A regional Bayesian POT model for flood frequency analysis
Flood frequency analysis is usually based on the fitting of an extreme value distribution to the local streamflow series. However, when the local data series is short, frequency analysis results become unreliable. Regional frequency analysis is a con…
Authors: Mathieu Ribatet (UR HHLY, INRS), Eric Sauquet (UR HHLY)
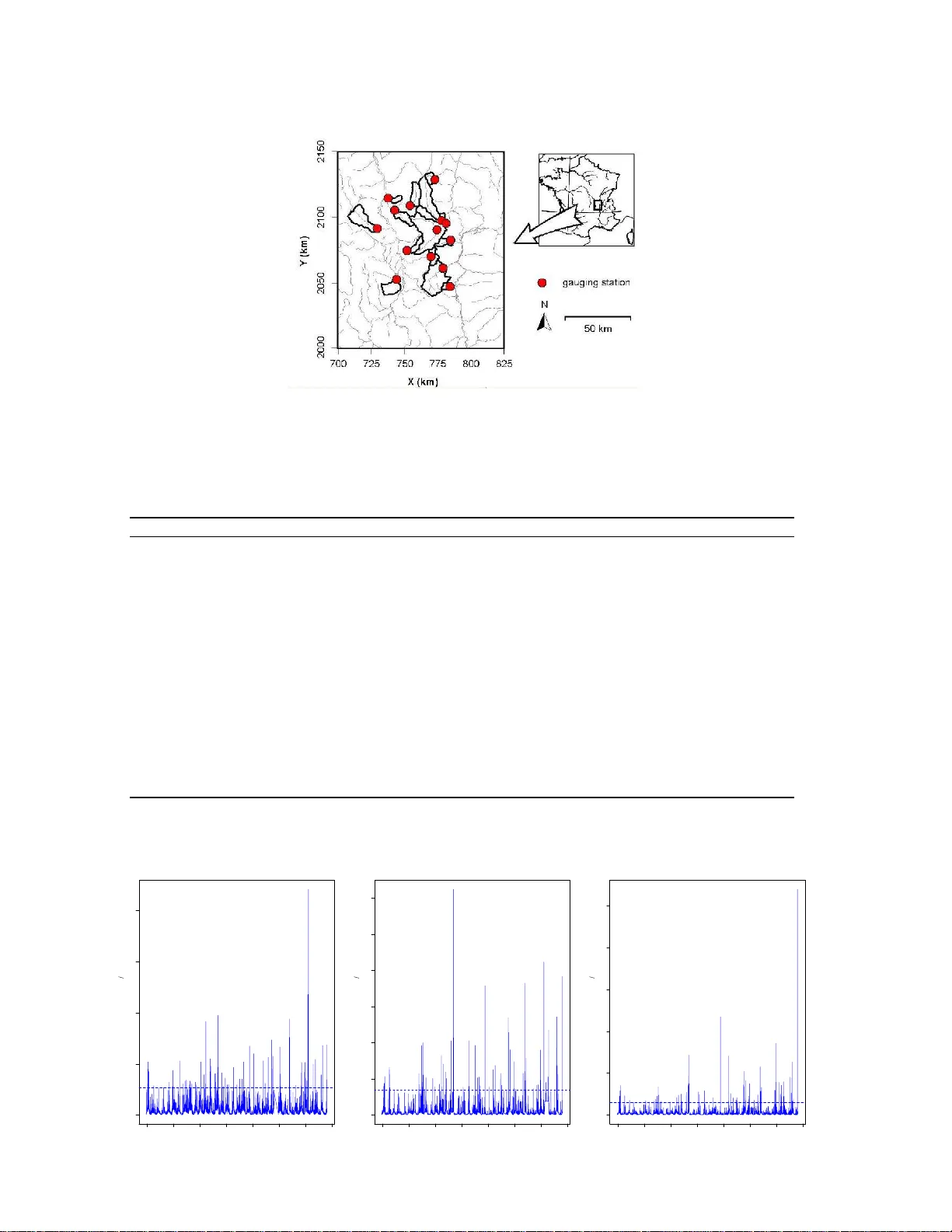
A Regional Bay esian POT Mo del for Flo o d F requency Analy sis Mathieu Ribatet 1 , 2 Eric Sauquet 2 Jean-Mic hel Gr ´ esillon 2 T aha B.M.J. Ouarda 1 1 INRS-ETE, Univ ersity of Qu´ ebe c, 4 90, de la Couro nne Qu´ eb ec, Qc, G1K 9 A9, C ANADA 2 Cemagref, 3 b is quai Cha uveau CP 220, 6 9336 Lyon Cedex 0 9 , FRANCE Abstract Floo d F requency Analysis is u sually based on the fitting of an ext reme v alue distribut ion to th e series of local streamflow. How ever, when the local d ata series is short, frequency analysis results b ecome unreliable. Regional frequency analysis is a con v enient w a y to reduce t h e estimation un certain ty . In this w ork, we propose a regional Bay esian model for short record length sites. This mo del is less restrictive than the Index Flo o d mo d el while preserving the formalism of “homoge neous regions”. Performance of the prop osed mo del is assessed on a set of gauging stations in F rance. The accuracy of q u antil e estimates as a function of homogeneousness level of the po oling group is also analysed. R esults indicate that the regional Ba yesia n mod el outp erforms the Index Floo d mo del and local estimators. F urthermore, it seems that w orking with relatively large and homogeneous regions ma y lead to more accurate results than w orking with smaller and highly homogeneous regions. Key words: Regional F requency Analysis – Bay esian Inference – In dex Flo od – L-moments – Marko v Chain Monte Carl o 1 In tro duction Flo o d frequency analys is is essential in preliminary studies to define the desig n flo o d. Metho ds for estimating design flow usually co nsist of fitting one of the distributio ns given by the extreme v a lue theory to a sa mple of flo od even ts. If mo delling exceedance ov er a thresho ld is o f interest, a theor etical justification (Fisher and Tipp ett, 1928; Balkema and Haa n, 1974; Pick ands, 197 5) exists for the use o f the Generalized Pareto distribution (GP). F ( x ) = 1 − 1 + ξ ( x − µ ) σ − 1 /ξ (1) where 1 + ξ ( x − µ ) / σ > 0, σ > 0 . µ , σ and ξ a re the lo catio n, s c a le and shap e para meters. This distribution is defined fo r ξ 6 = 0, and can b e derived by contin uit y in the ca se ξ = 0, corr esp onding to the Exp onential case: F ( x ) = 1 − exp − x − µ σ (2) A co mpr ehensive review o f the Extreme V alue Theor y is given by Embrec h ts et al. (19 97) a nd Co les (2001). How ever, frequency analy s is ca n lead to unreliable flo o d quantiles when little data is av ailable at the site o f interest. A conv enien t wa y to impr ov e estimates of flo o d sta tistics is to incorp ora te data fro m other g auged lo cations in the estimation pro cedures . This appro a ch is widely applied in hydrology and is known as Regio nal Flo o d F re q uency Analysis ( RFF A ). One of the most p opular and simple appro a ches privileged by enginee r s is the Index Flo o d metho d (Dalrymple, 1960). The sta ndard pr o cedure allows: a) the delineation o f homogeneous reg ions, i.e. a se t o f sites which b ehav e - hydrologically and/o r statistically - in the same wa y; b) the deriv a tion of a regio na l flo o d frequency distribution; c) and the estimation of the parameters and qua ntiles at the site o f in terest. Regions are collec tio ns o f gauged basins with simila r site characteristics r elated to the flo o d ma gnitude. The p o oled sta tio ns a re not necessa rily in the proximit y of the s ite of interest. F or ming homogeneous 1 regions can b e achiev ed in v ario us wa ys. Regions have first been geogra phically established. More recent work pr omoted the use of ge ographica lly non-co nt iguous reg ions (Burn, 1990; GRE HYS, 1996). Recent resear ch has defined the concept of “regio n of influence” (Acreman and Wiltshire, 19 89). Other techniques can be used such as Artificial Neural Netw or ks to identify g roups o f stations (Hall et al., 20 02). The Index Flo o d mo del assumes that flo o d distributions at a ll s ites within a region ar e identical, up to a scale factor. The Index Flo o d approa ch is not exempt from critics as its application requires strong assumptions. One ma jor implicit assumption, no ticed by Gupta et a l. (1 994), is that the co efficient of v ariatio n of p eak flows is to b e constant across the region. This fundamen tal prop erty seems not to b e verified in practice (Robinson and Siv apalan, 1997) and not physically justified (Katz et al., 2 002). The a ssumptions o f the Index Flo o d mo del nee d often to b e relaxed to s uit the obser v ations. F or this purp ose, Gabriele and Arnell (1991) prop osed a hierar chical approa ch to RFF A. The skewness is still suppo sed to b e constant o n the whole reg io n, but the co efficient o f v aria tio n and the mean annual flo o d can v ary slowly from one subregio n to a nother. How ever, the tw o a uthors underlined the pra ctical difficulty to delinea te these subregio ns . In the Index Flo o d mo del, each obser v ation fr om any site within the region hav e the same weight . How ever, it seems not optimal as, obviously , the most precio us information come from the targ et s ite. Indeed target data - even s ho rt - ar e the o nly o ne which are “r eally” distributed as the ta rget site. W e suggest her e to carr y out a Bayesian a pproach that encompas s es the cla ssical Index Flo o d mo del and uses the whole data in a mo re efficient manner . In summary , the prop osed Bay esian approach differs from the Index Floo d mo del as it: a) use s the at-s ite infor mation in a more efficien t wa y since this a pproach distinguishes the tar get site data a nd the re gional data; b) do es not imp os e a purely deterministic relationship b etw een sites within the regio n. The ma in g oal of this article is to test the efficiency and ro bustness of the developed regio nal Bay esian mo del when dealing with short r ecord length se r ies. F or this pur p o se, classical freq ue nc y analysis i.e. lo cal and tra ditional RFF A will b e compared to the sugg e s ted re g ional Bayesian appr o ach. Section 2 presents a br ief summa r y of the clas sical Index Flo o d mo del. Relev ant theoretica l asp ects of Bay esian theory are intro duced and applied to flo o d mo delling in a RFF A co nt ext in Sec tio n 3 . Section 4 describ es the data set used to illustra te the method. Section 5 des crib es the pro cedure used to elicit the prio r distribution. Section 6 outlines the weaknesses and strengths of each approa ch on a typical homogeneous region. Finally sec tio n 7 presents a n ana lysis of the effect of homog eneity level on q ua nt ile e stimation. 2 The In d ex Flo o d mo d el The Index Flo o d metho d states that flo o d frequency distributions within a par ticular region ar e supp osed to be identical when divided by a s cale facto r - namely the Index Flo o d. Mathematically , this ass umption is ex pressed as: Q ( S ) = C ( S ) Q ( R ) (3) where Q ( S ) is the quantile function at site S , C ( S ) the Index Flo o d at site S a nd Q ( R ) the regio nal quantile function i.e. the dimensio nless quantile function v alid acros s the homogeneous region. Equation (3) is the core of the mo del a nd lea ds to strong constra int s concer ning at-site distribution parameters . Consequently , the shap e parameter is the same thro ughout the homog eneous region, wher eas the lo cation and sc a le parameters ha ve simple sca ling behaviour - see App endix A. Equation (3 ) is supp os ed to b e satisfied if all sites ar e hydrologically a nd/or statistically similar . There- fore, one o f the ma in as p ects of this approa ch is to ident ify a homogeneous r e g ion which includes the target site. Similarity in ba sin character istics is ne c e ssary but not sufficient to ensure the homogeneity of the regio n regar ding the statistics of the flo od pea ks. Hos king and W allis (1993, 1 997) sugge sted a heter ogeneity measure H 1 to ass ess if a region is “a cceptably ho mogeneous” ( H 1 < 1), “proba bly heterogeneo us” (1 ≤ H 1 < 2) or “definitively heterogeneo us” ( H 1 ≥ 2). Note the case H 1 ≤ 0 seems to detect cor relations betw een sites within the r egion. Once the region satisfies the homogeneity test of Hosking and W allis (1993, 1 997), the regional flo o d frequency distribution and the r elated at-site distribution is co mputed in a class ical wa y . That is, by fitting 2 the regional distribution to the weight ed mean o f sample L -moments. Details for computing heterog eneity statistics, regio nal flo o d fre q uency and a t- site distr ibution can be found in (Hosking and W allis, 199 3, 1997). By definition of the Index Flo o d mo del, it c an b e seen that any realisatio ns of each samples hav e the sa me weigh t. Giving equa l w eights to all s ite obser v ations is debata ble since the mo st relev ant information is certainly the tar get site one. Relev ance o f the target site info r mation is obvious as this is the only one which is “ really” distributed a s the targ e t site. Th us, in this appro ach the av ailable info rmation is no t efficiently used. 3 Regional Ba y esian mo del The B ayesian co nce pts hav e alrea dy b e e n a pplied with succes s to the r egional frequency analy sis of extreme rainfalls (Coles and Pericc hi, 200 3) a nd flo o ds (Madsen and Ro s b jerg, 19 97; Nor throp, 2004). Regional information is not us ed to build a r egional distribution but to s pe c ify a kind of “ suspicion” ab out the targ e t site distr ibutio n. This is easily a chiev ed in the Bay e s ian fr amework through the so called prior distribution. The ma in goa l of Bay es ian inference is to compute the p oster ior distr ibution. The po sterior distribution π ( θ | x ) is given by the Bay es Theor e m: π ( θ | x ) = π ( θ ) π ( x ; θ ) R Θ π ( θ ) π ( x ; θ ) dθ ∝ π ( θ ) π ( x ; θ ) (4) where θ is the vector of parameters of the distr ibution to b e fitted, Θ is the space parameter . π ( x ; θ ) is the likelihoo d function, x is the vector o f o bs erv ation and π ( θ ) is the prior dis tribution. In theory , the p osterior distr ibution is entirely known but is o ften insolv able - b ecaus e o f the integral. One of the solutions is to fix a prior mo del which leads to a n a nalytical - or semi-ana ly tical - p oster ior distribution and which allows the p osterior distribution to b e computed more e a sily (Parent and Bernier, 2003). Nevertheless, the most conv enient wa y is to implement Markov Chain Mon te Carlo ( MCM C ) techn iques to sample the p oster ior distribution. This approa ch avoids using a purely a rtificial prior mo del with no theor etical and/or ph ysical justifications. F or o ur applica tion, the likelihoo d function co rresp onds to the GP distribution a s pe a ks over a threshold are of int erest. F r om Eq. (4), if the prio r distribution is known, pos terior distribution c a n b e co mputed - up to a cons tant. The next sectio n desc r ib es how to define the prior distribution. 3.1 Prior Distribution The prior mo del is usually a multiv ariate distribution which must r e pr esent b eliefs ab out the distribution of the parameters i.e. µ , σ and ξ prior to having a ny information ab out the data. As the prop osed mo del is fully parametric, the prio r dis tr ibution π ( θ ) is a multiv ariate distributio n ent irely defined by its hype r parameter s. In our cas e study , the marginal prio r distributions were supp osed to be indep endent logno rmal for bo th lo cation and sca le parameter s and nor ma l for the shap e parameter. Thu s, π ( θ ) ∝ J ex p ( θ ′ − γ ) T Σ − 1 ( θ ′ − γ ) (5) where γ , Σ ar e hyper para meters, θ ′ = (log µ, log σ, ξ ) and J is the Jacobian o f the transforma tion from θ ′ to θ , na mely J = 1 /µσ . γ = ( γ 1 , γ 2 , γ 3 ) is the mean vector, Σ is the cov ariance matrix. As marg inal priors are suppo sed to be independent, Σ is a 3-3 diago nal matrix with diago nal elements d 1 , d 2 , d 3 . 3 3.2 Estimation of the hyper parameters Hyper parameter s ar e defined through the Index Flo o d concept. Consider all sites of a reg ion except the target site - say the j -th site. A set of pseudo targ et site para meter s can b e computed: ˜ µ ( i ) = µ ( i ) ∗ C ( j ) (6) ˜ σ ( i ) = σ ( i ) ∗ C ( j ) (7) ˜ ξ ( i ) = ξ ( i ) ∗ (8) for all i 6 = j , where C ( i ) is the at-site Index Flo o d and µ ( i ) ∗ , σ ( i ) ∗ , ξ ( i ) ∗ are r esp ectively the lo c a tion, sca le and s hap e at-site parameter estimates from rescaled sample. Under the hyp o thesis o f the Index Flo o d mo del, pseudo para meters ˜ µ ( i ) , ˜ σ ( i ) , ˜ ξ ( i ) for i 6 = j are exp ected to b e similar to the target s ite distribution parameter s. Note that, infor mation from the target site sa mple is not used to elicit the prior dis tr ibution. Thu s, C ( j ) in eq ua tions (6) and (7) must b e es tima ted without use o f the j -th site sample. F ro m these pse udo par ameters, hyper par ameters can b e computed: γ 1 = 1 N − 1 X i 6 = j log ˜ µ ( i ) , d 1 = 1 N − 1 X i 6 = j V a r h log ˜ µ ( i ) i (9) γ 2 = 1 N − 1 X i 6 = j log ˜ σ ( i ) , d 2 = 1 N − 1 X i 6 = j V a r h log ˜ σ ( i ) i (10) γ 3 = 1 N − 1 X i 6 = j ˜ ξ ( i ) , d 3 = 1 N − 2 X i 6 = j ˜ ξ ( i ) − γ 3 2 (11) It is imp or tant at this step to incor p orate the uncertainties on the elicitation o f the prio r distributio n. In- deed, it may avoid pro blems re lated to misle a ding infor mation resulting from a region not so homogeneo us and mo de r ating a “ suspicion” that may b e to o true. F or this purp ose, tw o types of uncer tainties ar e taken into account: the one from pa rameter estimation, and the o ther one from ta r get site Index Flo o d estimation. Th us, hyper pa rameters γ 1 and γ 2 are estimated differently tha n γ 3 as pseudo para meters for lo cation and sca le parameters depends on the target site Index Flo o d. Under the hypothesis of indep endence b etw een C ( j ) and µ ( i ) ∗ , σ ( i ) ∗ the v ariance terms in E q. (9) and (10 ) are co mputed ac c ording thes e tw o types o f uncerta in ties: V a r h log ˜ µ ( i ) i = V ar h log C ( j ) i + V ar h log µ ( i ) ∗ i (12) V a r h log ˜ σ ( i ) i = V ar h log C ( j ) i + V ar h log σ ( i ) ∗ i (13) The indep endence a s sumption be tw een C ( j ) and µ ( i ) ∗ , σ ( i ) ∗ is not to o res trictive as the targe t site Index Flo o d C ( j ) is es timated independently from µ ( i ) ∗ , σ ( i ) ∗ . Note that V ar h log · ( i ) ∗ i are estimated thanks to Fisher Infor mation a nd the Delta metho d. E stimation of V ar log C ( j ) is a sp ecia l case and dep ends on the method for estimating the at-site Index Flo o d. Nevertheless, it is alwa ys pos sible to carr y o ut an estimation o f this v aria nce, at least throug h standard error s. 3.3 Sp ecificities of the prop osed prior mo del The construction of the prio r distribution with the r egional information w as a lready suggested b y (Northrop, 200 4). Nevertheless, the lo c a tion parameter - or equiv alently the thr eshold in the GP ca se - was supp osed to b e known. Y et, fro m a theo r etical p oint of view, the lo cation pa rameter can not be known prior to having any infor mation from the targ et s ite sample. No rthrop (2 004) developed a simila r approach based on the Index Flo o d but uncer taint y asso cia ted with the s cale facto r prediction was not considered. The prior distribution was elicited directly from the distr ibutio n of the “pseudo target site” 4 estimates ( ˜ µ ( i ) , ˜ σ ( i ) , ˜ ξ ( i ) ). In this p ersp ective, “pseudo targ et site” estimates are viewed as constant and not as rando m v a riables. When dealing with sites with a long recor d, uncer tainties on parameter distri- butions are low. O n the contrary , this hav e a much more impact for the Index Flo o d as uncerta int ies are a s muc h lar ger as the target site Index Flo o d is estimated witho ut use of at-site data - even with long record length sites. No te that if the prior distribution is ov e r ly accur ate, estimatio n a nd cr edibilit y int erv als are influenced. F o r these reaso ns and unlike the approach pro p o sed by Northro p (2004), the target site Index Flo o d in the prop osed methodo logy is co nsidered to be a r andom v aria ble and not a constant. Thu s, our pr ior distribution is not to o fals ely “tight fit”. But it reflects “ real” b eliefs ab out targ et site behaviour without an y use of tar get site sample. Madsen and Rosb jerg (1997) a nd Fill and Stedinger (1998) b o th pr esented a regio na l empirical B ayesian estimator. Both models used conjugates families for pr io r distributions. How ever, even if conjugates families ar e conv enient devices, they s hould no t only b e used just b ecause computatio ns a re ea sier. In their appro aches, prio r distributions are elicited with qua nt ile regres sion on re le v ant ph ysiogr aphic characteristics. Our approach differs differs from the tw o pr evious empirical Bay e sian appr o aches (i.e target site sample is not used to e lic it prio rs) a nd resp ects in tha t way abso lutely the B ayesian theor y . Mo r eov er, conjugate priors are not co nsidered, but pr iors are suited to the data. F or example, the log normal distribution for b oth lo catio n and shap e parameters is justified b y a physical and theoretical lower bo und as : a) discharge da ta are naturally non negative; so the lo cation pa rameter should also b e non negative; b) the scale parameter is str ictly p o sitive by definition of the GP distribution. This pr ior mo del is quite different from the o ne prop os ed by Co les and T awn (199 6) who intro duce d a lognorma l pr ior dis tr ibution only for the s cale par ameter. Note that it is p ossible to work with retur n levels (Coles and T awn, 1996) or retur n per io ds (Crowder, 19 92) instead of working with distribution parameters . Howev er, r egional infor mation is suited to work directly with distribution par a meters. F o r other studies, such prior mo dels co uld b e of int erest if “ suspicion” is base d on return levels or return per io ds. 4 Data description Streamflow data were collected at 48 gauging s tations in an area r eaching from the 4 5 th to 47 th N and from the 3 r d to the 8 th E. The s election of the ga uging sites was initially based on the 2 2 regions int o which F rance is divided for the implementation of the W ater F ramework Directive (W as son et al., 2004). Seven regions cover the a rea under study . T he s e r egions were manually delineated taking into account the spatia l pattern of mean annual r ainfall, elev ation and underlying g eology . All thes e v ar iables might influence flo o d genera tion pro cesses. Therefore this divis ion is co nsidered as a preliminar y g uide for po oling stations. Accor ding to Hosking and W allis (19 97), pr e-regio ns were slightly altered by identifying discordant sites while maximising the n um b e r of site within the r egion a nd meeting the heterog eneity test. Fina lly , a set of 14 s tations was s elected fo r this study . The heterog eneity statistic for this group is H 1 = 0 . 17 < 1 . Consequently , the reg ion b e consider ed as “acceptably homog eneous”. The datase t includes seven tr ibutaries to the Loire River a nd seven gauging statio ns lo cated in the F renc h part of the Rhˆ one basin (Fig. 1, T ab. 1). The reco r d length o f the instantaneous discharge time ser ies ranges from a minim um of 22 years to a maximum of 37 y ears, with a mean v a lue o f 32 years. The drainage a reas v ar y from 32 to 792 km 2 . Moreov er, most of the gauging s tations monito red first- order stream catchmen ts i.e. a ll but t w o pairs of c a tchmen ts are unnested. The lar ge ma jorities of flo o d in the region oc c ur dur ing autumn a nd wint er and a re caused b y heavy liquid precipitation. Partial dura tion flo o d ser ies w ere extracted fro m the time series for each statio n. Fig . 2 illustrates time series for stations U45 0501 0, U4 63501 0 and V3015 0 10 a nd their asso ciated thre sholds. Thr e s hold levels were selected to extra ct in av erage ar ound tw o even ts p er year while mee ting the criteria of indep endence betw een flo o ds (Lang et al., 1 9 99). Three stations U45 0501 0 , U463501 0 and V30 1501 0 w ere of particular interest bec a use of their e x tended record length of 3 7 years. The time series of those three sites are display ed in Fig. 2. In this case study , the sc a le factor was set to co rresp ond to the 1-year return flo o d q ua nt ile - or equiv alently the quantile a sso ciated with probability o f non exce e dance 0 .5. Thu s, our choice for the Index Flo o d 5 Figure 1: Loca tion of the gaug ing stations within the studied area T able 1: Characteristics of the stations of the homog eneous r egion Co de Station Area k m 2 X ( k m ) Y ( k m ) Record K0624 510 The Bo nson river a t St Mar cellin 104 744.72 2053.9 0 197 1-200 3 K0663 310 The Co ise river a t Lara jasse 61 770.67 2072.1 1 197 1-200 3 K0704 510 The T oranche river at St Cyr 62.3 752.63 2076.6 8 197 7-200 3 K0813 020 The Aix r iver a t St Ger main Lav a l 193 729.48 2093.7 1 197 3-200 2 K0943 010 The Rhins r iver a t Amplepuis 114 754.52 2111.1 0 197 3-200 3 K0974 010 The Ga nd r iver a t Neaux 85 743.45 2107.7 5 197 2-200 3 K1004 510 The Rho do n river at Perreux 32 738.40 2116.6 4 197 3-200 3 U45050 10 The Ardie r es river a t Beaujeu 54.5 773.67 2130.7 5 196 9-200 3 U46240 10 The Azer gues river at Cha tillon 336 779.07 2099.7 2 197 0-200 3 U46350 10 The Br evenne river at Sain Bel 219 775.90 2092.5 7 196 9-200 3 U46440 10 The Azer gues river at Lo zanne 792 782.56 2098.0 9 198 1-200 3 V30150 10 The Yzer on river a t Crap onne 48 785.47 2084.5 0 196 9-200 3 V31140 10 The Gier river at Riv e de Gier 319 780.54 2062.6 7 198 1-200 3 V33150 10 The V alencize river at Chav a nay 36 786.54 2048.6 0 197 8-200 3 1970 1975 1980 1985 1990 1995 2000 2005 0 10 20 30 40 Years Flow m 3 s U4505010 1970 1975 1980 1985 1990 1995 2000 2005 0 20 40 60 80 100 120 U4635010 Years Flow m 3 s 1970 1975 1980 1985 1990 1995 2000 2005 0 10 20 30 40 50 Years Flow m 3 s V3015010 Figure 2: Times ser ies for sites U450 5010 , U4635 010 and V3015 010 and thresholds asso cia ted 6 Location Density 3.0 3.5 4.0 4.5 5.0 5.5 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Scale Density 1 2 3 4 5 6 0.0 0.2 0.4 0.6 Shape Density −0.4 0.0 0.2 0.4 0.6 0.8 0.0 0.5 1.0 1.5 2.0 2.5 Figure 3: Histogra ms o f pseudo targ et site es timates of lo catio n, scale and sha p e pa rameters for site U45050 10 20 50 100 200 500 1000 5 10 20 50 100 Area ( km 2 ) C U4505010 Figure 4: Regr ession o n the basin a rea for estimating the at-site index flow for station U45050 10 is close to the sample median which was the r eference in Robson and Reed (199 9) but differs from Hosking and W allis (1997) where the sample mean was used. This par ticular choice for the Index Flo o d is not unint entional as estimating the quantile with probability of non exceeda nce 0.5 is more ro bus t than estimating the sample mean. Analys ing the influence of Index Flo o d selectio n is b eyond the sc o p e of this work. The ma in p oint is to keep the sa me Index Flo o d thro ughout the case study to compar e appr o aches on the s a me ba sis. 5 Elicitatio n of the prior d istribution T o es timate the tar get site Index Flo o d, the mos t p opular wa y is to develop an e mpir ical formula that relates the flow statistic to geomor phologica l, la nd-use and climatic descriptor s. This relationship is usually esta blished by multiv a riate regres s ion pro c e dures. In our case study , we consider a simple mo del for which only one expla na tory v ariable is introduce d in the regre s sion analysis : the dra inage area. The power fo r m mo del is adopted: C = aA b (14) where A is the area of the c a tchmen t. Parameters a and b ar e computed throug h ordina ry least square pro cedures on logarithmica lly transfor med data. How ever, more sophistica ted mo dels could b e car ried out. Nevertheless, for our case study , obs erv ations demonstrate that Eq. (14) is a go o d par ametrisation for estimating the Index Flo o d. Fig. 3 and 4 illustrate the efficiency o f the regressive and pr ior mo del for site U45 0501 0 for which: ˆ C = 0 . 12 A 1 . 01 R 2 = 0 . 94 (15) Regional informa tion was incorp ora ted in the prior distr ibutio n through the Index Flo o d mo del. More- ov er , uncer tainties in the prio r distribution were incor po rated. Thus, the prior infor mation is , on one 7 2 3 4 5 6 7 0.0 0.2 0.4 0.6 0.8 1.0 Location Density 0 2 4 6 8 10 12 0.0 0.2 0.4 0.6 Scale Density −2.0 −1.0 0.0 0.5 1.0 0.0 0.5 1.0 1.5 2.0 2.5 Shape Densities Figure 5: Prop os ed prior (dashed line), prop os ed p oster ior (so lid line) and p osterio r from an uninfor mative prior (dotted line) margina l densities for GP parameters . Site U45050 10 with 5 y ears rec ord leng th. V ertica l lines deno tes b enchmark v alues. hand, no t to o fa lsely accura te a nd on the other ha nd, informa tive enough b eca use of the supp osed ho - mogeneity of stations. 6 P erformance of the B a y esian mo del on a homogeneous region When making classica l infer ence on small samples, the uncertainties may be too la rge. If an extr emal even t or to o many “re gular even ts” in this short reco rd p erio d a re present, estimatio n can b e impacted. It could lead to a dr amatic overestimation or under e stimation of quantiles cor r esp onding to different return levels. A per fect mo del is expe c ted : a) to per form well enoug h even with sma ll sa mples; b) to b e robust enough when an extreme even t o c c urs in the sample; c) to b e ro bust eno ugh when to o many “reg ular” even ts o ccur in the sample. In this section, thre e different mo dels will b e applied. F o r this purp ose, the three stations U450501 0, U46350 10 and V301 5 010 were selec ted to a ssess the robustness a nd e fficie ncy of the lo ca l, regional and Bay e sian re g ional mo dels. These three different a pproaches corr esp ond to : a) lo ca l: fit the GP distr ibu- tion to the p ea ks ov er thr eshold data with the Max im um Likelihoo d Estimato r (MLE), Unbiased Prob- ability W eighted Moments (PWU) and the Biased Probability W eig ht ed Mo ment s (PWB); b) regio nal (REG): fit a regiona l GP distribution as describ ed in section 2 a nd obtain the target site distribution; c) regional Bayesian (BA Y): elicit the prio r densit y from regio nal info r mation, then compute the p osterio r density throug h MCMC techniques. As a n illustration o f MCMC output, Fig. 5 dis plays the prio r a nd po sterior marg inal dens ities for the GP pa rameters of the pro p o sed mo del. Margina l p os ter ior distribu- tion obtained fro m an uninformative prior mo del a r e also displayed. That is with the same prior mo del but with a large v ar iance - i.e. d i = 10 0 0 , i = 1 . . . 3. Fig. 5 shows the relev ance o f regio nal information as the pro po sed prior mo del is clearly mo re accura te than an analysis directly from data. Moreover, for the prop osed mo del and even with o nly 5 years reco rd length, ma r ginal p o sterior dens ities ar e more accurate than mar ginal prior densities - exc ept for the s hap e parameter. Thus, combination o f r egional and target site information at tw o different s ta ges is worth while, even when o nly few data are av a ilable. Lo cation para meter is a sp ecial case as the modes o f b oth ma rginal prior and pos terior densities seem to be s ignificantly dissimilar. As the main go al of this work is to compare models on small samples, efficiency will b e ev aluated on sub-samples from the origina l da ta. Loca l Maximum Likelihoo d Estimation on the whole s a mple will b e used as b enchmark to a ssess the p erformanc e of ea ch mo del. This pa rticular cas e will b e de no ted THEO in the following s ections. The choice of MLE estimate a s a b e nch mark v alue is reas o nable b e cause of its theoretica l motiv ation and a symptotic efficiency . Moreover, the MLE approach allows the calculation of profile confidence interv als. This is a key p oint as these profile confidence interv als ar e often more accurate than those ba sed o n the Delta Metho d and Fisher Infor mation (Coles, 2001). F urther mo re, a s interpretation on quantile e s timates is mor e na tural than for distribution par ameter estimates, the analy sis will focus on quantiles cor resp onding to return p erio d 2, 5 , 1 0 and 20 years. Benchmark v alue s for these quantiles - and their a sso ciated 90% pr ofile likeliho o d confidence in terv als 8 T able 2: Benchmark v alues for 2 , 5, 10 and 20 years quantiles and the asso ciated 90% pro file likelihoo d confidence in terv als in brack et Station Q 2 Q 5 Q 10 Q 20 U45050 10 10 .8(10.1, 11 .7) 1 5.3 (13 .9, 17.4) 19 .5(17.2, 23.4) 24 .4 (20.6 , 31.5) U46350 10 33 .0(30.0, 36 .5) 5 2.2 (45 .5, 62.5) 72 .2(60.2, 95.4) 98 .9(69.2, 20 0.5) V30150 10 7.5 ( 6.9, 8.3) 11.7 (10.4, 13.7) 1 5.9(13.6 , 19.9 ) 21.3 (17.3, 28.8 ) 0.5 1.0 2.0 5.0 10.0 20.0 50.0 200.0 500.0 0 20 40 60 80 100 Return Periods (Years) Sreamflow ( m 3 /s ) MLE PWU PWB BAY REG THEO Samp. Obs. MLE THEO BAY REG PWB PWU Figure 6: Comparison of frequency curves for site V3015 010 with 15 last years recor ding are deta iled in T a b. 2. Benchmark v alues with retur n p erio ds greater than 20 years will b e considered unreliable - a s uncertainties on these quantiles are to o large with only 37 years o f record. Moreov er, for such return p erio ds, b enchmark v alues ar e quite e quiv alent to those obtained with PWM estimates - with a mean bias of 0.89%. So, p erformance of each mo del is no t to o muc h impa cted b y the choice of the ML E estimato r for b enchmark v alues. Different freq uency curves for site V3015 010 with o nly the las t 15 years r ecording a re displayed in Fig. 6. Let us fo cus o n the larg est observ atio n. Return p erio d r elated to this even t is very high fo r the REG approach. All other mo dels lead to significantly low er return p erio ds. This flo o d even t is extreme at regional s c ale but not a nymore in a lo cal co ntext. This underestimation is due to the misuse of the target site sample to establish the r e gional distribution. On the other side, the regio na l Bay esian mo del per forms well for all return pe r io ds. Indeed, Fig. 6 indicates that the return level curve is very s imilar to benchmark one. This is quite logica l a s it adds up the a dv antage o f using efficiently the target site sample and a go o d “s uspicion” on the glo ba l b ehaviour o f the flo o d p eak distribution thanks to the s o-called prior distribution. Lo cal approa ches sug g est a v ery heavy tail as the extremal even t of year 2004 (see Fig. 2, right panel) was in the la st s equence of 15 years o f r ecords. As one of the main g oals of a RFF A pro cedure is to deal with small samples, the target site sa mple was trunca ted to obtain shorten p erio ds of r ecords of m years, m ∈ { 5 , 10 , 15 , 20 , 25 , 30 , 37 } . Robus tness and efficiency of the metho ds to conv er ge to the parameters of the targ et s ite distributio n are measured. F or this purp o s e, quantile estimates cor resp onding to return p erio d 2, 5, 10 , 20 years - cor r esp onding to non-exceedance proba bilities 0.75, 0.9, 0.95 a nd 0.975 resp ectively - are po int ed. The evolution of 9 Figure 7: Evolution of Q 2 , Q 5 , Q 10 , Q 20 estimates as the size increases for the site U463501 0 and 90% profile likelihoo d confidence in terv al for the b enchmark v alues - light blue area quantile estimates as a function of the r ecord length p er io d is presented in Fig. 7. The figur e is a chiev ed considering only the first m years ; tha t is, for exa mple, estimates rela ted to the 5-year r ecord length corres p o nds to the per io d 1969 – 1973. Because o f the extreme event o bserved in 1983 (see Fig. 2, middle panel), systematic underestimation o f benchmark v alues for lo cal a nd REG appro aches ca n b e noticed. This result shows that: on o ne ha nd, for small samples cla s sical inference like MLE, PWB and P WU are to o resp onsive if to o many “ regular ” even ts o ccur red. On the other hand, for the Index Flo o d mo del, underestimation o f quantiles is re la ted to the underestimation of the scale factor C ( S ) in Eq. (3 ) b ecause of these “regular ” even ts . Only the Bay e sian mo del p erforms well enough even with reco r d lengths low e r than 15 years. A mono tonic increa se of the design flo o d es timates w ith the sample leng th ca n b e noticed in Fig. 7. This be haviour is ea sily explained by Fig. 2, middle panel. Indeed, o nly the last part o f the time series shows r eally extreme even ts. As the recor d leng th increas es, m uch mo re extr eme even ts o ccur lea ding to higher es timates. The Bay e sian appr oach is the only o ne which do es no t really present this monotonic behaviour. Moreov er, the Bay esian appr o ach is by far the most robust a nd a ccurate mo del as, on the whole range of recor d length, and for all b enchmark v a lues, estimation lies in the 90% profile likelihoo d confidence int erv al. This is not true with any other mo del. The a dv antage of inco rp orating regio nal information within a Bayesian framework is certainly to define a “r estricted spa ce” where distribution par ameters belo ng to. Thus, the impact of a very extr emal ev ent - or conv ersely to o many low-level even ts - sho uld be r egarded as an extr eme event r elated to this “restricted s pace”. The g ain of accuracy in the target site from using reg ional information is clea rly established in s ection 6 (Fig. 6 a nd 7). The Bay esian appr oach seems to be robust ev en with small s amples while being accurate with larger sample. The p o or p er formance of the REG mo del is related to a bad selection of sites within the “ homogeneous” region b eing co nsidered and es timates may b e more accur a te if “b etter ” reg ions were considered. Unfortunately , building up such r egion is difficult b ecause of the purely deterministic rela tion (3). As the Bayesian approa ch rela x es the REG mo del, the s earch for mor e homog eneous regions co uld 10 T able 3 : Heter o geneity sta tistics for the four regio n consider ed - statistics in brack et are obtained with the scale factor taken to b e the 1- year quantile corresp onding to no n-exceedance probability 0 .5 Region H e + H e H o H o + H 1 7.11 (6.83) 1 .35 (1.37) 0.17 ( 0.08) -0.60 (-0.67) H 2 3.46 (3.38) 1 .00 (1.03) 0.41 ( 0.33) -1.28 (-1.31) H 3 1.40 (1.45) 0 .30 (0.28) -0.09 (-0 .1 4) - 1.14 (-1.18) be ineffective. The g oal of the next section is to meas ure the p otential ga in, for the Bayesian mo del, against homogeneity prop erty . 7 Effect of heterogeneit y d egree on quan tile estimation As indicated in the pre v ious sectio n, we fo cus now on the impact of the level o f homogeneo usness of the region. F or this purp ose, w e consider four differ e n t regions - denoted H e + , H e, H o and H o + - which corres p o nd to increasing ly homogeneo us reg ions accor ding to the test of Hosking and W allis (1 997). The H o r egion corr esp onds to the r egion analys ed in the previous section a nd describ ed in T ab. 1. All regions hav e 14 site except for the most homogeneo us one H o + which contains o nly 8 stations. H e and H e + regions a r e derived form H o . One to five sites ar e withdrawn and r eplaced by o ther stations to obtain larger heterogeneity measure. The H o + region is a s ub- region of H o . Heter ogeneity statistics fo r these regions are summarised in T ab. 3. T o ev alua te the influence of homo geneousness level o f a region on q uantile es tima tio n, mo de ls ar e assessed using tw o per formance criteria : the Normalis ed Bias ( NBIAS ) and the Normalis ed Ro ot Me a n Squar ed Erro r ( NRMSE ). These indices ar e defined as follows : N B I AS = 1 k k X i =1 ˆ Q i − Q Q (16) N RM S E = v u u t 1 k k X i =1 ˆ Q i − Q Q ! 2 (17) where k is the num ber of estimates of Q a nd ˆ Q i is the i-th estimate of the benchmark v alue Q . T o compute these tw o indices, we fit all mo dels on all trimmed p erio ds of size m years - m ∈ { 5 , 10 , 15 , 20 , 25 , 30 } . Moreov er, the ov er all p e rformance of each mo del is e v aluated using a rank s core. This technique was already used to co mpare differe nt models in Sh u a nd Burn (2 004). T o calculate the rank sc o re, the p mo dels are ordered thanks to their p er formance indices - 1 corres po nding to the b est mo del and p to the w orst. F or ea ch mo del, the s c ores for the differe n t criteria are summed to obtain the ov erall ra nk score R o for the mo del. F or convenience, the overall ra nk sco re R o is standardised in such a wa y that in lies within the interv al [0 , 1]: R s = pq − R o pq − q (18) where p is the num be r of mo dels b eing considered, and q the num b er of indices. A standar dised rank score close to 1 - resp . 0 - is asso cia ted to a mo del with a g o o d - r esp. p o o r - p erfor mance. Three quantiles a re of particular interest Q 5 , Q 10 and Q 20 - i.e. as so ciated to pro bability of non- exceedance 0.9, 0.95 and 0.975 resp e ctively . N RM S E , N B I AS and the standardised rank score for station U463501 0 and a record length o f 5 years a r e illus trated in T ab. 4. Notations for differ e n t mo dels in this table consist of o ne low ercase letter referring to the Bay es ian appr oach b or Regiona l Index Flo o d r and the denomina tion of the homo geneity deg ree of the region. Only the M LE mo del do es not use these notations a s it is completely independent of the ho mogeneity level. Results from T ab. 4 demonstrate that the Bay esian mo del p erforms q uite well independently o f the r e g ion being cons ide r ed. How ever, this model seems to pe rform even be tter when applied to a “ a cceptably homogeneous ” or “proba bly heterogeneo us” regio n. F or the H o + region, the Bay es ian approa ch p erforms po orly . This may b e explained by the fact tha t the prio r distr ibutio n is to o informative and proba bly 11 T able 4 : Estimatio n of N RM S E and N B I AS for station U4 63501 0 with a record leng th of 5 years Mo del N RM S E N B I AS Rank Score Q 5 Q 10 Q 20 Q 5 Q 10 Q 20 M LE 0.33 0.34 0.39 0.01 − 0 .09 − 0 .18 0 .26 bH e + 0.16 0.1 3 0.18 0.09 − 0.02 − 0.13 0.65 rH e + 0.27 0.3 0 0.37 − 0.12 − 0.2 2 − 0.3 1 0.1 8 bH e 0.10 0 .0 7 0.11 0.08 0.00 − 0.09 0.85 rH e 0.27 0.2 6 0.28 − 0.03 − 0.1 0 − 0.1 7 0.4 3 bH o 0.14 0.09 0.0 8 0.12 0.05 − 0.02 0.76 rH o 0.27 0 .26 0.27 0.01 − 0.06 − 0.12 0.58 bH o + 0.29 0.2 8 0.25 0.29 0.27 0.25 0.19 rH o + 0.28 0.2 7 0.26 0.02 − 0.01 − 0.04 0.60 5 10 15 20 25 30 Record length (Years) (a) Rank Score 0.0 0.2 0.4 0.6 0.8 1.0 MLE rHe + rHe rHo rHo + 5 10 15 20 25 30 Record length (Years) (b) Rank Score 0.0 0.2 0.4 0.6 0.8 1.0 MLE bHe + bHe bHo bHo + Figure 8 : Score evolution as a function o f recor d le ng th for Sta tio n V30 15010 . (a) REG scor es, (b) BA Y scores not co nsistent with the target s ite sample. This comment is y et not discrepant with the go o d ov erall per formance of the REG mo del on this regio n. Indeed, a s the prior distribution is elicited using equatio ns (6)–(8), and the sca le factor C ( j ) is estimated without any use of the target site sample, this can lead to a misleading prior distr ibution while the REG mo del p erforms well. The bad estimation of the scale factor is less imp or tant with a more heter ogeneous r e gion as the prio r information is less informa tive, th us the Bay e s ian mo del p e rformance is not highly impacted. On the other side, the ov erall rank sco re of the REG mo del incr eases with the homogeneity degree o f the region. Y et, the ov e r all r ank sco re for the REG mo del never exceeds the v alue of 0.6 - rea ched for the H o + region. This v a lue remains mu ch low er tha n the b est rank sco re for the Bay es ia n mo del - i.e. 0.85 . These results c orrob o rate the sup eriority of the Bay esian appro ach. F ro m T ab. 4, tw o co nclusions can be established. On one hand, for small samples, the Bay esian a pproach is the most comp etitive mo del. On the other hand, results seem to indicate that there is no need to keep increasing the ho mo geneousness o f the region as it incr eases the risk of b eing to o confident in the “homogeneo us region” without increasing significantly the efficiency of the mode l. These results are in line with similar results obtaine d for sta tio ns U4 50501 0 a nd V30150 10, except for the bad b ehaviour of the Bayesian mo del on the H o + region. Indeed, for the other s ta tions, the Bay esian mo del remains more efficient than the REG mo del within the H o + region. How ever, its ov erall ra nk score remains sta ble thr o ugh out the different r egion - H e, H o and H o + . The “ risk” to deal with to o m uch ho mogeneous regio n - as H o + - is also co r rob ora ted as the ov erall rank sco re for the Index Flo o d mo del fo r station U45050 1 0 decr eases dra matically until 0.06. Thus, the Index Flo o d for the H o + region per forms quite well for stations U463501 0 and V3 01501 0, while v ery surprisingly badly with U4 5 0501 0. In Fig . 8 , the evolution of the overall r a nk sco re as a function of the r ecord length is illustr ated for s ta tion V30150 10. The left pa nel cor r esp onds to the REG part, while the right one stands for the Ba yesian approach. In b oth panel, the M L E score is als o presented. Fig. 8 indicates that the evolution o f the ov er all rank sco re is mo re stable for reg ional mo dels - that is REG and Bayesian mo dels - than for the 12 15 20 25 30 0 1 2 3 4 5 Location Density 5 10 15 20 0.00 0.05 0.10 0.15 0.20 Scale Density −0.2 0.0 0.2 0.4 0.6 0.8 0 1 2 3 4 5 Shape Density Figure 9: Effect of bad estimation of target s ite Index Flo o d on marg inal prio r and p oster ior densities. Site U463501 0 with 10 years r ecord length. M LE . F urthermore, the b enefit o f increas ing the homog eneity degre e of the r egion is more relev an t for the REG mo del than for the Bay esian mo del. Nevertheless, the worst Bay esian r ank score is a lwa y s quite close to the b est REG r ank sco re. This see ms to indicate the super iority of the Bay esian a pproach. This last p oint is cor rob ora ted with the results cor r esp onding to s tations U4505 010 and U46 35010 except for the bH o + mo del for station U46 35010 b ecause o f the ba d estimation of the sca le fa c tor C ( j ) - as denoted earlier. The effect of bad estimation o f the target site Index Floo d on pr ior and thereby on p os terior distributions is depicted in Fig. 9 . F rom Fig. 9, it is ov erwhelming that the prior mo del is not appropria te - particularly for the lo catio n pa rameter. Pr ior for the shap e parameter is not to o false as it do es not depe nd o n the target site Index Flo o d estimate. As the record length increases, the M LE mo del beco mes more and more efficient. In particula r, for record leng ths grea ter than 15 years, it is mo re effective than rH e + , rH e a nd r H o mo dels. On one hand, for re cord le ng ths smaller than 1 5 years, M LE is alwa ys le s s efficient than Bay esian a pproaches and even significantly for bH e , bH o and b H o + mo dels. This is quite logical a s Bay esian e stimation can b e lo oked at as a r estrictive ma ximum likeliho o d estimato r - res triction b eing defined by the prior distribution. So, under the hypothesis that the prior distribution is well-defined, the “restric tive estimator ” is un biased and has a s maller v a riance. On the other hand, for reco rd lengths gr eater than 1 5 y ears, M L E , bH e and bH o seems to be e q uiv alent. 8 Conclusion A framework to p erfo rm a regio na l Bayesian frequency a nalysis for pa rtially gauged stations is presented. The pr op osed mo del has the adv antage of b eing less res tr ictive than the most widely us ed r egional mo del, that is the Index Flo o d. Several case s tudies fro m F rench sites were analysed to illustrate the sup eriority of the Bayesian appro ach in compar ison to the tr a ditional Index Flo o d and to lo cal a pproaches. The influence o f the homogeneousnes s level o f the p o o ling group on quantile estimates was also considered. Results demonstra te tha t working with quite large and homogeneo us reg ions r a ther than small a nd strongly homogeneo us r egions is more efficient . F urther work can fo cus on the reg ional estimation of other characteris tics of the flo o d hydrograph. F or ins ta nce, a regio na l Bay esian mo del can fo cus on Flo o d Duration F requency . All sta tis tica l a nalysis w as carrie d out in the R Development Core T eam (2005) fr amework. F or this purp ose, t wo pack ages were contributed to this s oftw ar e under the framework of the pre sent resea r ch work. These t w o pack ages integrate the tools that were developed to car ry o ut the modelling e ffo r t presented in this pap er . The first one POT p erfo rms statistica l inference o n Peaks Over Thresholds , while the second one, RF A , co nt ains se veral to ols to carry out a Regional F req ue nc y Analy s is. These t wo pack a ges are av ailable, free of charge, at the web site ht tp://w ww.R- project.org , s e ction CRAN, Pac k ages. 13 Ac kn o wledgemen ts The a uthors wish to thank the DIREN Rhne-Alp es for providing da ta. The author s ar e also very gr ateful to the tw o r eferees for their co nstructive remar ks which improve the do cument. App endix A. Prop erties of the Index Flo o d on GP parameters W e provide in this app endix the pro of for the following theorem: Theorem 1. L et X b e a r andom variable GP distribute d. So X has the Cumulative D istribution F unction define d by: F ( x ) = 1 − 1 + ξ ( x − µ ) σ − 1 /ξ L et Y = C X wher e C ∈ R + ∗ . Then, Y is also GP distribute d with p ar ameters ( C µ, C σ , ξ ) . Pr o of. Let X be a r.v. GP dis tributed with parameter s ( µ, σ, ξ ) a nd Y = C X where C ∈ R + ∗ . Then: Pr [ Y ≤ y ] = Pr h X ≤ y C i = 1 − 1 + ξ y C − µ σ ! − 1 /ξ = 1 − 1 + ξ ( y − µC ) σ C − 1 /ξ So, Y is a ls o GP distributed with parameters ( µC, σ C , ξ ) . The pro of for the GEV case can b e es tablished in the same way . References M Acr e man a nd S Wiltshire. The regio ns ar e dead: Long live the r egions. In FR I END S , volume 187 , pages 1 75–1 8 8, W a s hington, DC, 1 989. In ternational Ass o ciation of Hydr ologica l Sciences,. A. Balkema a nd L. de Haa n. Residual life time at great age. Annals of Pr ob ability , 2:792 –804, 197 4 . D.H. Burn. Ev aluation of r e gional flo o d frequency analys is with a r egion of influence appro ach. Water R esour c es Rese ar ch , 2 6(10):225 7–22 65, 1 990. S. Coles. An Intr o duction to Statistic al Mo del ling of Extr eme V alues . Springer Series in Statistics. Springers Series in Statistics, London, 2001. S. Coles and L. Pericchi. Anticipating catastrophes thr ough extreme v alue mo de lling . J R oyal Statistic al So c C , 52(4):40 5 –416 , 2 003. S. Coles and J. T awn. A bay e s ian a nalysis of extreme rainfall da ta. J ournal of t he R oyal Statistic al So ciety. Series C: Applie d Statistics , 45(4):463 –478, 199 6 . M. Crowder. Bay esian prior s based on a parameter trans formation using the distribution function. Annals of the Ins titute of Statistic al Mathematics , 44 (3):405–4 16, 199 2. T. Dalrymple. Flo o d fre q uency analysis. U.S. Ge ol. Surv. Water Supply Pap. , 1543 A:–, 1960. P . Embrec hts, C. K l ¨ uppelb erg, and T. Mikosch. Mo del ling Extrema l Events for Insur anc e and Financ e . Springer, New Y ork, 1997. H. D. Fill and J. R. Stedinger . Using reg ional regr ession within index flo o d pr o cedures and an empirical bay es ia n estimator . Journal of H ydr olo gy , 210 (1-4):128 –145 , 199 8. R.A. Fisher and L.H. Tipp ett. Limiting forms of the frequency distribution of the la rgest or smallest mem b e r of a sa mple. In Cambridge Phil. So c. , volume 24 , 192 8. 14 S. Gabriele and N. Arnell. A hierar chical a pproach to r egional flo o d frequency analy sis. Water Resour c es R ese ar ch , 27(6):128 1–128 9, 19 91. GREHYS. Int er-compar ison o f regio na l flo od freq uency pro ce dur es for ca nadian rivers. Journ al of Hydr olo gy , 18 6(1-4):85 –103, 1 996. V. K. Gupta, O . J. Me s a, and D. R. Da wdy . Multisca ling theory of floo d p eak s : Regional qua n tile analysis. Water R esour c es R ese ar ch , 30(12):34 05–3 421, 1994 . M. J . Hall, A. W. Minns, and A. K . M. Ashrafuzzama n. The a pplication of data mining techniques for the r egionalisa tion o f hydrologica l v a riables. Hydr olo gy and Earth System Scienc es , 6(4):685 –694 , 20 02. J. R. M. Hosking and J . R. W allis. So me statistics useful in r egional frequency ana lysis. Water R esour c es R ese ar ch , 29(2):271 –281, 1 993. J. R. M. Hos king and J. R. W a llis. Re gional Fr e qu ency An alysis . Cambridge Universit y P ress, 1 997. R.W. Ka tz, M.B. Parlang e, a nd P . Nav ea u. Statistics o f ex tremes in hydrology . A dvanc es in Water R esour c es , 25(8-12 ):1287– 1304, 2 002. M. Lang, T. B. M. J. Ouarda , a nd B . B o b´ ee. T owards o p er ational guidelines for over-threshold mo deling. Journal of Hydr olo gy , 22 5(3-4):10 3–117 , 19 99. H. Mads en and D. Rosb jerg. Genera lized leas t squar e s and empirical bayes estimation in reg io nal partial duration series index -flo o d mo deling. W ater Reso ur c es R ese ar ch , 33(4):77 1–78 1 , 199 7. P .J . Northro p. Lik eliho o d-based a pproaches to flo o d fre q uency es timation. Journal of H ydr olo gy , 29 2 (1-4):96– 113, 2004 . E. Parent and J. Bernier. Enco ding prior exp er ts judgment s to improv e risk analys is o f extreme hydro- logical ev ents via po t mo deling . J ournal of Hydr olo gy , 2 83(1-4 ):1–18, 2003 . J. II I Pick ands. Sta tis tica l infer ence using extr eme order statistics. Annals of Statistics , 3:119– 131, 1975 . R Development Core T eam. R: A language and envir onment for statistic al c omputing . R F oundation for Statistical Co mputing, Vienna, Austria, 200 5. URL ht tp://w ww.R- project.org . ISBN 3-90 0051- 07-0. J. S. Robinson and M. Siv apalan. An inv estigation in to the physical causes of scaling and heterog e neit y of regiona l flo o d frequency . Water R esour c es R ese ar ch , 33(5):104 5–10 5 9, 1997 . A.J. Robson a nd D.W. Reed. Flo o d Estimation Handb o ok , volume 3 . Ins titute of Hydrolo gy , W allingford, 1999. C. Shu and D.H. Burn. Artificial neural net work ens emb les a nd their a pplication in p o oled flo o d frequency analysis. Water R esour c es R ese ar ch , 40(9), 2004. J.G. W ass on, A. Chandesris , H. Pella, and L. Blanc. Hydro - ecoreg io ns : a functional approa ch of r iver t yp ology for the eur op ean w ater framework dir ective. Ing ´ enieries - EA T - in fr en ch - , 40(3- 1 0), 20 04. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment