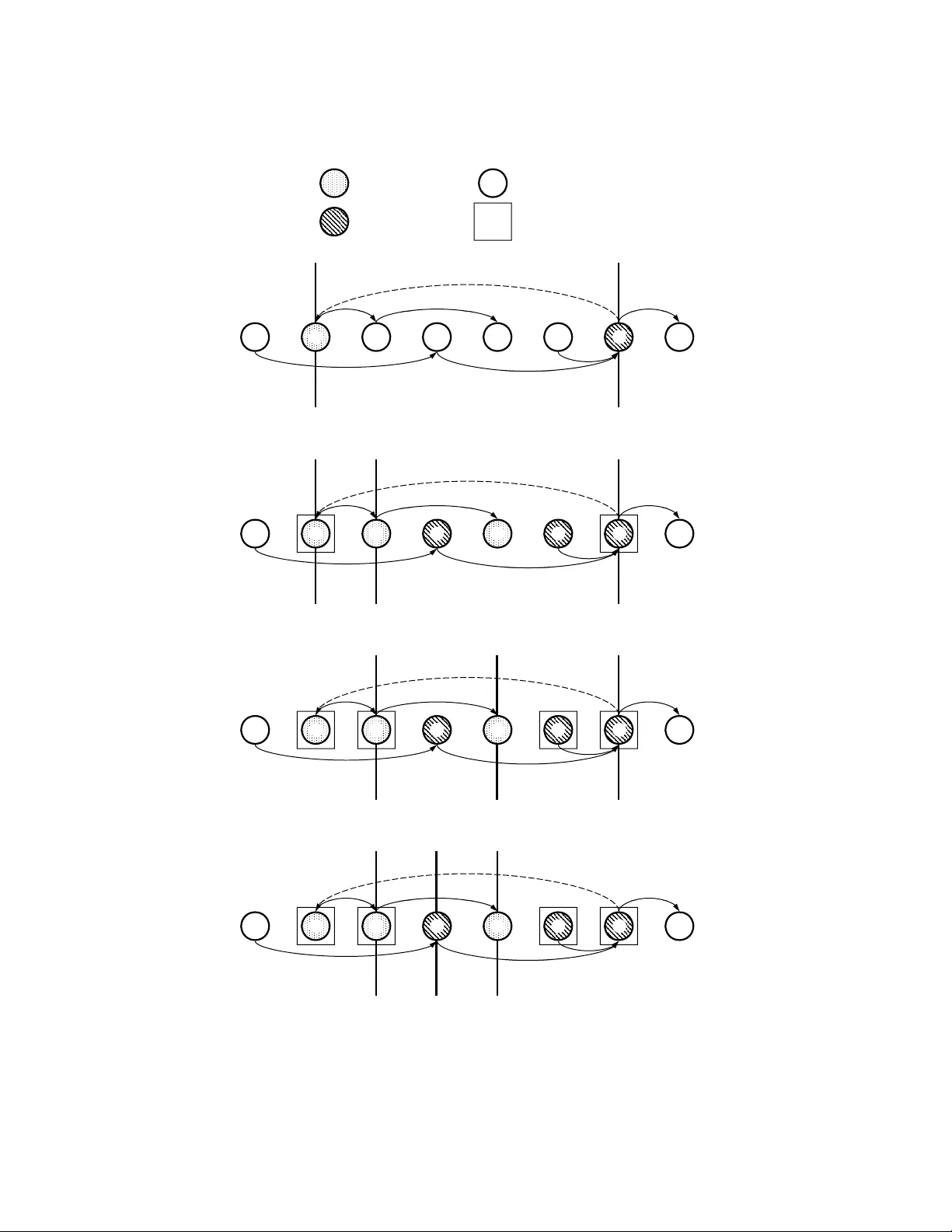
Incremen tal T op ological Ordering and Strong Comp onen t Main tenance Bernhard Haeupler 1 , Siddhartha Sen 1 , and Rob ert E. T arjan 1 , 2 1 Princeton Univ ersity , Princeton NJ 08544 { haeupler, sssix, ret } @cs.princeton.edu 2 HP Lab oratories, P alo Alto CA 94304 Octob er 23, 2018 Abstract. W e presen t an on-line algorithm for maintaining a topological order of a directed acyclic graph as arcs are added, and detecting a cycle when one is created. Our algorithm tak es O ( m 1 / 2 ) amortized time p er arc, where m is the total n um b er of arcs. F or sparse graphs, this b ound improv es the best previous bound b y a logarithmic factor and is tigh t to within a constan t factor for a natural class of algorithms that includes all the existing ones. Our main insigh t is that the bidirectional searc h metho d of previous algorithms do es not require an ordered search, but can be more general. This allows us to av oid the use of heaps (priority queues) entirely . Instead, the deter- ministic v ersion of our algorithm uses (appro ximate) median-finding. The randomized v ersion of our algorithm a v oids this complication, making it v ery simple. W e extend our top ological ordering algorithm to give the first detailed algorithm for maintaining the strong comp onen ts of a directed graph, and a topological order of these comp onen ts, as arcs are added. This extension also has an amortized time bound of O ( m 1 / 2 ) per arc. 1 In tro duction W e consider three related problems on dynamic directed graphs: cycle detection; maintaining a top ological order; and maintaining strong comp onents, along with a top ological order of them. Cycle detection and maintaining a topological order are closely connected, since a directed graph has a topological order if and only if it is acyclic. Previous w ork has fo cused mainly on the topological ordering problem; the problem of maintaining strong components has received little attention. W e presen t a solution to both problems that improv es the best kno wn time b ound for sparse graphs b y a logarithmic factor. A top olo gic al or der O of a directed graph is a total order of the vertices suc h that for ev ery arc ( v , w ), O ( v ) < O ( w ). A directed graph has a top ological order (and in general more than one) if and only if it is acyclic [12]. A directed graph is str ongly c onne cte d if, for each pair of v ertices v and w , there is a path from v to w . The str ongly c onne cte d c omp onents of a directed graph are its maximal strongly connected induced subgraphs. These components partition the vertices. Giv en a directed graph, its gr aph of str ong c omp onents is the multigraph whose v ertices are the comp onen ts of the giv en graph, with an arc ( c ( v ) , c ( w )) for each arc ( v , w ) of the original graph, where c ( x ) is the comp onen t containing vertex x . Ignoring lo ops, the graph of strong comp onen ts is acyclic; thus the components can b e top ologically ordered. Giv en a fixed n -vertex, m -arc graph, a top ological order can b e found in O ( n + m ) time b y either of t wo algorithms: rep eated deletion of sources [17, 18] or depth-first search [33]. The former metho d extends to the en umeration of all p ossible topological orderings. Strong comp onen ts, and a top ological order of them, can also be found in O ( n + m ) time b y depth-first searc h, either one-wa y [33, 7, 10] or tw o-w ay [1, 32]. In some applications, the graph is not fixed but changes o ver time. The incr emental top o- lo gic al or dering pr oblem is that of maintaining a top ological order of a directed graph as arcs are added, stopping when addition of an arc creates a cycle. This problem arises in incremen tal circuit ev aluation [3], p oin ter analysis [26], management of compilation dep endencies [20, 22], 2 and deadlo c k detection [4]. In some applications cycles are not fatal; strong comp onen ts, and a top ological order of them, must b e main tained. F or example, p ointer analysis can optimize w ork based on cyclic relationships [24]. In considering the incremental top ological ordering and strong comp onen ts problems, we shall assume that the vertex set is fixed and sp ecified initially , and that the arc set is initially empt y . One can easily extend our ideas to supp ort vertex as w ell as arc additions, with a time of O (1) per v ertex addition. The top ological ordering metho ds w e consider also easily handle arc deletions, since deletion of an arc cannot create a cycle nor inv alidate the current top ological order, but our time b ounds are only v alid if there are no arc deletions. Maintaining strong comp onents under arc deletions is a harder problem; we briefly discuss previous work on it in Section 6. One could of course recompute a top ological order, or strong comp onents, after eac h arc addition, but this w ould require O ( n + m ) time p er arc. Our goal is to do b etter. The incremen- tal top ological ordering problem has received muc h attention, esp ecially recently . Marchetti- Spaccamela et al. [21] ga ve an algorithm that takes O ( n ) amortized time per arc addition. Alp ern et al. [3] ga ve an algorithm that handles batc hed arc additions and has a go od time b ound in an incremen tal mo del of computation. Katriel and Bodlaender [15] sho wed that a v ariant of the algorithm of Alp ern et al. takes O (min { m 1 / 2 log n, m 1 / 2 + ( n 2 log n ) /m } ) amor- tized time p er arc addition. Liu and Chao [19] tightened this analysis to Θ ( m 1 / 2 + n 1 / 2 log n ) p er arc addition. P earce and Kelly [25] gav e an algorithm with an inferior asymptotic time b ound that they claimed was fast in practice on sparse graphs. Ajwani et al. [2] gav e an algorithm with an amortized time per arc addition of O ( n 2 . 75 /m ), whic h for dense graphs is better than the b ound of Liu and Chao. Finally , Kavitha and Mathew [16] improv ed the results of b oth Liu and Chao and Ajw ani et al. by presen ting another v arian t of the algorithm of Alp ern et al. with an amortized time b ound p er arc addition of O ( m 1 / 2 + ( n log n ) /m 1 / 2 ), and a differen t algorithm with an amortized time b ound p er arc addition of O ( n 2 . 5 /m ). The problem of maintaining strong comp onen ts incremen tally has receiv ed m uch less at- ten tion. F¨ ahndric h et al. [9] gav e an algorithm that searches for the p ossible new strong comp onen t after eac h arc addition; their algorithm do es not maintain a topological order of comp onen ts. P earce [23] and P earce et al. [24] men tion extending the top ological ordering al- gorithm of Pearce and Kelly and that of Marc hetti-Spaccamela et al. to the strong components problem, but they pro vide very few details. W e generalize the bidirectional search method in tro duced by Alp ern et al. for incremental top ological ordering and used in later algorithms. W e identify the prop erties of this metho d that allo w older algorithms to achiev e their resp ectiv e running times. W e observ e that the metho d do es not require an ordered searc h (used in all previous algorithms) to b e correct. This allows us to refine the general metho d into one that av oids the use of heaps (priority queues), but instead uses either approximate median-finding or random selection, resulting in an O ( m 1 / 2 ) amortized time b ound per arc addition. The randomized version of our algorithm is esp ecially simple. W e extend our incremen tal top ological ordering algorithm to pro vide the first detailed algorithm to maintain strong comp onen ts and a topological order of them. This algorithm also tak es O ( m 1 / 2 ) amortized time p er arc addition. The b o dy of our pap er is organized as follows. Section 2 describ es the bidirectional search metho d, verifies its correctness, and analyzes its running time. Section 3 refines the method to yield an algorithm fast for sparse graphs. Section 4 provides some implementation details. Section 5 extends the algorithm to the problem of maintaining strong comp onen ts. Section 6 examines lo wer b ounds and other issues. In particular, we show in this section that on sparse graphs our O ( m 1 / 2 ) amortized time b ound is tigh t to within a constan t factor for a natural class of algorithms that includes all the existing ones. 2 T op ological Ordering via Bidirectional Searc h W e develop our top ological ordering algorithm through refinemen t of a general metho d that encompasses ma n y of the older algorithms. By vertex order we mean the current top ological 3 order. W e main tain the v ertex order using a data structure suc h that testing the predicate “ x < y ” for t w o vertices x and y takes O (1) time, as do es deleting a v ertex from the order and reinserting it just b efore or just after another vertex. The dynamic ordered list structures of Dietz and Sleator [8] and Bender et al. [5] meet these requiremen ts: their structures take O (1) time w orst-case for an order query or a deletion, and O (1) time for an insertion, amortized or worst-case dep ending on the structure. F or us an amortized b ound suffices. In addition to a top ological order, we maintain the outgoing and incoming arcs of eac h vertex. This allo ws bidirectional search. Initially the vertex order is arbitrary and all sets of outgoing and incoming arcs are empt y . T o add an arc ( v , w ) to the graph, pro ceed as follo ws. Add ( v , w ) to the set of arcs out of v and to the set of arcs in to w . If v > w , do a bidirectional search forward from w and bac kward from v un til finding either a cycle or a set of vertices whose reordering will restore top ological order. A v ertex is forwar d if it is w or has b een reached from w by a path of arcs tra versed forw ard, b ackwar d if it is v or has b een reached from v b y a path of arcs trav ersed bac kward. A v ertex is sc anne d if it is forw ard and all its outgoing arcs hav e b een trav ersed, or it is bac kward and all its incoming arcs ha ve been trav ersed. T o do the search, trav erse arcs forw ard from forw ard vertices and bac kward from bac kward vertices un til either a forw ard trav ersal reaches a bac kward v ertex x or a bac kward tra versal reac hes a forw ard vertex x , in which case there is a cycle, or until there is a vertex s suc h that all forward vertices less than s and all backw ard v ertices greater than s are scanned. In the former case, stop and rep ort a cycle consisting of a path from w to x trav ersed forw ard, follow ed by a path from x to v tra versed backw ard, follow ed by ( v , w ). In the latter case, restore top ological order as follo ws. Let X b e the set of forward vertices less than s and Y the set of bac kward vertices greater than s . Find topological orders of O X and O Y of the subgraphs induced b y X and Y , resp ectiv ely . Assume s is not forward; the case of s not bac kward is symmetric. Delete the v ertices in X ∪ Y from the current vertex order and reinsert them just after s , in order O Y follo wed by O X . (See Figure 1.) Theorem 1. The incr emental top olo gic al or dering metho d is c orr e ct. Pr o of. W e pro ve by induction on the n umber of arc additions that the method main tains a top ological order until it stops and rep orts a cycle. Consider the bidirectional search triggered b y the addition of an arc ( v , w ) with v > w . The search must stop b ecause it even tually runs out of arcs to tra verse; when this happ ens, all forward and bac kward v ertices are scanned, whic h means that the second stopping condition holds for any s (although it may hold earlier for some particular s ). If a forward arc trav ersal during the search reaches a backw ard vertex x or a bac kward arc trav ersal reaches a forw ard v ertex x , then there is a cycle, consisting of a path from w to x tra versed forw ard, follow ed by a path from x to v trav ersed backw ard, follo wed by ( v , w ). Con versely , suppose that the addition of ( v, w ) creates a cycle, consisting of ( v , w ) follow ed b y a path P from w to v . Consider the situation when the search stops. Let x b e the first non-forw ard v ertex on P and y the last non-backw ard v ertex on P ; b oth x and y exist since v is backw ard (non-forward) and w is forward (non-bac kward). Let u b e the vertex preceding x on P and z the vertex follo wing y on P . Then u is forw ard and z is backw ard. T ra versal of the arc ( u, x ) causes either a cycle to b e rep orted (if x is backw ard) or x to b ecome forward (if it is previously unreached). The latter contradicts the choice of x . Thus either the search stops and rep orts a cycle, or u is unscanned. Symmetrically , either the searc h stops and rep orts a cycle or z is unscanned. Since u < z , for an y s either u < s or z > s . Thus the search cannot stop without rep orting a cycle. W e conclude that the metho d reports a cycle if and only if the addition of ( v , w ) creates one. Supp ose the addition of ( v , w ) do es not create a cycle. Then the searc h cannot report a cy- cle. Thus, for some s , the searc h will stop with all forward v ertices less than s and all bac kward v ertices greater than s scanned. W e need to sho w that the new v ertex order is top ological, assuming that the old one w as. Assume s is not forw ard; the case of s not backw ard is sym- metric. In the new order v < w , since v ∈ X and w ∈ Y ∪ { s } . Let ( x, y ) be any arc other than 4 forwar d vertex unreached vertex backwar d vertex scanned vertex v w s a b d e f Y X v w s e d b a f Fig. 1. Restoring top ological order after bidirectional search. Since s is not forward, the vertices in Y are inserted (in top ological order) just after s , follo wed by the v ertices in X . ( v , w ). W e do a case analysis based on which of the sets X and Y contain x and y . There are nine cases, but t wo are symmetric and t wo are impossible, reducing the n umber of cases to six. Case 1. { x, y } ⊆ X or { x, y } ⊆ Y : x < y in the new order since x and y are b oth in O X or b oth in O Y . Case 2. x ∈ X and y / ∈ X : y / ∈ Y since the graph is acyclic. Since x is scanned, y > s in the old order, whic h implies x < y in the new one. Case 3. x ∈ Y and y / ∈ Y : y / ∈ X since ( x, y ) 6 = ( v , w ). Since x ∈ Y , y > s in the old order, whic h implies x < y in the new one. Case 4. x / ∈ X ∪ Y and y ∈ X : x < y and y < s in the old order, which implies x < y in the new one. Case 5. x / ∈ X ∪ Y and y ∈ Y : x ≤ s in the old order since y is scanned and x / ∈ Y . In the new order, x ≤ s < y . Case 6. x / ∈ X ∪ Y and y / ∈ X ∪ Y : x < y in b oth the old and new orders. u t Lemma 1. The time p er ar c addition is O (1) plus O (1) p er ar c tr averse d by the se ar ch plus any overhe ad ne e de d to guide the se ar ch. Pr o of. The time for the bidirectional search is O (1) plus O (1) per arc trav ersed plus ov erhead. The subgraphs induced by X and Y contain only tra versed arcs. The time to topologically order them is linear since a static topological ordering algorithm suffices. The time to delete v ertices in X ∪ Y from the old vertex order and reinsert them is O (1) p er v ertex in X ∪ Y . u t T o obtain a go od time b ound we need to minimize both the num b er of arcs trav ersed and the search ov erhead. In our discussion we shall assume that no cycle is created. Only one arc addition, the last one, can create a cycle; the last search tak es O ( m ) time plus o verhead. W e need a wa y to charge the search time against graph c hanges caused b y arc additions. T o measure such c hanges, w e count pairs of related graph elemen ts, either v ertex pairs, v ertex- arc pairs, or arc-arc pairs: t wo such elements are r elate d if they are on a common path. The 5 n umber of related pairs is initially zero and nev er decreases. There are at most n 2 < n 2 / 2 v ertex-vertex pairs, nm v ertex-arc pairs, and m 2 < m 2 / 2 arc-arc pairs. Of most use to us are the related arc-arc pairs. W e limit the searc h in three wa ys to make it more efficien t. First, we restrict it to the affe cte d r e gion , the set of v ertices betw een w and v . Specifically , only arcs ( u, x ) with u < v are trav ersed forw ard, only arcs ( y , z ) with z > w are trav ersed bac kward. This suffices to attain an O ( n ) amortized time bound p er arc addition. The b ound comes from a count of newly-related vertex-arc pairs: eac h arc ( u, x ) trav ersed forward is newly related to v , each arc ( y , z ) tra versed backw ard is newly related to w . The algorithm of Marc hetti-Spaccamela et al. [21] is the sp ecial case that do es just a unidirectional search forw ard from w using s = v , with one refinemen t and one difference: it does a depth-first searc h, and it main tains the top ological order as an explicit mapping b et ween the v ertices and the integers from 1 to n . Unidirectional search allows a more space-efficient graph representation, since w e need only forward incidence sets, not bac kward ones. But bidirectional searc h has a b etter time b ound if it is suitably limited. W e mak e the searc h b alanc e d : eac h trav ersal step is of tw o arcs concurren tly , one forward and one backw ard. There are other balancing strategies [3, 15, 16], but this simple one is best for us. Balancing b y itself do es not improv e the time b ound; w e need a third restriction. W e call an arc ( u, x ) trav ersed forward and an arc ( y , z ) trav ersed bac kward c omp atible if u < z . Compatibility implies that ( u, x ) and ( y , z ) are newly related. W e make the search c omp atible : each trav ersal step is of tw o compatible arcs. Lemma 2. If the se ar ches ar e c omp atible, the amortize d numb er of ar cs tr averse d during se ar ches is O ( m 1 / 2 ) p er ar c addition. Pr o of. W e count related arc-arc pairs. Consider a compatible search of 2 k arc trav ersals, k forw ard and k backw ard. Order the arcs ( u, x ) trav ersed forward in increasing order on u , breaking ties arbitrarily . Let ( u, x ) b e the d k/ 2 e th arc in the order. Arc ( u, x ) and eac h arc follo wing ( u, x ) has a compatible arc ( y , z ) tra versed bac kward. Compatibilit y and the ordering of forw ard trav ersed arcs imply that u < z . Thus eac h suc h arc ( y , z ) is newly related to ( u, x ) and to eac h arc preceding ( u, x ), for a total of at least ( k / 2) 2 newly related pairs. W e divide searches into tw o kinds: those that trav erse at most m 1 / 2 arcs and those that tra verse more. Searches of the first kind satisfy the b ound of the lemma. Let 2 k i b e the n umber of arcs tra versed during the i th searc h of the second kind. Since 2 k i > m 1 / 2 and P i ( k i / 2) 2 < m 2 / 2, P i k i < 2 P i k i 2 /m 1 / 2 = 8 P i ( k i / 2) 2 /m 1 / 2 < 4 m 3 / 2 . Thus there are O ( m 1 / 2 ) arc tra versals p er arc addition. u t W e still need a wa y to do a compatible search. The most straigh tforward wa y is to make the searc h ordered: trav erse arcs ( u, x ) forw ard in non-decreasing order on u and arcs ( y , z ) bac kward in non-increasing order on z . W e can implement an ordered search using tw o heaps (priorit y queues) to store unscanned forward and unscanned bac kw ard v ertices. In essence this is the algorithm of Alp ern et al. [3], although they use a differen t balancing strategy . The heap o verhead is O (log n ) p er arc trav ersal, resulting in an amortized time b ound of O ( m 1 / 2 log n ) p er arc addition. More-complicated balancing strategies lead to the improv ements [15, 19, 16] in this b ound for non-dense graphs mentioned in Section 1. 3 Compatible Searc h via a Soft Threshold The running time of an ordered searc h can be reduced further, even for sparse graphs, b y using a faster heap implemen tation, such as those of v an Emde Boas [39, 38], Thorup [37], and Han and Thorup [11]. But we can do even b etter, av oiding the use of heaps en tirely , by exploiting the flexibility of compatible searc h. What we need is a wa y to find a pair of candidate vertices for a trav ersal step: an unscanned forward v ertex u and an unscanned backw ard v ertex z suc h that u < z . It is easy to k eep track of unscanned forward and bac kw ard v ertices, but if w e ha ve an unscanned forward v ertex u and an unscanned backw ard vertex z , what do w e 6 do if u > z ? One answer is to (temporarily) b ypass one of them, but which one? T o resolv e this dilemma, we use a soft threshold s that is an estimate of the stopping threshold for the searc h. If u > z , at least one is on the wrong side of s : either u ≥ s or z ≤ s (or b oth). W e call suc h a vertex far . Our decision rule is to bypass a far vertex. In addition to s , w e need t wo hard thresholds to bound candidate v ertices, a low threshold l and a high threshold h . W e also need a partition of the candidate forward v ertices into tw o sets, A and B , and a partition of the candidate bac kward v ertices into t wo sets, C and D . The v ertices in B ∪ D are far; we call the vertices in A ∪ C ne ar (they may or ma y not b e far). T o do a compatible search, initialize l to w , h to v , s to v or w or any v ertex in b et ween, A to { w } , C to { v } , and B , D , X , and Y to empt y . Then rep eat an applicable one of the follo wing cases until A ∪ B or C ∪ D is empty (see Figure 2): Case 1f. A is empt y: mo v e all v ertices in B to A , set l = s , let s be a v ertex in A , and set s = min { s, h } . Case 1b. C is empty: mov e all vertices in D to C , set h = s , let s b e a vertex in C , and set s = max { s, l } . In the remaining cases A and C are non-empty . Cho ose a vertex u in A and a vertex z in C . Case 2f. u ≥ h : delete u from A . Case 2b. z ≤ l : delete z from C . Case 3f. max { z , s } ≤ u < h : mov e u from A to B . Case 3b. l < z ≤ min { u, s } : mov e z from C to D . In the remaining cases l ≤ u < z ≤ h . Case 4f. All arcs out of u are trav ersed: mov e u from A to X . Case 4b. All arcs into z are trav ersed: mov e z from C to Y . Case 5. No other case applies: trav erse an untra versed arc ( u, x ) out of u and an untra v ersed arc ( y , z ) in to z . If x is bac kward or y is forward, stop and rep ort a cycle. If x is unreac hed, mak e it forward and add it to A ; if y is unreached, make it bac kward and add it to C . If the search stops without detecting a cycle, set s = h if A ∪ B is empt y , s = l otherwise. Delete from X all forw ard v ertices no less than s and from Y all bac kward v ertices no greater than s . Reorder the v ertices as describ ed in Section 2. This algorithm do es some deletions and bypasses lazily that could b e done more eagerly . In particular, when a vertex is mo ved from the far set to the near set in Case 1f or 1b, it can b e deleted if it is on the wrong side of the corresp onding hard threshold (by applying Case 2f or 2b immediately), and it can b e left in the far set if it is on the wrong side of the new soft threshold. The algorithm do es trav ersal steps eagerly: it can do such a step even if one of the t wo vertices inv olved is far, since all that Case 5 requires is compatibility . The results below apply to the original algorithm and to v ariants that do deletions and b ypasses more eagerly and tra versal steps more lazily . Theorem 2. Comp atible se ar ch with a soft thr eshold is c orr e ct. Pr o of. Compatible search is just a sp ecial case of the general metho d presented in Section 2. If the search stops with A ∪ B empt y , then all forward v ertices less than h are scanned; hence the stopping condition holds for s = h . The case of C ∪ D empt y is symmetric. u t Lemma 3. The running time of c omp atible se ar ch with a soft thr eshold is O (1) plus O (1) p er ar c tr averse d plus O (1) for e ach time a vertex b e c omes ne ar. Pr o of. Each case either trav erses tw o arcs and adds at most tw o vertices to A ∪ C , or p erma- nen tly deletes a vertex from A ∪ C , or mov es a vertex from A ∪ C to B ∪ D , or mov es one or more vertices from B ∪ D to A ∪ C . The num b er of times vertices are mo ved from A ∪ C to B ∪ D is at most the num b er of times vertices b ecome near. u t 7 forwar d vertex unreached vertex backwar d vertex scanned vertex ( v , w ) v w a b c d e f l , s h A ={ w } B ={ } D ={ } C ={ v } A = { w } , B = {} , D = {} , C = { v } v w a b c d e f l h s A ={ } B = { b d } D ={ } C = { e c } A = {} , B = { b , d } , D = {} , C = { e , c } v w a b c d e f h ls A ={ } B = { d } D = { c } C ={ } A = {} , B = { d } , D = { c } , C = {} v w a b c d e f h ls A ={ } B ={ } D = { c } C ={ } A = {} , B = {} , D = { c } , C = {} Fig. 2. Compatible search via a soft threshold. A t the end of the search, A ∪ B is empty , so s = h = d is the final threshold and the vertices are reordered as describ ed in Section 2. 8 The algorithm is correct for any choice of soft threshold, but only a careful choice makes it efficient. Rep eated cycling of vertices b et w een near and far is the remaining inefficiency . W e choose the soft threshold to limit such cycling no matter ho w the search proceeds. A goo d deterministic c hoice is to let the soft threshold be the median or an approximate median of the appropriate set ( A or C ); an - appr oximate me dian of a totally ordered set of g elemen ts is an y element that is no less than g and no greater than g of the elements, for some constant > 0. The median is a 1 / 2-approximate median. Finding the median or an approximate median takes O ( g ) time [6, 31]. An alternativ e is to choose the soft threshold uniformly at random from the appropriate set. This giv es a very simple y et efficient randomized algorithm. Lemma 4. If e ach soft thr eshold is an -appr oximate me dian of the set fr om which it is chosen, then the numb er of times a vertex b e c omes ne ar is O (1) plus O (1) p er ar c tr averse d. If e ach soft thr eshold is chosen uniformly at r andom, then the exp e cte d numb er of times a vertex b e c omes ne ar is O (1) plus O (1) p er ar c tr averse d. Pr o of. The v alue of l nev er decreases as the algorithm proceeds; the v alue of h nev er increases. Let k be the num b er of arcs trav ersed. Supp ose each soft threshold is an -approximate median. The first time a v ertex is reached, it b ecomes near. Each subsequen t time it b ecomes near, it is one of a set of g vertices that b ecome near, as a result of b eing mov ed from B to A or from D to C . The tw o cases are symmetric; consider the former. W e shall show that no matter what happ ens subsequently , at least g vertices ha ve b ecome near for the last time. Just after s is changed, at least g vertices in A are no less than s , and at least g vertices in A are no greater than s . Just before the next time s changes, l ≥ s or h ≤ s . In the former case, all v ertices no greater than s can never again b ecome near; in the latter case, all vertices no less than s can never again b ecome near. W e c harge the group of g newly near vertices to the v ertices that become near for the last time. The total num b er of times vertices can b ecome near is at most (1 + 1 / )(2 + k ), where k is the num b er of arcs trav ersed: there are at most 2 + k forward and backw ard vertices and at most 1 + 1 / times a vertex can b ecome near p er forw ard or backw ard vertex. Essen tially the same argument applies if the soft threshold is c hosen uniformly at random. If a set of g vertices b ecomes near, the exp ected num b er that b ecome near for the last time is at least P 1 ≤ i ≤ g / 2 (2 i ) /g = ( g / 2 + 1) / 2 > g / 4 if g is ev en, at least d g / 2 e + P 1 ≤ i< b g/ 2 c (2 i ) /g = d g / 2 e 2 /g > g / 4 if g is o dd. The total exp ected num b er of times v ertices can b ecome near is at most (5 / 4)(2 + k ). u t Theorem 3. The amortize d time for incr emental top olo gic al or dering via c omp atible se ar ch is O ( m 1 / 2 ) p er ar c addition, worst-c ase if e ach soft thr eshold is an -appr oximate me dian of the set fr om which it is chosen, exp e cte d if e ach soft thr eshold is chosen uniformly at r andom. Pr o of. Immediate from Lemmas 1-4. u t 4 Implemen tation In this section we fill in some implementation details. W e also give alternative implementations of dynamic ordered lists and the reordering step. W e need a w ay to keep track of trav ersed and untra versed arcs. W e maintain each incidence set as a singly-link ed list, with a p oin ter indicating the first untra versed arc. Eac h time a vertex is reached during a searc h, the p ointer for its appropriate incidence list is reset to the front. Since a vertex cannot b e b oth forward and backw ard during a single search, one p oin ter p er v ertex suffices. W e also need a w ay to report cycles that are detected, if this is required of the application. F or this purp ose we maintain, for each forward and backw ard vertex other than v and w , the arc b y which it is reached. The description of compatible search is quite general; in particular, it do es not sp ecify ho w to maintain the sets of candidate vertices, or the order in which to consider candidates. 9 A simple implementation is to store the candidate forw ard v ertices in a deque [17] (double- ended queue) F , with v ertices in A preceding those in B and a pointer to the first v ertex in B . The first vertex on F is u . New forward vertices are added to the front of F ; bypassed far v ertices are mov ed from the front to the back of F . When the p oin ter to the first vertex in B indicates the first vertex on F , this pointer is mov ed to the bac k, and l and s are up dated. A deque R that op erates in the same wa y stores the backw ard vertices. Both F and R are actually steques [13] (stack-ended queues or output-restricted deques [17]), since deletions are only from the front. Thus eac h can b e implemented as an array or as a singly-linked, p ossibly circular list. The dynamic ordered list implementations of Dietz and Sleator [8] and of Bender et al. [5] are tw o-level structures that store the elements, in our case v ertices, in contiguous blo c ks of up to b elemen ts, with b = O (log n ), and store the blo c ks in a doubly-linked list. The blo c ks hav e n umbers that are consistent with the list order, higher n umbers for later blo c ks. The elements within a blo ck hav e num b ers that are consisten t with the order within the blo ck. Thus eac h elemen t has a tw o-part num b er that can be retrieved in O (1) time and used to test order in O (1) time, worst-case. The t wo metho ds differ in the details of renum b ering when insertions tak e place. Deletions require no explicit ren umbering and tak e O (1) time worst-case. Insertion tak es O (1) amortized time. This b ound b ecomes worst-case if incremental up dating is done. F or us an amortized bound suffices. Even though the renum b ering schemes of Dietz and Sleator and of Bender et al. are not to o complicated, we can use a simpler t wo-lev el structure if we are willing to suffer an O ( n 1 / 2 ) additive ov erhead p er arc addition, whic h do es not affect the asymptotic bound. W e use a block size of O ( n 1 / 2 ), w e completely renum b er the elemen ts within a blo c k when the blo c k conten ts change other than by a deletion, and w e completely renum b er the blocks when a blo c k is inserted or deleted. W e num b er the blocks, and the elements within a new block, with consecutiv e integers starting from 1. When a blo c k b ecomes less than half full as a result of deletions, we combine it with one of its neighbors. With this metho d the time for a set of k consecutiv e insertions is O ( n 1 / 2 + k ), and the amortized time p er deletion is O (1). This data structure is essentially a t wo-lev el B-tree. Using more levels with a smaller b ound on blo c k size decreases the additive ov erhead p er arc addition but increases the constan t factor for order queries. W e can top ologically order the subgraphs induced by X and Y by using either of the tw o linear-time algorithms for static top ological ordering mentioned in Section 1. The subgraph induced b y X contains exactly the v ertices less than s that are reac hable from w . Th us a simple metho d to order X is to do a depth-first search forward from w , tra versing arcs only from v ertices less than s , and order the reac hed v ertices less than s in decreasing p ostorder [33]. A symmetric depth-first searc h backw ard from v orders Y . An alternative to using a static top ological ordering metho d is to sort X and Y on the current v ertex order. If we use binary comparisons, the time to sort is O ( k log k ), where k is the n umber of vertices sorted. This metho d has the disadv antage that it do es not preserve the O ( m 1 / 2 ) amortized b ound p er arc addition but incurs a logarithmic o verhead. Alternativ ely we can tak e adv antage of the v ertex num b ering used b y the dynamic ordered list structure. Since the num b er of bits needed to represen t the vertex num b ers is O (log n ), w e can sort in O ( n 1 / 2 + k ) time via a radix sort with a fixed num b er of passes; the additive term can be decreased at the exp ense of increasing the constan t factor. Radix sorting preserves the O ( m 1 / 2 ) b ound p er arc addition. Whic h implemen tation of the algorithm is fastest in practice is a question to be resolv ed b y exp erimen ts. 5 Main tenance of Strong Comp onents A natural extension of our top ological ordering algorithm is to the problem of maintaining strong comp onen ts, and a top ological order of them, as arcs are added. This problem has receiv ed muc h less attention than the topological ordering problem. Pearce [23] and P earce et al. [24] men tion extending their top ological ordering algorithm and that of Marchetti- Spaccamela et al. [21] to the strong comp onents problem, but they provide very few details. 10 W e shall describ e how to extend the general metho d of Section 2 and the sp ecific metho d of Section 3 to the strong comp onen ts problem, while main taining for the latter the O ( m 1 / 2 ) amortized time b ound p er arc addition. W e describ e only the additions and c hanges needed. W e b egin at a high level and then fill in the implemen tation details. The graph of strong comp onen ts con tains a vertex for each strong component, and, for eac h original arc ( v , w ), an arc ( c ( v ) , c ( w )), where c ( x ) is the v ertex for the strong comp onen t con taining original vertex x . The graph of strong comp onen ts can con tain lo ops (arcs of the form ( x, x )) and multiple arcs; w e allow both, but ignore loops when searc hing. T o maintain a top ological order of the graph of strong comp onen ts (ignoring lo ops), we extend the metho d of Section 2 as follo ws: T o add an arc ( v , w ), begin b y finding c ( v ) and c ( w ). Add ( c ( v ) , c ( w )) to the set of arcs out of c ( v ) and to the set of arcs into c ( w ). If c ( v ) > c ( w ), do a bidirectional searc h forward from c ( w ) and backw ard from c ( v ), but ignore lo ops and do not stop when a cycle is detected but allo w vertices to b e b oth forward and backw ard. Sp ecifically , do the search as follows. When ab out to tra verse a lo op, put it aside instead of trav ersing it, so it will never b e examined in future searches. When reaching a bac kward v ertex x by a forward trav ersal, do not stop, but instead make x forward. When reac hing a forw ard vertex x b y a backw ard tra versal, do not stop, but instead make x backw ard. Call a vertex forwar d sc anne d if all its outgoing arcs ha ve b een trav ersed, b ackwar d sc anne d if all its incoming arcs hav e b een trav ersed. Con tinue the searc h until there is a vertex s such that all forward v ertices less than s are forward scanned and all bac kward vertices greater than s are backw ard scanned. The addition of ( v, w ) creates a new cycle, and a single new strong comp onen t, if and only if at the end of the search some vertex is b oth forward and backw ard. If there is no such v ertex, reorder the v ertices as in Section 2. Otherwise, let X b e the set of forward vertices less than s and Y the set of backw ard vertices greater than s . The vertex set of the new comp onen t is a subset of X ∪ Y ∪ { s } . Find the vertex set Z of the new comp onent and con tract the vertices in Z to form a single new vertex x representing the comp onen t. Find top ological orders O X and O Y of the vertices in X − Z and the vertices in Y − Z . Delete all v ertices in X and Y from the vertex order. If s is in the comp onen t, replace s by x in the order. (Insert x after s and delete s .) Otherwise, insert x just after s if s is not forward, just b efore s otherwise. Reinsert the vertices in X − Z just after x in order O X and insert the v ertices in Y − Z just b efore x in order O Y . A simple extension of the pro of of Theorem 1 sho ws that this algorithm is correct. An arc can only become a lo op once and b e put aside once. If a new component is created, the time to find it is linear in the num b er of arcs trav ersed by the search if one of the linear-time static algorithms for finding strong comp onen ts mentioned in Section 1 is used. (W e describ e a simpler alternativ e b elo w.) W e can use compatible searc h with a soft threshold in this algorithm, the only change b eing to allow vertices to b e b oth forward and bac kward. The pro of of Theorem 2 gives correctness. Before analyzing the running time of the algorithm, w e fill in some implemen tation details. W e represent the v ertex sets of the strong comp onen ts using a disjoin t set data structure [34, 36]. Each set has a distinguished v ertex, defined by the data structure, that represen ts the set. Tw o op erations are p ossible: – f ind ( x ): return the representativ e of the set containing x ; – link ( x, y ): giv en represen tatives x and y of t wo different sets, form their union, and c ho ose one of x and y to represent it. Originally eac h vertex is in a singleton set. W e maintain the arcs in their original form, with their original end v ertices. F or each represen tative of a comp onen t, w e maintain the set of arcs out of comp onen t vertices and the set of arcs into comp onen t v ertices. These sets are singly link ed circular lists, so that catenation tak es O (1) time. Eac h representativ e also has t wo p ointers, to the first un trav ersed forw ard arc and the first untra versed backw ard arc. T o pro cess an arc ( v , w ) during a search, 11 put ( v, w ) aside (delete it from the incidence list) if f ind ( v ) = f ind ( w ); otherwise, tra verse ( f ind ( v ) , f ind ( w )). T o form a new strong component, com bine representativ es in to a single comp onen t by using l ink to combine the corresp onding vertex sets and catenating all the forw ard incidence lists and all the backw ard incidence lists of the representativ es to form the incidence lists of the represen tative of the new comp onen t. With this data structure the time per l ink is O (1) [34, 36]. Each catenation of arc lists tak es O (1) time per l ink . The total time for all the l ink s and all the catenations of arc lists o ver all arc additions is O (min { n, m } ), whic h is O (1) p er arc addition. There are t wo f ind s p er arc examined during the search. Such an arc is either found to b e a lo op and never examined again, or it is trav ersed by the search. Lemmas 1-4 and Theorem 3 hold for the extension to strong comp onen ts, not counting the time for f ind s. The num b er of f ind s is O ( m 1 / 2 ) p er arc addition b y Lemma 2. Since the b ound on the ratio of f ind s to link s is so high ( O ( m 1 / 2 )), the amortized time for f ind s is O ( m 1 / 2 ) p er arc addition, even if the disjoin t set implemen tation uses path compression with na ¨ ıv e linking [36]; this b ound also holds for path compression with linking by rank or size [36]. The total amortized time p er arc addition is O ( m 1 / 2 ). W e conclude this section with three remarks about implemen tation. First, there is a simple w ay to top ologically order X and Y and to find the new strong comp onen t when one is created. The metho d extends the top ological ordering method men tioned in Section 4. Do a forward depth-first search from w , trav ersing arcs only from vertices less than s . When trav ersing an arc ( x, y ), if y is backw ard, make x backw ard. When the search stops, the vertices in X ∩ Z are the vertices reached by the searc h that are backw ard; decreasing p ostorder is a top ological order of X − Z . A symmetric backw ard search from v gives the v ertices in Y ∩ Z and top ologically orders Y − Z . V ertex s is in the comp onen t if it is b oth forw ard and backw ard. Second, our represen tation of strong components do es not pro vide a wa y to list the vertices in each comp onen t. T o allow this, maintain for each comp onen t a circularly linked list of the v ertices in it: catenating such lists when a new comp onent is formed tak es O (1) time p er link , and the vertices of a comp onen t can b e listed in O (1) time p er vertex by starting at the represen tative (or at any vertex) and trav ersing the list. Third, our metho d does not maintain a representation of the original graph. T o represent b oth the graph of strong comp onen ts and the original graph, maintain, for each vertex, four lists of its inciden t arcs: outgoing but not y et found to b e lo ops; outgoing lo ops; incoming but not y et found to b e lo ops; incoming lo ops. The first and third lists are also part of the lists of outgoing and incoming arcs of the component representativ e; when the end of a sublist is reac hed during a search, this can be detected in O (1) time by chec king one end of the next arc. Each arc is on up to four lists, tw o of outgoing arcs and tw o of incoming arcs, but it only needs t wo p oin ters to arcs next on a list. (See Figure 3.) 6 Lo w er Bounds and Other Issues W e ha ve describ ed an incremen tal topological ordering algorithm that takes O ( m 1 / 2 ) amor- tized time per arc addition. In com bination with the O ( n 2 . 5 /m ) b ound of the second algorithm of Kavitha and Mathew, this giv es an ov erall b ound of O (min { m 1 / 2 , n 2 . 5 /m } ) p er arc addition. F or m/n = o (log n ), our b ound is asymptotically smaller than that of Ka vitha and Mathew ( O ( m 1 / 2 + ( n log n ) /m 1 / 2 )), by a logarithmic factor for m/n = O (1). Although our approach is based on that of Alpern et al. [3] and its v ariants, our metho d a voids the use of heaps. The randomized version of our algorithm is especially simple. Like previous algorithms, our algorithm can handle arc deletions, since a deletion preserves the v alidit y of the current top o- logical order, but the time b ound is no longer v alid. Katriel and Bo dlaender provide a class of examples on which our algorithm runs in Ω ( m 1 / 2 ) time p er arc addition; thus our analysis is tigh t. W e ha ve extended the algorithm to the problem of maintaining strong comp onen ts and a top ological order of strong comp onen ts. In this problem, arc deletions are harder to handle, since one arc deletion can cause a strong component to split into sev eral smaller ones. Ro ditt y and Zwic k [29] presen ted a randomized algorithm for maintaining strong components under 12 representative x y y incoming (non-loop) arc incoming loop arc local pointer global (representative) pointer Fig. 3. Data structure for maintaining the graph of strong comp onen ts and the original graph. Only incoming arc lists are shown. Component x and y were recently linked; all non-lo op arcs in the new comp onen t are accessible from x . arc deletions, but no additions, given an initial graph. The exp ected amortized time per arc deletion is O ( n ) and the query time is O (1), worst-case. Their algorithm do es not maintain a top ological order of the vertices but can b e easily mo dified to do so, with the same b ounds. If both additions and deletions are allo wed, there is no kno wn solution b etter than running an O ( m )-time static algorithm after eac h graph change, even for the simplest problem, that of cycle detection. There has b een quite a bit of work on the harder problem of main taining full reac hability information for a dynamic graph. See [29, 30]. F or the incremental top ological ordering problem there are a couple of low er b ounds, but there are large gaps betw een the existing low er bounds and the upper bounds. Ramalingam and Reps [28] gav e a class of examples in which n − 1 arc additions force Ω ( n log n ) v ertices to b e reordered, no matter what top ological order is maintained. This is the only general lo wer b ound. Katriel [14] considered what she called the top olo gic al sorting pr oblem , in whic h the topological order must b e maintained as an explicit map b et ween the vertices and the in tegers b et ween 1 and n . F or algorithms that only renum b er vertices within the affected region, she gav e a class of examples in whic h O ( n ) arc additions cause Ω ( n 2 ) v ertices to be reordered. The algorithms of Marc hetti-Spaccamela et al., P earce and Kelly , Ajw ani et al., and the O ( n 2 . 5 ) algorithm of Kavitha and Mathew are all sub ject to this b ound, although our algorithm is not. F or topological ordering algorithms that reorder only vertices within the affected region, w e can obtain a lo wer bound of Ω ( nm 1 / 2 ) on the total num b er of v ertex reorderings in the w orst case, assuming m = Ω ( n ). F or simplicit y assume that m is a perfect square and m 1 / 2 ev enly divides n . Number the vertices from 1 through n in their initial top ological order; use these fixed n umbers to p ermanen tly identify the vertices ev en as the order changes. Begin b y adding arcs to form m 1 / 2 paths, each consisting of a sequence of k = n/m 1 / 2 consecutiv e v ertices. Then add arcs (2 k, 1) , (3 k , 1) , . . . , ( n, 1) , (3 k , k + 1) , (4 k , k + 1) , . . . , ( n, k + 1) , (4 k , 2 k + 1) , (5 k , 2 k + 1) , . . . , ( n, 2 k + 1) , and so on. The total n umber of arcs added is n − m 1 / 2 to form the initial paths plus m 1 / 2 ( m 1 / 2 − 1) / 2, totaling less than m if n ≤ m/ 2 + 3 m 1 / 2 / 2. After the initial paths are formed, each arc addition forces the reordering of k vertices if the reordering is only within the affected region, for a total of Ω ( nm 1 / 2 ) vertex reorderings. The reordering is forced: eac h arc addition causes tw o paths to change places. (See Figure 4.) The b ound of Ω ( nm 1 / 2 ) applies to all existing algorithms, including ours; for sparse graphs, the running time of our algorithm matches this bound. If w e are only in terested in minimizing the n umber of vertex reorderings, not minimizing the running time, we can get a matc hing upp er b ound of O ( nm 1 / 2 ) on the num b er of vertex reorderings by doing an ordered bidirec- 13 123 456 789 1 0 1 1 1 2 123 456 78 9 1 0 1 1 1 2 456 123 78 9 1 0 1 1 1 2 456 123 10 11 12 7 8 9 Fig. 4. The Ω ( nm 1 / 2 ) v ertex reordering construction with n = 12, m = 16. tional search that alternates b et ween scanning a forward v ertex and scanning a backw ard v ertex; a count of related vertex pairs gives the b ound. Another observ ation is that if the incident arc lists are sorted by end vertex, our compatible searc h method can be modified so that the total search time ov er all arc additions is O ( n 2 ): stop trav ersing arcs inciden t to a vertex when the next arc is incident to a vertex outside the hard thresholds. This b ound, also, comes from a coun t of related v ertex pairs. Unfortunately , k eeping the arc lists sorted seems to require more than O ( m 3 / 2 ) time, giving us no actual impro vemen t. The O ( n 2 . 75 )-time algorithm of Ajw ani et al. uses this idea but keeps the arc lists partially sorted, trading off searc h time against arc list reordering time. The running time analysis of Ajw ani et al. and that of Ka vitha and Mathew for their O ( n 2 . 5 )-time algorithm rely on a linear program to b ound the total amount by whic h vertex n umbers change. Although the solution to this linear program is Θ ( n 2 . 5 ), it may not capture all the constrain ts of the problem, and Kavitha and Mathew do not pro vide a class of examples for which their time b ound is tight. One would like suc h a class of examples, or alternatively a tigh ter analysis of their algorithm. W e ha ve used amortized running time as our measure of efficiency . An alternative w ay to measure efficiency is to use an incremen tal competitive model [27], in whic h the time spent to handle an arc addition is compared against the minimum w ork that must b e done by any algorithm, giv en the same current topological order and the same arc addition. The minim um w ork that must b e done is the minimum n umber of vertices that must be reordered, which is the measure that Ramalingam and Reps used in their low er b ound. But no existing algorithm handles an arc addition in time p olynomial in the minimum num b er of vertices that must b e reordered. T o obtain p ositiv e results, some researchers hav e measured the p erformance of their algorithms against the minim um sum of degrees of vertices that m ust b e reordered [3] or a more-refined measure that coun ts out-degrees of forw ard v ertices and in-degrees of bac kward v ertices [25]. F or these mo dels, appropriately balanced forms of ordered search are comp etitive to within a logarithmic factor [3, 25]. In such a mo del, our algorithm is comp etitiv e to within a constan t factor. W e think, though, that suc h a mo del is misleading: it do es not account for the p ossibilit y that different algorithms may maintain different top ological orders, it do es not account for correlated effects of multiple arc additions, and go o d b ounds hav e only b een obtained for a mo del that may ov ercharge the adversary . Alp ern et al. and P earce and Kelly consider batched arc additions as well as single arc additions. W e ha ve not y et considered generalizing compatible searc h to handle batc hed arc additions. Doing so migh t lead improv ements in practice, if not in theory . 14 Our algorithm uses a vertex num b ering scheme in whic h all v ertices ha ve distinct n umbers. Alp ern et al. allo wed vertices to b e n umbered the same if there is no path b et ween them, in an effort to minimize the num b er of distinct vertex num b ers. Our algorithm can b e mo dified to include this idea, as follo ws. Add an extra level to the dynamic list order structure: v ertices are group ed into those of equal num b er; each group is an elemen t of a blo c k in the doubly-linked list of blo c ks. (See Section 4.) Start with all vertices in a single group. Ha ving computed X and Y after a search, delete all vertices in X and Y from their resp ectiv e groups, and delete all empty groups. If s is not forward, delete all forward vertices from the group containing s and add these vertices to X . If s is not backw ard, delete all backw ard vertices from the group con taining s and add them to Y . (If s is neither forward nor backw ard, do b oth.) Assign eac h vertex in X to a new group corresponding to its maxim um path length (in arcs) from w ; assign each vertex in Y to a new group corresp onding to its maximum path length (in arcs) to v . If s is not forw ard, insert the new groups just after that of s , with the groups of Y first, in decreasing order of their maximum path length to v , follow ed by the groups of X , in increasing order of their maximum path length from w . Pro ceed symmetrically if s is not bac kward. Computing maxim um path lengths tak es linear ti me [35], so the o v erall time bound is unaffected. This metho d extends to the main tenance of strong comp onents. Whether this idea yields a sp eed-up in practice is an exp erimen tal question. References 1. A. V. Aho, J. E. Hop croft, and J. D. Ullman. Data Structur es and Algorithms . Addison W esley , 1983. 2. D. Ajwani, T. F riedrich, and U. Meyer. An O ( n 2 . 75 ) algorithm for online topological ordering. In SW A T 2006 , volume 4059, pages 53–64, 2006. 3. B. Alp ern, R. Ho o ver, B. K. Rosen, P . F. Sweeney , and F. K. Zadeck. Incremental ev aluation of computational circuits. In SODA 1990 , pages 32–42, 1990. 4. F. Belik. An efficient deadlo c k a voidance technique. IEEE T r ans. on Comput. , 39(7), 1990. 5. M. A. Bender, R. Cole, E. D. Demaine, M. F arach-Colton, and J. Zito. Two simplified algorithms for main taining order in a list. In ESA 2002 , volume 2461, pages 152–164, 2002. 6. M. Blum, R. W. Floyd, V. Pratt, R. L. Riv est, and R. E. T arjan. Time b ounds for selection. J. of Comput. and Syst. Sci. , 7(4):448–461, 1973. 7. J. Cheriy an and K. Mehlhorn. Algorithms for dense graphs and netw orks on the random access computer. A lgorithmic a , 15(6):521–549, 1996. 8. P . F. Dietz and D. D. Sleator. Two algorithms for main taining order in a list. In STOC 1987 , pages 365–372, 1987. 9. M. F¨ ahndrich, J. S. F oster, Z. Su, and A. Aik en. Partial online cycle elimination in inclusion constrain t graphs. In PLDI 1998 , pages 85–96, 1998. 10. H. N. Gab o w. P ath-based depth-first searc h for strong and biconnected comp onents. Information Pr oc essing L etters , 74(3–4):107–114, 2000. 11. Y. Han and M. Thorup. In teger sorting in O ( n √ log log n ) expected time and linear space. In FOCS 2002 , pages 135–144, 2002. 12. F. Harary , R. Z. Norman, and D. Cartwrigh t. Structur al Mo dels : An Intro duction to the Theory of Dire cte d Gr aphs . John Wiley & Sons, 1965. 13. H. Kaplan and R. E. T arjan. P ersistent lists with catenation via recursive slow-do wn. In STOC 1995 , pages 93–102, 1995. 14. I. Katriel. On algorithms for online top ological ordering and sorting. T echnical Rep ort MPI-I- 2004-1-003, Max-Planc k-Institut f ¨ ur Informatik, Saarbr¨ uck en, Germany , 2004. 15. I. Katriel and H. L. Bo dlaender. Online top ological ordering. ACM T r ans. on Algor. , 2(3):364– 379, 2006. 16. T. Ka vitha and R. Mathew. F aster algorithms for online top ological ordering, 2007. 17. D. E. Knuth. The Art of Computer Pr o gr amming, V olume 1: F undamental Algorithms . Addison- W esley , 1973. 18. D. E. Knuth and J. L. Szwarcfiter. A structured program to generate all top ological sorting arrangemen ts. Inf. Pr o c. L ett. , 2(6):153–157, 1974. 19. H.-F. Liu and K.-M. Chao. A tight analysis of the Katriel-Bo dlaender algorithm for online top ological ordering. The or. Comput. Sci. , 389(1-2):182–189, 2007. 15 20. A. Marchetti-Spaccamela, U. Nanni, and H. Rohnert. On-line graph algorithms for incremental compilation. In WG 1993 , volume 790, pages 70–86. 1993. 21. A. Marc hetti-Spaccamela, U. Nanni, and H. Rohnert. Maintaining a top ological order under edge insertions. Inf. Pr o c. L ett. , 59(1):53–58, 1996. 22. S. M. Omoh undro, C.-C. Lim, and J. Bilmes. The Sather language compiler/debugger imple- men tation. T echnical Report TR-92-017, International Computer Science Institute, Berkeley , 1992. 23. D. J. Pearce. Some dir e cte d gr aph algorithms and their applic ation to p ointer analysis . PhD thesis, Imp erial College, London, 2005. 24. D. J. Pearce and P . H. J. Kelly . Online algorithms for top ological order and strongly connected comp onen ts, 2003. 25. D. J. P earce and P . H. J. Kelly . A dynamic top ological sort algorithm for directed acyclic graphs. J. of Exp. Algorithmics , 11:1.7, 2006. 26. D. J. Pearce, P . H. J. Kelly , and C. Hankin. Online cycle detection and difference propagation for p oin ter analysis. In SCAM 2003 , pages 3–12, 2003. 27. G. Ramalingam and T. W. Reps. On the computational complexity of incremental algorithms. T echnical Report CS-TR-1991-1033, Universit y of Wisconsin-Madison, 1991. 28. G. Ramalingam and T. W. Reps. On comp etitiv e on-line algorithms for the dynamic priorit y- ordering problem. Inf. Pr o c. L ett. , 51(3):155–161, 1994. 29. L. Ro ditty and U. Zwic k. Improv ed dynamic reachabilit y algorithms for directed graphs. In FOCS 2002 , pages 679–688, 2002. 30. L. Roditty and U. Zwic k. A fully dynamic reac habilit y algorithm for directed graphs with an almost linear up date time. In STOC 2004 , pages 184–191, 2004. 31. A. Sc h¨ onhage, M. Paterson, and N. Pippenger. Finding the median. J. of Comput. and Syst. Sci. , 13(2):184–199, 1976. 32. M. Sharir. A strong-connectivity algorithm and its applications in data flow analysis. Comput. and Math. with App. , 7(1):67–72, 1981. 33. R. E. T arjan. Depth-first search and linear graph algorithms. SIAM J. on Comput. , 1(2):146–160, 1972. 34. R. E. T arjan. Efficiency of a go od but not linear set union algorithm. J. of the ACM , 22(2):215– 225, 1975. 35. R. E. T arjan. Data Structur es and Network Algorithms . SIAM, 1983. 36. R. E. T arjan and J. v an Leeuw en. W orst-case analysis of set union algorithms. J. of the ACM , 31(2):245–281, 1984. 37. M. Thorup. In teger priorit y queues with decrease key in constan t time and the single source shortest paths problem. J. of Comput. Syst. Sci. , 69(3):330–353, 2004. 38. P . v an Emde Boas. Preserving order in a forest in less than logarithmic time and linear space. Inf. Pro c. L ett. , 6(3):80–82, 1977. 39. P . v an Emde Boas, R. Kaas, and E. Zijlstra. Design and implementation of an efficient priority queue. Mathematic al Systems The ory , 10:99–127, 1977.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment