Robust Audio Watermarking Against the D/A and A/D conversions
Audio watermarking has played an important role in multimedia security. In many applications using audio watermarking, D/A and A/D conversions (denoted by DA/AD in this paper) are often involved. In previous works, however, the robustness issue of au…
Authors: ** - Shijun Xiang (상하이 중산대학, 정보보안 연구소) - Jiwu Huang (상하이 중산대학, 정보보안 연구소) **
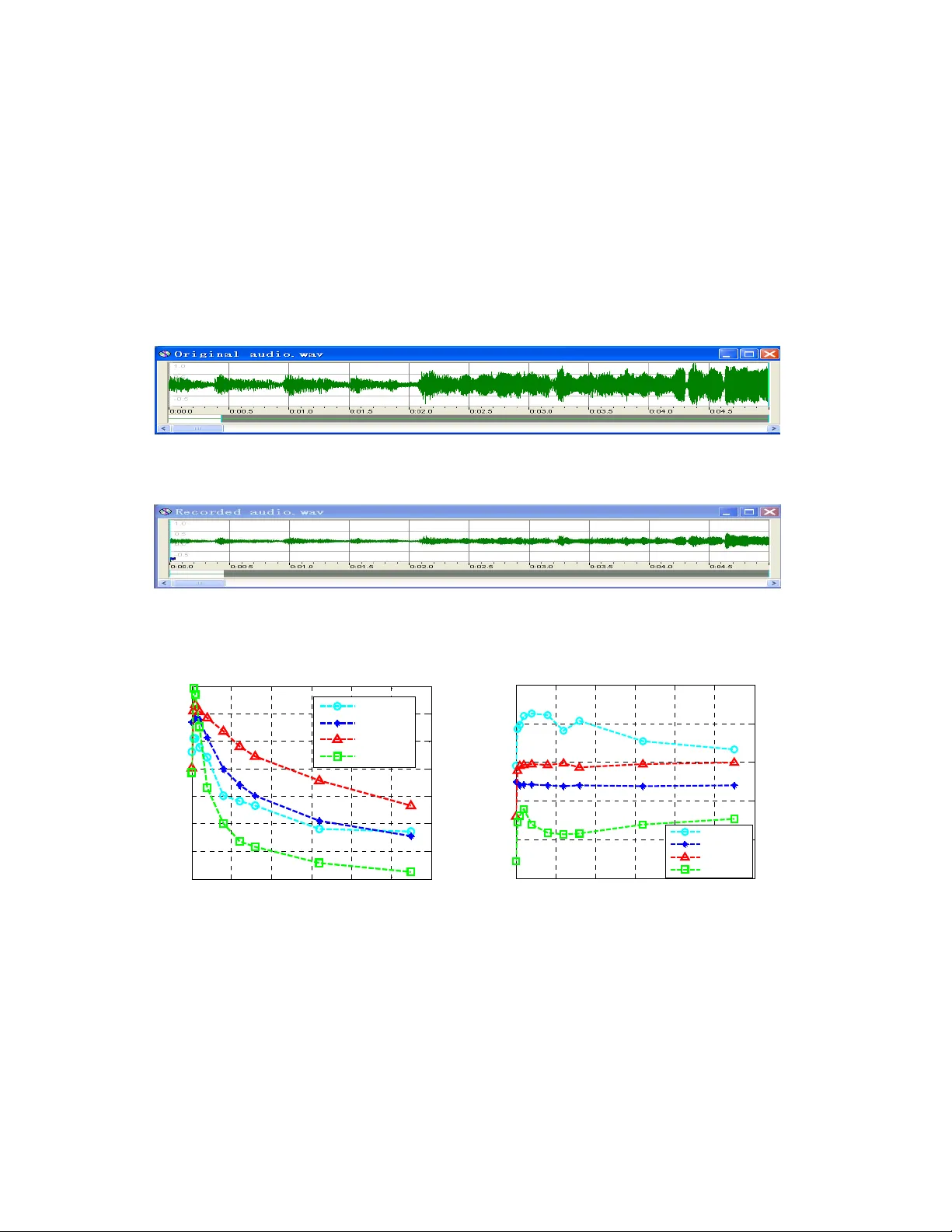
1 Robust Audio W atermarking Aga inst the D/A and A/D Conversions Shijun Xiang 1,2 , Jiwu Hua ng 1,2 xiangshijun@gma il.com , isshjw@mail.sysu.edu.cn 1. School of Informat ion Science and T echnology , Sun Y at -Sen University , Guangzhou 510275, P . R. China. 2. Guangdong Province K ey Laboratory of Informati on Security , Guangzhou, 510275. P . R. Chi na Abstract. Audio watermarking has played an im portant role in m ultimedia se curity . In many applications using audio watermar king, D/A and A/ D conversions (denoted by DA /AD in this paper ) are often invo lved. In previous w orks, however , the robustness issue of audio watermarking again st the DA/AD conver sions has not drawn suf ficient attention yet. In our extensive investigation, it has been found that the degradation of a waterm arked audio signal caused by the DA/AD conversions manifests itself m ainly in term s of wave magnitude distortion and linear temporal scaling, ma king the water mark extr action failed. A ccordingly , a DWT -based audio w atermarking algorithm robust against the DA/AD conversions is pr oposed in this paper . T o resist the magnitude distortion, the relative energy r elationships among dif ferent groups of the DWT coefficients in the low-f requency sub-band are utiliz ed in waterm ark embedding by adaptively contr olling the embedding strength. Furtherm ore, the r esynchroniza tion is designed to cope with the linear tempor al scaling. The time-frequency localiza tion characteristics of DWT are expl oited to save the computational load in the resynchr onization. Consequently , the propos ed audio watermarking algorithm is robust against the DA/AD conversions, other com mon audio pro cessi ng manipulations, and the attacks in S tirMark Benchmark f or Audio, which has be en verified by experim ents. Indexing keywords: Audio W atermarking, D/A and A/D Conversions, Resynchronizatio n, W ave Magnitude Distortion, Linear T empor al Scaling, W avelet T ransform. 2 1. Intr oduction Audio waterm arking [1, 2] plays an im portant role in ownership protection . According to IFPI (International Federati on of the Phonograp hic Industry) [3] , audio watermar king, at a certain data pay load sometim es also r eferred to as data em bedding capacity m ore than 20 bps (Bits Per -Second), should be able to resist the most com mon signal processing manipu la tions and attacks, such as tem poral scaling, noise corruption, MP3 com pression, re-sampling, re-quantiz ation, DA/A D conversions und er the constr aint of imperceptibility ( SNR , S ignal-to-Noise Ratio, should be higher than 20 dB). Audio watermarking may be implem ented in the ti me domain or frequency domain. The m ost typical algorithms in the time dom ain include LSB-based schemes [4], echo hiding [5], and etc. The algo rithms in the frequency dom ain embed waterm ark signal by modif ying transform coeff icients to improve th e robustness. T ransform ations comm only used include DFT (Discrete Fourier T ransform) [6, 7], DW T (Discrete W avelet T ransform) [8] and DCT (D iscrete Co sine T ransform) [9]. Since the water mar ked audio is susceptible to shifting and cr opping (such as editing, signal inter r uption in wir eless transmission and data packet loss in IP network), th e synchronizatio n codes are introduced into audio watermarking [8 -1 1]. In [8, 1 1], the time-frequency localization characteris tics of D WT ar e investigated and utilized to save the computational cost in the resynchr onization and th e watermark rob ustness is improved through data embedding carried out in the low- frequency sub-b and of DWT coefficients. In [1 0], the relationsh ips among dif ferent audio sample segments h ave been us ed to em bed the waterm ark. This is an effective strategy to resist modification of signal am plitude. Be cause data is embedded in the time dom ain, the watermar k thus generated cannot achi eve good robustness perfor mance. T oday’ s audio watermark embeddin g and detection stra tegies often de pend on digital chan nels such as CD, MP3 and IP network transmission. Fro m the sens e of application, however , the robustness of audio waterm arking against th e DA/AD is an important issue [12]. For instance s, in m any ap plications [13-16], waterm arks are re quired to survive in analog envir onm ents, during which the DA /AD ma y be involved. For instance, secret data is proposed to be transmitte d via analog telephone cha nnel in [13], and hidden watermar k signal may be used to identify pirated mu sic through speaker and PC soundcard, for broadcast music [14-15] or live concert [16] m onitoring. While some audio watermarkin g algorithms [10, 13-18] are claimed to be r obust to the DA/AD conversions, the BERs (Bit Error Rate) in these re ferences a r e either not reported o r rather high. 3 Furthermore, there are no technical descriptions on how to r esist the DA /AD conversions. Sp ecifically , none of them have reported ho w to resist the changes caused by th e D A/AD conversions in details . According to the refer ences in [6, 19-20] , the serious degradatio n of audio signal caused by the DA/AD conversions include modification of am plitude and phase, which still puzzles the waterm ark extraction. Therefore, the DA/AD conversions ar e considered a challenging issue for audio watermarking [19]. It is also noted that there are no test functions in Stir Mark Benchm ark for Audio [22, 28] that have been designed for evaluating the robustness of audio wate rmar king to the DA/AD conversion s. In sum mary , to the authors’ best knowledge, among a ll of the literature on audio waterm arking, only [19] has discussed the effects caused by the DA/AD conver sions on audio, but has not provid ed the theoretical deduction and experimental investigation f or the degradations caused by the DA/AD conversions on audio watermarking, such as waveform distortion an d phase modification. V ia extensive investigations, in this paper we analyze and conclude th at the main deg radation of audio watermar k caused by the DA/AD conve rsions is wave m agnitude distor tion and linear temporal scaling. Based on these distortions, we propose the following st rategies accordingly . Firstly , to resist the wave magnitude disto rtion of a water marked audio sign al, we adopt the em bedding stra tegy using the relative ener gy relationships am ong diff erent groups of the DWT in the low- frequency sub- band and adaptively controlling the embedding strength. This is robust to resist com mon signal processing manipulations, especially wave magnitu de distortion. Secondly , the temporal resy nchronization via using synchronization codes is designed to resist the linear temporal s caling. T he watermar k is resynchronized by com puting the scaling factor between two sy nc hronization codes. By exploiti ng the time-fr equency localization characteristics of DWT , the computational load for se arching synchronization code s is dramatically saved. Experimental results have dem onstrated that our pr oposed algorithm is robust to the DA/AD conversions , other comm on audio processing m ani pulations, and the attacks in S tirM ark Benchmark for Audio. The rest of this paper is organize d as follows. Section 2 analyzes the ef fects of the DA/AD conversions on audio watermar king. In Section 3 we introduce the fram ework and ideas of the proposed algorith m. Section 4 discusses data extr action. Section 5 is the perform ance analys is for the pr oposed algorithm. In Section 6, we present the experim e ntal results to demonstrate the pe rf ormance of the proposed alg orithm robust to the DA/AD conver sions and other kinds of a ttacks in S tirMark Benchmark for Audio. Finally , the conclusions are draw n in Section 7. 4 2. Effects of the D A/AD conv ersions on Audio W atermarking In this section, the effect of the DA/AD conversi ons on audio watermarking is investigated. In real applications, there are differ ent kinds of transmission channels [21]. In this pap er , we are focusing on the effect of the DA/AD conversions without the consideration of analog channels. 2.1. T est Scenario In order to investigate the ef fects caused by the DA /AD co nversions on audio si gnals, we have designed and used the following test model, as shown in Fig.1. The analog channe l may be considered clear here by using a cable line. Ta b l e 1 . Four dif ferent to-be-tested audio files File name Lengths (Sec. ) Properties marc h.wav 56 compositi on of both low and high-frequency drum.wav 56 mainl y composed of low frequency flute.wav 56 well-proportione d frequency distri bution dialog.wav 56 daily di alog Based on the test model in Fig.1, we test m any dif ferent audio files based on four dif ferent 16-bit signed mono audio files in the W A VE f ormat with diff erent f requency pr operties, denoted by mar ch.wav , drum.wav , flute.wav and dialog .wav , sampled at 8, 1 1.025, 16, 22.05, 32, 44. 1, 48, 96 and 128kHz f or the purpose of testing, r espectively , as listed in T able 1. The dialog.wav is about a daily dialog while others three are music generated by the respective music instru ments, such as drum , flute, etc. Audio files are played with the tool W indow Media Player 9.0 , after th e DA conversion caused by a sound card the transforme d analog signal is output via the Speaker port to the Line in port of the sam e or other soundcard, and recorded by the professional tool CoolEd it 2.1 . Speaker po rt of soundcar d (D/A ) Cab le Line in po rt of soundcard (A /D ) Digital Playing back audi o si gnals Rec or di ng audi o si gnals ' f ' F Ff Analog Analog Digital Fi g . 1. T est model for the DA/AD conversions 5 2.2. Effects of the DA/AD conversions on Audio During the DA/AD conversions, digital audio signal will suf fer from the following factors [19]. i. Noise produced by soundcar ds during DA conversion. ii. Modification of audio signal energy and noise ener gy . iii. Noise in analog channel. iv. Noise produced by soundcard during the AD conversion including q uantization distortion. Obviously , the digital audio will be distorted after the DA/AD conversions. However , the above knowledge for these distortion s is not expressly helpful to design rob ust watermar king against the DA/AD conversions, we need to f urther investigate a nd m odel them. The detail is described below . 2.2.1. Linear T emporal Scaling Based on the test model shown in Fig.1, num erous dif f erent soundcards are em ployed to test audio files with differ ent sampling frequencies described in T able 1. The experim e ntal results regarding tim e-scaling during the DA/AD conver sions as shown in T able 2. Sound Blaster Live5.1 is a consumer gr ade sound board, ICON S tudioPr o7.1 is professional on e, Realtek AC'97 audio for VIA (R) Audio contr oller , Audio PCI and SoundMAX Digital A udio are comm on PC sound blaster . From T able 2, it is noted that during the DA/AD convers ions, the time scalin g is existing. Th e detailed observations are described as follows. i. The scaling factor is dif ferent for differen t soundcards. In other wor ds, during the DA/AD conversions, dif ferent perform anc e of soundcards will cau se diff erent tim e-scale distortion. ii. The scaling factor is also related to the sampling ra te of audio files. For the sam e soundcard, dif ferent sampling rate of aud io file wil l have a differ ent scaling distortion duri ng the DA/AD conversions , referred to T able 2. As for other sampling rates (e.g., 22.5 kHz), the conclusion is sim ilar . iii. The temporal scaling is similar to using two differ ent soundcards are used at a tim e (One is used to perform the D A conversion while the other for the AD processing). iv. According to our observations, the scaling factor is in [0, 0.005] f or differ ent soundcards and dif ferent sampling rates of differen t kinds of audio files. 6 Soundcard Ta b l e 2 . The number of samples change d with the sampli ng rate of 8 and 44.1 kHz, respectively Blaster Live5.1 Realtek AC'97 Audio 2000 PCI S tudio Pro 7.1 SoundMAX Digit al Aud io 8 kHz 10s Reduce: 1 Increase: 5 Increase: Reduce: 70 Increase: 1 20s Reduce: 2 Increase: 10 Increase: Reduce: 140 Increase: 2 30s Reduce: 3 Increase: 15 Increase: Reduce: 210 Increase: 3 40s Reduce: 4 Increase: 20 Increase: Reduce: 280 Increase: 4 50s Reduce: 5 Increase: 25 Increase: Reduce: 350 Increase: 5 44.1 kHz 10s Reduce: 6 Increase: 4 Increas e: 0 Increase: 0 Increase: 2 20s Reduce: 12 Increase: 8 Increase: 0 Increase: 0 Increase: 4 30s Reduce: 18 Increase: 12 Increase: 0 Increase: 0 Increase: 6 40s Reduce: 24 Increase: 16 Increase: 0 Increase: 0 Increase: 8 50s Reduce: 30 Increase: 20 Increase: 0 Increase: 0 Increase: 10 2.2.2. W ave Magnitude Distortion Besides linear tem poral scaling discussed above, anot h er kind of degr adation on the digital audio caused by the DA/AD conversio ns is wave magnitude distor tion, wh ich is mainly represented as the modification of signal ener gy and additional noise corruption . This has been verified by our num erous experime nts. It is observed that the audio amplitudes are m odified du ring the DA/AD conversions, and the amount of the modification relies on the volum e played back, and th e perf ormance of soundcard. Fig.2 and Fig.3 have the same scaling in both horizontal a nd ver tical axis in displaying wa ves of the o riginal audio and the corresponding recorded audio by the Blaster Live5.1 soundcard. Compared with the original audio, th e amplitude of the recorded audio is obviously reduced. Modif ication of th e am plitude varies with different soundcards. We u s e SNR to measure the distortion of the recorded au dios versus the or iginal audios here. Th e SNR between F and F ″ can be expressed as ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − = ∑ ∑ = = N i N i i f i f i f SNR 1 2 1 2 10 )] ( [ )] ( ' ) ( [ log 10 ( 1 ) ∑ ∑ − = − = × = 1 0 1 0 ) ( ' ) ( ) ( ' ) ( " N i N i i f i f i f i f ( 2 ) Tim e 7 where { } ) 1 ( ),... 1 ( ), 0 ( − = N f f f F , { } ) 1 ( ' ),... 1 ( ' ), 0 ( ' ' − = N f f f F and { } ) 1 ( " ),... 1 ( " ), 0 ( " " − = N f f f F are the original audio, the recorde d audio and th e normalized audio by Equation (2), respectively . ) ( i f , ) ( ' i f and ) ( " i f are amplitude of the i th sample of F , F ′ and F ″ , r espectively . Note that in the case of linear temporal scaling, F " should be resynchronized (refer to Sec tion 4.1) to generate the resynchronized audio, " 1 F . Finally , SNR s between the original audios and the re corded audios after normalizatio n and resynchronization are calculated. For experim ental description, we choose the soundcard So und Blaster Live5.1 and audio f iles in T able 1 sampled at 44.1 kHz, to test the wave magnitude dist or tion caused by the DA/AD conversions based on the test model in Fig.1. SNR s of F versus F ″ and " 1 F are calculated shown in Figs.4 a nd 5, respectively . Fig.4 shows that SNR s of som e dif ferent audio signals F ″ with respect to F decrease quickly , Fig. 2. The original audio Fig. 3. The recorded audio 0 10 20 30 40 50 60 -5 0 5 10 15 20 25 30 Ti m e ( s ) SN R ( d b ) S NR of F and F" dialog. wav ma r ch .w a v drum .wav f lut e.wa v 0 10 20 30 40 50 60 10 15 20 25 30 35 Ti m e ( s ) S NR(d b) S NR of F and F " 1 dialog.wav ma r ch .w a v drum . wav fl u t e. w a v Fig. 4. SNR curve s before resynch ronization F ig. 5. SNR curves after resynchronizat ion 8 demonstrating that linear temporal scaling changed th e locations of some samp les and thus resulted in serious distortion. And F ig.5 shows the SNR s of som e diff erent audio signals " 1 F with respect to F , indicating that the resynchronization ef fe ctively resists linear tempor al scaling. 2.3. Effects of the DA/AD Conve rsions on Audio W atermarking In Section 2.2, we discussed the distor tion of audi o signals caused by the DA/AD conversio ns, including linear tempor al scaling and wave magnitude distortion . Fr om signal pr ocessing poi nt of view , watermarks are weak signals embedded in str ong background, such as digital audio and im age. Therefore, any changes of the cover -signal will directly influence the survival of the watermarks . Hence, it is expected that audio watermar king will suff er from the DA/AD conver sions in term s of the following two aspects. i. Linear tem poral scaling, meaning that the sh ift of audio sam ples in the time domain will directly influence the detection of the embedded waterm ark. ii. Audio signal magnitude distortion, meaning that the ef fect of signal energy modification followed by an additive noise will af fect waterm ark extraction. Mathematically speaking, the ef fect of the DA/AD conv ersions on Audi o W a termarking can be formulated as follows, '( ) ( ) i fi f λ η α = ⋅+ ( 3 ) where α and λ denote linear temporal scaling fact or and amplitude scaling factor , η is additive noise on the sample () f i , and '( ) f i is the version of () f i after the DA/AD Conversions. If i α is not an integer , () i f α is interpolated with the nearest sam ples in the shifted audio sign al. V i a extensive e xperiments , a suggesting value of par ameters is given: ] 005 . 0 , 0 [ ⊂ α , ] 0 . 2 , 5 . 0 [ ⊂ λ . 3. Proposed Embedding Algorithm After investigating the ef fect of linear temp oral scaling and wave m agnitud e distor tion caused by the DA/AD conversions, a new watermarki ng procedure is pr oposed to com b at the d egradation due to the DA/AD conversions. Referred to Equation (3), to res ist wave magnitude distortion f ormulated as the effect 9 of the param eters λ and η , the relative ener gy relationships am ong dif ferent groups of the DWT coefficients in the low-frequency sub- band are used in th e embedding stage by adaptively contr olling the embedding strength. Fur thermore, the resynchronization is designed to cope with lin ear temporal scaling in the detection by referring to the eff ect of the parameter α . The proposed watermar king strategy is addressed below . 3.1. Embedding Framework The main idea of the proposed embe dding algorithm is to split a long a udio into many segm ents, and then embed one sy nchronization code and a portion of to-be-em bedded informa tion bits into the DWT coef ficients in the low-frequency sub- band of each segment. The em bedding mo del is shown in Fig.6. In the algorithm, the water mark bits are embedded in such a way that the embedding strength is adaptively controlled to achieve the largest value under the im perceptibility constraint (the O DG value is in [0, -2]). The detail is desc ribed as f ollows. Suppose that S 1 is the ODG of the wate rm arked audio versus the original audio, S 0 , a predefined value. If S 1 < S 0 , the embedding strength will be autom atically decreased until S 1 ≥ S 0 . The ODG is computed in the DWT domain inst ead of in the time domain. This ef ficiently reduces the computational lo ad by av oiding the inverse discrete wavelet transform (IDWT) process. After the watermark embedded, the IDWT is performe d to r econstruct the watermar ked audio. Usually , the SNR is used to measure the distorti on due to the waterm ark. Since the SN R is not an acceptable measur e for audio quality without the consideration of the hum an auditory system , here the ODG value of PEAQ m odel is used to control the waterm arking distortion instead of comm on SNR measure r eferred to Section 6.1, the distortion caused by the watermark is considered acceptable when the ODG value is in [0, -2]. Original audio signal Segmenting and performi ng DWT for our segments Embedding IDWT Synchronization code Informativ e data Watermarked audio signal ODG Segment s linking Fig. 6. W atermark embedding framework 10 3.2. Embedding S trategy As mentioned above and w ill be fu rther discussed in the rest of th is paper , the proposed em bedding algorithm is conducted in DW T dom ain because of its su periority . T o hi de data robust to m odification of audio amplitude, the waterm arks are embedded in DW T dom ain by using the r elative relationships among differ ent groups of the DWT coefficients, { c ( i )}. It is noted that utilizing th e relationships am ong different audio sample sections to em bed data is proposed in [10]. However , what proposed in this paper is dif ferent from [1 0]. First, instead of in the tim e domain, we embed watermar k signal in the low-frequency sub-band of DWT in order to achieve better robustness perfor mance. Furthermore, in the DWT domain, the time- frequency localization char acteristic of DW T can be exp loited to save the computational load dur ing searching for sy nchronization codes [8, 1 1]. Denote three consecutive D WT coef ficient groups by Group_1, Group _2 and Group _3. Each group includ es L coefficien ts, as shown in Fig.7. Generally , L is chosen based on the em bedding bit rate, SNR of the waterm arked audio and the embedding strength. The ener gy of t hose three coef ficient groups, denoted by E 1 , E 2 and E 3 , respectively , is defined as ∑ − = = 1 0 1 ) ( L i i c E , ∑ − = = 1 2 2 ) ( L L i i c E , ∑ − = = 1 3 2 3 ) ( L L i i c E (4) where c ( i ) is the i th DWT coef ficient in the low-frequenc y subband. So the ir ener gy dif ferences may be obtained according to the following equation. ⎩ ⎨ ⎧ − = − = min max E E B E E A med med ( 5 ) where } , , max{ 3 2 1 max E E E E = , 123 {, , } med Em e d E E E = , } , , min{ 3 2 1 min E E E E = , and max , med and min are up operations picking the maximum , medium and minimu m of E 1 , E 2 and E 3 . A and B stan d for th e energy diff erences. Equation (6) is exploite d to express the em bedding strength. c(i) i 0 L2 L 3 L Group_1 Group_ 2 Group_3 Fig. 7. Three consecutive coef ficient groups in DWT low-freq uency subband 11 31 0 (( ) ) / 3 L i Sd c i − = =⋅ ∑ ( 6 ) The p arameter d in Equation (6) is the em bedding strength fa ctor , which plays a role in deciding the embedding strength S . T o resist wave m agnitude distortion dur ing th e DA/AD conversions, the value of d should be as lar ge as possible under th e imperceptibility constraint (measured by OD G ). Usually , during embedding waterm arks, d is assigned with a predefined value at first, and then modified automatically until SNR of the watermarked audio falls into the predefined range. SNR reduces as d increasing. After calculating the ener gy dif fer ences among th re e DWT coef ficient groups by Equation (5), one watermar k bit w ( i ) may be em bedded through the relationship between A and B , shown as Equation ( 7). ⎩ ⎨ ⎧ = ≥ − = ≥ − 0 ) ( 1 ) ( i w if S A B i w if S B A ( 7 ) Note that if the embedded bit w ( i ) is ‘1’ and A BS − ≥ or the embedded bit w ( i ) is ‘0’ and BA S −≥ , then there is no op eration. Otherw ise , the values of diff erent groups of the DWT coef ficients used to compute E max , E med and E min will be adjusted until satisfying A BS − ≥ or BA S − ≥ in term s of the embedded bit, referred to E quation (4). The rules app lied to modify E max , E med and E min are formulated as Equations (8 ), (9), (10) an d (11). If the embedded bit w ( i ) is ‘1’ and S B A < − , we apply Equation (8) by m odifying the values of dif ferent groups of the D WT coef ficients to satisf y A BS − ≥ : max min max min max min || () ( 1 ) , () 2 '( ) || () ( 1 ), () 2 med med med c i if c i is coefs used to generate E and E EE E ci c i if c i is coefs u sed to generate E EE E β β ⎧ ×+ ⎪ ++ ⎪ = ⎨ ⎪ ×− ⎪ ++ ⎩ ( 8 ) where || | | A BS S AB β =− − = − + . Modifying the D WT coef ficients to embedding ‘ 1’ with Equation (8) may cause the case that min med EE < due to the increase of E min and the decrease of E med . Obviously , this situation will influence the watermark extrac tion. In order to remain the relation of max min med EEE ≥≥ after em bedding ‘1’, we derive Equation (9 ) to control the em bedding strength. max min min 2 () med med E SE E EE ≤− + ( 9 ) 12 Similarly , if w ( i ) is ‘0’ and S A B < − , we apply Equation (10) by modifying the valu es of different groups of the D WT coef ficients to satisf y S A B ≥ − : max min max min max min || () ( 1 ) , () 2 '( ) || () ( 1 ) , () 2 med med med c i if c i is coefs u sed to generate E and E EE E ci ci i f ci i s c o e f s u s e d t o g e n e r a t e E EE E β β ⎧ ×− ⎪ ++ ⎪ = ⎨ ⎪ ×+ ⎪ ++ ⎩ ( 10 ) where || | | BA S S A B β =− − = + − . Also, using Equation (10) to mo dify the DWT coeff icients to embed bit ‘0’ may lead to mm a x ed EE > due to the increase of E med and the decr ease of E max . This will influence the watermar k extraction. Accordingly , we deduct Equa tion (1 1) to elude the case by controlling the embedding strength. max min max 2 () med med E SE E EE ≤− + ( 11 ) For the proof of Equations (9) and (1 1), please refer to APPENDIX I and II. It is worth notin g that our proposed waterm arking embe dding strategy is lar gely dif ferent from that in [10]. Comp ared with the method in [10], our prop osed strategy ef ficiently rem ains the relation of the maxima l, middle and m inimal unchanged, that is E max > E med > E min before the em bedding and after th e embedding E’ max > E’ med > E’ min . In addition, the computation cost is reduced, i.e. the co mputation load is (3 ) OL × for our proposed strategy and (3 ) OL M ×× in [10], respectively . M , often greater than 1, is the repeated times in the embedding. 3.3. W atermarking and Synchroniz ation Code The algorithm exploits a P N (Pseudo-random Nois e) sequence as a synchronization code. The synchronization code is used to locate the position of hidden inform ative bits, thus resisting the cropping and shifting attacks [8]. In this pa per , the synchronization code is in troduced to resist linear temporal scaling caused by the DA/AD conversions. Suppose { Syn ( i )} is an original synch ronization code and { Seq ( i )} is an unknown sequen ce both having the same length. If the number of dif ferent bits between { Syn ( i )} and { Seq ( i )}, when compared bit-by-bit, are less than or equal to a predefined threshold, T , the sequence { Seq ( i )} will be determined as the synchronization code. The analysis of error pr obabili ty in searching sy nchronization codes is given in 13 Section 5.2. T o make the w atermark robust to linear tem poral scaling dur ing the DA/AD conversion s, we embed the watermar k with synchronization codes. Before em bedding, the sy nchronization codes { Syn ( i )} and watermar k { Wmk ( i )} should be arranged into a b inary da ta s equence, as shown in Fig. 8. According to the length of { Syn ( i )} and { Wmk ( i )}, th e original audio is split into pr oper segments and then perform DWT o n each segment. As show n in Fig.8 and Fig.9, the sequences { Syn ( i )} and { Wmk ( i )} are embedded into the DWT low-freq uency sub-band of Segm ent_1 and Segment_2, respectively . W e embed one inform ation bit in three DWT coef ficient groups see Fig. 7), including 3 × L coefficients. Let N 1 and N 2 denote the lengths of samples in Segm en t_1 and Segment_2 in the tim e domain. So ) ( 2 3 1 code ation synchroniz of length The L N K × × = ( 12 ) ) ( 2 3 2 watermark the of length The L N K × × = ( 13 ) where K is the levels of DWT decom position, and L is the number of the DWT coefficients in a gr oup. 4. Pr oposed Extr action Algorithm Linear temporal scaling will m odify the positions of audio samples and lead to serous distortion ( as discussed in Section 2.2). T o resist linear temporal scaling, synchronization co des and the strategy of resynchronization are applied in the extracting. Du r ing searching for synchronization codes, the tim e- frequency localization characteristics of DWT are expl oited to save the computa tional load. The m odel of data extraction is shown in Fig.10. 4.1. Resynchronization in the Time Domain After the DA/AD conversions, we need to locate the em bedded watermark bits by sear ching for Synchroniz ation Code { Syn ( i )} Watermark { Wmk ( i )} …… …… Synchroniz ation Co de { Syn ( i )} Watermar k { Wmk ( i )} Fig. 8. Data structure of hidden bit stream Segment_ 1 N 1 Segment_ 2 N 2 Segment_ 1 N 1 Segment_2 N 2 …… …… Fig. 9. Segm enting of the host audio signal 14 synchronization code in to-be-tested au dio, ' F , and then com pute the num ber of the samples between two synchronization codes, denoted as ' 2 N . Note that the number of the samples N 2 in the original watermar ked audio between two synch r onization codes is a predefined value (refer to Section 3.3). Since linear tempor al scaling occurs repeatedly dur ing the DA /AD conver sions (refer to Section 2.2.1), a scaling factor is defined to perform the re synchronization, described as follows. Suppose that {} 1 , , 1 , 0 | ) ( 2 − = = N i i f F L and { } ) 1 ' ( ' ),... 1 ( ' ), 0 ( ' ' 2 − = N f f f F are the orig inal watermar ked audio and the audio after the DA/AD conversions betw een two synchronization co des, respectively . W e def ine the scaling factor as 2 2 / ' N N = α ( 14 ) In searching synchronizatio n codes, the computational load has been dramatically reduced by using the time-fr equency localization ch aracteristics of DWT . Thus it resolv es the contending requirements between robustness of hidden data and efficiency of synchr onization codes searching. The resynchronization is a procedure bas ed on the interpolation processing, which is designed to descale the linear temporal sc aling. W e have tested a few kinds of interpolation formulas (s uch as Lagrange, Newton, etc.), and the simulation results are similar in terms of resisting the linear tem poral scaling. Referred to Fig. 1 1, here, we list the most ef ficient Lagrange linear in terpolation as follows,. Segmenting and DW T Data extracting Retrieving informat ive data Unknow au dio Informative data Performing Resynchronization Synchronization code searching Relocating Not found Found Fig. 10. Block diagram of data extraction ) ( " i f α β ) 1 ( β − ⎣ ⎦ 1 + i α ⎣ ⎦ 2 + i α ⎣ ⎦ ) ( ' i f α ⎣⎦ 1 − i α ⎣⎦ ) 1 ( ' − i f α ⎣ ⎦ ) 1 ( ' + i f α ⎣ ⎦ ) 2 ( ' + i f α …… …… Fig. 1 1. The sketch map of resynchronization op eration in Equation (15). 15 ⎣⎦ ⎣⎦ ⎪ ⎩ ⎪ ⎨ ⎧ − = − − < < + ⋅ ⋅ + ⋅ ⋅ − = = 1 ), 1 ' ( ' , 1 0 ), 1 ( ' ) ( ' ) 1 ( , 0 ), 0 ( ' ) ( 2 2 2 " N i if N f N i if i f i f i if f i f α β α β ( 15 ) where { } ) 1 ( ),... 1 ( ), 0 ( 2 " " " " − = N f f f F is the version of ' F after synchronization m anipulation, ) ( " i f and ) ( ' j f the i th and j th sample of " F and ' F , 1 0 2 − ≤ ≤ N i , 1 ' 0 2 − ≤ ≤ N j , ⎣ ⎦ the floor function. ⎣⎦ i i ⋅ − ⋅ = α α β . 4.2. Data Extractio n After resynchronization, we per form the sa me D WT on the resynchronized audio segment " F as in the embedding to obtain the low- fre quency sub-band coef ficients {" ( ) } ci . As in Equation (4), we compute " 1 E , " 2 E and " 3 E . Where, ∑ − = = 1 0 " " 1 ) ( L i i c E , ∑ − = = 1 2 " " 2 ) ( L L i i c E , ∑ − = = 1 3 2 " " 3 ) ( L L i i c E , then which are or dered to obtain " max E , " med E and " min E . Similar to Equation (5), we defined ⎩ ⎨ ⎧ − = − = − = − = } , , min{ } , , { } , , { } , , max{ " 3 " 2 " 1 " 3 " 2 " 1 " min " " " 3 " 2 " 1 " 3 " 2 " 1 " " max " E E E E E E med E E B E E E med E E E E E A med med ( 16 ) Comparing " A and " B , we get the retrieved bit by using the following rule. ⎩ ⎨ ⎧ < − ≥ − = 0 0 0 1 ) ( " " " " " B A if B A if i w ( 17 ) The process is repeated to retrieve the whole binary data stream. In the extracting, the synchronization sequence { Seq ( i )} and the num ber of sam ples predefined between two synchronization codes N 2 are befor ehand known, and the original DWT coef ficients are not required in the extracting. Thus, waterm arking detection is blind. 5. Performa nce Analysis In this section, we evaluate the pe rformance of the proposed algorithm in term s of data em bedding capacity or payload, error probability of sy nchronization codes and watermarks, an d resisting am plitude modification attack. The BER is defined as 16 % 100 × = bits total of Number bits error of Number BER ( 18 ) Because we use the orthogonal wavelet in o ur algorith m and the em bedding rules in Section 3.2 d o not change the DWT coefficients in the high-frequency subbands of F , we rewrite Eq uation (1) as ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ ′ − − = ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − = 2 2 2 2 10 2 2 2 2 10 log 10 ' log 10 F C C F F F SNR (19) where } { i c C = and } { i c C ′ = ′ are the DWT coef ficients in low frequency sub-band of F and F ′ a f t e r a K - level DWT . 5.1. Data Embedding Capacity The data embedding capacity r efers to the num ber of bits that are embedded into the audio signal within a unit of time, measur ed in the unit of bps and denoted by B . Suppose that the sam pling rate of audio is R (Hz). The data embedding capacity B of the proposed algorith m can be expressed as ) ( ) 2 3 /( bps L R B K ⋅ ⋅ = ( 20 ) where K and L denotes wavelet decomposition level and the number of the DWT coef ficients in a group. 5.2. Error Analysis on Synchr onization Code Sear ching There are two types of errors in searching synchroni zation codes, f alse positive error and false negative error . A false positive error occurs wh en a synchronization code is supposed to be de tected in the location where no synchronization co de is embedded, while a f alse negative error occurs when an existing synchronization cod e is m issed. Once a false positive er ror occurs, the bits after the locations of the false synchronization code will be regarded as the watermar k bits. When a false negative error takes place, some watermar k bits will be lost. The false positiv e error probability of the synchronization code P 1 can be calculated as follows: ∑ = ⋅ = T k k N N C P 0 1 1 1 2 1 ( 21 ) where N 1 is the length of a sy nchronization code, and T is the threshold introduced in Section 3.3. Generally , we use the following formulation to evaluate the false ne gative error probability P 2 of the 17 synchronization code according to th e bit error probability , denoted as P d , in the detector . ∑ + = − − ⋅ ⋅ = 1 1 1 1 2 ) 1 ( ) ( N T k k N d k d k N P P C P ( 22 ) In our works, how to resynchronize the waterm ark is an im portant issue after the DA/A D conversions since the watermark is tracked by usin g synchroniza tion codes. Therefore, we need to consider the robustness of synchr onization codes to the linear tem p oral scaling caused by the DA/AD conversions. In [1 1], the authors proposed a s trategy by increasi ng the r edundancy of the sy nchronization bits and watermark bits locally to improve the robustness of th e watermar k and successfully resist pitch-invar iant TSM (T ime-Scale Modification) attacks of 4%. Specif ically , an 8-bit synchronization sequence with the local redundancy rate 3, 1010101 1, is defined as 11 100011 10001 1 1000 111111 . A c t u a l l y, t h e r e dundancy is a simple style of ECC (Err or Correcting Codes) [30]. In most of cases during DA/AD conversions, the amount of the linear temporal scaling is ver y small, es pecially at 44.1 kHz or high er only several even no samples shifted (referr ed to Section 2.2.1). In other wo rds, it is a feasible wa y to im prove the robustness of the synchronization code thro ugh using the local redundancy . In our extensive experiments, the synchronization co de with the length of 31 bits is robust to the linear tem poral scaling caused by the DA/AD conversions. 5.3. Error Analysis on W atermark Extraction It is noted that the introduction of synchronization codes in the algorithm may make the dif fer ence between the bit error probability of the watermark in the detector P d and in the channel P w , illustrated in Fig.12. Supposed th at x , the number of sy nchronization codes, ar e embedded and the num ber of the false positive synchronization codes and false nega tive synchronization c odes detected is y and z , respectively . So the error probability P w may be expressed as follows. The false positive error probability P 1 can be expressed as ) /( y z x y + − here. Fig. 12 . T he sketch map of the watermark bit er ro r probability in the channel and detector Encoder De t e c t o r A udio s i gnal Cha nn e l Wa t e r ma r k s No i s e P w P d 18 aw sw aw sw w P P P P N z y x P N y P N z x P ⋅ + ⋅ − = ⋅ − + ⋅ ⋅ + ⋅ ⋅ − = 1 1 2 2 2 ) 1 ( ) ( ) ( (23) In Equation (23), N 2 is the leng th of the waterm ark bits, w hich follow a corresponding synchronization code, P sw and P aw denote the error probability of the waterm ar ks in case of false negative and positive synchronization code occurring. From the view of point in probability theor y , the value of P sw and P aw is approximately P d and 50%. Accordingly , we have the following form ulation. % 50 ) 1 ( ) 1 ( 1 1 1 1 ⋅ + ⋅ − ≈ ⋅ + ⋅ − = P P P P P P P P d aw sw w ( 24 ) From Equation (24), it is noted that the bit error prob ability of the watermark in the channel is different from that in the detector after intro ducing synchronization code, and the dif fer ence mainly relies on the number of the false positiv e sync hronization code. T he occurring of the false negative synchronization code will lead to the loss of som e hidden information bits, the effect of w hich on the error probability of the watermark may be ignored. When the value of y go to ZERO, P 1 goes to ZERO, thus P w goes to P d . 5.4. Amplitude Modification Attack Some audio signal processing or hostile attacks m ay m odify the audio amplitude s, such as the wave magnitude distortion caused by the DA/AD conv ersion, which m ay be considered as amplitude scaling followed by the additional noise. Refer to Equati on (4), the su ms of dif ferent groups of the DW T coef ficients after a mplitude m odification attack ma y be form ulated as 1 max max ' Δ + ⋅ = E E ϕ , 2 ' Δ + ⋅ = med med E E ϕ , 3 min min ' Δ + ⋅ = E E ϕ . So, using E quation (5) the dif ference between A ′ and B ′ after the amplitude m odification attack is computed as max min max min 1 2 3 max min max min 2 1 3 '' ' 2 ' ' ( 2 ) 2 '' 2 ' ' ' ( 2 ) 2 med med med med AB E E E E E E BA E E E E E E ϕ ϕ −= − + = ⋅ − + + Δ − Δ + Δ ⎧ ⎨ − = − − = ⋅ − − + Δ −Δ −Δ ⎩ ( 25 ) where ϕ is amplitude scaling factor , 1 Δ , 2 Δ and 3 Δ the maxim um, m edium and minim um of th e additional noise in three c onsecutive DWT coef ficient groups, respectively . By using Equations (5), (6), (7) and (17), we may conclude the conditions to correctly extr act the watermar k bit w ( i ), defined as follows, 12 3 m a x m i n 12 3 m a x m i n 2( 2 ) () 1 2( 2 ) () 0 med med EE E if w i EEE if w i ϕϕ σ ϕϕ σ Δ− Δ + Δ ≥ − ⋅ − + ≥ − ⋅ = ⎧ ⎨ Δ− Δ + Δ ≤ ⋅ − − < ⋅ = ⎩ ( 26 ) where max min 2 med SE E E σ ≤− + ≤ if w ( i ) = 1, and max min 2 med SE E E σ ≤ −− ≤ if w ( i ) = 0. S is the 19 embedding strength, a positive number . For amplitude scaling attack, 123 0 Δ= Δ = Δ = and 0 ϕ σ ⋅ ≥ , indicating that w ( i ) can be always de tected correctly by Equation (26), m eaning that the wate rmark is robust to amp litude scaling attack. 6. Experimen tal Resul ts In the following experim ents, each synchronization code is composed of a 31 bit m- sequence and the corresponding waterm ark is a binary sequence with 32 bits. Six deco mposition levels o f db2 wavelet are applied. The length of the DWT coef ficient group L (refer to Fig.7) is 8. W ith Equation (20), we can estimate the data embedding capacity as 28.71 bps for 44.1 kHz of sampling rate. It needs an audio segment about 2.2 seconds to em bed a synchronization code and a waterm ark. T otally 25 synchronization codes and watermar ks are embedded in audio of 56 seconds, the length of the watermarks 800 bits. 6.1. Quality Evaluation of W atermark ed Audio The SNRs between the original audio an d the watermar ked audios are controlled as 20+ dB, satisf ying the IFPI requirem ent, and the waterm arks are not impercep tible during listening test. Since the SNR values are definitely NOT a good im perceptibility m easure, here we also provide w ith m ore relevant imperceptibility results through the softwar e EAQUAL 0.1.3 alpha [23-24], which consider s HAS (hum an auditory system ) models. EAQUAL is coded by the ITU-R recom mendati on BS.13 87 [25] to stand for watermar ked audio quality . T able 3 shows the value of MOVs (Model Output V ar iables), and the corresponding SNRs of audio files are 23.67 ( march.wav ), 21.67 ( drum.wav ), 29. 97 ( flute.wav ) and 15.63 ( dialog.wav ). In T able 3, the NMR (Noise-T o-Mask-Ratiovalue) of the files drum.wav and dialog.wav is respectively 15.94 and 4.23 more than 1.5 dB while their correspondi ng ODG (Objective Difference Grade) value is -3.91 and -3.77, very close to - 4. The audio quality rati ngs are measu red with the five point scale defined in ITU-R BS.1 11 6 and thus the SDG and OD G have a ra nge of [-4;0] wh ere -4 stands for very annoying diff erence and 0 stands for im perceptible dif ference be tween refer ence and test signal. In addition, if the NMR of any frequency b and is higher 1.5dB the f rame is assu med to be disturbed. In this case, the mar ch.wav and flute.wav is considered inaudible because their ODGs are close to ZERO and NMRs are less than 1.5 dB. And, the drum.wav and dialog.wav are assumed to be dist urbed by the watermarks embedded, but the SNR value of drum.wav is an acceptable value 21.67 dB according to IFPI [3] , 20 indicating the test standard based on EAQUAL and SNR is lar gely dif fer ent. There fore, adap tive watermar k embedding via MOV s instead of SNR is applied in this paper , referred to Fig.6. About the detail descriptions of MOVs, please refer to [23-26]. 6.2. Robustness Performance Ta b l e 4 shows the robustness of the waterm arks embedde d in audios w ith sampling rate of 44.1 kH z against the DA/AD conversions by Sound Blaster Live5.1 soundcard. Clearly , the introduction of synchronization technique lar gely reduces BER , aver age from 16.75% to 0.4375%, and f urther reduced to 0.0625% by using resynchr onization manipulation . Obviously , the proposed algorithm efficien tly impr oves the robustness of the watermark against the DA/AD conver sions. It m eans that the em bedding st rategy based on relative ener gy relationships am ong diff erent groups of the DWT coefficients has resist ed wave magnitud e distortion ca used by the DA/AD conversions and the resynchron iza tion operation based on the interpolatio n processing has descaled the linear tempor al scaling. Accordingl y , we believe t hat the linear tem poral scaling caused by the DA/A D conversions may be m odeled as an in terpolation processing, equivalent to the playback speed m odification presented in [29], and the resynchr onization operation is the corres ponding inver se processing operation. In the extraction, the number of the false po sitive synchronization c odes and f alse negative synchronization codes detected is zero , thus according to Equations (23) or (24). S o we ma y use P d to evaluate the false ne gative error probability P 2 by using Equation (22). T o choose the threshold T , both the false positive error probability and th e false negative er ror probability should be consider ed. W e choose T to be 5 in our work based on T able 5. T able 6 shows that our algorithms are very robust to comm on signal processing manipulations such as mp3 com pression, amplitude scaling, re-sam pling and re-quantization, lo w-pass filtering (LPF), and etc. It is owing to that in proposed w atermarking schem e the waterm ark is embedded in the low- frequency component of DWT domain. Ta b l e 7 shows the performance of our algorith m and seve ral recent audio wat ermarking st rategies i n [8, 10, 17, 18] against the DA/AD conversions, and so m e comm on audio processi ng m anipulations, lik e Gaussian noise corruption and MP3 compr ession. Thes e algorithm s are im plemented and sim ulated by using the test scenario of Fig. 1 and the audio files described in T able 1. Compared w ith them, our 21 algorithm not only can effectively resist Gaussian noise corruption and MP 3 compression, but also achieves higher robustness perform ance against th e DA/AD conversions. It shows that the pr oposed watermar king method is exactly pertinent to th e distortion caused by the DA /AD conversion: i. The temporal scaling in D A/AD conversions is mi nor and can be represente d as an interpolation processing operation. The m inor scaling will shift the sample position not so m uch, that means the synchronization code can ef fectively to locate the position of watermark em bedding. Due to the scaling is an interpolation processing, making th e interpolat ion-based resy nchronization can descale its effect. ii. The embeddin g strategy based on the relative relation is imm une to the energy change in the DA/AD conversion; iii. The corruption due to additive no ise in the DA/AD pr ocessing can be com bated by em bedding the watermar k in the low-frequency su b-band of DWT domain. Consequently , the watermark r obust to the DA/AD con versions is achieved. In order to further evaluate the performa nce of our pr oposed algorithm, we repor t the experim ental results regarding comm on audio signal processing, and S tirmar k Benchmark for Au dio with the diff erent kinds of au dio f iles described in Section 2. The test results are similar for dif ferent c lips. Here, w e take the mono signed audio file march.wav with sampling rate of 44.1 kH z as a example to pr esent the perfor mance of proposed watermarking str ategy , as tabulated in T ables 7-8. The audio editing and attacking tools adopted in experiment are CoolEdit Pro v2.1, Goldwave v5.10 and Stirm ark for Audio v0.2. T able 8 is the experimental results with “S tirmar k for Audio” v0.2, indicating that the waterm ark is robust to most attacks. However , it is noted that our proposed algorithm is sensitive to others kinds of Stir mark attack s, such as V oiceRem ove, AddFF TNoise, FFT _HLPass, RC_HighP ass, Copy Sample, FFT_T e st and FFT_stat1 attack. There are mainly the f ollowing reasons. i. Firstly , the watermark is removed by destroyi ng the content of the waterm arked audio. For instance, after V oiceRemove, AddFFTN oise processi ng, listening testing show s that the content of the audio is almost ruined completely . ii. Secondly , the waterm ark is removed by deleting th e low-frequency band of the cover -signal as the result of the attack FFT_HLPass or RC_HighPass. In this paper , since the watermark is embedded into the low-frequency sub-band of the DWT co efficients, the hidden inform ation is removed completely as long as the low-frequency com pon ent of watermarked signals is removed. 22 iii. Thirdly , the watermark is rem oved because th e energy relationships among sam ple points are modified. Since the waterm ark is embedded with the relative relationship strategy , as a result of the FFT_T est and FFT_stat1 attack, the energy r elationships among dif feren t groups of the DWT coefficients are modified due to swapping samp les in FFT domain, resulting in the watermark extraction failed. iv. The proposed algorithm is also robust to random rem oval even cutting one every 10 sam ples, but sensitive to the CopySamp le attack, which also changed the ener gy relationship am ong samples. When the BER is 20+%, we think that the watermar k extraction is failed. Robustness, imperceptibility and capacity of a waterm ark affect e ach other . In proposed watermarking algorithm, the robustness relies on the level of DWT decomposition. Their relation is the stronger robustness, the lower d ata embedding capacity and the severer the distortion due to the w atermark. Ta b l e 3 . Quality Evaluation of the W aterm arked Audio Using EQ UAL Audio Files march.wav drum.wav flute .wav d ialog.wav Band width Ref 20704.7882 101 11.9922 17751.6744 10667.8519 BandwidthT est 20704.7882 101 11.9922 17751.61 18 10667.8402 T otal NMR -16.2629 15.9422 -22 .5610 4.2279 WinModDif f1 4.8290 1 16.0379 3.7197 35.2723 ADB 0.7421 2.4325 0. 6324 2.1 682 EHS 0.1 150 1.2770 0.1443 0.7 374 A vgModDiff1 4.2554 1 17.3014 3.1457 13.91 12 A vgModDiff2 12.4491 1489.2157 6.9712 33.7151 RmsNoiseLoud 0.1 106 2.0097 0.2760 1.6 434 MFPD 1.0000 1.0000 1.0000 1.0 000 RDF 0.1086 0.8893 0.0124 0.5 498 DIX 2.24 -4.09 2.69 -2.95 ODG -0.19 -3.91 -0.05 -3.77 Ta b l e 4. The bits error of th e waterm arks in audios in the DA/AD conver sions Audio Files march.wav d rum.wav flute.wav dialog.wav A verage No Synchronizat ion Code Error Bits 137/800 174/ 800 191/800 34/ 800 134/800 BER ( % ) 17.12 21.75 23.88 4.25 16.75 No Resynchroniza tion Error Bit s 0 4/800 7/800 2/800 3.25/800 Movs 23 BER ( % ) 0 0.5 0.875 0.25 0.4375 Our algorithm Error Bits 0 0 2/800 0 0.5/800 BER ( % ) 0 0 0.25 0 0.0625 Here, 3.25 is the a verage value of er ror bits rela ted to dif ferent test clips, (0+4+7+2)/4=3.25. Ta b l e 5. The relationships among T , P 1 and P 2 T T = 5 T = 6 T = 7 T = 8 No Resynchronization P 1 9.61 × 10 -5 4.39 × 10 -4 5.3 0 × 10 -3 1.70 × 10 -3 P 2 4.70 × 10 -9 7.36 × 10 -11 1.09 × 10 -14 9.68 × 10 -13 Our algorithm P 1 9.61 × 10 -5 4.39 × 10 -4 5.3 0 × 10 -3 1.70 × 10 -3 P 2 4.33 × 10 -14 9.67 × 10 -17 2.90 × 10 -22 1.81 × 10 -19 Ta b l e 6. Robustness Performance to Common Attacks Attack T ype BER (%) Attack T ype BER (%) Unattacked 0 Gaussain (8 dB) 0 MP3 (32 kbps) 0 MP3 (128 kbps) 0 Requantization (8 bit) 0 Resample (8 kHz) 0 LPF (LowPassF req = 9000 Hz) 0 Amplitu de scaling (10%~150%) 0 Ta b l e 7. The perform ance of dif ferent algorithm s Algor ithm Data embedding capacity (bps) Gaussian noise BER ( % ) MP3 Compression BER ( % ) Resisting the DA/AD conversions BER ( % ) Ref. [8] About 172 0 (8 dB) 0 (32 kbps) Failed to extracting Ref.[10] About 49 Not mentione d About 2.92 (80 kbps) About 2 Ref. [17] About 8.53 2.73 (36 dB) About 2.99 (64 kbps) About 1.3 Ref. [18] About 25 Not ment ioned About 1.42 (64 kbps) About 3.57 Our A bout 28.71 0 (8 dB) 0 (32 kbps) About 0.0625 Ta b l e 8 . Robustness Perform ance to Other kinds of Attacks in Stirm ark for Audio v0.2 Attack T ype BER (%) Parameters AddBrumm _100 0 AddBrumm Freq = 55, AddBrumm from = 100 AddBrumm to = 10100, AddBrumm step = 1000 AddBrumm _1 100 15.79 AddNoise_100 0 Noisefrom = 100 Noiseto = 1000 Noisestep = 200 AddNoise _500 0.5 AddNoise _900 5.875 24 Compressor 0 ThresholdDB = -6.123, Com pressV alue = 2.1 AddSinus 0 AddSinusFr eq = 900, AddSinusAm p = 1300 AddDynNoise 0 Dynnoise = 20 Amplify 0 Amplify = 50 Exchange 0 ExtraS tereo_30 0 ExtraS tereofrom = 30 ExtraS tereoto = 70 ExtraS tereostep = 20 ExtraS tereo _50 0 ExtraS tereo _70 0 Normalize 0 ZeroLength 0 ZeroLength = 10 ZeroCross 0 Zero Cross = 1000 Invert 0 Nothing 0 Original 0 Stat1 0 Stat1 0 RC _LowPass 0 LowPassFr eq = 9000 Smooth2 0 Smooth 0 FFT_Inver t 0 FFTSIZE = 16384 FFT_RealRevers e 0 FFTSIZE = 16384 ZeroRemove 0 Echo 0 Period = 10 Echo 13.04 Period = 50 FlippSam ple 0 Period = 10, FlippDist = 6, FlippCount = 2 FlippSam ple 19.5 Period = 1000, FlippDist = 600, FlippCount= 200 CutSample 0 Remove = 10, RemoveNum ber = 1 CopySam ple 19.97 Period = 10, FlippDist = 6, FlippCount = 1 FFT_T est Failed FFTSIZE = 16384 AddFFTNoise Failed FFTSIZE = 16384, FFT Noise = 30000 FFT _HLPass Failed FFTSIZE = 16384, HighP assFreq =200,LowPassF req = 9000 FFT _S tat1 Failed RC_HighPass Failed High PassFreq = 200 V oiceRemove Failed 25 7. Conclusi ons W e are proposing in this paper an audio watermark ing scheme aim ing at solving the DA/A D conversions without the consideration of anal og ch annels. The ma in content is sim ply concluded as follows: i. Based on many experiments, we analyze the ef f ects of the DA/AD conversions on the audio, and conclude the main degr adations on the au dio watermark are linear tem poral scaling and wave magnitude distor tion. The amount of the linear te mporal scaling r elies on the tested soundcards and sampling rate of the tested audio. Com par ed with TSM algorithms, the tem poral scaling caused by the DA /AD conversions is linear and us ually m inor . And, the linear temporal scaling caused by the DA/AD conve rsions may be consider ed as a resample interpolation processing manipulation verifi ed by experiments. T he wa ve m agnitude distortion ma y be modeled as amplitude scaling f ollowed by the additional noise corruption. ii. By analyzing the distortion caused b y the DA/AD conversions, we propose a pertinent watermarking strategy . T o resist wave magnitude distortion, we adopt the embedding strategy of the relative energy r elationships among dif feren t groups of the DWT coef ficients in the low- frequency sub-band by adaptively controlling the embedding str ength. Furtherm ore, the interpolation-based resynchr onizati on via synchronization codes is designed to resist the linear temporal scaling. By exploiting the time-f reque ncy localization characte ristics of DWT , the computational cost for resynchronization is dr am atically saved, and the r obustness of the watermark is im proved by em beddi ng in the low-frequency sub-band. iii. By introducing the synchronization code, r esy nchronization strategy and DWT technique, w e present a DWT -based blind audio waterm ark algorithm robust to the DA/AD conversions by referring to the ef fect of the DA/AD on audio si gnals . W e also evaluate the performance of the proposed algorithm in ter ms of data embedding capacity , error prob ability of synchronization code and watermark extraction, and resisting am plitude m odification attack. Th e experimental results show the watermark is very robust against the DA/AD conversions, m ost of comm on audio processin g operations or the attack s In this paper , we focus on the investigation on th e DA /AD conversion. The ef fect of dif ferent analog transmission channels [21] with m ore DA/AD conversi on devices will be a consideration of future works. 26 Acknowledgments This work is suppor ted by NSFC (60325208, 6 04030 45), NSF of G uangdong (04205407), New Jersey Comm ission of Science and T echnology via New Jersey Center of W ireless Networking and Internet Security (NJWINS). Refer ences [1] M. Arnold, “Audio wat ermarking: fe atures, applica tions and algorit hms,” Pr oc. of IEEE Int. Conf. on Multimedia & Expo , New Y ork, USA, vol. 2, pp. 1013-1016, 2000. [2] M. D. Swanson, B. Zhu, A. H. T ewfik, “Current state of the art, c hallenges and future direct ions for audio watermarki ng,” Pr oc. of IEEE Int. Conf. on Multimedia Computing and Systems , vol. 1, pp.19-24, 1999. [3] S. Katzen beisser, F . A . P . Petitcolas, e d. Information Hiding T echniques for S teganography and Digital W atermarking . Artech House, Inc., 2000. [4] M. A. Gerzon, P . G . Graven, “A high-rate buried-da ta channel for audio CD,” Journal of the Audio Engineering Society , vol. 43, pp. 3-22, 1995. [5] D. Gruhl, A. Lu, W . Bender , “Echo hiding,” Pr oc. of the 1 st Information Hiding W orkshop . LNCS, vol. 1 174, Berlin: Germany Springer -V erlag, pp. 295–315, 1996. [6] W . Bender , D. Gruhl, N. Morimoto, “T echniques for data hiding,” IBM Systems Journal , vol. 35, pp. 313– 336, 1996. [7] Sang-Kwang Lee, Y o-Sung Ho, “Digi tal audio waterm arking in the cepstrum dom ain,” IEEE T rans. on Consumer Electr oni cs , vol. 46, pp. 744-750, 2000. [8] S. Q. W u, J. W . Huang, D. R. Huang, Y . Q. Shi, “Eff iciently self-synchronized audi o watermarki ng for assured audio data transmi ssion,” I EEE T rans. on Br oadcasting , vol. 51, no. 1, pp. 69-76, 2005. [9] J. W . Huang, Y . W ang, Y . Q. Shi, “ A blind audi o watermarki ng algorithm with self-sy nchronization,” Pr oc. of IEEE Int. Sym. on Circuits and Systems , vol. 3, pp. 627-630, 2002. [10] W .-N Lie, L.-C. Chang, “Robust and high-qualit y time -domain a udio waterma rking subject to 27 psychoacousti c masking,” Pr oc. of IEE E Int. Sym. on Cir cuits and Systems , vol. 2, pp. 45-48, 2002. [11] H. O. Kim, B. K. Lee, N. Y . Lee, “W avelet-based a udio watermarking t echniques: robustnes s and fast synchronizat ion”. http://a math.kaist.ac .kr/research/paper/ 01-1 1.pdf [12] C. I. Podilchuk and E. J. Delp, “Digital watermarking: algorithms and applicat ions,” IEEE Signal Pr ocessing Magazine , vol. 18, pp. 33-46, July 2001. [13] S. Chen, H. Leung, “Concurrent data transm ission on anal og telephone cha nnel by data hiding t echnique,” Pr oc. of IEEE Int. Sym. on Consumer Electronics , pp.295-298, 2004. [14] J. Haitsma, M. van der V een, T . Kalker , F . Bruekers, “A udio watermarki ng for monitoring and copy protection,” Pr oc. of ACM Multimedia W orkshops , pp. 1 19-122, 2000. [15] T . Nakamura, R. T achibana, and S. Kobaya shi, “Autom atic m usic monitoring and boundary detect ion for broadcast using audio w atermarking,” Pr oc. SPIE , vol. 4675, pp. 170-180, 2002. [16] R. T achibana, “Audio waterm arking for li ve performance,” Pr oc. SPIE , vol. 5020, pp. 32-43, 2003. [17] J. Seok, J. Hong, and J. Kim, “ A novel audio waterm arki ng algorithm for copyright protection of digit al audio,” ETRI Journal , vol. 24, no.3, pp. 181-189, 2002. [18] S. Shin, O. Kim , J. Kim , J. Choil, “A robust audio waterm arking algorithm using pitch scal ing,” Pr oc. of IEEE W orkshop on Digital Signal Proc essing , vol. 2, pp. 701–704, 2002. [19] M. Steinebach, A. Lang, J. Dittma nn, C. Neubauer , “Audio watermarking quali ty evaluation: robustness to DA/AD processes,” Pr oc. of I nt. Conf. on Information T echnology: Coding and Computing , pp. 100-103, 2002. [20] R. Popa, “An Analysis of S teganographic T echniques,” Ph. D T hesis , pp. 26-27, 1998. [21] S. J. Xiang, J. W . Huang. “Analysis of D/A and A/D conversions in quantizat ion-based audio watermarki ng,” International Journal of Network Security , V ol. 3, pp. 230-238, 2006. [22] Online: A v ailable at: [https://am sl-smb.cs .uni-magdebur g.de/smfa//all gemeines.php] . [23] Online: A vailable at: [http://www .mp3-tech.org/program mer/ sources/eaqual.tgz ] . [24] Online: A vailable at: [http://www .mp3-tech.org/programm er/mi sc.html]. [25] International T elecomm unication Union, “ Method for Objec tive Measurem ents of Perceived Audio Qual ity (PEAQ),” ITU- R BS 1387 , 1998. 28 [26] M. Arnold, “Subjective and objec tive quality evaluation of waterm arked audio tracks,” W eb Deliver ing of Music , pp. 161-167, 2002. [27] W . Li, X. Y . Xue and P . Z. Lu, “ Robust audio waterm arking based on rhythm region Detecti on,” IEE Electronics Let ters , vol. 41, no. 4, pp. 75-76, 2005. [28] M. Steinebach, F .A.P . Pet itcolas, F . Raynal, J. Dittm a nn, C. Font aine, S. Seibel, N. Fates, L.C. Ferri, “St irMark benchm ark: audio waterm arking attacks,” Pr oc. of Int. Conf. on Information T echnology: Cod ing and Computing , pp. 49-54, 2001. [29] B. Sylvain, V . D. V . Mi chiel and L. A weke, "Informe d detection of audio waterm ark for resolving Pl ayback speed modifi cations," Pr oc. the Multimedia and Security W orkshop , pp. 1 17-123, 2004. [30] L.H. Charles Lee, ed. Error -Control Block Code s fo r Comm unications Engineers. Artech House, Inc., 2000. APPENDIX I When the embedding bit is ‘1’ and A BS − < , we m odify the values of dif ferent groups of the DWT coefficients to satisfy S B A ≥ − according to Equation (8). Let A BS β = −− , so ma x max ma x mi n || '( 1 ) 2 med EE EE E β =× + ++ , mi n mi n ma x mi n || '( 1 ) 2 med EE EE E β =× + ++ , ma x mi n || '( 1 ) 2 med me d me d EE EE E β =× − ++ . Where max mi n ', ', ' med EEE is the correspond ing version of max min ,, med EEE . Obvio usly , after embedding bit ‘1’, max min ', ' EE increased while ' med E decreased on the basis of max min ,, med EEE . This m ay generate min '' med EE > . According Equations (5) , (6) and (7), w e have max min || 2 med SB A S E E E β = +−= + − − . In order to avoid the case after em bedding b it ‘1’, we hav e the following deduction. '' min min m a xm i n m a xm i n max min min m ax min max min min min max min || || (1 ) (1 ) 22 (2 | | ) (2 | | ) (2 2 ) (4 ) () ( 22 ) 2 med med med med med med med med med med med med me EE EE EE E EE E E E EE E E EE EE E S E E S SE E E E E E E S ββ β β ≥ ⇔× − ≥ × + ++ ++ ⇔× + + − ≥ × + + + ⇔× + − ≥ × + ⇔× + ≤ − ⇔≤ max min min () d med EE EE − + The proof of Equation (9) is finished. 29 APPENDIX II When the embedding bit is ‘0’ and B AS − < , we m odify the values of dif ferent groups of the DWT coefficients to satisfy BA S −≥ according to Equation (10). Let BA S β = −− , so ' ma x max ma x mi n || (1 ) 2 med EE EE E β =× − ++ , ' mi n mi n ma x mi n || (1 ) 2 med EE EE E β =× − ++ , ' ma x mi n || (1 ) 2 med me d med EE EE E β =× + ++ . Where max mi n ', ', ' med EEE is the correspondin g version of max min ,, med EEE . Obvio usly , after embedding bit ‘0’, max min ', ' EE decrease d while ' med E increased on the basis of max min ,, med EEE . This may lead to max '' med EE > . According Equ ations (5), (6) and (7), we have max mi n || 2 med SA B S E E E β = +−= + − + . In order to avoid the case occurring after em bedding bit ‘0’, we have th e following deductio n. '' ma x max m a xm i n m a xm i n max max mi n ma x min max max mi n max max ma x mi n || || (1 ) (1 ) 22 (2 | | ) (2 | | ) (4 ) (2 2 ) () ( 2 2 ) 2 med med med med med med med med med med med me EE EE EE E EE E EE E E EE E E EE S E E E S SE E E E E E E S ββ β β ≥ ⇔× − ≥ × + ++ ++ ⇔× + + − ≥ × + + + ⇔× − ≥ × + + ⇔× + ≤ − ⇔≤ max min max () d med EE EE − + The proof of Equation (1 1) is finished.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment