Throughput Optimal On-Line Algorithms for Advanced Resource Reservation in Ultra High-Speed Networks
Advanced channel reservation is emerging as an important feature of ultra high-speed networks requiring the transfer of large files. Applications include scientific data transfers and database backup. In this paper, we present two new, on-line algori…
Authors: ** 논문 저자는 명시되지 않았으나, 본 연구는 **고성능 네트워크 및 라우팅 분야**의 전문가들(예: 전산학·전기·통신공학 교수진 및 연구원)으로 구성된 팀에 의해 수행된 것으로 추정된다. **
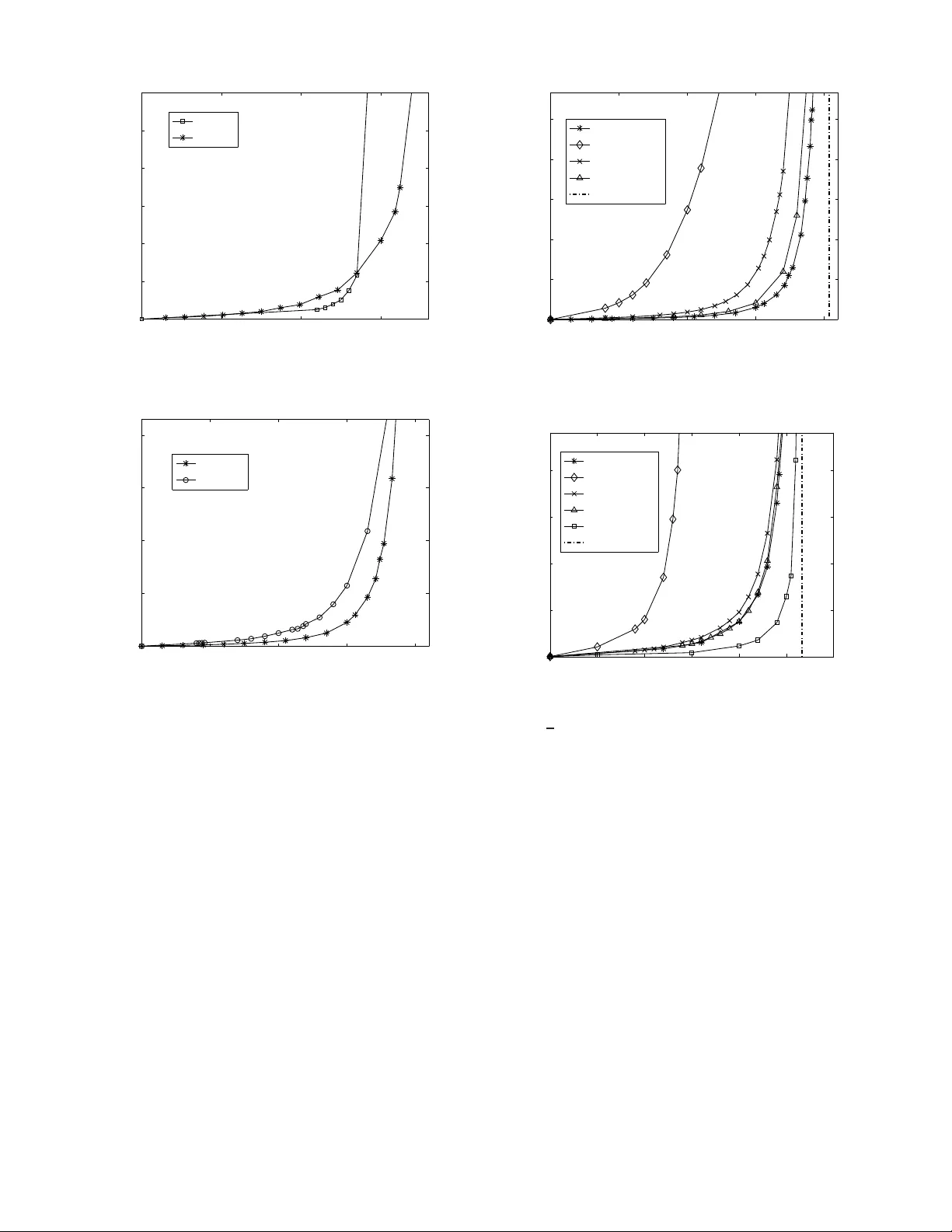
Throughp ut Optimal On-Line Algorithms for Adv anced Resou rce Reserv ation in Ultra High-Speed Netw orks Reuven Cohen 1 , 2 , Niloofar Fazlollahi 1 and David Starobinski 1 1 Dept. of Electrical and Computer Engin eering Boston U niv e rsity , B o ston, MA 02215 2 Dept. of Physics, MIT , Cambridge, MA 02139 Email: reuven@mit.e du, { n fazl,staro } @bu.edu Abstract —Advanced channel reser vation is emerging as an important fea tu re of u ltra high- speed networks requiring the transfer of large files. Applications include scientific data trans- fers and database backup . In this paper , we present two new , on- line algorithms for advanced reser vation, called BatchAll and BatchLim , th at are guaranteed to achieve optimal th roughput perfo rmance, based on multi-commodity flow arguments. Both algorithms are shown to hav e polynomial-time complexity and prov able b ounds on the maximum delay for 1 + ε b andwidth augmented netwo rks. The Ba tchLim algorithm r eturns the com- pletion time of a connection immediately as a request is placed, but at the expense of a slightly looser competitive ratio than that of BatchAl l . W e also pr esent a simple approach that limits the nu mber of parallel paths used by the algorithms while prov ably bounding the maximum reduction factor in the transmission throughput. W e show that, although the number of different paths can be exponentially large, the actual numb er of paths n eeded to approximate the flow is q uite small and proportional to the n umber of edges in the n etwork. Simulations fo r a n umber of topologies show that, i n practice, 3 to 5 parallel paths are suffi cient to achieve close to optimal performa n ce. The perfo rmance of the competitive algorithms ar e also compared to a greedy benchmark, both through analysis and simulation. I . I N T RO D U C T I O N TCP/IP h as been so far considered and u sed as th e cor e infrastructu re f or all sorts of data transfer including bulk FTP application s. Y et, it has recen tly be en o bserved that in ultra high speed ne tworks, ther e exists a large gap betwee n the capacity of network links and th e maximu m e nd-to-e nd throug hput ach ieved by TCP [1, 2]. This gap, which is mainly attributed to the shar ed nature of Internet traffic, is becomin g increasingly problematic fo r m odern Grid an d d ata b ackup applications requ iring transfer of extreme ly large datasets o n the o rders of ter abytes and more. These limitations ha ve raised efforts for development of an alternative p rotocol s tack to complem ent TCP/IP . This protoco l stack is based on the concept of advanced r eservation [2, 3], and is specifically tailored for large file tran sfers and other high through put applications. Th e most important proper ty of advanced re servation is to offer hosts and users the ability to reserve in ad vance de dicated paths to co nnect their re- sources. Th e importance of advanced reservation in suppor ting dedicated con nections has been m ade evident by the gr owing number of testbeds related to this technolog y , such as Ultra- Science Net [2], On-d emand Secure Circu its and Advanced Reservation System s (OSCARS) [4 ], and Dy namic Resource Allocation via GMPLS Optical Network s (DRA GON) [5]. Sev era l pr otocols and algo rithms have been p roposed in the literature to support advance reservation, see, e.g ., [ 2, 3, 6] and referenc es therein. T o the au thors’ knowledge, none o f them guaran tees th e same throughput perfor mance as an optimal off- line algo rithm. In stead, m ost are based on greed y appro aches, whereas each req uest is allocated a p ath guarantee ing the earliest co mpletion time at the time the requ est is place d. Our first contribution in this paper is to uncover fu ndamen tal limitations o f g reedy algor ithms. Specifically , we show tha t there exist network topo logies and re quest patter ns for which the maximum throug hput of these algorithms can be arbitrar ily smaller than the optima l throug hput, as the network size grows. Next, w e present competitive advanced r eservation algo- rithms that provably achiev e the maximum throu ghpu t for any network and req uest p rofile. The first algorithm , called BatchA ll , provides a competiti ve ratio on the maximum delay experienced by each request in an augmented resource network with respect to the op timal off-line algorith m in the original network. B atchA ll groups requests in to ba tches. In each batch , paths are efficiently assigned ba sed on a max imum concur rent flow optimization. All the requests arriving dur ing a cur rent batch must wait un til its co mpletion befo re b eing assigned to the next batch . The BatchAll algorithm does no t retur n the connec tion completion time to th e user at the time a requ est is placed , but only when the connectio n actually starts. Our second algorithm , called BatchLi m , return s the comp letion time im- mediately as a request is placed, but at the expense of a slightly looser competitive ra tio. This algorithm o perates b y limiting the length of each b atch. The pre sented com petitive algorithm s are b ased up on mul- ticommod ity flow algor ithms, an d therefore can be performe d efficiently in polyno mial time in the size of the network fo r each req uest. Our model assumes that the n etwork in frastructur e sup ports path dispersion, i.e., mu ltiple paths in parallel can be used 2 to ro ute data. Obviously , a too large p ath d ispersion may be undesirab le, as it may en tail fr agmenting a file into a large number of segments an d r eassembling th em at th e d estination. T o address this issue, w e present a simple approach , b ased on the max-flow min-cut theorem, that limits the number of parallel paths while boun ding the max imum reductio n factor in th e transmission throug hput. W e prove that this bo und is tigh t. W e, then, pro pose two algor ithms Batch AllDi sp and Bat chLimD isp , based up on Batch All and Ba tchLim respectively . These algorithms perfo rm similarly to the origin al algorithm s, in term s o f the batchin g p rocess. Howe ver , after filling each ba tch, the algo rithms will lim it th e d ispersion of each flow . Althoug h th ese algor ithms are no t thr oughp ut optimal anym ore, they are still throughp ut co mpetitive. While the m ain emphasis of this paper is o n th e deriv a- tion o f theor etical perfo rmance guaran tees on th e maximu m throug hput of advanced reservation protoco ls, we also pr o- vide simulation results illustrating the per forman ce of these protoco ls in terms of the average delay . The simu lations show that the pr oposed competitive algorithms compare fav orab ly to a gr eedy bench mark, althoug h the bench mark does sometim e exhibit supe rior per forman ce, especially in sparse topo logies or at low load. With respect to path dispersion, we show that excellent perform ance can be achie ved with a s few as five or so pa rallel paths p er conn ection. Note that preliminary findings lead ing to th is work wer e reported in a two-pag e abstract [7 ]. Th e only overlap is Lemma 4.1 an d Theor em 4 .3, which were presented without proof . This pap er is organ ized as follows. I n Section II , we br iefly scan the relate d work on advanced reserv ation , competitiv e ap- proach es, and p ath d ispersion. I n Sectio n I II, we introd uce our model and nota tion used throug hout the paper . W e also pr esent natural greedy ap proach es and d emonstrate their inefficiency . In Section IV, we describe the Ba tchAl l and Bat chLim algorithm s and deriv e results on their com petitive ratios. Our method for bounding path dispersion is described and analyzed in Section V. In Section VI , simulation results ev aluatin g the perfo rmance of some of our algorith ms under different network topolog ies and traffic param eters are pr esented. W e conclud e the paper in Section VII. I I . R E L A T E D W O R K Competitive algorithms for ad vanced reservation network s is the f ocus of [8 ]. This work discusses the lazy ftp proble m, where reservations are made for ch annels for the tran sfer o f different files. Th e algorithm p resented the re provides a 4- competitive algor ithm for the makespan (the total co mpletion time). Howe ver, [8] fo cuses on the case of fixed r outes. When routing is also to be con sidered, the time complexity of the algorithm presented ther e may be exponential in the network size. Another recent work [ 9], f ocusing on r outing in packet switched network in an adversarial setting, discusses choosing routes for fixed size packets injected by an adversary . It enforce s regular ity limitations o n the adversary which are stronger than the ones r equired her e, and achieves the network capacity with a gu arantee o n th e max imum q ueue size. It do es not discuss the case of ad vance re servation with different job sizes o r b andwidth req uiremen ts. It is based upo n a pprox imat- ing an in teger pr ogramm ing, which m ay not be extensible to a case whe re p ath reservation, rather than pac ket-based routing is inv olved. Most of the works regarding competitive app roaches to routing fo cused main ly on call adm ission, withou t the ability of ad vance reservation. For some results in this field see, e.g., [1 0, 11]. Some results inv olv ing ad vanced r eservation are p resented in [ 12]. However , the path selectio n th ere is based o n se veral alternati ves supplied by a user in the request rather than a path selection using an auto mated mechan ism attempting to optimize perfor mance, as d iscussed h ere. In [13] a combin ation of call admission and circuit switching is used to obtain a routing scheme with a logarithm ic com petitive ratio on the total r ev en ue received. A comp etitiv e routing scheme in terms of the nu mber of failed routes in the setting of ad-hoc networks is presented in [14] . A survey of on- line routing results is pr esented in [15 ]. A comp etitiv e a lgorithm for admission and ro uting in a multicasting setting is p resented in [16]. Most of the other existing work in this area consists of he uristic app roaches which m ain emp hasis are on th e algorithm cor rectness and comp utational complexity , without throug hput guarantees. In [17] a rate achieving scheme for packet switching at the switch level is presented. Th eir scheme is based on conv ergen ce to the o ptimal multicommod ity flow using de- layed decision for que ued packets. Their results somewhat resemble our Bat chAll algor ithm. However , th eir scheme depend s on the existence of an average packet size, wher eas our scheme addresses the full routing-sched uling q uestion for any size distribution an d any (ad versarial) arriv al sched ule. In [18 ] queuing analysis of sev er al optical tran sport network architecture s is cond ucted, and it is shown that u nder some condition s on the a rriv al pr ocess, some of the schemes can achieve the maximu m network rate. As the previous one, this paper d oes n ot discuss the fu ll rou ting-sched uling q uestion discussed h ere and does not hand le unbo unded job sizes. Another d ifference is that our paper pr ovides an algorithm, BatchL im discussed below , g uarantee ing the endin g time of a job a t the time of arrival, which, as far as we know is the first such algorithm. Many papers ha ve discussed the issue of path dispersion and attempted to a chieve good thr oughp ut with limited d ispersion, a survey o f some results in th is field is giv en in [1 9]. In [20, 21] h euristic m ethods of co ntrolling mu ltipath rou ting and some q uantitative measure s are presented. As far a s we know , our work p roposes the first fo rmal tr eatment allowing the approx imation o f a flow u sing a limited n umber of paths with any desired accur acy . 3 I I I . G R E E DY A L G O R I T H M S A N D T H E I R L I M I TA T I O N S A. Network Model W e first present the network m odel that will be u sed throug hout the paper (both for the g reedy and co mpetitive algorithm s). The model consists of a general network topolog y , represented by a graph G ( V , E ) , where V is the set of node s and E is the set of lin ks connecting the nodes. The graph G can b e dire cted o r und irected. Th e capacity o f each lin k e ∈ E is C ( e ) . A connection req uest, also referre d to as job, contains the tuple ( s, d, f ) , where s ∈ V is the source nod e, d ∈ V − { s } is the destination node, and f is the file size. According ly , an advance reser vation algorithm computes a starting tim e at which the connection can b e initiated , a set of paths used for the connectio n, an d an amou nt of band width allocated to each path. Our mo del sup ports p ath d ispersion, i.e., m ultiple path s in p arallel can be used to rou te data (in section V -B, we discuss practical m ethods to bound p ath dispersion wh ile still provid ing perfor mance guaran tees). In addition, the greed y alg orithms in troduce d b elow employ path switching, wh ereby a c onnectio n is allowed to switch b etween different paths throu ghout its du ration. In subsequent sections, we will m ake f requen t use o f mu lti- commod ity functio ns. The multicommo dity flow pr oblem is a linear planning p roblem returning t rue or fa lse based u pon the feasibility of transmitting concurr ent flows from all pairs of sources and destination du ring a g iv en time duration , such th at the to tal flo w throu gh each link do es no t exceed its ca pacity . It is solved by a fu nction mul ticom m ( G, L, T ) , wher e L is a list of jobs, each c ontaining a source, a destination, and a file size, an d T is the tim e du ration. In the sequel of this pa per, we will be interested in char- acterizing the saturation through put of the various algo rithms, which is defined as the maximu m a rriv al rate o f re quests such that the av e rage delay experienced b y r equests is still finite (delay is de fined as the time elapsing b etween the arrival o f a connectio n requ est until th e completion of th e correspond ing connectio n). The maximum co ncurren t flow is calculated by the f unction maxflo w ( G, L ) . It r eturns T min , the min imum value of T such that mult icomm ( G, L, T ) re turns true . Both th e multicom- modity and m aximum conc urrent flow pr oblems are k nown to be comp utable in polynomial time [22 , 23] . B. Algorithms Greedy . A seemingly natural way to implem ent advanced chann el reservation is to follo w a gre edy pr ocedur e, where, at the time a req uest is p laced, the request is allocated a path (or set of paths) guaran teeing the earliest possible completion time. W e refer to this appro ach as Gr eedy and explain it next. The Gree dy algorithm divides the time ax is into slots delineated b y event. Each ev en t cor respond s to a set up o r tea r down instance of a connectio n. T herefor e, d uring each time slot the state o f a ll lin ks in the network r emains un changed . In general, the tim e axis will c onsist of n time slots, w here n ≥ 1 is a variable and slot i corr esponds to time interval [ t i , t i +1 ] . Note that t 1 = t (the time at which the cu rrent request is placed) and t n +1 = ∞ . Let W i = { b i (1) , b i (2) , . . . , b i ( | E | ) } be the vector o f re- served bandwidth on all links at time slot i wher e i = 1 , . . . , n , and b i ( e ) denote th e reserved b andwidth on link e during slot i , with e = 1 , . . . , | E | . For each slot i ∈ L , constru ct a graph G i , where the capacity of link e ∈ E is C i ( e ) = C ( e ) − b i ( e ) , i.e., C i ( e ) represents the a vailable ban dwidth on lin k e during slot i . In ord er to g uarantee the earliest completio n time, Gre edy repeatedly pe rforms a max flow allocation between nodes s and d , for as many time slots as needed until the entir e file is transferred . This approach ensures th at, in each time slot, th e maximum po ssible number of bits is transm itted and, h ence, the earliest possible completion time (at the time the request is placed) is achiev ed . Th e Greedy algorithm can thus be concisely describe d with the following pseudo-co de: 1) In itialization • Set initial time slot: i =1. • Set initial size of remaining file: r = f . 2) If ma xflow ( G i , s, d, r ) ≥ t i +1 − t i (i.e., all the remain- ing file can b e transferred during the cu rrent time slot) then 3) Ex it step: • Up date W i by su btracting th e used bandwidth f rom ev er y link in the new flow and, if needed, create a new event t i +1 correspo nding to end of conn ection. • Ex it proced ure. else 4) Non -exit step: • Up date W i by su btracting th e used bandwidth f rom ev er y link in the new flow . • r = r − r × ( t i +1 − t i ) / maxfl ow ( G i , s, d, r ) (up date size of remaining file). • i = i + 1 (ad vance to the n ext time slot). • Go back to step 2. Greedy shorte st . The Greedy shorte st algorith m is a variation o f Greed y , where o nly sho rtest p aths (in terms of numb er of h ops) between the sou rce s and d estination d are utilized to rou te data. T o implemen t Greedy shorte st , we employ exactly the sam e pr ocedur e as in Gree dy , except that we p rune all the links not belonging to one of the shortest paths using b readth first search. Note that for a given source s and destination d , the pru ned links are the same for all th e grap hs G i . C. I nefficiency Results W e next constructively sho w that there exist certain ar- riv al p atterns, for which both Greedy and Greedy shorte st achieve a satu ration thr oughp ut significantly lower th an op- timal. Specifically , we presen t cases where th e saturation throug hput of Greedy and Gre edy shorte st is Ω( | V | ) times smaller than the optima l th roug hput. Th us, the ratio of the 4 (a) 3 N 1 2 (b) 2 1 Fig. 1. Examples for the disadv antages of the greedy approach. maximum throug hput of the gr eedy algorithms to that of the optimal alg orithm can b e arbitrar ily small. Theor em 3.1: For any given vertex set with cardinality | V | , th ere exists a grap h G ( V , E ) such that the saturation throug hput o f Greed y is | V | / 2 tim es smaller tha n the optim al saturation thro ughpu t. Pr oof: Consider the rin g network shown in Fig. 1(a). Suppose ev er y link is an undirected 1 Gb/s link and that durin g each second re quests arrive in this or der: 1Gb request from node 1 to 2, 1Gb req uest fro m n ode 2 to 3, 1Gb r equest f rom node 3 to 4, · · · , 1Gb request fro m nod e | V | to 1. The G reedy algo rithm will a llocate the maximum flow to each request, meanin g it will be split to two paths, half flowing directly , and half flo wing throu gh th e alternate path along the entire ring . Therefore, each new request will h av e to wait to the previous one to end, resulting in a completio n time of | V | / 2 seco nds. On the other hand , the optimal time is just one second using the direc t link between each pair of no des. Assuming the above p attern of requests repeats per iodically , then an optimal algorithm can supp ort at mo st o ne req uest pe r seco nd betwee n each pair of n eighbo ring n odes befor e reaching saturation, while G reedy can suppor t at most 2 / | V | request per second, hence pr oving the theorem. A similar result can be proved f or directed grap hs. W e next show th at restrictin g ro uting to shortest p aths d oes not solve the inefficiency pro blem. Theor em 3.2: For any given vertex set cardinality | V | , there exists a gr aph G ( V , E ) such that th e satur ation thro ughp ut of Greedy shortest (or any other algorithm using only shortest p ath rou ting) is | V | − 2 times smaller th an th e o ptimal saturation thro ughpu t. Pr oof: Conside r the n etwork d epicted in Fig . 1( b), where all requests are from n ode 1 to 2, and only the d irect p ath is used by the algorith m. In this scenario, an optimal algorithm would all | V | − 2 path s b etween n odes 1 and 2. Hence, the optimal algo rithm can a chieve a saturation throu ghpu t | V | − 2 higher than Greedy shorte st . I V . C O M P E T I T I V E A L G O R I T H M S In th e previous section, we uncovered some of the limita- tions of greedy algorith ms that im mediately allo cate resour ces to each ar riving request. In th is section, we p resent a n ew f am - ily of o n-line, poly nomial-time algorithms that rely on the idea of “batch ing” reque sts. Thus, instead of immed iately reserving a path for each incoming r equest as in th e greedy algorithms, we accu mulate several arri vals in a batch an d assign a more efficient set of flow paths to the whole batch. The pro posed algorithm s guar antee th at the m aximum delay exper ienced by each request is within a finite multiplicative factor of the value ach iev ed with an op timal o ff-line algor ithm. Th us, th ese algorithm s reach the max imum throug hput achiev able by any algorithm . A. Capacity Boun ds As a preparato ry step, we present a boun d on th e ma x- imum thr oughp ut achievable by any algorithm. This bound , based on a multicommod ity flow fo rmulation , will be used to compare the perf orman ce of the proposed on-line com petitive algorithm s to the op timal off-line algorithm . Lemma 4.1 : If du ring any time inter val T , each node i ∈ V sen ds on av er age γ ij bits of inform ation per un it time to node j ∈ V − { i } , then there exists a multi-commo dity flow allocation on graph G with flo w values f ij = γ ij . Pr oof: First, we prove that for any gi ven arran gement of sour ces and destinations in a network and at any tim e t , the transmission rates in bits pe r unit time comply with th e proper ties of multi-comm odity flows. T ake the transmission rate between nod e i and j going thr ough the (directed) edge k at tim e t to be R k i,j ( t ) . T he total through put passing ea ch link can not exceed th e link cap acity , P i,j R k i,j ( t ) ≤ C ( k ) . According to the information conservation prop erty , the total transmission rate into any node is equal to the out-goin g rate except for th e sour ce and destination o f any of th e transmissions. Now , th e average transmissions d uring any time interval T satisfy the same p roper ties a s above b ecause of linearity . Th us, we obtain a valid mu lti-commo dity flow problem , where the time average of each flow represents an admissible com modity . Cor ollary 4 .2: The a verage transmission rate between all pairs in the network for any time interval is a feasible multicomm odity flo w . B. The Batch All Competitive Algorithm In case no de terministic kn owledge on the futur e reque sts is giv e n, one would like to give some bound s on the perfor mance of the algorithm co mpared to th e performa nce of a “perfect” off-line algorithm (i.e., with full knowledge of the future and un limited com putational resources) . W e pr esent here an algorithm , called Batch All (since it b atches tog ether all pending requ ests), giving bounds on this measure. The alg orithm ca n be described as fo llows (we assume th at there is initially no pending request): 1) For a requ est l = { s, d, f } arriving at time t , give a n immediate startin g time and an en ding time of t c = t + max flow ( G, l ) . 2) Set L ← null. 3) While t < t c and ano ther req uest l ′ = { s ′ , d ′ , f ′ } arrives at time t : • Set L ← L ∪ l ′ . • Mar k t c as its starting time and add it to the waiting batch. 5 4) When t = t c , calcu late t ′ = m axflo w ( G, L ) . • If t ′ = 0 (i. e., there is no pending request) go back to step 1. • Else t c = t c + t ′ and go back to step 2. W e note that upon the arriv al of a r equest, the BatchAl l algorithm retu rns o nly the starting time o f the con nection. The allocated paths and completion time are computed o nly when the connection starts (in the next sectio n, we present an other competitive a lgorithm with a slightly loo ser compe titi ve ratio but wh ich returns the completion time at the arriv al time of a request). W e next comp are the perf ormance of an o ptimal off-line algorithm in the network with that of the Batch All algor ithm in an augmented network. The augmented network is similar to the original network, other than that it has a capacity o f (1 + ε ) C ( e ) at any link, e , that has capacity C ( e ) in the original network. T his implies tha t the performan ce of the competitive algorithm is c omparab le if o ne allows a factor ε extra capacity in the link s, or, alternati vely , one may say that the p erform ance of the algor ithm is co mparable to th e op timal off-line algor ithm in some lower cap acity network, allo win g the maximum rate o f only (1 + ε ) − 1 C ( e ) f or each lin k. The Batc hAll a lgorithm satisfies the following theoretical proper ty on the m aximum waiting time : Theor em 4.3: I n a network with augmented resources where ev e ry edge has b andwidth (1 + ε ) times the original bandwidth (for all ε > 0 ), the maxim um waiting time fro m request arriv al to the en d of the transmission using Bat chAll , for req uests arriving up to any time t ∗ , is n o more th an 2 /ε times the maxim um waiting time for the optimal algorithm in the o riginal network. Pr oof: Consider the augmen ted resou rce network . T ake the maximum length batch that accomm odates r equests arriv- ing before time t ∗ , say i , and mark its leng th b y T . Since the batch bef ore this o ne was of length at most T (if a req uest arrives when n o batch is executing, the b atch is considered to be of size 0 ), and all re quests in batch i were received during the execution of previous b atch i − 1 , th en th e total waiting time o f each of these requ ests was at most 2 T . By Corollary 4 .2, the total time for han dling all requests received during the e xecutio n of batch i − 1 must have b een at least T in the augmen ted network, or (1 + ε ) T in th e o riginal network . Since all of the se requ ests arrived d uring a time o f at most T , one of them must have been continu ing at least a time of εT after the last requ est under any alg orithm. Therefore the ratio between th e maximu m waiting time is at most 2 /ε . Cor ollary 4 .4: The saturatio n throu ghpu t of BatchAl l is optimal beca use for any arb itrarily small ǫ > 0 , th e delay of a request is guaran teed to be at most a finite multiplicative factor larger than th e ma ximum d elay of the o ptimal algo rithm in the reduced reso urces network. W e next sho w that th e comp utational complexity of BatchA ll is practical. Theor em 4.5: Th e comp utational comp lexity of algo rithm BatchA ll pe r request is at most poly nomial in the size of th e network. Pr oof: For each batch, th e BatchAl l a lgorithm so lves a max imum co ncurren t flow problem that c an be co mputed in polyn omial time [22 ]. Noting th at the nu mber of b atches cannot exceed the number of requests (since eac h batch contains at least one request), the theor em is p roven. C. Th e B atchLi m Competitive Algorithm The f ollowing algo rithm, called Ba tchLi m , oper ates in a similar setup to B atchA ll . Howev er, it gi ves a guarantee o n the finishing time of a job when it is sub mitted. The algorithm is based on creating increasing size ba tches in case of h igh loads. When the rate of requ est arri val is high, ea ch b atch created will be app roxima tely twice as long as the previous one, and thus larger batch es, giving a good approx imation of th e to tal flow will be created. When th e loa d is low only a single batch of pending requests exists at m ost times, and its size will rema in appro ximately co nstant or even decrease fo r decreasing load. The algorithm main tains a list of times, t i , i = 1 , . . . , n , where for every inter val, [ t i , t i +1 ] , a batch of jobs is assigned. When a new request between a sour ce s and a d estination d arrives at time t , then an attempt is first made to a dd it to one of the existing interv als b y using a m ulticommo dity flo w calculation. If the attempt fails, a new time , then a ne w batch is created and t n +1 = max( t n + ( t n − t ) , t n + M ) , where M = f / maxflo w ( G, s, d ) is the m inimum time fo r th e job completion , is added to the list, and th e job is assigned to the interval [ t n , t n +1 ] . W e next provid e a d etailed descr iption of how the algo rithm handles a new r equest. W e use the tuple l = { s, f , d } to denote th is job and the list L i to d enote the set of jobs already assigned to slot i . 1) In itialization: set i ← 1 . 2) While i ≤ n • If multi comm ( G, L i ∪ l , t i +1 − t i ) = true then return i and exit (check if requ est c an be accommo - dated du ring slot i ). • i ← i + 1 . 3) Set n ← n + 1 (create a ne w slot). 4) Set M = ma xflow ( G, l ) . 5) If M > t n − 1 − t then t n +1 ← t n + M ; else t n +1 ← t n + ( t n − t ) . 6) Return n . Fig. 2 illustrates runs o f the Batch All and Ba tchLi m alg o- rithms for the same set of r equests. The advantage of the Batch Lim algorithm ov e r Batc hAll is the assignme nt of a com pletion time to a req uest upo n its arriv al. Furthe rmore, the proof of the algorithm req uires only an attempt to assign a new job to the last interval, ra ther than to all of the m. Th erefore , it is also possible to giv e the details of the selected paths to the sour ce as soo n as a new batch is created. W e introdu ce th e following technical Lemma wh ich will be used to prove the main theo rem. 6 B 1 2 3 4 5 6 1 2,3 4,5 6,7 7 8 8 9 9 1:00 2:00 3:00 4:00 5:00 6:00 7:00 8:00 9:00 1 2,3,4 5,6,7 8 9 BatchLim BatchAll C A Fig. 2. Ill ustration of the ba tching process by the algorithms BatchAll and BatchLim . The odd numbered jobs request one hour of m aximum ban dwidth traf fic between nodes A and B and the e ven numbere d jobs re quest one hour maximum bandwidt h traf fic between B and C . In BatchAll , a ne w batch is created for all requests arrivi ng duri ng th e running of a pre vious batch. In BatchLim , for each ne w reque st an attempt is made to add it to one of the exi s ting windo ws, and if it fails, a new windo w is append ed at the end. Lemma 4.6 : (a) For any i , t i − t i − 1 ≥ ( t i − t ) / 2 . (b) For any i , t i +1 − t i ≤ max(2( t i − t i − 1 ) , M ) , where M is the minimum completio n time for the largest job in the interval [ t i +1 , t i ] . Pr oof: (a) When the time slot [ t i − 1 , t i ] is added, its length is the max imum o f M and [ t, t i − 1 ] . As t incre ases t i − t i − 1 ≥ t i − 1 − t , and therefo re 2( t i − t i − 1 ) ≥ ( t i − t i − 1 ) + ( t i − 1 − t ) = t i − t . (b) From (a) fo llows tha t at the time t wh en [ t i +1 , t i ] is added t i − t i − 1 ≥ ( t i − t ) / 2 . Since t i +1 − t i = ma x( t i − t, M ) the L emma follows. Theor em 4.7: For e very ε > 0 and e very time t ∗ , the maximum waiti n g time fro m the request time to the en d of a job for any req uest arriving up to time t ∗ and for a network with augmen ted resou rces, is no more than 4 /ε times the m aximum waiting time for the o ptimal algo rithm in the original network. Pr oof: Whe n creatin g a new batch, at the interval [ t n , t n +1 ] ther e are two possibilities: 1) t n +1 = t n + M , where M is the minimum time for the new jo b co mpletion. In this case, the minimu m time f or the completion of the jo b in the o riginal network would have been (1 + ε ) M . By Lemma 4.6(a ) th e total waiting time for the job h ere is at most 2 M , and theref ore the ratio of waiting times is 2 / (1 + ε ) < 4 / ε . 2) t n +1 = t n + ( t n − t ) , in this case, there e x ists a requ est among the set of tasks in batch n that according to theorem 4 .3 waits for a time of at least ( t n − t n − 1 ) . Therefo re, the m aximum waiting time in th e o riginal network is at least ε ( t n − t n − 1 ) . Since t n − t n − 1 ≥ ( t n − t ) / 2 , a nd t n +1 = t n + t n − t , it f ollows that t n +1 − t ≤ 4( t n − t n − 1 ) . Therefore, the ratio is at most 4 /ε . V . B O U N D I N G P AT H D I S P E R S I O N A. Appr oximating flows by single circuits The algorithm s presented in the pr evious sections (both greedy an d competitive), do no t limit the p ath d ispersion, i.e., the number of number of path s simu ltaneously used by a connectio n. In p ractice, it is desirable to minimize the n umber 2 ... ... ... ... 1 Fig. 3. A network demonstrati ng the optimality of L emma 5. 1. of such p aths due to th e cost of setting up many pa ths and the need to split a in to many low capacity chan nels. The following suggests a method of ach ieving this goal. Lemma 5.1 : In e very flow of size F b etween two no des on a dire cted grap h G ( V , E ) there exists a path of capacity at least F / | E | betwee n these no des. Pr oof: Remove all ed ges of capacity (strictly) less than F / | E | from th e graph . T he total capa city o f these e dges is smaller than F / | E | × | E | = F . By th e Max -Flow–Min-Cut theorem, the max imum flow e quals the m inimum cut in the network. Therefore , since the total flow is F there must remain at least on e path between the nodes after the r emoval. All edges in this path h av e capa city of at least F / | E | . T herefor e, the path capacity is at least F / | E | . Lemma 5.1 is tigh t in o rder in both | E | and | V | as can be seen for the network in Fig. 3. In th is network each pa th amounts f or only O ( | E | − 1 ) = O ( | V | − 2 ) o f th e total flow between nodes 1 and 2 . Theref ore, to obtain a flow that consists of a g iv en fraction of the maximum flow at least O ( | E | ) = O ( | V | 2 ) of paths must b e u sed. The following theorem establishes the maximum n umber of paths need ed to achieve a throug hput with a con stant factor of that achieved by th e or iginal flow . Theor em 5.2: For e very flow of size F between two no des on a directed graph G ( V , E ) and fo r e very α > 0 the re exists a set of at most ⌈ α | E |⌉ p aths achieving a flo w of at least (1 − e − α ) F . Pr oof: App ly L emma 5.1 , ⌈ α | E |⌉ times. Each time an approp riate path is foun d, its flow is removed f rom all of its links. For each such path the remainin g flo w is multiplied by at mo st 1 − 1 | E | ≤ exp 1 | E | . B. Competitive Algorithms Theorem 5. 2 provid es b oth an algo rithm for reduc ing th e number of paths and a bou nd on the thro ughp ut loss. T o approx imate the flow by a limited number of paths r emove all edg es with cap acity less than F / | E | an d find a remain- ing path. This pro cess can be repeated to o btain improving approx imations of the flow . The max imum num ber o f p aths needed to ac hieve an a pprox imation of the flow to within a constant factor is linear in | E | , while the nu mber o f p ossible paths may be expon ential in | E | . 7 (a) 8 node 9 7 8 6 5 3 4 10 1 2 0 (b) 11 node LambdaRail Fig. 4. Simulation topologies. Using th e above approxim ation in conjunc tion with the competitive a lgorithms o ne can d evise two new algo rithms BatchA llDis p an d BatchLimD isp , b ased upo n Batch All and Batch Lim re spectiv ely . These alg orithms perfo rm simi- larly to Ba tchAl l and B atchL im , in terms o f the batch ing process. Howe ver , af ter filling each b atch, the algorithms will limit the dispersion of e ach flow , and ap prox imate the flow . T o achiev e a partial flo w , each time we select the widest path from re maining edges (wher e the weig hts are determ ined by the link u tilization in the solu tion of the m ulticommo dity flo w) and reserve the total pa th bandwid th. W e repeat this un til either the desired numb er o f paths is reached or the entire flow is routed. Settin g the disper sion b ound to α | E | , Theorem 5.2 gu arantees that the time allocated for the slot will b e no more than max flow ( G, L ) / (1 − e − α ) , wher e maxflo w ( G, L ) is the origin al slot du ration. Algorithm s Batc hAllD isp and BatchL imDis p will achieve a thr ough put within a factor of 1 − e − α of the maximu m throughp ut (and will no longer be th rough put optimal as BatchA ll and B atchL im , but only throug hput competitiv e) . V I . S I M U L A T I O N S In this sectio n, we presen t simulation results illustra ting the perfor mance of the algo rithms described in this paper . While the empha sis o f the previous sections was o n the thro ughp ut optimality (or competitiveness) of our pr oposed alg orithms, here we ar e also interested in e valuating their perf ormanc e for other m etrics, especially av er age delay . A verage delay is defined as th e average time elapsing fro m the poin t a requ est is placed until the correspondin g co nnection is completed. The main points of interest are as follows: (1) how do the competitive algor ithms fare c ompared to the gr eedy approach of Section II I? (2) what value of path dispersion is needed to ensure good perform ance? It is impo rtant to emphasize that we do not expe ct the throu ghpu t op timal competitive algorith ms to always ou tperfor m the gre edy approa ch in term s o f average delay . A. Simulation Set-Up W e have written our own in simulato r in C + +. The simulator uses the COIN-OR Line ar Program So lver ( CLP) library [24] to solve multi-co mmodity optimization pro blems and allows ev aluating ou r alg orithms un der various topolog ical setting s and traffic conditions. The main simulation parameters are a s follows: • T opology: our simulator supports a rbitrary topolo gies. In this paper , we consider the two topo logies d epicted in Figure 4. One is a fu lly co nnected graph (clique) o f e ight nodes an d th e oth er is an 11-n ode topolo gy , similar to th e National Lam bdaRail testbe d [2 5]. Ea ch link on the se graphs is fu ll-duplex and assumed to hav e a capacity of 20 Gb/s. • Arrival p r ocess: we assume that the ag gregated ar riv al of requests to the network for ms a Poisson pr ocess (th is c an easily b e changed, if desired). The mean rate of arrivals is adjustab le. Our delay measurements are carr ied out at different arri val rates, referred to as network lo ad , in units of req uests per ho ur . • Fi le size distribution: W e consider two m odels for the file size distribution: 1) Pareto: F ( x ) = 1 − x m x − γ β , where x ≥ x m + γ . In the simulation s, we set β = 2 . 5 , x m = 1 . 48 TB (terabyte) and γ = 6 . 2 5 ∗ 10 − 3 TB, implying that the mean file size is 2 . 475 TB. 2) Ex ponen tial: F ( x ) = exp( − λx ) , where x ≥ 0 . In the simulations, 1 /λ = 2 . 47 5 TB. • S our ce and Destin ation : for each r equest, the sour ce and destination are selected uniformly at rand om, except that they must be dif fe rent nodes. All th e simulations are run for a tota l o f at least 10 6 requests. B. Results W e first presen t simulation results for the cliqu e topology . Figure 5 dep icts the average delay as a f unction of the network load for the algorithms Batch All an d Gree dy , assumin g a Pareto file size distribution. T he fig ure ind icates that Gree dy ’ s av er age delay in creases sharply around 140 requests/hour, while B atchA ll can sustain higher network loa d since it allocates flows more effi c iently . On the other hand, at lower load, Greedy achieves a lower average d elay than Bat chAll . This result can be explained by the fact that Greed y does not wait to establish a connection . This results illustrates the existence o f a delay-th rough put trade-off between the two algorithm s. Figure 6 compar es the p erform ance of the Bat chAll a nd BatchL im algorith ms. Th e file size distribution is exponen- tial. The figur e shows th at BatchLim is less ef ficien t than BatchA ll in term s of average delay , especially at low load . This result is somewhat expected giv e n that Batc hLim uses a less efficient batchin g process an d its delay ratio is lo oser . Howe ver , since Batc hLim is th rough put optimal, its perf or- mance ap proach es th at of BatchAl l at high load. Figure 7 e valuates and compares the perfor mance of the Batc hAll a nd Batch AllDi sp algorithm s. For BatchA llDis p , results are pr esented for th e cases where the 8 0 50 100 150 0 2 4 6 8 10 12 network load (requests/hour) average delay (hours) Greedy BatchAll Fig. 5. Performa nce comparison of algorit hms Batch All and Gree dy for the 8-node clique and Pareto file size distrib ution. 0 50 100 150 200 0 10 20 30 40 network load (requests/hour) average delay (hours) BatchAll BatchLim Fig. 6. Performance comparison of algorithms Ba tchAll and BatchLim for the 8-node clique and exponenti al file size distributi on. path disper sion bou nd is set to either 1, 3, or 5 path s per connectio n. The file size distribution is exponen tial. The figure shows also a fluid bo und o n capacity derived in [26 ]. I ts value represents an upper bound on the maximum network load fo r which the a verage delay of req uests is still bound ed. The figur e shows that Batc hAll app roaches the capacity bound at a reasonable delay value and that a path disper- sion o f 5 per connection (corr espondin g to α = 0 . 089 ) is sufficient for Batc hAllD isp to ac hieve per forman ce clo se to Ba tchAl l . It is worth mentioning tha t, in this topolog y , there exist 1957 possible paths between any two nodes. Thu s, with 5 paths, Batch AllDis p uses only 0 . 25% of th e total paths possible. The figur e also d emonstrates the imp ortance of multi- path ro uting: the perf orman ce achie ved u sing a single path per connections is far worse. Figure 8 dep icts the perfor mance of the various algorithms and the fluid b ound fo r the 11-nod e topology of figure 4( b). The file size follows a Pareto distribution. In this case, we observe that Ba tchAl lDisp with as fe w as 3 path s p er connectio n (or α = 0 . 107 ) appr oximates Ba tchAl l very 0 50 100 150 200 0 15 30 45 60 75 85 network load (requests/hour) average delay (hours) BatchAll BatchAllDisp1 BatchAllDisp3 BatchAllDisp5 Fluid bound Fig. 7. Performance ev aluation of algorithms BatchAll and BatchA llDisp with bounds 1, 3 or 5 paths per connection for the 8-node clique and expo nential file size distributio n. A fluid bound on capacity is also depicted. 0 5 10 15 20 25 30 0 5 10 15 20 network load (requests/hour) averag delay (hours) BatchAll BatchAllDisp1 BatchAllDisp2 BatchAllDisp3 Greedy Fluid bound Fig. 8. Performance ev aluati on of algori thms BatchAll , BatchAllDisp and Greedy shortest for the 11-node topology 4(b) and P areto file s ize. Algorith m BatchAllDisp is plotte d with bounds of 3, 2 and 1 on path dispersion. closely . Since th is network is sparser than the previous o ne, it is reasonable to obtain good performa nce with a smaller path dispe rsion. Ano ther ob servation is that for this top ology and the rang e of network loads under consider ation, Gr eedy outperf orms Batch All in terms o f average delay . Altho ugh BatchA ll ac hieves the optimal saturatio n thro ughp ut, its superiority over Greedy m ay only happ en at very large delays. The advantage of G reedy in this scenario can be explained by the sparsity of the u nderly ing topo logy . Seemin gly , the added efficiency in through put achieved with batching is no t sufficient to comp ensate the cost incurred by delayin g requests. V I I . C O N C L U S I O N Advance reservation o f dedicated network r esources is emerging as one of th e most im portant f eatures o f the next- generation of network architec tures. I n this pap er , we have made se veral adv an ces in this ar ea. Sp ecifically , we hav e propo sed two new on -line algo rithms for advanced reserva- 9 tion, called Batc hAll and BatchLim , that are guar anteed to achieve optimal throug hput p erform ance. W e have proven th at both algorithms ach iev e a com petitive ratio on the max imum delay until job com pletion in 1 + ε band width augmented networks. While B atchL im has a slightly loo ser compe titi ve ratio th an th at of Batch All (i.e., 4 /ǫ instead of 2 /ǫ ), it has the distinct ad vantage of compu ting the completio n time of a connectio n immediately as a request is placed. A key observation of th is p aper is that p ath disper sion is essential to a chieve full network u tilization. Howev er, splitting a transmission into too many different paths may render a flow- based app roach inapplicab le in many real-world en v ironmen ts. Thus, we have presented a rigor ous, theoretical approac h to address the path dispersion pr oblem and p resented a me thod for app roximatin g th e maximu m multicommod ity flow using a limited num ber of paths. Specifically , while th e numbe r o f paths b etween two nodes in a network scales expon entially with the nu mber of edges, we ha ve shown that thro ughpu t competitiveness up to any desire d r atio factor can b e achieved with a number of paths scaling linearly with th e total number of edges. In pr actice, our simulations in dicate th at 3 paths (in sparse graphs) to 5 paths (in dense graphs) may be sufficient. As shown in o ur simulation s, fo r some topolog ies, a g reedy approa ch m ay perf orm better than the competiti ve algorith ms, especially at low load, in sparse topolog ies, or with unco rre- lated traf fic between different p airs. Ho wever , we h ave shown that there exist scenarios where gre edy strategies can be highly inefficient. Th is can never be the ca se for the competitive algorithm s. W e con clude by noting that the algorithms pro posed in this paper can b e either run in a centralized fashion (a reasonable solution in small networks) or usin g link-state ro uting an d distributed signaling me chanism, such as en hanced versions of GMPLS [ 5] or RSVP [27]. Distributed approx imations of the m ulticommo dity flo w h av e also b een discussed extensi vely in the literature (see, e.g., [2 8–30 ]). Part of ou r future work will be to investigate these imp lementation issues into mo re detail. R E F E R E N C E S [1] “Netw ork Pro visioning and Protocols for DOE L arge- Science Appl ica- tions, ” in Pro visioning for Large-S cale Science Application s , N. S. Rao and W . R. W ing, Eds. Springer , Ne w-Y ork, April 2003, argonne, IL. [2] N.S.V . Rao and W .R. W ing and S. M. Carter and Q. Wu, “Ultra Science Net: Network T estbed for Large-Scal e Scie nce Applicati ons, ” IEEE Communicat ions Magazin e , v ol. , 2005. [3] R. Cohen and N. Fa zlollahi and D. Starobinski , “Graded Channel Reserv ation with Path Switching in Ultra High Capacit y Networks, ” in Gridnets’06 , October 2006, san-Jose, CA. [4] “On-de m and secure circui ts and advanc ed reservat ion systems, ” http:/ /www .es. net/osc ars/index.html. [5] “Dynami c resource alloca tion via gmpls optical network s , ” http:/ /dragon.maxgigapop.ne t . [6] Guerin , R. A. and Orda, A., “Networks Wit h Advance Reserv ations: The Routing Perspect ive , ” in Pro ceedings of INFOCOM’00 , March 2000, tel-A vi v , Israel . [7] N. Fazloll ahi and R. Cohen and D. St arobinski, “On the Capacity Limits of Adv anced Channel Reserv ation Architec tures, ” May 2007, proc . of the High-Speed Networks W orkshop. http://peopl e.bu.edu/staro/Starobinski- abstrac t.pdf. [8] A. Goel and M. Henzinger and S. Plotkin and E. T ardos, “Sche duling Data T ransfers in a Netw ork and the Set Scheduli ng Problem, ” in Proc. of the 31st Annual AC M Symp osium on th e Theory of Computing , 1999, pp. 189–199. [9] M. Andre ws and A. Fernandez and A. Goel and L. Zhang, “Source routing an d scheduling in pa cket network s, ” Journal of t he ACM (J ACM) , vol. 52 , no. 4, pp. 582–601, July 2005. [10] Y . Azar and J. Naor and R. Rom, “Routing strategie s for fast net works, ” in Proc. of IE EE Infocom , 1992. [11] B. A werbuch, Y . Azar , A. Fiat, S. Leonardi, A. Rosen, “On- line compet- iti ve algorit hm s for call admission in optical network s , ” Algorithmi ca , vol. 31 , no. 1, pp. 29–43, 2001. [12] Erleba ch, T ., “Call admission co ntrol for advanc e reserv ation requests with alternati ves, ” ETH, Zurich, T ech. Rep. 142, 2002. [13] S. A. Plotkin, “Competiti ve Routing of V irtual Cir cuits in A TM Net- works, ” IEEE J. on Selecte d Areas in Communication (J SAC) , vol. 13 , no. 6, pp. 1128–1136, 1995. [14] B. A werbuch, D. Holmer , H. Rubens, and R. D. Kleinber g, “Pro vably competit ive adapti ve routing. ” in INFOCOM , 2005, pp. 631–641. [15] S. Leonardi, “On-l ine netw ork routing. ” in Online Algori thms , 1996, pp. 242–267. [16] A. Goel, M. R. Henzi nger , and S. A. Plotkin, “ An online throughput - competit ive algorithm for multicast routin g and admission control . ” J . Algorithms , vol. 55, no. 1, pp. 1–20, 2005. [17] Ganja li, Y . and Kesha varzia n, A. and Shah, D., “Input Queued Swit ches: Cell Switching vs. Packet S witchin g, ” in Pr oceedings of INFOCOM’03 , March 2000, san-Fanc isco, CA, USA. [18] W eichenbe rg, G. and Chan, V . W . S. and M ´ edard, M., “On the Ca- pacit y of Optical Networks: A Framew ork for Comparing Differe nt Tra nsport Architectu res, ” in Proce edings of INFOCOM’06 , March 2000, barcel ona, Spain. [19] E. Gust afsson and G. Karlsson, “ A Literat ure Surve y on Traf fic Disper - sion, ” IEEE Network , vol. 11 , no. 2, pp. 28–36, March-April 1997. [20] J. Shen and J. Shi and J. Crowc roft, “Proac tiv e Multi-pat h Routing , ” Lect. Notes in Comp. Sci. , vol. 2511 , pp. 145–156, 2002. [21] R. Chow and C. W . Lee and and J. C. L. Liu, “T raffic Dispersion Strate gies for Multimedi a Streami ng, ” in Pr oceedings of the 8th IEE E W orkshop on Futur e T rends of Distribute d Computing Systems , 2001, p. 18. [22] F . Shahrok hi and D. W . Matula, “The Maximum Concurrent Flow Problem, ” Journal of the ACM (J ACM) , vol. 37 , no. 2, April 1990. [23] T . Leighton and S. Rao, “Multico m modity max-flo w min-cut theorems and thei r use in designing approximation algorithms, ” Journal of the ACM (J ACM) , vol. 46 , no. 4, pp. 787 – 832, Nove m ber 1999. [24] “Coi n-Or proj ect, ” http://www .coin-or .org/. [25] “Nat ional L ambdaRail Inc.” http://www .nlr .net/. [26] N. Fazloll ahi and R. Coh en an d D. Starobinski, “On the Capacity Limits of Adv anced Channel Reserv ation Architecture s, ” in Pr oc. of the High- Speed Networks W orkshop , May 2007. [27] A. Schill and S. Kuhn and F . Breite r, “Resourc e Reserva tion in Ad- v ance in Heterogeneo us Networks with Parti al A T M Infrastruc tures, ” in Pr oceedings of INFOCOM’97 , April 1997, kobe, Japan. [28] B. A werbuch and T . L eighton, “Improved approximation algorithms for the multi-commodit y flow problem and local competiti ve routin g in dynamic networks, ” in P r oceedings of the twenty-sixth annual A CM symposium on Theory of computing (STOC) , 1994, pp. 487 – 496. [29] A. Ka math and O. Pa lmon and S. Plotkin, “Fast a pproximation algorithm for minimum cost multi commodity flo w, ” in Pr oc. of the sixth ACM- SIAM Symposium on the Discre te Algorithms (SOD A) , 1995, pp. 493– 501. [30] B. A werbuch and R. Khande kar and S. Rao, “Distribut ed Algorithms for Multicommodit y Flo w Problems via Approximate Steepest Descent Frame work, ” in Pr oceedings of the ACM-SIAM symposium on Discret e Algorithms (SODA) , 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment