Linear Time Algorithms Based on Multilevel Prefix Tree for Finding Shortest Path with Positive Weights and Minimum Spanning Tree in a Networks
In this paper I present general outlook on questions relevant to the basic graph algorithms; Finding the Shortest Path with Positive Weights and Minimum Spanning Tree. I will show so far known solution set of basic graph problems and present my own. …
Authors: David S. Planeta
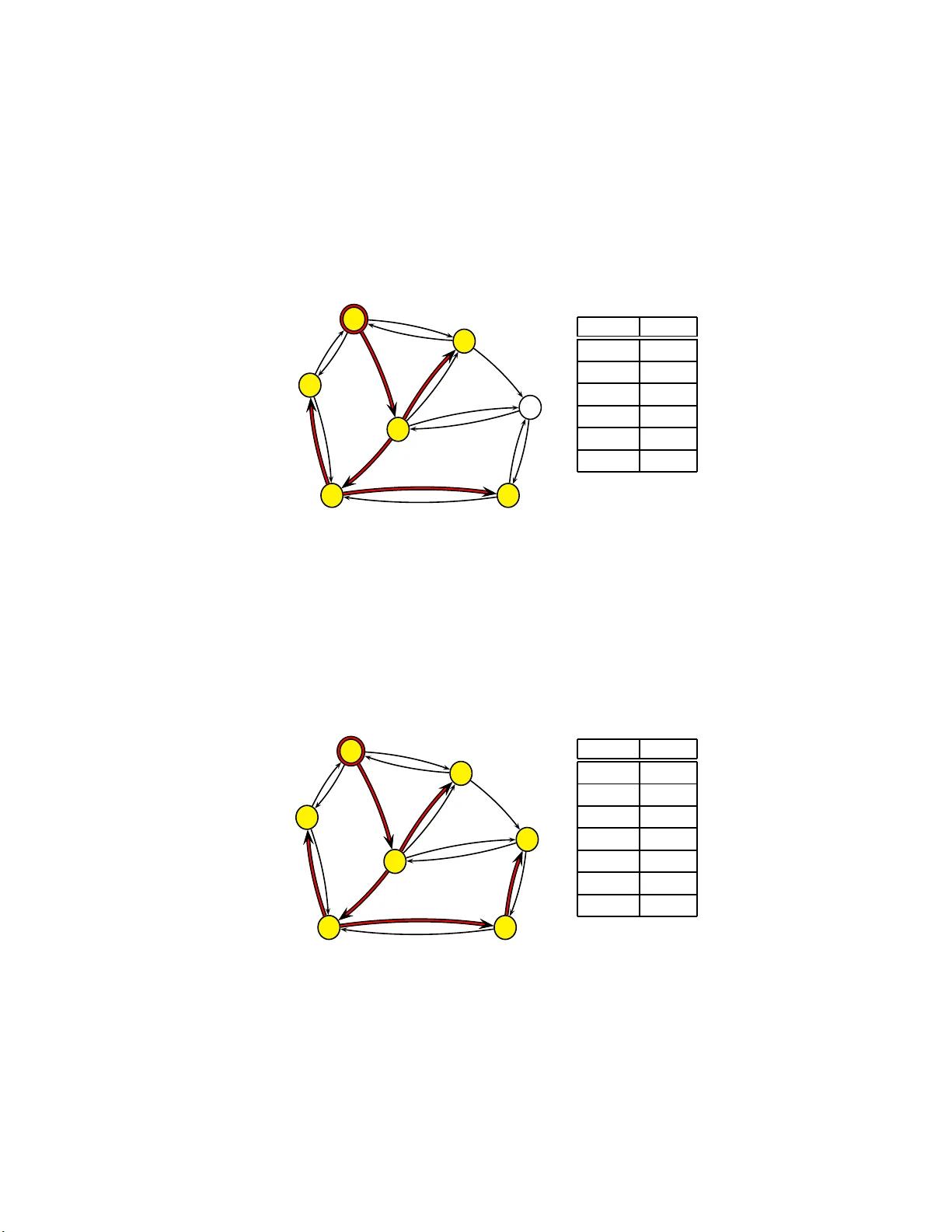
Linear Time Algorithms Based on Multilev el Prefix T ree for F inding Shortest P ath with P ositive W eigh ts and Minim um Spanning T ree in a Net w orks ∗ Da vid S. P laneta † No v em b er 15, 2018 Categori es and Sub ject Descripto rs 1 : C.2.1 [Compute r-C ommunication Net work]: Net work Arc hitecture and Design–Distributed ne tw orks E.1 [Data St ructures]: Graphs and net w orks F.2.2 [Analysis of Algorithms a nd Problem Complexit y]: Nonnumerical Algorithms and Problems G.2.2 [Discrete Mathe matics]: Graph Theory–trees General T erms: Algorithms, Net works Additional Key W ords and Phrases: Minimal Spanning T ree, the Shortest P ath, Single-Source Shortest P ath, Single-Destination Shortest Path, MST, SSSP , SDSP Abstract In this paper I presen t general outlook on questions rele v ant to the basic graph algorithms; Finding the Sh ortest Path with Po sitive W eigh ts and Mini- mum Sp anning T ree. I will show so far known solution set of basic graph prob- lems and presen t my ow n. My solutions to graph problems are characterized b y their linear worst-case time complexity . It should b e noticed that the algorithms whic h compute the Shortest P ath and Minim um Spanning T ree problems n ot only analyze the weig ht of arcs (which is the main and often the only criterion of solution hith erto know n algorithms) but also in case of identical path wei ghts they select this path w hich wal ks through as few v ertices as possible. I h a ve presented algorithms which use priorit y queue based on multilev el prefix tree – PT rie. PT rie is a cl ever com bination of the idea of prefix tree – T rie, the structure of logarithmic time complexit y for insert and remo ve operations, doubly link ed list and queues. In C++ I will implemen t linear worst-case time algori thm com- puting the Single-Destination Shortest-Paths problem and I wi ll explain i ts usage. ∗ Cornell U ni v ersity Computing and Information Science T echnical R eports [29] † dplaneta@gmail.com 1 The ACM Computing Classification System 1 1 In tro duction Graphs are a p erv asive da ta structure in computer science and a lgorithms for work- ing with them a re fundamental to the fie ld. There are h undreds of in teresting com- putational problems defined in ter ms of g raph. A lot of really complex pro cess es can b e solved in a very effective and clear wa y b y means of ter ms o f gr aph. Algo- rithms which solve graph pro blems are implemented in many appliances of ev eryday use. They help flig h t co ntrol system to administer the airspa ce. They are crucial for economists to do market research, mathematicians to so lv e complicated prob- lems. And finally , they help progr ammers des c ribe ob ject connections. E v ery day , many peo ple tr ust g raph a lg orithms when they , implemen ted in GPS system, ca lcu- late the shortest way to their destination. There a re many basic graph algor ithms, whose computatio na l complexity is of greatest imp ortance. They include alg orithms on directed graphs finding Single-Source Shortest Path with p ositive w eights (SSSP) and Minimum Spanning T r ee (MST) [Figur e 1]. Based on m ultilevel prefix tree (PT rie [28]) I co mpute these pr o blems in linear worst-case time and in cas e of iden tical path w eights it s elects those paths w hich walk through as few vertices as poss ible. Figure 1: Difference b et ween MST and SSSP pr oblems Minimum Spanning T ree Single-Source Shortest Path A B C D E F G 1 4 3 6 1 4 2 2 1 1 5 A B C D E F G 1 4 3 6 1 4 2 2 1 1 5 1.1 Previous w ork ab out MST Algorithm computing MST problem is frequen tly used by administrators , who think how to construct the framework o f their net works to connect all ser v ers in whic h they use as little optical fib er as p ossible. Not only computer engineers use algorithms based on MST. Architecture, electronics and many other different area s take adv an- tage o f algorithms using MST. The MST pr o blem is one of the oldest and most basic graph problems in computer science. The first MST algo rithm was disc overed b y Bor ˚ uvk a [5] in 19 26 (see [26] for an English translation). In fact, MST is pe r haps 2 the oldest op en pr oblem in computer science. Krusk al’s algorithm was rep orted b y Krusk al [25] in 19 5 6. The a lgorithm co mmonly known as Prim’s a lgorithm was in- deed in ven ted by Pr im [31] in 1957, but it was als o in ven ted earlier b y V o jtech Ja rn ´ ık in 19 30. Effective notation of these algorithms r equire O ( | V | l og | E | ) time, where | V | and | E | denote, respectively , the num b er o f vertices and edges in the gr aph. In 19 75, Y ao [35] first improved MST to O ( | E | l og l og | V | ), w hich starts with all no des as fra g - men ts, extends each fragment, then combines, then extends e a c h of the new enlarged fragments, then combin es again, and so forth. In 1 985, using a com bination o f the ideas from Prim’s algo rithm, Krusk al’s alg orithm a nd Bor ˚ uvk a ’s a lg orithm, together, F redman and T a rjan [15] g iv e on algorithm tha t runs in O ( | E | β ( | E | , | V | )) using Fi- bo nacci heaps, where β ( | E | , | V | ) is the n umber o f lo g iterations on | V | needed to make it less tha n | E | | V | . As an a lternative to Fibonacc i heaps we ca n use insignifi- cantly improved Relaxed heaps [12]. Relaxed heaps als o hav e some adv an tages ov er Fibo nacci heaps in par allel algorithms. Sho rtly after, Gabow, Galil, Sp encer, and T ar- jan [17] improv ed this algorithm to run in O ( | E | l og β ( | E | , | V | ). In 19 99, Cha zelle [7] takes a significant step to wards a solutio n and charts out a new line of attack, gives on algo r ithm that runs in O ( | E | α ( | E | , | V | )) time, where α ( | E | , | V | ) is the function inv erse o f Ack ermann’s function [33]. Unlike previous a lgorithms, Chazelle’s algo- rithm do es not follow the greedy metho d. In 1994, F redman and Willard [16] showed how to find a minimum spanning tree in O ( | V | + | E | ) time using a deterministic al- gorithm that is not comparison based. Their alg orithm assumes that the data are b -bit in tegers and that the computer memory c onsists of addres s able b -bit w ords . A g reat many of so far inv ented implementations a ttain linea r time on average runs but their worst-case time complexity is higher. The in ven tion of versatile a nd pra ctice algorithm running in linear worst-case time still re mains a n ope n problem. F o r decades many resear c hers hav e b een try ing to do find linear worst-case time alg o rithm so lving MST problem. T o find this algor ithm r esearchers start with Boruv k a’s alg o rithm and attempt to make it r un in linear worst-ca s e time b y fo cusing o n the structures use d b y the algo r ithm. 1.2 Previous w ork ab out SSSP The Single-So urce Shortest Path o n directed graph with po sitive weight (SSSP) is o ne of the most bas ic gr a ph problems in theo retical co mputer s cience. This problem is also one of the most natura l netw ork optimization problems and o c curs widely in prac tice. SSSP pro ble m co nsists in finding the shor test (minimum-w eight) path from the source vertex to every other v ertex in the g raph. The Sh or tes t Paths algorithms t ypically rely on the pr oper t y that the shor test path b etw een tw o vertices contains other short- est paths within it. Algorithms computing SSSP problem are used in considera ble amount of a pplications. Star ting from ro ck et soft ware and finishing with GPS inside our cars. In m any programs algorithm computing SSSP problem is a part o f bas ic data analysis. F or example, itineraries , flig h t schedules and other transp ort s ystems can b y presented as netw orks, in which v arious shortest path problems ar e very im- po rtant. W e many aim a t mak ing the time of fligh t b etw een tw o cities as short as 3 po ssible or a t minimizing the costs. In such netw orks the ca s ts may concern tim e, money or some other r esources. In these net works particular resource s don’t hav e to be dep endent . It should be no ted that in reality price of the tic ket may not b e a simple function of the distance b etw een t wo cities - it is quite common to trav el cheaper by taking a ro unda bout route nether than a direct one. Such difficulties ca n b e o vercome by means of a lgorithms solving the shortest path problems. Algorithm computing SSSP problem a re often used in real time systems, where is of great imp ortance ev- ery second. Lik e OSPF (op en shor test path first) [27] is a well known real-world implemen tation o f SSSP algorithm used in internet routing. That’s why time the ef- ficiency o f alg orithms computing SSSP problem is very imp ortant. By reversing the direction of each edge in the graph, we receive Single-Destination Shortest-Paths prob- lem (SDSP); the Shortest Path to a given destinatio n source vertex from each v ertex. Dijkstra’s alg orithm was in v ented b y Dijkstra [11] in 195 9, but it contained no men tion o f priority que ue, needs O ( | V | 2 + | E | ) time. The running time of Dijkstra’s algorithm dep ends on how the min-prior it y queue is implemented. If the graph is suffi- ciently spars e - in particular, E = o ( | V | 2 lg | V | ) - it is practical to implement the min-pr iority queue with a bina r y min-heap. Then the time of the algor ithm [2 2] is O ( | E | l og | V | ). In fact, w e can achiev e a r unning time of O ( | V | l g | V | + | E | ) b y implement ing the min- priority q ue ue with Fib onacci hea p [15]. Historically , the developmen t of Fib onacci heaps was motiv ated by the observ ation that in Dijkstra’s algorithm there are, t ypi- cally , many more decrease- key calls than extract-min calls, so a n y method of r e ducing the amortized time of each decrease-key op eratio n to o ( l g | V | ) without incr e asing the amortized time of extra ct-min would yield on asymptotica lly fa s ter imp lementation than with binary heaps . But Go ldberg and T a rjan [20] o bserved in pr actice and helped to explain wh y Dijkstra ’s co des based o n binary heaps p erform b etter than the ones based on Fib onacci heaps. A num ber of faster alg o rithms hav e b een developed on more powerful RAM (random access machine) mo del. In 1990, Ahuj a, Mehlhorn, Orlin, and T arjan [1] give on alg orithm that runs in O ( | E | + | V | √ l og W ), where W is the largest weigh t of an y edge in gr aph. In 200 0, Thor up [34] gives on O ( | V | + | E | l og l og | V | ) time algor ithm. F as ter approa ches for s omewhat denser g raphs have been pro pos ed by Rama n [32] in 199 6 . Raman’s a lgorithm req uire O ( | E | + | V | p l og | V | l og l og | V | ) and O ( | E | + | V | ( W ∗ l og | V | ) 1 / 3 ) time, r espec tively . How ever Asano [2] shows, the algo rithms don’t p erform w ell in practical simulations. The classic lab el-correcting alg orithm of Bellman-F ord is base d on separate algorithms by Be llma n [3], published in 19 58, and F ord [14], published in 1956 [13], and all of its improv ed deriv atives [8][10][30][19][4] need Ω( | V | ∗ | E | ) time in worst time. How ever in case of g raph with ir rationally heavy weigh t of edges algorithm’s may p ossibly equa l O (2 | V | ) time cos t [1 8]. But Bellman- F ord algo rithm no t only co mputes the single-s ource s ho rtest path with pos itive weigh ts, but also so lv es the s ingle-source shor test pa th problem in the general cas e in whic h edge weigh ts may b e negative. The Bellman-F ord alg orithm returns a bo olea n v a lue indicating whether or not there is a nega tiv e-weight cycle that is r eachable fro m the source. If there is such a cycle, the algorithm indicates that no solution exists. If there is no such cycle, the algor ithm pr oduces the Sho rtest Paths and their weigh ts. 4 2 Linear w orst-case time algorithms based on m ul- tilev el prefix tree computing the basic net w ork problems I show alg orithms which use priority queue ba sed on multilev el pr efix tree – PT rie [28]. PT rie is a clev er c om bination of the idea of prefix tree - T r ie [6], the structure of log - arithmic time complexity for insert and remov e o p era tions, doubly linked list [2 3] a nd queues [23]. I assume that algo r ithms whic h I present the w eight of edges is constan t. The weigh t of edges are in { 0 , . . . , 2 t − 1 } , wher e t denotes the word leng th (size o f ). F o r all edges of gra ph G = ( V , E ) the co nstan t v alue t max can b e matched. In other words, I as sume that the size of type which remembers the weight of edges is constant and ident ical for a ll edges of gr aph G = ( V , E ). 2.1 PT rie: Priority queu e based on m ultilev el prefix tree Prior ity T rie (P T rie) uses a few structures including T r ie o f 2 K degree [6], whic h is the structure cor e . Data recor ding in PT rie consists in brea king the word into parts which make the indexes o f the following lay ers in the structure (table lo ok- at). The last lay ers contain the addresse s of doubly link ed lis t’s no des. Each of the list no des stores the queue [2 3], in to which the elements are inser ted. Moreov er, each lay er contains the structure of lo garithmic time complexit y of insert and remov e op eratio ns. Which help to define the destina tion of data in the doubly link ed list [23]. 2.1.1 T erminology Bit pattern is a set of K bits. K (length of bit pattern) defines the num b e r of bits which a re cut off the binary word. M defines num ber (length) of bits in a bina ry word. v alue of word = M z }| { 101 ... 1 | {z } K 00101 ... N is num b er of all v alues of PT r ie. 2 K is v ariation K of element binar y set { 0 , 1 } . It determines the n umber of g roups (num ber of Lay ers [Figur e 2]), which the bit pattern may b e divided into during one step (one level). The set o f v alues decomp osed into the group by the firs t K bits (the version of algorithm describ ed in pap er was implemented by machine of little- e ndian type). The path is de fined starting from the most imp ortant bits of v ariable. The v alue of pattern K (index) determines the layer we mov e to [Figure 3]. The low est la yers determine the no des of the list whic h s tore the queues for inserted v alues . L defines the level the lay er is on. Probability that exactly G k eys corres p ond to one particular patter n, where for each of P L sequences of leading bits there is such a no de that cor resp onds to a t least t wo k eys equals N G P − GL (1 − P − L ) N − G 5 Figure 2: Lay er A C B D . . . log 2 P = l og 2 2 K = K The Structure of log- arithmics time com- plexit y of insert and remov e op erations MIN MAX 00 .... 00 G 1 00 ... 01 G 2 . . . 11 ... 11 G P P = 2 K Figure 3: PT rie A C B D . . . Θ( log 2 2 K ) = O ( K ) Lay er MIN MAX 00 .... 00 G 1 00 ... 01 G 2 . . . 11 ... 11 G P P = 2 K Lay er Lay er Lay er . . . . . . . . . . . . . . . . . . . . . . . . Θ( log 2 K N ) = Θ( lgN lg 2 K ) = O ( M K ) L 1 L 2 L log 2 K N N ode Queue N ode Queue N ode Queue N ode Queue N ode Queue T ail Head 6 F or rando m PT rie the a verage num b er of layers on level L , for L = 0 , 1 , 2 , . . . is P L (1 − (1 − P − L ) N ) − N (1 − P − L ) N − 1 If A N is av erage num ber o f layers in r andom PT rie of degree P = 2 K containing N keys. Then A 0 = A 1 = 0 , and for N ≥ 2 we get [24]: A N = 1 + X G 1 + ... + G P = N N ! G 1 ! . . . G P ! P − N A G 1 + . . . + A G P = 1 + P 1 − N X G 1 + ... + G P = N N ! G 1 ! . . . G P ! A G 1 = 1 + P 1 − N X G N G P − 1 N − G A G = 1 + 2 G (1 − N ) X G N G 2 G − 1 N − G A G 7 2.1.2 Implementation Op eration Description Bound create Creates ob ject O (1) insert(data) Adds element to the structure. O ( M K + K ) bo ole a n remov e(data) Remov es v alue from the tre e . If op eration failed beca use ther e w as no suc h v alue in the tree it r e- turns F ALSE(0), otherw is e returns TRU E(0). O ( M K + K ) bo ole a n search(data) Lo oks for the words in the tr ee. If finds return TRUE(1), other wise F ALSE(0 ). O ( M K ) *minimum () Returns the addr ess of the lowest v alue in the tree, or empt y addr ess if the op eration failed b ecause the tree was empty . O (1) *maximum() Returns the address of t he highes t v alue in the tree or empty addr ess if the op eration failed b ecause the tree was empty . O (1) next Returns the a ddr ess of the next no de in the tree o r empty address if v alue transmitted in par ameter w as the greatest. The or der of mo ving to successive elements is fixed - from the smallest to the lar gest a nd from “the youngest to the oldest” (stable) in case of identical words. O (1) prev Similar to ‘nex t’ but it retur ns the address of preceding no de in the tree. O (1) Basic op eratio ns can be joined. F or example, the effect connected with the heap; delete-min() can b e repla c ed b y op erations re move(minim um()). Insert Determine the interlink ed index (p oin ter) to ano ther layer using the length of pattern pro jecting on the word. If interlink determined by index is not empty and indicated the list node – try to insert the v alue into the queue of determined node. If the element s in the queue turn out to b e the same, insert v a lue into the queue. Otherwise , if elemen ts in the queue ar e differen t fro m the inserted v alue, the no de is “pushed” to a low er level and the hitherto existing level (the place of node) is com- plement ed with a new la yer. Next, try again to insert the element, this time how ever, int o the new ly created lay er. Else , if the interlink determined b y index is empty , insert v alue of index in to the ordered binar y tree from the current layer [Figure 4]. F ather of a newly crea ted no de 8 in ordered binar y tree from the current lay er determines the place for leav es; If the newly created no de in ordered binary tree is on the righ t side of father (added index > father index), the v alue added to the list will b e inserted after the no de determined by father index a nd the path o f the highest indexes (mak e use of p oin ter ‘max’ of the lay ers – time cost O (1)) o f lo wer lev el lay ers. If newly crea ted node is on the left s ide of f ather (added index < father index ), the v alue added to the list will be inserted be fore the no de determined b y father index and the path of the smallest in- dexes (make use of po in ter ‘min’ of the lay ers – time cost O (1)) o f lower level layers. One can wonder wh y we use the q ueue and not the stack or the v a lue counter. V a lue Figure 4: Insert v alue of index into the ordered binar y tree from the lay er A C B D La yer insert(index) < < < . . . MIN MAX 00 .... 00 00 ... 01 . . . 11 ... 11 counter cannot b e used b ecause c omplex elements can b e inserted into P T rie structure, distinguishable in the tree only b ecause of some words. Also, it is not a goo d idea to use a sta c k becaus e the queue makes the structure stable. And this is a very useful characteristic. I used “plain” Binary Sear c h T r e e in the structure of loga rithmic time complexity . F or a small n umber of tree no des it is a very go o d solution b ecause for K = 4, 2 K = 16. So in the tree there may be maximum 16 (different) elemen ts. F or such a sma ll amount of (different) v alues the re ma ining ordered t rees will pr obably turn out to be a t mos t a s effectiv e a s un usually simple Binary Search T re es. Analysis: In case o f ra ndo m data it will take Θ( lgN lg 2 K ) = Θ( l og 2 K N ) = O ( M K ) goings through layers to find the place in the heap core – T rie tree. On at least o ne layer o f PT rie structure w e will use inserting in to the ordered binary tr ee in which max im um nu mber of no des is 2 K . While inser ting the new v alue I need infor mation where exactly it will b e lo cated in the list. Suc h information ca n be obtained in tw o wa ys; I will get the infor mation if the representation of the neares t index on the list is to the left or to the right side o f the inserted word index. It ma y happ en that in the structure there is already is exactly the same word as the inserted one. In such case v alue index won’t b e inserted into any lay er of the PT rie b ecause it will not b e neces sary to add a new no de of the list. V alue will be inser ted in to the queue of already existing no de. T o sum up, while moving through the lay ers of PT rie w e can stop at some lev el b ecause of empty index. Then, a no de will b e added t o the list in pla ce deter mined b y binar y search 9 tree and the remaining part of the path. This is why the b ound of op eration which in- serts ne w v alue into PT rie equals Θ( l og 2 K N + l og 2 2 K ) = Θ( l og 2 K N + K ) = O ( M K + K ). Find Metho d find like in case of plain T rie trees go es thr o ugh succeeding lay ers following the path determined b y binary repr esen tation of search v a lue. It ca n b e stated that it uses num b er key as a guide while moving down the core of PT rie – pr e fix tree. In case of searching tr e e things can happ en: • W e don’t reach the no de of the lis t b ecause the index we determine is e mpty on any of la yers – sea r c hing failure. • W e reach the node but v alues from the queue are different fr om the sear c hed v alue – searching fa ilure. • W e reach the no de and the v alues from the queue are exactly like the ones we seek – s earching success. Analysis: Searching in prefix tree is very fast b ecause it finds the w ords using w ord key as indexes. In case of search failure the longest match of a s earched word is found. It m ust b e taken into consideration that during opera tion ‘s earch’ we use only the attributes of prefix tre e. T his is why the amount o f sea rch num b ers lo oked through during the ra ndom sea rch is Θ( l og 2 K N ) = O ( M K ). Remov e Remov e metho d just like find metho d “moves down” the PT rie structure to seek for the element to b e deleted. If it do esn’t reach the no de of the list, or it does but the search v alue is different from the v alue of no de queue, it do es no t delete any element of PT rie b ecause it is not ther e. How ever if it reaches the no de of the lis t and search v alue turns out to b e the v alue from the queue – it remov es the v alue from the queue. If it remains empty after removing the element from the queue the no de will b e r emo ved from the list and will return to the “upp er” la yers of pr efix t ree to delete poss ible, remaining, empt y la yers. Analysis: Since it is poss ible no t only to go down the tree but also come bac k up- wards (in ca se of deleting of the lower la yer or the no de of the list) the total leng th of the path mov e on is limited Θ(2 log 2 K N ). If delete the layer, it means there was only one w ay down fr o m that layer, whic h implicates the fact that the o rdered bi- nary tree of a given la yer con tained only one no de (index). The lay er is r emov ed if it remains empt y after the remov al of no de from ordered binary tree. So the nu mber of op eratio n necess a ry for the remov al of the lay er containing one elemen t equals Θ(1 ). In c a se of remov al o f lay er L i , if orde r ed binary tree of higher level lay er L i − 1 , despite removing the node which determines empty lay er we came from, do es not r emain empt y it means that there could b e maximum 2 K no des in the or- dered binary tree. Oper ation of v alue delete fro m ordered binary tree amounts to Θ( l og 2 2 K ) = Θ( K ). There is no p oint of “climbing” up the upp er lay ers, since the lay er w e came from would not be empty . A t this sta ge the method remov e ends. T o sum up, worse time co mplexit y o f remov e op eration is Θ(2 l og 2 K N + K ) = O ( M K + K ). 10 Extract min i m um and maximum If the list is not empt y , ‘minimum’ r eads the v alue p oint ed by the hea d o f the lis t a nd ‘Maximum’ rea ds the v alue p ointed by the ta il of the list. Analysis: Time complexity of opera tions is Θ(1). Iterators The no des o f the list are link ed. If we know the p osition of o ne of the nodes , we hav e a direct access to its neig h b ors. The ‘next’ o per ation reads the successor of current po in ted no de. The ‘prev’ op eration re ads the predecessor of currently pointed no de. Analysis: Moving to the no de its neighbor requires only reading of the con tents of the p oint er ‘next’ or ‘prev’. Time complexity o f such op erations equals Θ (1). 2.1.3 Correctness PT rie ha s b een designed like this, so as no t to assume that keys hav e to b e p ositive nu mbers o r only integers - they ca n be even str ing s (ho wev er, in most cases the w eight of ar cs is represe n ted by num be r s). T o inser t PT rie negative and p ositive in teger s I use not one PT rie, but tw o! One of the structures is destined exclusively fo r storing p ositive int eger s and the other one for stor ing only nega tiv e integers. The latter structure of PT rie is resp onsible only for negative integers - the int eger s a re stor ed in reverse o rder on the list (for machine of little-endian type). Therefore in case of the second structure of PT rie (respo nsible only for nega tiv e int eger s) I used standard op eration of PT rie: PT rie2.ma x im um to e x tract the smalles t v alue. Also real num bers (for example in ANSI IEEE 754-198 5 sta ndard [2 1]) ca n be used of the description o f the weigh t of arcs on condition that t w o interrelated structur es of P T rie will b e used to put off ex ponent and mantissa. It is p ossible, be c ause implementation of PT rie [28] described by me uses queue, which makes it stable. One of the structures of PT r ie ser v es as storag e for exp onen t, wher e each of the no des of the list will cont ain additiona l structure of PT rie to store mantissa. 2.1.4 Conclusion Efficiency of P T rie considerably depends o n the length of pattern K . K defines op- tional v alue, whic h is the power of t wo in the range [1, min( M )]. The total size o f necessary memory b ound is propo rtional to Θ( log 2 K N (2 K +1 ) K ) b e c ause the num b er of lay ers required to remember N random elements in PT rie of degr ee 2 K equals lgN lgP ∗ P . Moreov er, each lay ers has tree of maximum size 2 K no des and table of the P -elements, so the necessa ry memory b ound equal Θ( l og 2 K N ∗ 2 P ) = Θ( M K ∗ 2 K +1 ). F or data t yp es of constan t size max im um T rie tree height equals M K . So the pessimistic op eratio n time complexity is O ( M K + K ). F or example, for four-byte n um b ers it is the most effective to determine the pa tter n K = 4 bits lo ng. Then, the pes simistic nu mber o f steps necessa ry for the o pera tion on the PT rie will equal Θ( M K + K ) = 32 4 + 4 = 12. Increasing K to K = 8 doe s not increa se the efficiency of the structure o pera tion bec ause Θ( M K + K ) = 32 8 + 8 = 12. What is more, in will unnecessa rily increase 11 the memory demand. A single lay er consisting of P = 2 K groups for K = 8 will contain tables P = 2 8 = 2 56 long, not when K = 4, only P = 2 4 = 1 6 links. F or v ariable size data the time complexity equals Θ( l og 2 K N + K ). Moreov er, the length of pattern K must b e car e fully matc hed. F or exa mple, for strings K should not b e longer than 8 bits beca use w e could accidentally re ad the con tents from b eyond the string which norma lly consist of one- b yte sign! It is p ossible to r ecord data of v ari- able size in the structur e provided each of the analyzed words will end with identi- cal k ey . There are no obstacles for strings because they normally finish with “end of line” sign. Owing to the reading of word keys and going thro ug h indexes (table lo ok-at), primary , partial operatio ns of PT r ie metho d are very fast. If w e ca refully match K with data type, PT rie w ill ce rtainly serve as a really effective Prio rity Queue. 2.2 Linear time algorithm finding the Minimal Spann ing T ree (MST) Definition 2. 2.1 (MST [9]) L et G = ( V , E ) b e a c onne cte d, weighte d, undir e cte d gr aph . Any e dges of gr aph G = ( V , E ) have a weight function w : E → R . Sp anning tr e e of G is a sub gr ap h T which c ontains al l of the gr aph’s vertic es. The weight of a sp anning t r e e T is the sum of the weigh ts of its e dges: w ( T ) = X E ∈ T w ( E ) A minimu m sp anning tr e e of G = ( V , E ) is acyclic subset T ⊆ E that c onne cts al l of the vertic es and whose total weight is minimize d [Figure 5] . Figure 5: The Minimum Spinning T ree of G = ( V , E ) w ( M S T ) = 19 A B C D E G F H I J K 3 5 2 8 1 7 4 5 1 6 2 4 4 2 1 3 1 1 3 6 2 12 Let A b e a subs e t o f E that is included in some minimum spanning tree for G = ( V , E ). Jarnik-P rim’s algorithm has the pr oper t y that the edges in the set A always form a single tree. The tree starts from a n arbitrary source vertex s and grows until the tree spans all the v ertices in V . At eac h step, a light edge is added to the tree A that connects A to an isolated vertex of G A = ( V , A ). With the pro of o f Ja rnik-Prim’s algorithm follows that b y using this rule adds only edg es tha t are safe for A ; therefore, when the algorithm terminates, the edges in A form a minim um spanning tree. This strategy is greedy since the tree is augmented at e ac h step with an edge that contributes the minimum amount p ossible to the tre e ’s weight . The key to implementin g Jar nik- Prim’s algorithm efficiently is to make it e a sy to select a new edge to b e added to the tree for med by the edges in A . The p erformance of Jarnik-Pr im’s algo rithm dep ends o n how we implement the min-prio r it y queue Q . If Q is implemen ted a s a binary min-hea p, the total time for Ja rnik-Prim’s algor ithm is O ( | V | l og | V | + | E | l og | V | ) = O ( | E | l og | V | ). Lemma 2.2. 2 U sing t he priority qu eu e b ase d on mu ltilevel pr efix tre e (PT rie) to im- plement the min-priority queue Q , the running time of J arnik-Prim’s algorithm im- pr oves to running worst time O ( | E | + | V | ) . Pro of: Algorithm cr osses the gra ph a dding one edge to subset T . All the edges a r e inserted to PT rie – the str ucture w orking as the pr iority queue. In algor ithm we use three op erations of PT r ie: insert, extract-min and decrea se-key . Insert and decrease- key are c haracterize d by Θ ( M K + K ) time complex it y , whe r e M is the leng th of k ey required to r emem b er the weight o f edge and K is co nstan t defined by progra mmers as the v alue of function w ( K ) = ( M K + K ) is minimized. Time complexity of extract- min is constant Θ (1). If we use PT rie to s et a success iv e arc s app ending to s ubset T , by means of Jarnik- P rim’s metho d, we gain time complexity whic h a moun ts to Θ( | V | + | E | ∗ w ( k )). Let’s assume tha t the size of w ord (w ord length) needed to remember the weigh t o f arcs is co ns tan t for all arc s of the gra ph G = ( V , E ), then function w ( k ) is constant. W e can calculate minimum co efficient of min { w ( k ) } by matching suitably K with M . Therefore time co st eq uals Θ( | V | + | E | ∗ m i n { w const ( k ) } ) = O ( | V | + | E | ), where co efficien t equals mi n { w ( k ) = ( M const K + K ) } . 2.3 Minim um-w eigh t and minimal- v ertex-amoun t path algo- rithm with positive w eigh ts on directed graph in linear w orst-case time (SSSP) Definition 2. 3.1 (SSSP [9]) In a Single-Sour c e shortest- p aths with p ositive weights pr oblem, we ar e given a weighte d, dir e cte d gr aph G = ( V , E ) , with weight funct ion w : E → R + mapping e dges to p ositive re al-value d-weights. The weigh t of p ath p = < v 0 , v 1 , ..., v k > is the sum of the weig hts of its c onstituent e dges: w ( p ) = k X i =1 ( v i − 1 , v i ) 13 We define t he shortest-p ath weight fr om u to v by δ ( u, v ) = min { w ( p ) : u p v } path from u to v is not exist A shortest p ath fr om vert ex u to vertex v is then define d as any existing p ath p with weight w ( p ) = δ ( u, v ) [Figure 6]. Figure 6 : The Single- Source Shortest Path on directed g raph G = ( V , E ) for different source vertex s SSSP on G = ( V , E ) , when s = B SSSP on G = ( V , E ) , when s = C A B C D E 2 2 5 1 2 1 1 1 2 1 A B C D E 2 2 5 1 2 1 1 1 2 1 Dijkstra’s algorithm maintains a set S o f vertices w ho se final shortest-path w eights from the source s hav e already b een determined. The algo r ithm rep eatedly selects the vertex u ∈ V − S with the minimum shor test-path estimate, adds u to S , and relaxes all edges lea ving u . The running time of Dijkstra ’s algorithm depends on how the min-priority queue is implemen ted. The perfor mance of Dijkstra ’s algo rithm dep ends on how we implement the min-pr iority queue Q . If Q is implemented as a binary min- heap, the total time for Dijkstra’s algorithm is O (( | V | + | E | ) log | V | ) = O ( | E | l og | V | ). The quest fo r linear worst-case time Single-Source Shortest P ath Algorithm on arbitrar y directed g raphs with p ositive arc weigh ts is on ongoing hot r esearch topic. Algorithm which I present not o nly finds minimum-w eight path (shor test), but also makes the path w alk through as few v ertices as p o ssible. I prop ose implementation of Dijkstra’s algorithm which use s priority queue Q based on multilev el prefix tree (PT rie) [Figure 7]. PT rie is a stable structure [2 8]. Thanks to this algorithm it no t only builds the Sho rtest Path of minim um-weigh t considering the arc weights, but also considering to the num b er of vertices. Lemma 2.3. 2 D ijkstr a’s algorithm wher e PT rie is use d by priority queue r e quest O ( | V | + | E | ) time. Pro of: Dijkstra’s algorithm makes use of tree op erations o f PT rie: inser t, extract- min and remov e of Θ( | V | ∗ | E | w ( k )) time cost. Bec a use the length of word (size) necessary to r emem b er the w eight of arcs is constant fo r all a r cs of graph G = 14 Figure 7: The difference of Dijkstry’s algo rithm b etw een the use of basic prio rit y queue and PT rie Binary min-heap PT rie A B C D E 2 2 5 1 2 1 1 1 2 1 A B C D E 2 2 5 1 2 1 1 1 2 1 path weigh t arcs A p B 1 1 A p C 2 2 A p D 4 4 A p E 3 3 path weigh t arcs A p B 1 1 A p C 2 1 A p D 4 2 A p E 3 2 ( V , E ), function w ( k ) is constant. F unction w ( k ) is a constant co efficien t whic h equals min { w ( k ) = ( M const K + K ) } . Whic h means that time cos t o f pa rticular op erations ex- ecuted by P T rie in ca se of SSSP proble m equals O (1 ). Therefore Dijkstra’s a lg orithm where PT rie is us e d by prior it y queue needs O ( | V | + | E | ) time. 2.4 Single-Destination Shortest-Paths problem (SDSP) needs linear time The reverse SSSP problem is co mmo nly us e d in practice. Find a shortest path to a given des tination s o urce vertex s fr om ea c h vertex v (SDSP). By reversing the directio n of each edge in the graph G = ( V , E ), w e can reduce this problem to a single-source problem [Figur e 8]. Algorithm build SDSP tree T (subset of graph) of s ho rtest paths to so urce v ertex from each vertex, who se leav es are a ll vertices v ∈ V – witho ut the initial sour ce v ertex s ∈ V , which is the ro ot o f T . All pa ths lead fro m e a c h arbitra ry vertex v ∈ V to source vertex s for vertices access ible from a given destination sour ce vertex s . Definition 2. 4.1 (SDSP) We ar e given a weighte d, dir e cte d gr ap h G = ( V , E ) , r ep - r esente d by adjac ent list, with weight function w : E → R + mapping e dges to p ositive r e al -value d-weights. The weight of p ath p = < v 0 , v 1 , . . . , v k > , is the sum of t he weights of its c onstituent e dges. F or gr aph G = ( V , E ) exist destination sour c e vertex s ∈ V ; for al l vertic es v ∈ V it is ne c essary to find the shortest p ath with v to s . Similarly to other algo rithms I use the pro per ty that Shortest Paths algorithms t ypi- cally rely on the proper t y that the sho rtest path betw een t wo vertices con tains other 15 Figure 8: Difference b et ween SSSP and SDSP problems Single-Source Shortest P ath Single-Destination Short est-Pat h A B C D E F G 1 4 3 6 1 4 2 2 1 1 5 A B C D E F G 1 4 3 6 1 4 2 2 1 1 5 shortest paths within it. But I as sume double criterion to build the shortest path. I build the shortest pa th rela tive to the weigh t of a rcs and then r elative to the amo un t of vertices which contain the shor test (minim um-weigh t a nd minimum-v ertices) pa th. That is poss ible thanks to the stability o f PT r ie implementation [28]. Tha t s olution is suitable, b ecause it may happ en that there exist many shortest paths related to the weigh t o f arcs. In these circumstance s, minimal-weigh t path with minimum amount o f arcs b ecomes the Shortest Path. 2.4.1 Structure of v ertex and arc Structure of v ertex contain type ‘ data ’ whic h storage lab el of vertex. Because graph Vertex { data; Neighb ors *list; Neighb ors *back; }; G is represented b y a djacen t list, each v ertex has the list of po in ters to the neighbor s. The order on the list is random. The struc tur e of vertex has a helpful v ariable ‘ back ’ (used by any g raph algor ithms), which indicates one of a rcs lo cate o n the adjacent list of the structure. Ea ch vertex v ∈ V has a link ‘ back ’ to the neighbor (vertex from the adjacent list), in that momen t cons idered the successor on the s ho rtest path, o r ‘ back ’ equals NIL. F or this r eason we can for example, differentiate the vertices a dded to SDSP tree T [Figur e 9] from those ones which hasn’t been a nalyzed yet. The structure of a rc serves to inser t information ab out arc to P T rie. Therefore P T rie Arc{ weight ; pathWe ight; Vertex *tail; Vertex *head; }; will b e able to store not only in teger but detail information ab out arbitrar y ar c to o. The Arc structure stores informa - tion a bout the weight o f arc and path, and tw o p ointers; to vertex which is the tail o f the arc and to vertex which is the head of the arc. The ‘ pathW eig ht ’ c on tains the sum o f o p- timal arc s , which follow fro m the source vertex to currently 16 Figure 9: SDSP tree Shortest path p ( v k , v s ) . . . NIL v 1 .back v s v 1 v 2 v 3 v 4 v 5 v 6 v k analyzed vertex. P T rie uses this v ariable to determine the order. Such gra ph implementation allows consider able adaptability . It’s enough to know the a ddress of vertex (po in ter) to get to know the shortest path to a given destination of the so urce vertex. And by the w ay meet all vertices which are lo cated on this path. 2.4.2 Algorithm The algorithm starts with the s o urce vertex s ∈ V and inserts the adjacent list of ‘ s ’ to PT rie. Then with the help of ‘ minimu m ’ and ‘ r emov e ’ op erations ‘ extra cts − remov e − min ’ of a r cs from PT rie. W e move o n to the arc leadings to vertex. If vertex ha s not been attached to SDSP tree yet (the v alue of back is equal N I L ) the algorithm will attach the v ertex to SDSP tree. By s etting the p ointer ‘ back ’ on the tail (v ertex) of the arc which leads to the current vertex. Next, a ll a rcs o f the ana - lyzed vertex increa sed by the weigh t of the pa th, which le a ds to the c urrent vertex, are inserted to PT rie . Aga in we choose the smallest arc from P T rie . . . The algo - rithm ends its work when PT rie is empt y . It means that all arcs accessible from the source v ertex w ere browsed. Visited vertices hav e set arc ‘ back ’ is such a w ay that the path which the arcs ‘ b ack ’ built is no t only the minim um-weigh t path (the amount of arc weights is the smallest) but als o the path walks thro ugh as few ar cs as pos sible. Pseudo-co de of alg orithm co mpute SDSP problem 17 (1) SDSP(G, s) begin (2) PTrie. insert( s. −−−−−−→ neig hbors ) (3) while( PTrie is not empty) begin (4) arc = PTrie.m inimum( ) (5) PTrie. remove( arc) (6) if(arc .head.b ack is empty and isn’t s) begin (7) arc.he ad.back = reverse (arc) (8) PTrie. insert( arc.head. −−−−−−→ neig hbors + a rc.path Weight) (9) end (10) end (11) en d 1. The algor ithm b e gins to build t he SDSP tree from the arbitrar y source vertex ‘ s ’. SDSP tree consists o f all vertices accessible from any so urce vertex. 2. Insert the adjacent list to P T rie. 3. The a lg orithm w ill c heck the paths stored in P T rie as long as they e xist. 4. I take and r emem b er the pa th of the smallest weigh t from PT rie and the last a rc of this pa th. The v a riable ‘ w eig htP ath ’ defines the weigh t of the whole pa th. The v a r iable ‘ weig ht ’ defines the w eight of the last a rc, wher e the last arc is represented by v ariables ‘ tail ’ and ‘ head ’. The path leads fro m the sour c e vertex to the vertex indicate by ‘ h ead ’ 5. Remov e the path of the smallest weigh t from PT rie. 6. If the vertex which the arc leads to has not b een added to SDSP tree yet and it is not the s ource vertex . . . 7. Ascrib e the r everse of analy zed arc to the supp ortive arc ‘ back ’. arc: A → B revers e(arc): B → A 8. Insert the a rc of analyzed vertex to PT rie adding the weigh t of the path which brought us to the analyzed vertex. 9. If the vertex has alr eady been added to SDSP tree or its is a sourc e vertex, it is not analy zed an y more. 10. The alg o rithm finished chec king all arc s /vertices which were accessible from the source vertex. 11. When the algor ithm finishes its work an v ertices accessible from the source vertex by the supp ortive a rcs ‘ back ’ build SDSP tree, whose ro ot and vertex co nstitute the source vertex, to which le a d all the paths ba s ed on the ar cs ‘ ba ck ’. 18 Figure 10: Algorithm compute SDSP of a work, step I S tep I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 1 A p D 3 A p B 5 A p C extract-min: A p D path weigh t: w ( p ) = 1 path reject: FALSE Figure 11: Algorithm compute SDSP of a work, step I I S tep I I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 2 D p B 3 A p B 3 D p F 4 D p B 5 A p C 8 D p E extract-min: D p B path weigh t: w ( p ) = 2 path reject: FALSE 2.4.3 Analysis of the algori thm w ork I will a nalyze the algo rithm work step by step; How and in what or der a rcs are inserted to PT r ie? What is the sequenc e of vertex attachmen t to the tr ee containing the solutio n of SDSP pr oblem? Step by step descriptio n of the alg orithm co mputing SDSP pro ble m at work [Figur e s 10,11,12,13,14,15,16,17,18,19,20]. 19 Figure 12: Algorithm compute SDSP of a w ork , s tep I I I S tep I I I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 3 A p B 3 D p F 3 B p A 4 D p B 5 A p C 6 B p E 8 D p E extract-min: A p B path weigh t: w ( p ) = 3 path reject: TRUE Figure 13: Algorithm compute SDSP of a work, step IV S tep I V A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 3 D p F 3 B p A 4 D p B 5 A p C 6 B p E 8 D p E extract-min: D p F path weigh t: w ( p ) = 3 path reject: FALSE 20 Figure 14: Algorithm compute SDSP of a work, step V S tep V A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 3 B p A 4 D p B 4 F p C 4 F p G 5 A p C 6 B p E 8 D p E extract-min: B p A path weigh t: w ( p ) = 3 path reject: TRUE Figure 15: Algorithm compute SDSP of a work, step VI S tep V I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 4 D p B 4 F p C 4 F p G 5 A p C 6 B p E 8 D p E extract-min: D p B path weigh t: w ( p ) = 4 path reject: TRUE 21 Figure 16: Algorithm compute SDSP of a w ork , s tep VI I S tep V I I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 4 F p C 4 F p G 5 A p C 6 B p E 8 D p E extract-min: F p C path weigh t: w ( p ) = 4 path reject: FALSE Figure 17: Algorithm compute SDSP o f a w ork, step VI I I S tep V I I I A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 4 F p G 5 A p C 5 C p A 5 C p F 6 B p E 8 D p E extract-min: F p G path weigh t: w ( p ) = 4 path reject: FALSE 22 Figure 18: Algorithm compute SDSP of a work, step IX S tep I X A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 4 G p E 5 A p C 5 C p A 5 C p F 6 B p E 8 D p E extract-min: G p E path weigh t: w ( p ) = 4 path reject: FALSE Figure 19: Algorithm compute SDSP of a work, step X S tep X A B C D E F G 3 1 5 1 4 1 1 2 1 7 3 2 3 0 2 1 1 Inside the P T rie: weigh t path 5 A p C 5 C p A 5 C p F 6 B p E 6 E p D 7 E p G 8 D p E extract-min: remaining path weigh t: path reject: TRUE 23 Figure 20: Algorithm compute SDSP of a work: SDSP tree ro ot A B C D E F G NIL 1 2 1 0 1 1 Legend: gray arcs denote pointer ‘bac k’ on vertices yello w vertex with r e d aureola is a ro ot yello w vertices without r ed aureola are leav es 2.4.4 Analysis of correctness The alg orithm shown here sta rts to analyze the gr a ph and cr eate the shortest paths to the source v ertex. If the graph G is not strongly connected 2 the algorithm whic h solves SDSP pr oblem and starts its work from the source vertex will calculate SDSP tree of co nnec ted co mponents 3 containing the source v ertex; G s ∈ V = ( s, V , E ). The algorithm does not use weigh t rela xation. Arcs added to the SDSP tree are not mo dified any more. Only the order o f taking the pa ths out of the PT rie deter- mines the choice of ar cs or paths, s tarting from the minim um-w eight path. It’s worth remembering, howev er, that the weight of each vertex which has no t b een added to SDSP tree should be increas ed by the weight of the path whic h brought us there b e- fore inserting it to PT rie. So the v ertices to whic h lead the minim um-weigh t path are visited alw ays but only once. The SDSP tree is represented b y the ‘ back ’ con- nected with the vertices. That’s means that for ar bitr ary graph G = ( V , E ) with the directed sour c e vertex the algorithm define the tree, which is the subg raph of the predeces sor o f the graph G a s graph T back = ( V , E back ). Therefore the a lgo- rithm is correct b ecause the shortest paths are comp osed o f shortest pa ths. The pro of of this is based on the notion that if t here w as a shorter path than an y sub- path, then the shorter path should repla ce that sub-path to make the whole path shorter. That’s why the subgraph of predecessors T back is the Shortest Path T ree. 2 A dir ecte d graph is strongly connecte d if every tw o ve rtices are reach able fr om eac h other. 3 The connect ed components of a graph are the equiv alence classes of vertices under the “is reac hable from” r elation. 24 2.4.5 Analysis of the algori thm b ound Bo dy lo op whic h inser ts arcs to PT rie is Θ ( | E | ) time cos t. The op eration o f PT rie for co nstant length (size o f ) type weigh t of arc ar e Θ( M const K + K ) = O (1). T o lo ok through each of vertex gr a ph the a lg orithm require Θ ( | V | ) time. Therefore worst-case time c o mplexit y equals Θ( | V | + | E | ( M const K + K )) = O ( | V | + | E | ) time. 2.4.6 A s i mple example of the use of algorithm com puting SDSP problem in C++ The algorithm builds SDSP tree for gra ph presented in [Figure 10]. #include < iostream > // The R ep or t c ontains the PT rie sour c e c o de: // \ pr ote ct \ vrule width0pt \ pr ote ct \ hr ef { http :// te chr ep orts . li br ary . c ornel l . e du:8081/ }{ http:// te chr ep orts . libr ary . c o r n e l l . e d u : 8 0 8 1 / } // Dienst/UI/1.0/Display/cul.cis/TR2006 − 2023 // // Or, the Sour c eF or ge .net pr oje ct : // \ pr ote ct \ vrule width0pt \ pr ote ct \ hr ef { http :// ptrie . sour c efor ge . net }{ http :// ptrie . sour c ef or ge . net } #include ”PT rie.hpp” / ∗ ∗∗ \ protect \ vrule width0pt \ p rotect \ href { h ttp: //ptrie. sour c efor ge . net/sour c e/PT rie.hpp }{ http: // p t r i e . s o u r c e f o r g e . n e t / s o u r c e / P T r i e . h p p } ∗ / // < b e gin > namesp ac e dplaneta namespace d planeta { struct V ertex; struct Neighbors; struct Arc; / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ The definition of the structur e which r epr esents vertex . ∗ / struct V ertex { c har data; // L ab el Neighbors ∗ list ; //A djac ent Li st V ertex ∗ bac k; unsigned backW eight; // The meto d is r esp onsible for c onne cting vertic es with e ach other . V ertex& attach(V ertex ∗ attac h, unsigned weig ht); V ertex( c har name); ˜V ertex( void ); } ; 25 / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ The definition of the structur e r esp onsible for the or ganization ∗∗ of adjac ent list . ∗ / struct Neighbors { Neighbors ∗ nex t; // A djac ent List [ the singly − linke d li st ] // A r c r epr esent ation V ertex ∗ link ; unsigned weigh t; Neighbors(V ertex ∗ l, unsigned w, Neighbors ∗ n); ˜Neigh b ors( void ); } ; V ertex :: V ertex( char name): list (0), bac k(0), data(name) {} V ertex ::˜ V ertex( void ) { delete list ; back = 0; list = 0; } // The metho d ’attach’ implemente d in vertex structur e i s r esp onsible for the // c onne ction of the vertic es . F or example, to c onne ct vertex ’ A’ wi th ’ B’ // [ V ertex ∗ a = new V erte x (’A’), ∗ b = new V ert ex (’B’)] // We add the e dge which c onne cts vertex A to its adjac ent list . // [ a − > add(b, lenght);] // Be c ause of this we get the ar c ( dir e cte d e dge) joini ng ’ A’ and ’B’. // T o simul ate the e dge b etwe en ’ A’ and ’B’, also vert ex ’ B’ should c ontain the // ar c of the same length which joins it with ’ A’. [ b − > add(a, lenght);] // (A) < === > (B). V ertex& V ertex::attac h(V ertex ∗ attac h, unsigned weig ht) { list = new Neighb ors(attac h, w eight, list ); return ∗ this ; } Neighbors:: Neigh b ors(V ertex ∗ l, unsigned w, Neigh b ors ∗ n): link ( l ), w eight(w), next(n) {} Neighbors::˜Neighbors( void ) { 26 delete next; next = 0; } / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ The definition of the structur e which r epr esents ar c i s ne c essary ∗∗ i nside the PT rie. The structur e must have the impl emente d overlo ade d ∗∗ op er ators use d by PT rie. ∗ / struct Arc { unsigned weigh t, p athW eight; V ertex ∗ tail , ∗ h ead; unsigned op erator >> ( const unsigned i) const { return ( pathW eight >> i); } bo ol ope rator !=( const Arc& ob j) const { return this − > pathW eight!=ob j.pathW eight; } bo ol ope rator ==( const A rc& ob j ) const { return this − > pathW eight==ob j.pathW eig ht; } } ; / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ Supp ortive function use d by PT rie to r et urn size of T yp e < A r c.weight > ∗ / inline size t sizeF unc( const class Arc& ob j) { return sizeof (ob j.wei ght); } // If Y ou want to se e how the ar cs ar e analyze d by the algorithm ... // #define TEST / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ The algorithm builds the SDSP tr e e by pr op er arr angement of supp ort ∗∗ varieties ’ b ack ’ whi ch ar e lo c ate d in e very verte x . ∗ / void SDS P(V ertex ∗ sourceV ertex) { register Arc temp; register const Arc ∗ p; register const Neighbors ∗ t; 27 PT rie < Arc > Q( sizeF unc); PT rie < Arc > ::iterator iter=Q; #ifdef TEST std :: cout << ”Insert the adjacent list of the source vertex to PT rie: \ n”; #endif for ( t = sourceV ertex − > list; t!=NULL; t= t − > next) { temp.w eight = temp .pathW eight = t − > weig ht; temp. tail = sourceV ertex; temp.head = t − > link; Q. insert ( temp); #ifdef TEST std :: cout << ”[” << sourceV ertex − > d ata << ”] −− (” << t − > w eight << ”) − > [” << t − > link − > data << ”] \ n”; #endif } #ifdef TEST std :: cout << std::endl; #endif // Al l ar cs ac c essible fr om the sour c e vertex ar e analyze d . while (p = Q.minimum()) { #ifdef TEST std :: cout << ” \ tCame from the [” << p − > tail − > data << ”]; State of th e PT rie: \ n”; iter . b egin (); while (iter) { std :: cout << ” \ t[” << ( ∗ iter).tail − > data < < ”] −− (” << ( ∗ iter).pathW eight << ”) − > [” << ( ∗ iter).head − > data << ”] \ n”; iter ++; } std :: cout << std::endl; #endif if ( p − > head − > back==NULL && p − > head!=sourceV ertex) { #ifdef TEST std :: cout << ” \ nThe vertex is chosen: [” << p − > head − > data << ”] and insert the adjacent list to PT rie: \ n”; #endif (( Arc ∗ )p) − > head − > bac k = p − > tail; p − > head − > backW eigh t = p − > wei ght; // Insert the adjac ent list of the curr ent vertex to PT rie for ( t = p − > head − > list; t!=NULL; t=t − > next) { temp.w eight = t − > w eigh t; temp.pathW eight = t − > w eigh t + p − > path W eight ; temp. tail = p − > head; temp.head = t − > link; 28 Q. insert ( temp); #ifdef TEST std :: cout << ”[” << temp.tail − > data << ”] −− (” << t emp.w eigh t << ”) − > [” << temp.head − > data << ”]” \ ” w eight of path = ” << temp.pathW eight << std::en dl; #endif } #ifdef TEST std :: cout << std::endl; #endif } Q.remo ve( ∗ p); } } // The function walks on the p ath f r om the cho osen vertex to the sour c e vertex . void W alk( const V ertex ∗ v) { while (v) { std :: cout << ”[” << v − > data << ”]”; if ( v − > back) std::cout << ” −− (” << v − > backW eight << ”) − > ”; v = v − > bac k; } std :: cout << std::endl; } // The function shows the adjac ent list of the cho osen vertex . void ShowAdjecen tLists( const V ertex ∗ v) { for ( const N eigh b ors ∗ t = v − > list; t!=NULL; t=t − > next) std :: cout << ” \ t[” << v − > data << ”] −− (” << t − > wei ght << ”) − > [” << t − > link − > data << ”] \ n”; std :: cout << std::endl; } } // < end > namesp ac e dplaneta 29 / ∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗ ∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗∗∗∗∗∗∗∗∗∗∗ ∗∗ This example sour c e c o de demonstr ates how you c an use a shown algorithm ∗∗ c omputing SDSP pr oblem. ∗ / int main( in t argc, c har ∗ argv[]) { // We cr e ate the gr aph v ertic es dplaneta :: V ertex a( ’ A’ ), b( ’ B’ ), c ( ’ C’ ), d( ’ D’ ), e ( ’ E’ ), f ( ’ F’ ), g( ’ G’ ); dplaneta :: V ertex ∗ sourceV ertex; // Conne cting the gr aph vertic es . a . attach(&b, 3).attach(&c, 5). attach(&d, 1); b . attac h(&a, 1). attach(&e, 4); c . attac h(&f, 1). attach(&a, 1); d . attac h(&b, 1). attach(&b, 3).attach(&e, 7). attach(&f, 2); e . attac h(&d, 2). attach(&g, 3); f . attac h(&g, 1). attach(&c, 1); g . attach(&e, 0); std :: cout << ”Show adjecen t lists : \ n −−−−−−−−− − −−−−−−−−− − −−−\ n”; std :: cout << ”A: \ n”; Sho wAdjecentLists(&a); std :: cout << ”B: \ n”; Show AdjecentLists(&b); std :: cout << ”C: \ n”; Show AdjecentLists(&c); std :: cout << ”D: \ n”; Sho wAdjecentLists(&d); std :: cout << ”E: \ n”; S ho wAdjecentLists(&e); std :: cout << ”F: \ n”; S ho wAdjecentLists(&f); std :: cout << ”G: \ n”; S ho wAdjecentLists(&g); std :: cout << ” −−−−−−−− −−−−−−−−− − −−−−−\ n \ n”; // We cho ose on arbitr al vert ex fr om which the al gorithm wil l build SDSP tr e e. sourceV ertex = &a; // We cr e ate the SDSP tr e e , by suitably setting supp ortive // variable ’ b ack ’ which ar e lo c ate d in e ach vertex . dplaneta :: S DSP(sourceV ertex); // We che ck the p aths . std :: cout << ”SDSP P ath(es?): \ n”; dplaneta :: W alk(&a); dplaneta :: W alk(&b); dplaneta :: W alk(&c); dplaneta :: W alk(&d); dplaneta :: W alk(&e); dplaneta :: W alk(&f); dplaneta :: W alk(&g); 30 return 0; } 3 Conclusions I hav e shown linea r w ors t- worst case algorithms base d on P T rie whic h compute the basic Netw ork problems. Despite the fact that PT rie is based on digita l data, it can be us e d to stor e p ositive integer, integer but also real n umbers. Because all quan tities in computer ar e represented by binary words. That’s why the w eigh t of a rc can b e defined no t only by p ositive integer, but also by real nu mber, or even by string. Tha nks PT rie, whic h is stable, during computing the MST, SSSP and SDSP problems, we not only fo cus on the Shortest Path in relation to weigh t of arcs, but also to the amount of vertices and ar cs o n the path to o. Time complexity of mentioned alg o rithms equals O ( | V | + | E | ). Me mory b ound of a lgorithms equals memory b ound of PT rie . PT rie memory bound equals Θ( log 2 K N (2 K +1 ) K ). Presented algor ithms not only get the fastest asymptotic r unning time, but they are a lso very pra cticable a nd can be eas ily implemen ted. References [1] R. K. Ahuja, K . Mehlhorn, J. B. Orlin, and R. E. T arjan. F aster algorithms for the shortest p ath pr oblem , Journal of the A CM, 37(1990), 213-223. [2] Y. Asano and H . Imai. Pr actic al Efficiency of t he Line ar-Time A lgorithm for the Sin- gle Sour c e Shortes t Path Pr oblem , Journal of t he Op erations Researc h Society of Japan, 43(2000), 431-447. [3] R. Bellman. On a r outing pr oblem , Quarterly of Applied Mathematics, 16(1958), 87-90. [4] D. P . Bertsek as. A Simple adn F ast L ab el Corr e cting A lgorithm for Shortest Paths , Net- w orks, 23(199 3), 703-709. [5] O. Bor ˚ uvk a. O jist´ em pr obl ´ emu minim ´ aln ´ ım, Pr´ ac e Mor avsk ´ e P ˇ rir o dov ˇ ede ck ´ e Sp oleˇ cnosti , 3(1926), 37-58. [6] Ren´ e de la Briandais, File Se ar ching Using V ariable L ength Keys , Proceedings of the W estern Joint Computer Conference, 295-298, 1959. [7] B. Chaze lle. A minimum sp anning tr e e algorithm with inverse-A ck ermann typ e c omplexity , Journal of the ACM, 47(2000), 1028-1047 . [8] B. V. Cherk assky , A. V . Goldb erg, an d T. Radzik. Shortest p ath algorithms: The ory and exp erimenta l evaluation , Math. Programming, 73(199 6), 123-174. [9] T. H. Cormen, C. E. Leiserson, R. L. Rive st, C. Stein. Intr o duction to Algorithms , The MIT Press, 2nd Edition, 2001. 31 [10] N. D eo and Ch. Pang. Shortest Path Algorithms: T axonomy and Annotations , N et wor ks, 14(1984), 275-323. [11] E. W. Dijkstra. A note on two pr oblems in c onnexion with gr aphs , Numerische Mathe- matik, 1(1959), 269-271. [12] J. R. Driscoll, H . N. Gabow , R. Shrairman, and R . E. T arjan. R elaxe d he aps: An alterna- tive to Fib onac ci he aps with applic at ions to p ar el lel c omputation , Comm unications of the ACM , 31(1988 ), 1343-1354. [13] L. R. F ord. Network Flow The ory , The Rand Corporation, T echnical Report, P-932, 1956 [14] L. R. F ord and D. R. F ulk erson. Flows in Networks , Princeton Universit y Press, NJ, 1962. [15] M. L. F redm an and R . E. T arja n. Fib onac ci he aps and their uses in im pr ove d network optimization algorithms , Journal of the ACM, 34(1987), 596-615. [16] M. L. F redman and D. E. Willard. T r ans-dichotomous algorithms f or mi nimum sp anning tr e es and shorte st p aths , Journal of Comput er and System Science, 48(1994 ), 533-551. [17] H. N. Gabow, Z. Galil, T. Sp encer, and R. E. T arjan. Effi cient algorithms for finding minimum sp anning tr e es i n undir e cte d and dir e ct e d gr aphs , Com binatorica, 6(1986), 109- 122. [18] G. Gall o and S. P allottino. Short est Path Metho ds: A Unifie d Appr o ach , Mathematical Programming Stu dy , 26(1986), 38-64. [19] F. Glo ver, R. Glov er, and D. Klingman. Computational Study of an Impr ove d Shortest Path Algor ithm , Netw orks, 14(1984), 25-36. [20] A. V. Gol db erg and R. E . T arjan. Exp e ct e d Performanc e of Dijkstr a’ s Shorte st Path Algor ithm , Princeton Un iv ersity T echnical Rep orts, 1996, TR-530-96 [Online]. Av ailable: http://www .cs.princeton. edu/research/techreps/TR- 530- 96 [21] IEEE. IEEE Standar d for Binary Flo ating Point Arithmet ic , ANS I/IEEE Std 754-1985, 1985. [22] D. B. Johnson. Efficient A lgorithms f or Shortest Path in Sp arse Networks , Journal of the ACM , 24(1977 ), 1-13. [23] D. E. Knuth, The Art of Computer Pr o gr ammi ng V ol. 1: F undamental Algorithms, 3rd Edition, Ad dison W esl ey Longman, I nc. 1998. [24] D. E. Knuth, A rt of Com puter Pr o gr amming V ol. 3: Sorting and S earc hing, 2nd Edition, Addison W esley Longman, I nc. 1998. [25] J. B. Krusk al. On the shortest sp anning subtr e e of a gr aph and the tr aveling salesman pr oblem , Pro ceedings of the Americam Mathematical Society , 7(1956), 48-50. [26] J. Ne ˇ set ˇ ril, E. Milko v´ a, and H. Ne ˇ set ˇ rilo v´ a. Otakar Bor ˚ uvka on Minim um Sp anning T r e e Pr oblem , Discrete Mathematics, 233(2001), 3-36. [27] OSPF The Op en Shortes t Path First pr oto c ol , BBN-AR P ANET [Online]. Av ailable: http://www .cisco.com/uni vercd/cc/td/doc/cisintwk/ito_doc/ospf.pdf , Av ailable: http://too ls.ietf.org/ht ml/rfc3101 32 [28] D. S. P laneta. PT rie: Priority Queue b ase d on multilevel pr efix tr e e , Cor- nell Universi ty T ec hnical Rep orts, TR2006-2023 , 2006. [Online]. Av ailable: http://tec hreports.libra ry.cornell.edu:8081/Dienst/UI/1.0/Display/cul.cis/TR2006- 2023 Av ailable: http://arx iv.org/abs/070 8.2936 [29] D. S. P laneta. Line ar Time Algorithms Base d on Multilevel Pr efix T r e e for Finding Shortest Path with Positive W eights and Minimum Sp anning T r e e in a Networks , Cornell Universit y T echnical Rep orts, TR200 6-2043, 2006. [Online]. Av ailable: http://tec hreports.libra ry.cornell.edu:8081/Dienst/UI/1.0/Display/cul.cis/TR2006- 2043 [30] M. Pollac k a nd W. Wiebenson. Solutions of the Shortest-R oute Pr oblem – A R eview , Op erations Research, 8(1960), 224-230. [31] R. C. Prim. Shortest c onne ction networks and some gener al izations , Bell System T ec h- nical Journal, 33(1957), 1389 -1401. [32] R. Raman. Re c ent r esults on the single-sour c e shortest p aths pr oblem , ACM SIGACT News, 28(1997), 81-87. [33] R. E. T arj an. Efficiency of a go o d but not line ar set-union algorithm , Journal of the A CM, 22(1975), 215-225. [34] M. Thorup. On RAM priority queues , SIAM Journal on Computing, 30(200 0), 86-109. [35] A. Y ao. An O ( | E | l og log | V | ) al gorithm for finding minimum sp anning tr e es , Inf. Pro cess. Lett., 4(1975), 21-23. 33
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment