Mission impossible: Computing the network coding capacity region
One of the main theoretical motivations for the emerging area of network coding is the achievability of the max-flow/min-cut rate for single source multicast. This can exceed the rate achievable with routing alone, and is achievable with linear netwo…
Authors: Terence Chan, Alex Grant
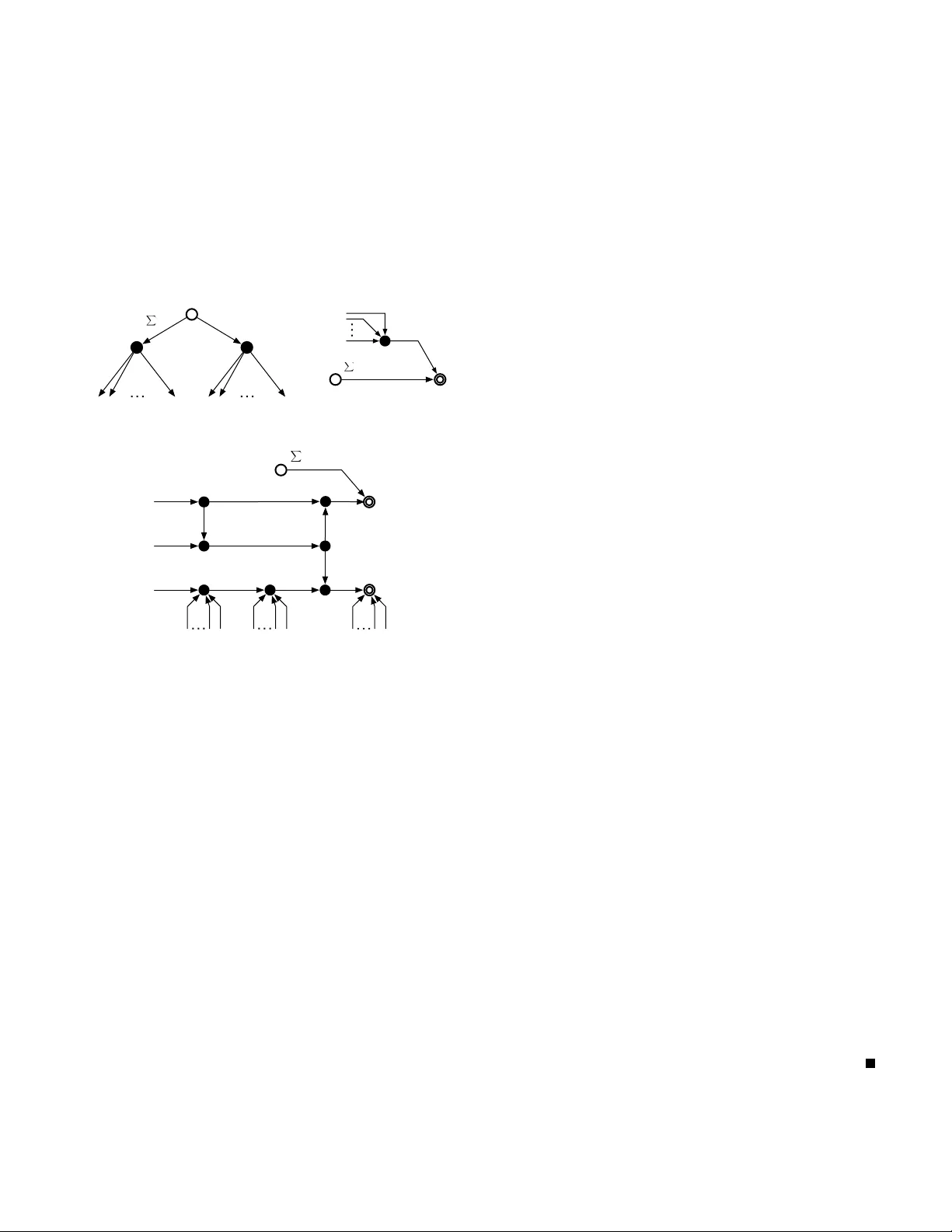
1 Mission impossible: Computing the network coding capacity re gion T erence Chan and Alex Grant Institute for T elecommunications Research Uni versity of South Australia, Australia { terence.chan, alex.grant } @unisa.edu.au Abstract — One of the main theoretical motiv ations f or the emerging area of network coding is the achievability of the max- flow/min-cut rate f or single source multicast. This can exceed the rate achievable with routing alone, and is achievable with linear network codes. The multi-source pr oblem is more complicated. Computation of its capacity region is equivalent to determination of the set of all entropy functions Γ ∗ , which is non-polyhedral. The aim of this paper is to demonstrate that this difficulty can arise even in single sour ce problems. In particular , f or single source networks with hierarchical sink requirements, and for single source networks with secrecy constraints. In both cases, we exhibit networks whose capacity regions in volve Γ ∗ . As in the multi-source case, linear codes ar e insufficient. I . I N T RO D U C T I O N Network coding [1], [2] generalizes routing by allowing in- termediate nodes to perform coding operations which combine receiv ed data packets. One of the most celebrated benefits of this approach is increased throughput in multicast scenarios. This stimulated much of the early research in the area. One fundamental problem in network coding is to understand the capacity region and the classes of codes that achieve capacity . In the single session multicast scenario, the problem is well understood. In particular , the capacity region is characterized by max-flo w/min-cut bounds and linear netw ork codes are sufficient to achie ve maximal throughput [2], [3]. Network coding not only yields a throughput advantage ov er routing, its capacity can be easily determined, and easily achiev ed. This is in stark contrast to routing, where computation of the capacity region and of optimal routes is fundamentally difficult. Significant practical and theoretical complications arise in more general multicast scenarios, in volving more than one session. An expression for the capacity region is known [4], howe ver it is giv en by the intersection of a set of hyperplanes (specified by the network topology and connection require- ment) and the set of entropy functions Γ ∗ . Unfortunately , this capacity re gion, or e ven the inner and outer bounds [5]– [7] cannot be computed in practice, due to the lack of an explicit characterization of the set of entropy functions for more than three random variables. This difficulty is not simply a consequence of the particular formulation of the capacity region given in [4]. It was recently shown that the problem of determining the capacity region for the multi-source problem is in fact entirely equi valent to the determination of ¯ Γ ∗ , the set of almost entropic functions [8]. Furthermore, the non-polyhedral nature of ¯ Γ ∗ , rev ealed in [9] implies a non- polyhedral capacity re gion (in contrast to the max-flo w result for single sources). T o make things even worse, it is also known that linear network codes are not sufficient for the multi-source problem [3], [8]. In this paper , we show that non-polyhedral capacity regions can occur even in single sour ce scenarios. W e demonstrate this phenomenon for single source networks with hierarchical sink constraints, and for single source networks with security constraints. Our approach is in the spirit of our recent work [8], which rev ealed a deep duality between network codes and entropy functions. Direct consequences are non-polyhedral capacity regions, the insufficiency of linear network codes and the importance of non-Shannon information inequalities. Section II pro vides the basic setup for secure network codes, and formally defines achiev ability and admissibility for networks with wiretapping adversaries. Section III focuses on the single source incremental multicast scenario, in which the sinks hav e hierarchical requirements. Given a function g , we construct an incremental multicast network that is solvable if and only if g is entropic. In Section IV we construct a special single source secure multicast problem which is equiv alent to an insecure multi-source multicast problem. In voking the du- ality results from [8] these constructions relate the solvability of both single-source incremental multicast and single source secure multicast, to multi-source multicast problems. I I . B A C K G RO U N D The network topology will be modeled by a directed acyclic graph G = ( P , E ) . V ertices u ∈ P correspond to communi- cation nodes and directed edges e ∈ E are error-free point- to-point communication links. The connection requir ement M , ( S , O , D ) is specified by three components. The set S index es the independent multicast sessions, each of which is a collection of packets to be multicast to a prescribed set of destinations. The session-source location mapping O : S 7→ P specifies the originating node O ( s ) for session s . The receiver - location mapping D : S 7→ 2 P indicates the set of nodes D ( s ) ⊆ P which require the data of session s . A network code is identified by a set of discrete random variables { T S , W E } , defined on finite sample spaces, where for concise notation, set-valued subscripts denote a set of objects index ed by the set, e.g. Z X = { Z i , i ∈ X } . The source random variables T s , s ∈ S are mutually independent and 2 are uniformly distributed on sample spaces whose size will be denoted | T s | . The variables W e , e ∈ E are the messages transmitted over link e . Since the network is acyclic, variables in T S and W E can be ancestrally ordered according to the network topology . Causal coding requires that edge messages are conditionally independent of their non-incident ancestral messages giv en their incident source and message v ariables. Definition 1: A network code is pr obabilistic if there exists an outgoing link message which is not a function of the incom- ing source and link messages. Otherwise, it is deterministic . Probabilistic network codes can be implemented via using independent random variables V u (internal randomness) at each node u ∈ P such that all outgoing messages from a node are deterministic functions of incoming sources and link messages and the independent randomness generated at the node. It is easy to prov e that all probabilistic network codes can be implemented in this way . Accordingly , we shall specify a probabilistic network code by the set { T S , W E , V P } . Lemma 1: Gi ven random v ariables X 1 , X 2 and V , if V is independent of X 1 and X 2 , and X 2 is a function of X 1 and V , then X 2 is a function of X 1 alone The implication of the lemma is as follo ws. At the sinks (or any intermediate node) of the network, if reconstruction of the source messages is possible, then it can also be achieved in the absence of “internal randomness”. In fact, in the absence of security constraints, it is kno wn that deterministic network codes are sufficient [6]. This is not always the case for the wiretapping scenarios considered in Section IV. In addition to legitimate sinks, there are |R| adversaries, which can ea vesdrop any message transmitted along a giv en collection of links. Each adversary attempts to reconstruct a particular set of source messages, according to a wiretapping pattern. Definition 2 (W ir etapping pattern): The wir etapping pat- tern is specified by a collection of tuples ( A r , B r ) for r ∈ R such that A r ⊆ S is the subset of sources to be reconstructed by adversary r , which observes only the links in B r . For a given network code designed with respect to a connection requirement M , define P e as the error probability that at least one recei ver fails to correctly reconstruct one or more of its requested source messages. A zer o-err or network code is one for which P e = 0 , and hence the source messages T S can be perfectly reconstructed at desired sinks. The goal of secure communications is to transmit information such that any ea vesdropper listening to the traf fic on all the links in B r remains “ignorant” of the data transmitted by the sources in A r . A perfectly secur e network code is one for which the information leakage I ( T A r ; W B r ) = 0 for all r ∈ R . Definition 3 (Admissible rate-capacity tuple): Gi ven a net- work G = ( P , E ) and a connection requirement M , a rate- capacity tuple ( λ, ω ) , ( λ S , ω E ) is admissible if there exists a perfectly secur e , zer o-err or network code Φ = { W f , f ∈ S ∪ E } , such that H ( W e ) ≤ log | w e | ≤ ω e , ∀ e ∈ E , H ( T s ) = log | w s | ≥ λ s , ∀ s ∈ S , where W e is the message symbol transmitted along link e and T s is the input symbol generated at source s . The preceding definitions consider zero-error network codes and perfect security . Relaxing these requirements prompts the following definition. Definition 4 (Achie vable): A rate-capacity tuple ( λ, ω ) is achie vable if there exists a sequence of network codes Φ ( n ) and normalizing constants r ( n ) > 0 such that lim n →∞ 1 r ( n ) H W ( n ) e ≤ lim n →∞ 1 r ( n ) log | w ( n ) e | ≤ ω e , ∀ e ∈ E , lim n →∞ 1 r ( n ) H T ( n ) s = lim n →∞ 1 r ( n ) log | w ( n ) s | ≥ λ s , ∀ s ∈ S , lim n →∞ P e Φ ( n ) = 0 , lim n →∞ 1 r ( n ) I ( T ( n ) A r ; W ( n ) B r ) = 0 , ∀ r ∈ R . In the absence of any security constraints, |R| = 0 , these definitions reduce to the usual ones and the multi-source, multi-sink capacity region is giv en by [4]. Bounds for the multi-source multi-sink scenario with wiretappers were giv en in [10]. I I I . I N C R E M E N T A L M U LT I C A S T In this section, we study a the special case of incremental multicast , meaning that the session indexes are totally ordered such that a receiv er requesting a particular session also re- quests all sessions with lower index. W e consider the simplest incremental multicast scenario, with only two source messages and no secrecy constraints (permitting deterministic codes). W e will show that determining the capacity region, ev en in such a simple scenario, can be no simpler than solving the general multicast problem. Our approach is inspired by [8]. Let H [ M ] ⊂ R 2 N with coordinates indexed by proper subsets of a ground set M with N elements. Points h ∈ H [ M ] can be regarded as functions, h : 2 M 7→ R with h ( ∅ ) , 0 . Given such an h ∈ H [ M ] we will construct a special network G † , an incremental connection requirement M † and a rate-capacity tuple T ( h ) that is admissible if and only if h is entropic. The network topology , connection requirement and link capacities are defined in Figure 1, which for con venience, is divided into several subnetworks. The single source node is an open circle, labelled with the two av ailable sessions (this node is repeated for con venience in Figures 1(a), 1(b) and 1(c)). The destinations are double circles, labelled with their requirements. Intermediate nodes are solid circles. The source and sink labels define the mappings O and D . Each capacitated edge is labeled with a pair of symbols denoting the edge capacity , and the edge message (and corresponding random variable). Unlabelled edges are assumed to be unca- pacitated, or to hav e a finite b ut suf ficiently large capacity to losslessly forward all receiv ed messages. The first part of the network, shown in Figure 1(a), contains the source where there are two independent sessions (i.e., two messages S 0 and S 1 ) available. The desired source rates asso- ciated with S 0 and S 1 are respectively P i ∈N h ( i ) and h ( N ) . There are 2 N specific edge messages that are of particular 3 interest. Rather than naming all edge variables W e , e ∈ E , we label these 2 N particular edge variables U j and V j for j = 1 , . . . , N . Remaining edge variables will be labelled with generic symbols W i index ed by an integer i . In Figure 1(a), the source node generates from S 0 and S 1 respectiv ely the sets of network coded messages { U 1 , U 2 , . . . , U N } and { V 1 , V 2 , . . . , V N } which are duplicated as required and forwarded to the rest of the network. The remainder of the network is di vided into subnetworks of two types, shown in Figures 1(b) and 1(c). h (2) , V 2 h (1) , V 1 h (1) , U 1 h (2) , U 2 h ( N ) , U N h ( N ) , V N ! i h ( i ) h ( N ) S 0 , S 1 (a) Source node V α { ! i ∈ N h ( i ) + h ( N ) − h ( α ) , W 2 h ( α ) , W 1 S 0 , S 1 S 0 , S 1 (b) T ype 1 subnetworks U i V α ! i ∈ N h ( i ) + h ( N ) − 2 h ( i ) V i h ( i ) h ( α , i ) − h ( α ) { { V i V α h ( i ) , W 1 h ( i ) , W 2 h ( i ) , W 3 { U j : j ! = i S 0 S 0 , S 1 S 0 , S 1 P 0 P 1 (c) T ype 2 subnetworks Fig. 1. The network G † . W ith reference to Figure 1(b), there are 2 N − 1 type 1 sub- networks, one for each nonempty α ∈ 2 N . These subnetworks introduce an edge of capacity h ( N ) − h ( α ) between the source and a sink requiring S 1 . There is an intermediate node which has another | α | incident edges (from Figure 1(a)), carrying V α = { V j , j ∈ α } . The intermediate node then has an edge of capacity h ( α ) to the sink. Figure 1(c) shows the structure of type 2 subnetworks, which are index ed by ∅ 6 = α ⊂ N and an element i ∈ N , i 6∈ α . Each type 2 subnetwork connects the source to the upper receiv er . In addition, there are other incident edges carrying { V j : j ∈ α } and { U j : j ∈ N } . For notational simplicity , we hav e written h ( α ∪ { i } ) , h ( α, i ) . So far , we ha ve described a network G † , a connection requirement M † and hav e assigned rates to sources and capacities to links. Clearly M † depends only on N , and not in any other way on h . Similarly , the topology of the network G † depends only on N . The choice of h affects only the source rates and edge capacities, which are collected into the rate- capacity tuple T ( h ) . Also, we can assume without loss of generality that T ( h ) is a linear function of h . Definition 5: A function h ∈ H [ N ] is called entr opic if there exists discrete random v ariables X 1 , . . . , X N such that the entropy of { X i : i ∈ α } is equal to h ( α ) for all ∅ 6 = α ⊆ N . Furthermore, h is called quasi-uniform if any subset of the variables are uniform over their support. Theor em 1: For the network G † and a connection require- ment M † , if a rate-capacity tuple T ( h ) is admissible, then h is quasi-uniform and hence entropic. Pr oof: Suppose that T ( h ) is admissible. By Definition 3, admissibility of T ( h ) on G † , M † requires the existence of a zero-error network code Φ with source messages S [ α ] , ∅ 6 = α ⊆ N and a subset of its coded messages U N and V N . Given this hypothesis, we will show that h is the entropy function of V N , and that V N is quasi-uniform. First focus on Figure 1(a). Applying min-cut bounds, it is straightforward to prov e H ( U N , V N ) = X i ∈N H ( U i ) + H ( V N ) , H ( U i ) = h ( i ) , ∀ i ∈ N , H ( V N ) = h ( N ) . H ( V i ) = h ( i ) , ∀ i ∈ N . Similarly , applying min-cut bounds to type 1 subnetworks of Figure 1(b), H ( V α ) ≥ h ( α ) , ∅ 6 = α ⊆ N . W e now focus on type 2 subnetworks of Figure 1(c) and aim to prove that H ( V α ) ≤ h ( α ) for any ∅ 6 = α ⊆ N . In order for the upper receiv er to reconstruct S 0 and S 1 , H ( W 1 , W 2 ) + h ( N ) + X j 6 = i h ( j ) − 2 h ( i ) ≥ H ( S 0 , S 1 ) or equiv alently , H ( W 1 , W 2 ) ≥ 2 h ( i ) . In addition, H ( W 1 , W 2 ) ≤ H ( U i , V i , W 1 , W 2 ) = H ( U i , V i ) ≤ 2 h ( i ) . As a result, H ( W 1 , W 2 ) = H ( U i , V i , W 1 , W 2 ) which further implies that V i is a function of W 1 , W 2 . Thus V i can be recov ered at P 0 . On the other hand, from the lo wer part of the subnetwork, H ( U i | W 3 ) = H ( U i | W 3 , U j , j 6 = i ) + I ( U i ; U j , j 6 = i | W 3 ) ( a ) = I ( U i ; U j , j 6 = i | W 3 ) ≤ I ( U i , W 3 ; U j , j 6 = i ) = 0 where ( a ) follo ws from the fact that S 0 can be reconstructed at the lower receiv er . This implies that U i can be reconstructed at P 1 . From [8], that P 0 can decode V i and that P 1 can decode U i further implies H ( V i | V α ) = h ( α, i ) − h ( α ) . By mathematical induction (similar to the proof of [8, Theorem 1]), the only solution that satisfies all of the conditions abov e is when the entropy function of V N is equal to h . Finally , from type 1 subnetworks, the support of V α is at most 2 h ( α ) . Hence, V α is indeed quasi-uniform (this also implies that the U i are quasi-uniform, via H ( U i ) = H ( V i ) = h ( i ) and the independence of the U i ). Theor em 2 (Con verse): For the network G † and a connec- tion requirement M † , a rate-capacity tuple T ( h ) is admissible if h is quasi-uniform. From Theorems 1 and 2, we can follow the approach in [8] and easily extend the result to almost entropic functions. 4 Theor em 3: For the network G † and a connection require- ment M † , a rate-capacity tuple T ( h ) is achiev able if and only if h is almost entropic 1 . I V . S E C U R E M U LT I C A S T Linear network codes (for single source multicast) that are resilient to eavesdropping are considered in [11]. Sufficient conditions for the existence of such codes was also deri ved. This was further generalized in [12] to multi-source cases. A similar result was also obtained in [13] which giv es necessary and sufficient conditions under which transmitted data are safe from being rev ealed to eav esdroppers. All of the above- cited works assume that the wiretapper aims to reconstruct all sources. Similar results hav e been obtained where only a subset of sources are to be reconstructed [14]. Inner and outer bounds to the secure capacity re gion were giv en in [10]. W e will now show that even for a simple single-session secure multicast problem, determination of the capacity region can be extremely hard. In particular, the problem is at least as hard as any multi-source multi-session multicast problem. Figure 2 shows the construction for a network G ? . The source message is X whose rate is d . The link capacities are parametrized by 0 < c < d . There is a single eav esdropper who only observes the message variable W 3 . Thus Figure 2 also specifies M ? , and the wiretapping pattern A ? , B ? . X c, W 1 c, K c, W 3 c, W 4 c, W 5 d − c, W 2 X P 0 P 1 Fig. 2. The network G ? . Pr oposition 1: Giv en network G ? and connection (and se- crecy) requirement M ? depicted in Figure 2, if a rate-capacity tuple T ( h ) is admissible then K is a function of W 4 . Pr oof: From the capacity constraint on G ? , we hav e H ( W 1 , W 2 ) ≤ H ( W 1 ) + H ( W 2 ) = c + d − c = H ( X ) . T ogether with the decodability requirement, H ( X | W 1 , W 2 ) = 0 , we hav e H ( W 1 , W 2 ) = H ( W 1 ) + H ( W 2 ) H ( W 1 , W 2 | X ) = 0 H ( W 1 , W 2 ) = H ( X ) H ( W 1 ) = c H ( W 2 ) = d − c. 1 A function h is almost entropic if it is the limit of a sequence of entropic functions. Applying a min-cut bound on the set of edge variables { W 2 , W 5 } , we can also prove that H ( W 5 ) = c and H ( W 5 | X ) = 0 . On the other hand, the secrecy constraint requires I ( W 3 ; X ) = 0 and hence I ( W 1 ; W 3 ) = 0 (1) as W 1 is a function of X . Now , we will sho w that H ( W 1 | W 3 , W 4 ) = 0 . First, I ( W 3 , W 4 ; X ) ( a ) = I ( W 3 , W 4 ; W 1 , X ) = I ( W 3 , W 4 ; W 1 ) + I ( W 3 , W 4 ; X | W 1 ) ( b ) = I ( W 3 , W 4 ; W 1 ) where (a) follows from the fact that W 1 is a function of X and (b) follows from the conditional independence implied by the underlying network topology . Using the same argument, we can also prove that I ( K , W 3 ; X ) = I ( K , W 3 ; W 1 ) . Since W 5 is a function of X and is thus independent of internal randomness, Lemma 1 implies that H ( W 5 | W 3 , W 4 ) = 0 . T ogether with H ( W 5 ) = c , we hav e I ( W 3 , W 4 ; W 1 ) = I ( W 3 , W 4 ; X ) ≥ I ( W 3 , W 4 ; W 5 ) = H ( W 5 ) = c. Since H ( W 1 ) = c , it implies that H ( W 1 | W 3 , W 4 ) = 0 or equiv alently that W 1 is a function of W 3 and W 4 . Sim- ilarly , using the same argument, we can also prove that H ( W 1 | K, W 3 ) = 0 . Our final aim is to show that H ( K ) = H ( W 4 ) = c and H ( K , W 4 ) = 2 c . Clearly , both H ( K ) and H ( W 4 ) are bounded above by c due to the edge capacity constraint. W e obtain a lower bound on the entropy of K as follows. H ( K ) ≥ I ( K ; W 1 | W 3 ) = I ( K ; W 1 | W 3 ) + H ( W 1 | K, W 3 ) = H ( W 1 | W 3 ) ( a ) = H ( W 1 ) = c where (a) follows from (1). Hence, H ( K ) = c . And similarly , we can also prove that H ( W 4 ) = c . Independence of W 1 and W 3 implies H ( K | W 1 , W 3 ) = H ( W 1 , K , W 3 ) − H ( W 1 , W 3 ) = H ( K, W 3 ) − H ( W 1 , W 3 ) = H ( K, W 3 ) − H ( W 1 ) − H ( W 3 ) ( a ) = H ( W 3 | K ) − H ( W 3 ) ≤ 0 , where (a) follows from H ( W 1 ) = H ( K ) = c . Consequently , H ( K | W 1 , W 3 ) = 0 . Similarly , H ( W 4 | W 1 , W 3 ) = 0 . Finally , 2 c ≥ H ( W 1 , W 3 ) = H ( W 1 , K , W 3 , W 4 ) ≥ H ( W 1 , K , W 4 ) ( a ) = H ( W 1 ) + H ( K, W 4 ) ≥ 2 c 5 where (a) follows from independence of W 1 and ( K , W 4 ) . Hence, H ( K , W 4 ) = c which further implies H ( K | W 4 ) = H ( W 4 | K ) = 0 . Under a regularity condition (that 2 c and 2 d are integers), the conv erse of Proposition 1 also holds. Pr oposition 2 (Conver se): For the network G ? with connec- tion (and secrecy) requirement M ? , the specified rate-capacity tuple is admissible if a secret key of a rate c can be transmitted from the node P 0 to P 1 . Essentially , Propositions 1 and 2 suggest that the admissi- bility of the single source secure multicast problem depends on communication of a secret key from P 0 to P 1 . Adhering sev eral copies of G ? together (see Figure 3), we can easily generalize the network such that admissibility implies that multiple secret keys must be transmitted across a network. This turns the single source secure multicast problem into a multi-source multicast. Theor em 4: For any multicast problem (without secrec y constraints), there exists a corresponding secure multicast problem such that the multicast problem is admissible if and only if the corresponding secure multicast problem is also admissible. Consequently , using the single-source two sessions network G † and a connection requirement M † , there exists a secure multicast problem such that a rate capacity tuple T ( h ) is achiev able if and only if h is almost entropic. X wiretapped K 1 K 2 K 1 K 2 wiretapped Fig. 3. Sev eral copies of G ? . V . I M P L I C AT I O N S A N D C O N C L U S I O N Theorems 3 and 4 show that e ven for a single-source network multicast problem with two independent sets of messages or for a single source secure multicast problem, the determination of the set of achiev able rate-capacity tuples can be extremely hard. Following the same arguments as used in [8], we can also prove the following results for a single- source two-session multicast problem or for a single-source single-session multicast problem with secrecy constraints: 1) Capacity regions are not polyhedral 2 in general. 2) LP bounds are not tight in general. 3) Linear codes are not sufficient to achieve capacity . In other words, finding capacity regions for (secure) multicast problems seems to be a mission impossible. Not only are the 2 That the single-source single-session secure multicast problem has a non- polyhedral capacity region is somewhat surprising, since the region for the same problem without the secrecy constraint is completely determined by the min-cut bound existing bounding techniques loose, the non-polyhedral nature of the capacity region suggests that LP bounds cannot fully characterize the region, even with the addition of more and more newly discovered information inequalities. Any finite set of such new inequalities can only further tighter the bound, but can never yield the exact capacity region. Despite the hardness of the problem, there are still many questions to be answered. It is unclear what makes finding the capacity region problem so difficult. In the case of a single session multicast or the case where there are only two sinks, capacity regions have explicit polyhedral charac- terizations provided by min-cut bounds. On the other hand, where there are many sinks, the capacity region can be extremely complicated to characterize, even if there are only two independent sessions. It will be of great importance to classify the set of networks and connection requirements that lead to polyhedral capacity regions characterized by min-cut bounds or LP bounds. R E F E R E N C E S [1] R. Ahlswede, N. Cai, S.-Y . R. Li, and R. W . Y eung, “Network informa- tion flow , ” IEEE T rans. Inform. Theory , vol. 46, no. 4, pp. 1204–1216, July 2000. [2] S.-Y . R. Li, R. Y eung, and N. Cai, “Linear network coding, ” IEEE T rans. Inform. Theory , vol. 49, no. 2, pp. 371–381, Feb . 2003. [3] R. Dougherty , C. Freiling, and K. Zeger , “Insufficiency of linear coding in network information flow , ” IEEE T rans. Inform. Theory , vol. 51, no. 8, pp. 2745–2759, Aug. 2005. [4] X. Y an, R. Y eung, and Z. Zhang, “The capacity region for multi-source multi-sink network coding, ” in IEEE Int. Symp. Inform. Theory , Nice, France, 2007, pp. 116–120. [5] L. Song, R. W . Y eung, and N. Cai, “Zero-error network coding for acyclic networks, ” IEEE T rans. Inform. Theory , vol. 49, no. 12, pp. 3129–3139, Dec. 2003. [6] R. W . Y eung, A F irst Course in Information Theory , ser . Information T echnology: Transmission, Processing and Storage. New Y ork: Kluwer Academic/Plenum Publishers, 2002. [7] R. W . Y eung, S.-Y . R. Li, N. Cai, and Z. Zhang, Network Coding The- ory , ser . Foundations and Trends in Communications and Information Theory . Now Publishers, 2006. [8] T . Chan and A. Grant, “Dualities between entropy functions and network codes, ” submitted to IEEE Trans. Inform. Theory . [Online]. A vailable: http://arxiv .org/abs/0708.4328v1 [9] F . Matus, “Infinitely many information inequalities, ” in IEEE Int. Symp. Inform. Theory , Nice, France, 2007, pp. 24–29. [10] T . H. Chan and A. Grant, “Capacity bounds for secure network coding, ” 2008, submitted to Australian Communications Theory W orkshop. [11] N. Cai and R. Y eung, “Secure network coding, ” in IEEE Int. Symp. Inform. Theory , 2002. [12] N. Cai and R. W . Y eung, “ A security condition for multi-source linear network coding, ” in IEEE Int. Symp. Inform. Theory , 2007. [13] J. Feldman, T . Malkin, C. Stein, and R. Servedio, “On the capacity of secure network coding, ” in 42nd Annual Allerton Confer ence on Communication, Contr ol, and Computing , 2004. [14] K. Bhattad and K. Narayanan, “W eakly secure network coding, ” in W orkshop on Network Coding, Theory , and Applications , 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment