Order-Optimal Consensus through Randomized Path Averaging
Gossip algorithms have recently received significant attention, mainly because they constitute simple and robust message-passing schemes for distributed information processing over networks. However for many topologies that are realistic for wireless…
Authors: F. Benezit, A.G. Dimakis, P. Thiran
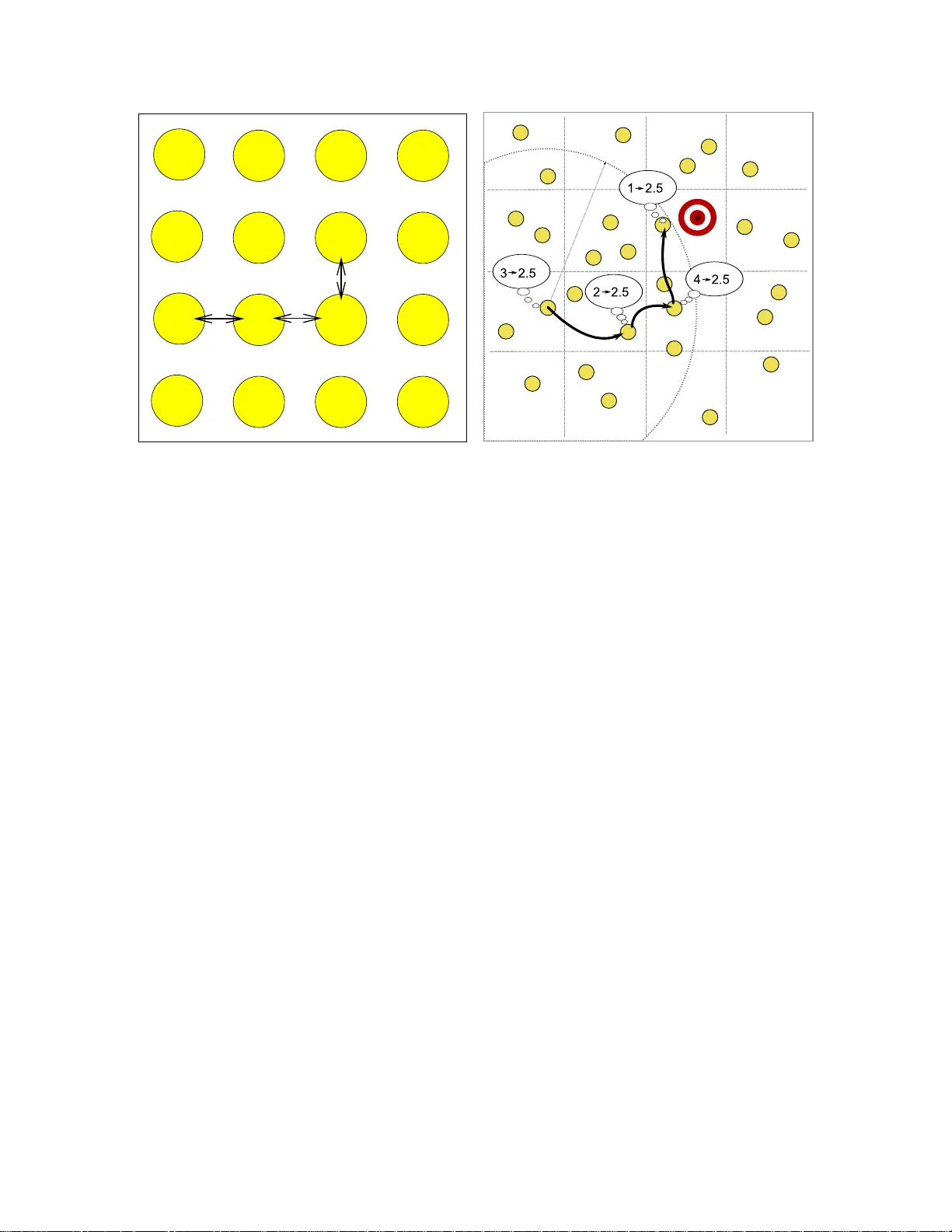
1 Order -Optimal Consensu s through Randomized P ath A v eraging Florence B ´ en ´ ezit ∗ , Alexandros G. Dimakis † , Patrick Thiran ∗ , Martin V etterli ∗ † ∗ School of IC, EP FL, Lausan ne CH-1015, Switzerland † Department of Ele ctrical Enginee ring and Computer Science (EECS) Univ e rsity of California, Berkeley Berkeley , CA 94720 , USA Abstract Gossip algorithms have recently receiv ed significant attention, mainly because they constitute simple and robu st message-passing schemes f or distributed information processing over networks. Howe ver for many topologies that are realistic for wireless ad-hoc and sensor networks (like grids and random geometric graphs), the standard nearest- neighbor gossip con ver ges as slowly as flooding ( O ( n 2 ) messages). A recently proposed algorithm called geograp hic gossip improves go ssip efficienc y by a √ n factor , by exploiting geographic i nformation to enable multi-hop long distance communications. In this paper we pro ve that a v ariation of geograph ic gossip that averages along routed paths, improv es efficiency by an additional √ n factor and is order optimal ( O ( n ) messages) f or grids and random geometric graphs. W e de velop a general tech nique (trav el agenc y method) based on Mark ov cha in mixing time inequalities, which can gi ve bounds on the performance of randomized message-passing algorithms operating ov er various graph topologies. I . I N T RO D U C T I O N Gossip algorithm s are distrib u ted message-passing schemes designed to disseminate and proce ss information over networks. Th ey have received significant intere st because the p roblem of com puting a glo bal fu nction of d ata distributi vely over a network, using only loc alized message-passing, is fundamental for num erous ap plications. These prob lems and their connectio ns to mixin g rates of Ma rkov chains have been extensively studied starting with the pioneering work of Tsitsiklis [2 6]. Ea rlier work studied mostly determin istic pr otocols, k nown as av erage consensus algorithms, in which each node commun icates with each of its neighbors in e very round . More recent w o rk (e.g. [1 2], [2]) has focu sed on so-called gossip alg orithms, a class of ra ndomized alg orithms th at solve the averaging problem by comp uting a sequenc e o f rando mly selected p airwise averages. Go ssip and consen sus alg orithms have been the focus o f renewed interest over the past se veral years [12], [3], [1 4], m otiv ated by applications in sensor networks and distributed control systems. Novem ber 1, 2018 DRAFT 2 The simplest setup is the following: n nodes are placed on a graph whose edges correspo nd to reliab le com- munication links. Eac h node is initially gi ven a scalar (wh ich co uld c orrespon d to some sensor measure ment like temperatur e) and we are intere sted in solving the distributed averaging problem : name ly , to find a distributed message-passing algorithm by which a ll nodes can compu te the ave rag e o f all n scalars. A scheme th at compu tes the average ca n easily be mo dified to compu te any lin ear fun ction (pro jection) o f the measuremen ts as well as more general functions. Furtherm ore, the scalars can be replaced with vectors and generalized to address problems like distributed filterin g and optimization as well as distributed detectio n in sensor n etworks [24], [27], [20]. Random projection s com puted via go ssip, can be used for co mpressive sen sing of senso r measuremen ts and field estimation as pr oposed in [19]. Note th at throu ghou t this paper we will be interested in gossip a lgorithms that comp ute linear function s, and will not d iscuss r elated p roblems like information dissemin ation ( see e.g. [15], [21] and references therein). Gossip alg orithms solve the averaging problem by first having each no de ran domly pick o ne of their one-h op neighbo rs an d iteratively co mpute pairwise averages: Initially all the no des start with their own measuremen t as an estimate of the average. T hey update this estimate with a pairwise average of current estimates w ith a random ly selected neighbor, at each gossip round . An attractiv e prop erty of gossip is th at n o coordina tion is required f or the gossip algorithm to conv erge to the global average wh en th e g raph is conn ected – nodes can just ran domly wake up, select on e of their one- hop n eighbo rs ran domly , exchang e estimates and update their estimate with the av erage. W e will ref er to this algo rithm as stand ar d or n earest-neigh bor gossip. A fun damental issue is the perf orman ce analysis o f such a lgorithms, namely the commu nication ( numbe r of messages passed be tween o ne-ho p neigh borin g nodes) re quired bef ore a gossip a lgorithm converges t o a sufficiently accurate estimate. For energy -constrain ed sensor n etwork applications, commu nication correspond s to energy con- sumption an d there fore should be min imized. Clearly , the co n vergence time will d epend o n the graph c onnectivity , and we expect well-c onnected g raphs to sp read inform ation faster and h ence to require fewer messages to conv erge. This question was first an alyzed for the complete gr aph in [ 12], wher e it was shown that Θ( n log ǫ − 1 ) go ssip messages need to be exchan ged to con verge to th e glob al average within ǫ accu racy . Boyd et al. [3] analyzed th e conv ergence time o f standard g ossip for any grap h and showed that it is clo sely lin ked to the mixing time of a Markov chain defined on the co mmunica tion g raph. They fu rther ad dressed the pr oblem o f o ptimizing the neighbo r selection prob abilities to accelerate convergence. For certain types o f well connected g raphs ( including expan ders and small world g raphs), standard gossip conv erges very quickly , req uiring the sam e n umber of messages ( Θ ( n log ǫ − 1 ) ) as the fully co nnected graph. Note that any algorithm that a vera ges n number s will r equire Ω( n ) messages. Unfortu nately , for rand om geo metric gr aphs and grids, wh ich are the relev ant to pologies for large wireless ad-h oc and sensor network s, standard gossip is extremely wasteful in term s of com municatio n requirem ents. For instance, ev en optimized stand ard go ssip algor ithms on gr ids converge very slo wly , requ iring Θ( n 2 log ǫ − 1 ) messages [3], [8]. Observe that this is of the sam e order as the energy required for every node to flo od its e stimate to all other nodes. On the contrary , the obviou s solutio n o f averaging numb ers on a spannin g tree an d flood ing bac k the average Novem ber 1, 2018 DRAFT 3 to a ll the nodes r equires o nly O ( n ) messages. Clearly , con structing and ma intaining a spannin g tree in dyn amic and ad-h oc networks introd uces sign ificant overhead and complexity , but a q uadratic nu mber of messages is a high price to pay for fault toleranc e. Recently Dimakis et al. [8] pro posed geographic gossip , an a lternative g ossip s cheme that r educes to Θ( n 1 . 5 log ǫ − 1 / √ log n ) the nu mber of require d messages, with slightly more com plexity at the nod es. Assum ing th at the nod es h av e knowledge of th eir geograph ic locatio n and under some assumptions in the network topology , greedy geographic routing can be used to b uild an overlay network where any p air of node s can com municate. The overlay network is a comp lete g raph on which standa rd gossip conv erges with Θ ( n log ǫ − 1 ) iterations. At each iteration w e perfo rm greedy routing, which costs Θ( p n/ log n ) messages on a geometric rand om gr aph. In total, g eograp hic g ossip th us requires Θ( n 1 . 5 log ǫ − 1 / √ log n ) messages. Li and Dai [1 3] recently pro posed Location-Aid ed Distributed A veraging (LAD A), a scheme that uses partial locations and markov c hain lifting to create fast g ossiping alg orithms. T he cluster-based LADA algorithm perfor ms slightly better than geog raphic gossip, req uiring Θ( n 1 . 5 log ǫ − 1 / (log n ) 1 . 5 ) messages for random geometric grap hs. While the th eoretical machinery is different, L AD A algor ithms also use directionality to accele rate gossip, but can operate even with partial locatio n inf ormation and have smaller total delay comp ared to geograph ic g ossip, at the cost of a somewhat mo re complicated algorith m. This paper: W e inv estigate the perfo rmance of path averaging , which is the same algorithm as geogr aphic gossip with the addition al m odification of averaging a ll the nodes on the r o uted pa ths . Ob serve th at av eraging the whole route come s a lmost for f ree in multihop co mmun ication, because a packet ca n accumulate the sum and the num ber of no des visited, comp ute the av erage when it r eaches its final destination and follow the same ro ute back wards to disseminate the a verag e to all the no des along this ro ute. In path averaging, the selection of the routed path ( and h ence th e r outing algo rithm) will affect the perfor mance of the alg orithm. W e start this paper by experimentally observ ing that the numb er of m essages for grids a nd rando m geometric grap hs seem s to scale linearly when r andom greedy rou ting is used . The mathematical an alysis of path a veragin g with greedy routing i s highly complex because the number of possible routes increases exponentially in the nu mber of nodes. T o make the analysis tractable we m ake two simplificatio ns: a) W e elim inate ed ge effects b y assum ing a grid o r rando m geom etric g raph on a toru s b) we use b ox-greedy r outing , a scheme very similar to gree dy routin g with the extra restriction that each hop is guar anteed to be within a virtual box that is not too close or too far from the existing no de. Box-greed y r outing (describ ed in section III -D) can be implemented in a distributed way if each n ode knows its location, the location of its o ne-ho pe neigh bors, and the total number of no des n . W e call path averaging with box-greed y routing Box -path averaging . The main result of this p aper is that geog raphic gossip with p ath averaging requ ires O ( n ) messages under th ese assumptions. Fur ther, we present exper imental evidence that su ggests that this optimal behavior is preserved even when different routing algor ithms are used. The remain der of this pap er is organized as follows: in Section II we define our time and n etwork mod els, g iv e a p recise d efinition of gossip algorith ms and explain our metrics to evaluate the p erform ance of gossip algorith ms. Novem ber 1, 2018 DRAFT 4 Grid Random geometric graph Standard gossip [3] C av e = Θ( n 2 log ǫ − 1 ) C av e = Θ “ n 2 log ǫ − 1 log n ” Hops per time-slot E [ R ] = Θ( √ n ) E [ R ] = Θ „ q n log n « Geographi c T av e = Θ( n log ǫ − 1 ) T av e = Θ( n log ǫ − 1 ) gossip [8] C av e = Θ( n 1 . 5 log ǫ − 1 ) C av e = Θ “ n 1 . 5 log ǫ − 1 √ log n ” Box- T av e = Θ( √ n log ǫ − 1 ) T av e = Θ( √ n log n log ǫ − 1 ) path ave raging C av e = Θ( n log ǫ − 1 ) C av e = Θ( n log ǫ − 1 ) T ABLE I P E R F O R M A N C E O F D I FF E R E N T G O S S I P A L G O R I T H M S . T av e D E N O T E S ǫ - A V E R AG I N G T I M E ( I N G O S S I P R O U N D S ) A N D C av e D E N O T E S E X P E C T E D N U M B E R O F M E S S AG E S R E Q U I R E D T O E S T I M AT E W I T H I N ǫ AC C U R A C Y . In Section II I, we de scribe path averaging with greedy ro uting and show its excellent per forman ce in simulatio ns. W e also define path av eraging with bo x-gre edy ro uting ( box-p ath a veraging), who se analysis is tractable and gives insight on gen eral gossip algorithm s. In Sec tion IV we present the techn ical tools we u se to theor etically show the efficiency of box-path averaging. W e show that the meth odolog y dev eloped in that section is general, simple an d insightful. Section IV -D states our results, and o utlines the pro ofs which can be f ound in the Appendix. I I . B AC K G RO U N D A N D M E T R I C S A. T ime model W e u se th e asyn chron ous time m odel [1], [3] , which is well-matched to the distributed nature o f sensor networks. In particu lar , we assume that eac h senso r has an indepe ndent clock whose “ticks” are distributed as a rate λ Poisson process. Howe ver, our analysis is based on measu ring tim e in te rms o f the n umber of ticks of an equivalent sing le virtual g lobal clock ticking accor ding to a rate nλ Poisson process. An exact analysis o f the tim e mod el can b e found in [3 ]. W e will refer to the time b etween two co nsecutive clock ticks as one timeslot. Throu ghout this paper we will b e interested in min imizing th e numb er of messages without worryin g abou t de lay . W e can therefo re ad just the length of the timeslots relati ve to th e communication tim e so th at only o ne packet exists in the network at each timeslot with high probability . Note t hat this assumption is made only for analytical convenience; in a practical imp lementation , several pa ckets m ight co-exist in the network, b ut the associated congestion control issues are b eyond th e scop e of this work. Novem ber 1, 2018 DRAFT 5 B. Network mod el W e model the wirele ss networks as r andom geometric graph s (RGG), fo llowing standard modelin g assump- tions [11], [1 8]. A random g eometric g raph G ( n, r ) is formed by choo sing n node lo cations uniformly and indepen dently in the unit squa re, with any pair of nod es i and j co nnected if their Euclide an distance is smaller than some transmission radius r (see Fig. 1) . It is well known [ 18], [ 11], [10] that in order to maintain connectivity and to minim ize interfere nce, the tr ansmission radiu s r ( n ) should scale like r ( n ) = p c log n/n . For the purp oses of ana lysis, we assume that co mmun ication within this transmission radius always succeeds 1 . No te that we assume that th e m essages inv olve real n umbers; the effects of message q uantization in gossip and con sensus algo rithms, is an active area of research (see fo r example [17], [25]). In th e Ap pendix we show a slightly stronger condition than conn ectivity , on h ow the scalin g co efficient c in r ( n ) tunes th e regularity of rand om geometr ic graph s. The result states th at, if c > 10 , then a ra ndom geometric g raph is r egular with h igh probability when n is large. Regular geometr ic gr aphs are ran dom geo metric grap hs with d egrees bound ed above and below . In particu lar , select constants a < α < b , draw a ran dom g eometric g raph a nd divide the unit square in square s of size α log n/n . If each squa re c ontains b etween a log n an d b lo g n node s, then the graph is called regular . One stan dard result [1 1], [18] that f or a suitable constant α , each of these squ ares will co ntain one or more nod es with hig h prob ability (w .h. p.). In the app endix we prove a sligh tly stronger regularity c ondition : that in fact, if α > 2 , th e numbe r of nodes in each square will be Θ(log n ) no des, i.e . the ra ndom geometric graphs are regu lar geom etric g raphs w .h .p. In Section III-D, we assume that ou r network is a regular geom etric grap h embedd ed on a tor us, and we ensure that any no de in a square is able to comm unicate with any other n ode of its four neighb oring squares by setting c > 10 . C. Gossip alg orithms Gossip is a class of d istributed averaging algo rithms, where average consensus ca n be reached up to any de sired lev el o f accu racy by iter ativ ely av eraging small rand om groups of estimates. At time-slot t = 0 , 1 , 2 , . . . , each no de i = 1 , . . . , n has an e stimate x i ( t ) of the g lobal average. W e use x ( t ) to den ote th e n -vector of these estimates an d therefor e x (0) g athers th e initial values to be averaged. The ultimate go al is to drive the estimate x ( t ) to the vector of av erages ¯ x av e ~ 1 , where ¯ x av e : = 1 n P n i =1 x i (0) , and ~ 1 is an n -vector o f ones. In gossip, at each time-slot t , a random set S ( t ) of nodes commun icate with each other and upd ate their estimates to the average of the estimates of S ( t ) : for all j ∈ S ( t ) , x j ( t + 1) = P i ∈ S ( t ) x i ( t ) / | S ( t ) | . In stand ard gossip ( nearest neighbor ) an d in geo graphic gossip, only r andom pairs of nodes average their estimates, hence S ( t ) always con tains exactly two nodes. On th e other hand , in path av eraging, S ( t ) is the set of no des in the rand om route ge nerated at ea ch time-slot t . There fore in this case, S ( t ) contains a rand om numbe r o f node s. 1 Ho we ver , we note that our proposed algorithm remains robust to communication and node failur es. Novem ber 1, 2018 DRAFT 6 Fig. 1. Random geometric graph example . The connec ti vity radius is r ( n ) . D. Metrics fo r conver gence time and message co st W e me asure the perform ance of g ossip algo rithms with a m etric that was recen tly intr oduced in [6]. In stead of defining conver gence time as th e time T ave elapsed until the error metric becom es smaller than ǫ with prob ability 1 − ǫ (see Eq. (2)) as in [3], we define it as th e time T c by wh ich the error metr ic is divided by an e factor with probab ility 1 in the long r un. Apar t from giving an almost sure c riterion for co n vergence time, consensus time T c also conveniently lightens the formalism b y removing the ǫ ’ s. For the algorithm s o f interest, the estimate vector x ( t ) and the err or vector ε ( t ) = x ( t ) − ¯ x av e ~ 1 for t > 0 are random . Howe ver, in th e long run, th e error decay s exponentially with a deterministic rate 1 /T c , where T c , called consensus time, is defined as follows [6]: Theor em 1: Consensu s time T c . If { S ( t ) } t > 0 is an indepen dently and id entically distributed ( i.i.d.) process, then the limit − 1 T c = lim t →∞ 1 t log k ε ( t ) k , (1) where k · k denotes the ℓ 2 norm, exists and is a constant with p robab ility 1 . In other words, after a transient regime, the numb er of iter ations needed to reduc e th e erro r k ε k by a factor e is almost surely e qual to T c , which therefore ch aracterizes the speed o f con vergence of the alg orithm. T c is easy to measure in expe riments, and can b e theor etically upper bou nded. Howe ver lo wer bou nding this qu antity remains an open p roblem . Previous work defined the ǫ -av eraging time T ave ( ǫ ) , another quantity d escribing speed of con vergence [3] (see also [9] for a related analysis): Definition 1: ǫ -averaging time T ave ( ǫ ) . Gi ven ǫ > 0 , th e ǫ - av eraging time is the earliest time at which the vector Novem ber 1, 2018 DRAFT 7 x ( k ) is ǫ close to the normalized true average with pro bability g reater than 1 − ǫ : T ave ( ǫ ) = sup x (0) inf t =0 , 1 , 2 ... ( P k x ( t ) − x ave ~ 1 k k x (0) k ≥ ǫ ! ≤ ǫ ) . (2) Although T ave ( ǫ ) is hard to measure in practice because it req uires the ev alu ation of an infinite n umber of probab ilities, it is easily uppe r and lower b ound ed theoretica lly in terms of the spectral ga p (see Section I V). Indeed T ave ( ǫ ) contain s a p robab ility tolerance ǫ in its defin ition, which facilitates g reatly its an alysis. On the contrary , T c is ha rd to a nalyze theoretically because it is co nstrained by the exigency of its inherent deter minism. An importa nt issue is the behavior of T c and T ave as the number n of nod es in the network g rows. It can be shown th at T c ( n ) = O ( T ave ( n, ǫ )) fo r any fixed ǫ , b ut wheth er the two quantities are equ iv alen t an d un der which condition s is still an op en problem. Previous theoretical results summar ized in T able I refer to ǫ -averaging time. W e comp are algorithms in ter ms of the amount of required comm unication . Mo re specifically , let R ( t ) represent the numbe r of o ne-ho p radio tran smissions r equired in time-slot t . In a standa rd g ossip protoco l, the qu antity R ( t ) ≡ R is simply a c onstant, w hereas for our protoco l, { R ( t ) } t > 1 will be a sequence of i.i.d. rando m variables. The total communicatio n cost at time-slot t , measured in one-hop transmissions, is giv en by the rand om variable C ( t ) = P t k =1 R ( k ) . Consensus cost C c is de fined as fo llows [6]: Theor em 2: Consensu s cost C c . I f { S ( t ) } t > 0 is an indep endently and iden tically distributed (i.i.d.) pro cess, then the fo llowing limit exists and is a constan t with probability 1 : − 1 C c = lim t →∞ 1 C ( t ) log k ε ( t ) k = lim t →∞ t C ( t ) lim t →∞ log k ε ( t ) k t . Thus, C c = E [ R (1)] T c is the nu mber of one- hop transmission s needed in the long ru n to reduce the er ror by a factor e with p robability 1 . Similarly , we define th e expected ǫ -averaging cost C ave ( ǫ ) to be the expected commu nication cost in th e first T ave ( ǫ ) iterations of the algorithm: C ave ( ǫ ) = E [ C ( T ave ( ǫ ))] = E [ R (1)] T ave ( ǫ ) . I I I . P A T H A V E R AG I N G A L G O R I T H M S A. P ath a veraging o n random geometric graphs. The prop osed algo rithm co mbines gossip with rand om gr eedy geogra phic routing . A key assumption is that each node kn ows its location and is able to learn the geograph ic lo cations of its one-h op n eighbo rs ( for example u sing a sing le transmission pe r nod e). Also the nod es need to know the size of the space they are embed ded in. Note that while our results are developped for rando m geo metric top ologies, the alg orithm can be applied on any set of nodes emb edded on some com pact and co n vex r egion. The algo rithm operates as follows: at each time-slo t one ran dom node activ ates and selects a ran dom position (target) on the u nit squar e region where th e nod es are spread out. Note that n o node need s to b e located on the target, since th is would require glob al knowledge of locations. Th e node then c reates a packet that contains its current estimate of th e average, its position, th e num ber of visited no des so far (one ), the target location, and passes Novem ber 1, 2018 DRAFT 8 r(n) ? Node i ? ? ? Fig. 2. Random greedy routing. Node i has to choose the follo wing node in the route among the nodes that are his neighbors (inside the ball of radius r ( n ) centered in node i ) and that are closer to the target than i (inside the ball of radius centered in the target, where d is the distance betwee n node i and the tar get). Next node is thus randomly chosen in the intersect ion of the two balls. the packet to a neig hbor that is rando mly chosen among its neighb ors closer to the target . As nodes receive the packet, rand omly an d greed ily f orwarding it towards th e target, th ey a dd their value to th e sum and increase the hop counter . When the packet reaches its destination nod e ( the first node whose nearest neighb ors have larger distance to the target compa red to it), the destination nod e co mputes the average of all the nodes on the path , and rero utes that in formatio n backwards on the sam e r oute. See Fig. 2 f or an illustration of rando m greedy r outing. It is not hard to show [8] th at for G ( n, r ) whe n r scales like Θ( p log n/ n ) , gr eedy forwardin g su cceeds to reach the clo sest node to the ran dom target with high proba bility over graphs — in other words there are n o large ’holes’ in the network. W e will refer to this whole pro cedure of rou ting a message and averaging on a random path a s one gossip round which lasts for one time-slot, after which O ( p n/ log n ) nodes will replace their estimates with their joint av erage. W e prefer not to route the estimates by choosing the next nod e as the c losest neighb or to the target, b ut as on e rand om neigh bor closer to the target, because we observed that the latter is cheaper (smaller C c ). Note that the nodes do not n eed to k now the number of nodes n in the ne twork, they only n eed the size o f th e field on which they are deployed. B. Motivation –P erformanc e simulation s W e e xperimen tally measu red T c and C c in o rder to ev aluate the perfor mance of p ath av eraging on r andom geometric gr aphs with a growing numb er n of nodes in the u nit squa re. Fig 3(b) shows that o ur alg orithm behaves strikingly better than standard gossip and geog raphic gossip, when, fo r example, r ( n ) = p c log n/n with c = 4 . 5 . For oth er values of c , th e perfor mance of our algorith m also gr eatly imp roves pr evious go ssip schemes. Mo st importan tly , for small conn ection r adius r ( n ) (small c ), the nu mber of messages C c behaves almo st linearly in n Novem ber 1, 2018 DRAFT 9 15 20 25 30 35 40 45 7 8 9 10 11 12 13 14 sqrt (n) mean route length (a) Mean route length E ( R ) . 200 400 600 800 1000 1200 1400 1600 0 2 4 6 8 10 12 14 16 18 x 10 4 network size n number of messages Path averaging Geographic gossip Standard gossip (b) Consensus cost C c : compare three methods 200 400 600 800 1000 1200 1400 1600 1800 2000 2000 4000 6000 8000 10000 12000 14000 16000 number of messages network size n (c) C c : path avera ging, r ( n ) = p 4 . 5 log n/n 200 400 600 800 1000 1200 1400 1600 1800 2000 2000 4000 6000 8000 10000 12000 number of messages network size n (d) C c : path avera ging, r ( n ) = p 25 log n/n Fig. 3. Performance of path ave raging. The simulations were performed ove r 15 graphs per n . A veraging time was measured here by T c ≃ ( t 1 − t 2 ) / [log k ǫ ( t 2 ) k − log k ǫ ( t 1 ) k ] for t 1 = 500 and t 2 = 1750 . (a) The mean route length in random greedy routing behav es in p n/ log n . (b) Comparison betwee n standard gossip, geogra phic gossip (without reject ion sampling) and path av eragin g with r ( n ) = p 4 . 5 log n/n . (c), (d) Consensus costs C c = E [ R ] T c for radii r ( n ) = p 4 . 5 log n/n and r ( n ) = p 25 l og n/n . (see Fig. 3(c)), and as c increases, the behavior improves (see Fig. 3(d )). The slight super-linearity in Fig.3(c) is due to small r ( n ) and p ossibly edge effects. Clearly , we cann ot expect better than linear behavior in n because at lea st n messages are necessary to average n values. Theref ore path a veraging with greedy routing seems to be optimal for suf ficiently large co nstant c . Unfortu nately , the theoretical analysis of path averaging with greed y routin g seems intracta ble. Howev er , with a slight modification in the routing algorithm, a nd by ignoring ed ge effects, we are able to analyze p ath a veraging, first fo r grid s and th en fo r regular ge ometric grap hs. Recall that ran dom geo metric graph s are r egular geometr ic graphs with h igh pro bability wh en n large if c is sufficiently large ( Section II-B). C. ( ↔ , l ) - path averaging on grids The first step in our an alysis is understan ding the behavior of path averaging on regular grids using a simple routing scheme. Throug hout this paper, a grid of n nodes will be a 4-con nected lattice on a torus of size √ n × √ n . ( ↔ , l ) -path a veraging per forms as follows: At each iteration t , a rand omly selected node I wakes up and selects Novem ber 1, 2018 DRAFT 10 I J (a) ( ↔ , l )-route (b) box-pat h av eraging Fig. 4. (a) Shortest ( ↔ , l )-route from I to J on the grid. (b) Example of box-path avera ging on an RGG: The node with inital va lue 3 selects a random position and plac es a targe t. Using ( ↔ , l ) -box routing to wards that target, all the nodes on the path replace their va lues with the av erage of the four nodes. a r andom destination node J so that the pair ( I , J ) is indep endently and uniformly distrib uted. N ode I also flips a fair co in to d esign the fir st direction : horizon tal ( ↔ ) or vertica l ( l ). If fo r instance horizontal was picked as the first direction , the path b etween I and J is then defined b y th e shortest h orizontal- vertical route between I and J (see Fig. 4(a)). Th e estimates of all the nodes on this p ath are aggregated an d av eraged by messages p assed on this path, an d at the end of the iteration th e estimate s of the nod es on th is path ar e u pdated to their glob al average. Clearly , this message- passing procedu re can be executed if e ach node k nows its location o n the g rid. D. Box-p ath averaging on re gular geometric graphs As seen in Section II -B, a r egular geometric grap h can be organized in virtual square s with the tr ansmission radius r ( n ) selecte d so that a node can pass messages to any no de in the fo ur squar es adjacent to its o wn square. In box -path averaging, whe n a node activ ates, it chooses unifor mly at ran dom a target location in the unit toru s and its initial d irection: horizo ntal or vertical. Th en a n ode is selected u niform ly fro m the on es in the adjacen t square in th e righ t direction. (Recall that r egularity ensures that w .h.p . Θ (log n ) nodes will b e in each square.) The routing sto ps w hen th e message reaches a no de in the squ are wh ere th e target is located . As in th e pre vious path av eraging algo rithms, the e stimates of all the nodes on the path are a veraged and all the node s replace their values with this estimate (see Fig. 4( b)). The key po int is that box -path a verag ing can b e executed if each n ode knows its loca tion, the locations of its one- hop neighb ors and th e total number of nodes n , because with this k nowledge each nod e can figure o ut which squ are it belo ngs to and p ass messages app ropriately . Novem ber 1, 2018 DRAFT 11 ? S T ? ? ? S T ? ? Fig. 5. Choosing next node in the route. On the left: random greedy routing, on the right: ( l , ↔ ) -box routing. It is easy to see that the two choice areas contain on av erage Θ(log n ) nodes. Box-greed y routing is a regularized version of random g reedy rou ting, and is introd uced to make the analy sis tractable. Both ro uting sche mes proce ed by c hoosing the next hop amo ng Θ(log n ) nodes (Fig. 5). Box -greedy rout- ing ge nerates ro utes with Θ( p n/ log n ) hop s on average, an d rand om greedy ro uting do es as well o n experim ents (Fig. 3(a)). W e are now r eady to start the theoretica l an alysis of the aforementio ned path averaging a lgorithms. I V . A N A LY S I S A. A veraging and eigenvalues. Let x ( t ) den ote the vector of estimates of th e g lobal averages after the t th gossip r ound , wh ere x (0) is the vector of initial m easurements. Any gossip algo rithm can be described by an equ ation of the f orm x ( t + 1) = W ( t ) x ( t ) , (3) where W ( t ) is the averaging matrix over the t th time-slot. W e say that the algorithm co n verges almost surely ( a.s.) if P [lim t →∞ x ( t ) = x ave ~ 1] = 1 . It converges in expectation if lim t →∞ E [ x ( t ) − x ave ~ 1] = 0 , and there is mean square con vergence if lim t →∞ E [ k x ( t ) − x ave ~ 1 k 2 ] = 0 . There are two n ecessary conditio ns f or convergence: ~ 1 T W ( t ) = ~ 1 T W ( t ) ~ 1 = ~ 1 , (4) which respectively en sure that the av erage is preserved at e very iteratio n, and that ~ 1 is a fixed point. For any linear distributed averaging alg orithm following (3) where { W ( t ) } t ≥ 0 is i.i.d., cond itions for con vergence in expectatio n and in me an sq uare can be found in [2]. In g ossip algorithm s, W ( t ) are symmetr ic and projectio n matrices. T ak ing into a ccount th is par ticularity , we can state specific c ondition s for co n vergence. Let λ 2 ( E [ W ]) be the seco nd largest eigenv alue in magn itude of the expectation of the av eraging matrix E [ W ] = E [ W ( t )] . If conditio n (4) h olds and if λ 2 ( E [ W ]) < 1 , then x ( t ) converges to x ave ~ 1 in expectation and in mean squar e. In the case where { W ( t ) } t ≥ 0 is station ary and ergodic (and th us in par ticular when { W ( t ) } t ≥ 0 is i.i. d.), sufficient condition s for a.s. convergence can be proven [5]: if the go ssip com munication ne twork is conn ected, the n the Novem ber 1, 2018 DRAFT 12 estimates of gossip con verge to the global average ¯ x av e with probab ility 1 . More precisely , define T η := inf { t ≥ 1 : Q t p =0 W ( t − p ) ≥ η > 0 } . T η is a stopping time. If E [ T η ] < ∞ , then th e estimates converge to the global av erage with probab ility 1 . I n other words, e very node has to e ven tually connect to the network, whic h has to be jointly con nected. Interestingly , the value of λ 2 ( E [ W ]) , that appear s in the criter ia of co n vergence in expe ctation and of me an square convergence, con trols the speed of con vergence : T c ( E [ W ]) 6 2 log 1 λ 2 ( E [ W ]) ≤ 2 1 − λ 2 ( E [ W ]) . (5) A straightfor ward extension of the p roof of Boyd et al. [ 3] from the case of p airwise averaging matrices to the case o f symme tric projection averaging matrices yield s the fo llowing bo und on the ǫ -averaging time, which a lso in volves λ 2 ( E [ W ]) : T ave ( ǫ, E [ W ]) ≤ 3 log ǫ − 1 log 1 λ 2 ( E [ W ]) ≤ 3 log ǫ − 1 1 − λ 2 ( E [ W ]) . (6) There is also a lower b ound of th e same or der, which implies that T ave ( ǫ, E [ W ]) = Θ (log ǫ − 1 / (1 − λ 2 ( E [ W ]))) . Consequently , the rate at wh ich the spectral gap 1 − λ 2 ( E [ W ]) appro aches zero a s n increases, contro ls both the ǫ -averaging tim e T ave and the c onsensus time T c . For example, in the case o f a complete gr aph and uniform pairwise gossiping, on e can show that λ 2 ( E [ W ]) = 1 − 1 /n . Therefo re, as p reviously mentioned , the con sensus time o f this scheme is O ( n ) . In p airwise gossipin g, the convergence time an d the num ber of messages have the same order becau se there is a constant n umber R o f transmissions per tim e-slot. In geogr aphic g ossip and in p ath av eraging on rando m geo metric graphs, one rou nd uses many messages fo r the path routin g ( p n/ log n m essages on av erage), h ence m ultiplying the order o f consensus time T c ( n ) by p n/ log n g iv es the order of consen sus cost C c ( n ) . B. The tr avel agency method A d irect c onsequen ce o f the p revious sectio n is tha t the ev aluatio n of consensus time requ ires an accurate upper bound on λ 2 ( E [ W ]) . Conseq uently , compu ting th e av eraging time of a scheme takes two steps: (1) ev alu ation of E [ W ] , (2 ) upperb ound of its secon d largest eigen value in magnitu de. E [ W ] is a doubly stochastic m atrix that correspo nds to a time-reversible Markov Cha in. W e can therefo re use techniques d ev eloped for boun ding the spectral g ap of Markov Chains to bo und the conv ergence time of gossip. In particu lar , we will use Poin car ´ e’ s inequa lity by Diaconis and Stro ock [7] ( see also [4], p. 212 - 21 3 and the related canon ical p aths techniqu e [ 23]) to d evelop a boun ding technique for g ossip. Theor em 3 (P o incar ´ e’ s inequ ality [7]): Let P deno te an n × n irredu cible and rev ersible stoc hastic matrix, and π its left eigenv ector associated to the eigenv alue 1 ( π T P = π T ) such that P n i =1 π ( i ) = 1 . A pair e = ( k , l ) is called an edge if P kl 6 = 0 . For ea ch ordere d pair ( i, j ) where 1 6 i, j 6 n , i 6 = j , choose on e and o nly one path γ ij = ( i , i 1 , . . . , i m , j ) between i an d j such that ( i, i 1 ) , ( i 1 , i 2 ) , . . . , ( i m , j ) are all edges. Define | γ ij | = 1 π ( i ) P ii 1 + 1 π ( i 1 ) P i 1 i 2 + . . . + 1 π ( i m ) P i m j . (7) Novem ber 1, 2018 DRAFT 13 The Poincar ´ e coefficient is define d as κ = max edge e X γ ij ∋ e | γ ij | π ( i ) π ( j ) . (8) Then the seco nd largest eigenv alu e of P verifies λ 2 ( P ) ≤ 1 − 1 κ . (9) W e will app ly this theorem with P = E [ W ] . Here π ( i ) = 1 /n for all 1 6 i 6 n . The co mbination of Poincar ´ e inequality with bou nds 5 and 6 f orms a versatile techn ique fo r bo unding the perfor mance o f go ssip algorithm s that we c all the tr avel agency metho d. It is crucial to un derstand that the edges used in the application o f the theore m a re abstract and d o not co rrespond to actual edg es in the physical network. They instead co rrespon d to paths o n which th ere is joint av eraging, an d hence informatio n flow , through m essage- passing. Consider the following analog y . Imag ine that n airpo rts ar e positioned at the locations of the nod es of the network. In this scenario , we are given a tab le P = E [ W ] o f the flight capa cities (number of passengers per time unit) b etween any pair of airpo rts a mong the n airports. A g ood averaging intensity E [ W ij ] be tween nodes i and j co rrespon d to a good capa city flight between airpo rts i and j in the travel age ncy metho d. He re edges e are existing flights and, in our specific case, there is the same nu mber of travelers in all the air ports ( π ( i ) = 1 /n for all i ) . W e are asked to design one an d on ly one roa d map γ ij between ea ch pair of airpo rts i and j that av oids congestion and multiple ho ps. | γ ij | measur es the level of c ongestion between airp ort i and air port j . The th eorem tells us that if we can co me u p with a road map that av oids significant con gestion on the worst flight (i.e . if κ is small), then we will have proven that the flying network is efficient ( λ 2 is small). The previous boun ds 5,6 can now b e used to b ound the co nsensus time an d consen sus co st. One of the importan t benefits of this b ound ing te chnique is th at we do not need know th e entries o f E [ W ] to bound the av eraging cost, and o nly good lower bound s suffice. In terms of the an alogy , w e only n eed to kn ow that each flight ( i, j ) has at least cap acity C i,j . If ( i, j ) can actually car ry mo re passengers ( P i,j > C i,j ), then our measure o f congestion κ will be overestimated. While o ur final u pper-boun ds w ill not be a s tight as they cou ld have been if w e had exact k nowledge o f E [ W ] , they suffice to establish the optimal asympto tic b ehavior . C. Example: stand ar d go ssip r evisited In or der to illustrate the generality of our techn ique, we show how to app ly it on simple examp les, by giving sketches of novel proofs for kn own results o n n earest neighb ors gossip on the complete graph and on the rando m geometric grap h. 1) Complete graph : For any i 6 = j , E [ W ij ] = 1 /n 2 . Ind eed W ij = 0 . 5 when node i wakes up ( ev ent of probab ility 1 /n ) and chooses node j (event of p robab ility 1 / n as well), or when j wakes up and ch ooses i . W e apply now the travel agency method . W e see in E [ W ] that all fligh ts have equal capacity 1 / n 2 and that there are Novem ber 1, 2018 DRAFT 14 direct fligh ts between any pair of airpor ts. W e choose he re the simple st ro ad m ap on e cou ld thin k of: to go from airport i to airpo rt j , each trav eller should take the direct hop γ ij = ( i , j ) . Then the sum in (7) has on ly on e ter m: | γ ij | = n 3 . In this case all flig hts a re equ al and one flight e = ( i, j ) belongs on ly to one road map: γ ij . Thus the sum in (8) also has o nly one term and κ = n 3 / ( n · n ) = n . Theref ore λ 2 ( E [ W ]) 6 1 − 1 / n , which proves that T c ( n ) = O ( n ) . No te that the complete graph is the overlay network of geo graphic gossip 2 (every pair of nod e can be averaged at the expense of routin g), wh ich thus p erfor ms in C c ( n ) = O ( n p n/ log n ) . 2) Ran dom geometric graph (RGG): W e show in the A ppend ix that if th e conn ection radius r ( n ) is la rge enoug h, then RGGs are regular with high probab ility , i.e. the nod es are very regularly spread out in the unit squ are, which implies th at each node has Θ(log n ) neighbo rs. T o keep th e illustration of the travel agency meth od simp le, we assume that the n odes lie on a torus (no bord er effects). Con sider th e p air o f no des ( i, j ) . If i and j are no t neighbo rs, th en E [ W ij ] = 0 ; if i and j are neighbo rs, th en E [ W ij ] = Θ (1 / ( n log n )) becau se no de i wakes u p w ith probab ility 1 /n and chooses node j with pro bability Θ (1 / log n ) . W e now h ave to create a roadma p with on ly short distance paths. Regularity en sures that there ar e no isolated n odes that cou ld create local con gestion. W e thus naturally decide that the b est way to go is to select p aths along the straighte st possible line between the departure airport and the destination airpor t. This will requ ire O ( p n/ log n ) hops, ther efore the right hand sid e of Equation (7) is the sum of O ( p n/ log n ) terms, eac h of equ al order: | γ ij | = O r n log n 1 1 /n Θ 1 1 /n lo g n = O ( n 2 p n log n ) . (10) Now we n eed to com pute in how many path s e ach particular flight is used. It follows from our regularity and toru s assumptions th at each fligh t ap pears in app roximatively the same num ber of road maps. T here are n 2 paths th at use O ( p n/ log n ) flights, but there are only Θ( n log n ) different flights, hence each fligh t is used in O ( n/ log n ) 1 . 5 paths. W e can now compute the Poincar ´ e coefficient κ . W e drop the max e argument in Equation (8) because all flights are eq ual. As π ( i ) = π ( j ) = 1 /n , κ = X γ ij ∋ e O ( n 2 p n log n ) 1 n 1 n (11) = O ( n log n ) 1 . 5 O ( p n log n ) (12) = O ( n 2 log n ) , (13) which proves that T c ( n ) = O ( n 2 / log n ) . 3) Comments: The proof of the per forman ce of path averaging on a RGG gi ven in Sectio n B g iv es insight on how to comple te this last proof . It is in teresting to see th at the travel agency metho d describes how inform ation will diffuse in the network. In the second example, far away nodes will n ev er directly average th eir estimates, b ut they will do it indirectly , u sing the no des between the m. Note that our me thod does not giv e lower -bo unds on λ 2 ( E [ W ]) , w hich would be usefu l to g iv e an eq uiv alen t order f or ǫ -averaging time T ave . In the c ase of path a veraging, th is is not an issue since it is not possible to achieve 2 In reality , geographic gossip will not be completel y uniform but rejectio n sampling can be used [8] to tamper the distributi on Novem ber 1, 2018 DRAFT 15 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 x 10 −5 d(i,j) E[W ij ] Standard gossip Geographic gossip Box−path averaging Fig. 6. Be hav ior of E [ W ij ] as a function of the distanc e in norm 1 betwe en i and j for standard gossip, geographic gossip and box-pat h av eraging. better than the con sensus cost C c ( n ) = Θ( n ) . So if the m ethod shows that T c ( n ) = O ( √ n log n ) , we h av e that C c ( n ) = O ( √ n log n ) O ( p n/ log n ) = O ( n ) and we can conclude that C c ( n ) = Θ( n ) . D. Main Results The main results of this pap er is that the consen sus cost of ( ↔ , l ) -path av eraging o n g rids and of bo x-path av eraging on ran dom geometric graph s, b ehave linea rly in the nu mber of nod es n : Theor em 4 ( ( ↔ , l ) -path averaging on grids): On a √ n × √ n torus grid, the con sensus time T c ( n ) of ( ↔ , l ) - path av eraging, d escribed in Section II I-C, is O ( √ n ) . Furtherm ore, the consensu s cost is lin ear: C c ( n ) = O ( n ) . Theor em 5 (Bo x-path averaging on RGG) : Consider a rand om geometric gr aph G ( n, r ) on the u nit toru s with r ( n ) = q c log n n , c > 10 . W ith h igh probab ility over graphs, the consensus time T c ( n ) of box- path averaging, described in Sec tion III-D, is O ( √ n log n ) . Furthe rmore, the consensus cost is linear: C c ( n ) = O ( n ) . The pro ofs of Theorem 4 and Theo rem 5 are given in th e Appen dix. Both proofs h av e the same struc ture: we first lower bound the en tries of E [ W ] an d next upp er boun d its secon d largest eigen value in magnitude. Figure 6 shows the behavior of E [ W ij ] as a fun ction of the L 1 distance between n odes i and j fo r standar d gossip, geogr aphic gossip and p ath averaging; respectively the pro ofs give us the insight beh ind the good p erform ance of box -path averaging compare d to stand ard gossip and geog raphic gossip b y simply analysing Fig. 6. Box- path a veraging concentrates the a veraging inten sities E [ W ij ] of nod e i in th e ar ea of nodes j close to i . Indeed, the closer two no des, the higher the probab ility that th ey are on th e same rou te. Th us, as we can observe on Fig. 6, close nod es have a much higher av eraging intensity E [ W ij ] than in geo graphic gossip, where nodes are eq ually rarely av eraged together (the proof shows an o rder p n/ log n high er). However , the averaging in tensity gained by close n odes is lost for far away nodes, which do not average toge ther well anymore (a factor n loss compare d to geograph ic gossip). Novem ber 1, 2018 DRAFT 16 In terms of the travel agen cy method, in box- path averaging over the unit are a torus, flights with that cover distances shor ter th an 1 / 2 h av e high capacity , whe reas long distance fligh ts are rar e. T o apply the method, the id ea is to cho se 2 -h op paths: to go from no de i to node j , the path will con tain two hops that stop half way , in o rder to exclusiv ely and fairly use the high capacity flights. Rememb er that standard gossip needs p n/ log n flights per path (see Section IV -C.1), which heavily pena lizes the perform ance despite a very hig h averaging intensity E [ W ij ] for neighbo ring nodes i and j (see Fig. 6, where E [ W ij ] is la rge fo r neighbor ing nodes but falls to 0 fo r distances larger than r ( n ) ). Th e p erform ance o f path averaging algorithms is good thank s to a diffusion scheme requir ing only O (1) flights in each p ath an d O (1) uses of ea ch flight in the road map, co mbined with a high enough le vel of averaging intensity E [ W ij ] . Each node can act as a d iffusion relay fo r som e far away no des, so that th e who le network can ben efit from the c oncentra tion of the averaging intensity . As a summ ary , in c ontrast with g eograp hic gossip, path averaging and stan dard g ossip co ncentrate their averaging intensity on close nod es, wh ich lea ds to larger coefficients E [ W i,j ] when no des i an d j a re close eno ugh. H owe ver, while standard g ossip pays fo r its concentr ation with lo ng pa ths overusing ev ery existing fligh t, the diffusion p attern of path averaging operates in 2 steps only witho ut cr eating any cong estion (mo re p recisely , we comp ute in the proo f that each flig ht is used in at most 9 paths). In co nclusion, the analysis shows that path averaging achieves a g ood tradeoff between promoting local averaging to increase a veraging intensity (large E [ W ij ] ) and favoring l ong distance av eraging to get an effi cient diffusion pattern (every path γ ij contains on ly O (1 ) ed ges, and every ed ge e app ears in on ly O (1) paths). V . C O N C L U S I O N S W e intro duced a novel gossip algorithm for distributed a verag ing. The proposed algorithm operates in a distributed and asynchro nous man ner on locally connected graph s and r equires an order-optima l nu mber o f commu nicated messages for random geometric g raph a nd grid to polog ies. The execution of path averaging r equires that each n ode knows its own location , th e loca tions of its nearest-ho p neigh bors and ( for the routing- scheme that was th eoretically analyzed) the total number of no des n . Location inform ation is indepen dently useful and likely to exist in many app lication scenarios. The key idea that makes path averaging so efficient is the oppo rtunistic combinatio n of routing and averaging. The issues o f delay (how se veral p aths can be con curren tly a verag ed in the network) and fault tolerance (r obustness and recovery in failures) remain as interesting f uture work. More generally , we belie ve that the idea of greedily routing towards a rando mly p re-selected target (and processing informa tion on the routed path s) is a very useful primitiv e for design ing message-p assing algorith ms on networks that h ave some geometry . The reason is that the target in trodu ces some d irectionality in the sch eduling o f m essage passing which avoids diffusi ve behavior . Other than compu ting linear functions, such path -proc essing algorithms can be de signed for infor mation dissemination o r more gen eral message passing co mputatio ns such as ma rginal computatio ns or MAP estimates fo r probab ilistic graphical mod els [22]. Sche duling the m essage-passing using some Novem ber 1, 2018 DRAFT 17 form of linear paths can accelerate the communicatio n requir ed f or the conver gence o f such algorithm s. W e plan to investi gate such protocols in futur e work. R E F E R E N C E S [1] D. Bertsekas and J. Tsitsiklis. P arallel and Distributed Computation: Numerical Methods . Athena Scientifi c, Belmont, MA, 1997. [2] S. Boyd, A. Ghosh, B . Prabhakar , and D. Shah. Analysis and optimization of randomized gossip algorithms. I n P r oceedings of the 43rd Conferen ce on Decision and Contro l (CDC 2004) , 2004. [3] S. Boyd, A. Ghosh, B. Prabhakar , and D. Shah. Rand omized gossip algorithms. In IEEE T ransaction s on Information Theory , Special issue of IEE E T ransactions on Information Theory and IEEE/ACM T ransactions on Networking , 2006. [4] P . Br ´ emaud. Marko v Chains. Gibbs F iel ds, Monte Carlo Simulation, and Queues . Springer , 1999. [5] P . Denantes. Performance of av eraging algorithms in time-varying networks. T echnical report, EPFL, 2007. [6] P . Denantes, F . B ´ en ´ ezit, P . Thiran, and M. V etterli. Which distri buted averag ing algorithm should i choose for my sensor network? In Pr oc. IEEE Infocom , 2008. [7] P . Diaconis and D. S troock. Geometric bounds for eigen values of marko v chains. In Annals of Applied P r obability , volume 1, 1991. [8] A. G. Dimakis, A. D. Sarwate, and M. J. W ainwright. Geographic gossip: efficient aggrega tion for sensor networks. In ACM/IEEE Symposium on Information Pro cessing in Sensor N etworks , 2006. [9] F . Fagna ni and S. Z ampieri. Randomized consensus algorithms ov er large scale networks. In IEEE J. on Selected Ar eas of Communications, to appear , 2008. [10] A. E. Gamal, J. Mammen, B. Prabhakar , and D. Shah. Throughput-delay trade-of f in wireless networks. In Proc eedings of the 24th Confer ence of the IEEE Communications Society (INFOCOM 2004) , 2004. [11] P . Gupta and P . Kumar . The capacity of wireless netw orks. IE EE Tr ansactions on Information Theory , 46(2):388–404, March 2000. [12] D. Kempe, A. Dobra, and J. Gehrke. Gossip-based computation of aggre gate information. In Pro c. IEE E Confer ence of F oundations of Computer Science, (FOCS) , 2003. [13] W . Li and H. Dai. Location-aided fast distributed conse nsus. In IEEE T ransac tions on Information Theory , submitted , 2008. [14] C. Moallemi and B. V . Roy . Consensus propagation. I n IEEE T ran sactions on Information T heory , 2006. [15] D. Mosk-Aoya ma and D. Shah. Information dissemination via gossip: Applications t o av eraging and coding. http://arxiv .org/cs.NI/0504 029, April 2005. [16] R. Motwani and P . Raghav an. Randomized Algorithms . Cambridge Uni versity Press, Cambridge, 1995. [17] A. Nedic, A. Olshevsk y , A. Ozdaglar , and J. T sitsiklis. On distributed averaging algorithms and quantization effects. In LIDS T echnical Report 2778, MIT ,LIDS, submitted for publication , 2007. [18] M. Penrose. Random Geometric Graphs . Oxford studies in probability . Oxford Univ ersity Press, Oxford, 2003. [19] M. Rabbat, J. Haupt, A.Singh, and R. Nowa k. Decentralized compression and predistribution via rando mized gossiping. In ACM/IEEE Confer ence on Information Proc essing in Sensor Networks (IPSN’06) , April 2006. [20] V . S aligrama, M. Alanyali, and O. S av as. Distributed detection in sensor networks with packet l osses and finite capacity links. In IEE E T ransactions on Signal Process ing, to appear , 2007. [21] S. Sangha vi, B. Hajek, and L. Massoulie. Gossiping wit h multiple messages. I n IEEE T ransactions on Information Theory , to appear , 2008. [22] J. Schiff, D. Antonelli, A. G. D imakis, D. Chu, and M. W ainwright. Robust message-passing for statisti cal inference in sensor networks. In Proce edings of t he Sixth International Symposium on Information Pro cessing in Sensor Networks , April 2007. Novem ber 1, 2018 DRAFT 18 [23] A. Sinclair . Improv ed bounds for mixing rates of marko v chains and multicommodity flow . In Combinatorics, Proba bility and Computing , volume 1, 1992. [24] D. Spanos, R. Olfati-Saber , and R. Murray . Distributed Kalman fi ltering in sensor networks with quantifiable performance. In 2005 F ourth International Symposium on Information Processin g in Sensor Networks , 2005. [25] M. J. C. T . C. A ysal and M. G. Rabbat. Rates of con verge nce of distributed average consensus using probabilistic quantization. In Proc. of t he Allerton Conferen ce on C ommunication, Contr ol, and Computing , 2007. [26] J. Tsi tsiklis. Pr oblems in decentr ali zed decision-making and computation . PhD t hesis, Department of EE CS, MIT , 1984. [27] L. Xiao, S. Boyd, and S. L all. A scheme for asynchro nous distributed sensor fusion based on average consensus. In 2005 F ourth International Symposium on Information Pr ocessing in Sensor Networks , 2005. V I . D E FI N I T I O N S A. Notation • G ( n, r ) or RGG : r andom geom etric graph with n n odes and co nnection radius r . • x (0) : vector of th e initial values to be a vera ged. • ¯ x av e = P n k =1 x k (0) /n . • x ( t ) : vector of th e estimates o f the average. • S ( t ) : the random set of n odes that average together at time- slot t . • R ( t ) : number of one h op transmission s at time-slot t . • ǫ ( t ) = x ( t ) − ¯ x av e ~ 1 : error vector, wher e ~ 1 is th e vector of all o nes. • W ( t ) : a verag ing matrix at tim e t . • λ 2 : second largest eigenv alu e in magnitude. • γ ij : path startin g in i and endin g in j . • | γ ij | measur es the “resistance” o f path γ ij (Eq. (7)). • κ : Poin car ´ e co efficient ( Eq. (8)). • T ave ( ǫ ) : ǫ - av eraging time (Def. 2) • C ave ( ǫ ) = E [ R (1)] T ave : expected ǫ -averaging co st. • T c , C c : consen sus time, consensus co st (Def. 1, 2). B. List o f the a lgorithms • Standar d gossip: pairwise go ssip where only direct neighbo rs can average their estimates to gether . • Geogr aphic gossip: pa irwise gossip where any pair of no des can average th eir estima tes togeth er at the expense of routin g. • Path averaging: at each iteration a rand om route is created by random greedy ro uting in an RGG. Th e nodes of the route average their estimates to gether . • ( ↔ , l ) -p ath a veraging: at each itera tion a rand om ro ute is created by ( ↔ , l ) -rou ting on a grid (embed ded o n a toru s in the ana lysis). The nod es of the route average their estimates to gether . • Box-p ath routing: at each iter ation a rand om route is crea ted by b ox-ro uting o n a regular geo metric graph (embedd ed o n a toru s in the an alysis). The no des of the route a verage their estimates to gether . Novem ber 1, 2018 DRAFT 19 A P P E N D I X A. P erformanc e of ( ↔ , l ) -path averaging on a grid This section pro oves Theorem 4, which states the linearity of consensu s c ost fo r ( ↔ , l ) -p ath averaging o n a grid. The analyze d algorithm is d escribed in Section III-C. 1) Notation : W e need to de fine th e shortest distance on a to rus. T o this end, we introd uce a to rus absolute value | . | T and a torus L 1 norm k . k 1 . For any alg ebraic value x on a o ne d imensional torus (circle with √ n nod es) and any vector i on a √ n × √ n two dim ensional torus, | x | T = min( | x | , | x − √ n | , | x + √ n | ) k i k 1 = | i x | T + | i y | T . W e call ℓ ij = k j − i k 1 the L 1 distance be tween nodes i and j . The shortest routes between I an d J have α = ℓ I J + 1 = | J x − I x | T + | J y − I y | T + 1 n odes to be averaged, thus the non -zero coefficients of their correspo nding matr ices W are all equal to 1 /α . T o each ro ute r , we assign a generalized gossip n × n matrix W ( r ) that averages the current estimates o f the nodes o n the ro ute. Con sequently , at iteratio n t , W ( t ) = W ( r ( t )) , where r ( t ) was rando mly chosen . W e call R the route random v a riable, s ( R ) its starting nod e, d ( R ) its destination node, an d ℓ ( R ) = ℓ s ( R ) d ( R ) + 1 its number of nodes. As we ch oose the sho rtest route, the max imum nu mber of n odes a r oute ca n contain is √ n if √ n is odd, √ n + 1 if √ n is even, which can be wr itten as 2 ⌊ √ n/ 2 ⌋ + 1 in short. 2) Evalu ating E [ W ] : Lemma 1: (E xpected E [ W ] o n th e grid) For any pair of nod es ( i, j ) , if their d istance n ormalized to the maxim um distance δ ij = k j − i k 1 / √ n is smaller than a co nstant, then E [ W i,j ] = Ω 1 n 1 . 5 . (14) More prec isely , E [ W i,j ] ≥ 2(1 − δ ij + δ ij log δ ij ) n √ n . Therefo re, as expected, far away no des are less likely to be jointly averaged compare d to neig hborin g on es (see Figure 6). Pr oof: Observing that E [ W ( R ) | ( ↔ , l )] = E [ W ( R ) | ( l , ↔ )] because the ro ute from a nod e I to a node J horizon tally first h as the same nodes as the ro ute from J to I vertically first, we get E [ W ] = E [ W ( R ) ] = 1 2 E [ W ( R ) | ( ↔ , l )] + 1 2 E [ W ( R ) | ( l , ↔ )] = E [ W ( R ) | ( ↔ , l )] . So, for a given pa ir o f no des ( i, j ) , we can comp ute the ( i, j ) th en try of th e m atrix expectatio n E [ W ] by systematically routin g first horizo ntally . On ly the ( ↔ , l ) - routes which contain bo th these two no des i and j will Novem ber 1, 2018 DRAFT 20 j i Fig. 7. Counting the number of routes of length ℓ = 9 nodes, in the case where ℓ ij = 5 . There are ℓ − ℓ ij = 9 − 5 = 4 possible routes with exa ctly ℓ nodes going through node i then through node j . W e admit only routes going horizontall y first then vertical ly . have a non -zero co ntribution in E [ W ij ] . Pick such a rou te r , the ( i, j ) th e ntry of the correspon ding averaging matrix is W ( r ) i,j = 1 /ℓ ( r ) . W e call R ℓ ij the set o f ( ↔ , l )-r outes with ℓ nodes p assing by node i and by nod e j , and denote x + = max( x, 0) . It is not hard to see that ( ℓ − ℓ ij ) + is the numb er of routes o f length ℓ passing by i first and j next (see Fig. 7) , so |R ℓ ij | = 2( ℓ − ℓ ij ) + . W e th us have f or any i 6 = j : E [ W i,j ] = X r W ( r ) i,j P [ R = r ] = 1 n 2 X r W ( r ) i,j = 1 n 2 2 ⌊ √ n 2 ⌋ +1 X ℓ = ℓ ij +1 |R ℓ ij | ℓ = 2 n 2 2 ⌊ √ n 2 ⌋ +1 X ℓ = ℓ ij +1 ℓ − ℓ ij ℓ , from which we can dedu ce that for i 6 = j E [ W i,j ] ≤ 2 n 2 Z √ n +2 ℓ ij +1 x − ℓ ij x dx = 2 n 2 √ n − ℓ ij + 1 − ℓ ij ln √ n + 2 ℓ ij + 1 E [ W i,j ] ≥ 2 n 2 Z √ n ℓ ij x − ℓ ij x dx = 2 n 2 √ n − ℓ ij − ℓ ij ln √ n ℓ ij . E [ W i,j ] de creases fro m 2 n √ n to o ( 1 n 2 ) as a function o f ℓ ij . T o get a no rmalized expression with respect to √ n , we Novem ber 1, 2018 DRAFT 21 use the co efficient δ ij defined in th e statement o f Lemma 1. 2 n √ n (1 − δ ij + δ ij ln δ ij ) ≤ E [ W i,j ] ≤ 2 n √ n 1 − δ ij + δ ij ln δ ij + 1 √ n − δ ij ln √ n + 2 √ n + 1 δ ij ! . This establishes the claim. In particu lar , if δ ij = 1 / 2 , th en E [ W i,j ] ∼ 1 − ln 2 n √ n . 3) Bou nding λ 2 ( E [ W ]) : W e nee d now to up perbou nd th e second largest eigen value in mag nitude o f E [ W ] , or equiv alently , the rela xation time 1 / (1 − λ 2 ( E [ W ])) . Lemma 2 ( Relaxation time): 1 1 − λ 2 ( E [ W ]) = O ( √ n ) . (15) Pr oof: The Poincar ´ e inequality (Theor em 3) b ound s the second largest eigenv alu e of a stoch astic matrix and not n ecessarily its secon d largest eig en value in magnitude , which is the impor tant q uantity inv olved in Eq. (5) . It cou ld happ en that the smallest n egativ e eigenv alu e is larger in mag nitude than th e secon d largest eigenv alu e. Consequently , if we show that all the eige n values o f E [ W ] ar e positive, then the two eigenv alues co incide and we can use the Po incar ´ e in equality to b ound the seco nd largest eigenvalue in magnitud e. E [ W ] is symm etric so all its eigenv alues are real. Th e sum of all the entries along the lines of E [ W ] without counting the diagonal elemen t is O (1 / √ n ) , w hereas th e diagonal elements are Θ(1) , so b y Ger shgorin bou nd [4], all th e eigenvalues of E [ W ] are positive. W e can now use the b ounds on E [ W ] to bo und its spectral gap. W e want to prove th at path a veraging performs √ n better than geogr aphic gossip, where E [ W i,j ] = 1 /n 2 (IV - C.1). It is enco uraging to note that for δ ij 6 1 / 2 , E [ W i,j ] > 1 − ln 2 n √ n , which is precisely √ n better than 1 /n 2 . W e thus observe that it is possible to find edg es with a good c apacity with leng th e qual to half of the whole g raph. However very d istant destinations remain prob lematic. Consid er the extreme c ase of a distance √ n between two nodes i and j . There are only two routes that will jointly average them: the route that go es from i to j , and the re verse on e. These routes are selected with pr obability 1 /n 2 and W ij = 1 / √ n , imp lying that E [ W ij ] = 2 /n 2 . 5 ≪ 1 /n 1 . 5 . Formally , for each or dered and distinct pair ( i, j ) , we choose a 2-ho p path γ ij from i to j stoppin g by an “airport” node k cho sen to be located approx imatively half way between i and j . T o be mo re precise, we define direction function s σ x and σ y , where σ x ( i, j ) = 1 (respectively , σ y ( i, j ) = 1 ) if the ho rizontal (resp., vertical) part of the route f rom i to j goes to the r ight (r esp., up) and σ x ( i, j ) = − 1 (resp., σ y ( i, j ) = − 1 ) if it g oes left (resp., down). The coor dinates of k in the to rus are: k x = i x + σ x ( i, j ) ⌊ | j x − i x | T 2 ⌋ (mo d √ n ) (16) k y = i y + σ y ( i, j ) ⌊ | j y − i y | T 2 ⌋ (mo d √ n ) . In the road map γ we hav e just co nstructed, th e maximum flight distance is smaller than √ n 2 + 1 in L 1 distance. Therefo re, accor ding to Lemma 1, for any edge e in γ , E [ W e ] > η / n 1 . 5 , whe re η is a non n egati ve constant slightly Novem ber 1, 2018 DRAFT 22 smaller than 1 − ln 2 . Thu s, for each p ath γ ij we have: | γ ij | = 1 π ( i ) E [ W i,k ] + 1 π ( k ) E [ W k,j ] = n 1 E [ W i,k ] + 1 E [ W k,j ] ≤ 2 n 2 √ n η . (17) W e can now compu te the Po incar ´ e coefficient: κ = max e X γ ij ∋ e | γ ij | π i π j = 1 n 2 max e X γ ij ∋ e | γ ij | . (18) T o compute this sum, we need to count the num ber of paths γ ij in the road map that use a given flight e . I n ou r construction , we have b alanced th e traffic load over all the sho rt fligh ts so that a fligh t e be longs to at most 8 paths. In deed, if a path contain s flight e , th en e is either the first or second flig ht. In th e first case, by co nstruction , the second flight has to be ap proxim ativ ely as lon g a s e . Moreover, because of q uantized grid effects, there are actually only 4 different possible flights a traveler in flight e migh t take as secon d flight (see Fig. 8). Repeating this argument in the case wher e e is the second flight, we then obtain that a flight e appears in at mo st 8 paths. Combining (17) an d (18), we get: κ ≤ 16 η √ n. As a re sult, λ 2 ≤ 1 − η 16 √ n , which yields Lem ma 2. The proof is com plete by using equ ation (5). In th e n ext Sectio n, we gen eralize this proof f rom g rids to regular geom etric g raphs. T he a pproac h will be th e same but the detailed compu tations will be different. Also, the constru ction of the pa ths in the travel a gency method will need some re finement. B. P erformanc e of bo x-path averaging. W e now prove Th eorem 5. All the f undam ental id eas coming fro m the proof on gr ids in the p revious section , appear here again, but some times in a mo re techn ical fo rm. W e have k boxes f orming a to rus g rid as in the pr evious section and k = ⌈ p ( n/ ( α log n )) ⌉ 2 ≃ n / ( α log n ) , for so me α > 2 . Using regularity , each bo x contains a n umber of no des between a log n and b log n . W e u se the ( ↔ , l ) -b ox routin g scheme pr esented in Section II I-D. Ther e are o nly a few mo difications to make to th e g rid proo f in order to o btain the regular geome tric graph proo f. The idea is to n otice that for any route r = ( r 1 , r 2 , · · · , r ℓ ) , we can attribute a box route e r consisting o f th e b oxes the no des of r belong to. If we call b ( i ) the box n ode i belong s to, then e r = ( b ( r 1 ) , b ( r 2 ) , · · · , b ( r ℓ )) . W e call n i the num ber of nodes in th e bo x b ( i ) n ode i belo ngs to . Th e seq uence o f n i is fixed by the g raph we are consid ering. ℓ ij is the L 1 distance between b oxes b ( i ) and b ( j ) : ℓ ij = k b ( j ) − b ( i ) k 1 . Novem ber 1, 2018 DRAFT 23 e 2 1 3 4 6 5 7 8 A B Fig. 8. Number of paths including an edge e = ( A, B ) in the road map. Paths have two hops of equal length, where equalit y here is defined up to grid ef fects. Therefore, for a gi ven edge e , there are at most 8 paths includ ing e : (1 , A, B ) , (2 , A, B ) , (3 , A, B ) , (4 , A, B ) and ( A, B , 5) , ( A, B , 6) , ( A, B , 7) , ( A, B , 8) . W e deno te by ℓ ( r ) the num ber of no des in r oute r , s ( e r ) the startin g bo x of ro ute e r and d ( e r ) its destination bo x. In our problem the chosen ro ute is random, which we will denote by capital case letter: R , leading to other ra ndom variables e R , ℓ ( R ) , s ( e R ) , etc. 1) Evalu ating E [ W ] : Lemma 3: (E xpected E [ W ] on the re gular geometric graph) For any pair o f nod es ( i, j ) that do n ot belon g to the same b ox, if their g rid-distance norm alized to the maxim um grid- distance δ ij = ℓ ij / √ k is smaller than a constant, then E [ W ij ] = Ω 1 n √ n log n . (19) More prec isely , E [ W i,j ] ≥ 4 a b 2 2 n 2 r n α log n (1 − δ ij + δ ij log δ ij ) , (20) Pr oof: F o r any node i and no de j that do no t b elong to the same bo x, we want to comp ute the expectation of W ij . Counting the routes in this setting is complicated because each sender has at least a log n nodes to send its message to. In o rder to use ou r simple analysis of th e grid , we con dition the expe ctation on th e box routes e R . Giv en a box route, W ij = 0 if i or j is not in the box rou te. On the contrar y , if they b oth are in the b ox route, then W ij = 1 /ℓ ( e R ) with pro bability 1 / ( n i n j ) . In deed, if i (o r j ) is in starting b ox, the prob ability that i is the starting node is 1 /n ( i ) , becau se all the no des wake up with the same rate. I f i (or j ) is in a nother bo x of the g iv en box r oute, then the prob ability that i is chosen is 1 /n ( i ) as well, because the ro uting cho oses next no de un iformly among the nodes o f the n ext box. E [ W ij ] = E e R [ E R [ W ij | e R ]] = E e R [ 1 n i n j 1 ℓ ( e R ) 1 b ( i ) ∈ e R 1 b ( j ) ∈ e R ] . Novem ber 1, 2018 DRAFT 24 From now on , we are ba ck to a pr oblem with routes o n a grid which has k “no des”. The difference with previous section is tha t routes are n o long er uniform . Ind eed, n ow , boxes wake u p more fre quently if they contain mo re nodes: th e probability tha t b ox b i wakes up is n i /n . Destina tion b oxes are still chosen un iformly at random with probab ility 1 /k bec ause there are k boxes in total. Just as bef ore, we consid er o nly ( ↔ , l )-b ox ro utes so that a box route is entirely determined by its startin g box and its destination box, and we co unt b ox rou tes of different leng th separately . Let R ℓ ij be the set of box rou tes of size ℓ including b i and b j . E [ W ij ] = 1 n i n j X e r 1 b ( i ) ∈ e r 1 b ( j ) ∈ e r ℓ ( e r ) P [ e R = e r ] = 1 n i n j 2 ⌊ √ k 2 ⌋ +1 X ℓ = ℓ ij +1 X e r ∈R ℓ ij P [ e R = e r ] ℓ = 1 n i n j 2 ⌊ √ k 2 ⌋ +1 X ℓ = ℓ ij +1 X e r ∈R ℓ ij P [ s ( e R ) = s ( e r ) , d ( e R ) = d ( e r )] ℓ = 1 n i n j 2 ⌊ √ k 2 ⌋ +1 X ℓ = ℓ ij +1 X e r ∈R ℓ ij 1 ℓ n s ( e r ) n 1 k . W e now use the regularity of th e graph : fo r any node m , a log n 6 n m 6 b lo g n . E [ W ij ] > 1 ( b log n ) 2 2 ⌊ √ k 2 ⌋ +1 X ℓ = ℓ ij +1 1 ℓ a log n n 4 log n n |R ℓ ij | . = 4 a b 2 1 n 2 2 ⌊ √ k 2 ⌋ +1 X ℓ = ℓ ij +1 |R ℓ ij | ℓ > 4 a b 2 2 n 2 √ k − ℓ ij − ℓ ij ln √ k ℓ ij ! . The last inequality comes f rom the same computation as f or the grid, and it can be reformulated as in Lem ma 3 when using th e norma lized distance coefficient δ ij = ℓ ij / √ k . 2) Bou nding λ 2 ( E [ W ]) : Lemma 4 ( Relaxation time R GG): 1 1 − λ 2 ( E [ W ]) = O ( p n log n ) . (21) Pr oof: As f or the g rid, we now apply the travel agency m ethod. The situation is very similar to th e grid case, except th at boxes now contain Θ(log n ) nod es each. Similarly to the grid case, we will be u sing 2- hop p aths for ev ery pair of no des, by adding one interm ediate stop half-way . Mo re precisely , this in termediate stop is chosen in the box whose coordin ates on the u nderlyin g lattice are given by equa tions 16, where i an d j are the lattice co ordina tes of the so urce and destina tion boxes. Then, within each box, we need to carefully and fairly assign the intermed iate nod es because a flight should not b e used more than a con stant n umber of times (it was 8 for the g rid), otherwise it would create cong estion. It is not hard to Novem ber 1, 2018 DRAFT 25 design suc h road map s b ecause the num ber of n odes in each box varies at m ost b y a con stant mu ltiplicativ e factor b/a . T o show this, assume that each box co ntains exactly lo g n n odes. Then, there are (lo g n ) 2 road maps to fin d between all the nod es in a pair of bo xes (assume b ox 1 and 3 , and let box 2 be the o ne ha lf-way), but happ ily enoug h, there are (log n ) 2 flights between box 1 and box 2 and also between box 2 an d 3 . Th erefor e, as we can see on Fig. 9, the box path (box 1 , bo x 2 , box 3 ) can cor respond to (log n ) 2 node road maps all using d ifferent flights (edg es). This flight allocation techn ique can e asily be exten ded to cases wh ere the boxes do not h ave th e same nu mber o f airp orts by using som e flights at most ⌈ b/a ⌉ times each in the pa ths between two given bo xes. There is a second refine ment to the grid proo f: so lving the p roblem for no des that share a comm on box, which d o Fig. 9. Path allocat ion when there are 3 nodes per box and thus 9 paths to design. not average jointly (Ou r b ound on E [ W ij ] is zero ). Howev er th ere are many edges to nod es in n eighbo ring boxes. So for mally , if nod e i and node j are in the same b ox, we design the ro ad map fr om i to j to b e a two h op road map stopping at a nod e located in the box above their box . By sh aring fairly th e available r elay airports, th e short north- south fligh ts might be used in ⌈ b/a ⌉ extra road maps. W e can thu s construct road maps for any pair of airp orts that will use at most 9 ⌈ b/ a ⌉ times each good intensity flight. The rest of the pr oof is identical to the grid pro of. For each path we ha ve: | γ ij | = 1 π ( i ) E [ W i,k ] + 1 π ( k ) E [ W k,j ] = n 1 E [ W i,k ] + 1 E [ W k,j ] ≤ cn 2 p n log n, (22) for som e co nstant c . Ine quality 22 was ob tained with the same r easoning as in the grid. W e the refore con clude, using the Poin car ´ e coefficient argumen t th at κ ≤ 9 ⌈ b a ⌉ c p n log n. As a re sult, for n large en ough, and some co nstant c ′ . λ 2 ≤ 1 − 1 c ′ √ n log n , which yields the lemma. Novem ber 1, 2018 DRAFT 26 C. Regularity of r andom geometric graphs Lemma 5 ( Re gularity of random geometric graphs): Con sider a ran dom geo metric g raph with n node s and par- tition the unit square in boxes of size α log n n . Then, all the boxes co ntain Θ (log n ) no des, with high p robab ility as n → ∞ . Pr oof: Let X i denote the number o f nod es contain ed in the i th box . X i are (non-in depend ent) Binomially distributed rando m variables with expectatio n α lo g n . Stan dard Ch ernoff (we do not optimize for the constants) bound s [1 6] imply: P ( X i ≤ α 2 log n ) ≤ e − α/ 8 log n . and P ( X i ≥ 2 α lo g n ) ≤ e − α/ 3 log n . which give tigh t bound s o n the num ber of node s in each b ox: P ( α 2 log n ≤ X i ≤ 2 α lo g n ) ≥ 1 − 2 e − α/ 8 log n . (23) A unio n bound over b oxes y ields the un iform bou nds on the maxim um and minimu m load of a square: P ( α 2 log n ≤ min i X i ≤ max i X i ≤ 2 α log n ) ≥ 1 − n 1 − α/ 8 2 α log n . Therefo re, selecting α ≥ 8 yields the lem ma. A m ore technical pro of shows that the lemma h olds for α > 2 . Novem ber 1, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment