A Generalized Information Formula as the Bridge between Shannon and Popper
A generalized information formula related to logical probability and fuzzy set is deduced from the classical information formula. The new information measure accords with to Popper's criterion for knowledge evolution very much. In comparison with squ…
Authors: Chenguang Lu
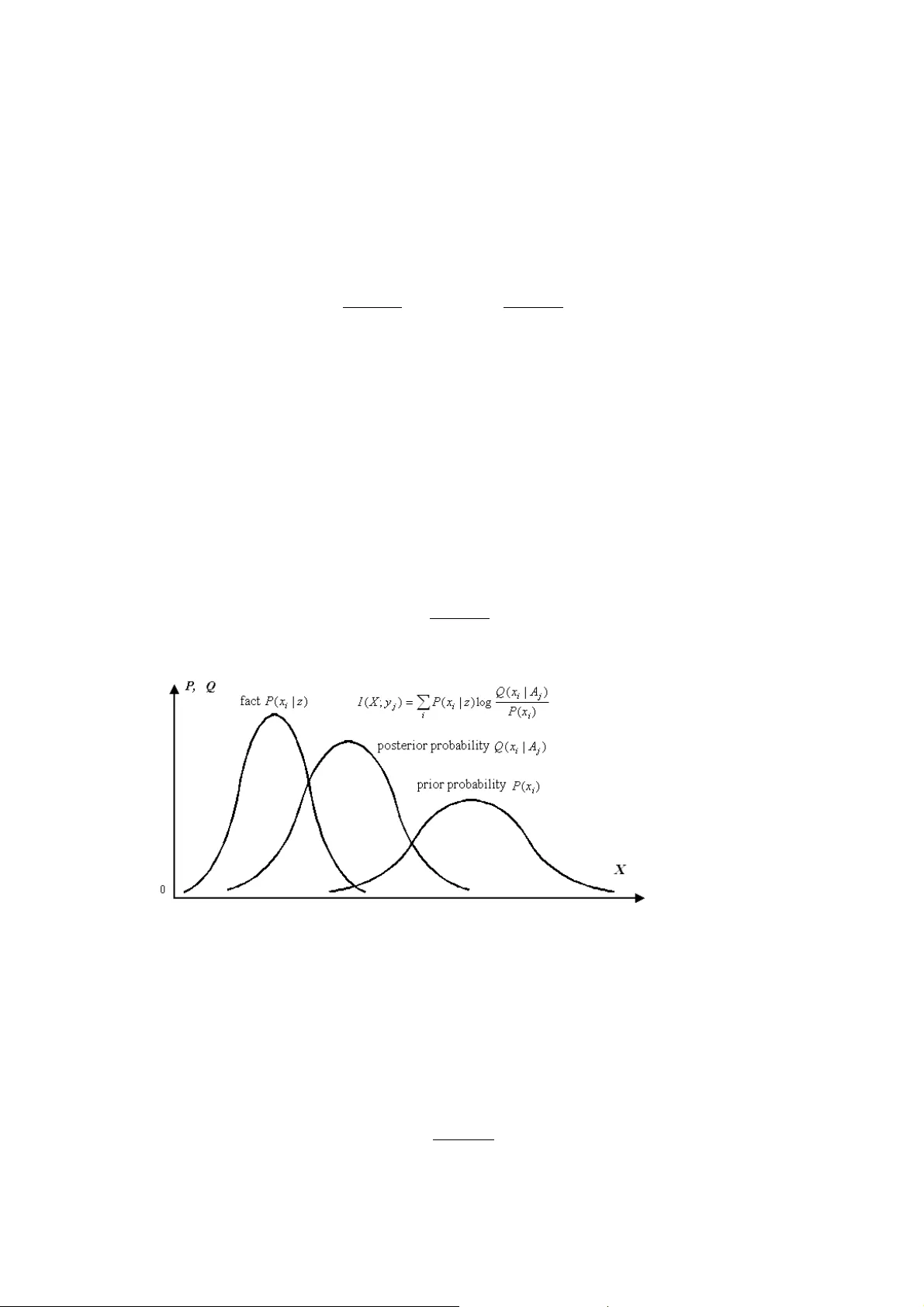
1 A Generalized Information Formula as the Bridge between Shannon and Popper Chenguang Lu 1 Independent Researcher, survival99@hotmail.com Abstract. A generalized information formula related to logical probability and fuzzy set is deduced from the classical information formula. The ne w information measure accords with to Popper’s criterion for knowledge evolution very much. In comparison with square error criterion, the information criterion does not only reflect error of a proposition, but also reflect the particularity of the events described by the proposition. It give s a proposition with less logical probability higher evaluation. The paper introduces how to select a prediction or sentence from many for forecasts and language translations according to the generalized information criterion. It also introduces the rate fidelity theory, which comes from the improvement of the rate distortion theory in the classical information theory by replacing distortion (i.e. av erage error) criterion with the generalized mutual information criterion, for data compression a nd communication efficiency. Some interesting conclusions are obtained from the rate-fidelity functi on in relation to image communication. It also discusses how to improve Popper’s theory. 1 Introduction Although Shannon’s information theory is successful for electrical com m unication, it does not deal with semantic information [1] . Semanti c information m eas ures have been discussed for long tim e [2], [3] , [4], [5]. However, no formul a can be properly used to measure t he information of a predicti on like “Tomorrow will be rainy” or “Temperature is about 10 ° C”. Twenty years ago, I set up a symm etrical m odel of color vision wit h four pairs of opponent colors instead of three pairs as in the popular zone m odel [6]. To prove t hat the m ore unique colors we perceive, the higher discrim ination to li ghts our ey es have, and hence the more i nformation we can obtain, I researched informat ion theory. Sim ilarly, i nformation conveye d by color vision is also related to semantics or m eaning of symbol s. From 1989 to 1993, I found the generali zed information form ula [7], [8] and published t he monograph [9] on generali zed information. Later, I wrot e some papers for further discussion [10], [11] and publ ished a m onograph on port folio and inform ation value [12]. This paper will focus on the generalized information criterion for selecting one from several sentences, or p redictions, and on the rate fidelity theory, which is an improv ed version of classical rate distortion theory, for dat a compression and com municati on efficiency. 2 Deducing Generalized Information Formula First we consider the inform ation provided by predi ctions such as “The growth rate of GDP of this y ear will be 8%”. Let X denote the random variabl e taking values from set A ={ x 1 , x 2 …} of events, such as the growth rates or temperatures, Y denote the random variable taking val ues from set B ={ y 1 , y 2 …} of sentences or predictions. For each y j , there is a subset or fuzzy subset A j of A and y j = “x i ∈ A j ”. In the classical inform ation theory, inform ation provided by y j about x i is ) ( ) | ( log ) ; ( i j i j i x P y x P y x I = . ( 1 ) 1 see his home page: http://survivor99.com/lcg/english for more articles. 2 Yet, in linguisti c comm unication we only know m eaning of a sentence or a prediction instead of the condition probability P ( x i | y j ). Fortunately, we can deduce the cond ition probability Q ( x i |A j ) of x i while condition x i ∈ A j , which means that y j = “x i ∈ A j ” is true, by Bayesian formula ) ( ) ( ) | ( ) | ( j i i j j i A Q x P x A Q A x Q = , ( 2 ) where ∑ = i i j i j x A Q x P A Q ) | ( ) ( ) ( . ( 3 ) Replacing P ( x i |y j ) with Q ( x i | A j ) in (1), we have the gene ralized information form ula: ) ( ) | ( log ) ( ) | ( log ) ; ( j i j i j i j i A Q x A Q x P A x Q y x I = = , ( 4 ) which is illustrated by Fig. 1. Note that th e most important thing is that generally Q ( x i | A j ) ≠ P ( x i | y j ) because P ( x i | y j )= P ( x i |“ x i ∈ A j ”)= P ( x i |“ x i ∈ A j ” is reported); yet, Q ( x i | A j )= P ( x i | x i ∈ A j )= P ( x i |“ x i ∈ A j ” is true). The y j may b e a n incorrect prediction or a lie; yet, x i ∈ A j means that y j must be correct. If they are always equal, then generalized information formula (4) will become the classical information formula (1). The generalized informati on formula can m easure not only sem antic inform ation, but also sensory information. Let X denote one of monochrom atic light s, Y denote the corresponding color perception, A j denote fuzzy set, which includes all x i that are confused with x j , of A , and Q ( A j | x i ) denote the confusion probab ility of x i with x j . Then, a color perception can be regarded as a sentence y j = “The color x i is about x j ”. Hence, the generalized information formula can also be used to m easure the information of a color perception. Fig. 1. Illustration of the generalized information formula. The more precise the prediction is, the more the inform ation is provi ded. Information m ight be negati ve if the prediction i s obviously wrong. The greater the error We use an example to show the properties of t he formula. Assum e we need to predict a stock index for the next weekend. Let the current index be x =100. There are predictions y j =“The index will be about x j ” and y k =“The index will be about x k ”. Assume there is pri or knowledge: QX C Xx d ( ) e xp[ () ], = ′ − − 0 2 0 2 2 where C’ is a normalizing constan t; ]. 2 ) ( exp[ = ) | ( ], 2 ) ( exp[ ) | ( 2 2 2 2 k k k j j j d x X X A Q d x X X A Q − − − − = 3 Figure 2 Information I about stock i ndex X conveyed by different predi ctions y j and y k Figure 2 shows the changes of informat ion conveyed by y j and y k respectively with X changing. It tells us that the more an occasiona l event is correctly pred icted, the more the inform ation is. The dashed lines show the case in which d j is reduced. The corresponding prediction m ay be expressed as “The index will be very clo sed to x j ”. It can be said that when predic tions are correct, the more precise the prediction is, the more the info rmation is. If a prediction is extremely fuzzy such as “The index will probably go up or not go up”, Q ( A j | X ) can be represented by a h orizontal line and the in formation will always be zero. 3 Comparing Information Criterion with Square Error Criterion Assume Q ( A j | x i ) is a normal function with the m aximum 1, i.e. ] 2 ) ( exp[ ) | ( 2 2 d x x x A Q j i i j − − = , ( 5 ) where d means the precision of a prediction or the discri mination of sense organ. The l ess the d is, the higher the precision or the discri mination i s. From (4) and (5), we have ) ( log 2 ) ( ) ; ( 2 2 j j i j i A Q d x x y x I − − − = . ( 6 ) If d and Q ( A j ) are 1 or constants, then the information will criterion become the square error criterion. In comparison with the square error criteri on, the informati on criterion gives m ore precise predictions, or predictions that predict more occasional events, highe r evaluation. If we use two criterions to evaluate people, the square error criterion m eans that no error is good; y et, the informat ion criterion m eans that contribution over error is good. Actually, philosopher K. R . Popper suggested using in formation as cri terion to evaluate a scie ntific theory or a proposition (see page 250 in [12]) long time ago. But he di dn’t provide suitable information formula. The above information m easure accords with Popper’s theory very m uch [8]. If Q ( A j | x i ) ≡ 1, then there must be I ( x ; y i )=0. This is just the m athematical description of Popper’s affirm ation that a proposition that cannot be falsified provides no information and hence is m eaningless. The less a fuzzy set A j is, or the more unexpected the events in A j are, the less the Q ( A j ) is, and hence the bigger the I ( x ; y i ) is while Q ( A j | x i )=1. This is just the m athematical description of Popper’s affirm ation that a proposition with less prior logical probability has mo re im portant scientific significance if it can go though tests of facts. For sentences “The temperature tomorrow morning will be lower than 10 ° C” and “There will be small to me dium rain tomorrow”, error is hard to be expressed because there is no center x j in fuzzy set A j . However, measuring information is the same easy for given logical probability Q ( A j | x i ) and probability d istribution P ( x i ). 4 4 Generalized Kullback Formula for Sentences Selection For given event X = x i , it is easy to select a descriptive sentence y * from m any sentences y 1 , y 2 … according to the generalized info rmation criterion. We calculate I ( x i ; y i ) for each y i . The y i that makes I ( x i ; y i ) h as t he ma xi mum is y * we want. However, in g eneral artificial intelligent systems, for given data or ev idences denoted by z , we can only know the probability distribution P ( x i | z ) instead of exact event x i . For example, to forecast rainfall, we first get P ( x i | z ) according to observed data, and then select a sentence such as “There will be heavy rain tomorrow” from m any as prediction according to P ( x i | z ). In theses cases, we need generalized Kullback formula (see Fig. 2): ) ( ) | ( log ) | ( ) ( ) | ( log ) | ( ) ; ( i i j i i i j i i i j A Q x A Q z x P x P A x Q z x P y X I ∑ ∑ = = , ( 7 ) which is the average of I ( x i ; y j ) for different x i . This formula is called generalized Kullback formula because it has the form of Kullback formula while Q ( x i | A j )= P ( x i | z ) (for each i ). We can prove that I ( X ; y j ) reaches its maxim um when Q ( x i | A j )= P ( x i | z ). Now, we calculate I ( X ; y j ) for different y j . The y j that makes I ( X ; y j ) have the maxi mum is y * we want. We can also use the generalized condition entropy ) | ( log ) | ( ) | ( * j i i i j A x Q z x P y X H ∑ = ( 8 ) as criterion to select y j *. But, actually, the calculation is not simple r than the right part of (7) because we need Q ( A j | x i ) and Q ( A j ) to calculate Q ( x i | A j ). For language translation, we need to translat e a sentence y ’ in a language to another sent ence y * in another language. In this case, we need to replace P ( x i | z ) with Q ( x i | A ’), where A ’ is a fuzzy subset of A , so that (7) become ) ( ) | ( log ) ' | ( ) ; ( i i j i i j A Q x A Q A x Q y X I ∑ = . ( 9 ) Fig. 3. The property of the generalized Kullback formula: the closer to the fact P ( x i | z ) the posterior probability Q ( x i | A j ) is in comparison with the prior probability P ( x i ), the more the information about X is conveyed by y j ; otherwise, the information is negative 4 Generalized Mutual Information Formula Actually, the probability P ( x i ) in (7) may be replaced with subjectively forecasted probability Q ( x i ) so that we have ) ( ) | ( log ) | ( ) ; ( i j i i j i j x Q A x Q y x P y X I ∑ = ( 10 ) 5 Calculating the average of I ( X ; y i ) for different y j , we have generalized mutual i nformation form ula: ), | ( ) ( ) | ( ) ( )] ( / ) | ( log[ ) , ( ) ; ( ) ( ) ; ( Y Y H Y H Y X H X H x Q A x Q y x P y X I y P X X I i j i i j i j j j − = − = = = ∑ ∑ ( 11 ) where ∑ − = i j i x Q x P X H ) ( log ) ( ) ( , ( 12 ) ∑∑ − = ji j i i i A x Q y x P Y X H ) | ( log ) , ( ) | ( , ( 13 ) ∑ − = j j j A Q y P Y H ) ( log ) ( ) ( , ( 14 ) ∑∑ − = ji i j i i x A Q y x P X Y H ) | ( log ) , ( ) | ( . ( 15 ) I call H ( X ) forecasting entropy, which reflects the av erage coding length wh en we economically encode X according to Q ( X ) while real source is P ( X ), and reaches its minimum as Q ( X )= P ( X ). I call H ( X | Y ) posterior forecasting entropy, call H ( Y ) generalized entropy, and call H ( Y | X ) generalized condition entropy or fuzzy entropy. I think that the generalized i nformation i s s ubjective inform ation and Shannon inform ation is objective information. If two weather forecasters al ways provide opposite forecasts and one is always correct and another is always incorrect . They conve y the sam e objective informat ion, but the different subjective information. If Q ( X )= P ( X ) and Q ( X|A j )= P ( X|y j ) for each j , which means subjective forecasts conform to objective facts, then the subjective mutual inform ation will be equal to objective or Shannon’s mutual inform ation. 5 Improving Rate Distortion Theory into Rate Fidelity Theory Shannon proposed the rate-distort ion function R ( D ) for data compression in his creative paper [1]. For given source P ( X ) and the upper lim it D of distorti on ∑∑ = ji j i i i y x d y x P Y X d ) , ( ) , ( ) , ( , ( 16 ) where d ( x i , y j ) is error measure such as square error, we change channel P ( Y|X ) to search the mi nimum of Shannon’s mutual inform ation I s (X; Y ). The minim um denoted by R = R ( D ) is just the rate-distortio n function, which reflects necessary communi cation rate for given source P ( X ) and distortion li mit D . Actually Shannon had mentioned fi delity criterion for lossy coding. He used the distortion, i.e. average error, as the criterion for optimizing lossy coding because the fidelity criterion is hard to be formulated. However, di stortion is not a good criterion in most cases. For this reason, I replace the error function d ij = d ( x i , y j ) with generalized information I ij = I ( x i ; y j ) and distortion d ( X , Y ) with generalized mutual information I ( X ; Y ) as criterion to search the m inimum of Shannon mutual information I s ( X ; Y ) for given P ( X )= Q ( X ) and the lo wer limit G of I ( X ; Y ). I call this criterion I ( X ; Y ) the fidelity criterion, call the minimum the rate-fidelity function R ( G ), and call the improved th eory the rate fidelity theory. In a way similar to that in the classical inform ation theory [14], we can obtai n the expression of function R ( G ) with parameter s : 6 ∑∑ ∑∑ + = = ji i i ji ij i ij j i x P s sG s R I sI y P x P s G λ λ log ) ( ) ( ) ( ) exp( ) ( ) ( ) ( ( 17 ) where s = dR/dG indicates the slope of functi on R ( G ) (see Fig. 3) and ) exp( ) ( / 1 ij j j i sI y P ∑ = λ ( 18 ) In [12], I defined inform ation value V by the increm ent of growing sp eed of a portfolio because of information, and suggest ed to use the informati on value as criterion to opti mize com municat ion to get rate-value function R ( V ), which is m ore meaningful in some cases. 6. Properties of Rate-fidelity Function and Image Compression Now we use the informati on provided by different gray levels of pixels of images (see [9] for details) as sample to discuss the properties o f rate-fidelity function. Th e conclusions are also meaningf ul to linguistic com muni cation. Fig. 4 Relationship between d and R ( G ) for b =63 Let the gray level of a digit ized pixel be a source and the gray level i s x i =i, i =0, 1... b =2 k -1 with normal probab ility distribution who se expectation= b /2 and standard deviation= b /8. Assume that after decoding, the pixel also has gray le vel y j = j =0, 1... b ; the perception caused by y j is also denoted by y j ; and discrimination function or confusin g probability fu nction of x j is )] 2 /( ) ( exp[ ) | ( 2 2 d j X X A Q j − − = ( 19 ) where d is discrimination parameter. The smaller the d i s, the higher the discrim ination is. Fig. 4 tells us that 1) The higher discrim ination can give us m o re information when objective information R is big enough; yet, lower discrim ination is bet ter when objective inform ation R is less. This conclusion can be supported by the fact that i t is better to wat ch TV with less pixels or with too much snowflake-l ike disturbance from further di stance. 2) When R =0, G <0, which means that if a coded im age has nothing to do with the original image, we still believe it reflects the original image, then the inform ation will be negative. For linguistic communi cation, this m eans that if one believes a fo rtunetel ler’s talk, one would be m ore ignorant about facts and the information he has will be redu ced. 3) When G =-2, R >0, which means that certain objective info rmation is necessary when one uses lie s to deceive his enemy to some exte nt; or say, lies against facts are m ore terrible than lies according to nothing. 4) The each line of function R ( G ) is tangent with the line R = G , which means there is a m atching poi nt at which ob jective information is equal to su bjectiv e information, and the higher t he discriminat ion is (the less the d is), the bigger the m atching inform ation am ount is. For lingui stic comm unication, t his means that for improving efficiency of communicat ion, it is necessary to m ake objective inform ation accord with subjective understanding. 7 5) The slope of R ( G ) becomes bigger and bigger wi th G increasing, which t ell us that for given discrimination, it is limited to increase subjective in formation, and too much obj ective information is wasteful. Fig. 5. Relationship between matching value of R with G , discrimination parameter d , and digitized bit k Fig. 5. tells us that fo r given discrimination, there exists th e optimal digitized bit k ' so that the matchi ng value of G and R reaches the maxim um. If k < k ', the matching information increases with k ; if k > k ', the m atching inform ation no longer increases wi th k . This m eans that too high resolution of i mages is unnecessary or uneconomi cal for given visual discrim ination. 7 Improvement of Popper Theory Popper and his successors tell us that reliability of a scientific proposition comes from the repeated tests by facts. What is the difference between the repeated tests and verification em phasized by logical positivism? Now we distinguish pr ior logical probability and posterior logical probability of a proposition. For the prior logical probability Q ( A j ), the less the better; yet for the po sterior logical probab ility Q ( A j | x i ), the bigger the better. So, both fal sification and verificat ion are necessary. There are many probabilistic and fuzzy propositions , such as “High hum idity will bring rain”, “Thirty years old is young”. Ho w do we falsify or evaluate these propositions? Can we use a counterexample to falsify a proposition? In theses cas es, the above information form ula can give these propositions appropriate evaluations. 8 Conclusions This paper provides the generali zed information criterion, which accords to Popper’s criterion of scientific advance, for sentences selection and data compression. Its ra tionality is supported by predictions’ evaluatio n and many properties of rate-fidelity fun ction. References 1. Shannon, C. E.: A Mathematical Theory of Communication. Bell System Technical Journal, 27 (1948) 379–429, 623–656 2. Weaver, W.: Recent Contributions to the Mathem atical Theory of Communication. In: The Mathematical Theory of Communication , edited by C. E. Shannon and W. Weaver, Un iversity of Illinois Press, Urbana (1949) 3. Bar-Hillel, Y. and Carnap, R.: An Outlin e of a Theory of Semantic Information. Tech. Rep. No.247, Research Lab. of Electronics, MIT (1952) 4. Klir, G. J. and Wierman M. J.: Uncertainty-Based In formation: Elements of Gene ralized Information Theory (Second Edition). Physica-Verlag/Springer-Ver lag, Heidelberg anf New York (1999) 5. Zhong, Y: Principle of Information Science(in Chinese). Beijing: Beijing University of Posts and Telecommunications Press (1996) 6. Lu, C.: Decoding Model of Colour Vision and Verifications. ACTA OPTIC SINICA (in Chinese), 9 (2) (1989) 158-163 7. Lu, C.: Reform of Shannon's Formulas (in Chinese). J. of China Institute of Com munication, 12 (2) (1991) 95- 96 8 8. Lu, C.: Coherence between the generalized mutual information formula and Popper's theory of scientific evolution” (in Chinese). J. of Changsha University, 2 (1991) 41-46 9. Lu C.: A Generalized Information Theory. Ch ina Science and Technology University Press (1993) 10. Lu, C.: Meanings of Generalized Entropy and Generali zed Mutual Information for Coding (in Chinese). J. of China Institute of Communication, 15(6) (1994) 37-44 11. Lu, C.: A Generalization of Sha nnon’s Information Theory. Int. J.of General Systems,28(6) (1999) 453-490 12. Lu, C.: Entropy Theory of Portfolio and Informati on Value. China Science and Technology University Press (1997) 13. Popper, K. R.: Conjectures and Refutations—the Growth of Scientif ic Knowledge. Routledge, London and New York (2002) 14. Kullback, S.: Information and Statistics. John Wiley & Sons Inc., New York (1959) 15. Berger, T.: Rate Distortion Theory. E nglewood Cliffs, N.J.: Prentice-Hall (1971)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment