Learning Balanced Mixtures of Discrete Distributions with Small Sample
We study the problem of partitioning a small sample of $n$ individuals from a mixture of $k$ product distributions over a Boolean cube $\{0, 1\}^K$ according to their distributions. Each distribution is described by a vector of allele frequencies in …
Authors: Shuheng Zhou
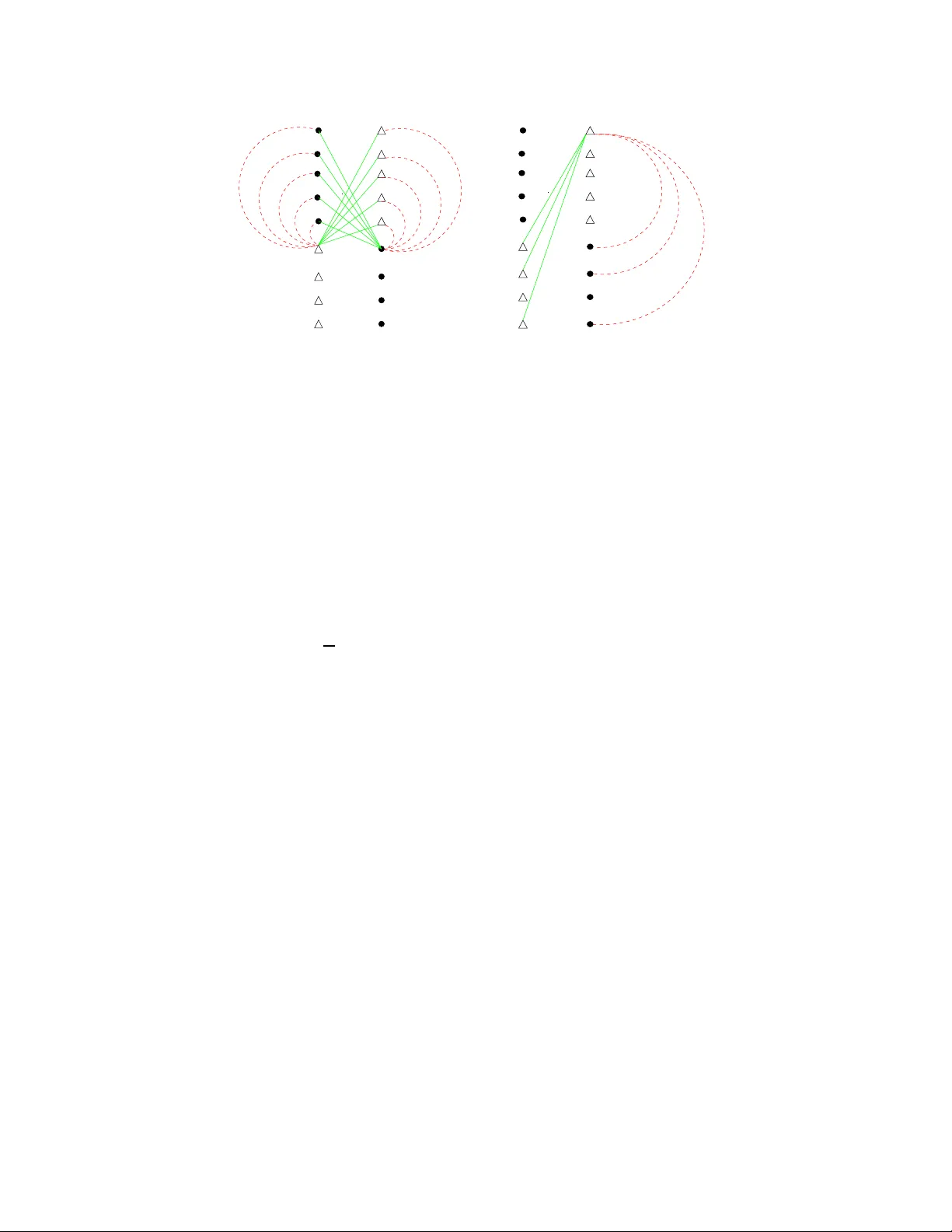
Learn ing Balanced Mixtur es of Discr ete Distrib utions with Small Sample Shuheng Zhou S Z H O U @ C S . C M U . E D U Computer Science Department Carne gie Mellon Univer sity Pittsbur gh, P A 15213, USA Abstract W e study the prob lem of partition ing a small sam ple of n individuals from a mixture of k pr oduct distri- butions over a Boolean cu be { 0 , 1 } K accordin g to their d ist ributions. Each distribution is described by a vector of allele fr equencies in R K . Giv e n two distributions, we use γ to d enote th e average ℓ 2 2 distance in frequen cies across K dimensions, which measures the statistical di vergence b etween th em. W e study the case assuming that bits are independe ntly distributed across K dimension s. This w o rk demonstrates that, for a balanced input instance for k = 2, a certain graph-b ased optimization function returns the correct partition with hig h pr obability , where a we ighted gra ph G is fo rmed over n in di vidu als, who s e pairwise h amming distances between their corr esponding bit vectors de fi ne the edge weights, so lo ng as K = ( ln n /γ ) and K n = ˜ ln n /γ 2 . The function co mputes a maxim um-weight b alanced cu t of G , where th e weig ht o f a cut is the sum of the we ights across a ll edges in the cut. This r esult demon st rates a nice prop erty in the high-d imensional feature space: one c an trade o f f the number of features that are required with the size of the sample to accomp lis h certain tasks like clustering. Keywords: Mix ture of Discrete Distributions, Graph-based Clustering, Max-Cut 1. In tr oduction W e explore a type of classificatio n problem t hat a rises in the conte xt of comp utatio nal biolog y . The prob lem is that we are giv en a small sample of size n , e.g., DN A of n in di viduals, each describ ed b y the v alues of K featur es or marke rs , e.g., SNPs (Single Nucleoti de Polymorphisms), where n ≪ K . Features hav e slight ly dif ferent frequenc ies dependin g on w h ich population the indi vidua l belongs to, and are assumed to be indepen dent of eac h other . Giv en the populatio n of origin of an indi vidual, the genotype (re presen ted as a bit vect or in this paper) can be reasonably assu med to be ge nerated by dra wing alleles independen tly from the appropri ate distrib ution . The objecti ve we consider is to minimize the number of features K , and thus tot al da ta size D = n K , to correctly classi fy the in di viduals in the s ample a ccord ing to the ir popu lation of origin, giv en an y n . W e des cribe K and n K as a fun ction of the “av erage qua lity” γ of the features. Through out the paper , we use p j i and x j i as short hands for p ( j ) i and x ( j ) i respec ti vely . W e first descri be a genera l mixture model that we use in this paper . The same model was previo usly used in Zhou (2006) and Blum et al. (2007). Statistic al Model: W e hav e k probability space s 1 , . . . , k ov er the set { 0 , 1 } K . Furthe r , the components ( featu r es ) of z ∈ t are independ ent and Pr t [ z i = 1 ] = p i t (1 ≤ t ≤ k , 1 ≤ i ≤ K ). Hence, the probabi lity spaces 1 , . . . , k comprise the distrib ution of the featur es for each of the k popu lation s. Moreo ve r , the input of the algorithm consists of a collection ( mixtur e ) of n = P k t = 1 N t unlabe led samples , N t points from t , and the algorithm is t o determine for e ach data point fr om which of 1 , . . . , k it was chosen. In general 1 we do not assume that N 1 , . . . , N t are rev ealed to the algorit hm; bu t we do require some bou nds on their relati ve sizes. A n important parameter of the pro babili ty ensemble 1 , . . . , k is th e measur e of d iver genc e γ = min 1 ≤ s < t ≤ k P K i = 1 ( p i s − p i t ) 2 K (1) between any two distrib utions . Note that √ K γ provide s a lower bound on the Euclidean distance between the means of an y two distri b ution s and represents their separatio n. Further , let N = n / k (so if the population s were balanced we woul d ha ve N of each type). This paper pro ves the follo w in g theorem which gi ves a su f ficient condit ion for a balan ced ( N 1 = N 2 ) inpu t instance when k = 2. Theor em 1 (Zho u, 2006, Chapter 9) A ss ume N 1 = N 2 = N . If K = ( ln N γ ) and K N = ( ln N lo g log N γ 2 ) then with pr obab ility 1 − 1 / po ly ( N ) , among all balanced cuts in the complete grap h formed among 2 N sample points, the maximum weight cut corr espond s to the partition of the 2 N poin ts acc or ding to their distrib utions . Her e the weight of a cut is the sum of weights acr oss all edges in the cut, and the edg e weight equals the Hamming distan ce between the bit vectors of the two endpoin ts. V ariants of the ab ov e theorem, based on a model that allo ws two rando m draws at each dimension for all points , are gi ven in Chaudhur i et al. ( 2007, The orem 3.1) and Zhou (2006, C h apter 8). The cle vernes s there i s th e c onstru ction of a dipl oid score at each dimension, gi ven an y pair of indivi duals , und er the assumpti on that two rando m bi ts can be dra wn from the s ame distrib ution at each di mension . In e xpectation , diploi d scores are high er among pairs from diff erent gr oups tha n for pairs in the same group across all K dimensio ns. In additio n, Chaudhuri et al. (2007, Lemma 2.2) sho ws that when K > ( ln n /γ 2 ) , g i ve n two bits from each dimension , one can alw ays classify for an y size of n , f or unb alance d cases with any number of mixtures, using essen tially connec ted compon ent based algorit hms, gi ven the weighted graph as in descr ibed in Theorem 1. The ke y contrib ution of this paper is to sho w ne w ideas that we use to accomplish the goal of cluste ring with the sa me a mount of features, while requiring only one ra ndom b it at ea ch di mension . While some ide as and pro ofs for Theorem 1 in Sectio n 4 ha ve a ppeare d in Chaudhuri et al. (2007), modificatio ns for handling a single bit at each dimension are ubiquit ous throu ghout the proof. Hence we contain the complete proof in this paper noneth eless to giv e a comple te exposit ion. Finding a max-cu t is computatio nally in tracta ble; a hill-c limbing algorith m w as gi ven in Chaudhu ri et al. (2007) to partition a balanced mixture, with a stronger requirement on K , giv en any n , as the middle green curv e in Figure 1 sho ws. T wo simpler algorithms using spectra l techniq ues were constructe d in B lu m et al. (2007), attempting to reproduce condition s abo ve. B o th spectral algorithms in Blum et al. (2007) achie ve the bound establish ed by Theorem 1 without requiring the input inst ances being balanced, and work for cases when k ≥ 2 is a const ant; Howe ver , the y req uire n = ( 1 /γ ) , ev en when k = 2 an d the input instanc e is balanc ed, as the vertical line in Figure 1 sho ws. Note that when N = ˜ ( 1 /γ ) , i.e., when we hav e eno ugh sample fro m each di strib ution, K = ( ln N γ ) becomes the only re quiremen t in Theorem 1. Exploring the tradeo f fs between n an d K , when n is small, as in T he orem 1 in algor ithmic design is both of theoretical interes ts and practical valu e. 1.1 Rela ted W ork In a seminal paper , Pritcha rd et al. (20 00) presented a model-b ased clu stering method to separate popula- tions us ing genoty pe data. T he y assume tha t observ ations from each clus ter are ran dom from some para- 2 0 1000 2000 3000 4000 5000 6000 7000 1e+02 1e+03 1e+04 1e+05 1e+06 Samples (n) Features (K) Kn>1/ γ 2 −−> n>1/ γ [BCFZ 07] K>=1/ γ K>=1/ γ 2 [CHRZ 07] [CHRZ 07] [This Paper] [CHRZ 07] Figure 1: T h is figure ill ustrate s resu lts from three papers. T op and midd le curves are algorithmic resu lts from Chaudh uri et al. (2007). Bottom red curve are non -algori thm resu lts from this paper with single rando m draw and C h audhu ri et al. (2007) with two random draws at each dimension . For n > ( 1 /γ ) , to the right of the vertical dashe d line, spe ctral algorit hms Blum et al. (2007) achie ve bounds gi ven in the red curve. The cur ves are gener ated usin g a biased di strib ution in terms of the ℓ 1 distan ces in alle le frequ encies : for 9 / 10 of features, p i 1 − p i 2 = 10 − 5 ; and for the rest, it is 0 . 1265 ; for thi s mixture, γ = 0 . 0016. metric model. Inf erence for the paramet ers correspond ing to each population is done jointly with inferen ce for the cluster membership of each indi vidual, and k in the mixture, using Bayesian methods. Applying spec tral techniqu es by McSherry (2001) on gra ph partit ioning , and an extensio n due to Coja-Oghla n (2006) fro m their origina l setting on graphs to th e asymmetric n × K matrix of indi viduals/fe atures yield s a polyn omial time algorith m for this problem whe n k is giv en as a con stant, as analyz ed by Blum et al. (2007). For k = 2, an extr emely simple algor ithm based on examining valu es in the top two left singu lar vec tors of the random matri x can clu ster samples ef ficiently . Ho weve r , spectr al tec hniqu es require a lower bound on the sample size n to be at least 1 /γ as sho wn in Figure 2. There are tw o str eams of rela ted work in the learning community . The first stream is the rec ent progres s in lear ning from the point of view of clusteri ng: giv en samples drawn from a mixtu re of w el l-sepa rated Gaussian s (component distrib utions) , one aims to classify each sample accordin g to which component dis- trib ution it comes from, as studied in D a sgupta (1999); D a sgupta and Schulman (2000); Arora and Kanna n (2001); V empala and W ang (2002); A c hliopt as and McS h erry (2005); Kannan et al. (2005); D a sgupt a et al. (2005). This framewo rk has been extended to more general di strib utions such as log-conca ve dis trib utions by Achlio ptas and McSherry (2005); Kannan et al . (200 5), and hea vy-tailed distrib utions by Dasg upta et al. (2005), as well as to more th an two po pulations. These results focus mainly on r educin g the requiremen t on the sepa ration s between any two c enters P 1 and P 2 . In c ontras t, we focus on the sampl e size D . This is mo - 3 ti vated by previo us results (Chaudhur i et al., 2007; Zhou, 2006) stating that by acquiring enoug h attrib utes along the sa me set o f dimensio ns from each co mponent distrib ution, w i th high p robab ility , we can co rrectl y classif y ev ery indi vidual. While our aim is dif ferent from those results, w h ere n > K is almost uni versal and we focus on cases K > n , we do ha ve o ne common axis for comparison, the ℓ 2 -distan ce between an y two ce nters of the distrib utions. In earlier works of Dasgupt a and S c hulman (2000); Arora and Kannan (2001), the s epara- tion requ irement depended on the number of dimensions of each distrib ution; this has recently been re- duced to be ind epend ent of K , the dimensionali ty of the dis trib ution for certain c lasses of distrib ution s in Achli optas and McSherry (2005); Kanna n et al. (2005). This is comparab le to our requir ement in The- orem 1 and that of Blum et al. (2007) for disc rete dist rib utions. For ex ample, according to Theorem 7 in Achliopt as and M c Sherry (2005), in order to separate the mixture of two Gaussi ans, k P 1 − P 2 k 2 = σ √ ω + σ p log n is requi red. Besides Gaussian and Logco nca ve, a general theor em in Achliop tas and McSherry (2005, Theorem 6) is deri ved that in p rincip le also app lies to mixtures of disc rete distrib utions. The ke y difficul ty of ap- plying their theore m directly to our scenario is that it relies on a conc entrati on pro perty of the distrib u- tion (Achlioptas and McSherry, 2005, Eq (10)) that need not hold in our case. In additio n, once the dis- tance between any two centers is fix ed, that is, once γ is fixed in the disc rete dist rib ution, the sample size n in their algorit hms is alway s lar ger than K ω log 5 K (Achliop tas and McSherry, 2005; Kanna n et al., 2005) for log-conca ve dis trib utions (in fact, in Theorem 3 of Kannan et al. (2005), they discard at least this many indi viduals in order to correc tly classify the rest in the sample), and lar ger th an ( K ω ) for G a us- sians (Achliopta s and McSherry , 2005), whereas n < K al ways hold s w h en n < 1 γ in the prese nt paper . The sec ond stream of work is u nder the P A C-learning frame work, where gi ven a sample gener ated from some tar get d istrib ution Z , the go al is to outpu t a distrib ution Z 1 that is clo se to Z in Kul lback- Leibler di ver gence : K L ( Z || Z 1 ) , where Z is a mixture of produ ct distrib utions ov er discrete domai ns or Gaus- sians (K earns et al., 1994; Freund and Mansour, 1999; Cryan, 1999; Cryan et al., 2002; Mossel and Roch, 2005; Feldman et al., 2005, 2006). T h ey do not require a minimal distance be tween any two distrib utions, b ut they do not aim to cla ssify ev ery sample point corr ectly either , and in general require much more data. 2. Pr eliminaries and Definitions Let us first formally define a prod uct distrib ution ove r a Boolean cube { 0 , 1 } K . Definition 2 A pr oduc t distrib ution D m , ∀ m = 1 , 2 , over a Boolean cube { 0 , 1 } K is chara cteriz ed by its e xpecte d value E p m = ( p 1 m , . . . , p K m ) ∈ [0 , 1] K , which we r efer to as the center of D m . W e then restate our problem as a fun damenta l problem of learning mixtu res of two prod uct dis trib utions ov er discr ete domain s, in par ticula r , ov er the K -dimensiona l Boolean cube { 0 , 1 } K , where K is a v ariabl e whose v alue we ne ed to resolve. W e use X = E x = ( x 1 , x 2 , . . . , x K ) to represen t a random K -bit v ector , gi ven a set of K attribu tes. Sometimes we also use x i j to represen t the i t h coordi nate of poi nt X j . Definition 3 A random vector E x fr om the distrib ution D m , which we denote as E x ∼ D m or E x ∼ E p m , wher e E p m is the center of D m , is gene rat ed by independen tly selec ting each coor dinate x i to be 1 with pr obab ility p i m and thus ∀ i , ∀ m , E E x ∼ D m E x = E p m . W e next use the inner- produ ct of two K -dimensio nal vectors E x and E y as the score between X and Y , as in Definition 4, and d efine a complete gra ph, wher e nod es are sample po ints and each edge weight is the score between the two endp oints. 4 Definition 4 score ( X , Y ) = < E x , E y > = P K i = 1 x i y i . Definition 5 Let X be a sample point fr om distrib ution D 1 and Y be a sample point fr om D 2 . Let X ′ , Y ′ be points ran domly drawn fr om D 1 and D 2 r espectivel y , diff ( X ) = E E x ′ ∼ E p 1 score ( X , X ′ ) − E E y ′ ∼ E p 2 score ( X , Y ′ ) , diff ( Y ) = E E y ′ ∼ E p 2 score ( Y , Y ′ ) − E E x ′ ∼ E p 1 score ( Y , X ′ ) , wher e expec tation s ar e taken over all poss ible rea lizatio ns of X ′ , Y ′ r espectivel y . 3. T he Ap pr o ach Our go al is to show th at the perfect part ition T = ( P 1 , P 2 ) is the minimum cut (min-cut) i n terms of score among all ba lanced cut ( S , ¯ S ) , both in e xpectation and with high probabilit y . Let us first define th ese object s formally . In this complete graph, let P 1 repres ent the set of points X 1 , X 2 , . . . , X N from a produ ct distrib ution D 1 , and P 2 repres ent the set of points Y 1 , Y 2 , . . . , Y N from a prod uct distrib ution D 2 . Definition 6 Consi der a balance d cut ( S , ¯ S ) , as in Fi gur e 2, wher e L ∈ [ 1 , N / 2] is the number of nodes that have been swapped fr om o ne side of T to the other , let S = { X i ∈ P 1 , i = 1 , . . . , N − L , V j ∈ P 2 , j = 1 , . . . , L } , and ¯ S = { Y i ∈ P 2 , i = 1 , . . . , N − L , U j ∈ P 1 , j = 1 , . . . , L } . Let score ( S , ¯ S ) = P N − L i = 1 P N − L j = 1 score ( X i , Y j ) + P L i = 1 P L j = 1 score ( U i , V j ) + P N − L i = 1 P L j = 1 score ( X i , U j ) + score ( Y i , V j ), w h ich define s score ( T ) when L = 0 , i.e., score ( T ) = P N i = 1 P N j = 1 score ( X i , Y j ). It is easy to verify that in exp ectati on, the perfect partition has the minimum score , i.e., ∀ balan ced ( S , ¯ S ) other th an T , that is, E [ score ( T ) ] < E score ( S , ¯ S ) ). The fol lo w i ng theorem says that th is is true with high proba bility , gi ven a lar ge enoug h K . Theor em 7 F or a balanced mixtur e of two distrib utions, w it h pr obabil ity 1 − 1 / poly ( N ) , score ( T ) < score ( S , ¯ S ) , for all other bal anced cut ( S , ¯ S ) , give n K = ( ln N γ ) and K N = ( ln N lo g log N γ 2 ) , and N ≥ 4 . Cor ollar y 8 F ollowing steps in T h eor em 7, one can show that if scor es ar e rep laced with pairwise Hamming distan ces, i.e., ∀ X , Y , H ( E x , E y ) = P K i = 1 x i ⊕ y i , the max-cut will ident ify the perfect partition with high pr obabi lity , given the same or der of numbe r of attrib utes as stated in Theor em 1 . The ke y technicalit y in this paper and Chaud huri et al. (2007) is that, instead of sho wing that each balanced cut ( S , ¯ S ) has score t hat is clo se t o its e xpected v alue, we sho w t hat, for each balanced cu t ( S , ¯ S ) , th e follo wing ran dom variab le diff ( T , ( S , S ), L ) as in (2), which captures the differe nce be tween the present cut and the unique perfect partition T , stays close to its expected valu e, which is a positi ve number , giv en a lar ge enough K . Note that for a particular balance d cut ( S , ¯ S ) , diff ( T , ( S , S ), L ) > 0 imm e diately implies that score ( T ) < score ( S , ¯ S ) . F ig ure 2 shows the edges whose weigh t contrib ute to: diff ( T , ( S , S ), L ) = score ( S , ¯ S ) − score ( T ) = (2) L X j = 1 N − L X i = 1 score ( V j , Y i ) − score ( V j , X i ) + score ( U j , X i ) − score ( U j , Y i ). The random v ariabl e diff ( T , ( S , S ), L ), ∀ N / 2 ≥ L ≥ 1, compris es exac tly of score s ov er the set of edges that dif fer between tho se in T and th ose in ( S , ¯ S ) , w h ich is exactly the set of 4 L ( N − L ) edges between 5 Y 3 U 1 U 2 V 1 V L U L X 1 Y N−L X N−L X 3 X 2 V 2 Y 1 Y 2 Y 2 Y 3 U 1 U 2 V 1 X 3 X N−L Y N−L V L U L X 1 X 2 V 2 Y 1 Figure 2: E d ges that are differ ent between a perfe ct partition T and another balanced partition ( S , ¯ S ) , seen only from U 1 ∼ E p 1 and V 1 ∼ E p 2 , and Y 1 ∼ E p 2 , red dotted edges are in T and green solid edges are in ( S , ¯ S ) . In more detail, we refer to X i and Y i , ∀ i ∈ [1 , N − L ] as unswapped node s, as the majority type in the ir side; we denote V j ∈ ( S ∩ P 2 ), U j ∈ ( ¯ S ∩ P 1 ), ∀ j ∈ [1 , L ] as swappe d nodes as the minority on their ne w side. In par ticula r , for ( S , ¯ S ) , origin al cut (red dotted ) edg es that belong to T are replac ed with (green solid) edges, which are the ne w edges that appear in ( S , ¯ S ) ; the set of common edges tha t belong to T ∩ ( S , ¯ S ) are not shown. swapp ed node s and un swapp ed nodes, amon g which 4 ( N − L ) edges ar e sho wn in Figur e 2. Hence we only need to consider the in fluence of 2 N K random bits o ver thes e two sets of ed ges con trib uting to (2), ∀ ( S , ¯ S ) . It is not hard to ve rify the follo wing: E diff ( T , ( S , S ), L ) = ( N − L ) L E E x ∼ E p 1 diff ( X ) + E E y ∼ E p 2 diff ( Y ) . (3) 3.1 K ey Idea in the One-bit Construction The dif ference from Chaudhu ri et al. (2007) is that we r equire only a sin gle bit at eac h dimension for score in t he pre sent pape r . The ide a that makes a n inne r -prod uct based score w ork is that a lthoug h from an indi vidual, e.g., Y ’ s perspe cti ve, d i ff ( Y ) may n ot be sig nificantly positi ve due to the de finition of our s core , the sum of diff s ov er a pair of swapp ed nodes, e.g., diff ( X ) + diff ( Y ) as in Figure 3, can be sho wn to be positi ve with high probab ility , giv en K = ( ln N /γ ) . Hence we pre vent the sum of diff ( X ) + diff ( Y ) from de viatin g too much from its expecte d v alue K γ (Propositi on 13), by excludin g those bad node events (Definition 9), whose probab ility w e bound in L e mma 16 and 17. Definition 9 (Bad Node Event) Let a bad node event E ( Z ) be the ev ent that { diff ( Z ) < E diff ( Z ) − K γ / 4 } , wher e Z is a sample point in the mixtur e. Note this is an e vent in an individual pr obability space ( Z , F Z , Pr Z ) , wher e ( Z , F Z , Pr Z ) is defined over all possib le outcomes of K rand om bits for sample point Z . Note that all bad node e vents are mutually indepe ndent. From now on, we use ( i , F i , Pr i ) to refer to ( Z i , F Z i , Pr Z i ) for the input 2 N nodes, assuming a certain ordering . Definition 10 (Bad Event E N 1 ) E N 1 is the sa me as E ( Z 1 ) ∪ . . . ∪ E ( Z 2 N ) in the pr oduct pr obability space ( , F , Pr ) composed of distinct pr obabil ity spaces ( 1 , F 1 , Pr 1 ), . . . , ( 2 N , F 2 N , Pr 2 N ) as in Definition 9. Let ¯ E N 1 denote the pr oduct pr obability space ( , F , Pr ) excl uding E N 1 . 6 a b d c X Y X c a d b Y Figure 3: G i ven Dots ∼ E p 1 and T riangles ∼ E p 2 . Define diff ( X ) = E [ c | X ] − E [ b | X ] and diff ( Y ) = E [ d | Y ] − E [ a | Y ] . Giv en K = ( ln N /γ ) , with hig h probability , diff ( X ) + diff ( Y ) ≥ K γ / 2, giv en that E E x ∼ E p 1 diff ( X ) + E E y ∼ E p 2 diff ( Y ) = K γ ; Hence a + b ≤ c + d , with high prob abilit y , gi ven also that K N = ( ln N log log N /γ 2 ) . For each balan ced cut ( S , S ) , condi tioned upon fixing a subset of random bits on all sw apped no des, as sho wn in Figure 2, to beha ve nicely in the sense of Lemma 16 and 17, we sho w that the cond itiona l ex- pectat ions, in the sense of D e finition 20, for random v ariables diff ( T , ( S , S ), L ) , ∀ L > 0, are significan tly positi ve, so that th e perfec t partition can almost a lwa ys win o ver a ll other b alanced cuts, in terms of the par- ticular measure (minimum total score here), despite the lar ge de viation e ven ts tha t we handle in Secti on 4. This idea has been exp lored in the proof of Chaudhuri et al. (2007) for diploid scores. The key dif ference be tween t his score and the “dipl oid s core” (see Chaudhu ri et al. , 2007, Section 2.1) i s that the corr espon ding diploid diff ( Y ) is alwa ys signific antly positive in expe ctation , i.e., E E y ∼ D m diff ( Y ) > 0, ∀ m = 1 , 2, and thus remain s so with high probab ility gi ven K = ( ln N /γ ) . That is, an ind i vidua l is a lmost always mo re s imilar to a ran domly ch osen pee r from its popu lation , tha n a randomly cho sen indi vidual from another popu lation giv en a larg e enough K bas ed on “diploid scores”. T he cost of this nice proper ty is: two random bits from the same distrib ution are required at each dimension from all sample. In the present paper , we provid e a similar positi venes s guarant ee, for a pair of scores diff ( X ) + d if f ( Y ) , where E x ∼ D 1 and E y ∼ D 2 , as illustrat ed in Figure 3. This property is due to Proposit ion 13, Lemma 16 an d 17. W e li ke to point out that t he requ irement on the input instance bein g balan ced is due to the fact t hat we need pairin g up two indi viduals such that o ne comes from each d istrib ution, in order to obtain the initial e xpected minimality for T as defined in Propositi on 18. 3.2 The Expec ted Differ ence of T wo Edges W e fi rs t sh o w that the p erfect pa rtition T has the minimum v alue among al l b alance d cuts in expec ta- tion , when su mming up scores over all edges acros s the cut in Proposition 18. The inspi ration for us- ing an inner -product base d s core and pairing up diff ( X ) and diff ( Y ) , fo r X ∼ D 1 and Y ∼ D 2 , comes from Freund and Mansour (1999). W e fi r st sho w that the sum of expecte d differe nces o ver X ∼ D 1 and Y ∼ D 2 is signi ficant. Pro position 11 ∀ a , b = 1 , 2 , E E x ∼ D a , E y ∼ D b < E x , E y > = < E p a , E p b > . Pro of W e ha ve ∀ a , b = 1 , 2, E E x ∼ D a , E y ∼ D b < E x , E y > = E h P K i = 1 x i y i i = P K i = 1 E x i y i = P K i = 1 p i a p i b = < E p a , E p b > . Pro position 12 Let X be a sample point fr om D 1 and Y be a point fr om D 2 , d if f ( X ) = P K i = 1 x i ( p i 1 − p i 2 ), and diff ( Y ) = P K i = 1 y i ( p i 2 − p i 1 ) . Pro position 13 (Freun d and Mansour, 1999) E E x ∼ E p 1 diff ( X ) + E E y ∼ E p 2 diff ( Y ) = k E p 1 − E p 2 k 2 2 = K γ . 7 Pro of By Propo sition 12, E E x ∼ E p 1 diff ( X ) + E E y ∼ E p 2 diff ( Y ) = P K i = 1 p i 1 ( p i 1 − p i 2 ) + P K i = 1 p i 2 ( p i 2 − p i 1 ) = < E p 1 , E p 1 − E p 2 > + < E p 2 , E p 2 − E p 1 > = K γ . Before we procee d, we fi rs t state the follo wing theorem and its corollary on Hoeffdi ng Bounds. Theor em 14 (Hoef fding, 1963) If X 1 , X 2 , . . . , X K ar e independe nt and a i ≤ X i ≤ b i , ∀ i = 1 , 2 , . . . , K , and if ¯ X = ( X 1 + . . . + X K )/ K and µ = E ¯ X , then for t > 0 , P r ¯ X − µ ≥ t ≤ e − 2 K 2 t 2 / P K i = 1 ( b i − a i ) 2 . Cor ollar y 15 (Hoeffd ing, 1963) If Y 1 , . . . , Y n , Z 1 , . . . , Z m ar e independe nt rand om variables with values in the interv al [ a , b ] , and if ¯ Y = ( Y 1 + . . . + Y m )/ m , ¯ Z = ( Z 1 + . . . + Z n )/ n , then for t > 0 , Pr ¯ Y − ¯ Z − ( E ¯ Y − E ¯ Z ) ≥ t ≤ e − 2 t 2 /( m − 1 + n − 1 )( b − a ) 2 . Let us denote w .l.o.g. η = E E x ∼ E p 1 diff ( X ) ≥ K γ / 2, and thus E E y ∼ E p 2 diff ( X ) = K γ − η , and sho w the follo wing two lemmas. Lemma 16 Give n that K ≥ 8 l n 1 /τ γ , Pr X diff ( X ) < η − K γ / 4 < τ . Pro of Let us define γ k = ( p k 1 − p k 2 ) 2 , ∀ k = 1 , . . . , K . Gi ven that x 1 , . . . , x K are independen t Bernoul li random varia bles and ( p k 1 − p k 2 ) x k is either in [0 , √ γ k ] or [ − √ γ k , 0], ∀ k = 1 , . . . , K , we apply Hoef fding bound as in Theorem 14 with t = K γ / 4 K = γ / 4: Pr X " − K X k = 1 ( p k 1 − p k 2 ) x k + η ≥ K γ / 4 # = Pr X " K X k = 1 ( p k 1 − p k 2 ) x k − η ≤ − K γ / 4 # ≤ e − 2 K 2 (γ / 4 ) 2 / P K k = 1 ( √ γ k ) 2 ≤ τ . Thus we ha ve that P r X h P K k = 1 ( p k 1 − p k 2 ) x k ≥ η − K γ / 4 i ≥ 1 − τ . Lemma 17 Give n that K ≥ 8 l n 1 /τ γ , Pr Y diff ( Y ) < ( K γ − η) − K γ / 4 < τ . Pro of Similar to proof of Lemma 16, we ha ve Pr Y h P K k = 1 ( p k 2 − p k 1 ) y i − ( K γ − η) ≤ − K γ / 4 i ≤ τ , where K γ − η = E E y ∼ E p 2 diff ( Y ) . Henc e [ Pr Y h P K k = 1 ( p k 2 − p k 1 ) y i ≥ ( K γ − η ) − K γ / 4 i ≥ 1 − τ . In parti cular , combin ing ( 3 ) and Propositi on 13, w e hav e the follo wing. Pro position 18 E diff ( T , ( S , S ), L ) = ( N − L ) L K γ . Pro of By Definition 5, we ha ve diff ( X ) = E E x ′ ∼ E p 1 score ( X , X ′ ) − E E y ′ ∼ E p 2 score ( X , Y ′ ) = E E x ′ ∼ E p 1 h < E x , E x ′ > i − E E y ′ ∼ E p 2 h < E x , E y ′ > i = < E x , E p 1 − E p 2 > = K X i = 1 x i ( p i 1 − p i 2 ), diff ( Y ) = E E y ′ ∼ E p 2 score ( Y , Y ′ ) − E E x ′ ∼ E p 1 score ( Y , X ′ ) = E E y ′ ∼ E p 2 h < E y , E y ′ > i − E E x ′ ∼ E p 1 h < E y , E x ′ > i = < E y , E p 2 − E p 1 > = K X i = 1 y i ( p i 2 − p i 1 ). 8 Giv en such a po siti veness guara ntee on the condi tional expectat ions of diff ( T , ( S , S ), L ) describe d abo ve, the res t of the proof foc us on bounding lar ge deviat ion e vents; a sk etch of the key ideas has ap peared in Chaudhu ri et al. (2007, Section 3), based on “dipl oid s cores” . W e need to sho w that, with high probabilit y , all of O ( 2 n ) random v ariabl es, in the form of diff ( T , ( S , S ), L ) , stay positi ve all simulta neousl y , gi ven enoug h number of features and total number of random bits. W e describ e the important ideas of this proo f in next three sectio ns, which contain ke y lemmas for each step; more proofs are containe d in the append ix for completen ess of presentatio n. 4. Pr oof T echniques for Conc entration W e first introdu ce some notat ion re garding the sample probability space ( , F , Pr ) . The set is the set of all possibl e outco mes for 2 N K random bits, where we denote each bit as b k j for a point j at dimension k . The σ -field F of eve nts is the set 6 () of all subsets of ; and the probabil ity measur e Pr is ba sed on the product of probabilit ies of each rando m bit b k j , ∀ k , j , corresp ondin g to Bernoulli( p k a ), where a ∈ { 1 , 2 } depen ds on the population of origin for indiv idual j . Formall y , Definition 19 The elementa ry events in the underlying sample space ( , F , Pr ) ar e all possible 2 2 N K cho ices of D = 2 N K bits. F or 0 ≤ i ≤ D and w ∈ { 0 , 1 } i , let B w denote the event that the fir st i bits equa l to the bit string w . Let F i be the σ -field gener ated by the partit ion of into bloc ks B w , f or w ∈ { 0 , 1 } i . Then the sequence F 0 , . . . , F D forms a filter . In the σ -field F i , the o nly vali d eve nts a r e the ones that depen d on the values of the first i bit s, and all such e vents ar e valid within. The e vents that we de fine ne xt and the ir inte ractio ns are sho w n in Figure 5 . W e show that, with high probab ility , all of the O ( 2 2 N ) random v ariables diff ( T , ( S , S ), L ) , as in (2), one c orresp onding to each balanc ed ( S , ¯ S ) , are positi ve. W e initially confine ourselv es into a good subsp ace ¯ E N 1 by exclu ding any bad nod e e ve nt (Definiti on 9). T h is subspace has the nice propert y in the sen se of T h eorem 23. W e the n use union bound to bound the probability of any bad scor e eve nt in this subspace, where a single bad scor e e ven t occurs w h en diff ( T , ( S , S ), L ) ≤ 0 for a particul ar ba lanced ( S , ¯ S ) . W e use the bounded dif ferences method to bound probab ilities of such ev ents. Each time we examine diff ( T , ( S , S ), L ) for a partic ular balanced ( S , ¯ S ) , we let vector ( H 1 , . . . , H 2 K N ) record the entire history of random bits, where ( H 1 , . . . , H 2 K L ) record the partial history of bits on the 2 L swapp ed nodes corre spond ing to ( S , ¯ S ) . Let ℓ = 2 K L be a pos iti ve inte ger . W e denote this 2 K L -history with H (ℓ) . Fo r a balan ced ( S , ¯ S ) , let h be a fixed possi ble ℓ -history: h = { ˜ U 1 , . . . , ˜ U L , ˜ V 1 , . . . , ˜ V L } denotes a vector of 2 K L random bi ts on 2 L swapped nod es as sho wn in F i gure 2, where ˜ X is the outco me of a particu lar point X in our sample. L e t h denote that e vent that we observe this partic ular 2 K L -histo ry: h = { π ∈ : H (ℓ) (π ) = h } . Giv en that h occurs , we are conc erned about the followin g probabil ity space ( h , 6 ( h ), Pr h ) , we ha ve the follo wing definition and propositi on. Definition 20 E h diff ( T , ( S , S ), L ) = E diff ( T , ( S , S ), L ) | F 2 K L is the expec ted value of diff ( T , ( S , S ), L ) condit ioned on an e vent h ∈ F 2 K L . This conditional expe ctatio n E diff ( T , ( S , S ), L ) | F 2 K L is a rando m variab le that can be viewed as a functio n into R fr om the bloc ks in the partition of F 2 K L . Hence E h diff ( T , ( S , S ), L ) is an e v aluation at a particular outcome h ∈ F 2 K L . Pro position 21 F or a particul ar outcome h ∈ F 2 K L , E h diff ( T , ( S , S ), L ) = ( N − L ) P L j = 1 diff ( ˜ U j ) + ( N − L ) P L j = 1 diff ( ˜ V j ) = ( N − L ) P L j = 1 P K k = 1 ( p k 1 − p k 2 )( ˜ u k j − ˜ v k j ). 9 Our startin g point for using the bo unded dif ferences method to bound a singl e bad scor e e ven t o ver ( S , ¯ S ) is when we hav e rev ealed the 2 K L bits and obtained a 2 K L -history h in ¯ E N 1 . Giv en a fixed history h , we call the remaining 2 K ( N − L ) bits on unswapped nodes as t he 2 K ( N − L ) - futu r e . Let ¯ f = ( H 2 K L + 1 , . . . , H 2 K N ) be a fixe d possible 2 K ( N − L ) - futur e . For simplicity of analys is, gi ven h , we first e xpand the confined subsp ace ¯ E N 1 by drop ping constraints on the 2 ( N − L ) unswapp ed nodes. In thi s exp anded sub space, we only require the first 2 L swapp ed node s to be good nodes, a cond ition that we denot e with ¯ E L 1 ( S , ¯ S ) , while leavi ng bits on the 2 ( N − L ) unswa pped nodes uncon strain ed; that is, these nodes can be bad nodes. Thus ( h , 6 ( h ), Pr h ) correspond s to the expan ded sub space of ¯ E N 1 gi ven h , where we can apply the bound ed dif ferenc es method to analyze pr obabil ity for { d if f ( T , ( S , S ), L ) ≤ 0 } in a clean manner applying Azuma’ s Inequality as in Lemma 36. In fact, our starting point of the bounded dif ferences analysis is E h diff ( T , ( S , S ), L ) , w h ere h is a fixed possible 2 K L -histo ry on the 2 L swap ped nodes for ( S , ¯ S ) , s ubject to h ∈ ¯ E L 1 ( S , ¯ S ) : Definition 22 E L 1 ( S , ¯ S ) is the same as E ( U 1 ) ∪ . . . ∪ E ( U L ) ∪ E ( V 1 ) ∪ . . . ∪ E ( V L ) in the pr oduct pr obability space composed of distin ct pr obability spa ces d efined ove r n odes U 1 , . . . , U L , V 1 , . . . , V L as in Definitio n 9. This imm e diately indic ates that the conditiona l e xpecte d valu e E h diff ( T , ( S , S ), L ) ≥ ( N − L ) L K γ / 2, which is our “adv antageous base point” gi ve n that h occurs . T h e proof of the follo wing th eorem appea rs in Section 5. Theor em 23 Give tha t all points ar e drawn fr om ¯ E N 1 , the pr obabilit y space ( , F , Pr ) excl uding E N 1 , we have ∀ balanced ( S , ¯ S ) , wher e h is a particu lar 2 K L -histo ry corr espondin g to the 2 L swap ped nod es specifi ed over ( S , ¯ S ) with res pect to T , E h diff ( T , ( S , S ), L ) ≥ ( N − L ) L K γ / 2 , (4) wher e the con dition al e xpectati on is over eac h of the individual ly e xpanded pr obabili ty space ( h , 6 ( h ), Pr h ) given h ∈ ¯ E L 1 , wher e E L 1 is defined in Definition 22. This s tatement re mains t rue after we r equir e th at h ∈ ¯ E L 2 in addi tion, wher e E L 2 is defin ed in Definition 26. No w a s we rev eal one by one the f uture 2 K ( N − L ) random bits , the conditi onal expecte d v alues E h h diff ( T , ( S , S ), L ) | H (ℓ ′ ) i , ∀ ℓ ′ ≥ 2 K L form a martingal e that is amenab le to the bound ed dif ferences analys is as shown in Theo rem 37 in Section 6. Howe ver , in order to obtain a concentratio n bound as tight as tha t in Theo rem 37, we need to excl ude one more ev ent E L 2 as in D e finition 26, from the 2 K L -histor y h , while e xamining a bala nced ( S , ¯ S ) . W e first giv e some definiti ons regarding E L 2 . Nodes are shown in Figure 2. Definition 24 Give n vectors E u 1 , . . . , E u L and E v 1 , . . . , E v L , wher e u k j , v k j ar e the k t h bit of U j and V j r espec- tively , f k 2 ( h ) = P L j = 1 u k j − P L j = 1 v k j . Definition 25 (De viation V alues) ∀ k = 1 , . . . , K , let t k √ L be the exact deviation on f k 2 ( h ) , i.e., f k 2 ( h ) − E f k 2 ( h ) = t k √ L , ∀ k . Definition 26 (Bad Deviatio n Event E L 2 ) In pr obability space ( , F , Pr ) , given a balan ced ( S , ¯ S ) and its corr espond ing 2 K L -histo ry h , E L 2 is the ev ent suc h that the set of r andom variable s t 1 , . . . , t k r e gar ding 2 K L ra ndom b its r ecor ded in h , as defined in Definition 25, are simultaneous ly large a nd sati sfy P K k = 1 t 2 k ≥ 1 = 8 N ln 2 + 4 K ln 2 ( log log N + 1 ) + 3 ln N / 2 . 10 Using Definition 26 and 25, we immediatel y hav e the follo wing lemma. Lemma 27 Give n that h ∈ ¯ E L 2 , we have ∀ k , f k 2 ( h ) ≤ E f k 2 ( h ) + t k √ L , and P K k = 1 t 2 k ≤ 1 , wher e t k is in Definition 25, and E L 2 is in Definition 26. Pro of By de finition of t k , ∀ k , we ha ve t hat f k 2 ( h ) = E f k 2 ( h ) + t k √ L , wh ere t k ∈ [ − L − E f k 2 ( h ) √ L , L − E f k 2 ( h ) √ L ]. Thus the lemma holds gi ven that h ∈ ¯ E L 2 . Excludin g E L 2 from h is crucial in boundin g the diff erence that each of the 2 ( N − L ) K - futur e rand om bits causes when we work in pr obabil ity space ( h , 6 ( h ), Pr h ) , where the dif fer ence refers to E h h diff ( T , ( S , ¯ S ), L ) | H (ℓ ′ ) i − E h h diff ( T , ( S , S ), L ) | H (ℓ ′ − 1 ) i , where 2 K N ≥ ℓ ′ > 2 K L depends on the bit, such that t he square sum of all these diff erence s is not too big as in Lemma 27. This is illustrat ed in the second graph in Figur e 2. This all o w s us to bound the probab ility on a bad score ev ent, i.e., diff ( T , ( S , S ), L ) ≤ 0 , using Azuma’ s inequa lity in probab ility space ( h , 6 ( h ), Pr h ) as in Section 6. The proof of the follo wing l emma is rather long and sho wn in S e ction A.1. Lemma 28 Let h be the spe cific 2 K L -history that we re cor d for a balan ced cut ( S , ¯ S ) such that h ∈ ¯ E L 1 ∩ ¯ E L 2 . Let ρ L 3 = 2 N 4 L . Then for K = ( ln N γ ) and K N = ( ln N lo g log N γ 2 ) , for all N ≥ 4 , Pr diff ( T , ( S , S ), L ) ≤ 0 | h ∈ ¯ E L 2 ∩ ¯ E L 1 , ¯ f at r andom ≤ ρ L 3 . Event ually we compute the probabil ity of e ven ts { diff ( T , ( S , S ), L ) ≤ 0 } in ¯ E N 1 for all balance d ( S , S ) in Section 7. 5. Pr oof of Theor em 23 This sectio n is dedicated to prove Theore m 23. W e first gi ve another definition . Definition 29 E N − L 1 ( S , ¯ S ) is the same as E ( X 1 ) ∪ . . . ∪ E ( X N − L ) ∪ E ( Y 1 ) ∪ . . . ∪ E ( Y N − L ) in the pr oduct pr ob- ability space compos ed of distinct pr obability spaces defined over nodes X 1 , . . . , X N − L and Y 1 , . . . , Y N − L as in Definitio n 9 . Hence ¯ E L 1 and ¯ E N − L 1 imply that no bad node ev ent happens in the appro priate product spaces thus defined. W e omit ( S , ¯ S ) from E L 1 ( S , ¯ S ) and E N − L 1 ( S , ¯ S ) w h en it is clear from the cont ext. Given a balance d c ut ( S , ¯ S ) , h record s a histo ry on the 2 K L bits on swapp ed nodes U 1 , . . . , U L , V 1 , . . . , V L . Pro position 30 Given all nodes ar e drawn fr om ¯ E N 1 , for an y balanced cu t ( S , ¯ S ) and its particula r 2 K L - histor y h that we r ecor d must satisfy the following: h ∈ ¯ E L 1 ( S , ¯ S ) . Pro of Gi ven ¯ E N 1 , we kno w that for all nodes Z 1 , . . . , Z 2 N , diff ( Z i ) ≥ E diff ( Z i ) − K γ / 4 , (5) 11 simultan eously in the product probabilit y space ( , F , Pr ) , where diff ( Z i ) is a random v ariable sol ely de- termined b y node Z i ’ s bit v ector . In part icular , for each balanced ( S , ¯ S ) , w e focus on the product prob abilit y space that is compos ed of distin ct probability space s defined ov er swap ped nodes U 1 , . . . , U L , V 1 , . . . , V L as in Definition 22. A ft er we re veal these 2 L bit v ectors on U j , V j , ∀ j = 1 , . . . , L , by (5), diff ( U j ) ≥ E diff ( U j ) − K γ / 4 , ∀ j = 1 , . . . , L , (6) diff ( V j ) ≥ E diff ( V j ) − K γ / 4 , ∀ j = 1 , . . . , L . (7) Thus we ha ve h ∈ ¯ E L 1 ( S , ¯ S ) . Definition 31 W e use ¯ f to denote the future of the 2 ( N − L ) K ra ndom bits tha t we ar e going to re veal for the unswappe d nodes on a given ba lanced cut ( S , ¯ S ) . Recall tha t onc e we are fixed to the pr obabi lity space such that E N 1 does not happen, w e know that bot h h and ¯ f ar e confined; the following two notation ar e equivalent: ( h ∈ ¯ E L 1 ( S , ¯ S )) ∩ ( ¯ f ∈ ¯ E N − L 1 ( S , ¯ S )), ( h , ¯ f ) ∈ ¯ E N 1 . Remark 32 A no ther w a y of see ing ¯ E L 1 ( S , ¯ S ) (with r espect to a particular balanc ed cut ( S , ¯ S ) ) is to view it as an event in the simple pr obability spac e ( , F , Pr ) , such that we put constra ints only on the specific 2 L swapped nodes define d on ( S , ¯ S ) while leaving the ¯ f at r ando m. Hence we hav e ¯ E N 1 ⊂ ¯ E L 1 ( S , ¯ S ) in ( , F , Pr ) . W e lea ve this confined space giv en ¯ E N 1 for no w and explore the follo wing e xpanded subsp ace, where we requir e h ∈ ¯ E L 1 while lea ving t he future ¯ f at random. ( h , 6 ( h ), Pr h ) correspon ds to this expa nded subsp ace, w h ere h ∈ ¯ E L 1 . This imm e diatel y implies the follo w i ng lemma. Lemma 33 F or a balanc ed cut ( S , ¯ S ) , g iven a part icular 2 K L -history h ∈ F 2 K L on the 2 L swapp ed nodes suc h that h ∈ ¯ E L 1 , E h diff ( T , ( S , S ), L ) | h ∈ ¯ E L 1 , ¯ f at r andom ≥ L ( N − L ) K γ / 2 , (8) wher e e xpectation is ov er al l pos sible outco mes of the 2 ( N − L ) K rand om bits in ¯ f in pr obability space ( h , 6 ( h ), Pr h ) . Pro of For a b alance d cut ( S , ¯ S ) , giv en h ∈ ¯ E L 1 , where h records 2 K L bits ov er sw apped nod es U j , V j , ∀ j = 1 , . . . , L , by Definition 9, diff ( U j ) ≥ E diff ( U j ) − K γ / 4 , ∀ j = 1 , . . . , L , (9) diff ( V j ) ≥ E diff ( V j ) − K γ / 4 , ∀ j = 1 , . . . , L , (10) and he nce diff ( U j ) + diff ( V j ) ≥ K γ / 2 , ∀ j = 1 , . . . , L by Proposition 13. Thus, in ( h , 6 ( h ), Pr h ) , where ¯ f is a t rando m and h ∈ ¯ E L 1 , we ha ve from Proposition 21, E h diff ( T , ( S , ¯ S ), L ) = ( N − L ) L X j = 1 diff ( U j ) + ( N − L ) L X j = 1 diff ( V j ) ≥ ( N − L ) L X j = 1 ( diff ( U j ) + diff ( V j )) ≥ ( N − L ) L K γ / 2 . 12 Recall that ¯ E L 2 is the eve nt that no simultaneous ly lar ge devi ation happens across 2 L indi viduals o ver their 2 K L random bits. Cor ollar y 34 Given that h ∈ ¯ E L 1 ∩ ¯ E L 2 , and ¯ f is a t ran dom: E h diff ( T , ( S , S ), L ) | h ∈ ¯ E L 1 ∩ ¯ E L 2 , ¯ f at r andom ≥ L ( N − L ) K γ / 2 , (11) which hol ds so long as h ∈ ¯ E L 1 . W e next bou nd E h diff ( T , ( S , S ), L ) for all balance d ( S , ¯ S ) , where h is confine d in ¯ E N 1 and ¯ E L 2 . W e no w prove Theor em 23. Pr oof of Theorem 23. B y Pro positio n 30, for each balanced cut ( S , ¯ S ) , we ha ve h ∈ ¯ E L 1 ( S , ¯ S ). (12) No w apply Corollary 34, gi ven that h ∈ ¯ E L 1 ( S , ¯ S ) ∩ ¯ E L 2 , we immediatel y ha ve the theorem. Remark 35 d iff ( Z ) is de termined by node Z ’ s bit pattern, which is the same when we observe it fr om eve ry balanced cut, wher e it acts as a swap ped node. Hence although we do have O ( 2 n ) balance d cuts , E h diff ( T , ( S , ¯ S ), L ) for all balanc ed cuts are jus t deter mined by the 2 N r andom variab les diff ( Z 1 ), . . . , diff ( Z 2 N ) , eac h of whic h is dete rmined by the bit vector of an individu al in our sample . 6. B ounded Differ ences In order to show Lemma 28 (actual proof see Section A.1), we prove Theor em 37 in this secti on, w h ere we bound the de viation of rando m v ariable d iff ( T , ( S , S ), L ) for a p articu lar bala nced cut ( S , ¯ S ) . Recall that w e let bit vector ( H 1 , . . . , H 2 K N ) record the enti re his tory of random bits that we see, wher e ( H 1 , . . . , H 2 K L ) record the 2 K L -histor y H (ℓ) on 2 L swapped no des. First it is con venient to introduce some more no ta- tion: For ℓ ′ ≥ 2 K L , we b egi n t o re veal the ra ndom bi ts o n u nswap ped nodes in ( S , ¯ S ) . The random v ariabl e E h h diff ( T , ( S , S ), L ) | H (ℓ ′ ) i depen ds on the rando m extension H (ℓ ′ ) of h observ ed. By definition E h h diff ( T , ( S , S ), L ) | H (ℓ ′ ) i (π ) = E h h diff ( T , ( S , S ), L ) | H (ℓ ′ ) = h ′ i for π ∈ h , where h ′ = H (ℓ ′ ) (π ) ; anothe r not ation for this is E h diff ( T , ( S , S ), L ) | F where F is the σ -field genera ted by H (ℓ ′ ) restric ted to h . T o prov e the theorem, w e introduce the followin g. Lemma 36 (Azuma’ s Inequality) L e t Z 0 , Z 1 , . . . , Z m = f be a m a rting ale on some pr obability spac e, and suppo se that | Z i − Z i − 1 | ≤ c i , ∀ i = 1 , 2 , . . . , m , then Pr [ | f − E [ f ] | ≥ t ] ≤ 2 e − t 2 / 2 σ 2 , wher e σ 2 = P m i = 1 c 2 i . W e are no w ready to use bounded diffe rences approach in ( h , 6 ( h ), Pr h ) and pro ve Theore m 37. Theor em 37 Let h be a possibl e 2 K L -history that we r ecor d fo r a balan ced cut ( S , ¯ S ) such that h ∈ ¯ E L 2 ∩ ¯ E L 1 . Then , for t > 0 , in pr obability space ( h , 6 ( h ), Pr h ) , wher e all futur e 2 ( N − L ) K r andom bits ¯ f ar e completely at random, Pr h | E h diff ( T , ( S , ¯ S ), L ) | H 2 K N − E h diff ( T , ( S , ¯ S ), L ) | ≥ t ≤ 2 e − t 2 / 2 σ 2 , wher e σ 2 ≤ 4 ( N − L ) L 2 ( K γ ) + 4 ( N − L ) L 1 , for all balan ced ( S , ¯ S ) with 0 < L ≤ N / 2 swapped nodes. 13 Pro of W e shall set up things to use L emma 36. W e work in probabili ty space ( h , 6 ( h ), Pr h ) . W e start to re veal the 2 K ( N − L ) bits on un swapp ed nodes that are ch osen indep enden tly at ra ndom, and re ly on 2 L swapp ed nodes havin g a good history h , gi ven that h ∈ ¯ E L 2 ∩ ¯ E L 1 . Giv en the σ -field ( h , 6 ( h )) , with 6 ( h ) = 2 h , let us first define a filter F . Gi ven independ ent random bits H 2 K L + 1 , . . . , H 2 K N , the filter is defined by letting F i , ∀ i = 1 , . . . , m , w h ere m = 2 K ( N − L ) , be the σ -field gen erated by histories H ( 2 K L + 1 ) , . . . , H ( 2 K L + i ) . W e thus obtain a natural F : { ∅ , h } = F 0 ⊂ F 1 ⊂ . . . ⊂ F m = 2 h , where for 0 ≤ i ≤ m = 2 K ( N − L ) , ( h , F i ) is a σ -field. Hence F corresp onds to the increasingly refined partiti ons of h obtain ed from all the diffe rent possible extens ions of the 2 K L -histo ry h . W e obt ain a martin gale for rand om va riable diff ( T , ( S , ¯ S ), L ) such that: L et Z 0 = E h diff ( T , ( S , ¯ S ), L ) and Z ℓ ′ − 2 K L = E h h diff ( T , ( S , ¯ S ), L ) | H (ℓ ′ ) i = E h diff ( T , ( S , S ), L ) | F ℓ ′ − 2 K L , (13) where F ℓ ′ − 2 K L is the σ -field gener ated by H (ℓ ′ ) restric ted to h and 2 K N ≥ ℓ ′ > 2 K L . Let H 2 K L + 1 , . . . , H 2 K N map to random bits on x 1 i , . . . , x K N − L , y 1 i , . . . y K N − L , where x k i or y k i refers to a single bit on dimension k on indi vidua l X i or Y i respec ti vely . W e first define the follo wing, ∀ j = 1 , 2 , . . . , m , where m = 2 K ( N − L ) , Z j − Z j − 1 = c j . (14) W e also need to tra nslate between c j , where j = 1 , 2 , . . . , m , and d i , k ( X i ) and d i , k ( Y i ) , ∀ i = 1 , . . . , N − L , k = 1 , . . . , K that corres pond to the bit on dimensio n k of X i and Y i respec ti vely . In particular , ∀ i , ∀ k , we let c ( i − 1 ) K + k = d i , k ( X i ), (15) c ( N − L + i − 1 ) K + k = d i , k ( Y i ). (16) Let j = 2 K L + ( i − 1 ) K + k − 1, we hav e Y 2 Y 3 U 1 U 2 V 1 X 3 X N−L Y N−L V L U L X 1 X 2 V 2 Y 1 Figure 4: Set of e dges that random bits on Y 1 influence upon d i , k ( X i ) = E h diff ( T , ( S , ¯ S ), L ) | H ( j ) , x k i − E h diff ( T , ( S , ¯ S ), L ) | H ( j ) . (17) 14 And similarl y , let ℓ ′ = 2 K L + ( N − L ) K + ( i − 1 ) K + k − 1, we hav e d i , k ( Y i ) = E h h diff ( T , ( S , ¯ S ), L ) | H (ℓ ′ ) , y k i i − E h h diff ( T , ( S , ¯ S ), L ) | H (ℓ ′ ) i . W e immediately ha ve the follo wing lemma that w e can plug into A zu ma’ s in equali ty , where d i , k applie s to both d i , k ( X i ) and d i , k ( Y i ) . Lemma 38 F or the 2 ( N − L ) K random bits o n uns wapped nodes X i , Y i ∀ i ∈ [1 , N − L ] that we re veal, at dimensio n k ∈ [1 , K ] , we have d i , k ≤ L ( p k 2 − p k 1 ) + t k √ L , wher e t k is defined in Definition 25 and 1 as in Definiti on 26, and P K k = 1 t 2 k ≤ 1 . Pro of Giv en tha t Y i , ∀ i , comes from D 2 and X i , ∀ i , comes from D 1 , and by definiti on of d i , k ( Y i ) and d i , k ( X i ) , d i , k ( Y i ) = p k 2 f k 2 ( h ) : y k i = 0 , 1 − p k 2 f k 2 ( h ) : y k i = 1 , and d i , k ( X i ) = p k 1 f k 2 ( h ) : x k i = 0 , 1 − p k 1 f k 2 ( h ) : x k i = 1 . Hence gi ven that h ∈ ¯ E L 2 , Lemma 27, and E f k 2 ( h ) = L ( p k 2 − p k 1 ) as in Propositi on 40, d i , k ( Y i ) ≤ f k 2 ( h ) ≤ E f k 2 ( h ) + t k √ L = L ( p k 2 − p k 1 ) + t k √ L , (18) and similarly , d i , k ( X i ) ≤ L ( p k 2 − p k 1 ) + t k √ L , where P K k = 1 t 2 k ≤ 1 . W e are now ready to obtain a bound for σ 2 = 2 P N − L i = 1 P K k = 1 d 2 i , k , where d 2 i , k ≤ L ( p k 2 − p k 1 ) + √ L ( t k ) ) 2 applie s to unswa pped nodes X i , Y i , ∀ i = 1 , . . . , N − L , in bound ing the differe nces they cause by re vea ling the random bits on dimension K . Giv en that P K k = 1 t 2 k ≤ 1 , σ 2 = X i , k ( d 2 i , k ( X i ) + d 2 i , k ( Y i )) = 2 X i , k d 2 i , k ≤ 2 N − L X i = 1 K X k = 1 L ( p k 2 − p k 1 ) + √ L ( t k ) 2 ≤ 2 ( N − L ) X k 2 ( L ( p k 2 − p k 1 )) 2 + 2 ( √ L ( t k )) 2 = 4 L 2 ( N − L ) X k ( p k 2 − p k 1 ) 2 + 4 L ( N − L ) X k t 2 k ≤ 4 ( N − L ) L 2 ( K γ ) + 4 ( N − L ) L 1 , where 1 = 8 N ln 2 + 4 K ln 2 ( log log N + 1 ) + 3 ln N / 2 as in Definition 26. 15 7. Pu tting Things T o get her First, there are two lemmas regar ding these ev ents. W e want to emphasize the we exclud e ¯ E N 1 once for all 2 N nodes, while exclud ing one ¯ E L 2 from each bala nced cut ( S , ¯ S ) , where L denotes that the e vent ¯ E L 2 is defined ov er the particular set of 2 K L bits across K dimension s on the 2 L swa pped nodes in ( S , ¯ S ) ; we ha ve N L 2 number of suc h eve nts for each L , whose pro babili ties we sum up later using union bound. Lemma 39 Let K ≥ 256 ln N γ , in pr obabi lity space ( , F , Pr ) , Pr E N 1 ≤ ρ 1 = 2 N N 32 . Pro of Apply Lemma 16 to ea ch diff ( Z ) with τ = 1 / N 32 ; Giv en K ≥ 256 ln N γ , we hav e ∀ Z , Pr Z [ E ( Z ) ] ≤ 1 N 32 . W e ado pt the vie w of composing the product space ( , F , Pr ) throu gh distinct probab ility spaces ( 1 , F 1 , Pr 1 ) , . . . , ( 2 N , F 2 N , Pr 2 N ) as in Definition 10, whe re ( i , F i , Pr i ), ∀ i , is define d ov er a ll pos sible outcomes for K random bits fo r indi vidual Z i . Therefore by definiti on, eve nt ¯ E N 1 is the same as the joint e vent ¯ E ( Z 1 ) ∩ . . . ∩ ¯ E ( Z 2 N ) in ( , F , Pr ) . Pr ¯ E N 1 = Pr none of E ( Z ) happ ens, for all nodes Z (19) = Pr ¯ E ( Z 1 ) ∩ ¯ E ( Z 2 ) ∩ . . . ∩ ¯ E ( Z 2 N ) (20) = Pr 1 ¯ E ( Z 1 ) · Pr 2 ¯ E ( Z 2 ) · . . . · Pr 2 N ¯ E ( Z 2 N ) (21) = ( 1 − Pr 1 [ E ( Z 1 ) ] ) · ( 1 − Pr 2 [ E ( Z 2 ) ] ) · . . . · ( 1 − Pr 2 N [ E ( Z 2 N ) ] ) ≥ ( 1 − 1 N 32 ) 2 N ≥ 1 − 2 N N 32 . (22) Before we prov e L emma 42, first let us obtain the expe cted va lue of f k 2 ( h ), ∀ k as in Definition 24. Pro position 40 E f k 2 ( h ) = E h P L j = 1 u k j − v k j i = L ( p k 1 − p k 2 ). Next we e xamine the deviat ion for each random var iable f k 2 ( h ), ∀ k . Lemma 41 ∀ k , for rand om variab le f k 2 ( h ) as in Definitio n 24, Pr h f k 2 ( h ) − E f k 2 ( h ) ≥ t k √ L i ≤ 2 e − t k 2 . (23) In addi tion, events corr espondi ng to dif fer ent dimensions ar e independ ent. Pro of Let us de fine random varia bles ¯ U k , ¯ V k such that f k 2 ( h ) = L ( ¯ U k − ¯ V k ), (24) where ¯ U k = P L j = 1 u k j / L an d ¯ V k = P L j = 1 v k j / L . Thus by Propos ition 40, E ¯ U k − E ¯ V k = 1 L E f k 2 ( h ) = p k 1 − p k 2 . 16 No w apply ing C o rollary 15 of Theorem 14 to bound proba bility of dev iation s on both sides of the exp ected dif ferences, let t = t k √ L / L , we hav e Pr h f k 2 ( h ) − E f k 2 ( h ) ≥ t k √ L i = Pr h ¯ U k − ¯ V k − ( E ¯ U k − E ¯ V k ) ≥ t k √ L / L i ≤ 2 e − 2 ( t k √ L / L ) 2 ( 2 / L ) ≤ 2 e − t 2 k . The followin g two lemmas shows that { h ∈ E L 2 } remains exponen tially small giv en ¯ E N 1 or not. A varia nt of the foll o wing lemma has b een used in t he full pr oof for Chaud huri et al. (2007, Theor em 3.1). It is inclu ded in Section A for complete ness. Lemma 42 (Cha udhur i et al., 2007) In pr obability space ( , F , Pr ) , for eac h balanced cut ( S , ¯ S ) , Pr h ∈ E L 2 ≤ ρ 2 , wher e ρ 2 = O ( 1 2 2 N poly ( N ) ) and N ≥ 2 . Lemma 43 Pr h ∈ E L 2 | ¯ E N 1 = P r h ∈ E L 2 | h ∈ ¯ E L 1 ≤ ρ 2 1 − 2 L / N 32 . Pro of Gi ven the follo wing equations: Pr h ∈ E L 2 = Pr h ∈ E L 2 | h ∈ E L 1 · Pr h ∈ E L 1 + P r h ∈ E L 2 | h ∈ ¯ E L 1 · Pr h ∈ ¯ E L 1 , Pr h ∈ ¯ E L 1 = ( 1 − 1 N 32 ) 2 L ≥ 1 − 2 L / N 32 , (25) we ha ve: Pr h ∈ E L 2 | h ∈ ¯ E L 1 = Pr h ∈ E L 2 − P r h ∈ E L 2 | h ∈ E L 1 · Pr h ∈ E L 1 Pr h ∈ ¯ E L 1 (26) ≤ Pr h ∈ E L 2 Pr h ∈ ¯ E L 1 ≤ ρ 2 1 − 2 L / N 32 . (27) Lemma 44 shows that Pr h diff ( T , ( S , S ), L ) ≤ 0 remains small re gardle ss whethe r ¯ f stays in the confine d subsp ace ¯ E N 1 or is enti rely at random as in ( h , 6 ( h ), Pr h ) . Lemma 44 Pr diff ( T , ( S , S ), L ) ≤ 0 | ( h , ¯ f ) ∈ ¯ E N 1 ∩ h ∈ ¯ E L 2 ≤ ρ L 3 1 − 2 ( N − L )/ N 32 . Pro of W e use e 0 to replace { diff ( T , ( S , S ), L ) ≤ 0 } and boun d the following : Pr e 0 | ( h ∈ ¯ E L 1 ∩ ¯ E L 2 ) ∩ ¯ f ∈ ¯ E N − L 1 , which is the same as the term in the statement of the lemma, Pr e 0 | h ∈ ¯ E L 2 ∩ ¯ E L 1 , ¯ f at r andom = Pr e 0 | ( h ∈ ¯ E L 2 ∩ ¯ E L 1 ) ∩ ¯ f ∈ ¯ E N − L 1 · Pr ¯ f ∈ ¯ E N − L 1 | h ∈ ¯ E L 2 ∩ ¯ E L 1 + Pr e 0 | ( h ∈ ¯ E L 2 ∩ ¯ E L 1 ) ∩ ¯ f ∈ E N − L 1 · Pr ¯ f ∈ E N − L 1 | h ∈ ¯ E L 2 ∩ ¯ E L 1 . 17 By indepe ndenc e between node ev ents: Pr ¯ f ∈ ¯ E N − L 1 | h ∈ ¯ E L 2 ∩ ¯ E L 1 = Pr ¯ f ∈ ¯ E N − L 1 , (28) Pr ¯ f ∈ E N − L 1 | h ∈ ¯ E L 2 ∩ ¯ E L 1 = Pr ¯ f ∈ E N − L 1 . (29) Giv en that ev ents E L 2 , E L 1 defined on 2 L swapped nodes are indepen dent of ev ent E N − L 1 on 2 ( N − L ) unswa pped nodes, we hav e the followin g, where we omit writing out the ¯ f at r andom conditio n, Pr e 0 | ( h ∈ ¯ E L 2 ∩ ¯ E L 1 ) ∩ ¯ f ∈ ¯ E N − L 1 = Pr e 0 | h ∈ ¯ E L 2 ∩ ¯ E L 1 − P r e 0 | ( h ∈ ¯ E L 2 ∩ ¯ E L 1 ) ∩ ¯ f ∈ E N − L 1 · Pr ¯ f ∈ E N − L 1 Pr ¯ f ∈ ¯ E N − L 1 ≤ Pr diff ( T , ( S , S ), L ) ≤ 0 | h ∈ ¯ E L 2 ∩ ¯ E L 1 Pr ¯ f ∈ ¯ E N − L 1 ≤ ρ L 3 ( 1 − 1 N 32 ) 2 ( N − L ) ≤ ρ L 3 ( 1 − 2 ( N − L ) N 32 ) , where Pr ¯ f ∈ ¯ E N − L 1 ≥ 1 − 2 ( N − L ) N 32 follo wing a proof similar to that of Lemma 39. Lemma 45 Pr diff ( T , ( S , S ), L ) ≤ 0 | ¯ E N 1 ≤ ρ 2 1 − 2 L / N 32 + ρ L 3 1 − 2 ( N − L )/ N 32 . Pro of By assu mption of independ ence between node e ven ts, Pr h ∈ E L 2 | ¯ E N 1 = Pr h ∈ E L 2 | h ∈ ¯ E L 1 ∩ ¯ f ∈ ¯ E N − L 1 = P r h ∈ E L 2 | h ∈ ¯ E L 1 ≤ ρ 2 1 − 2 L / N 32 . When h ∈ E L 2 , we gi ve up boundin g diff ( T , ( S , S ), L ) ≤ 0; hen ce by L e mma 43 and 44, Pr diff ( T , ( S , S ), L ) ≤ 0 | ¯ E N 1 ≤ Pr h ∈ E L 2 | ¯ E N 1 + Pr diff ( T , ( S , S ), L ) ≤ 0 | ( h , ¯ f ) ∈ ¯ E N 1 ∩ h ∈ ¯ E L 2 · Pr h ∈ ¯ E L 2 | ¯ E N 1 ≤ ρ 2 1 − 2 L / N 32 + ρ L 3 1 − 2 ( N − L )/ N 32 , Finally , we prov e T h eorem 1. Pr oof of Theorem 1. Pr ∃ ( S , ¯ S ) s.t. score ( S , ¯ S ) > score T ≤ Pr E N 1 + X ( S , ¯ S ) Pr diff ( T , ( S , S ), L ) ≤ 0 | ¯ E N 1 ≤ 32 N 32 + 2 2 N ρ 2 1 − 2 L / N 32 + N / 2 X L = 1 N L N L ρ L 3 1 − 2 ( N − L )/ N 32 = O 1 poly ( N ) Acknowledgmen ts This mate rial is based o n res earch spon sored in pa rt by t he Army Research Of fice, und er agre ement number D AAD19–02–1–03 89, and NSF grant CNF–0435 382. The author than ks A vrim Blum for man y help ful discus sions and Alon Orlitsky for asking the quest ion: why is not one bit enough? 18 ❄ Input with 2 N nodes Examine bad node e vents Giv e up with Pr E N 1 ≤ 2 N N 32 ✲ ¯ E N 1 ❄ For e ach balanced ( S , ¯ S ) , gi ven h as 2 K L history h ∈ ¯ E L 1 diff = diff ( T , ( S , ¯ S ), L ) ✠ h ∈ E L 2 ❅ ❅ ❅ ❅ ❅ ❘ h ∈ ¯ E L 2 Giv e up with ≤ ρ 2 1 − 2 L / N 32 Pr h ∈ E L 2 | h ∈ ¯ E L 1 h ∈ ¯ E L 2 ∩ ¯ E L 1 , ¯ f ∈ ¯ E N − L 1 Pr diff ≤ 0 | h , ¯ f ≤ ρ L 3 1 − 2 ( N − L )/ N 32 ❄ Expand into Subspace h ✻ Map back ρ 2 = 1 2 2 N poly ( N ) ρ L 3 = 2 N 4 L h ∈ ¯ E L 2 ∩ ¯ E L 1 ¯ f : rando m bits E h diff ( T , ( S , S ), L ) | h , ¯ f ≥ 2 L ( N − L ) K γ Azuma’ s inequality in h Pr diff ≤ 0 | h , ¯ f ≤ ρ L 3 ] Figure 5: E V E N T S R E L A T I O N S H I P I N S E C T I O N 7 Refer ences D. Achlioptas and F . McSherry . On spectral le arning of mixtur es o f d istrib utions. In P r oceedings of the 18th Annual COLT , pages 458–46 9, 2005 . (V ersion in http://www .cs.ucsc.edu / optas/pa pers/) . S. Aro ra and R. Kannan. Learning mixtures o f arbitra ry gaus sians. In P r oceedings o f 33 r d A CM Sympo sium on Theory of Computing , pages 247–257, 2001. A. Blum, A. C o ja-Oghla n, A. Frieze, and S. Zhou. Separating popu lation s with w id e d ata: a spec tral analys is. In P r oceedings of the 18th Internatio nal Symposiu m on Algo rithms and Computatio n , Sendai, Japan, December 2007. (ISAA C 2007). 19 K. Chaudhuri, E. Halperin, S. Rao, a nd S . Zhou. A rigorous a nalysi s of populatio n stratificati on with limited data. In Pr oceedi ngs of the 18th ACM-SIAM SOD A , 2007. A. Coja-Oghlan. An adapti ve spectra l heuristi c for partition ing random graphs. In P r oceeding s of the 33r d ICALP , 2006. M. C r yan. Learning and appr oximation Alg orithms for Pr oblems motiva ted by evolutio nary tr ees . P h D thesis , Univ ersity of W arwick, 1999. M. Cryan, L. Goldber g, and P . Goldber g. Evolu tionary tree s can be learned in polynomial time in the two state gener al m a rko v model. SIAM J. of Compu ting , 31(2):37 5–397 , 20 02. A. Dasgupta, J. Hopcroft, J. Kleinber g, and M. Sandler . On learning mixtures of heavy -tailed distrib utions. In Pr oceedin gs of the 46th IEE E FOCS , page s 491–500, 2005. S. Dasgupta . Learning mixtures of gaussia ns. In Pr oceedin gs of the 40th IEEE Symposium on F oundations of Computer S cience , pages 634–644, 1999. S. Dasgupta and L. J. Schulman. A tw o-roun d v ariant of em for gaussian m i xtures . In Pr oceedings of the 16th Confer ence on Uncertaint y in Artificial Intellig ence (U AI) , 2000. J. Feldman, R. O’Donnell, and R. Serv edio. L ea rning mixtur es of product distrib utions over discrete do- mains. In Pr oceedin gs of the 46th IEE E FO CS , 2005. J. Feldman, R. O’Donnel l, and R. Served io. P AC learning mixtures of Gauss ians with no separation as- sumption . In Pr oceedings of the 19th Annual COLT , 2006 . Y . Freund an d Y . Mans our . Estimating a mixture of two product distrib utions. In P r oceeding s of the 12th Annual COLT , pages 183–19 2, 1999 . W . Hoef fding. Probabil ity inequ alities for sums of bounded ran dom v ariables. Journ al of the American Statis tical A s sociat ion , 58(301):13 –30, 1963. R. Kanna n, H. Salmasian, an d S. V empala. The spe ctral method for g eneral mixture mode ls. In Pr oc. of the 18th Annual COLT , 20 05. M. Kearn s, Y . Mansour , D. Ron, R. Rubinfeld, R. Schapir , and L. Sellie. On the lea rnabil ity of discrete distrib utions. I n Pr oceedings of the 26th A CM STOC , p ages 273–28 2, 1994. Frank McSherry . S pe ctral partitioning of random graphs. In P r oceedings of the 42nd IE EE Sympos ium on F ounda tions of Computer Science , pages 529–537, 2001. E. Mosse l and S. Roch. Learning nonsi nglar phyloge nies and hidde n markov mo dels. In Pr oceedin gs of the 37th A CM STOC , 2005. J. K. Pritchard , M. S t ephen s, and P . Donnelly . In ferenc e of population struc ture using m u ltiloc us genoty pe data. Genetics , 155:954– 959, June 2000. V . V empala and G. W ang. A spectra l algo rithm of learning mixture s of distrib utions. In P r oceeding s of the 43r d IEEE FO CS , pages 113–123, 2002. S. Zhou. R o uting , Disjoint P aths, and Classific ation . PhD thesis, Carne gie Mellon Univ ersity , Pittsb urgh , P A, 20 06. CMU T echnical Report, CMU -PDL-06- 109. 20 Ap pendix A. Proof of Lemma 42 The follo wing proof hav e been used in the full proof in Chaudhuri et al. (2007, Theorem 3.1). Pr oof of Lemma 42. T o faci litate ou r proof, we obtain a set of nonne gativ e numbers ( ˜ t 1 , . . . , ˜ t k ) as fo llo ws; ∀ k , to obtain ˜ t k , we round | t k | do wn to nearest non neg ativ e n umber | ˜ t k | tha t is po wer of two. It is easy to v erify that ∀ k , t k ∈ h − 2 L − E f k 2 ( h ) √ L , 2 L − E f k 2 ( h ) √ L i by P ro positi on 40. Thus we ha ve ˜ t k ≤ | t k | ≤ 2 √ L + E f k 2 ( h ) √ L . Let us div ide the entire r ange of | t k | into interv als using po wer-of- 2 non -ne gati ve i nteg ers as di viding poin ts; Let r k , ∀ k rep resent the number of such interv als: we ha ve ∀ k , s o long as N ≥ 2, r k = log ( √ L + L ( p k 1 − p k 2 )/ √ L ) ≤ log 2 √ L ≤ log 2 p N / 2 ≤ log N . (30) Thus we ha ve at most ( log N ) K blocks in the K -dimensi onal space such that each block along each dimen- sion is a subinterv al of h 0 , 2 √ L + E f k 2 ( h ) √ L i . Let B (β 1 , . . . , β k ) represent a block in the K -dimension al space, where β 1 , . . . , β k are nonneg ati ve po wer-of- 2 inte gers and e very point in B (β 1 , . . . , β k ) has its v alue fixed in interv al [ β k , 2 β k ) along dimension k , ∀ k ; hence (β 1 , . . . , β k ) is the point in t he K -dimension al space with the smallest coordi nate in ev ery dimensio n in B (β 1 , . . . , β k ) . A set of va lues ( t 1 , . . . , t k ) as in Definition 25 is mapped into one of these blocks uni quely as follo ws. W e say a point ( t 1 , . . . , t k ) maps to B (β 1 , . . . , β k ) , if ∀ k , 2 β k > | t k | ≥ β k , i.e., ( ˜ t 1 , . . . , ˜ t k ) = (β 1 , . . . , β k ) . W e first bound the followin g e vent using Lemm a 46. L e t us fix one blo ck B (β 1 , . . . , β k ) for a fi x ed set of v alues β 1 , . . . , β k such that P K k = 1 β 2 k ≥ 1 / 4. Lemma 46 Let 1 / 4 = 2 N ln 2 + K ( ln 2 )( log log N + 1 ) + ( 3 ln N )/ 8 as 1 is defined in Definition 26. Pr " h maps to a fixed B (β 1 , . . . , β k ) s.t. K X k = 1 ˜ t 2 k ≥ 1 / 4 # ≤ 1 2 2 N · ( log N ) K · N 3 / 2 . Pro of L et t 1 √ L , . . . , t k √ L be the de viatio n that we obser ve in h for random va riables f 1 2 ( h ), f 2 2 ( h ), . . . , f k 2 ( h ) as in Definition 25 . If coordin ates ( ˜ t 1 , . . . , ˜ t k ) of h maps to (β 1 , . . . , β k ) , we know that ∀ k , 2 β k ≥ | t k | ≥ β k gi ven the definition of B (β 1 , . . . , β k ) . In addi tion, by Lemma 41, we kno w that Pr h f k 2 ( h ) − E f k 2 ( h ) ≥ β k √ L i ≤ 2 e − β k 2 / 4 , (31) and e ven ts corresp ondin g to differe nt dimensions are independen t; Thus we ha ve Pr " h maps to a partic ular B (β 1 , . . . , β k ) s.t. K X k = 1 β 2 k ≥ 1 / 4 # = K Y k = 1 Pr " 2 β k √ L ≥ f k 2 ( h ) − E f k 2 ( h ) = t k √ L ≥ β k √ L s.t. K X k = 1 β 2 k ≥ 1 / 4 # ≤ K Y k = 1 Pr " f k 2 ( h ) − E f k 2 ( h ) ≥ β k √ L s.t. K X k = 1 β 2 k ≥ 1 / 4 # ≤ K Y k = 1 2 e − β 2 k / 4 ≤ 2 K e − P k k = 1 β 2 k 4 (32) ≤ 2 K e − 1 / 16 ≤ 2 K exp − ( 2 N ln 2 + K ln 2 ( log log N + 1 ) + 3 ln N / 2 ) (33) = 2 K 2 2 N · ( 2 log N ) K · N 3 / 2 = 1 2 2 N · ( log N ) K · N 3 / 2 . (34) 21 Giv en tha t t 2 k ≤ 4 ˜ t 2 k , ∀ k , we kno w that P K k = 1 t 2 k ≥ 1 impli es that P K k = 1 ˜ t 2 k ≥ 1 4 P K k = 1 t 2 k ≥ 1 / 4 . Thus we ha ve Pr " K X k = 1 t 2 k ≥ 1 # ≤ P r " K X k = 1 ˜ t 2 k ≥ 1 / 4 # (35) = Pr " h maps to some B (β 1 , . . . , β k ) s.t. K X k = 1 β 2 k ≥ 1 / 4 # . (36) This allo ws us to upper bound P r E L 2 with e vents regardi ng P K k = 1 ˜ t 2 k as follo ws: Pr E L 2 = Pr " K \ k = 1 ( f k 2 ( h ) − E f k 2 ( h ) = t k √ L ) s.t. K X k = 1 t 2 k ≥ 1 # (37) ≤ Pr " h maps to some B (β 1 , . . . , β k ) s.t. K X k = 1 β 2 k ≥ 1 / 4 # ≤ ( log N ) K 2 2 N · ( log N ) K · N 3 / 2 ≤ 1 2 2 N poly ( N ) . (38) Hence the prob abilit y that the 2 K L unordered pairs induce simultaneou sly lar ge de viation for random vari- ables f 1 2 ( h ), . . . , f k 2 ( h ) , as in Definition 26, is at most ρ 2 = O ( 1 2 2 N poly ( N ) ) . A.1 A c tual Proof of Lemma 28 Note that the const ant in the lemma has not been optimized. Pr oof of Lemma 28. W e take pre p t = E h diff ( T , ( S , ¯ S ), L ) ≥ K L ( N − L )γ / 2 and plug in Theo - rem 37, we ha ve the follo w in g: Pr diff ( T , ( S , S ), L ) ≤ 0 | h ∈ ¯ E L 2 ∩ ¯ E L 1 = Pr h E h diff ( T , ( S , ¯ S ), L ) | H 2 K N − E h diff ( T , ( S , ¯ S ), L ) ≤ − E h diff ( T , ( S , ¯ S ), L ) ≤ 2 e − t 2 / 2 σ 2 ≤ 2 e − ( K L ( N − L )γ / 2 ) 2 / 2 σ 2 , (39) where σ 2 ≤ 4 ( N − L ) L 2 ( K γ ) + 4 ( N − L ) L 1 as defined in Theorem 37. W e will prov e that for all N ≥ 4, so long as 1. K ≥ ( ln N γ ) , 2. K N ≥ ( ln N lo g log N γ 2 ) , we will ha ve 2 e − t 2 / 2 σ 2 ≤ 2 e − ( 2 K L ( N − L ) γ ) 2 / 2 σ 2 ≤ 2 N 4 L . (40) In what follows, we sho w that gi ven differe nt v alues of N , by choosing sligh tly diffe rent con stants in (1) and (2), (40) is alw ays satisfied. Case 1: 4 ≤ N ≤ log log N / 2 γ . In this case, we requir e that K N ≥ c 1 ln N lo g log N γ 2 , where c 1 ≥ 148 8, which immediately impli es the follo wing inequalitie s giv en that N ≤ log log N / 2 γ : 22 1. K ≥ 2 c 1 ln N γ , 2. N ≤ K log lo g N 4 c 1 ln N , 3. log log N ≥ 4 γ , ∀ N ≥ 4, i.e., we consider cases where γ is small enough, 4. ln N ≥ 2 ln 2, ∀ N ≥ 4. W e first deri ve the follo w i ng term that appears in σ 2 as specified in Theorem 37, 16 L ( N − L )( 32 N ln 2 + 6 ln N ) ≤ 512 ln 2 ( N − L ) L N + 96 ( N − L ) L ln N ≤ 128 ln 2 K ( N − L ) L log log N c 1 ln N + 48 γ K ( N − L ) L c 1 ≤ 64 K ( N − L ) L log log N c 1 + 12 K ( N − L ) L log log N c 1 ≤ 76 K ( N − L ) L log log N c 1 ≤ K ( N − L ) L log log N , gi ven that c 1 ≥ 1488 . Next, gi ven that L γ ≤ N γ / 2 ≤ log log N 4 , we hav e σ 2 ≤ 64 K ( N − L ) L ( L γ ) + 355 K ( N − L ) L log log N + K L ( N − L ) log log N ≤ 16 K L ( N − L ) log log N + 356 K L ( N − L ) log log N ≤ 372 K L ( N − L ) log log N . Finally , gi ve n that K N ≥ 1488 log l og N ln N γ 2 , we ha ve: 2 e − t 2 / 2 σ 2 ≤ e − ( 2 K L ( N − L ) γ ) 2 / 2 σ 2 ≤ 2 e − 4 K L ( N − L )γ 2 2 × 284 log log N ≤ 2 e − L K N γ 2 284 log log N ≤ 2 N 4 L . Thus we also ha ve K ≥ 2 c 1 ln N γ = 2976 ln N γ gi ven that N ≤ log log N / 2 γ . Case 2: log lo g N 2 γ < N ≤ K log lo g N 20 . In this case, K and N are close and we require the follo wing, 1. K ≥ c 2 ln N γ , where c 2 = 512, 2. K N ≥ c 0 ln N lo g log N γ 2 , where c 0 = 2000. Note that consta nts c 0 , c 2 abo ve are not opt imized; gi ven any N , an optimal combinatio n of c 0 , c 2 will result in the lo w e st possible K giv en that K ≥ max { c 0 ln N lo g log N N γ 2 , c 2 ln N γ } . Giv en that N ≤ K log lo g N 20 , we ha ve: 16 L ( N − L )( 32 N ln 2 + 6 ln N ) ≤ 400 20 K ( N − L ) L log log N ≤ 20 K ( N − L ) L log log N , and hence σ 2 ≤ 64 K ( N − L ) L 2 γ + 355 K ( N − L ) L log log N + 20 K ( N − L ) L log log N ≤ 64 ( N − L ) L 2 K γ + 375 K L ( N − L ) log log N . 23 The follo wing inequalitie s are due to (1) and (2) respecti vely , ( 2 K L ( N − L )γ ) 2 2 ∗ 64 K ( N − L ) L 2 γ ≥ 16 L ln N , (41) ( 2 K L ( N − L )γ ) 2 2 ∗ 375 K L ( N − L ) log log N ≥ 16 3 L ln N , (42) and thus 2 σ 2 ≤ ( 2 K L ( N − L )γ ) 2 16 L ln N + ( 2 K L ( N − L )γ ) 2 16 L ln N / 3 ≤ ( 2 K L ( N − L )γ ) 2 4 L ln N / 3 , (43) and 2 e − t 2 / 2 σ 2 ≤ 2 e − ( 2 K L ( N − L )γ ) 2 2 σ 2 ≤ 2 e − 4 L ln N ≤ 2 / N 4 L . Case 3: N ≥ K log lo g N 20 ≥ 16. Here we require that K = c 3 ln N γ for some c 3 to be determine d. Thus we ha ve K N ≥ c 2 3 ln 2 N log log N 80 γ 2 , which satisfies the const raint of the form K N ≥ ( ln N lo g log N γ 2 ) as in other case s. Giv en that N ≥ 4, we hav e that ln N ≥ 2 ln 2 an d hence 16 L ( N − L )( 32 N ln 2 + 6 ln N ) ≤ 128 ( N − L ) L N ln N + 6 N L ( N − L ) ln N ≤ 134 ( N − L ) L N ln N . Giv en that K log log N ≤ 20 N , we hav e: σ 2 ≤ 64 K ( N − L ) L 2 γ + 512 ln 2 ∗ ( K log log N )( N − L ) L + 134 ( N − L ) L N ln N ≤ 64 ( N − L ) L 2 ( K γ ) + 512 ln 2 ∗ 20 N ( N − L ) L + 102 ( N − L ) L N ln N ≤ 64 c 3 ln N γ γ ( N − L ) L ( N / 2 ) + ( N − L ) L N ln N ( 128 ∗ 20 + 134 ) ≤ ( 32 c 3 + 2694 )( N − L ) L N ln N . By taking c 3 = 188 such that c 2 3 ≥ 4 ( 32 c 3 + 2694 ) , we ha ve t 2 / 2 σ 2 ≥ ( 2 K ( N − L ) L γ ) 2 2 σ 2 = ( 2 c 3 ( N − L ) L ln N ) 2 2 σ 2 ≥ 2 ( c 3 ( N − L ) L ln N ) 2 ( 32 c 3 + 2694 ) N ( N − L ) L ln N ≥ 2 c 2 3 ( N − L ) L ln N ( 32 c 3 + 2694 ) N ≥ c 2 3 L ln N ( 32 c 3 + 2694 ) ≥ 4 L ln N . Thus 2 e − t 2 / 2 σ 2 ≤ 2 e − c 2 3 L ln N ( 32 c 3 + 2694 ) ≤ 2 e − 4 L ln N = 2 N 4 L . In summary , w e ha ve the follo wing requiremen ts. Not e that N alway s fall s into one of these cases. For all cases, we r equire tha t K ≥ ( ln N /γ ) (which is implicit for Case 1); the constan t that we require in K for Case 2 is larger than that for Case 3, (i.e., c 2 ≥ c 3 as in abo ve) , so that the two cases can ov erlap. • Case 1: 16 ≤ N ≤ log log N / 2 γ . W e req uire that K N ≥ 1488 ln N log lo g N γ 2 , which implies that K ≥ 2976 ln N /γ . • Case 2: log log N 2 γ < N ≤ K l og log N 20 . W e require that K ≥ 512 ln N γ , and K N ≥ 2000 ln N log lo g N γ 2 . • Case 3: N ≥ K log lo g N 20 . W e require K ≥ 188 ln N γ . 24
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment