Toeplitz Block Matrices in Compressed Sensing
Recent work in compressed sensing theory shows that $n\times N$ independent and identically distributed (IID) sensing matrices whose entries are drawn independently from certain probability distributions guarantee exact recovery of a sparse signal wi…
Authors: Florian Sebert, Leslie Ying, Yi Ming Zou
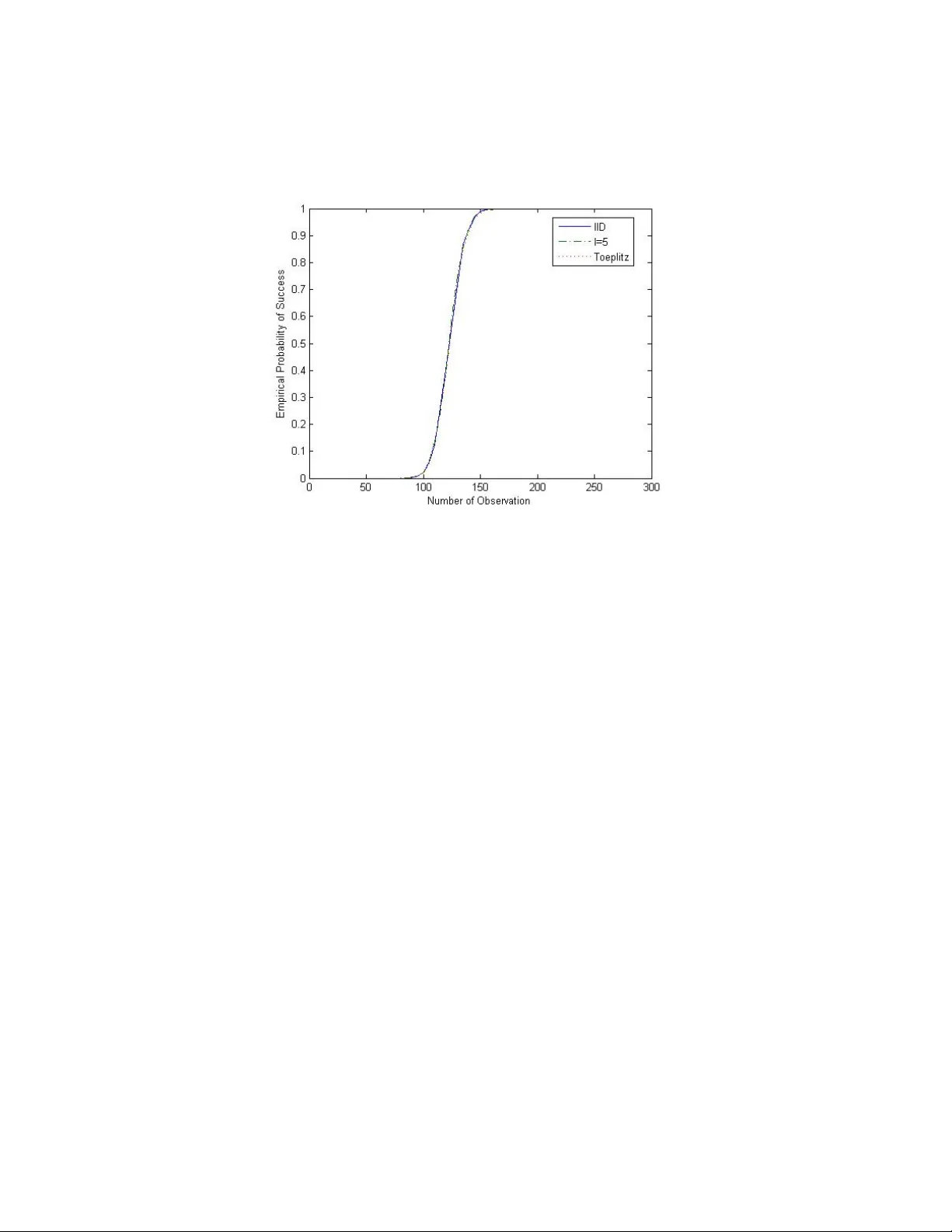
TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU Abstract. Recen t work in compressed sensing theory sho ws that n × N indep enden t and iden tically distributed (IID) sensing matri- ces whose en tries are dra wn independently from certain probabilit y distributions guaran tee exact reco v ery of a sparse signal with high probabilit y ev en if n N . Motiv ated b y signal pro cessing ap- plications, random filtering with T o eplitz sensing matrices whose elemen ts are drawn from the same distributions were considered and shown to also b e sufficient to reco v er a sparse signal from reduced samples exactly with high probability . This pap er con- siders T o eplitz blo ck matrices as sensing matrices. They naturally arise in multic hannel and multidimensional filtering applications and include T o eplitz matrices as sp ecial cases. It is shown that the probabilit y of exact reconstruction is also high. Their p erformance is v alidated using sim ulations. 1. Introduction The cen tral problem in compressed sensing (CS) is the recov ery of a v ector x ∈ R N from its linear measurements y of the form y i = < x, ϕ i >, 1 ≤ i ≤ n, (1.1) where n is assumed to b e m uch smaller than N . Of course, for n N , (1.1) p osts an under-determined system of equations whic h has non- unique solutions. Exact reco very of the original v ector x needs further prior information. The w ork b y Cand ´ es, Donoho, Romberg, T ao, and others (see e.g. [1],[2], and the references therein) sho wed that under the assumption that x is sparse, one can actually reco ver x from a sample y whic h is muc h smaller in size than x b y solving a conv ex Date : 01/10/2008. F. Sebert and Y. M. Zou are with the Departmen t of Mathematical Sciences, Univ ersit y of Wisconsin, Milw aukee, WI 53201, USA email: fmseb ert@u wm.edu, ymzou@u wm.edu. L. Ying is with the Department of Electrical Engineering, Universit y of Wiscon- sin, Milw auk ee, WI 53201, USA email: leiying@u wm.edu. 1 2 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU program with a suitably c hosen sampling basis ϕ i , 1 ≤ i ≤ n . If w e write the linear system (1.1) in the form y = Φ x, where Φ is an n × N matrix , (1.2) then the question ab out what sampling metho ds guaran tee the exact reco very of x b ecomes the question ab out what matrices are “go o d” compressed sensing matrices, meaning that they ensure exact recov ery of a sparse x from y with high probabilit y under the condition that n N . In [3] Cand ` es and T ao in tro duce the r estricte d isometry pr op erty as a condition on matrices Φ which pro vides a guaran tee on the p erformance of Φ in compressed sensing. F ollowing their definition, we say that a matrix Φ ∈ R n × N satisfies RIP of order m ∈ N and constan t δ m ∈ (0 , 1) if (1.3) (1 − δ m ) k z k 2 2 ≤ k Φ T z k 2 2 ≤ (1 + δ m ) k z k 2 2 ∀ z ∈ R | T | , where T ⊂ { 1 , 2 , . . . , N } , | T | ≤ m , and Φ T denotes the matrix obtained b y retaining only the columns of Φ corresp onding to the en tries of T . It w as sho wn in [3] (rein terpreted in [4]) that if Φ satisfies RIP of order 3 m and constant δ 3 m ∈ (0 , 1): (1.4) (1 − δ 3 m ) k z k 2 2 ≤ k Φ T z k 2 2 ≤ (1 + δ 3 m ) k z k 2 2 ∀ z ∈ R | T | , where T ⊂ { 1 , 2 , . . . , N } and | T | ≤ 3 m , the deco der given b y (1.5) 4 ( y ) := argmin k x k l N 1 sub ject to Φ x = y ensures exact recov ery of x from y . Recen tly Baraniuk et al [5] sho w ed that matrices whose entries are dra wn indep endently from certain probability distribution P satisfy RIP of order m with probabilit y ≥ 1 − e − c 2 n for every δ m ∈ (0 , 1) pro vided that n ≥ c 1 m ln( N /m ), where c 1 , c 2 > 0 are some p ositiv e constan ts dep ending only on δ m . Motiv ated b y applications in signal pro cessing, Ba jw a et al [6] considered (truncated) T o eplitz-structured matrices whose entries are drawn from the same probability distribu- tions P and sho w ed that they satisfy RIP of order 3 m with probability ≥ 1 − e − c 2 n/m 2 for ev ery δ 3 m ∈ (0 , 1) pro vided that n ≥ c 1 m 3 ln( N /m ). Some examples of probabilit y distributions that can b e used in this con text ha ve b een studied in [7]. They include r i,j ∼ N 0 , 1 n , TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 3 (1.6) r i,j = 1 √ n with probabilit y 1 / 2 − 1 √ n with probabilit y 1 / 2 , r i,j = r 3 n with probabilit y 1 / 6 0 with probabilit y 2 / 3 − r 3 n with probabilit y 1 / 6 . Motiv ated b y applications in m ultichannel sampling, in this pap er we will consider T o eplitz block matrices with elemen ts in each blo ck dra wn indep enden tly from one of the probability distributions in (1.6) and some other blo ck matrices with similar structures. W e show that suc h matrices also satisfy RIP of order 3 m for every δ 3 m ∈ (0 , 1) with high probabilit y , provided that n ≥ c 1 l m ln( N /m ), where l ≤ 3 m (3 m − 1) and c 1 > 0 is some p ositiv e constant dep ending only on δ 3 m . These T o eplitz block matrices naturally represent the system equation matri- ces in m ultichannel sampling applications where a single input signal is reco vered from output samples of m ultiple channels with I ID random filters. The result justifies the use of multic hannel o v er single-channel systems in compressed sensing. The adv an tages of T o eplitz matrices p oin ted out in [6], lik e e.g. efficient implementations, also apply to the matrices considered in this pap er. 2. Main Resul t Theorem 2.1. F or T o eplitz blo ck matric es of the form (2.1) Φ = Φ k Φ k − 1 . . . Φ 2 Φ 1 Φ k +1 Φ k . . . Φ 3 Φ 2 . . . . . . . . . . . . . . . Φ k + l − 1 Φ k + l − 2 . . . . . . Φ l ∈ R n × N with blo cks Φ i ∈ R d × e whose elements ar e dr awn indep endently fr om one of the pr ob ability distributions in (1.6), ther e exist c onstants c 1 , c 2 > 0 dep ending only on δ 3 m ∈ (0 , 1) , such that: (i) If l ≤ 3 m (3 m − 1) , then for any n ≥ c 1 l m ln( N /m ) , Φ satisfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/l . 4 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU (ii) If l > 3 m (3 m − 1) , then for any n ≥ c 1 m 3 ln( N /m ) , Φ satisfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/m 2 . The ab ov e theorem gives the requirement for and probabilit y of ex- act reconstruction of a 3 m -sparse signal x from a measurement y if T o eplitz blo c k matrices are used. In particular it says, that if the num- b er of blo c ks ( l ) in one column of Φ do es not exceed a certain v alue dep ending only on the sparsity of the signal x , the probabilit y of p erfect reconstruction is greater and the num b er of required measuremen ts is smaller than if l is not b ounded in this w ay . As noted in [6, 9], T o eplitz matrices naturally arise in one-dimensional single-c hannel filtering applications where the matrix elemen ts are fil- ter co efficien ts. Similarly , the T o eplitz blo ck matrices defined in (2.1) naturally arise in one-dimensional m ultichannel sampling applications where the length of the filter is at least l points larger than that of the input signal. The conv en tional multic hannel sampling theorem states that the sampling rate reduction ov er the single channel system cannot exceed the n umber of channels for exact recov ery . While Theorem 2.1 suggests that multic hannel systems with I ID random filters migh t b e able to reduce the sampling rate by a factor higher than the n umber of c hannels. W e remark, that for other block matrices with similar structures, the result in Theorem 2.1 also holds (see IV). 3. Proof of Main Resul t Let T ⊂ { 1 , 2 , . . . , N } . Denote by Φ T ,i the i -th row of the matrix Φ T obtained by retaining only those columns of Φ corresp onding to the elemen ts in T , and let Φ T ,i ∩ Φ j denote the set of random v ariables common to the i -th ro w of Φ T and the j -th blo ck of Φ. W e note that, if (1.4) holds for a set T ⊂ { 1 , 2 , . . . , N } , then it also holds for an y ˜ T ⊂ T . T o prov e that T o eplitz I ID blo c k matrices satisfy RIP with high probability , it is therefore enough to consider only those sets T where | T | = 3 m . Lemma 3.1. Define the sets D T ,i by D T ,i = { j ∈ { 1 , 2 , . . . , n } : Φ T ,j is sto chastic al ly dep endent on Φ T ,i , j 6 = i } . (i) If T satisfies | T | < 1+ √ 1+4 l 2 , then | D T ,i | ≤ | T | ( | T | − 1) ≤ l − 1 . (ii) If T satisfies | T | ≥ 1+ √ 1+4 l 2 , then | D T ,i | ≤ l − 1 . TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 5 Pr o of. Fix Φ T ,i . T defines a sequence { r t s } k s =1 , where r t s is the num b er of columns from blo ck Φ t s in T . Th us P k s =1 r t s = | T | . Consider the n umber of rows that hav e dep endency with the elemen ts in Φ t s ∩ Φ T ,i . Since all elements inside a single blo ck are indep enden t, there can b e no dep endencies within one blo c k. Moreo v er, b ecause of the structure of the matrix Φ, there can b e at most 0 if Φ t s ∩ Φ T ,i = ∅ | T | − r t s if Φ t s ∩ Φ T ,i 6 = ∅ ro ws outside the blo ck Φ t s that dep end on an y element in Φ t s ∩ Φ T ,i . (i) If T satisfies | T | < 1+ √ 1+4 l 2 , i.e. if l > | T | ( | T | − 1), these ro ws may b e distinct, and w e hav e | D T ,i | ≤ X { t s ,s ∈{ 1 , 2 ,...,k } :Φ t s ∩ Φ T ,i 6 = ∅} ( | T | − r t s ) ≤ X t ∈ T ( | T | − 1) = | T | ( | T | − 1) ≤ l − 1 dep enden t ro ws. (ii) If T satisfies | T | ≥ 1+ √ 1+4 l 2 , i.e. if | T | ( | T | − 1) ≥ l , then | D T ,i | is upp er b ounded by the n umber of blo c ks, so | D T ,i | ≤ l − 1. In [7] it has b een shown that for giv en n , N , and T ⊂ { 1 , 2 , . . . , N } with | T | ≤ m , an I ID matrix of size n × N with entries dra wn inde- p enden tly from one of the distributions P in (1.6) 1 satisfies (1.3) with probabilit y (3.1) ≥ 1 − e − f ( n,m,δ m ) , where (3.2) f ( n, m, δ m ) = c 0 n − m ln(12 /δ m ) − ln(2) . No w consider a (truncated) T o eplitz blo ck matrix Φ ∈ R n × N as in (2.1), where the blo c ks { Φ i } k + l − 1 i =1 are such I ID matrices ∈ R d × e with entries drawn indep enden tly from the same set of distributions as ab o v e. The following lemma giv es an upp er b ound for the probability that a matrix as in (2.1) with 1 ≤ l ≤ n satisfies (1.4) for an y fixed subset T with | T | = 3 m . Lemma 3.3 giv es a tigh ter b ound for the case l > | T | ( | T | − 1). 1 These matrices consist of columns whose squared norm is equal to 1 in exp ectation. 6 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU The pro of of Lemma 3.2 uses an argument similar to the one in the pro of of Lemma 1 in [6]. Lemma 3.2. F or given T ⊂ { 1 , 2 , . . . , N } with | T | = m , and δ m ∈ (0 , 1) , the T o eplitz blo ck submatrix Φ T satisfies (1.4) with pr ob ability at le ast 1 − e − f ( d,m,δ m )+ln( l ) . Pr o of. W e can write the matrix Φ T as (3.3) Φ T = Φ 1 T . . . Φ l T , where the blo cks Φ i T of size d × | T | are giv en b y the columns determined b y T in the i -th ro w of blo cks (Φ k + i − 1 , Φ k + i − 2 , . . . , Φ i ) in Φ. Note that ∀ i ∈ { 1 , 2 , . . . , l } , Φ i T is an I ID matrix with entries from one of the distributions in (1.6). If we let ˜ Φ i T = √ l Φ i T , then the matrices ˜ Φ i T ha ve columns whose squared norm is equal to 1 in exp ectation and b y (3.1) satisfy (1.4), i.e. (1 − δ m ) k z k 2 2 ≤ k ˜ Φ i T z k 2 2 ≤ (1 + δ m ) k z k 2 2 , ∀ z ∈ R | T | , ∀ i ∈ { 1 , 2 , . . . , l } , with probabilit y at least (3.4) 1 − e − f ( d,m,δ m ) . No w since (3.5) k Φ T z k 2 2 = l X i =1 k Φ i T z k 2 2 = l X i =1 1 l k ˜ Φ i T z k 2 2 and P l i =1 1 l = 1, we hav e (1 − δ m ) k z k 2 2 ≤ k Φ T z k 2 2 ≤ (1 + δ m ) k z k 2 2 , ∀ z ∈ R | T | . In other words, the even t E 1 = { ˜ Φ i T satisfies (1.4) ∀ i } implies the ev ent E 2 = { Φ T satisfies (1 . 4) } . Consequently , P ( E 2 ) = 1 − P ( E c 2 ) ≥ 1 − P ( E c 1 ) ≥ 1 − l X i =1 P ( { ˜ Φ i T do es not satisfy (1 . 4) } ) ≥ 1 − l X i =1 e − f ( d,m,δ m ) (b y (3.4)) = 1 − e − f ( d,m,δ m )+ln( l ) . TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 7 Lemma 3.3. F or given T ⊂ { 1 , 2 , . . . , N } with | T | = m , and δ m ∈ (0 , 1) , if l > | T | ( | T | − 1) , the T o eplitz blo ck submatrix Φ T satisfies (1.4) with pr ob ability at le ast 1 − e − f ( b n/q c ,m,δ m )+ln( q ) , wher e q = | T | ( | T | − 1) + 1 . Pr o of. Let Φ T ,i denote the i -th ro w of Φ T and construct an undirected dep endency graph G = ( V , E ) such that V = { 1 , 2 , . . . , n } and E = { ( i, i 0 ) ∈ V × V : i 6 = i 0 , Φ T ,i and Φ T ,i 0 are dep endent } . By Lemma 3.1, Φ T ,i can at most b e dep enden t with | T | ( | T | − 1) other ro ws. Therefore, the maxim um degree 4 of G is giv en b y 4 ≤ | T | ( | T | − 1), and using the Ha jnal-Szemer ´ edi theorem on equitable coloring of graphs, w e can partition G using q = | T | ( | T | − 1) + 1 colors. Let { C j } q j =1 b e the different color classes, then | C j | = b n/q c or | C j | = d n/q e . No w, let Φ j T b e the | C j | × | T | submatrix obtained from Φ T retaining the ro ws corresp onding to the indices in C j and define ˜ Φ j T = p n/ | C j | Φ j T . Then (3.6) ∀ z ∈ R | T | , k Φ T z k 2 2 = q X j =1 k Φ j T z k 2 2 = q X j =1 | C j | n k ˜ Φ j T z k 2 2 . Ev ery ˜ Φ j T is a | C j | × | T | I ID matrix whose columns hav e squared norm equal to 1 in exp ectation. By (3.1), they satisfy (1.4) with probability at least (3.7) 1 − e − f ( | C j | ,m,δ m ) ≥ 1 − e − f ( b n/q c ,m,δ m ) . Since P q j =1 | C j | n = 1, by (3.6), we hav e that if (1 − δ m ) k z k 2 2 ≤ k ˜ Φ j T z k 2 2 ≤ (1+ δ m ) k z k 2 2 , ∀ z ∈ R | T | , ∀ j ∈ { 1 , 2 , . . . , q } then (1 − δ m ) k z k 2 2 ≤ k Φ T z k 2 2 ≤ (1 + δ m ) k z k 2 2 , ∀ z ∈ R | T | . 8 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU In other w ords, the ev ent E 1 = { ˜ Φ j T satisfies (1.4) for all j } implies the ev ent E 2 = { Φ T satisfies (1 . 4) } . Consequently , P ( E 2 ) = 1 − P ( E c 2 ) ≥ 1 − P ( E c 1 ) ≥ 1 − q X j =1 P ( { ˜ Φ j T do es not satisfy (1 . 4) } ) ≥ 1 − q X j =1 e − f ( b n/q c ,m,δ m ) (b y (3.7)) = 1 − e − f ( b n/q c ,m,δ m )+ln( q ) . Main result in Theorem 2.1. Pr o of. (i) F rom (3.2) and Lemma 3.2 w e hav e that Φ satisfies (1.4) for an y T ⊂ { 1 , 2 , . . . , N } such that | T | = 3 m with probabilit y at least (3.8) 1 − e − c 0 d +3 m ln(12 /δ 3 m )+ln(2)+ln( l ) . Since there are N 3 m ≤ ( eN / 3 m ) 3 m suc h subsets, using Bonferroni’s inequalit y (see e.g. [8]) yields that Φ satisfies RIP of order 3 m with probabilit y at least (3.9) 1 − e − c 0 n/l +3 m [ln(12 /δ 3 m )+ln( N/ 3 m )+1]+ln(2)+ln( l ) . Fix c 2 > 0 and pick c 1 = (3 ln((12 /δ 3 m )) + 15) / ( c 0 − c 2 ). Then for an y n ≥ c 1 l m ln( N /m ), the exp onent of e in (3.9) is upp er b ounded by TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 9 − c 2 n/l : − c 0 n l + 3 m ln 12 δ 3 m N 3 m + 1 + ln(2 l ) ≤ − c 2 n l ⇔ 3 m ln 12 δ 3 m N 3 m + 1 + ln(2 l ) ≤ n l ( c 0 − c 2 ) ⇔ 3 l m c 0 − c 2 ln 12 δ 3 m N 3 m + 1 + ln(2) 3 m + ln( l ) 3 m ≤ n ⇔ 3 l m ln N m c 0 − c 2 ln 12 δ 3 m N 3 m + 1 + ln(2) + ln( l ) 3 m ln N m ≤ n ⇐ 3 l m ln N m c 0 − c 2 ln 12 δ 3 m + 5 ≤ n ⇔ c 1 l m ln N m ≤ n (ii) F rom (3.2) and Lemma 3.3 w e hav e that Φ satisfies (1.4) for an y T ⊂ { 1 , 2 , . . . , N } such that | T | = 3 m with probability at least 1 − e − c 0 b n/q c +3 m ln(12 /δ 3 m )+ln(2)+ln( q ) ≥ 1 − e − c 0 n/ 9 m 2 +3 m ln(12 /δ 3 m )+ln(2)+ln(9 m 2 )+ c 0 . (3.10) Since there are N 3 m ≤ ( eN / 3 m ) 3 m suc h subsets, using Bonferroni’s inequalit y again yields that Φ satisfies RIP of order 3 m with probabilit y at least (3.11) 1 − e − c 0 k/ 9 m 2 +3 m [ln(12 /δ 3 m )+ln( N/ 3 m )+1]+ln(2)+ln(9 m 2 )+ c 0 . No w fix c 2 > 0 and pick c 1 > 27 c 3 / ( c 0 − 9 c 2 ), where c 3 = ln(12 /δ 3 m ) + ln(2) + c 0 + 4. Then, for any n ≥ c 1 m 3 ln( N /m ), the exp onent of e in (3.11) is upp er b ounded b y − c 2 n/m 2 . This completes the pro of of the theorem. R emark 3.1 . If l = 1, then Φ is an I ID matrix, and Theorem 2.1 low er b ounds the probability of Φ satisfying RIP of order 3 m by 1 − e − c 2 n , whic h reco vers the bound obtained in [5]. R emark 3.2 . As long as l ≤ 3 m (3 m − 1), a matrix Φ as in (2.1) satisfies RIP of order 3 m with probability 1 − e − c 2 n/l ≥ 1 − e c 0 2 n/m 2 , which is the b ound given in [6], since (3.12) − c 2 n/l ≤ − c 2 n/ (9 m 2 − 3 m ) ≤ − c 2 n/ 9 m 2 = − c 0 2 n/m 2 . 10 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU 4. Other Block Ma trices 4.1. Circular matrices. The ab o v e consideration can b e applied to (truncated) circulan t blo ck matrices of the form (4.1) Φ = Φ k Φ k − 1 . . . Φ 2 Φ 1 Φ 1 Φ k . . . Φ 3 Φ 2 . . . . . . . . . . . . . . . Φ l − 1 Φ l − 2 . . . . . . Φ l ∈ R n × N , where the blo cks Φ i are all I ID matrices. Similar to (2.1), the circulan t matrices in (4.1) also re presen t the sys- tem equation matrices in multic hannel sampling, but the conv olution is a circular one. They usually arise in applications where con v olutions are implemen ted by multiplications in F ourier domain. Before we present the theorem for this type of matrices, w e first commen t on the maximum n umber of sto chastically dep enden t rows in a (truncated) circulant matrix of the form A = a q a q − 1 . . . a 2 a 1 a 1 a q . . . a 3 a 2 . . . . . . . . . . . . . . . a p − 1 a p − 2 . . . . . . a p ∈ R p × q . (4.2) Again, we denote by A T ,i the i -th row of the matrix A T , which is obtained b y retaining only those columns of A corresp onding to T ⊂ { 1 , 2 , . . . , N } . Lemma 4.1. Define the sets D T ,i by D T ,i = { j ∈ { 1 , 2 , . . . , p } : A T ,j is sto chastic al ly dep endent on A T ,i , j 6 = i } . Then D T ,i has c ar- dinality at most | T | ( | T | − 1) . Pr o of. Note first, that an upp er b ound for the case p = q clearly upp er b ounds the case where p < q . W e may therefore assume that p = q and A is a square circulant matrix. Then the num b er of rows sto c hastically dep enden t on A T ,i is indep enden t of i and we can, w.l.o.g., assume that i = 1. Let t ∈ { 0 , 1 } q b e a q -tuple defined b y t j = 0 if j 6∈ T 1 if j ∈ T , j=1,. . . ,q , and consider the matrix (4.3) ˜ A = t σ ( t ) . . . σ q − 1 ( t ) ∈ R q × q , TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 11 where σ : { 0 , 1 } q → { 0 , 1 } q defines the righ t-shift ( t 1 , . . . , t q − 1 , t q ) → ( t q , t 1 , . . . , t q − 1 ). Denote by ˜ A T the matrix obtained by retaining only those columns of ˜ A corresp onding to T ⊂ { 1 , 2 , . . . , q } . It is now easy to see that | D T ,i | = |{ ˜ A T ,i , i ∈ { 2 , . . . , q } : h ( ˜ A T , 1 , ˜ A T ,i ) < | T |}| ≤ { # of ones in t } · ( { # of ones in t } − 1) = | T | ( | T | − 1) , where h : { 0 , 1 } q × { 0 , 1 } q → N is the Hamming distance defined by h ( x, y ) = |{ j ∈ { 1 , 2 , . . . , q } : x j 6 = y j }| . The follo wing theorem gives low er b ounds for the probability that a circulan t blo ck matrix as in 4.2 satisfies the RIP of order 3 m . Note that the b ounds obtained are the same as in 2.1 although the n umber of indep endent en tries in Φ is greater than b efore. This is due to the nature of the pro of using the n um b er of sto chastically dep endent rows of Φ which is the same for b oth T o eplitz and circulan t matrices. Theorem 4.1. L et Φ b e as in (4.1). Then ther e exist c onstants c 1 , c 2 > 0 dep ending only on δ 3 m ∈ (0 , 1) , such that: (i) If l ≤ 3 m (3 m − 1) , then for any n ≥ c 1 l m ln( N /m ) , Φ satisfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/l . (ii) If l > 3 m (3 m − 1) , then for any n ≥ c 1 m 3 ln( N /m ) , Φ satisfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/m 2 . Pr o of. A similar argumen t as the one in the pro of of Lemma 3.1 shows that the upp er b ound for the maxim um n umber of rows sto chastically dep enden t on any row of a (truncated) circulant blo c k matrix is the same as for the (truncated) T o eplitz blo ck matrices (use Lemma 4.1). Then the pro of of Theorem 2.1 directly applies to the setting at hand. 4.2. Circulan t-circulant Matrices. W e also consider matrices that are (truncated) circulant blo ck matrices whose blo cks are themselv es 12 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU circulan t: Φ = Φ k Φ k − 1 . . . Φ 2 Φ 1 Φ 1 Φ k . . . Φ 3 Φ 2 . . . . . . . . . . . . . . . Φ l − 1 Φ l − 2 . . . . . . Φ l ∈ R n × N , (4.4) Φ i = ϕ i p ϕ i p − 1 . . . ϕ i 2 ϕ i 1 ϕ i 1 ϕ i p . . . ϕ i 3 ϕ i 2 . . . . . . . . . . . . . . . ϕ i q − 1 ϕ i q − 2 . . . . . . ϕ i q ∈ R q × p . (4.5) Denote b y τ : { 0 , 1 } kp → { 0 , 1 } kp the righ t-shift of blo cks Φ i and b y σ : { 0 , 1 } kp → { 0 , 1 } kp the righ t-shift of elements inside a blo ck Φ i , b oth by one p osition. These matrices arise in tw o-dimen tional imaging applications where the indep endent elements are the co efficients of the p oin t spread function of the imaging system. Replacing (4.3) in the pro of of Lemma 4.1 by ¯ A = t σ 1 τ 0 ( t ) . . . σ ( i − 1)(mod p ) τ b i − 1 p c ( t ) . . . σ p − 1 τ l − 1 ( t ) ∈ R lq × k p , readily yields the upp er b ound | T | ( | T | − 1) for the num b er of rows sto c hastically dependent on any one ro w of Φ. Applying Lemma 3.3 and Theorem 4.1 shows that the probability for p erfect reconstruction is no less than 1 − e − c 2 n/m 2 . This sa ys that imaging systems with I ID random p oin t spread functions can significantly reduce the num b er of acquired samples, while still b eing able to reconstruct the original sparse image if the ab o ve conditions hold. 4.3. Circulan t-circulant Blo c k Matrices. As a generalization of the matrices defined b y (4.4) and (4.5), the follo wing matrices are also TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 13 considered: Φ = Φ k 1 Φ k 1 − 1 . . . Φ 2 Φ 1 Φ 1 Φ k 1 . . . Φ 3 Φ 2 . . . . . . . . . . . . . . . Φ l 1 − 1 Φ l 1 − 2 . . . . . . Φ l 1 ∈ R n × N , (4.6) Φ i = Υ k 2 Υ k 2 − 1 . . . Υ 2 Υ 1 Υ 1 Υ k 2 . . . Υ 3 Υ 2 . . . . . . . . . . . . . . . Υ l 2 − 1 Υ l 2 − 2 . . . . . . Υ l 2 , where the blo cks Υ j are all I ID matrices. These matrices arise in mul- tic hannel t wo-dimensional imaging applications where the num b er of ro ws in Υ j corresp onds to the n/ ( l 1 l 2 ) indep endent channels. W e show next that these matrices are also go o d compressed sensing matrices. Corollary 4.1. L et Φ b e as in (4.6). Then ther e exist c onstants c 1 , c 2 > 0 dep ending only on δ 3 m ∈ (0 , 1) , such that: (i) If l 1 l 2 ≤ 3 m (3 m − 1) , then for any n ≥ c 1 l 1 l 2 m ln( N /m ) , Φ satisfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/l 1 l 2 . (ii) If l 1 l 2 > 3 m (3 m − 1) , then for any n ≥ c 1 m 3 ln( N /m ) , Φ sat- isfies RIP of or der 3 m for every δ 3 m ∈ (0 , 1) with pr ob ability at le ast 1 − e − c 2 n/m 2 . This follo ws directly from Lemma 4.1 and Theorem 4.1. 4.4. Deterministic Construction. The CS matrices we ha ve consid- ered so far are based on randomized constructions. Ho w ev er, in certain applications, deterministic constructions are preferred. In [10] DeV ore pro vided a deterministic construction of CS matrices using polynomials o ver finite fields. W e will consider deterministic blo ck matrices based on DeV ore’s construction. Let us first recall the construction in [10]. Consider the set Z p × Z p , where Z p denotes the field of integers mo dulo p , p a prime. This set has n := p 2 elemen ts. Define P r := { f ∈ Z p [ x ] : deg( f ) ≤ r } , 0 < r < p . This set has N := p r +1 elemen ts. F or ev ery f ∈ P r , define the graph of f by G ( f ) = { ( x, y ) ∈ Z p × Z p : y = f ( x ) , x ∈ Z p } ⊂ Z p × Z p 14 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU and consider the column vector v ( f ) ∈ { 0 , 1 } n , indexed b y the elements of Z p × Z p ordered lexicographically , giv en b y v ( f ) := ( 1 (0 , 0) ∈G ( f ) , . . . , 1 (0 ,p − 1) ∈G ( f ) , 1 (1 , 0) ∈G ( f ) , . . . , 1 ( p − 1 ,p − 1) ∈G ( f ) ) t , where 1 ( a,b ) ∈G ( f ) = 1 if ( a, b ) ∈ G ( f ) 0 if ( a, b ) 6∈ G ( f ) Construct the matrix Φ 0 = ( v ( f 1 ) , v ( f 2 ) , . . . , v ( f N )), where the p oly- nomials f i are ordered lexicographically with resp ect to their co effi- cien ts. It was sho wn in [10], that the matrix Φ = 1 √ p Φ 0 satisfies RIP for an y m < p/r + 1 with δ = ( m − 1) r/p ( < 1). No w consider (4.7) Ψ 0 = Ψ t Ψ t − 1 . . . Ψ 2 Ψ 1 Ψ t +1 Ψ t . . . Ψ 3 Ψ 2 . . . . . . . . . . . . . . . Ψ t + s − 1 Ψ t + s − 2 . . . . . . Ψ s ∈ R sp 2 × tl , where tl ≤ p r +1 , and eac h blo ck Ψ ∈ R p 2 × l is constructed from the first tl v ectors v ( f ) , f ∈ P r , as ab ov e. Theorem 4.2. The matrix Ψ = 1 √ sp Ψ 0 satisfies RIP with δ = ( m − 1) r /p for any m < p/r + 1 . Pr o of. As b efore, w e only ha v e to consider the case where | T | = m . Let T ⊂ { 1 , 2 , . . . , tl } such that | T | = m , and let Ψ T b e the matrix obtained by retaining only those columns of Ψ corresp onding to the el- emen ts in T . Consider the matrix G T = Ψ t T Ψ T . Since every column of Ψ 0 has exactly sp ones, the diagonal elemen ts of G T are all one. An off diagonal elemen t of G T has the form g T ij = P s x =1 h v x,i , v x,j i , where i, j ∈ { 1 , 2 , . . . , m } , and v x,i denotes the v ector (Ψ T , ( x − 1) n +1 ,i , . . . , Ψ T , ( x − 1) n + n,i ) t ∈ { 0 , 1 } n that represents some p olynomial f ∈ P r . Since the graphs of t wo different p olynomials in P r ha ve at most r elements in common, g T ij ≤ sr /sp = r /p for an y i 6 = j . Therefore, the sum of all off diagonal elemen ts in an y ro w or column of G T is ≤ ( m − 1) r /p = δ < 1 whenev er m < p/r + 1. W e can, therefore, write (4.8) G T = I + B T , where k B T k 1 ≤ δ and k B T k ∞ ≤ δ . Since k B T k 2 2 ≤ k B T k 1 k B T k ∞ , we ha ve that k B T k 2 ≤ δ and so the sp ectral norms of B T and B − 1 T are ≤ 1 + δ and ≤ (1 − δ ) − 1 , resp ectiv ely . This shows that Ψ satisfies (1.4). TOEPLITZ BLOCK MA TRICES IN COMPRESSED SENSING 15 Figure 1. Empirical probabilit y of success plotted against the num b er of observ ations for I ID, T o eplitz blo c k, and T o eplitz matrices. 5. Numerical Resul ts T o v alidate that the probability of exact recov ery for T o eplitz block CS matrices is high, the p erformance of T o eplitz blo ck, I ID, and T o eplitz CS matrices is compared empirically . In our simulation, a length n = 2048 signal with randomly placed m = 20 non-zero entries drawn in- dep enden tly from the Gaussian distribution w as generated. Eac h such generated signal is sampled using n × N I ID, T o eplitz and T o eplitz blo c k matrices with entries drawn indep endently from the Bernoulli distribution and reconstructed using the log barrier solv er from [11]. The exp erimen t is declared a success if the signal is exactly recov ered, i.e., the error is within the range of machine precision. The empirical probabilit y of success is determined by rep eating the reconstruction exp erimen t 1000 times and calculating the fraction of success. This empirical probability of success is plotted as a function of the n umber of measurement samples n in Fig. 1. The simulation results show, that in the v ast ma jorit y of applications all T o eplitz blo c k matrices p erform similar to I ID matrices. 16 FLORIAN SEBER T, LESLIE YING, AND YI MING ZOU A cknowledgment The third author w ould lik e to ackno wledge the supp ort from IMA for his participation in the short course “Compressive Sampling and F rontiers in Signal Pro cessing”. References [1] E. Cand ` es, J. Romberg, and T. T ao, ”Robust uncertain t y principles: Exact sinal reconstruction from highly incomplete frequency information”, IEEE T r ans. Inf. The ory 52 , no. 2, pp. 489-509, 2006. [2] D. Donoho, ”Compressed Sensing”, IEEE T r ans. Information The ory 52 , no. 4, pp. 1289-1306, 2006. [3] E. Cand` es and T. T ao, ”Decoding by linear programming”, IEEE T r ans. Inf. The ory 51 , no. 12, pp. 4203-4215, 2005. [4] A. Cohen, W. Dahmen, and R. DeV ore, ”Compressed sensing and b est k-term appro ximation”, (2006), Preprin t. [5] R. Baraniuk, M. Dav enp ort, R. DeV ore, and M. W akin, ”A Simple Pro of of the Restricted Isometry Prop ert y for Random Matrices”, (2007), Preprin t. [6] W. Ba jw a, J. Haupt, G. Raz, S. W right, and R. Now ak, ”T o eplitz-Structured Compressed Sensing Matrices”, IEEE SSP Workshop , pp. 294-298, 2007. [7] D. Ac hlioptas, ”Database-friendly Random Pro jections”, Pr o c. ACM SIGMOD- SIGA CT-SIGAR T Symp. on Principles of Datab ase Systems , pp. 274-281, 2001. [8] Y. Do dge, F. Marriott, Int. Statistical Institute, ”The Oxford dictionary of statistical terms”, 6th ed, Oxfor d University Pr ess , p. 47, 2003. [9] J.A. T ropp, ”Random Filters for Compressive Sampling”, Pr o c e e dings of 40th A nnual Confer enc e on Information Scienc es and Systems , pp. 216 - 217, 22-24 Marc h 2006. [10] R. DeV ore, ”Deterministic Constructions of Compressed Sensing Matrices”, (2007), Preprin t. [11] E. Cand´ es, http://www.acm.c alte ch.e du/l1magic/ .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment