Set-based complexity and biological information
It is not obvious what fraction of all the potential information residing in the molecules and structures of living systems is significant or meaningful to the system. Sets of random sequences or identically repeated sequences, for example, would be …
Authors: David J. Galas, Matti Nykter, Gregory W. Carter
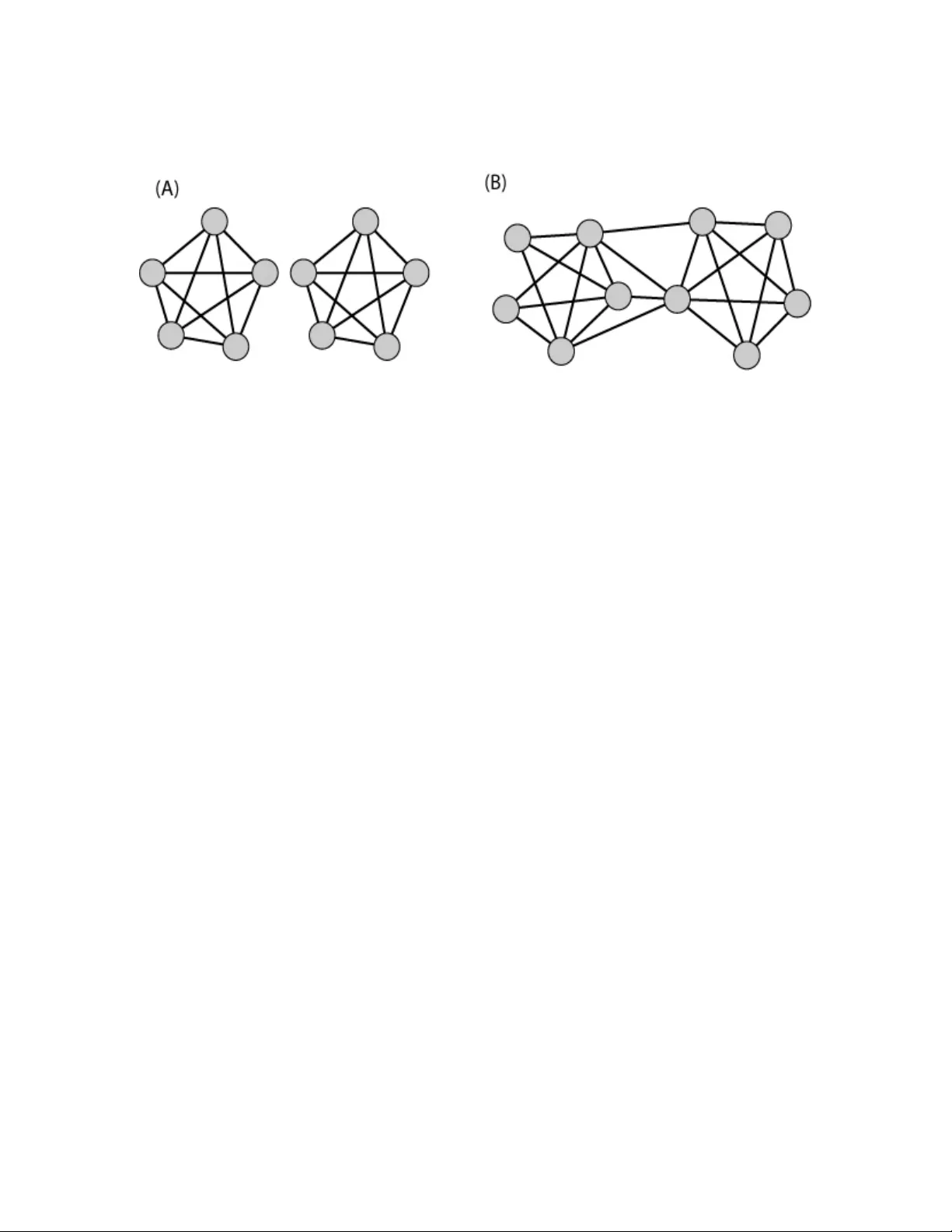
Bio-Informatio n Galas et al 1/11/2008 1 Set-based Complexity and Biological Inform ation David J. Galas* 1,2 , Matti Nykter 1,3 , Gregory W. Carter 1 , Nathan D. Price 1+ and I lya Shmulevich 1 1 Institute for System s Biology, Seattle, WA, USA 2 Battelle Memorial Institute, Colum bus, OH, USA 3 Institute of Signal Processing, Tam pere University of Technology, Tampere, Finland Summary It is not obvious what fraction of all the potential information r esiding in the molecules and structures of li ving systems is si gnificant or m eaningful to t he system. Sets of random sequences or i denticall y repeated sequences, for ex ample, would be expected to contribute little or no use ful information to a cell. This issue of quantitation of information is important sin ce the ebb and flow of biolog icall y significant information is essential to our quantitative understandin g of biological function and evolution. Motivated specifically by these problems of biological information, we propose here a class of m easures to quantify the contextual nature of the information i n sets of obj ects, based o n Kolmogorov’s intrinsic co mplex ity. Such measures discount both random and redundant information and are i nherent in that they do not require a defined state s pace to quantif y the inform ation. The maximization of this new measure, which can be formulated in terms of t he universal information distance, appears t o hav e several us eful and in teresting properties, some of whic h we illustrate with examp les. * Correspond ing author, dgalas@system sbiolog y.org or galasd@b attelle.org + Current Add ress : Departmen t of Che mical and B iomolecular Engineerin g & Institute for Geno mic Biology, U niversit y of Illinois, Urb ana-Cha mpaign Bio-Informatio n Galas et al 1/11/2008 2 Introduction A living system is distinguished from most of its non- living counter parts by its storage and transmission of information. It is this biological inform ation that is the key to biological function. It is also at the heart of the conceptual basis of systems biology . Bio-information resides in digital sequences in molecules like DNA and RNA, 3-dimensional structures, chem ical modifications, chemical activities, both of small molecules and enzymes, and i n other components and properties of biological systems, but depends critically on how ea ch unit interacts with, and is related to, other components of the system. Biological information is therefore inherently context- dependent which raises significant i ssues concern ing its qu antitative m easure and re presentation. An important i ssue fo r the effective theoretic al treatment of biolog ical sy stems is : how can context-dependent information be usefully represent ed and measured? This is important both to the understanding of the storage and flow of information that occurs in the functioning of biological systems and in ev olution. There have been several attempts to address this pr oblem for biological com plexity. Gell-Mann has stat ed one part of the que stion clearly and sugg ested an approach t o answering it [1, 2]. Standish has also suggested that context-dependence is a critical problem for the understanding of complexity i n g eneral and has discussed a lgorithmic complexity a nd the invocation of context in terms of uni versal Turing machines as an approach to its solution [3]. Adami and Cerf have formulated a solution to t heir particular formulation of the problem for macromolecular sequences by de fining an imaginary e nsemble of sequences and appending to t hat the cont ext for interpretation as an explicit set of constraints as to which p ositions are conserved and which are “random” [4]. There have als o been attem pts to grapple with the i ssue of structural com plexity, related to the problem defined here: most notably the idea of “therm odynamic depth” of Loyd and Pagels [5], and the i dea of “ca usal states” of Crutchfield and Shalizi [6]. We take a di fferent approach here, which is t o deal directly with the complexity of sets of bit-strings. This provides a general approach t o c ontext dependence, which sh ould be ap plicable to m any pr oblems t hat depend o n the c omplexity o f a system, and pr ovide computational t ools applicable to real biological problems. We find that the direct approaches provided by t he powerful concepts of intrinsic complexity pioneered by K olmog orov [7], Chaitin [8], and Solomonoff [9, 10], and extended by Li, V itanyi, G acs and o thers [11 -14] can be applied to this problem in a particularly simple way. Furthermore, the construct of an inform ation manifold derived from the demonstration of a well- defined metric, an “information dist ance” [11, 13], lends itself well to a Bio-Informatio n Galas et al 1/11/2008 3 class of set-based information m easures, including mutual i nformation, and i lluminates its meaning. Multiple types of information can be r epresented by bit -strings. Shannon information [15], devised to deal with co mmunications channels, is defined i n ter ms of the ensemble of all possible messages or bit strings (a state s pace), a f undamentally probabilistic d efinition which is related to physical entropy. Kolmogorov-Chaitin-Solom onoff (K CS) information ( we use the terms “information” a nd “complexity” interchangeably her e), on the o ther hand, is intrinsic to the object. It i s based fundamentally on the difficulty of describing the object – t he more difficult it is to describe by a computational process, t he m ore i nformation is present [ 16]. In the K CS conception the definition of the information in a bit string is the length of the shortest computer program ( on a universal Turing machine) whose output is this bit string. This definition, often called “Algorithmic Information Content” (AIC), while elegant, and conceptually powerful, is not computable. I t has become cl ear, however, that compression algorithm s can be use d to estim ate the K CS information in a bit string in several ways [ 11, 17] - the maximum p ossible c ompression gives the best estimate for the KCS information of a bit string , which can be estimated by a suitable compression algorithm (like the lossless Lempel-Ziv or Kieffer-Yang algorithms.) This idea, which is a practical implementation of the abstract idea of “Computable Information Content” (CIC), enables the practical use of KCS co mplexity. T his alternative to probabilistic, statistical a pproaches allows c onsideration of inform ation absen t any knowledge of the ensemble of all possibilities from whi ch the object is drawn, knowledge which is often i mpractical and presents a number of difficulties in biology. It is problematic when considering sequ ences of macromolecules in that the state space is usually defined by a construct of questionable significance, like “the e nsemble of all possible sequences” or “all possible functional mutant forms of a protein sequence” [4]. This powerful id ea of the “ intrinsic complexity” o f a string, in contrast to a pr obability- based measure, is t he hallmark of the Kolmogorov or KCS complexity. Whenever the sample space and probabilities are well defined, useful calculatio ns can be done using Shannon information, b ut this is often not the case in b iology. Another advantage of t he KCS information is that it c an be viewed as an absolute and objective quantification of the information in a specific string or o bject. Absolute information content of individual objects, rather than the average information to communicate objects produced by a random source (the key concept of Shannon inform ation theory) is clearly preferable. Bio-Informatio n Galas et al 1/11/2008 4 From what we know of biological function at the molecular l evel, t he interactive, highly connected networks wit h systems-like behaviors suggest to us that any measures that don’t take this k ind o f context i nto account will be less than us eful in accounting for biolo gical information content. Protein-protein interaction networks, metabolic networks and gene regulatory networks are examples of the remarkable complexity of biological networks, and indicative of the importance of context. It is useful t o approach t he context question, however, by considering two “paradoxes” that illuminate t he problem of inf ormation in biology. A “rando m” bit string, r , has maximum KCS complexity, and therefore contains the most information, for a st ring of this length. Another way of looking at the information in a random string, though this is a difficult issue [12, 14], i s that by definition i t is “ incompressible” and can only be repre sented by a string of approximately it s own leng th, L(r) ; i.e . for a minimal description C(r), L(C(r)) ≈ L(r). Th e proper definition of “randomness” act ually makes use of t his notion [18]. In s pite of this way of measuring information content, a random s equence, however, is devoid of useful i nformation. This is a problem that Kolm ogorov grappled with and responded by defining his structure function (attribution in [19].) A random sequence has essentially no biological information (e.g. a random protein sequence has essentially no functional use) - the cell containing this sequence is therefore not more complex than the one without it, and we should be counting its contribution to the complexity of the set of information in the c ell as zero. Gi bberish doesn’t help with any biological process, to paraphrase Gel l-Mann [2]. This is the first “paradox”. Consider on the other hand, adding not a r andom s equence bu t on e that exactly matches a sequence that already exists in the set. Using a context- free measure, that does not consider the other content of the se t, thi s should add an am ount of inf ormation equal to the existing sequence that it matches. The duplic ation of existing information in t he set (e.g. like the exact dupli cation of a gene) adds less new infor mation t o the set than the original, duplicated bit string, howev er. This is the second “paradox”, though i t seems a weaker one. A good measure of information should therefore disc ount the addition of either random or pre- existing inform ation to resolve these paradox-like conflicts. Bot h are dependent on t he relationship of t he information to other i nformation in the cell. Since biological function depends on relationships within the system, a measure of complexity, and a good definition of biological information, must account for r elationships and context. Our approach to the problem of biological i nformation, therefore, will b e to c onstruct a measure of information in a set of bi t strings, since this is general enough to d eal with most problem s. Bio-Informatio n Galas et al 1/11/2008 5 Consider then an unordered set of N bit- strings, { } N i x S i ,... 1 , = = . The information in each of the strings individually may b e described as KCS inf ormation or co mplexity, K(x i ) . Our biological measure of information must also reflect, however, the relationships to other string s in the set because there is som e shared information t hat de termines “function”. For example, ther e is some i nformation in the st ructure and sequen ce of one protein in the structure and sequence of any protein that interacts with it. Taking all i nteractions and structures into account, therefore, a protein interaction network is remarkably rich in information. There is also i nform ation about a metabolic pathway in an e nzyme that catalyz es a reaction in the pathway and is coupled t o it by product inhibition, or affected by the binding of ot her proteins. There are many other examples of bi ological context that contain information. Our challenge is t o quantify i t in a use ful way. The relationship between strings, then, is what we characterize to begin tackling the b iological information problem. Context-dependent Information Measures A use ful m easure of information in one string, since it must in clude co ntributions from the oth er strings i n the set, must be a f unction of the e ntire set. With t his in mind we can approach the problem by defining a meas ure with a number of propert ies that we can specify. 1. A random string adds zero information to the set. 2. An exactly duplicated string adds little or nothing to the overall inform ation in the set. 3. The measure includes the i nformation content of the st rings indi vidually as well as the information contained in the relationships wi th other mem bers of the set. The second criterion is i mprecise, but important, and one t hat we will return to discuss in more detail. T he simplest and most direct measure of t he information in a set might be the simple sum of the information in the in dividual bit-strings. ∑ = ≡ Θ N i i x K 1 ) ( (1) Clearly, this measure fails to s atisfy o ur criteria and d oes not have any of the desired pr operties. We ca n, however, modify th e definition in a si mple way . T he contribution o f each string, x i , is modified by a f unction, F i , that depends on t he entire set , and is th erefore inherently context- dependent: Bio-Informatio n Galas et al 1/11/2008 6 Ψ ( S ) ≡ K ( x i ) i = 1 N ∑ F i ( S ) . (2) If F i =1 for all i=1,….N, then Ψ reverts to Θ and t here is no context dependence, but if we take into account the dependence of F i o n the relationships between the i th string and the others in t he set we can construct a function t hat satisfies t he three criteria abov e. Before we make th at construction we need to introd uce another useful measure. The informational relationship between strings has been well studied and a particularly useful measure exits, that of “universal information distance”. We consi der t his function over the pairs of mem bers of the set in t he next section. Universal Information Distance and Se t Information A normalized inf ormation di stance function between two s trings, x a nd y has been de fined by Li, Vitanyi et al . [11]. It has been shown to define a metric i n that it sati sfies the three criteria: identity, the triangle inequality , and symm etry. This normalized distance m easure d ( x , y ) ≡ max( K ( x | y ), K ( y | x )) max( K ( x ), K ( y )) (3) takes values in [0,1] . For a set of strings the metric defines a space with a maximum distance of 1 between strings i n all di mensions – in general a set of N strings determines an ( 1 − N )- dimensional space. A non-normalized i nformation distance, defining a metric had been previously p roposed by B ennett et al. [13], but for reasons articulated in [11], including t he diverse lengths of strings o f potential interest, is inadequate for most strings of interest to us. T he normalized i nformation distance is a powerful measure of similarity in that, as Li , Vitanyi a nd colleagues have shown, it i s truly universal as it discovers all c omputable similarities between strings [11]. We can use the important “additivity of complexit y” pr operty which was proved (in a difficult proof) by Gacs [14]: ) | ( ) ( ) | ( ) ( ) , ( * * y x K y K x y K x K y x K + = + = (where the equal sign means “to within a n additive constant ” in this equation, and K(x,y) is the joint K olmogorov complexity of x and y ) to rewrite eqn. 3 as Bio-Informatio n Galas et al 1/11/2008 7 )) ( ), ( max( )) ( ), ( min( ) , ( ) , ( y K x K y K x K y x K y x d − = . (4) The s y mbol y * indicates the shortest program that gener ates y , which then gives us the additiv e cons tant r elatio n. If we si mpl y use the string y itsel f, th e eq uali ty is true t o within “logarithm ic term s” [1 4, 20, 2 1]. Th e difference i s cruci al for som e appl ication s, but is not im portan t in the us e we mak e of th e rela tion. Since the complexity of a finite string is a finite we can order the string s in the set by increasing complexity, and index them such that if i >j then ) ( ) ( j i x K x K ≥ . Thus, since the joint complexity is symm etric, we have < = − > = − = j i if x K x x K x K x K x x K j i if x K x x K x K x K x x K x x d j i j j i j i i j i i j j i j i ) ( ) | ( ) ( ) ( ) , ( ) ( ) | ( ) ( ) ( ) , ( ) , ( (5) The average distance betwe en pairs of strings in the set, for exam ple, can be calculated from the sum: ∑ ∑ ∑ < > + = j i j i j j i i j i j i j i x K x x K x K x x K x x d ) ( ) | ( ) ( ) | ( ) , ( , (the larger K is always in the denom inator, and we ignore i=j since d(x i ,x i )= 0). Using the symmetry of d evident in the above exp ression the average can now be wri tten as d S = 2 N ( N − 1 ) K ( x i | x j ) K ( x i ) i > j ∑ (6) A si milar expression, the “c omplexity-w eighted” average distance, Λ S , reduces to a simple expression since, in a set ordered by increasing complexity, we have a very simple expression for the conditional complexity, K ( x i | x j ) = d ( x i , x j ) K ( x i ) , ∀ i > j . Thus Bio-Informatio n Galas et al 1/11/2008 8 ∑ ∑ = − = − ≡ Λ pairs j i j i pairs j i i S x x K x x K N N x x d x K N N ) | ( ) | ( ) 1 ( 2 ) , ( ) ( ) 1 ( 2 (7) The average conditional com plexity over the set is thus equal to the “com plexity-weighted” average distance. The conditional complexity of each pair of strings i s the larger of the complexities of the two times the di stance between the strings in this space . Set Complexity We turn now to the three criteria that must be satisfied for a f unction of the set, F i (S), described in eqn. 2. The first criterion is satisfied if a r andom bit string, x i , added to the set S makes F i (S) = 0. If in doing this we ens ure that F i (S) depends on the e ntire set then criterion 3 is also sa tisfied. These two criteria can be f ulfilled by expressing F i (S) i n terms of the universal i nform ation distance, which leads to a simple defi nition of set complexity. Clearly, if a bit string x i is random, then (for a sufficiently long string) the distance in the information m anifold from any string is just 1, the maximal distance. T hus, criterion num ber 1 can be met in general by an y expression that includes a sum over the ent ire set: ) ( ) ( ) ( ∑ = j ij i i i i d f x S G x S F U U (8) (the choice of a summ ation i s somewhat ar bitrary her e) where G is a ny positive finite function over s ets of bit strings, d ij i s shorthand for d(x i ,x j ), and f (x) is a function of th e pair- wise universal distances, positive i n (0,1), with a z ero at x =1 . The zero at the m aximum di stance is k ey. T his relationship applies to any set , S . Criterion number 2, however, is a s omewhat loose constraint. Let’s consider it f irst by the c ase of adding an id entical string to a set that consists of all identical bit s trings o nly. For su ch a set, S, t hen, the condition can be satisfied exactly if we use the summation in a similar way ∑ = j ij i i i i d g x S G x S F ) ( ) ( ) ( U U (9) where G is any finite f unction of the set, and g(x) has a zero at x =0. W hat this constraint means for an arbitrary set (not only t he set of all identical strings) is that the i ncrease in complexity of the set saturates as the number of i dentical bit strings increases (it does not continue to increase Bio-Informatio n Galas et al 1/11/2008 9 with the size of the set.) We c an now define the se t complexity, Ψ , in term s of the above functions f a nd g that satisfy all t hree criteria. We s imply s et G = 2/( N - 1) for normalization, an d multiply f and g to get ∑ ∑ = − = Ψ N i pairs ij ij i d g d f N N x K S 1 ) ( ) ( ) 1 ( 2 ) ( ) ( (10a) and since the simplest functions t hat satisfy these criteria are ) 1 ( ) ( d d f − = and d d g = ) ( , we can appeal to parsimony and define the correspondingly simplest expression for set complexity: ( ) ∑ ∑ − − = = Ψ = pairs ij ij i N i i i d d N N S F S F x K S 1 ) 1 ( 2 ) ( where , ) ( ) ( ) ( 1 (10b) where the sum ov er pairs is consistent with the ordering of the set. Finally, we c an generalize this function, call it Π , to any th at have zeros at 0 and 1 so that it satisfies all the criteria we speci fied: α β β α α β β α αβ β + = ∞ = ∞ = − = − − − = Π ∑ ∑ ∑ ∑ n ij n ij ij pairs ij ij i d n d d d d a N N S ) ( ) 1 ( ) 1 ( ) 1 ( 2 ) ( 0 1 1 (11) This is a context- dependent measure of set complexity which we will consider in this paper onl y in its sim plest form: eqn 10b. In addit ion to this form there a re other simple ones such as ij ij d d ln , or ) 1 ln ( ) 1 ( ij i j d d − − . Relationship to Mutual Infor mation The idea of mutual information is a central concept in understanding the sharing of inf ormation between two objects, in our case bit strings. Mutual inf ormation quantifies the inf ormation in string y about string x , and is symmetric. These properties can be defined in both algorithmic Bio-Informatio n Galas et al 1/11/2008 10 (individual) and probabilistic terms [ 21], and the algorithmic concept represents a significant sharpening of the probabilistic notion. T he mutual information, I , between two strings, x and y , can be defined in ter ms of complexity in the no tation of Gacs et al. [21], using the additivity relation (see first section). ) , ( ) ( ) ( ) | ( ) ( ) : ( * y x K y K x K y x K x K y x I − + = − = (12) (the second equality is again within an add itive constant, and the symm etry has this character as well) Since the distance betw een x and y , if K(x)>K(y) , can be written a s ) ( ) | ( ) , ( x K y x K y x d = we can express the mutual information ( to within the accuracy pointed out in [14, 21]) in terms of this distance, which gives us )) , ( 1 )( ( ) , ( ) ( ) ( ) : ( y x d x K y x d x K x K y x I − = − = (13) where the same ordering constraints apply. A defi nition of set complexity using mutual information, of course, con tains context inf ormation, and s o it i s useful t o make such a definition by constructing such a function F . In fact, this is what is represented in eqn. 8 with f =(1-d). Thus, ∑ − − ≡ Φ pairs j i i d x K N N ) 1 )( ( ) 1 ( 2 , (14) (Again the s um over pairs assumes that K(x i ) is the larger of the complexities of the two strings of each pair.) This m utual information sum , Φ , actually resolves one of our “p aradoxes”. I t discounts r andom sequences entirely, but the identical s equence probl em remains unsolved. The mutual information measure, when ex pressed in the met ric space, is close to our cons traint-based measure Ψ , (having a zero at d= 1), but it i s i nsufficient to resolve t he second “paradox” since there is n o zero at d= 0. Nonetheless, the relation b etween Φ and Ψ i s illustrative of a lar ge class of set information measures defined entirely in t erms of pair-wise distances in an i nformation manifold. This represents a large class of m easures, as shown in eqn. 10 a. To illustrate Bio-Informatio n Galas et al 1/11/2008 11 explicitly the first few of t hese “statistics” (indicating the normalization factor by 1 1 ) ( − = N N ξ ) . ) 1 ( ) ( ) ( ), 1 ( ) ( ) ( , ) ( ) ( 1 ) ( ) ( ) ( ) ( ij i j ij i i j ij i i j ij i i i i i d d N S F d N S F d N S F S F S F x K S M − = − = = = ≡ ∑ ∑ ∑ ∑ < < < ξ ξ ξ (15) M= Θ , simple sum ( no context depen dence) M= Λ , weighted average distance, or average conditional co mplexity (context-dependence) M= Φ , mutual information ( context-dependence) M= Ψ , satisfies constraints ( context-dependence) This set of measures, foc used on the properties of t he metric f unction, F , is clearly representative of a much l arger set of i nteresting set functions illustrated in eqn . 11. All but the first of these functions give a context dependent measure. The last one is the simplest possible function with zeros at 0 and 1, and r epresents our chosen measure function. I n genera l, these information measures differ by the weig htings given to the distribution of relative string complexities in t he set. A simple relationship between th ese f unctions is evident from eqn. 15: ) ( ) ( ) ( S S S Λ − Θ = Φ . T here i s another that is less obvious that we now cons ider in the next section. “Mean field” Approximat ion and Fluctuations in the Information Mani fold Since we can express our information m easure in terms of information distances w e can usefully examine the relationship between the abov e measures and the variations in a set of strings in the same metric terms. We can re late Ψ to d using the relations in eqn 15. 2 2 ) ( ) ( ) )( ( ) ( ) ( ij pairs i ij ij i pairs d x K N d d x K N S ∑ ∑ − Λ = − = Ψ ξ ξ (16) Then with a term that repre sents the complexity- weighted distance variance of the set, we have. Bio-Informatio n Galas et al 1/11/2008 12 2 2 2 2 2 2 2 ) ( ) ( ) ( ) ( ) 1 ( ) ( ) ( ) ( − ≡ ∆ ∆ − Λ − Λ = − Λ + Λ − Λ = Ψ ∑ ∑ ∑ pairs ij i ij pairs i ij pairs i d x K N d x K N d x K N S ξ ξ ξ (17) The above e xpression f or Ψ looks intr iguingly l ike a “mean field” t erm pl us a f luctuation term. The “mean field t erm” is e ssentially a r eflection of the for m of the distance- function i n Eq. 10b. The fluctuation term, 2 ∆ , measures the degree of deviation of the complexity distribution of t he set, and any deviation redu ces the overall set complexity. We c an make this more precis e. The mean-field-like approximation ( mf Ψ , the mean-field approximation to Ψ ) simply sets ∆ to zero. Then we have the complexity-weighted di stance average or the a verage conditional complexity, Λ as the key vari able: ) 1 ( Λ − Λ ∝ Ψ mf . We can describe the mean-field in t erms of t his statistic. Further, if the bit strings wer e uniformly s paced at distance d , then 2 ∆ a nd Ψ would simplify (carefully accounting for the numbers in the pairs sum): ) 1 ( ) 1 ( ) ( ) ( 2 2 2 2 Θ − Θ − Λ − Λ = Ψ − = ∆ ∑ ∑ d x K d x K d uniform i i i i uniform (18) but since Θ = Λ d uniform , a very simple expression (also obv ious from Eq. 10b) emerg es: Θ − = Ψ ) 1 ( d d uniform (19) If we make the further simplify ing assumption that the uniform distance and the total of the complexities can be varied separately, th en it is clear that the maxim um of Ψ occurs when d = ½ . Computational estimation and appl ication of set-based information The set complexity based on inherent KCS complexity of strings has many advantages, as discussed, but the definition of set complexity (eqn. 12) is inherently inc omputable. Thus we need to int roduce a co mputational approximation for this quantity. Data compression has been used to make this kind of approximation (see [22] for a comparison of several approaches). It has been shown that the universal information distance can be approximated using t he Normalized Bio-Informatio n Galas et al 1/11/2008 13 Compression Di stance (NCD) and this is comparable to a different approxim ation, Universal Compression Distance (UCD ). We will use NCD here ( ) ( ) ) ( ), ( max ) ( ), ( min ) ( ) , ( y C x C y C x C xy C y x d NCD − = (20) where ) ( x C is the co mpressed size of strin g x and xy is a concatenation of strings x a nd y [ 17]. This approximation is based on the estimation o f K olmogorov co mplexity usi ng a r eal compression algorithm, and makes use of th e a dditivity pro perty (s ee eqn. 4). By r eplaci ng the KCS complexity K ( x ) by a computational approximation C ( x ), th e set complex ity ca n be defin ed simply as ( ) ∑ − = Ψ pairs j i NCD j i NCD i x x d x x d x C N S ) , ( 1 ) , ( ) ( ) ( ) ( ˆ ξ (21) The compressed size C ( x ) of a string x is an u pper-bound for the Kolmogorov complexi ty K ( x ). Even t hough the NCD can be applied t o ap proximate the universal information dista nce with remarkable success, one is sue is that the ra nge of NCD may be s maller t han [0 ,1]. In some cas es, the estimate of NCD can even ta ke on value s larger tha n one [17]. As ou r measure of set complexity is b ased on the ass umption that the dista nce between two identica l strings as well as between two random st rings approa ches zero, problems in t he e stimation of set complexity can arise, since t he err ors i n the NCD acc umulate in the sum of di stances in Equation ( 21). We ca n address t his problem b y int roducing scaling fac tors for the computed NCD value s, and normalizing the obtained distances to the [0,1]- interval. These scaling factors can be obtai ned b y computing t he minimum an d maximum observabl e distan ce for a given set of d ata. The minimum dis tance is obtained by computin g the distance b etween two identical strin gs; that is, for each string in a s et, compute th e d istance to it self and select t he one that has the smallest value. The maximum dis tance is o btained by c omparin g ra ndom st rings; that is , f or a set of strings, permute the strings a nd find the maximum distanc e among all per muted strin gs within the set. In orde r to study t he behavior of the estimated set complexity, Ψ ˆ , we considered a s et of 2 5 random, b ut identical, binary stri ngs of length L = 1000 and used t he fa miliar gzi p co mpression algorithm to esti mate the Kolmogorov co mplexit y (this is b ased on the Lempel-Ziv algorit hm). Bio-Informatio n Galas et al 1/11/2008 14 We introduce noise by randomly perturbin g one bit a t a time in each string. The set complexity for different amounts of noise is shown in Figure 1. It can be seen that as the n oise i s i ntroduced, the set complexity increases until the amount of noise exceeds a certain value. As the individual strings start t o lo ose comm on structure, t he set complexity begins to decrease as the set b ecomes more and more ra ndom. Due to the a pproximation issues discussed above, t he set informati on does not go to zero for either the identical or ran domized s ets. T here are two sources of e rror in the compression approximation: 1. the estimates o f randomness are inherently poorer the shorter the length of the strings – specificall y the distance between finite bit strings never goes to 1 and the accumulat ed e rror can be substantial; a nd 2. the computatio nal i ssues mentioned ab ove (see [17, 22]). We can actu ally study the errors in our a pproximation by computing set com plexi ty under conditions whos e outcome we know a prio ri . An expe riment of this kind can be def ined as follows. Start from a s et of al l identical strings. As discussed e arlier, the set complexity fo r this set should be zero. Then, r eplace one string at a time by a co mpletely ran dom stri ng. As a random stri ng does not contribute to the complex ity since i t should b e distant fr om all others ( 1 ≈ d ), t he set information should remain zer o. This can be re peated for all strings i n a set , leading t o a set of ran dom strings whose set information should a lso equal zero. Thus, with this process we c an move f rom a set of id entical strings to a se t of rando m strin gs, generati ng a series of s ets that should all have se t informati on of zero if our approximati on were exact. T he result of the computational approximation of this process is shown i n Fi gure 2. It c an b e seen t hat, in practice, the e stimated complexity of a set of random st rings i s l arger than t he complexity of a se t of identical str ings. T his is not unexpected, as for finite, ra ndomized st rings, and wit h the gzip approximation , the residual mutual information estimate is clearly not zero. Overal l t he estimate of Ψ has a difference o f about 1.8-fold at the extreme en ds of these test sets. This enables us to estimate the computational error in t he estimated informational distances. Each “r andom” string has a calculated dist ance from the others of about 0.92 on average. We can t hen refin e our calculations t ake t his average e rror into account, and use the ran domized strings to a djust the estimates of distance in our computa tional estimatio n. T he devia tion i n Figure 2 wa s so use d to adjust the process shown in Figure 1, resulting in the normalized set complexi ty estimate shown in Figure 3. W ith this adjust ment there is no signifi cant difference in c omplexity bet ween a s et of identical stri ngs and a set of random strings. Bio-Informatio n Galas et al 1/11/2008 15 Criticality in the Dynamics o f Boolean Networks As another ap plication of our set complexit y measure, we decid ed t o examine the amount of information c ontained in the st ate dynamics of a model cl ass of co mplex systems t hat can exh ibit ordered, c haotic, and c ritical dynamics. Fo r simplicity we con sider random Bool ean networ ks (RBNs), which have been ex tensively stud ied as highly simplif ied models of gene regulatory networks [23, 2 4] and other complex syste ms phenomena [25]. In a Boolean n etwork, each node is a bi nary-valued variable th e value of which (0 or 1) i s determined by a Boo lean f unction that t akes inputs from some subset of nodes, possibly inclu ding the n ode itself. In t he s implest fo rmulation, all nodes are updated synchronous ly, thereb y generating tr ajectories of states, where a state of the syst em at a particular time is an n -length binary vect or containing the values of each of the n nodes in the network. Boole an networ k models for several biological gene regulatory circuits have been constructed and shown to reproduce experimenta lly observed results [ 26-29]. In a n RBN, each of the n nodes receives input f rom k node s (deter mined by the random s tructure of the network) that determine its value at the next t ime step via a randomly chose n Boolean function assigned to that node. The output of each s uch function is chosen to be 1 with probability p , which is known a s the bias [30]. Th us, the parameters k and p can be used to define ensembles of RBNs. I n the l imit of l arge n , RBNs exhib it a ph ase transiti on be tween a dynamicall y or dered and a chaotic regime. In the ord ered r egime, a perturbation to one node prop agates on average to less t han one other nod e duri ng one ti me step , so that small transient perturbations to t he node s die out over time. In the cha otic r egime, s uch perturbations increase exponentially over time, since a perturbation propagates on avera ge to more t han one no de d uring o ne time step [25]. Networks that operate a t t he bound ary betwee n the ordered and the c haotic r egimes h ave bee n of particular interest a s models of gene regulatory networ ks, as the y e xhibit complex dyna mics combined with sta bility under perturbations [24, 31-33]. For network e nsembles parameterized by k and p , an order parameter called the a verage sensitivity [34], given by ) 1 ( 2 p kp s − = , determines the critical phase t ransition in RBNs by specifying the average number of nodes that are affected by a pert urbation to a rand om nod e. Thus, th e ordere d regime corr esponds to 1 < s , the chaotic re gime to 1 > s , and the boundary a t 1 = s def ines t he point of the phase trans ition. The average sens itivity correspo nds to the well - known pr obabilis tic phase tr ansition cur ve derived b y Derrida [35]. It i s also easily computa ble Bio-Informatio n Galas et al 1/11/2008 16 for a p articular network given i ts set of Boolea n updat e fu nctions. T he l ogarithm of t he average sensitivit y can be in terpreted as t he Lyapuno v exponent [36]. Thus, by t uning k and p , networks can be made to un dergo a phas e transition . Networ ks that operat e cl ose to t he critical regime c an exh ibit t he most complex dynamics, as compared to ordered or chaotic networks. Indeed, ord ered networks give rise t o simple state trajector ies, mea ning that the st ates i n a traje ctory are ver y simil ar, pe riodic, o r quasi -periodic and often identical due to the " freezin g" of a large propor tion of nodes in the netw ork. Ch aotic netwo rks, on the other hand, tend to gene rate "noisy" state trajectorie s t hat i n time become indistin guishable fro m random coll ections of states when the para meters are dee p i n th e chaotic regime. In both these regimes, the set complexity of a randomly chosen state trajectory might be expecte d to be small , since it should contain a set of nearly identic al or nearly ran dom state s. We examined this question by ap plying our NCD-based estimate of set complexity to stat e trajector ies gener ated by ens embles o f rando m Bo ol ean netw orks opera ting in t he or dered, chaoti c, a nd critical regimes. S pecificall y, we ha ve set th e connectivity to be k = 3 and tuned the bias p in in crements of 0 .01 so th at the average sensi tivity, s , varie s fro m 1 < s ( ordered) to 1 > s (chaotic ). For e ach value of s , 50 r andom networks (number of nodes, n = 100 0) were each u sed to gene rate a traject ory of 20 sta tes, after an initial "burn in" of run ning the netwo rk 100 ti me steps from a rando m initial st ate i n ord er to allow th e dyna mics t o s tabilize (i.e., reach the attractor s). We collecte d the se 20 netwo rk states into a set S for eac h network of the e nsemble and calcula ted ) ( ˆ S Ψ for each . Figure 4 shows t he aver age ) ( ˆ S Ψ o ver t he 50 netw orks as a functi on of the average net work se nsitivity s (pl otted a fun ction of λ = log s, the Lyap unov expon ent). It i s clear that n etworks that are op erating close t o t he cr itical regime have t he highest a verage set complexi ty of their s tate traje ctories. In addit ion, t he vari ability o f the set complex ity i s also highest nea r th e critic al r egime, i ndicati ng th at c ritical (or near critical) networks are cap able of exhibiti ng t he m ost diverse dynamics. When ne tworks are dee p i n t he ordered regi me ( far to the left), the average set c omplexity of their stat e t rajectories is lo w and the variability is s mall. This can be e xplained by th e rela tively s imple network d ynamics, co nsisting most ly of fro zen n ode states an d no des t hat exhibit shor t p eriodic dynamics. As networks bec ome more c haotic, the states in the traject ories become more stoch astic, resulting in a d ecrease in their set comple xity. Our results clea rly s upport the view that co mplex systems operati ng at or near criticality, a Bio-Informatio n Galas et al 1/11/2008 17 propert y that i s beli eved to ho ld f or living s ystems, appear to ex hibit the most inf ormational ly complex d ynamics . Th e measur e Ψ seems very wel l suite d to des cribing captu ring t his pheno menon near criticality. Context-dependent Information o f Networks In the spi rit o f grappling wi th context-depe ndence in biological applicati ons, we a pply our complexi ty measure to networks. Fi rst, we c onsider only und irected gra phs with unweighte d edges, represented as an a djacency m atri x s uch t hat A ij = 1 if an edge c onne cts n odes i a nd j , and A ij = 0 if not. W hile there are nu merous methods fo r r epresenti ng t he similarit y be tween indivi dual n odes, our objective here is t o quantify the glo bal complexit y of the graph in a way that bala nces regular ity with ran domness as discussed abo ve. To u se our measu re, we mus t first d efine the i nformati on content , or comple xity, of ea ch node. Since we have not yet defi ned any ot her attri butes to the n odes or edges, this must der ive from th e conne ctivity of e ach n ode. T his i s repr esented i n the c omplexi ty of the b it stri ng x i , the i th row vector of t he adjace ncy matrix . T he s et of c omplexities is { K i }. I n th e same way we take inter - nodal informat ion distances, { d ij }, t o be du al to the mutual i nformati on be tween nod es, with d ij = 1 – w ij (s ee eqn. 15.) The complexi ty o f the s trings can be calculated using the K CS a pproac h. This i s a case where we can t ake the relation ships we ha ve in the algorithmic fo rmalism an d define the measu res, such as mutual infor mation , in th e p robabilisti c s ense. T he subtle relation ship bet ween t he two approaches is e xtensively discussed in referen ces [ 21] an d , f or example. It is i mportant to note th at the algori thmic formali sm is mor e fun damental, bu t in this case, whe re we have a well defin ed state space, the quan tities can be calc ulated using the famili ar Shanno n e ntropy an d mutual info rmation based on row vector s i n the adj acency mat rix. For each node we have: ( ) ∑ = − = 1 0 2 ) ( log ) ( a i i i a p a p K , (22) where we co nsider o nly whet her two nodes are con nected or not ( a takes o n the val ues 0 or 1 – that is; the alp habet describing the connecti ons is bina ry) : p i ( 1 ) is th e pro bability of t he i- t h node being connecte d and p i ( 0 ) = 1 – p i ( 1 ) is t he probability of it being u nconn ected (self connecting loops are not allowed.) The inter-nodal infor mation distanc es are defined in a simila r way. T he Shanno n mutual i nformation bet ween two variables, a an d b , is given by Bio-Informatio n Galas et al 1/11/2008 18 ∑ − = > < − ≡ b b a p H b a p a p H b a H a H a a I )) | ( ( ) , ( )) ( ( ) | ( ) ( ) : ( (23 ) where H is the Shanno n infor mation a nd is t he average conditi onal i nformatio n. (The secon d line of eq. 23 indicate s the d ependence of th ese qua ntities on the pr obability di stributio n of the var iables a and b .) Thus, ∑ = − = 1 0 , 2 ) ( ) ( ) , ( log ) , ( 1 b a j i ij ij ij b p a p b a p b a p d ( 24) Here p ij (a,b) is t he join t proba bility of node s i a nd j being r elated t o a th ird node wit h value (a,b), so the probabilities measure the relative prevale nce of p attern of connectivity; e.g . p ij ( 1,1 ) is the proba bility of both b eing co nnected to a nother node. By taking logari thms of base 2 her e, both K i and d ij ca n b e nor malized to t he interval [0,1]. We c an now ap ply e qn. 11 directly to comput e t he complexi ty Ψ , of the network. It i s simple to show that f or this measure (with b inary value conne ctions) a gra ph and its c onjugate have e qual c omplexity. As we fo und above, th e maxi mal val ue o f Ψ arises when all d ij = d = 1/2 and is prop ortional to a unifor m nod al information content K . W ith our normalized formula tion this cor responds to all K i = 1 . From th e “mean-fie ld” approximati on we can intuit that t he maximall y complex graph will have mini mal vari ation i n bo th single-node i nformatio n an d mutu al i nformation b etwe en nodes . This suggests that a somewhat uniform degree di stributio n corresponds to maximal complexi ty. We also can expect t he degree distribution to be centered a t N /2, since according t o equati on (23) nodes with e qual numbers of nei ghbors a nd non-neighbors have maxi mal informati on content ( K = 1 when p 1 = 0.5). However, it is importan t to note that perfect unifor mity in degree distribution will ac tually l ead t o low complex ity due to top ological redun dancy. For exa mple, t he unio n of two complete graphs (K N /2 U K N /2 ) (or a lmost equival ently it s c onjugate, the complet e bip artite gra ph K N /2, N /2 ) generates a very low Ψ (Fi gure 5A). A few ed ge rearr angements, ho wever, t hat disr upt the uniformity tr ansform suc h graphs into highly comple x net works, as sho wn in Fi gure 5B. Thus, fo r undirected, un weighted, Erdos-Renyi ran dom graphs we find that maximal complex ity arises from nea rly bimodu lar or near-bipa rtite gra phs. The se gra phs appear to balance the Bio-Informatio n Galas et al 1/11/2008 19 requir ement of m aximal complexity f or each single node wit h the requirement of uni form mutual informati on betwee n all n ode pairs . This suggests that modular graph archite cture adds informati on content, although it remains to determine how this finding translat es to other classes of grap hs (dire cted, weighted , scale -free, multiple edge types , etc .). Since biological networ ks appear to be ra ther modular, this is a n i nteresting co rrelati on. Since t he c ountervailin g requir ements of maximum comple xity for each node and high, uniform mutual inf ormation are balance d when we attempt t o maxi mize Ψ , and si nce th ese two requirement s a re r eminis cent of obser ved propert ies of biological networks, we e xpect t hat Ψ , or a c losely re lated f unction, h as strong bio logical meanin g f or networks. If we impos ed other co nstraints on the net work (e.g. functi onal constraints, specific motifs, a sp ecific growth and evolution process) and maximize Ψ with those constraints, Ψ may take on a clear meani ng. Whil e t his i s an imp ortant issue to explore it is beyond t he scope of the pr esent paper . If we consi der more realist ic networks w here different cha racters of the e dges are important (differe nt edge type s, or “alph abets”), we wi ll increas e the descri ptive alp habet of the edges beyond binary, identif ying d istinct types o f node i nteractio ns. For equations 22 and 24 t he s ums will now e xtend over t he f ull alpha bet describi ng those ed ge t ypes. We ha ve used s uch an extende d alphabet i n our analysi s o f genetic i nteractions for whi ch there are many p ossi ble types of in teractions that c an be usefully d istinguis hed. In t hat case the pr oblem of cla ssification of interacti on t ypes corresponds to an opti mization of Ψ b y a lphabet r eduction (Carter, Galitski and Galas , in preparation ). It is worth notin g that the p roblem of maxi mizing Ψ by reduci ng the alphabet size for networks, as ju st describ ed, is a n example o f a ver y gene ral problem – tha t of balancin g the s implicit y of the descri ptors of relat ionships wi th the c omplexity being desc ribed (not unlike the pr oblems fo r which the “infor mation bottlen eck method” w as de vised [37].) Discussion In this paper we have us ed th e intrinsic information conce pts of Ko lmorgorov-Chai tin- Solomonof f compl exity to c onstruct a simple measure f or set -based i nformation t hat pro vides a theoreti cal foundati on f or dealing with context-depend ent biolo gical information. Over the past 50 yea rs or so t he theo retical foundations have been well laid for defin ing the ab solute informati on conten t of an individual object, a nd the u nderpinnings of the i deas of r andomnes s and Bio-Informatio n Galas et al 1/11/2008 20 of proba bility theor y that began much ear lier. This is cl early the best way, in our vie w, to approac h d ifficult info rmation proble ms, like those we en counter in biolo gical syst ems. We can avoid the difficulties of d efinin g ensembles and probability distribution s over sam ple spa ces that are problematic to d efine, as i s r equired for a Shannon- base d approach, and we can bring t o bear the gains in rigor a nd c onceptual approach t o i nformation and complexity of th e K CS i nsights. I f the sample space a nd probabil ity i s natu rally well d efined, a s i n our net work example, o n the other hand, the cont ext-depende nt meas ure is amenable to Sha nnon-type ca lculation (s ee [2 0] for an excell ent review o f the relati onships). While it is o ften stated t hat biology i s a n i nformati on sci ence [38-40], we are still far f rom h aving the tools to provide a gener al theoretic al basis for dealin g with it as suc h. It i s diffic ult to overesti mate the importa nce of deali ng rigorously with cont ext-depend ence in biology. While it is ofte n acknowl edged as impor tant it is often dif ficult an d ungainly to deal wit h. Since t he process es of natura l selection are well known to be powerful sculp tors of con text depend ence in biologica l s ystems, selecting c omple mentary alleles o f genes i n a gen ome, for e xample, with ruthle ss ef ficiency, we expect a natural selection to be a pr odigious generator of cont ext depen dence. W e do f ind, in fact , that t he cont ext-based meas ure i s partic ularly us eful i n deciphe ring gene i nteraction data (Carter, Galitski and Galas, in pr eparation. ) Gene interacti ons, while of funda mental impor tance in biology, ar e only on e exa mple where context i s expected to be hi ghly significan t. It is important to note t hat c ontext dependenc e, d riven by n atural selectio n, leads to a dynamic pheno menon long st udied in biology, of which the allele inte raction effect i s but one example . The pheno menon o f “symmetry br eaking”, whi ch c haracteri zes the loss of some s ymmetry or simplicit y, the ac quisition of new disti nctions, i s no t fully und erstood or appreciated in comple x systems. It is, howe ver, wide spread in biology – for example see [41, 42]. In ord er to deal with symmetry brea king generally and ef fectively we need to have a global formalism, and since it i s the infor mation t hat dominat es our vie w, a glob al formalis m for co ntext -dependent info rmation is just wha t’s needed. We propo se that t he theory pr esented her e i s a beginn ing o f the development of a clas s of tools for analyzing thi s aspe ct of biolo gy. An importa nt proble m for future stu dy then is that of d escribin g a n interactive dynamics for a b iological process in the i nformation m anifo ld in te rms of the c omplexities and di stances. T his h olds the prospe ct for a deep under standing of the ori gins and evolu tion of bio logical bro ken symmetry in terms o f biological information . Bio-Informatio n Galas et al 1/11/2008 21 We began our constru ction by setti ng context-base d constraints on an informati on measur e for a set of bit strings, and we for mulate d two “para doxes” f or biologic al informat ion whic h then guided us to find a measure that resolves them. We found that a constru ct, based on the complexi ty of the bit strings in a set, ca n be expressed in terms of dis tances in an inf ormation metric s pace usin g t he el egant and useful un iversal in formation distance of Li an d V itan yi [11], a normali zed i nformati on distance. T he connect ion t o informati on di stances and the metric space of informati on (also called “univers al similarit y”) p rovides a set of new tools for formula ting problems in systems biology and e voluti on, as it pr omises to allow us to deal q uantitatively with the ebb and flow of information in biol ogy. Sinc e thi s i nformation is deeply co ntext depende nt there h as been n o cons istent and r igorous w ay to gra pple with th ese probl ems. Sinc e biological informati on is inhere ntly context-depend ent, t here have be en significant i ssues w ith its quantita tive represen tation using the usua l i nformation measures since bot h prob abilistic and intrinsic approaches (S hannon and K olmorgorov-Cha itin-Solomono ff) are inherently context-free in an d of themsel ves. Our formula tion p rovides a solu tion to t his problem. Our appro ach leads to a gener al formulati on allowing us to des cribe a very genera l class of informati on measu res. One o f these proposed measures, Ψ , appears t o solve so me key concep tual difficult ies o f biological informat ion – th e “paradoxes” of t he us elessness of both rando m and redun dant information. It is also the simplest f orm in the class of measures that wil l l ikely be useful in a varie ty of sp ecific applications . Our a pproach is quite disti nct f rom pr evious wor k, like that of Adami and Cer f [ 4] that req uires an ensemble of b iologically f unct ional examples a nd an explicit constraint representi ng th e “en vironment”. Wh ile th eir appro ach c an work for s pecific sets of functi onal molec ules, like t RNA seq uences, it is no t useful f or more comple x probl ems, partic ularly whe n the ensemble is i mpossible to spec ify. Nonethe less, it is clea r that our theoreti cal co nstruction is o nly a be ginning. There are a n umber of r emaining p roblems. One of these p roblems is the actual calc ulation of the KCS complexities . There have b een a number of importa nt ad vances toward t he estimatio n of co mplexity b y the use of co mpressi on algorithms, but these methods ar e not always practical b ecause of computa tional intensity, a nd they are inherent ly a pproxi mations w hose accurac y i s so metimes d iffic ult t o es timate. It is clear that while the Shannon formulat ion is not particul arly useful in many of the ca ses in which we are interest ed, it often does prov ide a practical approa ch to computation. Since it is clear that there is a d irect corr espondence betwee n t he probabilit y-based a nd inhere nt co mplexity-base d a pproac hes (carefully r eviewed by Grünwa ld and Vitanyi [20]) t his provides a rea sonable appro ach to Bio-Informatio n Galas et al 1/11/2008 22 practica l c omputati on i n some c ases , as in our descri ption of networ k ( graph) compl exity. W e a re currentl y exploring th e use of t hese techniqu es in a wi de range of a pplicatio ns. Among t he major remai ning pro blems we i dentify is the “ encodin g pro blem.” W hile the repres entation of i nformation in bit strings i s a po werful and gen eral approach, there remains the conce ptual difficulty of enc odin g actual biological informatio n in thi s representation (this is similar t o the pro blem f or macro molecul ar sequences that is “s olved” in reference [ 4] by postulat ing a functional ense mble of examples . To describe , even under the simple st of assumpti ons, th e i nformation in t he living ce ll that gives cont ext to o ther pieces of infor mation in the cell (all information that in teracts with them) i s a fo rmidabl e challenge – this i s what we c all the “en coding pro blem.” The application of our a pproach to problems of complex syste ms analysi s out side of the realm o f biology sh ould be a natural e xtension o f the problems discussed h ere. One gene ral p roblem of signific ant intere st relates to the extensio n of the method s of “ maximum e ntro py” and the ideas of “Occa m’s razor” [43] using context-depe ndent measur es on sets. This extension should be straight forward, but the useful setting of and int erpretation of the co nstraints is an inter esting challe nge. The pote ntial similar ity of these ideas to noti ons about p erceived simi larities be tween object s t hat a re close in distance in a “psycholo gy space ” of some kin d is also not l ost o n us [44]. In some rea l sen se it is the di stinction between objects bas ed on the overall context of the set t hat determine s the potentia l biol ogical usefulness of th e obj ect – the a nalogy wit h the ideas from psychol ogy is an interesting one , and not a little biologic al. Our purpose her e is to lay the found ations of t he qu antitative theor y, but we d o not unde restimate either the i mporta nce o r the difficult y of t his encodin g pr oblem, whose solut ion will be necessary for applicati ons of our methods t o real b iological pr oblems. We a re cu rrently wor king to ext end ou r trea tment to include a genera lization a nd to grap ple wit h this encodin g probl em explicitly by a nal yzing several model syst ems. Acknowle dgements: This work was supp orted by NSF FIBR grant EF -0527023, N IH P50 GM076 547, NIH GM0 72855, t he Battelle M emorial Instit ute, and the Academy of Finland, (supp orting MN: project No. 120 411 and No. 122973). NDP was su pported b y the Sam E. an d Kathlee n Henry pos tdoctoral fellowship from the Ameri can Cance r Society. Bio-Informatio n Galas et al 1/11/2008 23 Referen ces: 1. Murray Gell-Mann, S.L., Information measures, effective complexity, and total information. Complexity , 1996. 2 (1): p. 44-52. 2. G ell-Mann, M ., The quark and the jaguar : adventures in the simple and the complex . 1994, New York: W .H. Freeman. xv iii, 392 p. 3. Standish, R., On complexity and emergence. Complexi ty International, 2001. 9 : p. 1-5. 4. Adami, C. and N.J. Cerf, Physical complexity of symbolic sequences . Physica D, 2000. 137 : p. 62-69. 5. Lloyd, S. and H. Pagels, Complexity as thermodynamic dep th. Annals of Physi cs, 1988. 188 : p. 186-213. 6. Crut chfield, J.P. and C.R. Shali zi, Thermodynamic depth of causal states: Objective complexity via minimal representations. Physical Review E, 1999 . 59 (1): p. 275. 7. Kolmog orov, A.N., Three approaches to the definition of the concept "quan tity of information". (Russian). Problemy Peredachi Informacii, 1965. 1 : p. 3-11. 8. Chaitin, G.J., On the length of programs for comp uting finite binary sequences. Journal of the ACM, 1966. 13 (4): p. 547-569. 9. Solomonoff, R.J., A formal theory of inductive inference. II. Informa tion and Control, 1964. 7 : p. 224--254. 10. Solomonoff, R.J., A formal theory of inductive inference. I. In formation and Control, 1964. 7 : p. 1--22. 11. Li, M., et al., The similarity metric. IEEE T Inform Theory , 2004. 50 (12): p. 3250- 3264. 12. Vitanyi, P.M.B. and M. Li, Simplicity, information, K olmogorov complexity, and prediction , in Simplicity, inference and modeli ng , H.A.K. A. Zellner, M. McAl eer, Editor. 2002, Cambridge Uni versity Press: Cambridge, UK. p. 135-155. 13. Bennett, C.H., et al., Information distance. IEEE T Inform Theo ry, 1998. 44 (4): p. 1407-1423. 14. Gacs, P., The symmetry of algorithmic information. Dokl. A kad. Nauk SSSR, 1974. 218 : p. 1265--1267. 15. Shannon, C.E., A mathematical theory of communication. Bell Sy stem Tech. J., 1948. 27 : p. 379--423, 623--656. 16. Li, M. and P.M.B. Vitâanyi, An introduction to Kolmogorov complexity and its applications . 2nd ed. 1997, New York: Springer. xx, 637 p. 17. Cilibrasi, R. and P.M.B. Vitanyi, Clustering by co mpression. IEEE T Inform Theory, 2005. 51 (4): p. 1523-1545. 18. Martin-Lof, P., The definition of random sequences. In formation and Control, 1966. 9 : p. 602--619. 19. Shen, A. K., The notion o f $(\alpha,\beta)$-stochasticity in Kolmogorov 's sense and its properties. Dokl. A kad. Nauk SSSR, 1983. 271 (6): p. 1337--1340 . 20. Gr ünwald, P., D. and P. Vitányi , M. B., Kolmogorov Complexity and Information Theory. With an Interpretation in Terms of Questions and Answers. Jou rnal of Logic, Language and Information, 2003. 12 (4): p. 497-529. 21. Gacs, P., J.T. Tromp, and P.M.B. Vitanyi , Algorithmic statistics. IEEE Tran s. Inform. Theory, 2001. 47 (6): p. 2443--2463 . 22. Ferragina, P., et al., Compression-based classification of biologi cal sequences and structures via the Uni versal Similarity Metric: experimental assessmen t. BMC Bioinformatics, 2007. 8 : p. 252. Bio-Informatio n Galas et al 1/11/2008 24 23. Kauffman, S., Homeostasis and differentiation in random gene tic control networks. Nature, 1969. 224 (215): p. 177 -8. 24. Kauffman, S.A., The origins of order : self organization and selec tion in evolution . 1993, New York: Oxford Uni versity Press. xviii, 709 p. 25. Aldana, M., S. Coppersmith, and L.P. Kadanoff, Bool ean dynamics with random couplings , in Perspectives and Problems in Nonlinear Science , E. Kaplan, J.E. Marsden, and K.R. Sreeni vasan, Editors. 2002, Springer: New York. p. 23-89. 26. Albert, R. and H.G. Othmer , The topology of the regulatory inte ractions predicts the expression pattern of the segment polarity genes in Drosophila melanogaster. J Theor Biol , 2003. 223 (1): p. 1-18. 27. Espinosa-Soto, C., P. Padilla-Longoria, and E.R. Alv arez-Buylla, A gene regulatory network model for cell-fate de termination during Arabidopsis thal iana flower development that is robust and re covers experimental gene express ion profiles. Plant Cell, 2004. 16 (11): p. 2923-39. 28. Li, F., et al., The yeast cell-cycle network is robustly designed. Proc Natl Acad Sci U S A, 2004. 101 (14): p. 4781-6. 29. Faure, A., et al., Dynamical analysis of a generic B oolean model for the control of the mammalian cell cycle. Bioin formatics, 2006. 22 (14): p. e124-31. 30. Bastolla, U. and G. Parisi, Relevant elements, magnetiz ation and dynamical properties in Kauffman networks: A nume rical study. Physica D: Nonlinear Phenomena, 1998. 115 (3-4): p. 203-218. 31. Ramo, P., J. Kesseli, and O. Yli-Harja, Perturbation avalanches and criticality in gene regulatory networks. J Theor Biol, 2006 . 242 (1): p. 164-70. 32. Serra, R., M. Villani, and A. Semeria, Genetic network models and statistical properties of gene expression data in knock -out experiments. J Theor Biol, 2004. 227 (1): p. 149-57. 33. Shmulevich, I., S.A. Kauffman, and M. Aldana, Eukaryotic cells are dynamically ordered or critical but not chaotic. Proc Na tl Acad Sci U S A, 2005. 102 (38) : p. 13439-44. 34. Shmulevich, I. and S.A. Kauffman, Activities and Sensitivities in Boolean Network Models. Physical Review Letters, 2004. 93 (4) : p. 048701-4. 35. Derrida, B. and Y. Pomeau, Rando m networks of automata: a simple anne aled approximation. Europhys Lett, 1986. 1 (2 ): p. 45-49. 36. Luq ue, B. and R.V. Sole, Lyapunov exponents in random Boole an networks. Physica A: Statistical M echanics and its Applications, 2000. 284 (1-4): p. 3 3-45. 37. T ishby, N., F.C. Pereira, a nd W. Bialek, The information bottleneck method. Arxiv preprint physics/0004057, 2000 . 38. Maynard Smith, J., The 1999 Crafoord Priz e Lectures. The idea of information in biology. Q Rev Biol, 1999. 74 (4): p. 395-400. 39. Maynard Smith, J., The concept of information in biology. Philosophy of Sci ence, 2000. 67 (2): p. 177-194. 40. Hood, L. and D. Galas, The digital code of DNA. N ature, 2003. 421 (6921): p. 444-8. 41. Hartwell, L.H., et al., From molecular to modular cell biology. Nature, 1999. 402 (6761 Suppl): p. C47-52. 42. Barrio, R.A., et al., Size-dependent symmetry bre aking in models for morphogenesis. Physica D: Nonlinear Phenomen a, 2002. 168-169 : p. 61-72. 43. Li, M., J. Tromp, and P. Vitanyi, Sharpening Occ am's razor. Information Processing Letters, 2003. 85 (5): p . 267-274. 44. Chater, N. and P.M.B. Vitanyi, The generaliz ed universal law of generalization. Journal of Mathematical Psy chology, 2003. 47 : p. 346-369. Bio-Informatio n Galas et al 1/11/2008 25 Bio-Informatio n Galas et al 1/11/2008 26 1 2 3 Figure 1 . The estimated complex ity of a set of 25 binary strings ( L = 1000), using gzip to estimate the string complexity , and NCD to estimate the distance, as a function of the number of introduced rando mized bits. Bio-Informatio n Galas et al 1/11/2008 27 2 1 1.2 1.4 1.6 1.8 Figure 2. The estimated set complex ity using the method employed in figure 1 (see text) as a function of the numb er of random strings substituted for identical strings in the se t. Bio-Informatio n Galas et al 1/11/2008 28 1.0 1.2 1.4 1.6 0.8 0.6 0.4 0.2 0 -.2 Figure 3. The set complex ity of Figure 1 adjusted by the estimations o f set complexity in Figure 2. As can be seen, the resultin g set complex ity of a set of identical strings is close to that of a set of random strings, as expected from such a measure. Bio-Informatio n Galas et al 1/11/2008 29 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 300 400 500 600 700 800 900 1000 1100 1200 1300 λ Ψ (S) Figure 4: The average, estima ted set complexity of random state trajector ies as a function of the log of the av erage sensitivity λ, the Lyupanov ex ponent, g enerated by networks operating in the orde red ( λ < 0), critical ( λ = 0), and chaotic regimes ( λ > 0). The bars show the variabi lity (one standard deviation) of the estimated set complexity for 50 networks. Bio-Informatio n Galas et al 1/11/2008 30 Figure 5. Information content of two graphs with N = 10. Graph (A) has a low information content: Ψ A = 0.2. Graph (B), the max imally informative undirected, unweighted graph wi th N = 10, on the other hand, has a much higher in formation content: Ψ B = 1.9.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment