Bayesian Checking of the Second Levels of Hierarchical Models
Hierarchical models are increasingly used in many applications. Along with this increased use comes a desire to investigate whether the model is compatible with the observed data. Bayesian methods are well suited to eliminate the many (nuisance) para…
Authors: M. J. Bayarri, M. E. Castellanos
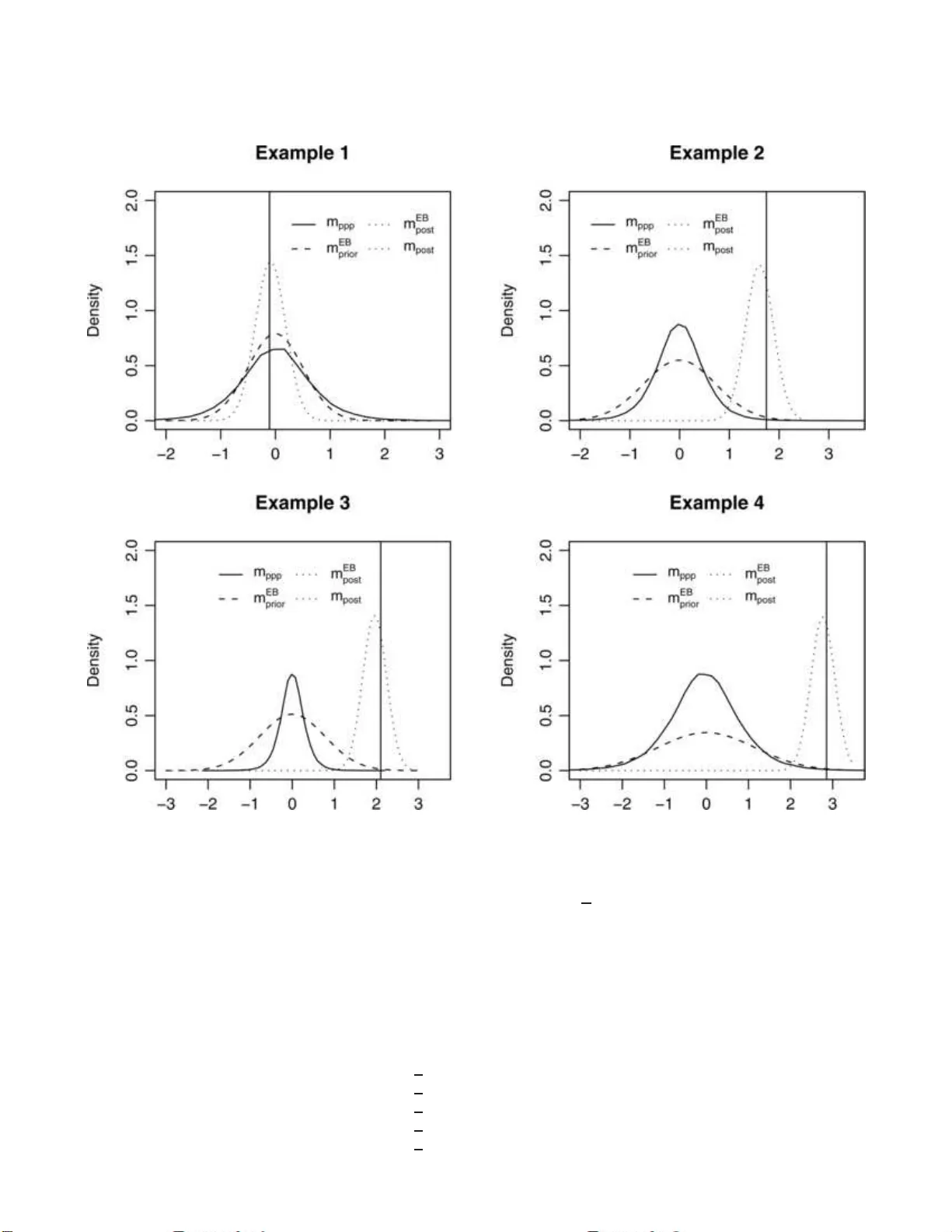
Statistic al Scienc e 2007, V ol. 22, No. 3, 322– 343 DOI: 10.1214 /07-STS235 c Institute of Mathematical Statisti cs , 2007 Ba y esian Checking of the Second L e vels of Hi e ra rc hi cal Mo dels 1 M. J. Ba y a rri and M. E. Castellanos Abstr act. Hierarc h ical mo dels are increasingly used in man y appli- cations. Along with this increased use comes a desire to in v estigate whether the m o del is compatible with the observed data. Ba y esian metho ds are w ell suited to eliminate the many (n uisance) paramete rs in these complicated mo dels; in this pap er w e in ve stigate Ba yesia n meth- o ds for mo del chec king. Since w e con template mo d el c hec king as a pre- liminary , exploratory analysis, w e concen trate on obje ctive Bayesian metho ds in whic h careful sp ecification of an in formativ e prior distribu- tion is a vo ided. Numerous exa mples are giv en and different p rop osals are inv estigated an d critically compared. Key wor ds and phr ases: Mo del chec king, mo del c riticism, ob j ectiv e Ba yesia n metho ds, p -v alues, conflict, empir ical-Ba y es, p osterior pre- dictiv e, partial p osterior p redictiv e. 1. INTRODUCTION With the a v ailabilit y of p ow erfu l numerical com- putations, use of hierarchica l (or multilev el, or ran- dom effects) mod els has b ecome ve ry common in ap- plications. They nicely generaliz e and extend standard one-lev el mo dels to complica ted situations, where these simple mo dels would not ap- ply . With their widesp r ead use comes along an in - creased need t o c heck the ad equ acy of su ch mo d- els to the observ ed data. Recent Ba y esian metho d s ( Ba yarri and Berger ( 1999 ), 2000 ) ha v e sho wn con- M. J . Bayarri is Pr ofessor, Dep artment of Statist ics and Op er ation R ese ar ch, University of V alencia, Burjassot, (V alencia), 46100 Sp ain e-mail: susie.b ayarri@uv.es . M. E. Castel lanos is Asso ciate Pr ofessor, Dep artment of Statistics and Op er ation R ese ar ch, R ey J uan Carlos University, M´ ostoles, (Madrid), 28933 Sp ain e-mail: maria.c ast el lanos@urjc.es . 1 Discussed in 10.1214 /07-STS235C , 10.1214 /07-STS235A , 10.1214 /07-STS235D and 10.1214/07-STS235B ; rejoinder at 10.1214 /07-STS235REJ . This is an electronic reprint of the original ar ticle published b y the Institute of Mathematical Statistics in Statistic al Scienc e , 2007 , V ol. 22, No. 3 , 3 22–3 43 . This reprint differs from the or iginal in pagina tion and t yp ogr aphic detail. siderable promise in c hec king one-lev el mod els, esp e- cially in nonstandard situations in whic h parameter- free testing s tatistics are not known. In this pap er w e show ho w these m etho ds can b e extended to c h ec king hierarc hical mo dels. W e also review state- of-the-art Ba ye sian p rop osals for c hec king hierarchi- cal mo d els and critically compare th em. W e appr oac h mo del c hec king as a p reliminary anal- ysis in that if the data are compatible with the as- sumed mo d el, then the full (and difficult) Ba y esian pro cess of mo del elab oration and mo del selection (or a veraging) can b e a voided. Th e role of Ba yesia n mo del chec king v ersus mod el selection has b een d is- cussed, fo r example, in Ba yarri and Berger ( 1999 , 2000 ) and O’Hagan ( 2003 ) and we will n ot rep eat it here. In general, in a parametric m o del c h ec king sce- nario, w e relate observ ables X with paramet ers θ through a parametric mo del X | θ ∼ f ( x | θ ) . W e then observe data x obs and wish to assess wh ether x obs are compatible with the assumed (null) mo del f ( x | θ ). Most of the existing metho d s for mo del c h ec king (b oth Ba yesia n and frequentist) can b e seen to corresp ond to particular c hoices of: 1. A diagnostic statistic T , to quanti fy incompati- bilit y of the mo del with the observ ed data thr ough t obs = T ( x obs ). 1 2 M. J. BA Y ARRI AND M. E. CASTELLANOS 2. A completely sp ecified distrib ution for the statis- tic, h ( t ), under the n u ll mo del, in which to lo cate the observ ed t obs . 3. A wa y to measur e conflict b et wee n the observ ed statistic, and the null distribution, h ( t ), for T . The most p opular measures are ta il areas ( p -v alues) and relativ e h eigh t of th e d en sit y h ( t ) at t obs . In this pap er, w e concen tr ate on the optimal c hoice in item 2, whic h basically red u ces to c hoice of meth- o ds to eliminate the nuisance parameters θ from the null mo del. Our recommendations then apply to any c hoices in 1 and 3. [W e abuse notation and use the same h ( · ) to ind icate b oth the completely sp ecified distr ibution for X , after elimination of θ , and the corresp ond ing distribution for T .] Of course, c h oice of 1 is very imp ortan t; as a matter of fact, in some scenarios a “goo d” T can b e c h osen w hic h is ancillary or nearly so, thus making c hoice of 2 nearly irrelev an t. S o our w ork w ill b e most rele- v an t for complica ted scenarios when suc h optimal T ’s are not kno wn, or extremely difficult to imp le- men t (for an example of these, see Robin s, v an der V aart a nd V e ntura ( 2000 )). In these situati ons, T is often c hosen casually , based on in tuitiv e consid- erations, and hence w e concen trate on these c hoices (with no implications w hatso ev er that these are our recommended choic es for T ; w e s imply do not ad- dress choic e of T in this pap er). Also, without loss of generalit y , w e can assume that T has b een defin ed suc h that the larger T is, th e more incompatible data are w ith the assumed mo d el. As measures of conflict in item 3 abov e, we explore the tw o b est known me a- sur es of surp rise , namely the p -v alue and the r elative pr e dictive surprise, RPS (see Berger ( 1985 ), Section 4.7.2) used (with v arian ts) by man y au th ors. Th ese t w o measures are defin ed as p = Pr h ( · ) ( t ( X ) ≥ t ( x obs )) , (1.1) RPS = h ( t ( x obs )) sup t h ( t ) . (1.2) Note that smal l v alues of ( 1.1 ) and ( 1.2 ) denote in- compatibilit y . F requen tist and Ba y esian c hoices for h ( · ) are dis- cussed at length in Ba yarri and Berger ( 2000 ), and w e limit our selv es here to an extremely br ief (and incomplete) mentio n of some of them. Th e natu- ral Ba y esian c hoice for h ( · ) is the prior p redictiv e distribution, in wh ic h the parameters get natur ally in tegrated out with resp ect to the prior distribu - tion. ( Bo x ( 198 0 ) pioneered use of p -v alues com- puted in the prior predictiv e for Ba yesian mo del cr it- icism.) Ho wev er, this requires a fairly in f ormativ e prior distrib ution (see O’Hagan ( 2003 ) for a discus- sion) whic h might not b e desirable for m o del c h ec k- ing for t wo r easons: (i) we might wish to a void the careful (and difficult) p rior quantificati on in these earlier stages of the analysis, sin ce the mo d el might w ell not b e appropr iate and hence the effort is w asted; (ii) most imp ortan tly , mo d el c hec king with informa- tiv e priors cannot separate inadequacy of the prior from in adequacy of the mo del. In the sequ el we will concent rate on obje ctive Ba yesia n method s for m o del c hec king. W e use the term obje ctive to refer to Ba yesian methods in whic h the priors are c hosen by some default, agreed u p on rules ( obje ctive priors ) rather than r eflecting gen- uine (sub jectiv e) prior information. This term is fr e- quen t among Ba y esians (see, e.g., Berger, 2003 , 2006 ) but its use is n ot without cont rov ersy . Ob jectiv e priors are u sually improp er. Note that this impro- priet y mak es the pr ior pr ed ictiv e distribution und e- fined and hence not a v ailable for (ob jectiv e) mo del c h ec king. Guttman’s ( 1967 ) an d Rubin’s ( 1984 ) choic e for h ( · ) is the p osterior p r edictiv e distr ib ution, result- ing from in tegrating θ out with resp ect to the p os- terior distribu tion instead of the p rior. This allo ws use of improp er priors, and h ence of ob jectiv e mo del c h ec king. Th is p rop osal is ve ry easy to implemen t b y Marko v c hain Mon te Carlo (MCMC) metho ds, and hence has b ecome fairly p opular in Bay esian mo del c hec king. Ho we ve r, its double use of the data can result in an extreme conserv atism of the re- sulting p -v alues, unless the c hecking statisti c is fairly ancillary (in whic h case the wa y to deal with the p arameters is basically irrelev an t). This con- serv atism is sho w n to hold asymptotically in Robins, v an der V aart and V entura ( 2000 ), and for finite n and sev eral sce narios in, for e xample, B a- y arri an d Berger ( 1999 , 2000 ), Ba yarri and C astellanos ( 2001 ) and Ba y arri an d Morales ( 2003 ). Miscalibra- tion of p osterior predictiv e measures is also do cu- men ted in Dahl ( 200 6 ), Drap er and Krn ja ji ´ c ( 2006 ) and Hjort, Dahl and Steinbakk ( 20 06 ); the double use of the data was noted in the d iscu ssion of Gelman, Meng and Stern ( 2003 ) (see, in particular, Drap er ( 1996 )). This is not mean t in an y wa y to im- ply that p osterior predictiv e measures are w ith ou t merit [see Gelman ( 200 3 ) f or a recent exp osition of BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 3 their adv an tages and in terpretation], only th at they ha v e to b e interpreted in a differen t w a y: a p osterior p -v alue equal to, sa y , 0 . 4 can not naiv ely b e in ter- preted as co mpatibilit y with the null mo d el in a l l problems. A small p osterior predictiv e measure can safely b e interpreted as incompatibilit y with the null mo del. Alternativ e choic es of h ( · ) for ob jectiv e m o del c h ec king are prop osed in Ba y arri and Berger ( 1997 , 1999 , 2000 ). Th eir asymptotic optimalit y is sh own in Robins, v an der V aart and V entura ( 2000 ). In this pap er we deriv e these marginals for hierarchica l mo del c hec king. W e a lso compare the results with those obtained with p osterior pr ed ictiv e d istribu- tions and sev eral “p lu g-in” c hoices for h ( · ). Note that “plug-in” p -v alues would b e natural c hoices for frequent ist c h ec k in g when in terpreting the s econd lev el of a h ierarc hical m o del as a “random effect,” so in particular, we compare some p opular choic es of Ba y esian p -v alues with MLE “plug-in” p -v alues. There are not man y prop osals for chec king the dis- tributional assumption o f “rand om effects.” Alo ng with the mentioned metho ds, we also carefully re- view state-of-t he-art Ba yesia n prop osals, namely (i) the simulation-b ase d c h ec king of Dey , Gelfand, Swartz and Vlac hos ( 1998 ), a compu - tationally intensiv e m etho d b ased on Mon te Carlo tests, (ii) the O ’ Hagan method ( O’Hagan ( 200 3 )) for c hec king graphical mo dels, and (iii) the c onflict p -values of Marshall and Sp iegelhalter ( 2003 ), close in spirit to cross-v alidation metho ds. W e critically compare these metho ds in sev eral examples. In this pap er most atten tion is devo ted to the chec king of a fairly simple normal-normal hierarc hical mo d el so as to b est illustrate the different prop osals a nd criti- cally judge their b eh a v ior. Of course, the main ideas also apply to the c h ecking of many other hierarc h i- cal mo dels. In S ection 2 w e briefly review the dif- feren t m e asur es of surprise (MS) that we will de- riv e and compare. In Sectio n 3 we deriv e th ese mea- sures for the hierarchica l normal-normal mo d el. W e also study the sampling d istribution of the d ifferen t p -v alues, b oth when the null mo d el is tru e, an d w hen the data come from alternativ e mo dels. In Section 4 w e apply these measures to a particular simple test whic h allo ws easy and int uitive comparisons of the differen t prop osals. In Section 5 we br iefly s umma- rize other metho d s for Ba yesia n c hec king of hierar- c h ical mo dels, namely those prop osed by Dey , Gelfand, Swartz and Vlac hos ( 1998 ), O’Hagan ( 2003 ) and Marshall and S p iegelhalter ( 20 03 ), com- paring them with the p revious prop osals in an exam- ple. Finally , in Section 6 we c hec k the adequacy of a binomial/b eta hierarchica l mo del in a we ll-kno wn example using a ll of the method s review ed in the pap er. 2. MEASURES OF S URPRISE IN THE CHECKING OF HIERARCHICAL MODELS In this pap er w e will b e dealing with the MS de- fined in ( 1.1 ) and ( 1.2 ). Their relativ e merits and dra wbac ks are d iscussed at length in Ba y arri and Berger ( 1997 , 1999 ) and w ill not b e rep eated here. In this section w e d eriv e these measures in the con- text of hierarc hical mo dels, and for some sp ecific c h oices of the completely sp ecified distrib ution h ( · ). W e consider the general t w o-lev el mo del: X ij | θ i ind . ∼ f ( x ij | θ i ) , i = 1 , . . . , I ; j = 1 , . . . , n i , θ | η ind . ∼ π ( θ | η ) = I Y i =1 π ( θ i | η ) , η ∼ π ( η ) , where θ = ( θ 1 , . . . , θ I ) an d η = ( η 1 , . . . , η p ) T o get a completely sp ecified distribution h ( · ) f or X , w e need to in tegrate θ out from f ( x | θ ) with re- sp ect to some completely s p ecified distribu tion for θ . W e next consider three p ossibilities that ha ve b een p rop osed in the literature for such a d istribu- tion: empirical Ba ye s t yp es (plug-in), p osterior d is- tribution, and partial p osterior distribu tion, as they apply in the hierarc hical scenario. Notice that, since w e w ill b e d ealing with improp er priors for η , the natural (marginal) pr ior π ( θ ) is also improp er and cannot b e used for this pur p ose [it would pro d uce an impr op er h ( · )]. 2.1 Empirical Ba y es (Plug-In) Measures This is the sim p lest prop osal, v ery intuitiv e and frequent ly used in empirical Ba ye s analysis (see, e.g., Carlin and Louis ( 2000 ), Chapter 3). It simply con- sists in replacing the unknown η in π ( θ | η ) by an estimate (we use the MLE, b ut moment estimates are often used as well) . In this prop osal, θ is inte - grated out with resp ect to π EB ( θ ) = π ( θ | b η ) = π ( θ | η = b η ) , (2.1) where b η maximizes th e in tegrated lik eliho o d: f ( x | η ) = Z f ( x | θ ) π ( θ | η ) d θ . 4 M. J. BA Y ARRI AND M. E. CASTELLANOS The corresp ond ing pr op osal for a completely sp eci- fied h ( · ) in wh ic h to defin e the MS is m EB prior ( t ) = Z f ( t | θ ) π EB ( θ ) d θ . (2.2) The MS p EB prior and RPS EB prior are no w given b y ( 1.1 ) and ( 1.2 ), r esp ectiv ely , in whic h h ( · ) = m EB prior ( · ). Strictly for comparison pu rp oses, w e will later use another d istribution whic h is also of the empirical Ba yes t yp e; in th is new distribution, the empirical Ba yes prior ( 2.1 ) gets n eedlessly (and inapp r opri- ately) up dated us in g again the same d ata. In this (wrong) prop osal, θ gets integ rated out with resp ect to π EB ( θ | x obs ) ∝ f ( x obs | θ ) π EB ( θ ) , (2.3) resulting in m EB p ost ( t ) = Z f ( t | θ ) π EB ( θ | x obs ) d θ . (2.4) The corresp onding MS p EB p ost and RPS EB p ost are again computed u sing ( 1.1 ) a nd ( 1 .2 ), resp ectiv ely , with h ( · ) = m EB p ost ( t ). 2.2 P osterio r Predictive Measures This p rop osal is also intuitiv e and seems to hav e a more Ba ye sian “fla vour” than the p lug-in s olution present ed in the previous section. This along with its ease of imp lemen tation has made the metho d a p opular one for ob jectiv e Ba yesian mo del c hec king. This p opularit y mak es in v estigation of its prop erties all the m ore imp ortant . The idea is simple: use th e p osterior to in tegrate θ ou t. Assuming that the p os- terior is p rop er (as usual), th is allo w s mo del chec k- ing when π ( η ) [and hence π ( θ )] is improp er. T h us, the prop osal for h ( · ) is the p osterior p redictiv e dis- tribution m p ost ( t | x obs ) = Z f ( t | θ ) π ( θ | x obs ) d θ , (2.5) where π ( θ | x obs ) is th e marginal from the joint p os- terior π ( θ , η | x obs ) ∝ f ( x obs | θ ) π ( θ , η ) = f ( x obs | θ ) π ( η ) I Y i =1 π ( θ i | η ) . The p osterior p -value and the p osterior RPS are denoted b y p p ost and RPS p ost , and computed from ( 1.1 ) and ( 1.2 ), resp ectiv ely , w ith h ( · ) = m p ost ( · ). It is imp ortan t to r emark that, und er regularit y conditions, the empirical Bay es p osterior π EB ( θ | x obs ) giv en in ( 2.3 ) appro ximates the tru e p osterior π ( θ | x obs ). Both are, in fact, asymptotically equiv a- len t. Hence whatev er inadequ acy of m EB p ost ( t ) in ( 2.4 ) for mo del c hec king is likely to apply as well to the p osterior predictiv e m p ost ( t | x obs ) in ( 2.5 ). W e w ill see demonstration of the similar b eha vior of b oth predictiv e distribu tions in all the examples in this pap er. Use of p osterior pr edictiv e measures was in- tro duced b y Guttman ( 1967 ) and Rubin ( 1984 ) and extended and formalized in Gelman, Meng and Stern ( 2003 ). They are v ery easy to compute and they are p erhap s th e most widely used c hec king p r o cedure. W e refer to Meng ( 1994 ), Gelman, Meng and Stern ( 2003 ) and Gelman ( 2003 ) for extended discuss ion and m otiv ation. 2.3 P a rtial P osterio r Predictive Measures Both the empirical Ba y es and p osterior prop osals present ed in Sections 2.1 and 2.2 use the same data to (i) “train” th e improp er π ( θ ) into a prop er dis- tribution to compute a predictiv e d istribution and (ii) compute the observe d t obs to b e lo cated in th is same predictiv e distribution throu gh the MS. This can r esult in a sev ere conserv atism in capable of de- tecting clea rly inappropr iate mo dels. A natural w a y to a void this d ouble use of the data is to u se part of the d ata for “training” and th e rest to compute the MS, as in cross-v alidation m etho ds. The p ro- p osal in Ba yarri and Berger ( 1999 , 2000 ) is similar in spirit: since t obs is used to compute the su r prise measures, it uses the information in the data not in t obs to “train” the improp er prior in to a prop er one. A natural w a y to “remo ve ” the inform ation in t obs = T ( X = x obs ) fr om x obs is by conditioning in the observed v alue of the statistic T ( X ); that is, us- ing the c onditional distribu tion f ( x obs | t obs , θ ) in- stead of f ( x obs | θ ) to defin e the likel iho o d. The re- sulting p osterior distribution for θ (assumed prop er) is ca lled a p artial p osterior distribution and giv en by π ppp ( θ | x obs \ t obs ) ∝ f ( x obs | t obs , θ ) π ( θ ) ∝ f ( x obs | θ ) π ( θ ) f ( t obs | θ ) . The corresp onding prop osal for th e completely sp ec- ified h ( · ) is then the p artial p osterior pr e dictive dis- tribution computed as m ppp ( t | x obs \ t obs ) = Z f ( t | θ ) π ( θ | x obs \ t obs ) d θ . The p artial p osterior pr e dictive me asur es of su r prise will b e denoted b y p ppp and RPS ppp and, as b efore, BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 5 computed u sing ( 1.1 ) a nd ( 1 .2 ), resp ectiv ely , with h ( · ) = m ppp ( · ). Extensiv e d iscussions of the adv anta ges and dis- adv an tages of this prop osal as compared w ith th e previous o nes can be found in Ba y arri and Berger ( 2000 ) and Robins, v an der V aart and V entura ( 2000 ). In this pap er we demonstrate th eir p erfor- mance in hierarchica l mo dels. 2.4 Computation of p h ( · ) and RPS h ( · ) Often, f or a p r op osed h ( · ), the m easures p h ( · ) and RPS h ( · ) cannot b e computed in close d form. In fact, h ( · ) is often not of closed form itself. In these cases w e use Mon te Carlo (MC), or Marko v Chain Mon te Carlo (MCMC) metho ds , to (appro ximately) com- pute them. I f x 1 , . . . , x M is a sample of s ize M gen- erated from h ( x ), then t i = t ( x i ) is a sample f rom h ( t ), and we appr o x im ate the MS as: 1. p -v alue P r h ( · ) ( T ≥ t obs ) = # of t i ≥ t obs M , 2. relativ e predictiv e surp rise RPS h ( · ) = ˆ h ( t obs ) sup t ˆ h ( t ) , where ˆ h ( t ) is an estimate (for instance a kernel estimate) of the density h at t . When the distri- bution of the test s tatistic T , f T ( t | θ ) , has closed form expression, one can av oid k ernel estimation b y usin g a “Rao–B lac kw ellized” Mon te C arlo es- timate of h , that is, ˆ h ( t ) = (1 /m ) P m k =1 f T ( t | θ k ), where t he θ k ’s are draws from the appr op r iate distribution for θ (pr op er p rior, p osterior, par- tial p osterior, . . . ). This is the metho d used in the examples of this pap er and was p oint ed to us b y a referee. 3. CHECKING HIERARCHICAL NORMAL MODELS Consider the u sual normal-normal tw o-lev el hier- arc h ical (or rand om effects) mo del with I groups and n i observ ations p er group. The I means are as- sumed to b e exc h angeable. F or sim p licit y , w e b e- gin by assuming the v ariances σ 2 i at th e observ ation lev el to b e known. The m o del is X ij | θ i i ∼ N ( θ i , σ 2 i ) , i = 1 , . . . , I , j = 1 , . . . , n i , (3.1) π ( θ | µ, τ ) = I Y i =1 N ( θ i | µ, τ 2 ) , π ( µ, τ 2 ) = π ( µ ) π ( τ 2 ) ∝ 1 τ . In this pap er we concen trate on c hec king the ade- quacy of th e second-lev el assumptions on the means θ i . O f course, chec king the normalit y of the obser- v ations is also imp ortan t, bu t it w ill n ot b e consid- ered here. The tec h niques consider ed in this pap er as applied to the c hec king of simp le mo d els ha v e b een explored in Bay arri and Castellanos ( 2001 ), Castellanos ( 1999 ) and Ba y arri and Morales ( 2003 ). Assume t hat c hoice of the departure statistic T is d one in a rather casual mann er , and that we are esp ecially concerned ab out the u p p er tail of the dis- tribution of the means. In this situation, a natural c h oice for T is T = max { X 1 · , . . . , X I · } , (3.2) where X i · denotes the usual sample mean for group i . This T is r ather natural, but th e analysis w ould b e virtually iden tical with an y other c hoice. Recall that if the statistic i s f airly ancillary , th en the answers from all metho d s are going to b e rather similar, no matter h o w we in tegrate θ out. The d ensit y of the statistic ( 3.2 ) u n der the (null) mo del s p ecified in ( 3.1 ) can b e computed to b e f T ( t | θ ) = I X k =1 N t | θ k , σ 2 k n k (3.3) · I Y l =1 l 6 = k F t | θ l , σ 2 l n l , where N ( t | a, b ) a nd F ( t | a, b ) denote the densit y and distribution f u nction, resp ectiv ely , of a normal distribution with mean a and v ariance b ev aluated at t . W e next in tegrate the u nknown θ f rom ( 3.3 ) using the tec hniques outlined in Section 2 . 3.1 Empirical Ba y es Distributions It is easy to see that the lik eliho o d for µ and τ 2 is simp ly f ( x | µ, τ 2 ) = I Y i =1 N ¯ x i µ, σ 2 i n i + τ 2 , (3.4) 6 M. J. BA Y ARRI AND M. E. CASTELLANOS from wh ic h ˆ µ and ˆ τ 2 can b e computed. Then ( 2.1 ) is giv en by π EB ( θ ) = π ( θ | ˆ µ, ˆ τ 2 ) = I Y i =1 N ( θ i | ˆ µ, ˆ τ 2 ) , whic h w e use to int egrate θ out f rom ( 3.3 ). The re- sulting m EB prior ( x ) do es not h av e a closed form ex- pression, bu t sim ulations can b e o btained b y sim- ple MC metho d s. F or comparison p urp oses, we will also consider integ rating θ w.r.t. the (inappropri- ate) empirical Ba y es p osterior distribution. The re- sulting m EB p ost ( x ) is also trivial to sim ulate f rom by using a similar MC sc heme. Details are giv en in Ap- p end ix A . 3.2 P osterio r Predictive Distribution This prop osal integrate s θ out from ( 3.3 ) w .r.t. its p osterior d istribution. F or the n oninformativ e prior π ( µ, τ 2 ) ∝ 1 /τ , the joint p osterior is π p ost ( θ , µ, τ 2 | x obs ) ∝ f ( x | θ , µ, τ 2 ) π ( θ | µ, τ 2 ) π ( µ, τ 2 ) (3.5) = 1 τ I Y i =1 N x i · θ i , σ 2 i n i I Y i =1 N ( θ i | µ, τ 2 ) . T o sim ulate from the resulting p osterior predic- tiv e distribution m p ost ( x | x obs ), w e fi rst simulate from π p ost ( θ , µ, τ 2 | x obs ) and for eac h sim ulated θ , w e simulat e x from f ( x | θ ). T o sim ulate f rom the join t p osterior ( 3.5 ) we use an easy Gibbs sampler defined by full conditionals giv en in App endix B . 3.3 P a rtial P osterio r Distribution T o simula te from the partial p osterior pr edictiv e distribution, m ppp , w e pro ceed simila rly to Section 3.2 , except that simulatio ns for the param- eters are generated from the partial p osterior distri- bution: π ppp ( θ , µ, τ 2 | x obs \ t obs ) ∝ π p ost ( θ , µ, τ 2 | x obs ) f ( t obs | θ ) , where π p ost ( θ , µ, τ 2 | x obs ) is giv en in ( 3.5 ). Details are given in App end ix C . 3.4 Examples F or illustration, w e now compute the MS, that is, the p -v alues and the relativ e p redictiv e surprise in- dexes for the d ifferen t p rop osals. W e use a couple of data sets with fiv e group s and eight observ ations in eac h group. In b oth of them the null mo del is not the mo del generating the data; in Example 1 one of the means comes from a differen t normal with a larger mean, wh ereas in Example 2 the means come from a Gamma distrib ution. Recall th at the null mo d el ( 3.1 ) h ad the group means i.i.d. n ormal. Example 1. The group means are 1.56, 0.64, 1.98, 0.01, 6.96, sim ulated from X ij ∼ N ( θ i , 4) , i = 1 , . . . , 5 , j = 1 , . . . , 8 , θ i ∼ N (1 , 1) , j = 1 , . . . , 4 , θ 5 ∼ N (5 , 1) . Example 2. The group means are: 0.75, 0 .77, 5.77, 1.86, 0.75, sim ulated from X ij ∼ N ( θ i , 4) , i = 1 , . . . , 5 , j = 1 , . . . , 8 , θ i ∼ Ga (0 . 6 , 0 . 2) , i = 1 , . . . , 5 . In T able 1 w e sho w all MS for the tw o examples. The partial p osterior measures clearly detect the in- adequate mo dels, with v ery small p -v alues and RPS . On the other hand , none of the other predictiv e dis- tributions w ork w ell for this pu rp ose, n o matter ho w w e choose to lo cate the observed t obs in them (with p -v alues or RPS ). The p r ior empirical Ba ye s are conserv ativ e, with p and RPS an order of magni- tude larger than the ones prod uced by the partial p osterior predictiv e d istribution. Bot h the p osterior empirical B a y es and predictiv e p osterior measures are extr emely conserv ativ e, indicating almost p er- fect agreemen t of the observ ed data with the quite ob viously wrong null models. Besides, it can b e seen that EB p osterior and p osterior predictiv e measures are ve ry similar to eac h other. Th is is n ot a sp ecific feature of these examp les, bu t occurs ve ry often. W e further explore it in a rather simple null mo del in Section 4 . W e next study the b eha vior of the differen t p -v alues, when considered as a function of X , u nder the null and u nder some alternativ es. 3.5 Null Sampling Distribution of the p -V alues In Section 2 , we ha v e review ed four d ifferent w a ys to define (Ba y esian) p -v alues for mo del c hec king. T o compare their p erform an ce, we should add r ess the question of what do w e wan t in a p -v alue. F or f r equen tists, one app ealing pr op erty of p -v alues is that, wh en considered as random v ariables, p ( X ) ha v e U (0 , 1 ) distribu tions u nder the null mo dels. This endorses p -v alues with a v ery desirable pr op- ert y , n amely ha ving the same in terpretation across BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 7 T able 1 p -values and RPS for Exampl es 1 and 2 p EB prior RPS EB prior p EB p ost RPS EB p ost p p ost RPS p ost p ppp RPS ppp Ex. 1 0.13 0.28 0.35 0.93 0.41 0.97 0.01 0.01 Ex. 2 0.12 0.29 0.30 0.88 0.38 0.95 0.01 0.01 problems. S tatistica l m easur es th at lac k a common in terpretation across problems are simp ly not v ery useful. (F or more extensiv e discussion of this p oin t, see Robins, v an der V aart and V en tura ( 2000 ).) In fact, the uniformity of p -v alues has often b een tak en as their “defining” c haracteristic ( Meng ( 1994 ); Rubin ( 199 6 ); De la Horr a and Ro driguez-Bernal ( 1997 ); Thompson ( 1997 ); Robins ( 1999 ); Robins, v an der V aart and V entura ( 2000 )). F or most p r oblems, exact uniformit y u nder the n ull for all θ cannot b e attained for any p -v alue. Thus one m ust weak en the requirement to some extent. A nat- ural weak er requ ir emen t is that a p -v alue b e U (0 , 1) under the n ull in an asymp totic sens e (see Robins, v an der V aart and V entura ( 2000 )). As an aside, it should b e remarke d that uniformity of p -v alues is an essen tial assumption for some anal- yses based on p -v alues, as some p opular algorithms for h an d ling multipliciti es (see Cab r as ( 2004 )). It is not ob vious that Ba y esians sh ould be con- cerned with e stablishing that a p -v alue is un iform under the n u ll for al l θ . F or instance, when the prior is pr op er, the prior pred ictiv e p -v alue is U (0 , 1) u n- der m ( x ), wh ich means it is U (0 , 1) in an av erage sense o v er θ . If the prior distribu tion is c h osen sub - jectiv ely , a Bay esian could we ll argue that this is sufficien t. Indeed Meng ( 1994 ) suggested that un i- formit y un d er m ( x ) is a useful criterion for the ev al- uation of an y prop osed (Ba yesian) p -v alue. If the prior is impr op er, ho w ev er (as it is often the case in ob jectiv e Ba yes mo del c hec king, the sub - ject of t his pap er), then this p r ior predictiv e u n i- formit y criterion cannot b e u sed. Of course, if a p -v alue is un iform u nder the null in the frequen - tist sense, then it has the str ong Bay esian prop erty of b eing marginally U ( 0 , 1) under any prop er prior distribution. This explains why Ba y esians should, at least, b e highly satisfied if the frequen tist r e- quirement obtains. Pe rhaps more to the p oint , if a prop osed p -v alue is always either conserv ativ e or an ticonserv ativ e in a fr equ en tist sen se (see Robins, v an der V aart and V entura ( 20 00 ), for defi- nitions), then it is lik ewise guaran teed to b e conser- v ativ e or anti-c onserv ative in a Ba y esian sens e, no matter w hat the pr ior. In teresting related d iscus- sion concerning the p osterior predictiv e p -v alue can b e foun d in Meng ( 1994 ), Gelman, Meng and Stern ( 2003 ), Ru b in ( 1996 ), Gelman ( 2003 ), Dahl ( 2006 ) and Hjort, Dahl and Stein bakk ( 2006 ). There is a v ast literature on other metho ds of ev aluating p -v alues. F urther discussion and references ca n b e found in Ba yarri and Berger ( 2000 ). Here, we fo cus on studying the d egree to wh ic h the v arious p -v alues d eviate from uniformity in fin ite sample scenarios. F or this purp ose, w e simulate the n ull samplin g distribution of p EB prior ( X ), p p ost ( X ) and p ppp ( X ), w hen X comes from a hierarchica l normal- normal m o del as defined in ( 3.1 ). [W e do not sho w the b eh avior of p EB p ost ( X ) b ecause it is basically iden- tical to that of p p ost ( X ).] In particular, w e ha v e sim ulated 1000 samples from the follo wing mo del: X ij ∼ N ( θ i , 4) , i = 1 , . . . , I , j = 1 , . . . , 8 , θ i ∼ N (0 , 1) , i = 1 , . . . , I . W e ha v e considered thr ee differen t “group sizes”: I = 5, 15 an d 25. (Since here we are c hecking the dis- tribution of the means, th e adequate “asymptotics” is in the n umb er of group s.) W e compu te the different p -v alues for 1000 sim- ulated samples. Figure 1 sho ws the resu lting his- tograms. As we can s ee, p ppp ( X ) h as already a (nearly) uniform distribution ev en for I (n umb er of groups) as small as 5. On the other hand, the dis- tributions of b oth p EB prior ( X ) and p p ost ( X ) are quite far from u niformit y , the distribution of p p ost ( X ) b e- ing the farthest. Moreo v er, the deviation from the U (0 , 1) is in the d ir ection of more conserv atism (giv en little pr obabilit y to small p -v alues, and concentrat - ing around 0 . 5), as it is the case in simpler mo dels. Notice th at conserv atism usually results in lac k of p ow er (and th u s in n ot being able to detec t data coming from w rong mod els). P articularly worrisome 8 M. J. BA Y ARRI AND M. E. CASTELLANOS is the b eha vior of p p ost ( X ) for small num b er of groups. W e hav e also p erformed similar sim ulations for larger I ’s (n umb er of group s) to in vesti gate whether the distribution of these p -v alues appr oac hes uniformit y as I grows. I n Figure 2 w e sho w the histograms for I = 100 and I = 200 of p -v alues p p ost ( X ) and p EB prior ( X ) [w e do n ot show p ppp ( X ) as it is virtually uniform]. The distrib utions of these p -v alues do not seem to change m uc h as I is doubled from I = 100 to I = 200, and they are still quite far from unifor- mit y , still showing a tend ency to concen trate around middle v alues for p . W e do n ot kn o w wh ether these p -v alues are asym p totically U (0 , 1). 3.6 Distribution of p -V alues Under Some Alternatives In this section w e stud y the b eha vior of p EB prior ( X ), p p ost ( X ) and p ppp ( X ), wh en the “n ull” normal-normal mo del is wrong. In particular, w e fo- cus on violations of normalit y at the second lev el. Sp ecifically , we simulate data sets from three dif- feren t mo dels. I n all the three, we tak e the d istribu- tion at the fi rst lev el to b e the same and in agree- men t with th e firs t lev el in the n ull mo del ( 3.1 ): X ij ∼ N ( θ i , σ 2 = 4) , i = 1 , . . . , I , j = 1 , . . . , 8 . W e use three differen t distributions for the group means (rememb er, under the n ull mo del, the θ i ’s w ere normal): 1. Exp on ential distribu tion: θ i ∼ Exp(1) , i = 1 , . . . , I . 2. Gumbel distribu tion: θ i ∼ Gumbel(0 , 2) , i = 1 , . . . , I , wh ere the Gumb el( α , β ) den sit y is f ( x | α, β ) = 1 β exp − x − α β · exp − exp − x − α β , for −∞ < x < ∞ . Gumbel d istribution is also kno wn as Extr eme V alue T yp e I distribution . It is skew, w ith a long tail to the right (left) when deriv ed as the limiting distribu tion of a maxim u m (minim um). 3. Log-Normal distribu tion: θ i ∼ L ogNormal(0 , 1), i = 1 , . . . , I . W e ha ve consider ed I = 5 and I = 10, simulated 1000 samples from eac h mo del and compu ted the differen t p -v alues for eac h sample. In T ab le 2 we sho w P r ( p ≤ α ) for the three p -v alues and some v al- ues of α . p ppp seems to sho w decen t p o wer giv en the T able 2 Pr ( p ≤ α ) for p ppp , p p ost and p EB prior , for differ ent values of I and the thr e e alternative mo dels α 0.02 0.05 0.1 0.2 0.02 0.05 0.1 0.2 Normal-Exp onential I = 5 I = 10 p ppp 0.04 0.08 0.15 0.24 0.12 0.20 0.29 0.42 p p ost 0.00 0.00 0.00 0.00 0.00 0.00 0.01 0.05 p EB prior 0.00 0.00 0.00 0.23 0.00 0.06 0.18 0.37 Normal-Gumbel I = 5 I = 10 p ppp 0.12 0.22 0.32 0.46 0.21 0.31 0.42 0.55 p p ost 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 p EB prior 0.00 0.00 0.00 0.23 0.00 0.07 0.19 0.38 Normal-Lognormal I = 5 I = 10 p ppp 0.16 0.22 0.31 0.41 0.32 0.42 0.50 0.61 p p ost 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.02 p EB prior 0.00 0.00 0.00 0.23 0.01 0.06 0.13 0.23 small sample sizes and num b er of groups (p o we r is lo wer for the exp onen tial alternativ e, and largest for the log-normal); both p EB prior and p p ost sho w co nsider- able lac k of p o we r in comparison. In particular, no- tice the extreme lo w p o w er of p p ost in all instances, pro du cing basically no p -v alues smaller th an 0 . 2. 4. TESTING µ = µ 0 As we ha ve seen in S ection 3 , the sp ecified predic- tiv e distributions f or T (empirical Ba y es, p osterior and partia l p osterior) used to lo cate the observ ed t obs had to b e dealt with b y MC and MCMC meth- o ds. T o gain und erstanding in the b eha vior of the differen t pr op osals to “get r id” of the un kno wn pa- rameters, w e address here a simpler “n ull m o del” whic h results in simp ler expressions and allo ws for easier comparisons. Supp ose th at w e hav e the normal-normal hierar- c h ical mo del ( 3.1 ) (with σ 2 i kno wn) bu t that w e are in terested in testing H 0 : µ = µ 0 . A natural T to consider to inv estigate this H 0 is the grand m ean: T = P I i =1 n i X i · P I i =1 n i , where X i · , i = 1 , . . . , I , are the sample means for the I group s. Th e (null) sampling distribution of T is: T | θ ∼ N ( µ T , V T ) BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 9 Fig. 1. Nul l distribution of p EB prior ( X ) (first c olumn), p p ost ( X ) (se c ond c olumn) and p ppp ( X ) (thir d c olumn) for I = 5 (first r ow), 15 (se c ond r ow) and 25 (thir d r ow). (4.1) with µ T = P I i =1 n i θ i P I i =1 n i , V T = P I i =1 n i σ 2 i ( P I i =1 n i ) 2 . Again w e will integrat e θ out from ( 4.1 ) w ith the previous prop osals and compare the r esulting p re- dictiv e distributions for T , h ( t ), and the corresp ond- ing MS (which w e tak e relativ e to µ 0 ): p = P r h ( · ) ( | t ( X ) − µ 0 | ≥ | t ( x obs ) − µ 0 | ) , (4.2) RPS = h ( t ( x obs )) /h ( µ 0 ) sup t h ( t ) /h ( µ 0 ) . (4.3) 4.1 Empirical Ba y es Distributions In this case the in tegrated lik eliho o d for τ 2 is sim- ply given by ( 3.4 ) w ith µ r ep laced by µ 0 , from whic h ˆ τ 2 the MLE of τ 2 can b e computed. F or this null mo del, it is p ossible to deriv e clo sed form exp res- sions for the prior and p osterior emp irical Ba y es dis- tributions giv en in ( 2.2 ) and ( 2.4 ), resp ectiv ely . 10 M. J. BA Y ARRI AND M. E. CASTELLANOS Fig. 2. Nul l distribution of p EB prior ( X ) and p p ost ( X ) when I = 100 (first r ow) and I = 200 (se c ond r ow). Indeed, the join t empir ical Ba y es prior predictiv e for X = ( X 1 · , . . . , X I · ) is m EB prior ( ¯ x ) = I Y i =1 N ¯ x i · µ 0 , σ 2 i n i + ˆ τ 2 , so that the corresp onding distribution for T , m EB prior ( t ), is normal with m ean and v ariance giv en b y E EB prior = µ 0 , (4.4) V EB prior = 1 ( P I i =1 n i ) 2 I X i =1 n 2 i σ 2 i n i + ˆ τ 2 . The empirical B a y es p osterior pr edictiv e distribu - tion m EB p ost ( ¯ x ) can b e deriv ed in a similar mann er resulting also in a normal m EB p ost ( t ) with mean and v ariance E EB p ost = P I i =1 n i e E i P I i =1 n i , BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 11 (4.5) V EB p ost = 1 ( P I i =1 n i ) 2 I X i =1 n 2 i σ 2 i n i + e V i , where e E i = n i x i · /σ 2 i + µ 0 / ˆ τ 2 n i /σ 2 i + 1 / ˆ τ 2 and e V i = 1 n i /σ 2 i + 1 / ˆ τ 2 . The MS ( 4.2 ) and ( 4.3 ) can also b e computed in closed form. The (prior) empirical Ba yes measur es are p EB prior = 2 · 1 − Φ | t obs − µ 0 | q V EB prior , RPS EB prior = exp − ( t obs − µ 0 ) 2 2 V EB prior , where Φ denotes the standard n ormal d istribution function. The p osterior empirical Ba y es measures can similarly b e derive d in closed f orm, but they are of m uch less interest and w e do not pr o duce them here (see Castellanos ( 2002 )). The in adequacies of m EB p ost for testing the n ull m o del can already b e seen in the ab o v e formulas, b u t th ey are more eviden t in the particular homoscedastic, balanced case: σ 2 i = σ 2 and n i = n ∀ i, i = 1 , . . . , I . In this case the distribution of T simp lifies to T ∼ N P I i =1 θ i I , σ 2 I n . Also, there is a closed f orm expr ession for the MLE of τ 2 : ˆ τ 2 = max 0 , P I i =1 ( x i · − µ 0 ) 2 I − σ 2 n . Then, the m ean and v ariance of m EB prior , as give n in ( 4.4 ), are E EB prior = µ 0 , V EB prior = σ 2 n + ˆ τ 2 I . Similarly , the mean and v ariance of m EB p ost , giv en in ( 4.5 ), r educe to E EB p ost = nt obs /σ 2 + µ 0 / ˆ τ 2 n/σ 2 + 1 / ˆ τ 2 , V EB p ost = 2 nσ 2 ˆ τ 2 + σ 4 nI ( n ˆ τ 2 + σ 2 ) . F or a giv en µ 0 (and fi xed τ ), it is now easy to in v es- tigate the b eha vior of m EB prior and m EB p ost as t obs → ∞ , indicating fl agran t incompatibilit y b et ween the data and H 0 . The comparison in this simp le case is en- ligh tening. First, note that m EB prior cen ters at µ 0 , whic h in p rinciple allo ws for declaring incompatible a ve ry large v alue t obs ; how eve r, the v ariance al so gro w s to ∞ as t obs gro w s, th us al leviating th e incom- patibilit y , and ma yb e “missing” some surprisingly large t obs . Th u s, the b eha vior of m EB prior is reaso n- able, bu t migh t b e conserv ative . On the other hand, the b eha vior of m EB p ost is completely inad equ ate. In - deed, for v ery large t obs , it cen ters precisely at t obs , th us p recluding detecting as unusual any v alue t obs , no matter ho w large! Moreo v er, the v ariance go es to (2 σ 2 ) / ( nI ) , a fin ite constan t. It is imm ediate to see that m EB p ost should n ot b e u sed to c hec k this partic- ular (and admittedly simple) m o del; as a matter of fact, for t obs → ∞ (extremely inadequ ate mo dels) w e exp ect p -v alues of around 0 . 5. W e remark that the previous argumen t do es n ot b elong to any particu- lar MS; rather it reflects the inadequ acy of m EB p ost for mo del c hec king, whatev er MS w e u s e. Note that we exp ect similar inadequ acies to o ccur with the p os- terior p redictiv e d istribution, w h ic h is rather often used in ob jectiv e Bay es mo d el c hec king. 4.2 P osterio r Distribution No ma jor simp lifications o ccur for th is sp ecific H 0 . The p osterior distr ibution is not of closed form (not ev en for the h omoscedastic, balanced case), and hence neither is the p osterior predictiv e distribution. W e can, h o w ev er, easily generate from it w ith vir- tually the same Gibbs sampler used in Section 3.2 : it suffices to (ob viously) ignore the fu ll conditional for µ and r eplace µ with the v alue µ 0 in the other t w o full conditionals ( B.2 ) and ( B.3 ), which w ere standard distr ib utions. 4.3 P a rtial P osterio r Distribution There is no closed form expression for the partial p osterior distribu tion either, but considerable sim- plification occurs since the Metrop olis-within-Gibbs step is n o longer n eeded and a straigh t Gibb s sam- pler suffices. T he full cond itional for τ 2 is as given in ( C.2 ) with µ r eplaced by µ 0 ; the fu ll conditional of eac h θ i is here also normal: π ( θ i | τ 2 , θ − i , x obs \ t obs ) = N ( θ i | E 0 i , V 0 i ) , 12 M. J. BA Y ARRI AND M. E. CASTELLANOS where E 0 i = 1 V 0 i " n i σ 2 i x i · − σ 2 i P j n j σ 2 j · X j n j t obs − X l 6 = i n l θ l !! (4.6) + 1 τ 2 µ 0 # , 1 V 0 i = n i σ 2 i 1 − n i σ 2 i P I j =1 n j σ 2 j + 1 τ 2 . (4.7) Details of the deriv ations app ear in Ap p end ix D . 4.4 Some Examples W e next consider four examples in whic h we ca rry out the testi ng H 0 : µ = 0 . W e consider I = 8 groups, with n = 12 observ ations p er group, and σ 2 = 4 . In one of the examples (Example 1 ) H 0 is tru e and the means θ i are generated from a N (0 , 1). In the r e- maining th ree examples the n ull H 0 is w rong, with θ i ∼ N (1 . 5 , 1) in Example 2 , θ i ∼ N (2 . 5 , 1) in Exam- ple 3 , and θ i ∼ N (2 . 5 , 3) in Example 4 . The simu- lated samp le means are: Example 3. x = ( − 2 . 18 , − 1 . 47 , − 0 . 87 , − 0 . 38 , 0 . 05 , 0 . 29 , 0 . 96 , 2 . 74) . Example 4. x = ( − 0 . 05 , 0 . 66 , 1 . 37 , 1 . 70 , 1 . 72 , 2 . 14 , 2 . 73 , 3 . 68) . Example 5. x = (1 . 53 , 1 . 6 5 , 1 . 71 , 1 . 75 , 1 . 87 , 2 . 16 , 2 . 47 , 3 . 68) . Example 6. x = (0 . 50 , 1 . 5 2 , 1 . 59 , 2 . 73 , 2 . 88 , 3 . 54 , 4 . 21 , 5 . 86) . In Figure 3 w e sho w the predictiv e d istributions for all p rop osals in the f our examples. A quite re- mark able feature is th at in ev ery o ccasion, m EB p ost basically coincides with m p ost , so m uc h that they can hardly b e told apart. W e we re exp ecting them to b e close, but not so close. Also, wh en the null is true (Example 1 ), all distr ibutions righ tly c oncen- trate aroun d the n ull and, as exp ected, the most concen tr ated is m EB p ost (and m p ost ), and th e least is m ppp ( m EB prior ignores th e u ncertain t y in the estima- tion of τ 2 ). When the null mod el is wrong, ho wev er, ev en though b oth m ppp and m EB prior ha v e the righ t lo- cation, m ppp is more concen trated than m EB prior , th us indicating more promise in detecting extreme t obs . Notice the hop eless (and identi cal) beh avior of m EB p ost and m p ost : b oth concent rate around t obs , no matter ho w extreme; that is, there is no hop e that it can detect incompatibilit y of a v ery large t obs with the h yp othetical v alue of 0. In T able 3 we show the differen t MS for the four examples. All b ehav e w ell w hen the null is tru e, bu t only the p pp and the pr ior empirical Ba ye s measures detect the wrong mo dels (ppp more clearly). On th e other hand, m EB p ost and m p ost pro du ce ve ry similar measures and b oth are in capable of d etecting cl early inappropriate n ull mo dels. N otice that the conser- v atism of the p osterior predictiv e measures (and the p osterior emp irical Ba ye s ones) is extreme. 5. A COMP ARISON WITH OTHER BA YESIA N METHODS In this section w e retak e the main goa l of c hec king the adequacy of the second lev el in the h ierarc h ical mo del: X ij | θ i i ∼ N ( θ i , σ 2 ) , i = 1 , . . . , I , j = 1 , . . . , n i , π ( θ | µ, τ ) = I Y i =1 N ( θ i | µ, τ 2 ) , with σ 2 unknown, as w ell as µ, τ 2 . W e first p r o- vide s ome details needed to d eriv e the MS us ed so far when σ 2 is un k n o wn; we then b r iefly review three recent metho ds for Ba y esian c hec king of hierarc hical mo dels, prop osed in Dey , Gelfand, Swartz and Vlac hos ( 1998 ), O’Hagan ( 2003 ) and Marshall and Sp iegelhalte r ( 2003 ). W e do n ot s p ecifically address here (b ecause th e philos- oph y is somewhat d ifferent) the m uc h earlier, lik eli- ho o d/empir ical Ba y es p rop osal of Lange and Ry an ( 1989 ), whic h basically consists in chec king the nor- malit y of some s tand ardized version of estimated T able 3 p -values and RPS for testing µ = 0 i n the four examples Example 1 Example 2 Example 3 Example 4 p RPS p RPS p RPS p RPS ppp 0.86 0.98 0.01 0.01 0.00 0.00 0.00 0.0 1 EB prior 0.83 0.98 0.02 0.06 0.0 1 0.03 0.01 0.05 EB p ost 0.71 1.00 0.31 0.89 0.30 0 .88 0.38 1.00 p ost 0.71 1.00 0.33 0.92 0.3 2 0.95 0.39 1.00 BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 13 Fig. 3. Differ ent pr e dictive distribution for T in e ach example. The vertic al soli d line lo c ates t obs . The curves c orr esp ondi ng to m p ost and m EB p ost wer e almost indistinguishable and for clarity ar e r epr esente d as identic al. residuals. W e apply the four metho d s considered so far and the thr ee new metho d s to a data s et pro- p osed in O’Hagan ( 2003 ). O’Hagan (2003) exampl e. In the general sce- nario of chec king th e normal-normal hierarchical mo del, O’Hagan ( 2003 ) uses the follo win g data set: Group 1 2.73, 0.56, 0.87, 0 .90, 2.27, 0.82. x 1 · = 1.36. Group 2 1.60, 2.17, 1.78, 1.84, 1.83, 0.80. x 2 · = 1.67. Group 3 1.62, 0.19, 4.10, 0.65, 1.98, 0.86. x 3 · = 1.57. Group 4 0.96, 1.92, 0.96, 1.83, 0.94, 1.42. x 4 · = 1.34. Group 5 6.32, 3.66, 4.51, 3.29, 5.61, 3.27. x 5 · = 4.44. Note that x 5 · is considerably far from the other four sample means. 5.1 Metho ds Used So Fa r The empirical Ba yes methods (b oth the prior and the p osterior) ha ve an easy generalizati on to th e un- kno wn σ 2 case. It su ffices to substitute σ 2 b y its usual MLE estimate and app ly the pro cedu r es in Section 3 for σ 2 kno wn. F or b oth the p osterior predictiv e and the partial p osterior predictiv e measures, w e need to sp ecify a new (noninformative ) join t prior. Since w e can u se 14 M. J. BA Y ARRI AND M. E. CASTELLANOS the standard nonin f ormativ e pr ior for σ 2 , w e tak e π ( µ, σ 2 , τ 2 ) ∝ 1 σ 2 1 τ . (5.1) T o s im ulate from the p osterior distribution, we again use Gibbs samp lin g. Th e fu ll conditionals for θ , µ and τ 2 are the same as f or th e kno wn σ 2 and they are giv en in ( B.3 ), ( B.1 ) and ( B.2 ), r esp ectiv ely . The full conditional for the n ew p arameter, σ 2 , is σ 2 | θ , µ, τ 2 , x obs ∼ χ − 2 ( m, e σ 2 ) , where m = P I i =1 n i and e σ 2 = P I i =1 P n i j =1 ( x ij − θ i ) 2 /n . The (joint) partial p osterior distribution is π ppp ( θ , σ 2 , µ, τ 2 | x obs \ t obs ) ∝ π ( θ , σ 2 , µ, τ 2 | x obs ) f ( t obs | θ , σ 2 ) , and again we use the same general pro cedur e as for the σ 2 kno wn scenario (see Sectio n 3). W e only need to sp ecify how to simulate from the full conditional of σ 2 : π ppp ( σ 2 | θ , µ, τ 2 , x obs \ t obs ) ∝ χ − 2 ( m, e σ 2 ) f ( t obs | θ , σ 2 ) . W e us e Metrop olis–Hastings with χ − 2 ( m, e σ 2 ) as pro- p osal distribution. The acceptance probabilit y (at stage k ) of candidate σ 2 ∗ , giv en the simulated v al- ues ( θ ( k ) , σ 2( k ) , µ ( k ) , τ 2( k ) ), is α = min 1 , f ( t obs | θ ( k ) , σ 2( k ) ) f ( t obs | θ ( k ) , σ 2 ∗ ) . W e next derive the d ifferen t MS for O’Hagan data. O’Hagan (2003) examp le (continued). The empirical Bay es, p osterior p r edictiv e and partial p os- terior predictiv e MS ap p lied to this data set, using T = max i { X i } , are shown in T able 4 . W e again observ e the same b eha vior as the one rep eatedly observ ed in p r evious examples: in spite of such an “ob vious” d ata set, only the p artial p os- terior measures detect the incompatibilit y b et we en data and mo del. The emp irical Ba ye s prior measures are too conserv ativ e, and the p osterior pred ictive measures (and their v er y m uc h alik e empirical Ba yes p osterior on es) are completely hop eless. 5.2 Simulation-Based Mo del Checking This metho d is p rop osed in Dey , Gelfand, Swartz and Vlac hos ( 199 8 ), as a com- putationally in tense metho d for m o del c hec king. This metho d w orks not on ly with chec king statis- tics T , but more generally , with discrepancy mea- sures d , that is, w ith functions of the parameters and the data. This feature also app lies to the p os- terior predictiv e c hec ks that we h a v e been consid- ering all along. In essence, th e metho d c onsists in comparing the p osterior distribution d | x obs with R p osterior distr ib utions of d giv en R data sets x r , for r = 1 , . . . , R , generated from the (n ull) prior pr e dic- tive mo del. Note that this metho d r e quir es prop er priors. Comparison is carried out via Monte Carlo T ests ( Besag and Clifford ( 1989 )). Letting x r , for r = 0, denote the observ ed data x obs , their algorithm is as follo ws: • F or eac h p osterior distribution of d giv en x r , r = 0 , . . . , R , compu te t he v ector of quan tiles q ( r ) = ( q ( r ) 0 . 05 , q ( r ) 0 . 25 , q ( r ) 0 . 5 , q ( r ) 0 . 75 , q ( r ) 0 . 95 ), wh ere q ( r ) α is th e α - quantile of th e posterior distribu tion give n d ata x r , r = 0 , . . . , R . • Compute the v ector q of a ve rages, o ver r , of these quan tiles: q = ( q 0 . 05 , q 0 . 25 , q 0 . 5 , q 0 . 75 , q 0 . 95 ). • Compute th e r + 1 E uclidean distances b etw een q ( r ) , r = 0 , 1 , . . . , R and q . • P erform a 0.05 one-sided, upp er tail Monte Carlo test, that is, c hec k wh ether or not the distance corresp ondin g to the original data is smaller than the 95th p ercentile of th e r + 1 distances. In rea lit y , this metho d is not a comp etitor of the ones we hav e b een co nsider in g pr eviously , since it r e quir es p rop er priors, and h ence is not a v ailable for ob jectiv e m o del chec king. W e, how eve r, apply it also to O’Hagan data. O’Hagan ( 2003) example (c ontinued). In order to p erform the simulation-b ase d mo del che c k - ing , w e need p rop er priors. W e u se the ones pr op osed in O’Hagan ( 2003 ): µ ∼ N (2 , 10) , σ 2 ∼ 22 W , τ 2 ∼ 6 W (5.2) where W ∼ χ − 2 20 . Along w ith the statistic used so f ar, w e ha ve also considered a measure of discrepancy w hic h in this case is jus t a fu nction of the p arameters: T 1 = max X i · , T 2 = max | θ i − µ | . With 1000 sim ulated data sets from the null, the results are sho wn in T able 5 . It can b e seen that, with th e giv en prior, incompatibilit y is detected with T 2 , but not with T 1 . W e do n ot k n o w whether T 2 w ould detect incompatibilit y with other priors (see related r esu lts in Section 5.3). BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 15 T able 4 M S ( σ 2 unknown) for O ’ Hagan data set p EB prior RPS EB prior p EB p ost RPS EB p ost p p ost RPS p ost p ppp RPS ppp 0.19 0.4 0.37 0.95 0.40 0.99 0.01 0 .02 5.3 O’Hagan Metho d O’Hagan ( 200 3 ) prop oses a general metho d to in- v estigate adequacy of graphical mo dels at eac h no de. W e will not d escrib e his metho d in full generalit y , but only ho w it applies to c hec king the second lev el of our normal-normal hierarc hical mo d el. T o inv estigate conflict b et w een the data and the normal assum ption for ea c h of the group means, this prop osal inv estigates conflict b et we en th e lik eliho o d for θ i , Q n i j =1 f ( x ij | θ i , σ 2 ) , and the (null) densit y for θ i , π ( θ i | µ, τ 2 ) . T o c hec k conflict b et ween tw o kn o wn u niv ariate densities/lik eliho o ds, O’Hagan prop oses a “measure of conflict” based on their r elativ e heigh ts at an “in termed iate” v alue. Sp ecifically , the lik eli- ho o ds/d en sities are firs t normalized so that th eir maxim um h eigh t is 1 (notice th at this is equiv a- len t to dividin g b y their resp ectiv e maximum, as in RPS b efore). Th en the (common) d ensit y height , z , at the v alue of θ i b et wee n the t w o mo des where the tw o d ensities are equal, is computed. The p ro- p osed measure of conflict is c = − 2 ln z . F or the p ar- ticular case of comparing tw o normal distribu tions, N ( ω i , γ 2 i ), for i = 1 , 2, this measure is c = ω 1 − ω 2 √ γ 1 + √ γ 2 2 . (5.3) O’Hagan indicates th at a conflict measure s maller than 1 sh ould b e tak en as indicativ e of no conflict, whereas v alues of 4 or larger wo uld indicate clear conflict. No ind ication is give n for v alues lying b e- t w een 1 an d 4. When, as u sual, the distributions in vol ve d dep end on unknown parameters, the measures of conflict [in T able 5 Euclide an distanc e b etwe en q (0) and q and the 0.95 quantile of al l distanc es k q (0) − q k 0.95 quan tile T 1 2.31 13.46 T 2 1.82 0.81 T able 6 Posterior me dians of c i , i = 1 , . . . , 5 , for O ’ Hagan data set θ 1 θ 2 θ 3 θ 4 θ 5 O’Hagan priors 0.43 0.14 0.22 0.46 4.81 Noninformative priors 0.16 0.09 0.11 0.16 1.36 particular ( 5.3 )], cannot b e compu ted. O’Hagan’s prop osal is then to u se the median of their p osterior distribution. Notice that this is closely related to computing a relativ e height on the p osterior pr edic- tiv e d istribution and, hence, the concern exists that it can be t o o co nserv ativ e for u s eful mo d el c hec k- ing. In fact this conserv atism w as h ighligh ted in the discussions by Ba yarri ( 2003 ) and Gelfand ( 2003 ). In terestingly enough, O’Hagan defends use of pr o- p er priors for the u nknown parameters, so n either p osterior pr edictiv e nor p osterior distributions a re needed f or implemen tation of his p rop osal (sin ce the prior predictive s and priors are pr op er). Alterna- tiv ely , if one wishes to insist on using p osterior dis- tributions (instea d of the, more natur al, prior distri- butions), then pr op er p riors are no longer n eeded, and the metho d can th us b e ge neralized. Accord- ingly , we also apply h is pr op osal with the noninfor- mativ e prior ( 5.1 ). O’Hagan ( 2003) exampl e (continued). W e compute the measure ( 5.3 ) for the data set prop osed b y O’Hagan ( 2003 ). T o derive the p osterior distri- butions, we use b oth th e prop er priors prop osed by O’Hagan for this example, giv en in ( 5.2 ), an d the noninformativ e prior ( 5.1 ). The posterior medians for c are sho wn in T able 6 . It can b e seen that the results are v ery dep endent on the p rior used: the spurious group 5 is detected with the sp ecific prop er prior u sed, bu t not with the n oninformativ e pr iors (th us suffering from th e expected conserv atism). W e recall that data we re clearly indicating an anoma- lous group 5. 5.4 “Conflict” p -Value Marshall and Sp iegelhalter ( 2003 ) prop osed th is approac h b ased on, and generaliz ing, cross-v alidation 16 M. J. BA Y ARRI AND M. E. CASTELLANOS metho ds (see Gelfand, Dey and Chang ( 1992 ); Bernardo and Smith ( 1994 ), Chapter 6). In cr oss-v alidation, to c hec k adequ acy of group i , data in group i , X i , are us ed to compute the “sur- prise” statistic (or diagnostic measure), whereas the rest of th e data, X − i , are used to train the improp er prior. A mixe d p -v alue is accordingly computed as p i,mix = P r m cr oss ( · | X − i ) ( T i ≥ T obs i ) , (5.4) where the completely sp ecified distribution u sed to compute the i th p -v alue is m cr oss ( t i | X − i ) = Z f ( t i | θ i , σ 2 ) π ( θ i | µ, τ 2 ) π ( µ, τ 2 , σ 2 | X − i ) d θ , and thus there is no doub le use of the data. Marshall and Sp iegelhalter ( 2003 ) aim to preserve the cross-v alidation spirit wh ile a vo iding choic e of a particular statistic or discrepancy measure T i = T ( X i ). Sp ecifically , they prop ose use of c onflict p -v alues for eac h group i , compu ted as follo w s: • Simulat e θ r ep i from th e p osterior θ i | X − i . • Simulat e θ fix i from th e p osterior θ i | X i . • Compute θ diff i = θ r ep i − θ fix i . • Compute the “conflict” p -v alue for group i, i = 1 , . . . , I , as p i,con = P r ( θ diff i ≤ 0 | x ) . (5.5) Marshall and Sp iegelhalter ( 2003 ) show that for lo cation parameters θ i , the confl ict p -v alue ( 5.5 ) is equal to the cross-v alidation p -v alue ( 5.4 ) based on statistics ˆ θ i with symmetric likel iho o ds and using uniform p riors in the deriv ation of θ fix i . A clear disadv ant age of this approac h (as we ll as with the cross-v alidation mixed p -v alues) is that we ha v e as ma ny p -v alues as group s, and multiplic it y migh t b e an issue. (O’Hagan’s measur es might suf- fer fr om it to o.) Since w e are dealing w ith p -v alues, adjustment is most lik ely d one b y classica l m etho ds [con tr olling either the family-wise error rate, as the Bonferroni metho d, or the false disco v ery rate and related metho ds, as the Benjamini and Ho ch b erg ( 1995 ) metho d]. None of these metho d s is fo olpro of and the danger exists that they also result in a lac k of p o wer. O’Hagan ( 2003) exampl e (continued). W e compute the c onflict p -v alues for the O’Hagan data set. W e again use b oth, O’Hag an priors and non- informativ e p riors. The resu lts are shown in T able 7 . T aken at face v alue, these p -v alues b eha v e nicely and d etect the outlying group. T able 7 Conflict p -values for the O ’ Hagan data set using noninformative priors and O ’ Hagan pri ors Group 1 Group 2 G roup 3 Group 4 Group 5 O’Hagan priors 0.84 0.74 0.73 0. 88 0.00 Noninformative 0.66 0.59 0.6 1 0.68 0.00 6. A BINOMIAL-BET A EXAMP LE: BRIS T OL RO Y AL INFIR MARY INQUIRY DA T A W e finish the pap er with a real example and a differen t hierarc hical mo del. Sp ecifically , w e exem- plify the different c h ec k in g pro cedu r es in a hierar- c h ical Binomial-B eta m o del on a d ata set analyzed at length in Spiegelhalter et al. ( 2002 ). Data consist in the n umber n i of op en-heart op erations and the corresp ondin g num b er Y i of deaths for c hildren u n- der o ne y ear of ag e carried out in 12 hospitals in England. Data are sho wn in Figure 4 . W e consider the follo win g mo del: Y i | θ i i ∼ Bin( θ i , n i ) , i = 1 , . . . , I , π ( θ | α, β ) = I Y i =1 Beta( θ i | α, β ) , π ( α, β ) ∝ [( ψ 1 ( α ) − ψ 1 ( α + β )) (6.1) · ( ψ 1 ( β ) − ψ 1 ( α + β )) − ψ 1 ( α + β ) 2 ] 1 / 2 , where π ( α, β ) is the Jeffreys prior ( Y ang and Berger ( 1997 )), and ψ 1 ( x ) = P ∞ i =1 ( x + i ) − 2 denotes the tri- gamma function. W e use b oth the maxim um and the minimum of the fr equencies of d eaths, y i /n i , as c hec king statistics. Also, when simulati ng fr om the partial distr ibutions w e ha v e used the n ormal appro ximation to the bin omial, y i /n i ≈ N ( θ i , θ i (1 − θ i ) /n i ), so that the conditional d istribution of th e maxim um and the minim um has an easy closed form expression. W e compu te the o ve rall p artial and p osterior p re- dictiv e p -v alues, and also the individual (one for T able 8 p -values for the mortality in p e diatric c ar diac sur gery p EB prior p EB p ost p p ost p ppp Maxim um 0.03 0.16 0.23 0 .00 Minim um 0.67 0.56 0.62 0 .64 BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 17 eac h hospital) O’Hagan’s conflict measur es and Mar- shall and Sp iegelhalter’s conflict p -v alues. All r e- quire MCMC. W e use 30,000 simulations after a w arm-up p erio d of 10,000 . Algorithms in R are a v ail- able in h ttp://ba y es.escet.urjc.es/˜mec astellanos/ F unctionsBristol.zip . The o v erall p -v alues (EB prior, EB p osterior, p os- terior an d partial p osterior) app ear in T able 8 . Also, in Figures 5 and 6 we sh o w the corresp onding p re- dictiv e distribu tions for, resp ectiv ely , the maxim u m and the minim u m. Both the figures and the table sho w that the observ ed m in im um is wel l supp orted b y the assumed mo dels with an y of the p -v alues used. Ho wev er, w ith the maxim um, the EB prior an d partial p osterior sho w incompatibilit y (with the ppp sho wing more in compatibilit y th an the EB prior), while the EB p osterior and p osterior p -v alues fail to do so. The m u ltiple conflict mea sur es are in T able 9 , and the multiple conflict p -v alues in T able 10 . I n these tables, “1” r efers to the hospital with the lo w est mortalit y rate, and “10” to the one with the largest. According to O’Hagan’s pr escriptions, no hospitals sho w clear in dication of incompatibilit y; all but Bris- tol are compatible. On th e other hand, the multiple T able 9 Posterior me dians of c i , i = 1 , . . . , 12 , for Bristol data set 1 2 3 4 5 6 7 8 9 10 11 12 0.51 0.09 0.07 0.06 0.06 0.05 0.05 0.05 0.10 0.19 0.64 3.11 Hospitals are ordered from low est to largest mortality rate. conflict p -v alues isolates Bristol as th e only one in- compatible. No correction for m ultiplicit y h as b een used. 7. CONCLUSIONS In this pap er we hav e inv estigated the c hec king of hierarc h ical mo dels from an ob jectiv e Bay esian p oint of view (i.e., introdu cing only the information in the d ata and mo del). W e hav e explored several T able 10 Conflict p -values for e ach hospital 1 2 3 4 5 6 7 8 9 10 11 12 0.89 0.72 0.70 0.71 0.70 0.66 0.46 0.47 0.42 0.35 0.17 0.00 Hospitals are ordered from low est to largest mortality rate. Fig. 4. Numb er of op en-he art op er ations and de aths for chil dr en under one ye ar of age c arrie d out in 12 hosp itals in England b etwe en 1991 and 1995. 18 M. J. BA Y ARRI AND M. E. CASTELLANOS w a ys of eliminating th e unk n o wn parameters to de- riv e “reference” d istributions. W e h a v e also explored differen t w a ys of charact erizing “incompatibilit y .” W e prop ose use of the p artial p osterior pr e dictive me asur es ( M S ppp ), whic h we compare with man y other pr op osals. Some of our fi ndings are: • M S ppp b ehav e consider ab ly b etter than the al- ternativ e M S EB prior , M S EB p ost and M S p ost . Th e b e- ha vior of M S p ost can b e p articularly bad with ca- sually c hosen T ’s, failing to reject clearly wr on g mo dels (but notice that the sp ecific T we use is the one pr op osed in Gelman, Carlin, S tern and Rubin ( 2003 ), Section 6.8). As a matter of fact, the mea- sures M S p ost are ve ry similar to th e clearly inap- propriate M S EB p ost . • In our (limited) sim ulation study , the null sam- pling distribution of p ppp is f ou n d to b e appro xi- mately uniform, while those of p EB prior and p p ost are far from uniformit y . Also, p ppp is the most p o w er- ful f or the considered alternativ es. • The s imulation-based mo del chec king seems to w ork w ell in detecting the incompatibilit y b et ween the mo del and the d ata, bu t it requires p rop er pr i- ors. • The O’Hagan metho d is highly sensitiv e to the prior c hosen, and in fact it seems to b e conserv a- tiv e with non in formativ e priors. • The confl ict p -v alues p i,con seem to wo rk w ell, but they p r o duce as man y p -v alues as n umb er of groups and m ultiplicit y m igh t b e an issue. Also, the resulting p -v alues w ill t ypically b e highly de- p end ent (any tw o p -v alues are based in th e same data except for t wo observ ations). P artial p osterior p -v alues are not as easy to compute as p osterior p -v alues, bu t they are still relativ ely easy , and indeed nothing more sophisticated than R wa s needed for the computations in this pap er. This, along with their go o d prop erties (as demon- strated along the pap er), mak es th em th e clearly recommended pro cedu re for ob jectiv e m o del c hec k- ing when the testing statistic T is not (nearly) an- cillary . But if computation is p erceiv ed as an o ve r- whelming reason in fa v or of posterior p -v alues, w e recommend instead use of the E B-prior p -v alues: they h a v e b etter pr op erties an d are easier to com- pute. APPENDIX A: MC C OMP UT A TIONS FOR SECTION 3.1 T o sim ulate fr om the empirical Ba y es prior p re- dictiv e d istribution m EB prior ( x ) simply pro ceed as fol- lo w s : F or l = 1 , . . . , M sim u late θ ( l ) = ( θ 1( l ) , . . . , θ I ( l ) ) ∼ π EB ( θ ) = I Y i =1 π ( θ i | ˆ µ, ˆ τ 2 ) , and f or eac h θ ( l ) , l = 1 , . . . , M , simulate ¯ x ( l ) = ( x 1 · ( l ) , . . . , x I · ( l ) ) ∼ f ( ¯ x | θ ( l ) ) = I Y i =1 f ( x i · | θ i ( l ) ) . Sim ulations for the empirical Ba ye s p osterior pr e- dictiv e m EB p ost ( x ) pro ceed al ong the same lines except that θ is now simulat ed from θ ( l ) = ( θ 1( l ) , . . . , θ I ( l ) ) ∼ π EB ( θ | x obs ) = I Y i =1 N ( b E i , b V i ) , where b E i = n i x i · /σ 2 i + ˆ µ/ ˆ τ 2 n i /σ 2 i + 1 / ˆ τ 2 and b V i = 1 n i /σ 2 i + 1 / ˆ τ 2 . APPENDIX B: FULL CONDITIONAL F OR THE G IB BS S AMPLER IN S ECTION 3. 2 T o simulate from the join t p osterior ( 3.5 ) w e u se an easy Gibbs sampler defined by the full condition- als µ | θ , τ 2 , x obs ∼ N ( E µ , V µ ) (B.1) with E µ = P I i =1 θ i I and V µ = τ 2 I , τ 2 | θ , µ, x obs ∼ χ − 2 ( I − 1 , e τ 2 ) (B.2) where e τ 2 = P I i =1 ( θ i − µ ) 2 I − 1 , θ i | µ, τ 2 , x obs ∼ N ( E i , V i ) , where (B.3) E i = n i x i · /σ 2 i + µ/τ 2 n i /σ 2 i + 1 /τ 2 and V i = 1 n i /σ 2 i + 1 /τ 2 . All th e full conditionals are standard distributions, trivial to sim ulate from. χ − 2 ( ν, a ) r efers to a sc ale d in v erse c hi-square distribu tion: it is the distribu tion of ( ν a ) / Y where Y ∼ χ 2 ( ν ). BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 19 Fig. 5. Pr e dictive distribution f or T = max { y i /n i } in the Bristol R oyal Infirmary data. APPENDIX C: DET AILS FOR MCMC COMPUT A TIONS IN SECTION 3.3 The f u ll conditionals for the Gibb s samp ler are µ | θ , τ 2 , x obs \ t obs ∝ π ( µ | θ , τ 2 , x obs ) f ( t obs | θ ) (C.1) ∝ π ( µ | θ , τ 2 , x obs ) , τ 2 | θ , µ, x obs \ t obs ∝ π ( τ 2 | θ , µ, x obs ) f ( t obs | θ ) (C.2) ∝ π ( τ 2 | θ , µ, x obs ) , θ | µ, τ 2 , x obs \ t obs ∝ π ( θ | µ, τ 2 , x obs ) f ( t obs | θ ) . (C.3) The fu ll conditionals ( C.1 ) and ( C.2 ) are ident i- cal to ( B.1 ) an d ( B.2 ), resp ectiv ely , and hence th ey are easy to sim u late f rom. Equation ( C.3 ) is not of closed form, and w e use Met rop olis–Hastings within Gibbs for the full conditional of eac h θ i : π ppp ( θ i | µ, τ , θ − i , x obs \ t obs ) 20 M. J. BA Y ARRI AND M. E. CASTELLANOS Fig. 6. Pr e dictive distribution for T = min { y i /n i } in the Bristol R oyal Infirmary data. ∝ π p ost ( θ i | µ, τ 2 , x obs ) f ( t obs | θ ) (C.4) ∝ N ( θ i | E i , V i ) f ( t obs | θ ) , where E i , V i are giv en in ( B.3 ). Next w e need to find a g o o d prop osal t o sim u late from ( C.4 ). An ob vi- ous prop osal w ould simp ly b e the p osterior π p ost ( θ i | µ, τ 2 , x obs ), but this can b e a v er y bad prop osal when the data are indeed “sur prising” for the en- tertained mo del. In particular, th e p osterior distri- bution cent ers around the MLE b θ while the par- tial p osterior cen ters around the c onditional MLE, b θ cMLE , that is, b θ cMLE = arg m ax f ( x obs | t obs , θ ) = arg m ax f ( x obs | θ ) f ( t obs | θ ) . It is in tuitiv ely ob vious that, w hen th e data are not “surpr ising,” that is, when t obs comes from the “n ull” mo d el, then f ( x obs | t obs , θ ) w ould b e similar BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 21 to f ( x obs | θ ) and the partial an d p osterior distribu- tions w ould also b e similar. Ho w ev er, when the data are “ sur p rising” and t obs is n ot a “typica l” v alue, then the “n ull” mo del and the conditional mo del can b e considerably differen t, as well as the corresp ond - ing MLEs. F or Metrop olis prop osals, Ba yarri and Berger ( 2000 ) then suggest generating from the p osterior distribu tion but then “mo ving” the generated v alues closer to the mo d e of the target distribution (the partial p osterior) by adding b θ cMLE ,i − b θ MLE ,i , m ultiplied (when this results in improv ed mixing) by a Uniform(0,1) r andom generation. Th is and other algorithms for computing conditional distr ib utions are pr esen ted in Ba yarri, C astellanos and Morales ( 2006 ). T o a v oid computation of b θ cMLE , which can b e rather time consu ming, w e use instead an estimate e θ c whic h w e exp ect to b e close enough (for our purp oses) to b θ cMLE for this mo del and this T (see Ba yarri and Morales ( 2003 )). In p articular, we tak e all comp onen ts to b e equal and given by e θ c = P I − 1 l =1 X ( l · ) I − 1 , where ( X (1 · ) , . . . , X ( I · ) ) denote the group means sorted in ascendent order. That is, we s im p ly remo ve the largest sample mean and then a v erage (we co uld ha v e also used a w eighte d a ve rage if the samp le size s w ere v ery d ifferen t). Then, the r esulting algorithm to simulate from ( C.4 ) at stage k , giv en the (sim ulated) v alues ( θ k − i , θ k i , µ k , τ 2( k ) ), is: 1. Simulat e θ ∗ i ∼ N ( θ i | E i , V i ). 2. Mo ve th e sim ulation θ ∗ i to e θ ∗ i = θ ∗ i + U · ( e θ c − e θ MLE ,i ) , where U is random n umb er in (0,1). 3. Accept candidate e θ ∗ i with p robabilit y α = min 1 , N ( e θ ∗ i | E i , V i ) N ( θ k i | E i , V i ) f ( t obs | θ k − i , e θ k i ) N ( e θ k i | E i , V i ) N ( θ ∗ i | E i , V i ) f ( t obs | θ k − i , e θ ∗ i ) . APPENDIX D: DERIV A TION OF THE FULL CONDITIONAL OF θ ’S IN SECT ION 4.3 The fu ll conditional partial p osterior density for θ i is π ( θ i | τ 2 , θ 1 , . . . , θ i − 1 , θ i +1 , . . . , θ I , x obs \ t obs ) ∝ π p ost ( θ i | τ 2 , θ 1 , . . . , θ i − 1 , θ i +1 , . . . , θ I , x obs ) f ( t obs | θ 1 , . . . , θ i , . . . , θ I ) ∝ exp − 1 2 n i σ 2 i + 1 τ 2 θ i − n i x i · /σ 2 i + µ 0 /τ 2 n i /σ 2 i + 1 /τ 2 2 · exp 1 2 ( P j n j ) 2 P j n j σ 2 j t obs − P I j =1 n j θ j P j n j 2 ∝ exp − 1 2 θ 2 i n i σ 2 i + 1 τ 2 − 2 θ i n i σ 2 i x i · + 1 τ 2 µ 0 · exp ( 1 2 P j n j σ 2 j X j n j t obs − n i θ i − X l 6 = i n l θ l ! 2 ) ∝ exp ( − 1 2 θ 2 i n i σ 2 i + 1 τ 2 − n 2 i P j n j σ 2 j − 2 θ i n i σ 2 i x i · + µ 0 τ 2 − n i P j n j σ 2 j · X j n j t obs − X l 6 = i n l θ l !!) , whic h, after some algebra, redu ces to π ( θ i | τ 2 , θ 1 , . . . , θ i − 1 , θ i +1 , . . . , θ I , x obs \ t obs ) ∝ exp − 1 2 V 0 i ( θ i − E 0 i ) 2 , with E 0 i and V 0 i giv en in ( 4.6 ) and ( 4.7 ), r esp ec- tiv ely . The result then follo ws if V 0 i can b e shown to b e greater than 0, which is true b ecause 1 − n i σ 2 i P I j =1 n j σ 2 j > 0. A CKNO WLEDGMENTS This w ork wa s su pp orted b y the S panish Ministry of Science and T ec hnology Gran ts MTM2004-0 3290 and T SI2004-06 801-C04-01 . REFERENCES Ba y arri , M. J. (2003). Wh ic h “base” distribut ion for m o del criticism? Discussion on HSSS mod el criticism by A. O’Hagan. In Hi ghly Structur e d Sto chastic Systems (P . J. Green, N. L. Hjort and S. T. R ic hardson, ed s.) 445–448. Oxford Univ. Press. MR2082403 22 M. J. BA Y ARRI AND M. E. CASTELLANOS Ba y arri , M. J. and Berger, J. O. (1997). Measures of sur- prise in Bay esian analysis. ISDS D iscussion P ap er 97-46, Duke Un iv. Ba y arri , M. J. and Ber ger, J. O. (1999). Quantifying sur- prise in the data and mod el verificatio n. In Bayesian Statis- tics 6 (J. M. Bernardo, J. O. Berge r, A. P . Da wid and A. F. M. Smith, eds.) 53–82. Oxford Univ. Press. MR1723493 Ba y arri , M. J. and B erger, J. O. (2000). p -v alues for com- p osite n ull mod els (with discussion). J. Amer. Statist. As- so c. 95 1127–1142, 1157–1 170. MR1804239 Ba y arri , M. J. and Castellanos, M. E. (2001). A com- parison b etw een p -v alues for go o dness-of-fit chec king. In Mono gr aphs of Official Statistics. Bayesian Metho ds wi th Applic ations to Scienc e , Policy and Offi cial Statistics (E. I. George, ed.) 1–10. Eurostat. Ba y arri , M. J. and Morales, J. (2003). Ba yesian measures of surprise for outlier detection. J. Statist. Plann. Infer enc e 111 3–22. MR1955869 Ba y arri , M. J. , Castellanos, M. E. and Morales, J. (2006). MCMC meth od s to approximate conditional p re- dictive distributions. Comput. Statist. Data A nal. 51 621– 640. MR2297533 Benjami ni, Y. and Hochberg, Y. (1995). Con trolling the false disco very rate: A p ractical and p ow erful approach. J. R. Stat. So c. Ser. B Stat. Metho dol. 57 289–300. MR1325392 Berger, J. O. (1985). Statistic al De cision The ory and Bayesian Analysis , 2nd ed. Springer, New Y ork. MR0804611 Berger, J. O. (2003). Could Fisher, Jeffreys and Neyman hav e agreed up on testing? Statist. Sci. 18 1–32. MR1997064 Berger, J. O. (2006). The case for ob jective Ba yesian anal- ysis. Bayesian A nal. 1 385–402. MR2221271 Bernardo, J. M. and Smith, A. F. M. (1994). Bayesian The ory . Wiley , Chichester. MR1274699 Besag, J. an d Clifford, P. (1989). Generalized Monte Carlo significance tests. Biometrika 76 633–64 2. MR1041408 Box, G. E. P. (1980 ). S ampling and Ba yes inference in sci- entific mo delling and robustness. J. R oy. Statist. So c. Ser. A 143 383–430. MR0603745 Cabras, S . (2004). Multiple hyp othesis testing for composite null mod els. T echnical rep ort, Dept. Mathematics, Univ. Cagliari . Carlin, B. P. and Louis, T. A. ( 2000). Bayes and Empiric al Bayes Metho ds for Data Analysis , 2nd ed. Chapman and Hall, London. MR1427749 Castellanos, M. E. (1999). Medidas d e sorpres a para b on- dad de a juste. Master thesis, Dept. Estad ´ ıstica i I .O., Univ . V al ` encia. Castellanos, M. E. (2002). Diagn´ ostico s Bay esianos d e mod elos, PhD. dissertation. Dept . Estad ´ ıstica y Mat. Ap li- cada, Univ. Miguel Hern´ andez. Dahl, F. A. (2006). On t he conserv ativeness of p osterior predictive p -v alues. Statist. Pr ob ab. L ett. 76 1170–1 174. MR2269289 De la Horra, J. and Rodriguez-Bernal, M. T. (1997). Asymptotic b ehaviour of the p osterior predictive p -v alue. Comm. Statist. The ory Metho ds 26 2689–2699. MR1605584 Dey, D. K. , Ge lf and, A. E. , S w ar tz, T. B. an d V lachos, A. K. (1998). A simulation-in tensive approach for chec k ing hierarc hical mo dels. T est 7 325– 346. Draper, D. (1996). Utility , sensitivity analysis, and cross- v alidation in Ba yesia n mo del selection. Discussion of Pos- terior predictive assessmen t of model fitn ess via realized discrepancies. Statist. Sinic a 6 760–767. Draper, D. and Krnjaj i ´ c, M. (2006). Ba yesian model sp ec- ification. T echnical rep ort, UC Santa Cruz. Av ailable at http://www .ams.ucsc.edu/ ~ draper/wri tings.html Gelf and, A. E. (2003). Some commen ts on mod el criti- cism, discussion on HSSS mo del criti cism. In Highly Struc - tur e d Sto chastic Sy stems (P . J. Green, N. L. H jort and S. T. Richardson, eds.), 449–454. Oxford Un iv. Press. MR2082403 Gelf and, A. E. , Dey, D. K. and Chang, H. (1992). Model determination using predictive distributions with implementa tion via sampling-based meth od s. In Bayesian Statistics 4 (J. M. Bernardo, J. O. Berger, A. P . Dawid and A. F. M. Smith, eds.) 147–167. Ox ford Un iv. Press. MR1380275 Gelman, A. ( 2003). A Bay esian formulation of exploratory data analysis and go o d ness-of-fit testing. Internat. Statist. R ev. 71 369 –382. Gelman, A. , Ca rlin, J. B. , Ste rn , H. S. and Rubin, D. B. (2003). Bayes ian Data Analysis , 2nd ed. Chapman and Hall/CR C, London. MR1385925 Gelman, A. , Meng, X. L. and Stern, H. S . (1996). Pos- terior predictive assessmen t of model fitn ess via realized discrepancies (with discussion). Statist. Sinic a 6 733–760. MR1422404 Guttman, I. (1967). The use of the concept of a futu re ob- serv ation in goo dness-of-fit p roblems. J. R. Stat . So c. Ser. B Stat. Metho dol. 29 83–100 . MR0216699 Hjor t, N. L. , D ahl, F. A. and Steinbakk, G. H. (2006). P ost-pro cessing posterior predictive p -val ues. J. A mer. Statist. Asso c. 101 11 57–1174. MR232415 4 Lange, N. and R y an, L. (1989). Assessing normal ity in ran- dom effects mo dels. Ann. Sta tist. 17 624–6 42. MR0994255 Marshall, E. C. and Spie gelhal ter, D. J. (2003). A p- proximate cross-v alidatory predictive c hecks in disease mapping models. Stat. Me d. 22 1649–166 0. Meng, X . L. (1994). Pos terior predictive p -v alues. Ann. Statist. 22 1142–1160 . MR1311969 O’Hagan, A. ( 2003). HSSS mod el criticism ( with discussion). In Highly Structur e d Sto chastic Systems (P . J. Green, N. L. Hjort and S. T. Richardson, eds.) 423–445. Oxford Univ. Press. MR2082403 Ro bins, J. M. (1999). Discussion of q uantifying surprise in the data and mo del verification. In Bayesian Statistics 6 (J. M. Bernardo, J. O. Berger, A . P . D a wid and A. F. M. Smith, eds.) 67–70. Ox ford Un iv . Press. MR1723490 Ro bins, J. M. , v a n der V aar t, A. and Ventura, V. (2000). Asymptotic distribution of p val ues in comp osite null mo d- els ( with discussion). J. A m er. Sta tist. Asso c. 95 1143– 1167, 1171–11 72. MR1804240 Rubin, D. B. (1984). Bay esian justifiable and relev ant fre- quency calculations for the applied statistician. Ann. Statist. 12 1151–1172 . MR0760681 BA Y ESIAN CHECKING OF THE SECOND LEV ELS OF HIERA RCHICAL MODELS 23 Rubin, D. B. (1996). Discussion of p osterior predictive as- sessmen t of mo del fitness v ia realized d iscrepancies. Statist. Sinic a 6 787–792. MR142240 4 Spiegelha l ter, D. J. , A ylin, P. , Ev ans, S. J. W. , Mur- ra y, G. D. and Best, N. G. (2002). Commissioned anal- ysis of surgical p erformance using routine d ata: Lessons from the Bristol I nquiry (with d iscussion). J. R oy. Statist. So c. Ser. A 165 191– 232. MR1869173 Thompson, P. (1997). Ba yesian p -v alues. St atist. Pr ob ab. L ett. 31 267 –271. MR1439945 Y ang, R . and Berger, J. (1997). A catalog of noninforma- tive p riors. ISDS Discussion Pa p er 97-42, D uke Un iv.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment