Convergence of some leader election algorithms
We start with a set of n players. With some probability P(n,k), we kill n-k players; the other ones stay alive, and we repeat with them. What is the distribution of the number X_n of phases (or rounds) before getting only one player? We present a pro…
Authors: Svante Janson, Christian Lavault, Guy Louchard
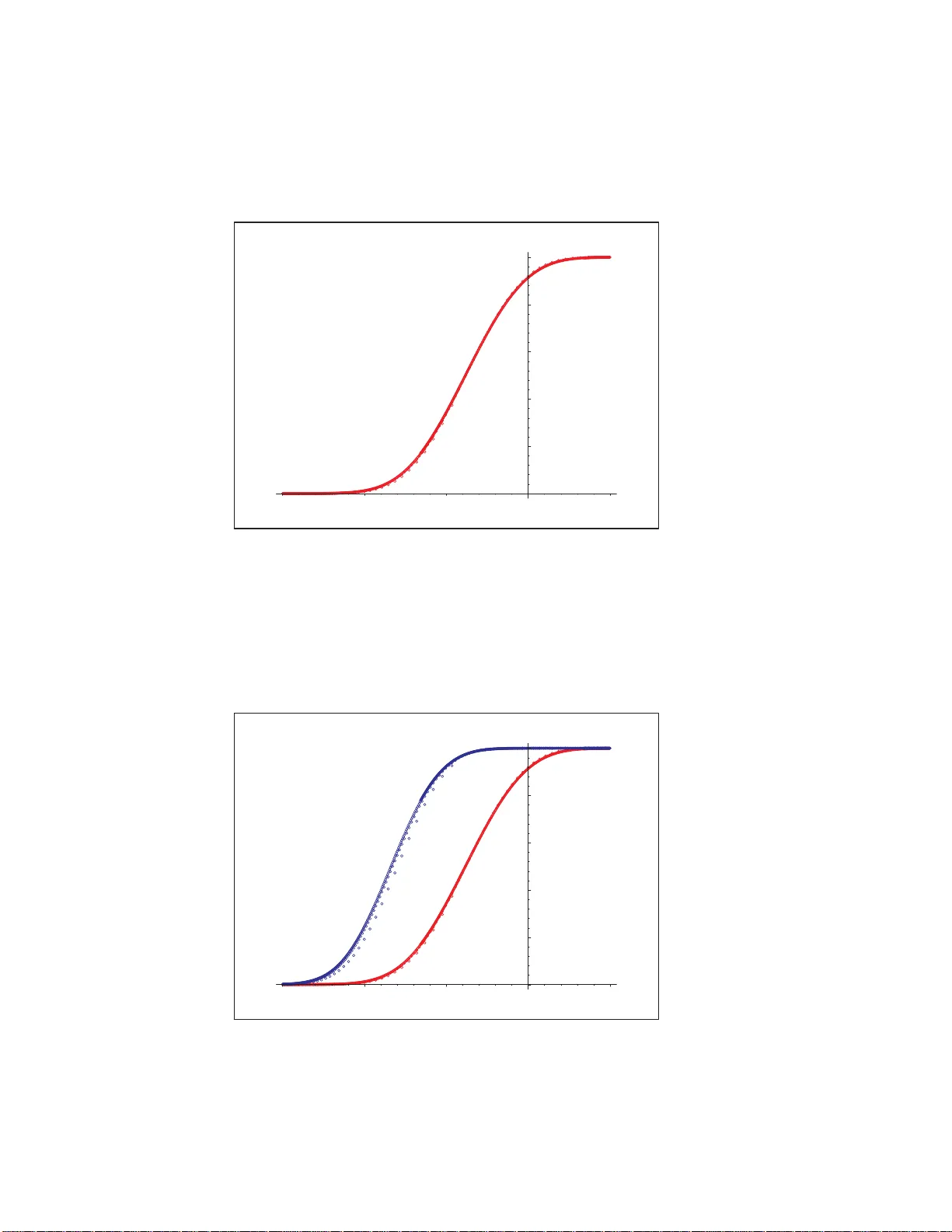
Con v ergence of some le ader electi on algorith ms Sv an te Janson ∗ Christian Lav ault † Guy Louc hard ‡ F ebruary 8, 2008 Abstract W e start with a set of n play ers. With some probability P ( n, k ), we kill n − k play ers; the other ones sta y aliv e, and we rep eat with them. What is the distribution of the num b er X n of phases (or r ounds) befo re ge tting o nly one player? W e present a probabilistic analysis o f this algo r ithm under some conditions on the probability distributions P ( n, k ), including sto chastic monoto nicit y and the assumption that r oughly a fixed pr op ortion α of the players surv ive in eac h round. W e prov e a kind of conv er gence in distribution for X n − lo g 1 /α n ; as in man y other similar problems there are oscilla tions and no true limit distribution, but suitable sub- sequences con verge, and th ere is an absolutely con tin uous rando m v a riable Z suc h tha t d ( X n , ⌈ Z + log 1 /α n ⌉ ) → 0, where d is either the total v ariation distance or the W asserstein distance. Applications of the general result include the leader election a lgorithm wher e players are eliminated b y indep endent coin tosses and a v aria tion of the leader election algor ithm prop osed b y W.R. F r a nklin [7]. W e study the latter a lgorithm further , including numerical results. 1 A general con v ergence theorem W e consid er a general leader election algo rithm of the follo wing t yp e: W e are giv en some random pro cedu re that, giv en any set of n ≥ 2 in dividuals, eliminates some (but not all) individuals. If there is more that one surviv or, w e r ep eat the pro cedure with th e set of survivo rs u ntil only one (the win n er) remains. W e are inte rested in the (random) num b er X n of r ounds required if we s tart with n individuals. (W e set X 1 = 0, and ha v e X n ≥ 1 for n ≥ 2.) W e let N k b e the n um b er of in dividuals r emaining after round k ; thus X n := min { k : N k = 1 } , where w e start with N 0 = n . F or con v en ience we ma y supp ose that we con tinue with infinitely man y roun ds where nothing happ en s ; th us N k is defin ed for all k ≥ 0 and N k = 1 for all k ≥ X n . W e assume that the num b er Y n of s urvivo rs of a set of n ind ividuals h as a distribution dep end ing on ly on n . W e ha v e 1 ≤ Y n ≤ n ; w e allo w the p ossibilit y that Y n = n , but we ∗ Uppsala Universit y , Department of Mathematics, P O Box 480, SE-751 06 Uppsala, Sw ed en . svante.jan son@math.uu. se † LIPN (U MR CNRS 7030), Universit ´ e Pari s 13, 99, a v. J.-B. Cl´ ement 93430 Villetaneuse, F rance. lavault@li pn.univ-pari s13.fr ‡ Universit ´ e Libre d e Bruxelles, D´ epartement d ’I n formatique, CP 212, Boulev ard du T riomphe, B-1050 Bruxelles, Belgium. louchard@ulb.ac.b e 1 assume P ( Y n = n ) < 1 for ev ery n ≥ 2, so that w e will not get stuc k b efore selecti ng a winner. W e f urther assume that, giv en the num b er of remaining ind ivid uals at th e start of a new round , th e n um b er of sur viv ors is indep end en t of th e p r evious history . In other w ords, th e sequence ( N k ) ∞ 0 is a Marko v c h ain on { 1 , 2 , . . . } , and X n is the num b er of steps to absorp tion in 1. The transitio n probabilities of this Mark o v c hain are, w ith Y 1 = 1, P ( i, j ) := P ( Y i = j ) = P ( j surviv es of a set o f i ) . (1.1) Note th at P ( i, j ) = 0 if j > i and P ( i, i ) < 1, for i > 1. Conv ersely , any Marko v c hain on { 1 , 2 , . . . } with suc h P ( i, j ) can b e regarded as a leader election algorithm in the generalit y just d escrib ed. W e will in this pap er treat leader elec tion algorithms where, asymptotically , a fixed pro- p ortion is eliminated in eac h rou n d. (Th us, w e exp ect X n to b e of th e order log n .) More precisely , we assume the follo w ing for Y n , where we also rep eat the ke y assump tions ab o v e. (Here and b elo w, log n should b e interpreted as some fixed p ositive n umber w hen n = 1.) Condition 1.1. F or every n ≥ 1 , Y n is a r andom variable such that 1 ≤ Y n ≤ n , and P ( Y n = n ) < 1 for n ≥ 2 . F u rther: (i) Y n is sto chastic al ly incr e asing in n , i.e., P ( Y n ≤ k ) ≥ P ( Y n +1 ≤ k ) for al l n ≥ 1 and k ≥ 1 . Equivalently, we may c ouple Y n and Y n +1 such that Y n ≤ Y n +1 . (ii) F or some c onstants α ∈ (0 , 1) and ε > 0 and a se quenc e δ n = O (log n ) − 1 − ε , E Y n +1 − E Y n = α + O ( δ n ) . (1.2) (iii) F or some ε an d δ n as in (ii) , P ( | Y n − αn | > δ n n ) = O ( n − 2 − ε ) . (1.3) Note th at E | Y n − αn | p = O ( n p/ 2 ) (1.4) for some p > 4 suffices for (iii), for a su itable c hoice of ε > 0 and δ n (e.g., δ n = n − η , η > 0 and ε small). Remark 1.2. If (1.2) or (1.3) holds for some sequence ( δ n ), it holds for ev ery larger sequ ence ( δ n ) to o; similarly , if δ n = O (log n ) − 1 − ε or (1.3) holds for some ε , it holds for ev ery small er ε to o. Hence we may assum e that (ii) and (iii) h old with the same ε > 0 and the same δ n , an d w e ma y assum e δ n ≥ (log n ) − 1 − ε . In particular, th is implies that δ k = O ( δ n ) when C − 1 n ≤ k ≤ C n , for eac h constan t C . The b eha viour of the election alg orithm is giv en b y the recurs ion X 1 = 0 and X n d = X Y n + 1 , n ≥ 2 , (1.5) where we assume that ( X i ) n i =1 and Y n are ind ep endent. W e state a general con v ergence theorem f or leader elec tion algorithms of this t yp e. 2 W e recall the d efinitions of th e total v ariation distance d TV and the W a sserstein distance d W (also kno wn as the Dudley , F o rtet-Mourier or Kan toro vic h distance, or m in imal L 1 dis- tance); these are b oth metrics on spaces of probabilit y distributions, bu t it is conv enient to write also d TV ( X, Y ) := d TV ( µ, ν ) and d W ( X, Y ) := d W ( µ, ν ) for r andom v ariables X, Y with X ∼ µ and Y ∼ ν . The total v ariation d istance d TV b et w een (the distributions of ) tw o arbitrary random v ariables X and Y is defined b y d TV ( X, Y ) := s up A | P ( X ∈ A ) − P ( Y ∈ A ) | . (1.6) F or int eger-v alued random v ariables, as is the case in our theorem, this is easily s een to b e equiv alen t to d TV ( X, Y ) = 1 2 X k | P ( X = k ) − P ( Y = k ) | . (1.7) F urther, for an y distributions µ and ν , d TV ( µ, ν ) := inf { P ( X 6 = Y ) : X ∼ µ, Y ∼ ν } ; (1.8) the infimum is tak en ov er all r andom v ectors ( X, Y ) on a j oin t pr obabilit y sp ace with the giv en m arginal distribu tions µ and ν . (In other w ords, o v er all couplings ( X, Y ) of µ and ν .) F or in teger-v alued random v ariables, con verge nce in d TV is e quiv alent to conv ergence in distribution, o r equiv alen tly , w eak conv ergence of t he c orresp on d ing distribu tions. The W asserstein distance d W is defined only for probability distributions with finite ex- p ectation, and can b e defin ed by , in analogy with (1.8), d W ( µ, ν ) := inf { E | X − Y | : X ∼ µ, Y ∼ ν } . (1.9) There are sev eral equiv alent formulas. F or example, for in teger-v alued random v ariables, d TV ( X, Y ) = X k | P ( X ≤ k ) − P ( Y ≤ k ) | . (1.10) It is immediate f r om (1.8) and (1.9) that for in teger-v alued random v ariables X and Y (but not in general), d TV ( X, Y ) ≤ d W ( X, Y ) . (1.11) It is well- kno wn that d W is a complete metric on the space of probabilit y measures on R with finite exp ectation, and that conv ergence in d W is equiv alen t to w eak con v ergence plus con v ergence of the fi rst absolute momen t. All u nsp ecified limits in this pap er are as n → ∞ . Theorem 1.3. Co nsider the le ader ele ction algo rithm describ e d ab ove, with Y n satisfying Condition 1.1. Then, ther e exists a distribution function F with b ounde d density function f = F ′ such that sup k ∈ Z | P ( X n ≤ k ) − F ( k − log 1 /α n ) | → 0 (1.12) or, e quivalently, if Z ∼ F , d TV ( X n , ⌈ Z + log 1 /α n ⌉ ) → 0 . (1.13) 3 Mor e pr e cisely, d W ( X n , ⌈ Z + log 1 /α n ⌉ ) → 0 , which is e q u ivalent to X k ∈ Z | P ( X n ≤ k ) − F ( k − log 1 /α n ) | → 0 . (1.14) As a c onse quenc e, defining ∆ F ( x ) := F ( x ) − F ( x − 1) , sup k ∈ Z | P ( X n = k ) − ∆ F ( k − log 1 /α n ) | → 0 (1.15 ) F urthermor e, E X n = log 1 /α n + φ ( n ) + o (1) , (1.16) for a c ontinuous function φ ( t ) on (0 , ∞ ) which is p erio dic in log 1 /α t , i.e . φ ( t ) = φ ( αt ) , and lo c al ly Lipschitz. W e thus d o not hav e con v ergence in distribution as n → ∞ , b u t the usual t yp e of oscilla - tions with an asymptotic p erio d icit y in log 1 /α n and conv ergence in distribution along subse- quences suc h that the fractional part { log 1 /α n } con v erges. (This phenomenon is w ell-kno wn for man y other p roblems with in teger-v alued r andom v ariables, see for example [14, 10]; it happ en s fr equ en tly w hen the v ariance sta ys b oun ded.) This is illustrated in Figure 1. 0 0.2 0.4 0.6 0.8 1 –3 –2 –1 1 2 3 4 5 x Figure 1: Illustration of Th eorem 1.3 Pr o of. W e assu me that δ n are as in Remark 1.2. Let q := sup n ≥ 2 P ( Y n = n ). S ince eac h P ( Y n = n ) < 1, and P ( Y n = n ) → 0 b y (iii), q < 1. Hence X n is sto chasti cally dominated by a sum of n − 1 g eometric Ge(1 − q ) r an d om v ariables, a nd th u s E X n = O ( n ). In particular, E X n < ∞ for ev ery n . Since the sequence ( Y n ) is sto c hastically increasing, w e ma y couple all Y n suc h that Y 1 ≤ Y 2 ≤ . . . . If w e consider starting our algorithm with different initial v alues, an d 4 use this coupling of ( Y n ) in eac h r ound, we obtain a coupling of all X n , n ≥ 1, s u c h that X n +1 ≥ X n a.s. for ev ery n ≥ 1. W e use these couplings of ( Y n ) and ( X n ) th roughout the pro of. Let x n := E X n , d n := E X n +1 − E X n = x n +1 − x n , b n := max 1 ≤ k ≤ n k d k . W e extend b n to real argumen ts by the same formula; th u s, b t = b ⌊ t ⌋ for real t ≥ 1. By (1.5), x n = E X n = 1 + E x Y n , n ≥ 2 . Th us, for n ≥ 2, d n = E ( x Y n +1 − x Y n ) = E Y n +1 − 1 X Y n d j = E n X j =1 d j 1 [ Y n ≤ j < Y n +1 ] = n X j =1 d j P ( Y n ≤ j < Y n +1 ) . (1.17) By (ii), E Y n +1 − E Y n → α , and thus there exi sts n 0 suc h th at if n ≥ n 0 then n X j =1 P ( Y n ≤ j < Y n +1 ) = E Y n +1 − E Y n < 1 . Hence (1.17) implies, w ith d ∗ n = max k ≤ n d k , for n ≥ n 0 , d n (1 − P ( Y n ≤ n < Y n +1 )) ≤ n − 1 X j =1 P ( Y n ≤ j < Y n +1 ) d ∗ n − 1 ≤ d ∗ n − 1 (1 − P ( Y n ≤ n < Y n +1 )) , and thus d n ≤ d ∗ n − 1 so d ∗ n = d n ∨ d ∗ n − 1 = d ∗ n − 1 . Con s equen tly , d ∗ n = d ∗ n 0 < ∞ , for all n ≥ n 0 . In other w ord s, d ∗ := sup n d n < ∞ . Let β := (1 + α ) / 2; th us α < β < 1. If n is large enough, so that ( α + δ n +1 )( n + 1) < β n , then (1.17) yields, using (1.3) and (1.2), d n ≤ d ∗ X j < ( α − δ n ) n P ( Y n ≤ j ) + 1 n ( α − δ n ) b β n X j P ( Y n ≤ j < Y n +1 ) + d ∗ X j >β n P ( Y n +1 > j ) ≤ d ∗ O ( nn − 2 − ε ) + 1 n ( α − δ n ) b β n ( E Y n +1 − E Y n ) = O ( n − 1 − ε ) + 1 n α + O ( δ n ) α − δ n b β n . Th us nd n ≤ (1 + O ( δ n )) b β n + O ( n − ε ) . (1.18) 5 Replace n by k and tak e the s upremum o v er all k suc h that β n < k ≤ n . S ince b k is increasing, and by our simplifying assumptions in Remark 1.2, this yields b n ≤ (1 + O ( δ n )) b β n + O ( n − ε ) = 1 + O ( δ n ) b β n . It follo ws b y ind uction o v er m that if (1 /β ) m ≤ n < (1 /β ) m +1 , th en b n ≤ C 1 m Y j =1 1 + C 2 j 1+ ε and thus b n = O (1). In other w ord s, we ha v e sho wn d n = O (1 /n ) . (1.19) W e now use the W asserstein distance d W . Sin ce X n +1 ≥ X n a.s., it is easily seen b y (1.9) that d W ( X n , X n +1 ) = E ( X n +1 − X n ) = d n . Th us, if m ≤ n , b y (1.19), d W ( X n , X m ) ≤ n − 1 X k = m d W ( X k , X k +1 ) = n − 1 X k = m d k = O n − m m , and thus, for al l n and m , d W ( X n , X m ) = O | n − m | n ∧ m . (1.20) Note also that (iii) implies E | Y n − αn | ≤ δ n n + O ( n − 1 − ε ) = O ( nδ n ) . (1.21) Define e X t := X ⌊ t ⌋ − log 1 /α t, t ≥ 1 . (1.22) Then, for t ≥ 2 /α , using (1 .5), (1. 20) , (1.21), (1.3), and 1 ≤ Y ⌊ t ⌋ ≤ t , d W ( e X t , e X αt ) = d W X ⌊ t ⌋ − log 1 /α ( t ) , X ⌊ αt ⌋ − log 1 /α ( αt ) = d W X ⌊ t ⌋ − 1 , X ⌊ αt ⌋ ≤ E d W X Y ⌊ t ⌋ , X ⌊ αt ⌋ ≤ C 3 E | Y ⌊ t ⌋ − ⌊ αt ⌋| Y ⌊ t ⌋ ∧ ⌊ αt ⌋ ≤ C 3 E | Y ⌊ t ⌋ − ⌊ αt ⌋| αt/ 2 + t 1 Y ⌊ t ⌋ < αt/ 2 = O t − 1 E | Y ⌊ t ⌋ − ⌊ αt ⌋| + O t P Y ⌊ t ⌋ < αt/ 2 = O ( δ ⌊ t ⌋ ) + O ( t · t − 2 − ε ) = O log − 1 − ε t . Hence, for an y t ≥ 2 /α , ∞ X j =0 d W ( e X α − j t , e X α − j − 1 t ) = O log − ε t < ∞ . (1.23) 6 Since d W is a complete metric, thus there exists for eve ry t > 0 a limiting distribution µ ( t ), suc h th at if Z ( t ) ∼ µ ( t ), th en d W e X α − j t , Z ( t ) → 0 as j → ∞ . (1.24) In p articular, e X α − j t d → Z ( t ) as j → ∞ . (1.25) (W e find it more con venien t to use the random v ariable Z ( t ) than its distrib ution µ ( t ).) Clearly , Z ( αt ) d = Z ( t ), so the d istribution µ ( t ) is a p erio dic fu nction of log 1 /α t . Hence, (1.24) can also b e wr itten, adding the explicit estima te obtained from ( 1.23), d W e X t , Z ( t ) = O log − ε t → 0 as t → ∞ . (1.26) Note f urther that, for γ ≥ 1, by (1 .22) and (1.20), d W ( e X t , e X γ t ) ≤ d W ( X ⌊ t ⌋ , X ⌊ γ t ⌋ ) + | log 1 /α t − log 1 /α ( γ t ) | = O ⌊ γ t ⌋ − ⌊ t ⌋ t + log 1 /α γ = O ( γ − 1 + 1 /t ) . Replacing t b y α − j t and letting j → ∞ , it follo ws from ( 1.24) that, for a ll t > 0 a nd γ ≥ 1, d W ( Z ( t ) , Z ( γ t )) = O ( γ − 1) . (1.27) Consequent ly , t → µ ( t ) = L ( Z ( t )) is contin uous and Lipsc hitz in the W asserstein metric . Define, f or eve ry real x , F ( x ) = P ( Z ( t ) ≤ x ) (1.28) for an y t > 0 suc h that x + log 1 /α t is an inte ger; since Z ( t ) is p erio dic in lo g 1 /α t , this does not dep end on the c hoice of t . Since e X α − j t + log 1 /α t = X α − j t − j ∈ Z , the rand om v ariable Z ( t ) + log 1 /α t is in teger- v alued for every t . It is easily seen that for int eger-v alued random v ariables Z 1 and Z 2 , the total v ariation d istance d TV ( Z 1 , Z 2 ) ≤ d W ( Z 1 , Z 2 ). Hence, for an y x ∈ R and u ≥ 0, c ho osing t suc h th at x + log 1 /α t is an in teger and letting γ = α − u , which imp lies that x − u + log 1 /α ( γ t ) = x + log 1 /α ( t ) ∈ Z , we obtain fr om the definition (1.28) and (1.27), F ( x ) − F ( x − u ) = P Z ( t ) ≤ x − P Z ( γ t ) ≤ x − u = P Z ( t ) + log 1 /α t ≤ x + log 1 /α t − P Z ( γ t ) + log 1 /α ( γ t ) ≤ x + log 1 /α t ≤ d TV Z ( t ) + log 1 /α t, Z ( γ t ) + log 1 /α ( γ t ) ≤ d W Z ( t ) + log 1 /α t, Z ( γ t ) + log 1 /α ( γ t ) ≤ d W Z ( t ) , Z ( γ t ) + | log 1 /α t − log 1 /α ( γ t ) | = O ( γ − 1) + log 1 /α γ = O ( u ) . (1.29) Hence, F ( x ) is a con tinuous f u nction of x . W e ha v e sho wn that t → L ( Z ( t )) is con tin uous in the W asserstein metric, and thus in the usual top ology of we ak con v ergence in the space P ( R ) of probabilit y measures on R . Since fu rther L ( Z ( t )) is p erio dic in t , the set {L ( Z ( t )) : t > 0 } = {L ( Z ( t )) : 1 ≤ t ≤ α − 1 } 7 is compact in P ( R ), whic h b y Prohoro v’s theorem means that the family { Z ( t ) } of rand om v ariables is tigh t, see e.g . Billingsley [1 ]. Hence, P ( Z ( t ) ≤ x ) → 0 as x → −∞ and P ( Z ( t ) ≤ x ) → 1 as x → + ∞ , uniformly in t , and it follo ws from (1.28) that lim x →−∞ F ( x ) = 0 and lim x →∞ F ( x ) = 1. F u r thermore, (1 .26) and (1.28) sho w that, for any sequence k n of integers, as n → ∞ , P ( X n ≤ k n ) = P e X n ≤ k n − log 1 /α n = P Z ( n ) ≤ k n − log 1 /α n + o (1) = F ( k n − log 1 /α n ) + o (1) . (1.30) Since fu rther the sequence X n is increasing, it no w follo ws from Janson [10, Lemma 4.6] that F is monotone, and thus a distribution fun ction. By (1.29), the distribu tion is absolutely con tin uous and has a b ounded den s it y function F ′ ( x ). It is easy to see that (1.30) , (1.12 ) and (1.13) are equiv alen t, see [10, Lemma 4.1]. Th e corresp ondin g result in the W asserstein distance follo ws from (1.26) b ecause d W ( X n , ⌈ Z + log 1 /α n ⌉ ) = d W ( e X n , Z ( n )), e.g. by Remark 1.4 b elo w; (1.14) then follo ws b y (1.1 0). Finally , (1.26) implies that E e X t = E X ⌊ t ⌋ − log 1 /α t = E Z ( t ) + O log − ε t , whic h p ro v es (1.16) with φ ( t ) := E Z ( t ), w hic h is p erio dic in log 1 /α t . Since | φ ( t ) − φ ( u ) | = | E ( Z ( t ) − Z ( u )) | ≤ d W ( Z ( t ) , Z ( u )), (1.2 7 ) imp lies that φ is con tin uous, and Lipsc hitz on compact in terv als. Remark 1.4. As r emark ed ab ov e, Z ( t ) + log 1 /α t is intege r-v alued. Moreo v er, for ev ery in teger k , P Z ( t ) + log 1 /α t ≤ k = P Z ( t ) ≤ k − log 1 /α t = F ( k − log 1 /α t ) = P Z ≤ k − log 1 /α t = P Z + log 1 /α t ≤ k = P ⌈ Z + log 1 /α t ⌉ ≤ k . Hence, for ev ery t > 0, Z ( t ) d = ⌈ Z + log 1 /α t ⌉ − log 1 /α t . General famili es of r an d om v ariables of th is t yp e are stud ied in [10]. In particular, [10, Th eorem 2.3] sho ws ho w φ ( t ) := E Z ( t ) in Theorem 1.3 can b e obtained from th e c h aracteristic function of the distribution F of Z . Remark 1.5. The very slow conv ergence rate O log − ε t in (1.2 6 ) is b ecause w e allo w δ n to tend to 0 slo wly . I n t ypical applicatio ns, δ n = n − a for some a > 0, and then b etter con v ergence rates can b e obtained. W e ha ve, how eve r, not pu r sued this. Remark 1.6. Note that F and φ are influenced b y the distrib u tion of Y n for small n > 2, for example Y 3 and Y 4 ; hence there is no hop e for a nice explici t formula for F or φ dep ending only on asymptotic prop erties of Y n . Remark 1.7. The general problem of studying th e num b er of steps until absorption at 1 of a decreasing Marko v c hain on { 1 , 2 , . . . } app ears in man y other situations to o, usually with quite differen t b eha viour of Y n and X n . As examples we men tion th e recen t p ap ers studying random trees and coa lescen ts by Drmota, Iksano v, Mo ehle and Ro esler [3], Iksano v and M¨ ohle [9] and Gnedin and Y aku b o vic h [8 ]; in these p ap ers the num b er killed in eac h round is m u c h smaller than here and th us X n is la rger, of the ord er n or n/ log n ; moreo ve r, after n ormalizatio n X n has a stable limit la w. 8 2 Extensions W e h a v e assumed that w e rep eat the eliminatio n step until only one pla y er remains. As a generalizat ion we m a y supp ose th at w e stop when there are at most a pla yers left, for some giv en n umber a . Theorem 2.1. Consider the le ader ele ction algorithm describ e d in Se c tion 1, but stopping as so on as the numb er of r e maining players is at mo st a , for some fixe d a ≥ 1 . Supp ose tha t Condition 1.1 is satisfie d. Then, th e c onclusions of The or em 1 .3 hold, for some F and φ that dep e nd on the thr eshold a . Pr o of. This generalization can b e obtained from the v ersion in Section 1 by replacing Y n b y Y ′ n := ( Y n , Y n > a ; 1 , Y n ≤ a. Supp ose that Condition 1.1 holds for ( Y n ). It is easily seen that then Condition 1.1 holds for ( Y ′ n ) to o, with the same α ; for (ii), n ote that Condition 1.1(iii) implies that E | Y n − Y ′ n | ≤ a P ( Y n ≤ a ) = O ( n − 2 − ε ) and th u s E Y ′ n +1 − E Y ′ n = E Y n +1 − E Y n + o ( n − 2 ). Consequ ently , Theorem 1.3 applies to ( Y ′ n ), and th e result follo w s. In this situation, it is also int eresting to study the probabilit y π i ( n ) that th e pro cedu re ends with exact ly i play ers, starting with n p la yers; h ere i = 1 , . . . , a and P a i =1 π i ( n ) = 1. W e ha ve a corresp onding limit theorem for π i ( n ). Theorem 2.2. Supp ose that Condition 1.1 ho lds and that a ≥ 1 is gi ven as in The or em 2.1. Then, π i ( n ) = ψ i ( n ) + o (1) , i = 1 , . . . , a, (2.1) for some c ontinuous functions ψ i ( t ) on (0 , ∞ ) which ar e p erio dic in log 1 /α t , i.e. ψ i ( t ) = ψ i ( αt ) , and lo c al ly Lipschitz. Pr o of. A mo d ifi cation of the pr o of of Theorem 1.3, no w taking x n := π i ( n ) and d n := | x n +1 − x n | and replacing the random e X t b y x ⌊ t ⌋ = π i ( ⌊ t ⌋ ), yields π i ( n + 1) − π i ( n ) = O (1 /n ) and π i ( α − j t ) − π i ( α − ( j +1) t ) = O ( j − 1 − ε ); hence, for an y t > 0, π i ( α − j t ) → ψ i ( t ) for some ψ i ( t ), wh ic h easily is seen to satisfy the stated co nditions. W e omit the d etails. More generally , th ere is a similar result on the probability that the p ro cess p asses through a certain state; this is inte resting also for the pro cess in Section 1 with a = 1. Theorem 2.3. Supp ose that Condition 1.1 hold s and that a ≥ 1 is given as ab ove. L et π i ( n ) , i ≥ 1 , b e the pr ob ability that, starting with n players, ther e exists some r ound with exactly i survivors. Then π i ( n ) = ψ i ( n ) + o (1) , i = 1 , 2 , . . . , (2.2) for some c ontinuous functions ψ i ( t ) on (0 , ∞ ) which ar e p erio dic in log 1 /α t , i.e. ψ i ( t ) = ψ i ( αt ) , and lo c al ly Lipschitz. 9 Pr o of. F or i ≤ a , this π i ( n ) is the same as in Theorem 2.2, and for eac h i > a , this π i ( n ) is the same as in Theorem 2.2 if w e r eplace a b y i . Remark 2.4. Another v ariation, whic h is natural in some pr oblems, is to study a non- increasing Marko v c hain on { 0 , 1 , . . . } and ask for the num b er of steps to reac h 0; in other w ords, the time un til all pla y ers are killed. In this case, we thus assum e that 0 ≤ Y n ≤ n . This c an ob viously b e transformed to our set-up on { 1 , 2 , . . . } by by increasing eac h integ er b y 1; in other w ords, w e replace Y n b y Y ′ n := Y n − 1 + 1, n ≥ 2; we can in terpret this as adding a dummy play er that nev er is eliminated, and con tin u ing unt il only th e d u mm y remains. If Condition 1.1 holds for Y n , except that Y n = 0 is allo w ed and P ( Y 1 = 0) > 0 , then Condition 1.1 holds for Y ′ n to o, and th us our results hold also in this case, with X n no w defined as th e num b er of steps un til absorption in 0. (T o b e precise, X n = X ′ n +1 , with ( X ′ n ) corresp onding to ( Y n ), since we add a dummy , but there is no d ifference b et w een th e asymptotics of X ′ n +1 and X ′ n .) 3 Examples Example 3.1 (a to y example) . F or a simple example to illustrate the theorems ab o ve, let, for n ≥ 2, Y n = ⌊ ( n + I ) / 2 ⌋ , where I ∼ Be(1 / 2) is 0 or 1 with P ( I = 1) = 1 / 2. In other w ords, we t oss a coin and let Y n b e either ⌊ n/ 2 ⌋ or ⌈ n/ 2 ⌉ dep ending on the outcome. (If n is ev en, th us alw ays Y n = n/ 2.) Note that E Y n = n/ 2, n ≥ 2, and that Condition 1. 1 holds trivially , with α = 1 / 2 . If w e start with N 0 = n play ers and m 2 j ≤ n ≤ ( m + 1)2 j , m ≥ 1, then the n umber N j of survivo rs after j round s sat isfies m ≤ N j ≤ m + 1 and E N j = 2 − j n (b y ind uction on j ). Consequ ently , if m 2 j ≤ n ≤ ( m + 1)2 j , P ( N j = m ) = m + 1 − 2 − j n, P ( N j = m + 1) = 2 − j n − m. (3.1) T aking m = 1, this sho ws that if 2 j ≤ n ≤ 2 j +1 , then P ( X n = j ) = P ( N j = 1) = 2 − 2 − j n, P ( X n = j + 1) = 1 − P ( X n = j ) = 2 − j n − 1 . (3.2) Hence, (1.12) holds exactly , P ( X n ≤ k ) = F ( k − log 2 n ), for all k ∈ Z and n ≥ 1, with F ( x ) = 0 , x ≤ − 1 , 2 − 2 − x , − 1 ≤ x ≤ 0 , 1 , x ≥ 0 , and (1.16) holds exactly , E X n = log 2 n + φ ( n ), with φ (2 x ) = 2 x −⌊ x ⌋ − x − ⌊ x ⌋ − 1 . Supp ose no w, as in Section 2, that we stop when there are at most a = 3 pla y ers left. (Similar results are easily obtained for other v alues of a .) If 2 i ≤ n ≤ 2 i +1 with i ≥ 1, we tak e j = i − 1 and n ote that N j ∈ { 2 , 3 , 4 } . If N j = 4, the procedu re ends afte r one further round w ith 2 pla y ers le ft; otherwise it ends immediate ly with N j = 2 or 3 su rviv ors. T aking m = 2 or m = 3 in (3.1), we th us find π 2 ( n ) = P ( N i − 1 = 2) + P ( N i − 1 = 4) = | 2 1 − i n − 3 | , 2 i ≤ n ≤ 2 i +1 . 10 Consequent ly , π 2 ( n ) = ψ 2 ( n ) exactly , for all n ≥ 2, w ith ψ 2 (2 x ) = | 2 1+ x −⌊ x ⌋ − 3 | . F u r ther, ψ 3 ( t ) = 1 − ψ 2 ( t ) and ψ 1 ( t ) = 0. Example 3.2 (a counte r example) . The pro cedure in Example 3.1 is almost deterministic. In con trast, the very similar but completely deterministic Y n = ⌊ n/ 2 ⌋ , n ≥ 2, do es n ot satisfy Condition 1.1(ii). I n this case, X n = ⌊ log 2 n ⌋ and P ( X n ≤ k ) = F ( k − log 2 n ), for all k ∈ Z and n ≥ 1, where F ( x ) = 1 [ x ≥ 0], the distribu tion of Z := 0; this limit F is not con tin uous so the conclusions of Theorem 1.3 do not all hold. Example 3.3. A leader election algorithm stu died by Pro dinger [18], Fill, Mahmoud and Szpank o wski [5] Kn essl [12], and Louc hard an d Pro dinger [16], see also Szpanko wski [19, Section 10.5.1], is the follo wing: Each player tosses a fair c oin. If a t le ast one player thr ows he ads, then al l players thr owing tails ar e e liminate d; if al l players thr ow ta ils, then al l survive until the next r ound. Except for the sp ecial ru le when all throw tails, whic h guarant ees that at least on e pla y er survive s eac h round, the num b er Y n of sur viv ors in a round th us has a binomial distribution Bi( n, 1 2 ). More precisely , if W n is the n um b er of heads thr o wn, Y n = W n + n 1 [ W n = 0] with W n ∼ Bi( n, 1 2 ) . (3.3) Note th at E | Y n − n/ 2 | 6 = E | W n − n/ 2 | 6 = O ( n 3 ) , so (1.4) holds for p = 6 (and , indeed, f or an y p > 0), and th u s (1.3) holds. Similarly , E Y n = E W n + 2 − n n = 1 2 n + n 2 − n . Th us, co nditions (ii) and (iii) in Theorem 1.3 are s atisfied. Also the monoto nicit y condition (i) is satisfied, b ecause if 1 ≤ k ≤ n − 1 (o ther c ases are trivial), then P ( Y n +1 ≤ k ) = P (1 ≤ W n +1 ≤ k ) = 1 2 P (1 ≤ W n ≤ k ) + 1 2 P (0 ≤ W n ≤ k − 1) = P ( Y n ≤ k ) + 1 2 P ( W n = 0) − P ( W n = k ) < P ( Y n ≤ k ) . (3.4) Hence Cond ition 1.1 is satisfied with α = 1 / 2 and T h eorem 1.3 a pplies. In this case, Prod inger [18], see also Fill, Mahmoud and S zpank o wski [5], found an exact form ula for the exp ectati on E X n and asymptotics of the form (1.16) with th e explicit fu nction φ ( t ) = 1 2 − (log 2) − 1 X k 6 =0 ζ (1 − χ k )Γ(1 − χ k ) e 2 kπ i log 2 t , χ k := 2 k π log 2 i . (3.5) Fill, Mahmoud and Szpanko wski [5] fur ther found asymptotics of the distribution that can b e writte n as (1.12) with F ( x ) = 2 − x exp(2 − x ) − 1 , (3.6) 11 whic h thus is the distribution function of Z in this case. S econd and higher momen ts are considered by Louc hard and Pro din ger [16]. Pro dinger [18] considered also the p ossibility of s topping at a = 2 pla y ers, and sho w ed (1.16) ab o ve in this case too, with an explicit f orm ula for th e fun ction φ ( t ) (of the same t yp e as (3.5) for a = 1). Example 3.4. A v ariation of Example 3 .3 studied by Janson and Szpanko wski [11], Knessl [12] and Louc hard and Pro din ger [16] is to let the coin b e biased, with probability p ∈ (0 , 1) for heads (=sur viv al). Then (3 .3) still holds, b ut with W n ∼ Bi( n, p ). Conditions 1.1(ii)(iii) hold as ab o v e, with α = p , but arguing as in (3.4) w e see that Condition 1.1(i) holds if p ≥ 1 / 2, but not for smaller p . Hence, Theorem 1.3 applies when p ≥ 1 / 2. In fact, the results of [11] sh o w that the conclusions (1.12) and (1.16) hold for all p ∈ (0 , 1), for some fu nctions F and φ explicitly giv en in [11]. (See also [16 ], where further higher momen ts are treated.) Th is suggests that Theorem 1.3 shou ld hold more generally . Note th at although Condition 1.1 (i) do es n ot hold for p < 1 / 2, t he difference P ( Y n +1 ≤ k ) − P ( Y n ≤ k ) is at most P ( Y n = 0) = (1 − p ) n , and thus negati v e or exp onen tially small for large n . I t seems lik ely that T h eorem 1.3 can b e extended to suc h cases, by allo wing a small error in Condition 1.1(i) ; this then w ould include this leader election algorithm with a bisaed coin for an y p ∈ (0 , 1). Ho we v er, w e ha ve not p ursued this. It w as left as an open question in [11] whether for eac h p ∈ (0 , 1) the limit function F is monotone, and th us a distribu tion function, whic h means that there exists a random v ariable Z su c h that (1.13) holds . By the discussion ab o ve, Th eorem 1.3 sho ws that this holds for p ≥ 1 / 2, bu t the case p < 1 / 2 is as far as w e kno w still op en. Cf. Remark 4.2 and Figure 6 b elo w, whic h sho w that monotonicit y fails in a related situatio n. Nu merical exp eriments, based on [16, Prop. 3.1 ], indicate that F is monot one, at least f or some c hoices of p < 1 / 2. A fur ther v ariation of Example 3.3 is to let the probabilit y p dep end on n . The ca se p = 1 /n is studied b y Lav ault and Louchard [13]; in this case E Y n is boun ded and Condition 1.1 do es n ot h old, so T heorem 1 .3 does not apply . Example 3.5. The sp ecial r ule in Examp les 3.3 and 3.4 for the exceptional case when all thro w tai ls is of course necessary to prev en t us from killing all pla y ers, but a s w e ha v e seen, it complicates the analysis, esp ecially for p < 1 / 2 when it d estro ys sto c hastic monotonicit y of Y n . Note th at this rule t ypically is inv oked only to w ards the end of the algorithm, wh en only a few pla y ers are left. W e regard the rule as an emergency exit, and it could b e replaced b y other sp ecial rules for th is c ase. F or example, an alt ernativ e would be to s witc h to some other algorithm that is fail-safe although in principle (for large n ) slo we r; for our p urp ose this means that the present algorithm terminates, so we ma y describ e this b y letting Y n = 1 in this case, i.e., (3 .3) is r eplaced b y Y n = W n + 1 [ W n = 0] = m ax( W n , 1). Note that for this v ersion, Condition 1.1 h olds for ev ery p ∈ (0 , 1), with α = p , so our theo rems apply . An equiv alen t w a y to treat this version is to add (as in Remark 2.4) a du m m y , whic h is exempt from elimination, and to eliminate ev ery one else that thro ws a tail; w e then stop when there are at most 2 play ers left (the dummy and, p ossibly , one real p lay er). This is th us the v ersion in Section 2, with a = 2 a nd Y n = 1 + W n − 1 , W m ∼ Bi( m, p ) (and starting with n + 1 play ers). Again, Condition 1.1 h olds , with α = p , and the results in S ection 2 apply . In particular, since in v oking the sp ecial rule corresp onds to eliminat ing ev ery one except the dummy , the probabilit y that we ha ve to in vok e the sp ecial rule is the same as the 12 probabilit y that the dummy version ends with only the d ummy , i.e. π 1 ( n + 1) in th e notation of Theorem 2.2; the asymptotics of this probabilit y is th us give n b y (2.1). Example 3.6. Pro dinger [17] (for p = 1 / 2 ) and Louc h ard and P r o dinger [15] stud ied a v ersion of Examples 3.3 and 3.4 where, as in Remark 2.4, we allo w all pla y ers to b e killed and let X n b e the time until that h app ens. Thus, in eac h roun d, eac h pla y er tosses a coin and is killed with probabilit y 1 − p (and we do not ha ve any sp ecial ru le). Additionally , there is a demon, who in eac h round kills one of the survivo rs (if an y) with probabilit y ν ∈ [0 , 1]. W e th us hav e the m o dification discus sed in Remark 2.4, with Y n = max( W n − I , 0) , W n ∼ Bi( n, p ) , I ν ∼ Be( ν ) , where W n and I ν are indep endent; thus also Y ′ n = Y n − 1 + 1 = max( W n − 1 + 1 − I ν , 1). Condition 1.1 h olds, in the mo dification for absorption in 0, and thus our results apply . In fact, Louc hard and Pr o dinger [15] show (1.12) and (1.16) for this problem with explicitly giv en F and φ ; they further g iv e an extension of (1.1 6 ) to higher moments. As remarke d in [17, 15], the sp ecial case ν = 1 is equiv alen t to appro ximate count ing and ν = 0 is equiv alent to the cost of an un successful search in a trie; in the latter case, X n is simply the maximum of n i.i.d geometric rand om v ariables w h ic h can b e treated by elemen tary metho d s . Example 3.7. W .R. F ranklin [7 ] prop osed a leader elect ion algo rithm where the n play ers are arranged in a r ing. Eac h pla yer g ets a random num b er; these are i.i.d. and , sa y , uniform on [0 , 1]. (Since only the order of these n u m b ers will matter, an y con tin uous distribu tion will do; moreo v er, it is equiv alent to let ξ 1 , . . . , ξ n b e a rand om p ermutat ion of 1 , . . . , n .) A pla y er survive s the fir st roun d if her r andom num b er is a p eak; in other words, if ξ 1 , . . . , ξ n are i.i.d. random n um b ers, then pla y er i survives if ξ i ≥ ξ i − 1 and ξ ≥ ξ i +1 (with indices taken mo dulo n ). W e ma y ignore th e p ossibilit y that tw o num b ers ξ i and ξ j are equ al; h ence we may as w ell r equ ire ξ i > ξ i − 1 and ξ > ξ i +1 . In F ranklin’s algorithm, the surviv ors con tin ue by comparing their original num b ers in the same w a y with the nearest surviving pla y ers; this is rep eated un til a single winner remains. W e h a v e so far n ot b een able to analyse this algorithm. It is easy to verify th at even if w e condition on the num b er m of survivo rs after the fir st round , th e m ! p ossible different orderings of th e surviv ors do not app ear with equ al probabilities, w hic h means th at the algorithm is not of the recur siv e t yp e studied in this pap er. ( F or example, starting with a ring of 8 pla y ers and conditioning on ha ving 4 sur viv ors (p eaks) in the first round; the probabilit y of getting 2 su rviv ors in the second round is 10/34, and not 1/3 as in the uniform case.) Ho wev er, w e can study a v ariation of F ranklin’s algorithm, wh ere the surviv ors dr a w new random num b ers in eac h round. This is an algorithm of the t yp e studied in S ection 1, with Y n giv en by the n um b er of p eaks in a random p erm utation, r egarded as a circular list. Note that there is alw a ys at lea st one p eak (the maxim u m will alwa ys do), so Y n ≥ 1 as required. It is easily seen th at inserting a new p la y er will nev er decrease the num b er of p eaks; h ence Y n is s to chastica lly increasing in n . F urther , we ha v e Y n = P n 1 I i , where I i := 1 [ ξ i > max( ξ i − 1 , ξ i +1 )] is the indicator th at pla yer i sur viv es (again, indices are tak en mo dulo n ). If n ≥ 3, then E I i = 1 / 3 by symmetry , and thus E Y n = n/ 3. In particular, (ii) holds with α = 1 / 3. F urth ermore, I i and I j are indep endent un less | i − j | ≤ 2 (mod n ), and 13 similarly for sets of the indicators I i , and it follo ws easily that E ( Y n − E Y n ) 6 = O ( n 3 ), and th us (1.4) holds for p = 6. (Indeed, (1.4) holds for all ev en p b y this argum en t.) Consequent ly , Condition 1.1 holds and Theorem 1.3 applies, with 1 /α = 3. Remark 3.8. It migh t b e sho wn that for the true F ranklin a lgorithm, the exp ected num b er of sur viv ors after 2 round s is c 2 n + o ( n ), w here c 2 = 3 e 4 − 48 e 2 + 233 384 ≈ 0 . 109 686868 1 . (3.7) (Detail s might app ear elsewhere.) In comparison, for the v ariation with new rand om n umbers eac h round, it is easily seen that the exp ected n um b er after k round s is (1 / 3) k n + o (1), for an y fixed k ; in particular, after tw o round s it is n/ 9 + o ( n ). Note th at c 2 in (3 .7) is sligh tly smaller than 1 / 9 , and thus b etter in terms of p erformance. It m ight ha v e b een hop ed that the true F ranklin algorithm is asymptotically equiv alent to the v ariation stu d ied here, but the fact that c 2 6 = 1 / 9 suggests that this is not the case. Nev ertheless, we conjecture that Theorem 1.3 remains tru e for the F ranklin algorithm, for some u nkno wn α < 1 / 3. Example 3 .9. In b oth v ersions in Example 3.7, the play ers are arranged in a circle. Al- ternativ ely , the pla yers ma y b e arranged in a line. W e use the same rules as ab o v e, bu t we ha v e to sp ecify wh en a play er a t the end (with only one neighbour ) is a p eak. There are tw o ob vious possib ilities: (i) Nev er regard the fi rst and last play ers as p eaks. (Define ξ 0 = ξ n +1 = + ∞ .) (ii) Regard them as p eaks if ξ 1 > ξ 2 and ξ n > ξ n − 1 , resp ectiv ely . (Define ξ 0 = ξ n +1 = −∞ .) In the fi r st case, it is p ossible that there are no p eaks, and th u s we h av e to add an emergency exit as in Example 3. 5. As in Example 3.7, t here a re t w o v ersions (for ea c h of (i) and (ii)): we ma y use the same random num b ers in all roun ds, or w e ma y dra w n ew ones eac h roun d. In the latter case, w e are again in the s itu ation of S ection 1. In b oth cases (i) and (ii), the distribution of Y n is related to the distribution in the circular case in Examp le 3.7. I n deed, if we start with a circular list of n + 1 n umber s and eliminate the pla y er with the largest n umber, then the remaining n n umbers form a linear list, and the p eaks in this list u s ing v ersion (i) equal the p eaks except the maxim um one in the original circular list. Similarly , if w e instead eliminate the pla ye r with the smallest num b er, then the p eaks in the remaining list using version (ii) equ al the p eaks in the original list. Hence, if Z n is the n um b er of p eaks in a random circular list of length n , then (i) yields Y n d = Z n +1 − 1 and (ii) yields Y n d = Z n +1 . In b oth cases, this im p lies that Condition 1.1 holds (pr ovided w e add a suitable emergency exit in case (i)) b ecause it holds for Z n . Cons equ en tly , Theorem 1.3 applies to b oth these linear versions of (the v ariation of ) F ranklin’s algo rithm, again with 1 /α = 3. 4 First v ariation of the F ranklin leader election algorithm. The linear case W e assume that the survivo rs dra w new random num b ers in eac h round and that th ey are arranged in line. W e u se p ossibility (i) o f Example 3 .9. W e s tart with a set of n p lay ers. W e 14 assign a classical p erm utation of { 1 , . . . , n } to the set, all pla y ers corresp ondin g to a p eak sta y aliv e, the other ones are killed. If there are no p eaks, we choose the follo w ing emergency exit: a pla y er is chosen at random (this is assum ed to ha v e 0 cost), ind eed in the original game, one deals with circular p erm utations, so th ere alw a ys exists at least one p eak, here w e approac h the problem with a classical inline p erm utation. What is the d istribution of the num b er X n of phases (or rou n ds) b efore getting only on e pla y er? 4.1 The analysis Let Y n := num b er of p eaks, starting with n pla ye rs , P ( n, k ) := P [ Y n = k ] = P [ k p eaks, starting with n pla y er s ] , Π( n, j ) := P ( X n = j ) = P [ j phases are necessary to end the g ame, starting with n pla y ers] , Λ( n, j ) := j X k =0 Π( n, k ) = P [at most j phases are necessa ry , starting with n play ers] . W e will sometimes use the subscript l to distinguish these from the circular case discussed in Section 5 . First of all, we kn ow (Carlitz [2]; s ee also [6, Chapter 3]), that the p enta v ariate generating function (GF) of v alleys ( u 0 ), d ouble rise ( u 1 ), double fall ( u ′ 1 ) and p eaks ( u 2 ) is giv en b y I ( z , u ) = δ u 2 v 1 + δ tan( z δ ) δ − v 1 tan( z δ ) − v 1 u 2 , with v 1 = ( u 1 + u ′ 1 ) / 2 , δ = q u 0 u 2 − v 2 1 . This giv es the GF of the n umb er of p eaks: tan[ z ( u − 1) 1 / 2 ] ( u − 1) 1 / 2 − tan[ z ( u − 1) 1 / 2 ] , (4.1) hence the mean M and v ariance V of the num b er of p eaks, for n ≥ 2 and n ≥ 4, resp ectiv ely: M ( n ) = ( n − 2) / 3 , V ( n ) = 2( n + 1) / 45 . (4.2) This GF is also giv en in Carlitz [2]. Moreo ver, fr om [6, C h apter 9], we kno w that the distribution P is asymptotically Gaussian. Th is is also pro v ed in Esseen [4] by p robabilistic metho ds. Let x ( n ) b e the mean n um b er of phases, E ( X n ), starting with n pla y ers. As w e shall see, the initial v alues are x (0) = x (1) = 0 , x (2) = x (3) = x (4) = 1 . Since (4.2) yields M ( n ) + 1 = ( n + 1) / 3 for n ≥ 2, we hav e (appro ximating b y u sing this f or n ≤ 1 to o) that the m ean num b er of pla ye rs c ( j ) still aliv e afte r j p hases is c ( j ) ≈ 3 − j ( n + 1) − 1 . 15 k n ❩ ❩ ❩ 0 1 2 3 4 1 1 0 0 0 0 2 1 0 0 0 0 3 2 / 3 1 / 3 0 0 0 4 1 / 3 2 / 3 0 0 0 5 2 / 15 11 / 15 2 / 15 0 0 6 2 / 45 26 / 45 17 / 45 0 0 7 4 / 315 38 / 10 5 4 / 7 17 / 315 0 T able 1: P l ( n, k ) (An induction easily yields the exact formula | c ( j ) − 3 − j n | < 1 for all j .) If we wan t c ( j ) = 1, this leads to the appro ximation x ( n ) ≈ j ≈ log 3 n − log 3 2 . W e see from Theorem 1.3 (wh ic h applies by Example 3.9) that this is roughly correct, but the constan t − log 3 2 h as to be replaced by a p erio dic fun ction φ ( n ). Let u s now construct Π. W e h a v e, for n ≥ 2 a nd j ≥ 1, Π( n, j ) = ⌊ ( n − 1) / 2 ⌋ X k =0 P ( n, k )Π( k , j − 1) . (4.3) W e ha ve th e in itial v alues Π(0 , 0) = 1 , Π(0 , j ) = 0 , j > 0 , Π(1 , 0) = 1 , Π(1 , j ) = 0 , j > 0 , Π( n, 0) = 0 , n ≥ 2 . Also Π(2 , 1) = Π(3 , 1) = Π(4 , 1) = 1 . Some v alues of P and Π is giv en in T ables 1 and 2 . (W e use in the tables and figures the subscript l to emph asise that w e deal with the linear case.) Denoting the j th column of Π by π ( j ) , we ha v e π ( j ) = P j − 1 π (1) . F or j ≥ 2, it suffices to consider k ≥ 2 in (4.3), so w e need only the matrix ( P ( n, k )) n,k ≥ 2 . Since P ( n, k ) = 0 if k > ( n − 1) / 2, this matrix is triangular, and so is P j − 1 . But π (1) ( n ) < 10 − 7 , n > 20, so numericall y , the significan t columns o f P j − 1 are the fi rst 20 columns. Also, w e see the imp ortance of the initial first column of Π. Moreo ver, for n > 75, P ( n, k ) is indistinguishable fr om the Gaussian limit. S o we hav e u s ed the expansion of the G F (4.1) for n ≤ 75 and the Gaussian limit afterw ards in our numerical c alculations. Of cours e we ha v e x ( n ) = ∞ X j =0 Π( n, j ) j, and x ( n ) = 1 + ∞ X k =2 P ( n, k ) x ( k ) , n ≥ 2 . 16 j n ❩ ❩ ❩ 0 1 2 3 0 1 0 0 0 1 1 0 0 0 2 0 1 0 0 3 0 1 0 0 4 0 1 0 0 5 0 13 / 15 2 / 15 0 6 0 28 / 45 17 / 45 0 7 0 118 / 3 15 197 / 315 0 · 20 0 < 10 − 7 • • T able 2: Π l ( n, j ) Remark 4.1. A nother approac h could b e the follo wing: Let I ( k ) := [ [ one of the phases has k pla yers ] ] , I ( j, k ) := [ [ ph ase j has k pla ye rs ] ] , Q ( k ) := P [ I ( k ) = 1] , R ( j, k ) := P [ I ( j, k ) = 1] , Q ( k ) = P h _ j I ( j, k ) = 1 i = n − k X j =1 R ( j, k ) , as P [ I ( j, k ) ∧ I ( i, k )] = 0 , if i 6 = j, R ( j, k ) = X l R ( j − 1 , l ) P ( l , k ) , j ≥ 1 , and R (0 , k ) = δ k n x ( n ) = E h n X 1 I ( k ) i = n X 1 Q ( k ) . A plot of x ( n ) − log 3 n ve rsus log 3 n is giv en in Figure 2 for n = 50 , . . . , 500. The oscillati ons exp ected from (1.16 ) are clear. Recall that according to Theorem 1.3 , there exists a limiting distribution function F ( x ) = F l ( x ) (in a certain sen se) for X n . In Figure 3, we approximat e this distribution fun ction F ( x ) b y plotting Λ( n, j ) = P ( X n ≤ j ) against j − log 3 n for n = 2 0 , . . . , 500, cf. (1.12). W e h a v e also plotted a scaled Gum b el distrib ution; the fit is b ad. Similarly , in Figure 4 w e sh o w the probabilit y Π( n, j ), n = 150 , . . . , 500, p lotted against j − log 3 n . T he fit with a Ga ussian distribution is e qually bad. The few scattered p oints of b oth figu r es are actually due to small n a nd the p ropagation of the more erratic b eha viour for n = 1 , . . . , 40 sh o wn in Figure 5. So we observe the f ollo wing facts: (i) A first regime ( n = 1 , . . . , 40) create some scattered p oin ts whic h almost lo ok lik e t wo distributions. (ii) Bet w een n = 40 and n ∼ 75 , a limiting distribu tion is attained; Π( n, j ) is concen trated on j = log 3 n + O (1), 17 –0.4 –0.35 –0.3 –0.25 –0.2 3 3.5 4 4.5 5 5.5 Figure 2: x l ( n ) − log 3 n versus log 3 n , n = 50 , . . . , 500 (iii) F or n > 75, the limiting Gaussian for P with its n arro w ( √ n ) disp ersion, in tuitiv ely induces, with (4 .3), a propagation, with some smo othing, of the previous distrib ution. W e attain the limiting distrib ution F ( x ) giv en b y Theorem 1.3. (iv) A t most tw o v alues carry the main part of the p r obabilit y mass Π( n, j ). T h is is clear from the observ ed ran ge of F ( x ) in Figures 3 and 4. (v) P is tr iangular, and so is P j . Also, P j ( n, k ) = Θ(1), with k = O (1), only if j = log 3 n + O (1). (vi) As F ( x ) is absolutely con tin uous, we can deriv e, as in [14], m o dulo some uniform in tegrabilit y conditions, all (p erio dic) moments of X n , in particular x ( n ). (vii) The effect of initial values is no w clear. T o illus trate this we ha v e c hanged to Π(0 , 1) = Π(1 , 0) = 1, whic h means that w e add a cost 1 for the extra selection required when the algorithm terminates with n o elemen t left. This leads to T ab le 3. The equ iv alen t of Figures 3, 4 and 5 is giv en in Figures 6, 7 and 8. Note th at X n no longer is stochastica lly monotone in n ; we h a v e by defin ition X 0 = 1 > 0 = X 1 , and T able 3 sho ws other examples of non-monotonicit y for s m all n . Mo reo v er, Figure 6 sho ws that the non- monotonicit y p er s ists for large n ; w e clearly hav e con v ergence to a limit fu nction, G ( x ) sa y , but the limit is not m onotone and th u s not a distribution function as in Figure 4 and, more generally , in Th eorem 1.3. Remark 4.2. Note that th e example in (vii) and Figure 6 does not co nt radict Theorem 1.3 b ecause X n no w is defined with other initial v alues than in Theorem 1.3. Nev ertheless, it is a w arning th at monotonicit y of the limit should not b e take n for granted in cases s uc h as Example 3.4 w ith p < 1 / 2 where the monotonicit y assumption of Theorem 1.3 is not satisfied. 18 0 0.2 0.4 0.6 0.8 1 –1.4 –1.2 –1 –0.8 –0.6 –0.4 –0.2 0.2 0.4 x ◦ : observe d — : Gumb el distribution Figure 3: Λ l ( n, j ) = P ( X n ≤ j ) versus j − log 3 n , app r o ximating F l ( x ), n = 20 , . . . , 500 4.2 P erio dicities Let ψ ( α ) := R e αx f ( x ) dx b e the Laplace trans f orm of the limiting distribution F . (W e do not kno w wh ether ψ ( α ) exists in general, although we conjecture so, but we really on ly need it for imaginary α , i.e., the c haracteristic function of F .) Similarly , let ˜ ψ ( α ) := R e αx ∆ F ( x ) dx b e the Laplace transform of ∆ F . Since ∆ F ( x ) := F ( x ) − F ( x − 1) = R 1 0 f ( x − t ) dt , ∆ F = f ∗ χ [0 , 1] , and thus, since χ [0 , 1] has Laplace transform ( e α − 1) /α , ˜ ψ ( α ) = e α − 1 α ψ ( α ) . With the usual mac hinery (see [1 4] or [10, Theorem 2.3]), w e obtain from Theorem 1.3 and Remark 1.4, assuming some tec hnical conditions that are very lik ely to hold but not rigorously j n ❩ ❩ ❩ 0 1 2 3 0 0 1 0 0 1 1 0 0 0 2 0 0 1 0 3 0 1 / 3 2 / 3 0 4 0 2 / 3 1 / 3 0 5 0 11 / 15 2 / 15 2 / 15 · T able 3: Π( n, j ), other in itializa tion 19 0 0.2 0.4 0.6 0.8 1 –1.5 –1 –0.5 0.5 1 ◦ : observe d — : Gaussian distribution Figure 4: Π l ( n, j ) = P ( X n = j ) versus j − log 3 n , app r o ximating ∆ F l ( x ), n = 150 , . . . , 500 v erified, x ( n ) := E X n = log 3 n + ˜ m 1 + w 1 (log 3 n ) + o (1) , (4.4) where ˜ m 1 := ˜ ψ ′ (0) = ψ ′ (0) + 1 2 , (4.5) w 1 ( x ) := X l 6 =0 ˜ ψ ′ (2 π l i ) e 2 π l i x = X l 6 =0 ψ (2 π l i ) 2 π l i e 2 π l i x . (4.6) With the observed v alues of Π( n, j ) (see Figure 4), w e hav e compu ted the Laplace trans- form n umerically (with a v ariable step E uler–MacLaurin) as follo w s. Assu me th at we ha v e N computed v alues { Π( n i , j i ) : i = 1 , . . . , N } . Setting x = j − log n , this giv es { Π( n i , x i ) : i = 1 , . . . , N } . Sorting wrt x i , we wr ite this as { Π( n k , y k ) : y k ≤ y k +1 , k = 1 , . . . , N } . Construct a numerical Laplace transform ˜ ψ ( α ) = X e αy k Π( n k , y k )( y k +1 − y k − 1 ) / 2 . Using this numerically computed ψ in (4.4)–(4.6), w e co mpute ˜ m 1 + w 1 ( x ), whic h fits quite w ell with the observed p erio dicities of x ( n ) − log 3 n in Figure 2; the comparison is giv en in Figure 9. 20 0 0.2 0.4 0.6 0.8 1 –1.5 –1 –0.5 0.5 Figure 5: Π l ( n, j ) v ersu s j − log 3 n , n = 1 , . . . , 40 5 Second v ariation of the F ranklin leader election algorithm. The circular case If we d enote by P c ( n, k ) the d istribution of the num b er of p eaks in th e circular case and b y P l ( n, k ) the distrib ution in th e linear case, w e k n o w, b y Example 3.9 that P c ( n, k ) = P l ( n − 1 , k − 1). It is easy to c hec k that this leads to , for n ≥ 3 and n ≥ 5, respective ly , M ( n ) = n / 3 , V ( n ) = 2 n/ 45 , whic h also is easy to see pr obabilistically , b y writing Y n as the sum of th e n indicators [ [pla y er i is a p eak] ], and noting that indicators w ith distance a t lea st 3 are in dep end en t.) The in itial v alues are no w giv en by P (1 , 1) = 1 , P (2 , 1) = 1 , P (3 , 1) = 1 , Π(0 , 0) = 1 , Π(1 , 0) = 1 , Π(2 , 1) = 1 , Π(3 , 1) = 1 . The corresp ondin g pictures are give n in T ables 4 and 5. (W e u se a su bscript c for the circular case.) A plot of Λ c ( n, j ) v ersus j − log 3 n for n = 20 , . . . , 500 is give n in Figure 10. W e see that there are fewe r scattered p oints than in th e linear case. Let us mentio n that the fits with Gum b el or Gaussian are equally bad. A comparison o f Λ c ( n, j ) with Λ l ( n, j ) is giv en in Figure 11. No n um erical relation exists b et ween the t wo distribu tions. Π c ( n, j ) v ersus j − log 3 n , n = 1 , . . . , 40, is plotted in Fig ure 12. These initia l p oints are no w scattered less th an in the lin ear case. The obser ved v ersus co mputed p erio d icities are giv en in Fig ure 13. In conclusion, apart fr om numerical differences, the b ehaviour of our tw o v ariations are quite s imilar. Note th at the mean num b er of needed messages is asymptotically 2 n log 3 ( n ), as we use 2 n messages p er roun d. F ranklin [7] giv es an upp er b ound 2 n log 2 ( n ). 21 k n ❩ ❩ ❩ 0 1 2 3 4 1 0 1 0 0 0 2 0 1 0 0 0 3 0 1 0 0 0 4 0 2 / 3 1 / 3 0 0 5 0 1 / 3 2 / 3 0 0 6 0 2 / 15 11 / 15 2 / 15 0 7 0 2 / 45 26 / 45 17 / 45 0 T able 4: P c ( n, k ) j n ❩ ❩ ❩ 0 1 2 3 0 1 0 0 0 1 1 0 0 0 2 0 1 0 0 3 0 1 0 0 4 0 2 / 3 1 / 3 0 5 0 1 / 3 2 / 3 0 6 0 2 / 15 13 / 15 0 7 0 2 / 45 43 / 45 0 · 20 0 < 10 − 7 • • T able 5: Π c ( n, j ) 22 0.2 0.4 0.6 0.8 1 –1.5 –1 –0.5 0.5 1 Figure 6: Λ( n, j ) v ersus j − log 3 n , other initia lization, n = 5 , . . . , 500 References [1] P . Billingsley . Conver genc e of Pr ob ability M e asur es . Wiley , 1968 . [2] L. Carlitz. Perm u tations and sequences. A dvanc es in Mathematics , 14 :92–120 , 1974. [3] M. Drmota, A. Iksano v, M. Mo ehle, and U. Ro esler. A limiting distribu tion for the n umber of cuts needed to isolate t he ro ot of a random recursiv e tr ee. 2006. Prepr int. [4] C. G. Esseen. On the app lication of the theory of p robabilit y to t wo com binatorial problems in vo ving p ermutat ions. In Pr o c e e dings of the Seventh Confer enc e on Pr ob ability The ory (Br a¸ sov, 1982) , pag es 13 7–147, 1 982. [5] J.A. Fill , H. Mahmoud, and W. S zpank o wski. On the distribution for t he duration of a randomized leader election algorithm. An nals of A pplie d P r ob ability , 1:1 260–12 83, 1996 . [6] P . Fla jolet and B. Sedgewic k. A nalytic Combinatorics . C ambridge Universit y Press, to app ear, 2008+. Av ailable at http:// algo.inria.fr/fla jolet/Publications/. [7] W. R. F ranklin. On an impr o v ed algorithm for decen tralized extrema-finding in a circular configuration o f p ro cessors. Communic ations of the A CM , 25(5):336 –337, 1982. [8] A. Gnedin and Y. Y akub o vic h . On th e n um b er of collisions in Λ-coalesce nt s. 2006. arXiv:0704 .3902v1. [9] A. Iksan ov and M. M¨ ohle. A probabilistic p ro of of a w eak limit la w f or the num b er of cuts needed to isolate the ro ot of a random recursiv e tree. Ele ctr onic Communic ations in Pr ob ability , 1 2(4):28– 35, 200 7. [10] S. Janson. Rounding of con tin uous rand om v ariables and oscillato ry asymptotics. Annals of Pr ob ability , 34:18 07–182 6, 2006 . 23 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 –1.5 –1 –0.5 0.5 1 1.5 2 Figure 7: Π( n, j ) v ersu s j − log 3 n , other initializa tion, n = 5 , . . . , 500 [11] S. Jans on an d W. Szpanko wski. Analysis of an asymmetric leader election algorithm. Ele ctr onic Journal of Combinatorics , 4(R1 7), 1997. [12] C. Knessl. Asymp totics and numerical studies of the leader election algorithm. E ur op e an Journal of Applie d Mathemat ics , 12:645 –664, 2001. [13] C. Lav ault and G. Louchard. Asymptotic analysis of a leader election alg orithm. The o- r etic al Computer Scie nc e , 359:239–25 4, 2006. [14] G. Louc hard and H. Pr o dinger. Asymptotics of the m oments of extreme-v alue related d istribution fu nctions. A lgorithmic a , 46:4 31–467 , 2006. Lon g version: h ttp://www.ulb.ac.b e/di/mcs/louc h ard/moml.ps. [15] G. Louc hard and H. Pro dinger. Adv ancing in the presence of a demon. M athematic a Slovac a , to app ear. [16] G. Louc hard and H. Pro dinger. The asymmetric leader elec tion algorithm. Annals of Combinatorics , to app ear. [17] H. Pro dinger. Ho w to ad v ance on a stairw ay b y coin flippings. In Applic ations of Fib onac ci N umb ers, V ol. 5 (St. Andr ews, 1992) , pages 473–479 , 1993. [18] H. Prodin ger. Ho w to select a loser. D iscr ete Mathematics , 120 :149–15 9, 1993. [19] W. Szpank o wski. Aver age Ca se Analysis of Algo rithms on Se q uenc es . Wiley , New Y ork, 2001. 24 0 0.2 0.4 0.6 –1.5 –1 –0.5 0.5 1 1.5 2 Figure 8: Π( n, j ) v ersu s j − log 3 n , n = 1 , . . . , 100, other initializatio n –0.4 –0.35 –0.3 –0.25 4 4.5 5 5.5 x Figure 9: observed x ( n ) − log 3 n ( ◦ ) and computed with (4.4) (line) p erio dicities versus log 3 n (linear case), n = 50 , . . . , 500 25 0 0.2 0.4 0.6 0.8 1 –1.5 –1 –0.5 0.5 Figure 10: Λ c ( n, j ) v ersu s j − log 3 n , app r o ximating F c ( x ), n = 5 , . . . , 500 0 0.2 0.4 0.6 0.8 1 –1.5 –1 –0.5 0.5 Figure 11: A comparison of Λ c ( n, j ) ( right curv e) with Λ l ( n, j ) (left cur v e) 26 0 0.2 0.4 0.6 0.8 –2 –1.5 –1 –0.5 0.5 1 1.5 Figure 12: Π c ( n, j ) v ersus j − log 3 n , n = 1 , . . . , 40 0.06 0.08 0.1 0.12 0.14 0.16 0.18 4 4.5 5 5.5 x Figure 13: observed x ( n ) − log 3 n ( ◦ ) an d computed with (4.4) (line) p erio dicities v ersus log 3 n (circular case), n = 50 , . . . , 500 27
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment