Interior-Point Algorithms for Linear-Programming Decoding
Interior-point algorithms constitute a very interesting class of algorithms for solving linear-programming problems. In this paper we study efficient implementations of such algorithms for solving the linear program that appears in the linear-program…
Authors: Pascal O. Vontobel
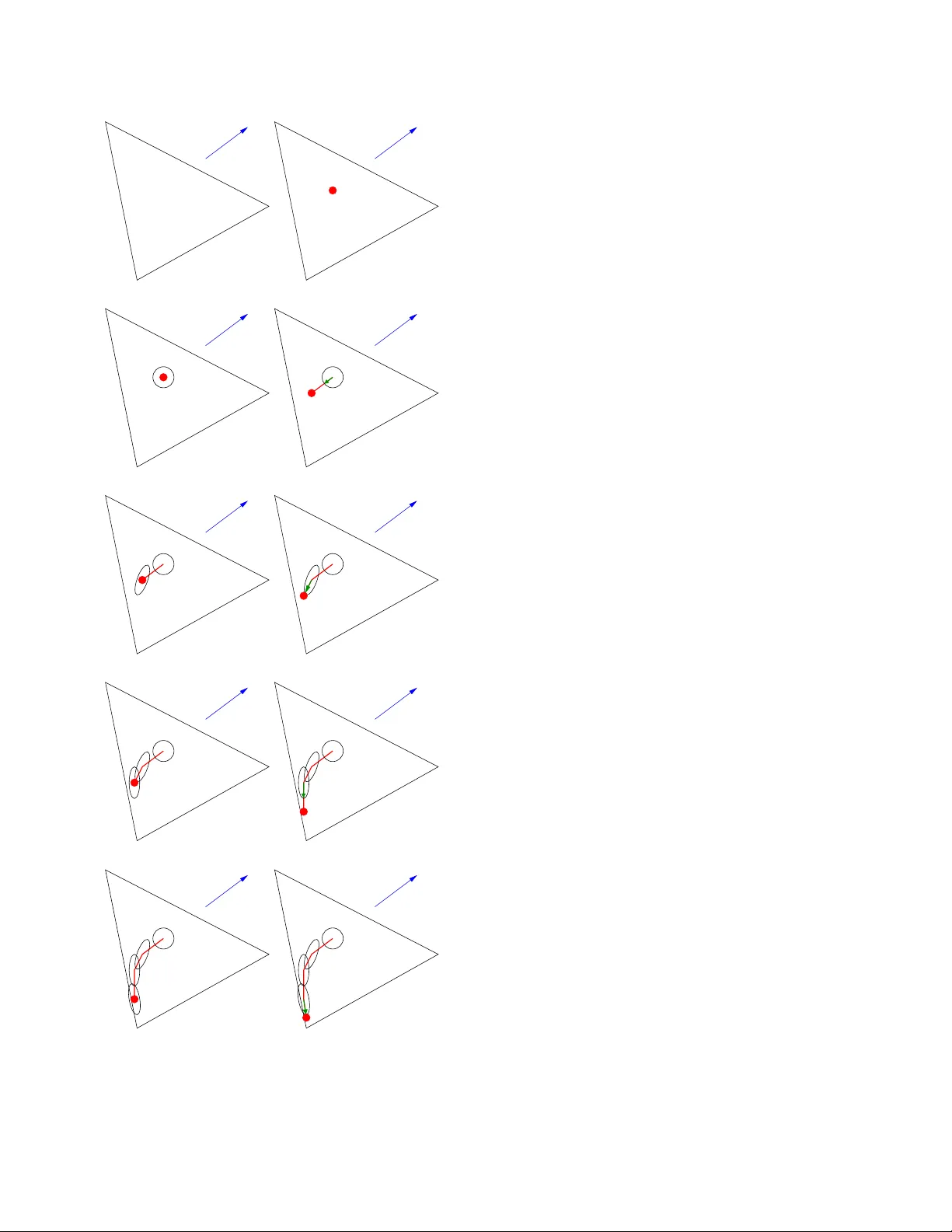
Interior -Point Algorithms for Linear -Programming Decoding 0 Pascal O. V ontobel Hewlett–P ackard Laboratories Palo Alto, CA 94 304, USA Email: pascal.vontobel@ieee.org Abstract — Interior -point algorithms constitute a very interest- ing class of algorithms for solving linear -p rogra mming problems. In this paper we study efficient implementations of such algo- rithms fo r solving the linear progra m that appears in the linear - program ming d ecoder for mulation. I . I N T R O D U C T I O N Consider a binary linear code C of length n that is used for d ata tr ansmission over a binary -input discrete memoryless channel. As was observed by Feld man et al. [1], [2 ], the ML decoder f or this setup can be written as ˆ x ML = ar g min x ∈C h γ , x i , where γ is a length- n vector that contain s the log- likelihood ratios and where h γ , x i is th e inner product (in R ) of the vector γ with the vector x . Because the cost function in this minimization pro blem is linear, this is essentially equivalent to th e solution of ˆ x ′ ML , arg min x ∈ conv( C ) h γ , x i , where conv( C ) den otes the con ve x h ull of C when C is embedd ed in R n . (W e say “essentially equiv a lent” beca use in the case wh ere there is a un ique optimal codeword then th e two minimization problem s y ield the same solutio n. Howe ver, when there are multiple optimal code words then ˆ x ML and ˆ x ′ ML are no n-singlet sets and it h olds that conv( ˆ x ML ) = ˆ x ′ ML .) Because the above two o ptimization p roblems are usu ally practically intractable, Feldman et al. [1], [2] propo sed to solve a r elaxation of the ab ove pr oblem. Namely , f or a cod e C th at can be written as the intersection of m binary linear code s of len gth n , i.e. , C , ∩ m j =1 C j , th ey introd uced the so-ca lled linear pr ogramm ing ( LP) deco der ˆ x LP , arg min x ∈P h γ , x i , (1) with th e relaxed po lytope P , m \ j =1 conv( C j ) ⊇ conv( C ) ⊇ C , (2) 0 This is essentia lly the paper that appeared in the Proceedi ngs of the 2008 Informatio n Theory and Applicati ons W orkshop, U C San Diego , CA, USA, January 27 – F ebruary 1, 2008. The only (major) cha nge conc erns the vec tor γ : it is now defined such that ˆ x ML , ˆ x ′ ML , and ˆ x LP are solutions to minimizati on (and not maximizat ion ) problems. for which it can easily be shown that all co dew ords in C a re vertices of P . The same polytop e P appear ed also in papers by K oetter and V ontobel [3], [ 4], [ 5], wh ere message-passing iterative (MPI) d ecoders were a nalyzed a nd where th is p olytope P was called the fund amental p olytope. The appear ance of th e same object in these two different co ntexts sug gests that there is a tight con nection between LP d ecoding and MPI decodin g. The above co des C j can be any codes o f length n , howe ver , in the following we will foc us on the case where these co des are codes of dimen sion n − 1 . For examp le, let H be an m × n parity-ch eck matrix fo r the code C and let h T j be the j -th row of H . 1 Then, defin ing C j = x ∈ { 0 , 1 } n h h j , x i = 0 (mod 2 ) for j = 1 , . . . , m , we obtain C = ∩ m j =1 C j . Of co urse, the reason why the decod er in (1) is called LP decoder is b ecause the optimization prob lem in that equatio n is a linear pro gram (LP). 2 There are two standard for ms for LPs, n amely minimize h c , x i subj. to Ax = b (3) x ≥ 0 and maximize h b , λ i subj. to A T λ + s = c (4) s ≥ 0 Any LP c an be refo rmulated (b y intr oducin g suitable au xiliary variables, b y reform ulating eq ualities as two inequalities, etc.) so that it loo ks like th e first standard form . Any LP can also be reformulated so th at it looks like the secon d stand ard form. Moreover , the first and second standard form are tightly related in th e sense that they are dual conv ex p rogram s. Usually , the LP in ( 3) is called the prim al LP an d the LP in (4) is called the dual LP . (As it is to be expected from th e expression “d uality , ” the prim al LP is the du al of the d ual LP .) Not unexpected ly , there are ma ny ways to express the LP that appears in (1) in either the fir st or the seco nd standard 1 Note that in this pape r all vectors are column vect ors. 2 W e use LP to denot e both “linear programming” and “linear program. ” form, an d each of th ese refo rmulation s has its advantages (and disadvantages). Onc e it is expressed in on e of the standar d forms, any g eneral-p urpose LP solver can basically be used to obtain the LP d ecoder output. Howe ver , the LP at han d has a lot of structure and one should take ad vantage of it in ord er to obtain very fast algorithms that can comp ete co mplexity- a nd time-wise with MPI decod ers. Sev eral ideas have been p resented in th e past in this direc- tion, e.g., by Feldman et al. [6] who briefly men tioned the use o f sub- gradient meth ods for solving the LP of an early version of th e LP d ecoder (n amely for turbo-like codes), b y Y ang et a l. [7], [8] on efficiently solvable variations of the LP d ecoder, by T agha vi and Siegel [9] o n cuttin g-hyp erplane- type ap proach es, b y V o ntobel and Koetter [10] on coordina te- ascent-type ap proach es, by Dim akis an d W ainwright [11] and by Draper et al. [12] on improvements upon the LP decoder solution, and by T aghavi an d Siegel [13] and by W ad ayama [14] on u sing variations of LP decodin g (to gether with efficient implemen tations) fo r in tersymbol- interferen ce channels. In this pap er ou r focus will be on so-called interio r-point algorithm s, a type of LP solvers that has b ecome popular with the seminal work o f K armarkar [15]. (After the publication of [15] in 1984, earlier work on in terior-point-type alg orithms by Dikin [1 6] and others b ecame m ore wide ly k nown). W e present some in itial thou ghts on how to u se this class of algorithm s in the context of LP decod ing. So far , with the notable exception of [14], interio r-point-type alg orithms that are especially targeted to the LP in (1) do no t seem to have been consider ed. One of ou r goals by p ursuing these type of me thods is that we can potentially obtain alg orithms that are better an alyzable than MPI d ecoders, especially wh en it comes to finite-leng th codes. ( W ad ayama [14] discusses so me efficient inter ior-point-type method s, howev er , he is trying to minimize a q uadratic cost function , and the final solution is obtained throug h the use of the sum- produ ct algor ithm that is in itialized by th e re sult of the in terior-point search. Al- though [1 4] pr esents some very in teresting app roaches that a re worthwhile pursuing, it is not quite clear if these algo rithms are better an alyzable than MPI deco ders.) There are some interesting facts about interio r-point-type algorithm s that make th em worthwh ile study objects. First of all, there are variants for which one can prove p olynom ial-time conv ergence (ev en in the worst case, which is in contra st to the simplex algorithm) . Seco ndly , we can round an intermed iate result to the next vector with only 0 / 1 2 / 1 entries and check if it is a codeword. 3 (This is very similar to the stopping cr iterion that is used for MPI algorith ms.) Note that a similar approa ch will prob ably no t work well fo r simp lex- type algorithms that typically wander from vertex to vertex of the fundam ental polyto pe. The reason is that rou nding the coordin ates of a vertex yields on ly a cod ew ord if the vertex 3 T o be precise, by rounding we m ean that coordi nates below 1 2 are mapped to 0 , that coordinates abov e 1 2 are mapped to 1 , and that coordi nates equal to 1 2 are mapped to 1 2 . was a codew ord. 4 Thirdly , inter ior-point-type algorith ms are also interesting because they ar e less sensitive than simplex- type algo rithms to degenerate vertices of the f easible r egion; this is impor tant because the fundam ental polytope has many degenerate vertices. The present paper is structu red as follows. In Secs. II and III we discuss two classes of interior-point alg orithms, na mely affine-scaling algo rithms and primal- dual interior-point algo - rithms, r espectiv ely . As we will see, the b ottleneck step of the algorithm s in these two sections is to repeatedly find the solutio n to a certain type of sy stem o f linear eq uations. Therefo re, we will address th is issue, and effi cient solu tions to it, in Sec. I V. Finally , we briefly men tion some appr oaches for potential algor ithm simplifications in Sec. V and we con clude the pap er in Sec. VI . I I . A FFI N E - S C A L I N G A L G O R I T H M S An in teresting class o f interior-poin t-type a lgorithms are so-called affine scalin g algorithm s wh ich were introduce d by Dik in [16] and re- in vented m any times afterwards. Goo d introdu ctions to this class of algorithms can be found in [17], [18]. Fig. 1 gives a n intuitive p icture of the working s o f one instance of an affine-scaling alg orithm. Consider the LP in (3) and assum e th at the set of all feasible p oints, i. e., the set of all x such that Ax = b and x ≥ 0 , is a trian gle. For th e vector c shown in Fig. 1, the o ptimal solutio n will be the vertex in the lower left part. The algo rithm works as follows: 1) Select an initial po int that is in the interior o f th e set of all feasible p oints, cf . Fig. 1 (b), and let th e cu rrent p oint be equ al to this initial p oint. 2) Minimizing h c , x i over the triangle is difficult (in fact, it is the p roblem we are trying to s olve); th erefore, we replace the triangle constraint by an ellipsoidal constraint that is centered aro und the cu rrent point. Such an ellipsoid is shown in Fig. 1(c) . I ts ske wness depe nds on the closeness to the different bou ndaries. 3) W e then minimize the function h c , x i over this ellip soid. The d ifference vector between this minimizing p oint and the center o f the ellipsoid (see the little vector in Fig. 1(d)) p oints in the direction in which the next step will be taken. 4) Depend ing on wh at strategy is p ursued, a sho rter o r a longer step in th e above-found direction is taken. This results in a new curr ent point. (Whatever step size is taken, we alw ays impose the constrain t that the step size is such that the new current poin t lies in the interior of the set of feasible p oints.) 5) If the current p oint is “close enough” to som e vertex the n stop, oth erwise go to Step 2. ( “Closeness” is determ ined accordin g to som e criterio n.) 4 Proof: in an LDPC code where all checks hav e deg ree at least tw o, the larg est coordina te of an y nonzer o-vec tor vert ex is at least 1 2 . T herefore, there is no nonzero-vec tor vert ex that is rounded to the all-zer o codew ord. The proof is finished by using the symmetry of the fundament al polytope, i.e., the fac t that the fundamental polyto pe “looks” the same from any code word. c (a) c (b) c (c) c (d) c (e) c (f) c (g) c (h) c (i) c (j) Fig. 1. Some iter ations of the affine -scaling algorithm. (See text for detail s.) Not surp risingly , when shor t (long ) steps are taken in Step 4, the resultin g algo rithm is called the short-step (lo ng-step) affine-scaling algorithm. Convergence pro ofs for d ifferent cases can be foun d in [19], [20], [ 21]. Of course, an affine-scaling algorithm can also be for- mulated for the LP in ( 4). Moreover , in stead of the above- described discrete-time version, one can easily come up with a co ntinuo us-time version, see e.g. [2 2]. T he latter type of algorithm s might actually be interesting for decoders that are implemented in analog VLSI. The bottleneck step in the affine-scaling algorithm is to fin d the new direction, which am ounts to solv ing a system of linear equations of th e f orm Pu = v , where P is a giv en (iter ation- depend ent) po siti ve definite matrix , v is a gi ven vecto r , an d u is the direction vector th at needs to be found . W e will comment on efficient app roaches for solving such systems of eq uations in Sec. IV. I I I . P R I M A L - D U A L I N T E R I O R P O I N T A L G O R I T H M S In contrast to affine-scaling algorithm s, which either work only with the primal LP or o nly with th e dua l LP , prim al- dual inte rior p oint algo rithms – as the name suggests – work simultaneou sly on ob taining a primal and a dual optimal solution. A very readab le and detailed introd uction to this topic can be found in [23]. As in the case of the affine-scaling algorithm th ere ar e m any different variations: sho rt-step, lo ng- step, pre dictor-corrector, p ath-following, e tc. Again, the bottlen eck step is to find the solu tion to a system of linear e quations Pu = v , where P is a given (iteratio n- depend ent) positive definite matrix, v is a gi ven (iteratio n- depend ent) vecto r , and u is the sough t quan tity . W e will comment in Sec. IV on how such systems o f linear equations can be solved efficiently . A variant th at is worthwhile to be men tioned is the class of so-c alled infeasible-in terior-point a lgorithms. The r eason is that very o ften it is easy to fin d an initial primal feasible p oint or it is easy to find an initial dual fe asible poin t but not b oth at th e same time. Therefo re, one starts the algor ithm with a primal/du al point pair wh ere the pr imal and /or the du al poin t are infeasib le points; the algor ithm then tries to d ecrease the amount o f “infe asibility” (a qu antity that we will not define here) at every iteration, b esides of course o ptimizing the co st function . One of the m ost intrigu ing aspects of p rimal-du al interior- point algorithms is the polyno mial-time worst-case bound s that can be stated. Of c ourse, th ese b ounds say mostly someth ing about the behavior when th e algorithm is already close to the solution vertex. It remains to be seen if these results are useful fo r im plementation s of the LP decoder where it is desirable that the in itial iteration s are as agg ressiv e as p ossible and where the b ehavior clo se to a vertex is no t that cr ucial. (W e remind the reader of the roun ding-p rocedu re that was discussed at th e en d o f Sec. I, a proce dure that took ad vantage of some special prop erties of the fun damental polyto pe.) I V . E FFI C I E N T A P P R OA C H E S F O R S O LV I N G Pu = v W H E R E P I S A P O S I T I V E D E FI N I T E M A T R I X In Sec s. I I an d III we saw that the crucial par t in the discussed algo rithms was to repeated ly a nd efficiently solve a system of linear equations that look s like Pu = v , where P is an iteration-dep endent positive d efinite matrix and where v is an iteration-d ependen t vector . Th e fact that P is positive defin ite helps because u can also be seen to be the solution o f the quadr atic unconstrain ed optimization pro blem minimize 1 2 u T Pu − h v , u i (5) subj. to u ∈ R h where we assumed th at P is an h × h - matrix. It is imp ortant to remark that fo r the algo rithms in Secs. II and III the vector u usually does no t have to b e fou nd perfectly . It is good enoug h to find an ap proxim ation of u that is clo se enough to the correct u . (For mo re details, see e.g . [18, Ch. 9].) Using a standard gr adient-typ e algorithm to find u might work. Howev er , the matrix P is of ten ill-conditioned , i.e., the ratio of the largest to the smallest eigenv alue can be quite big (especially to wards the final iterations), and so the con vergen ce speed of a gradien t-type algorithm mig ht suffer considera bly . Therefo re, more sophisticated approache s are desirable. Such an a pproach is the conju gate-grad ient algorithm wh ich was intro duced by Hestenes an d Stiefel [24]. ( See Shewchuk’ s paper [2 5] for a very re adable introdu ction to this topic an d for some histor ical comments.) This method is especially attractive when P is sparse or when P can be written as a produ ct o f sparse matr ices, the latter being the case for LP decodin g o f LDPC cod es. In the context of th e affine-scaling algorith m, e.g. Resende and V eig a [ 26] used th e conjug ate-grad ient a lgorithm to e ffi- ciently solve the relev ant equa tion systems. They also studied the b ehavior of the con jugate-gr adient algorithm with different pre-con ditioners. A qu ite different, yet interesting variant to solve th e mini- mization p roblem in (5) is by usin g grap hical models. Namely , one can r epresent the co st f unction in (5) by an ad ditive factor graph [27], [28], [29]. Of course, there are a variety of factor graph representatio ns for the this cost function, ho we ver , probab ly the most reasonab le choice in the context o f LP decodin g is to c hoose th e factor graph that loo ks to pologically like th e factor graph that is usua lly used for sum -prod uct or min-sum algorith m d ecoding of LDPC co des. One can then try to find th e solution with the h elp of the m in-sum algorith m. [Equivalently , one can loo k at the maximizatio n p roblem maximize exp − 1 2 u T Pu + h v , u i (6) subj. to u ∈ R h . Here th e func tion to b e optimized is pro portion al to a Gau s- sian den sity an d can be rep resented with a Gaussian factor (a) (b) Fig. 2. Replac ement of a partial factor graph representing a degree- k chec k functio n node by another partial factor graph with k − 2 check nodes of degree three and with k − 3 ne w auxili ary vari able nodes. (Here k = 6 .) graph [2 7], [ 28], [29]. (Which in co ntrast to the above factor graph is a multiplicative factor grap h.) One can th en try to find the solution with the help of the m ax-pro duct algorithm, which in the case o f Gaussian grap hical models is equiv alent (up to propo rtionality constants) to the sum-pro duct algorithm.] The re ason for this being an interesting app roach is th at the beh avior o f the m in-sum algo rithm applied to a quad ratic- cost-functio n factor g raphs is much better und erstood than for other factor graphs. E .g., it is known that if the algo rithm conv erges then the solutio n vector is correct. More over , by now ther e are also pra ctically verifiable sufficient co nditions for conv ergence [ 30], [31], [ 32]. Ho wever , th e q uadratic-c ost- function factor graphs needed for the ab ove pr oblem are more general than the special class of quad ratic-cost-fu nction factor graphs considere d in the cited paper s. Of course, one could represent the cost fun ction in (6) by a factor g raph within this special class ( so that the ab ove-mentioned results are applicable) , h owe ver , and quite interestingly , wh en this cost function is represented by a factor gr aph th at is n ot in this special class, then th e conv ergence con ditions seem to be (judgin g from some empirical e vidence) less stringen t. I n fact, we ob tained some very intere sting behavior in the co ntext of the sh ort-step affine-scaling algorithm where only one iteration of the min -sum algorithm was perform ed per iteration of the affine-scaling algorith m. (The min-sum algorith m was initialized with th e me ssages obtained in the p revious affine- scaling algo rithm iteration .) V . O T H E R S I M P L I FI C A T I O N S Dependin g on the used algo rithm, there ar e many small (but very useful) variations that can lead – w hen p roperly ap plied – to considerable simplifications. E.g., one can replace the partial factor graph in Fig. 2(a) by the partial factor g raph in Fig. 2 (b) that co ntains ne w auxiliary v ariable nodes but contains only ch eck nodes of d egree three [33], [34]. Or, one can ada ptiv ely modify the set of inequalities that are included in the LP formu lation [9], [ 14]. V I . C O N C L U S I O N W e have presented some initial consideratio ns tow ards using interior-point algorithm s f or obtain ing efficient L P de coders. Encour aging preliminar y results h av e been o btained but mor e research is n eeded to fu lly und erstand and exploit the p otential of these algo rithms. A C K N O W L E D G M E N T This research was partly supported by NSF Grant CCF- 05148 01. R E F E R E N C E S [1] J. F eldman, “Decoding error-corre cting codes via linear programming , ” Ph.D. dissertation, Massachusetts Institute of T echnology , Cambridge, MA, 2003. [2] J. Feldman, M. J. W ainwright, and D. R. Karger , “Using linear program- ming to decode binary linear codes, ” IEE E T rans. on Inform. Theory , vol. IT –51, no. 3, pp. 954–972, May 2005. [3] R. Koett er and P . O. V ontobel, “Graph cov ers and iterati v e decoding of finite-lengt h codes, ” in Proc . 3r d Intern. Symp. on T urbo Codes and Related T opics , Brest, F rance, Sept. 1–5 2003, pp. 75–82. [4] P . O. V ontobel and R. Koe tter , “Graph-co ver decoding and finite- length analysis of message-passing itera ti ve decoding of LDPC codes, ” accept ed for IE EE Tr ans. Inform. Theory , available online under http://www.arx iv.org/abs/cs.I T/0512078 , 2007. [5] ——, “On the relationship between linea r programming decodi ng and min-sum algorithm decoding, ” in Pr oc. Intern. Symp. on Inform. Theory and its A pplicat ions (ISIT A) , Pa rma, Italy , Oct. 10–13 2004, pp. 991– 996. [6] J. Feldman, D. R. Karger , and M. J. W ainwri ght, “Linea r programming- based decodi ng of turbo-lik e codes and its relation to iterati ve ap- proache s, ” in Pro c. 40th Allerton Conf. on Communications, Contr ol, and Computing , Allerton House, Monticel lo, Illinois, USA, October 2– 4 2002. [7] K. Y ang, X. W ang, and J. Feldman, “Non-linear programming ap- proache s to decodin g low-densit y parity-ch eck codes, ” in Proc . 43rd Allerton Conf . on Communications, Contr ol, and Computing , Allerton House, Montic ello, Illinois, USA, Sep. 28–30 2005. [8] ——, “Fast ML decoding of SPC product code by linear program- ming decoding, ” in Pr oc. IEEE GLOBECOM , W ashingt on, DC, USA, Nov . 26–30 2007, pp. 1577–1581. [9] M. H. T aghavi and P . H. Siege l, “ Adaptiv e linear programming decod- ing, ” in Proc. IEEE Intern. Symp. on Inform. Theory , S eattl e, W A, USA, July 9–14 2006, pp. 1374–1378. [10] P . O. V ontobel and R. Koett er , “On low-c omplexi ty linear -programming decodin g of LDPC codes, ” Europ. T rans. on T elecomm. , vol. 5, pp. 509– 517, Aug. 2007. [11] A. G. Dimakis and M. J. W ainwright, “Guessing face ts: polytope structure and improv ed LP decoder , ” in Pro c. IE EE Intern. Symp. on Inform. Theory , Seattle, W A, USA, July 9–14 2006, pp. 1369–1373. [12] S. C. Draper , J. S. Y edi dia, and Y . W ang, “ML decoding via mixed- inte ger adapti ve linear programming, ” in Pr oc. IEEE Intern. Symp. on Inform. Theory , Nice, France, June 24–29 2007, pp. 1656–1660. [13] M. H. T agha vi and P . H. Siegel, “Equaliz ation on graphs: linear programming and message passing, ” in Pr oc. IE EE Intern. Symp. on Inform. Theory , Nice, France, June 24–29 2007, pp. 2551–2555. [14] T . W adaya ma, “Interior point decoding for linear vector chan- nels, ” submitt ed, avail able onli ne under http:// 0705.3990 , May 2007. [15] N. Karmarkar , “ A ne w polynomial -time algorithm for linear program- ming, ” Combinat orica , vol. 4, no. 4, pp. 373–395, Dec. 1984. [16] I. I. Dikin, “Iterat i ve solutio n of problems of linear and quadrat ic programming, ” Sov iet Math. Dokla dy , vol. 8, pp. 674–675 , 1967. [17] D. Bertsek as, Nonl inear Pro grammin g , 2nd ed. Belmont, MA: Athena Scienti fic, 1999. [18] D. Bertsimas and J. N. Tsitsiklis, Linear Optimizat ion . Bel mont, MA: Athena Scientific, 1997. [19] T . Ts uchiya , “Global con ver gence of the affine s calin g methods for dege nerate line ar programming proble ms, ” Math. P r ogr . , vol. 52, no. 3, pp. 377–404, May 1991. [20] T . Tsuchiya and M. Muramatsu, “Global con vergenc e of a long-step af fine scaling algorith m for degenera te linear progra mming problems, ” SIAM J. Opt. , vol. 5, no. 3, pp. 525–551, Aug. 1995. [21] R. S aigal , “ A simple proof of a primal af fine scaling method, ” Ann. Oper . Res. , vo l. 62, pp. 303–324, 1996. [22] I. Adler and R. D. C. Monteiro, “Limiting beha vior of the affine scaling continu ous traject ories for linea r programming problems, ” Math. P r ogr . , vol. 50, no. 1, pp. 29–51, Mar . 1991. [23] S. J. Wright, Primal-Dual Interior -P oint Methods . Philade lphia, P A: Society for Industrial and Applied Mathemat ics (SIAM), 1997. [24] M. R. Hestenes and E. S tiefe l, “Methods of conjuga te gradients for solving linear systems, ” J ournal of R esear ch of the National Bur eau of Standar ds , vo l. 49, 1952. [25] J. R. She wchuk, An intr oduction to the conjugate gradien t method without the agonizing pain . T echnical Report, Carneg ie Mellon Uni versi ty , Pitt sburg h, P A, 1994. [26] M. G. C. Resende and G. V eiga, “ An implementat ion of the dual affine scaling algori thm for m inimum-cost flow on biparti te uncap acita ted netw orks, ” SIAM Journal on Optimizat ion , vol. 3, no. 3, pp. 516–537, 1993. [27] F . R. Kschischan g, B. J. Frey , and H.-A. Loeliger , “Fac tor graph s and the sum-product algorithm, ” IEEE T rans. on Inform. Theory , vol. IT –47, no. 2, pp. 498–519, Feb. 2001. [28] G. D. Forne y , Jr ., “Codes on graph s: normal real izati ons, ” IEEE T rans. on Inform. Theory , vo l. IT –47, no. 2, pp. 520–548, Feb . 2001. [29] H.-A. Loelige r , “ An introduc tion to fac tor graphs, ” IEEE Sig . Pr oc. Ma g. , vol. 21, no. 1, pp. 28–41, Jan. 2004. [30] D. M. Maliouto v , J. K. J ohnson, and A. S. W illsk y , “W alk-sums and belie f propagatio n in Gaussian graphic al models, ” J . Mach. L earn. Res. , vol. 7, pp. 2031–2064, Dec. 2006. [31] C. C. Moallemi and B. V an Roy, “Con ver gence of the min-sum message passing algorithm for quadrat ic optimizati on, ” submitted , Mar . 2006. [32] ——, “Con ver gence of the m in-sum algorithm for conv e x optimization, ” submitte d , May 2007. [33] M. Chertk ov and M. Stepanov , “Pseudo-code word landsc ape, ” in Proc. IEEE Intern. Symp. on Inform. Theory , Nice, France, June 24–29 2007, pp. 1546–1550. [34] K. Y an g, X. W ang, and J. Feldman, “Cascade d formulat ion of the fundamenta l polytope of general linea r block codes, ” in P r oc. IE EE Intern. Symp. on Inform. Theory , Nice, France , June 24–29 2007, pp. 1361–1365.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment