An integral formula for large random rectangular matrices and its application to analysis of linear vector channels
A statistical mechanical framework for analyzing random linear vector channels is presented in a large system limit. The framework is based on the assumptions that the left and right singular value bases of the rectangular channel matrix $\bH$ are ge…
Authors: Yoshiyuki Kabashima
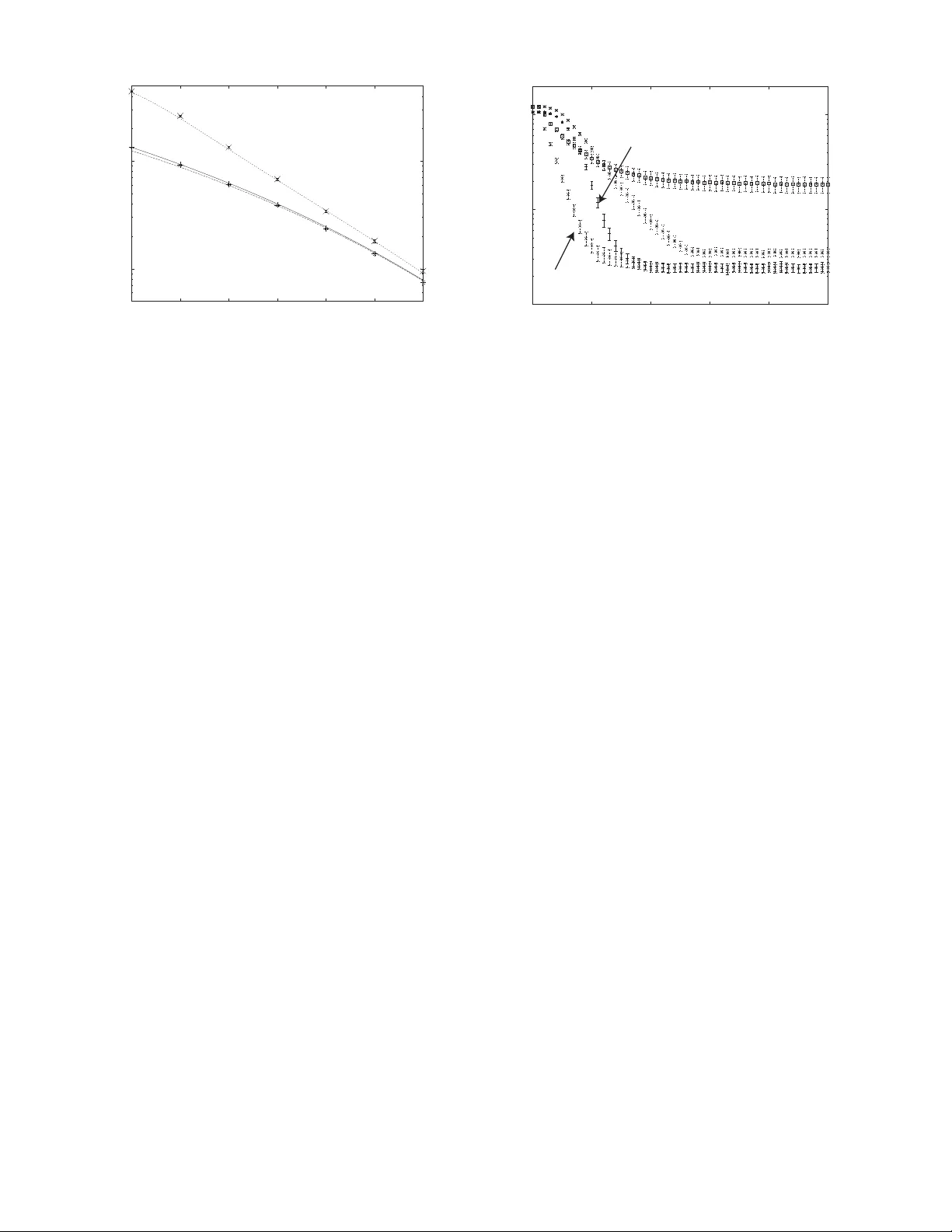
An inte gral formula for lar ge random recta ng ular matric es and its application to analysis of linear v ector channels Y oshiyuki Kabash ima Departmen t of Co mputation al Intelligenc e and Systems Science T okyo Institute of T echn ology , Y okohama 22 6–850 2, Japan Email: k aba@dis.titech.ac.jp Abstract —A statistical mechanical framew ork for analyzing random linear ve ctor channels is presented in a lar ge system limit. Th e framework is based on th e assumptions t hat the l eft and right singular value bases of the rectangular channel matrix H are generated indep endently from un ifo rm distributions over Haar measures and the eigen values of H T H asymptotically fo ll ow a certain specific distribution. Th ese assump tions make it possible to characterize the communication perfo rmance of the channel utilizing a n in tegral f ormula with r espect to H , which is analogous to the one introduced by Marinari et. al. in J. P hys. A 27, 7647 (1994) fo r large rand om square (symmetric) matrices. A computationally feasible algorithm for approximately decoding recei ved signals b ased on the integral fo rmula is also prov id ed. I . I N T RO D U C T I O N In a genera l s cen ario for linear vector channels, multiple messages ar e tran smitted to the receiver , being linearly trans- formed to multip le output signals by a r andom matrix and degraded by channel n oises. Th is yields a complicated depe n- dence on message variables, which en sures that the prob lem of inferrin g the tra nsmitted messages from the received outpu t signals is non -trivial. In general, inf erence pro blems of this kind can be m apped to vir tual magnetic systems governed by random interaction s [1]. This similarity has promoted a sequence o f statistical mechanical analy ses of linear vector channels in a large system lim it from the beginning of this century [2], [3], [4], [5], [ 6], [7], [8]. In the simplest ana lysis, each e ntry o f the channel matrix is regarde d as an in depend ent an d identica lly distributed (IID) random variable. Howe ver , suc h a tre atment is not nec essar - ily ad equate for de scribing r ealistic systems, in which non - negligible statistical correlations acro ss th e matrix entries are created by spatial/time pro ximity of messages/antennas o r ma - trix design for enhancem ent of co mmunica tion per forman ce. Therefo re, the dev elo pment o f methodolo gies th at can deal with correla tions in the chan nel m atrix is o f great impo rtance to research in th e area o f line ar vector channels. It is intended that the present article s h ould contribute such a methodo logy for applicatio n to these commu nication channels. More precisely , we develop a statistical mechanical fram ew ork for analyzing linea r vector channels so th at the in fluence o f the corr elations across the matrix e ntries can be taken into account. Th e developed fr amew or k is applicab le not only to Gaussian ch annels of Gaussian inpu ts [9], but also general memory -less channels of continuo us/discrete inputs, which are characterized b y a factorizab le prior distribution. This article is organized a s follows: In the next section , the model of linear vector chann els that we fo cus on here in is defined. In section III, which is the main part of th e current article, an inte gr al formu la with respect to large rando m rectangu lar matrices is introdu ced. A scheme to assess the p er- forman ce of the linear vector channel an d a computationally feasible appro ximate deco ding alg orithm are developed on the basis of this for mula. The utility of th e developed schem es is examined in sectio n I V by application to an example system. The final section sum marizes th e pr esent stud y’ s finding s. I I . M O D E L D E FI N I T I O N For simplicity , we here assume that all the variables rele vant to the com municatio n are real; but extending th e following framework to complex variables is straightforward [ 10]. Let us suppose a line ar vector chann el in which an input m essage vector of K com ponents, x = ( x k ) , is linearly transformed to an M dimensional sequence, ∆ = (∆ µ ) , by a K × N channel matrix , H = ( H µk ) , as ∆ = H x . For gen erality and simplicity , we assume a g eneral memo ry-less ch annel, which implies that an N dimensio nal o utput signal vector, y = ( y µ ) , follows a certain factorizable con ditional distribution as P ( y | x ; H ) = P ( y | H x ) = N Y µ =1 P ( y µ | ∆ µ ) . (1) In a ddition, w e assume a factorizab le prior distribution P ( x ) = K Y k =1 P ( x k ) , (2) for x , wh ich ma y b e continuo us or discre te. An expr ession of the singular value decomp osition of H H = U D V T , (3) is th e basis of our f ramework. Here, the super script T de- notes the tran spose of the m atrix to which it is attach ed, D = diag ( d k ) is an N × K diagonal matrix compo sed of the singular values d k ( k = 1 , 2 , . . . , min( N , K ) ) , where min( N , K ) den otes the lesser value of N and K . The values d k are linked to th e eigenv alues of H T H , λ k , as λ k = d 2 k for k = 1 , 2 , . . . , min( N , K ) . U and V ar e orthogo nal matrices of o rder N × N and K × K , re spectiv ely . In order to han dle correlation s in H analytically , we assum e that U and V are independ ently gener ated fro m unif orm d istributions of the Haar measures o f N × N a nd K × K ortho gonal matr ices, respectively , a nd that the empir ical eigenv alue distribution o f H T H , K − 1 P K k =1 δ ( λ − λ k ) = (1 − min( N , K ) /K ) δ ( λ ) + K − 1 P K k =1 δ ( λ − d 2 k ) conv erges to a certain specific distri- bution ρ ( λ ) in the limit as N and K tend to in finity while keeping the load β = K / N ∼ O (1) . Con trolling ρ ( λ ) allows us to express various second -order correla tions in H . I I I . A N A L Y S I S A. An integr al formula for lar ge random r ectangu lar matrices W ith knowledge of H , the receiver decodes y in orde r to infer x , wh ich is perf ormed on the b asis of the Bayes formula P ( x | y ; H ) = Q N µ =1 P ( y µ | ∆ µ ) Q K k =1 P ( x k ) P ( y ; H ) . (4) Here, the probab ility P ( y ; H ) = T r x N Y µ =1 P ( y µ | ∆ µ ) K Y k =1 P ( x k ) , (5) expresses the margin al p robability with re spect to y , wher e T r x denotes su mmation or integration over the all possible states of x . Eq. (5) also serves a s the p artition func tion concern ing the m essage vector x in statistical mechanics. Let us examine statistical pro perties of Eq . (5) pr ior to analyzing Eq. (4). The expr ession P ( y ; H ) = T r u , x exp i u T H x N Y µ =1 b P ( y µ | u µ ) K Y k =1 P ( x k ) , (6) is useful fo r this purp ose, w here i = √ − 1 , u = ( u µ ) and b P ( y µ | u µ ) = (2 π ) − 1 R d ∆ µ exp ( − i u µ ∆ µ ) P ( y µ | ∆ µ ) de notes the Fourier transfor mation of likelihood P ( y µ | ∆ µ ) . W e su bsti- tute H in Eq. ( 6) by Eq. (3) and take an a verage with r espect to U and V . For this a ssessment, it is no tew or thy that fo r any fixed set of u and x , e u = U T u and e x = V T x behave as co ntinuou s random variables that satisfy strict constrain ts N − 1 | e u | 2 = N − 1 | u | 2 = T u and K − 1 | e x | 2 = K − 1 | x | 2 = T x . In th e limit N , K → ∞ keeping β = K/ N ∼ O (1 ) , which we will h ereafter a ssume if necessary , this yields an expre ssion 1 N ln exp ( i u T H x ) = F ( T x , T u ) , (7) where · · · den otes the average with respect to U and V , an d F ( ξ , η ) = Extr Λ ξ , Λ η − β 2 h ln(Λ ξ Λ η + λ ) i ρ − 1 − β 2 ln Λ ξ + β Λ ξ ξ 2 + Λ η η 2 − β 2 ln ξ − 1 2 ln η − 1 + β 2 , (8 ) where h· · ·i ρ denotes the average with respect to ρ ( λ ) , while Extr θ {· · ·} r epresents extremization with re spect to θ [11]. This formula is analogou s to the one known for en sembles of random squar e (symmetric) matrices [1 2], [13], [1 4], which is closely related to the R -tran sformation dev elo ped in fr ee probab ility th eory [15], [ 9], [16]. Se veral integral f ormulae for large rando m matrices related to Eq. (7) , but fo r d ifferent large system limits, are p resented in [ 17]. Eq. (7) implies 1 N ln T r y P ( y ; H ) = Extr T x ,T u { F ( T x , T u ) + β A x ( T x ) + A u ( T u ) } , (9) where A x ( T x ) = Extr b T x n b T x T x / 2 + ln T r x P ( x ) e − b T x x 2 / 2 o and A u ( T u ) = Extr b T u n b T u T u / 2 + ln T r y ,u b P ( y | u ) e − b T u u 2 / 2 o . The norm alization co nstraint T r y P ( y ; H ) = 1 , in con- junction with the extrem ization in Eq . (9), yield s T x = T r x x 2 P ( x ) , b T x = 0 , T u = 0 an d b T u = β h λ i ρ T x . The physical implication of these results is tha t compon ents o f ∆ = H x behave as IID Gau ssian variables of zero m ean and variance b T u in the large system limit when x is drawn fro m Eq. (2), while U and V are independen tly gener ated f rom the Haar m easures. B. P erformance assessment Now , we are read y to analy ze th e typical com munication perfor mance of the cu rrent ch annel mo del. This is perfo rmed by assessing the typ ical mutual in formatio n (per outpu t signal) between x an d y , I ( X, Y ) , based on Eqs. (4) and (5) a s I ( X, Y ) = 1 N T r y , x P ( y | x ; H ) P ( x ) ln P ( y | x ; H ) P ( y ; H ) = F + T r y Z D z P y | q b T u z ln P y | q b T u z , (10) where F = − 1 N T r y P ( y ; H ) ln P ( y ; H ) , (11) represents the cond itional entropy of y , and serves as the av- erage free energy with respect to x . D z = (2 π ) − 1 / 2 dz e − z 2 / 2 denotes the Gaussian measure. The statistical pro perties o f ∆ ev aluated in the la st parag raph are emp loyed to assess the second term on the right-h and side of the last line of Eq. (1 0). F can be e valuated by means of the r eplica method. Namely , we ev alua te the n -th mom ent of th e par tition function P ( y ; H ) for n ∈ N as T r y P n +1 ( y ; H ) = T r y , { x a } , { u a } exp i n X a =1 ( u a ) T H x a ! × n +1 Y a =1 N Y µ =1 b P ( y µ | u a µ ) × n +1 Y a =1 K Y k =1 P ( x a k ) , (12) and assess F as F = − lim n → 0 ∂ ∂ n 1 N ln T r y P n +1 ( y ; H ) , (13) analytically continuin g expressions obtained for Eq. (1 2) from n ∈ N to n ∈ R . Here, { x a } denotes a set of n + 1 replicated vectors x 0 , x 1 , · · · , x n , with { u a } defined similar ly . Eq. (13) is gene rally expressed using F ( ξ , η ) , an d the deriv ation of the expression can b e foun d in [11]. In particu lar , the expression obtaine d under the re plica symme tric ansatz, which is belie ved to be correct for th e curr ent case since the inference is perfo rmed o n th e basis of the cor rect p osterior (4) [18], is giv en in a co mpact form as F = − Extr q x ,q u {A xu ( q x , q u ) + β A x ( q x ) + A u ( q u ) } , (14) where A xu ( q x , q u ) = F ( T x − q x , q u ) + b T u q u 2 , (15) A x ( q x ) = E xtr b q x − b q x q x 2 + Z D z P ( z ; b q x ) ln P ( z ; b q x ) , (16) and A u ( q u ) = E xtr b q u − b q u q u 2 + T r y Z D z P ( y | z ; b q u ) ln P ( y | z ; b q u ) , (17) in which P ( z ; b q x ) = T r x P ( x ) e − b q x x 2 / 2+ √ b q x z x and P ( y | z ; b q u ) = R D sP y | q b T u − b q u s + p b q u z . The q x and q u determined by Eq . (14) repre sent K − 1 | h x i | 2 and − N − 1 | h u i | 2 , r espectiv ely , where h· · ·i denotes averaging over the posterior d istribution (4) while [ · · · ] indic ates th e av era ge with r espect to y , U and V . These av erag es, h· · ·i and [ · · · ] , corr espond to the therm al and qu enched averages in statistical mech anics, respectively . The quantities b q x and b q u appearin g in Eqs. (16) an d (17) can be used f or a ssessing perfor mance mea sures other th an Eq. (10), such as the mean square error ( MSE) an d th e bit err or rate (BER). C. Compu tationally feasible appr oxima te decodin g Let us su ppose a situation which requires ev alua tion of the posterior average m x = T r x x P ( x | y ; H ) , (18) where m x = ( m xk ) , with similar notatio n used fo r other vectors below . Eq. (18) serves as the estimator that min imizes the MSE in gen eral, and can be used to m inimize the BER for binary messages. Ex act assessment o f such averages is, howe ver, comp utationally difficult for large system s, which motiv ates us to develop compu tationally feasible appro xima- tion algorithms [19], [3], [20]. A generalized Gibbs free energy e Φ( m x , m u ; l ) = Extr h x , h u { h x · m x + h u · m u − ln ( Z ( h x , h u ; l )) o , (19) where Z ( h x , h u ; l ) = T r x , u Q N µ =1 b P ( y µ | u µ ) × Q K k =1 P ( x k ) × exp h x · x + h u · (i u ) + (i u ) T ( l H ) x , offers a useful basis for this pur pose since Eq . (18) is characterized as the unique saddle p oint o f E q. ( 19) for l = 1 [2 1], [2 2]. MPforP erceptron { Perform Initialization ; Iterate H-Step and V -S tep alternately sufficient times; } Initialization { χ x ← 1 K K X k =1 x 2 k P ( x k ); b χ x ← 0; Λ x ← 1 χ x − b χ x ; m xk ← T r x k x k P ( x k ) ( k = 1 , 2 , . . . , K ); h u ← H m x ; m u ← 0 ; } H-Step { Search ( χ u , Λ u ) for given ( χ x , Λ x ) to satisfy conditions χ x = fi Λ u Λ x Λ u + λ fl ρ and χ u = 1 − β Λ u + fi β Λ x Λ x Λ u + λ fl ρ ; b χ u ← 1 χ u − Λ u ; h u ← h u − b χ u m u ; m uµ ← ∂ ∂ h uµ ln „ Z Dx P ( y µ | p b χ u x + h uµ ) « ( µ = 1 , 2 , . . . , N ); h x ← H T m u ; χ u ← − 1 N N X µ =1 ∂ 2 ∂ h 2 uµ ln „ Z DsP ( y µ | p b χ u s + h uµ ) « ; Λ u ← 1 χ u − b χ u ; } V -Step { Search ( χ x , Λ x ) for given ( χ u , Λ u ) to satisfy conditions χ x = fi Λ u Λ x Λ u + λ fl ρ and χ u = 1 − β Λ u + fi β Λ x Λ x Λ u + λ fl ρ ; b χ w ← 1 χ x − Λ x ; h x ← h x + b χ x m x ; m xk ← ∂ ∂ h xk ln “ T r x P ( x ) e − 1 2 b χ x x 2 + h xk x ” ( k = 1 , 2 , . . . , K ); h u ← H m x ; χ x ← 1 K K X k =1 ∂ 2 ∂ h 2 xk ln “ T r x P ( x ) e − 1 2 b χ x x 2 + h xk x ” ; Λ x ← 1 χ x − b χ x ; } Fig. 1. Pseudocode of the m essage-passi ng algori thm M Pfor Perceptr on [23]. T he symbols “;” and “ ← ” represent the end of a command line and the operation of substitut ion, respecti ve ly . The quanti ties Λ x and Λ u are the counter parts of Λ ξ and Λ η in Eq. (8) for ξ = χ x and η = χ u , respecti vely . Unfortu nately , the ev aluation of Eq. (19) is also com puta- tionally difficult. One approa ch to overcoming this difficulty is to perform a T ay lor expansion aroun d l = 0 , for which e Φ( m x , m u ; l ) can be analytically calculated as an excep tional case, and su bstitute l = 1 in th e expression obtained [ 21]. Howe ver , the ev alu ation of h igher-order terms, which are not negligible in general, requ ires a comp licated calculation in this expansion, which sometimes prevents the sch eme f rom being practically feasible. In or der to av oid such d ifficulty , we take an a lternative appr oach here, which is inspired by a deri vativ e of E q. ( 19), ∂ e Φ( m x , m u ; l ) ∂ l = − (i u ) T H x l , (20) following a st r ategy proposed by Opper and W inthe r [22]. Here, h· · ·i l represents the a verage with r espect to the generalized weight Q N µ =1 b P ( y µ | u µ ) × Q K k =1 P ( x k ) × exp h x · x + h u · (i u ) + (i u ) T ( l H ) x , in which h x and h u are deter mined so as to satisfy h x i l = m x and h (i u ) i l = m u , respectively . The right-hand side of this equation is an average of a qua dratic f orm compo sed of many rand om v ariab les. The cen tral limit theore m implies that such an average does not d epend on the details of the o bjective distribution, but is determined only by the values of the fi rst and second moments. In order to construct a simple approx imation scheme, let us assume th at the seco nd mo ments are c haracterized mac roscop- ically by | x | 2 l − | h x i l | 2 = K χ x and | u | 2 l − | h u i l | 2 = N χ u . Evaluating the right-han d side o f Eq. (2 0) u sing a Gaussian d istribution, the first and second m oments of which are co nstrained to be identical to those of the gener alized weight, and integrating from l = 0 to l = 1 , we have e Φ( χ x , χ u , m x , m u ; 1) − e Φ( χ x , χ u , m x , m u ; 0) ≃ − m T u H m x − N F ( χ x , χ u ) , (21) where the f unction F ( ξ , η ) is provided as in Eq. (8) by the empir ical eigenv alue spectrum of H T H , ρ ( λ ) = K − 1 P K k =1 δ ( λ − λ k ) and the macrosco pic secon d m oments χ x and χ u are included in argum ents of the Gibbs free energy b ecause the rig ht-hand side of Eq. (2 0) depen ds o n these mo ments. Eq. ( 21) offers a comp utationally feasible approx imation o f Eq. (1 9) for l = 1 , since assessment of e Φ( χ x , χ u , m x , m u ; 0) , in which o ne can perfor m summa- tions with respect to relevant variables independ ently , can be achieved at a reason able com putational cost. Although evaluation of E q. ( 21) is comp utationally feasible, searching f or saddle p oints o f this fu nction within a practica l time is still a non -trivial p roblem. In Fig. 1, we presen t a message-passing type algor ithm, which was recently prop osed for a classification prob lem of single lay er percep trons [23], as a p romising heuristic solu tion for this pro blem. The efficacy of this method u nder appro priate cond itions was experime ntally confirmed fo r th e per ceptron pr oblem, and to the extent to which it has been a pplied to se veral ensembles of lin ear vector ch annels, this algo rithm has also b een shown to exhibit a reasonable perfo rmance for the current inferen ce task as well. Howe ver , its prop erties in cluding convergence condition s h av e n ot y et been fu lly clarified , and, th erefore further in vestigation is ne cessary f or the theoretical validation and improvement of the pe rforman ce of th is m ethod. I V . E X A M P L E : W E L C H B O U N D E Q U A L I T Y S E Q U E N C E S In ord er to demo nstrate the utility of the proposed appro ach, let us app ly th e curren t meth odolog ies to the analy sis of the m atrix e nsemble that is ch aracterized by ρ ( λ ) = (1 − β − 1 ) δ ( λ ) + β − 1 δ ( λ − β ) u nder the assumption β > 1 , which correspo nds to the case o f W elch bound equality sequen ces (WBES) [24]. W e fo cus o n the case of th e Gaussian chan nel P ( y | ∆) = (2 π σ 2 ) − 1 / 2 exp − ( y − ∆) 2 / (2 σ 2 ) and binary inputs x ∈ { +1 , − 1 } K , since this constitutes a simple, yet non-tr i v ial prob lem. Under these assumptions, the developed framework has a highe r cap ability than is requ ired f or the assessment of the ty pical co mmunica tion perfor mance with respect to the matrix ensemble, which can be carried out by a simpler method dev elo ped by the author an d his colleagues [25], [1 0], as was recen tly shown by Kitagawa and T an aka [26]. Nevertheless, the framework is still useful as one can derive a compu tationally f easible appr oximate d ecoding algo- rithm of good c on vergence pr operties ba sed on the pro cedure shown in Fig . 1. For Gaussian channels, Λ u in Fig. 1 can be fixed as Λ u = σ 2 in g eneral. This yie lds an algo rithm m t +1 u = 1 σ 2 + b χ t u y − H m t x + b χ t u m t u , (22) m t +1 xk = tanh N X µ =1 H µk m t +1 uµ + b χ t +1 x m t xk ! (23) ( k = 1 , 2 , . . . , K ) , for WBES, where t den otes the numbe r of iterations. b χ t u in Eq. (22) is pr ovided as b χ t u = β / Λ t x , where Λ t x is determin ed so as to satisfy χ t x = (1 − β − 1 ) / Λ t x + β − 1 σ 2 / ( σ 2 Λ t x + β ) fo r giv en χ t x = 1 − K − 1 | m t x | 2 . Utilizin g the identical Λ t x , b χ t +1 x in Eq . (2 3) is evaluated as b χ t +1 x = 1 / χ t x − Λ t x . Fig. 2 compares th e BER for the theoretical a ssessment by the replica method with the experime ntal ev aluation obtained by the algorith m of Eq s. (22) and (23). In the exper iments, the estimates of the bin ary messages are comp uted as b x k = sign( m xk ) fo r k = 1 , 2 , . . . , K , where sign( a ) = a/ | a | fo r a 6 = 0 . This deco ding scheme is optimal f or minim izing BER if m x represents the correct p osterior av era ge (1 8) [27]. The excellent ag reement between the curves and markers in this plot vali d ates both the perform ance assessment based on the replica meth od and that based on the developed algorithm. A characteristic feature of Eqs. (2 2) and (2 3) is the inclusion of macroscop ic variables b χ t u and b χ t +1 x , which are expecte d to act to cancel the self-reactions from previous states. [28]. Fig. 3 plots the influ ence of this operation , ind icating that the can cellation acts to maintain the q uality o f the c on verged solution u p to larger β un der a con dition of fixed SNR. V . S U M M A RY In summa ry , we h av e developed a framework to analyze linear vector ch annels in a large system limit. The frame- work is based on the assump tions that the left an d right singular value b ases of the channel matrix can b e regard ed as indepe ndently drawn fro m Haa r measures over or thogon al (unitary , if the n umber field is define d over the complex variables) groups, and that the e igenv alues of the cross cor re- lation matrix of the channel matrix asy mptotically appro ach 0.001 0.01 4 4.5 5 5.5 6 6.5 7 SNR[dB] P b Fig. 2. BER vs. signal-to-no ise ratio (SNR) for binary inputs for the case β = 1 . 1 . The SNR plotted on the horizontal axis is giv en by − 10 log 10 (2 σ 2 ) while the vertica l axis denotes the BER. The curves indicat e theoreti cal predict ions, which correspond to the s calar Gaussian channe l, WBES and the basic matrix ensemble (BASIC ) from the bottom. Sample matric es of B ASIC are composed of IID entries of zero mean and 1 / N va riance Gaussian random varia bles. V alues for WBES and B ASIC are assessed by the replica method. The m arke rs indica te expe rimental estimate s of the BER obtain ed from 500 sample s ystems with K = 2048 and N = 1862 on the basis of the algorithm shown in Fig. 1. Excelle nt agreeme nt betwee n the curves and marker s vali dates both the performance analysis based on the replica method and that of the dev eloped appro ximation algorithm. a certain specific distribution in the limit of large matrix size. These m odeling assumptio ns allow a characterizatio n of the system in terms of an in tegral formula in two variables, which is fully d etermined by the eige n value distrib utio n. Upon applying this form ula in conjunction with the replica method , we h av e deriv ed a general expression fo r the typical mu tual informa tion of general memory -less channels with factorizable priors of con tinuous/discrete inp uts. W e hav e fu rther proposed a co mputation ally feasible decodin g algorithm based on the formu la, an d have fo und that numer ical results obtained fro m this algor ithm ar e in excellent agreemen t with the theoretical prediction s ev aluated b y th e replica method. Future research d irections include the application of the developed fram ew ork to various mod els o f linear vector ch an- nels, and further imp rovement o f the co mputation ally feasible decodin g algorithm. A C K N O W L E D G M E N T S The auth or thank s Jean-Bernar d Z uber fo r useful discus- sions concer ning Eq. (8). Th is research was suppo rted in part by Gr ants-in-Aid M EXT/JSPS, Jap an, No s. 17340 116 and 18079 006. R E F E R E N C E S [1] H. Nishimori, Statistical Physics of Spin Glasses and Information Pr ocessing (Oxford: Oxford Uni versity Press), 2001. [2] T . T anaka , Euro phys. Lett. 54 , 540, 2001; IEEE T rans. on Infor . Theory 48 , 2888, 2002. [3] Y . Kabashima, J. Phys. A 36 , 11111, 2003. [4] R. R. M ¨ uller, IEEE T rans. on Signal Proc essing 51 2821, 2003. [5] A. L. Moustaka s IEEE T rans. on Infor . Theory 49 , 2545, 2003. [6] D. Guo and S. V erd ´ u IEEE T rans. on Infor . Theory 51 , 1983, 2005. 0.001 0.01 0.1 0 10 20 30 40 50 t P b β=1.6 β=1.6 (No SRC) β=1.5 β=1.5 (No SRC) Fig. 3. Influence of the cancellat ion of self-reac tions in the approximate decodin g for WBES. E xperiment ally assessed trajec tories are plotted for two approximat ion algorithms for the cases β = 1 . 5 and 1 . 6 , where SNR is fixed to 6.0. The horizontal axis represents the number of itera tions, while the vert ical axis denotes the BER. The data are obta ined from 100 e xperiments of K = 512 systems. The first algorithm used in these exp eriments is that presente d by Eqs. (22) and (23) while the second algorithm, the results of which are denote d by “No SRC” in the figure, is found by consideri ng v anishing valu es of the m acroscop ic v ariables b χ t u and b χ t +1 x in E qs. (22) and (23). For both algorit hms, initia l states in the experi ments were set as m xk = tanh( θ k /σ 2 ) , where, in contrast to Fig. 1, θ k = P N µ =1 H µk y µ ( k = 1 , 2 , . . . , K ) . F or β = 1 . 5 , both algorit hms con verge to almost identi cal solutions, although the con vergenc e of the first algorithm is slowe r . Howe ver , for β = 1 . 6 , the second algo rithm con verge s to solutions of significantly higher BER while solution s found by the first algorithm still exhibi t rela tiv ely lo w values of the BER. T his indicate s that the cance llation of the self-reac tion terms in the approx imation algorithm acts to maintain the quality of the con ver gent solut ions for larger va lues of β . [7] J. P . Neirotti and D. Saad, Europh ys. Lett. 71 , 866, 2005. [8] A. Montanari and D. Tse, arXiv: cs/0602028 , 2006. [9] A. M. T ulino and S. V erd ´ u, Random Matri x Theory and W irele ss Communicat ions (Hanov er , MA: No w Publishers), 2004. [10] K. T ak eda, A. Hatabu and Y . Kabashima, J . Phys. A 40 , 14085, 2007. [11] Y . Kabashima, J. Phys.: Conf. Ser . 95 , 012001, 2008. [12] E. Marina ri, G. Pari si and F . Ritort, J. Phys. A 27 , 7647, 1994. [13] G. Parisi and M. Potters, J. Phys. A 28 , 5267, 1995. [14] C. Itzykson and J . B. Z uber, J . Math. Phys. 21 , 411, 1980. [15] D. V . V oiculescu, K. J. Dyke m a and A. Nica, F ree R andom V ariables (Provid ence, R.I.: American Mathematic al S ociet y), 1992. [16] T . T anaka, J . P hys.: Conf. Ser . 95 , 012002, 2008. [17] P . Z inn-Justin and J. B. Zuber, J. Phys. A 36 , 3173, 2003. [18] H. Nishimori, Eur ophys. Lett. 57 , 302, 2002. [19] M. K. V aranasi and B. Aazha ng, IEE E T rans. on Commun. 38 , 509, 1990; ibid. . 39 , 725, 1991. [20] T . T anaka and M. Okada, IEE E T rans. on Infor . Theory 51 700, 2005. [21] T . Plefka, J. Phys. A 15 , 1971, 1982. [22] M. Opper and O. Win ther, Jo urnal of Machi ne Learning Resear ch 6 , 2177, 2005. [23] T . Shinzato and Y . Kabashi ma, arXi v:0712.4050, 2007. [24] L. R. W elch , IEE E T rans. on Infor . Theory . IT -20 , 397, 1974. [25] K. T ake da K, S. Uda and Y . Kabashima, Europ hys. Lett. 76 , 1193, 2006. [26] K. Kitagawa and T . T anaka , Proc. The 30th Symposium on Information Theory and Its A pplicat ion (SIT A2007) (in Japanese ), 799, 2007. [27] Y . Iba, J. Phys. A 32 , 3875, 1999. [28] D. J. Thouless, P . W . Anderson and R. G. Pal m er, Phil. Mag. 35 , 593, 1977.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment