
Eess-As

STACodec: Semantic Token Assignment for Balancing Acoustic Fidelity and Semantic Information in Audio Codecs

B-GRPO: Unsupervised Speech Emotion Recognition based on Batched-Group Relative Policy Optimization
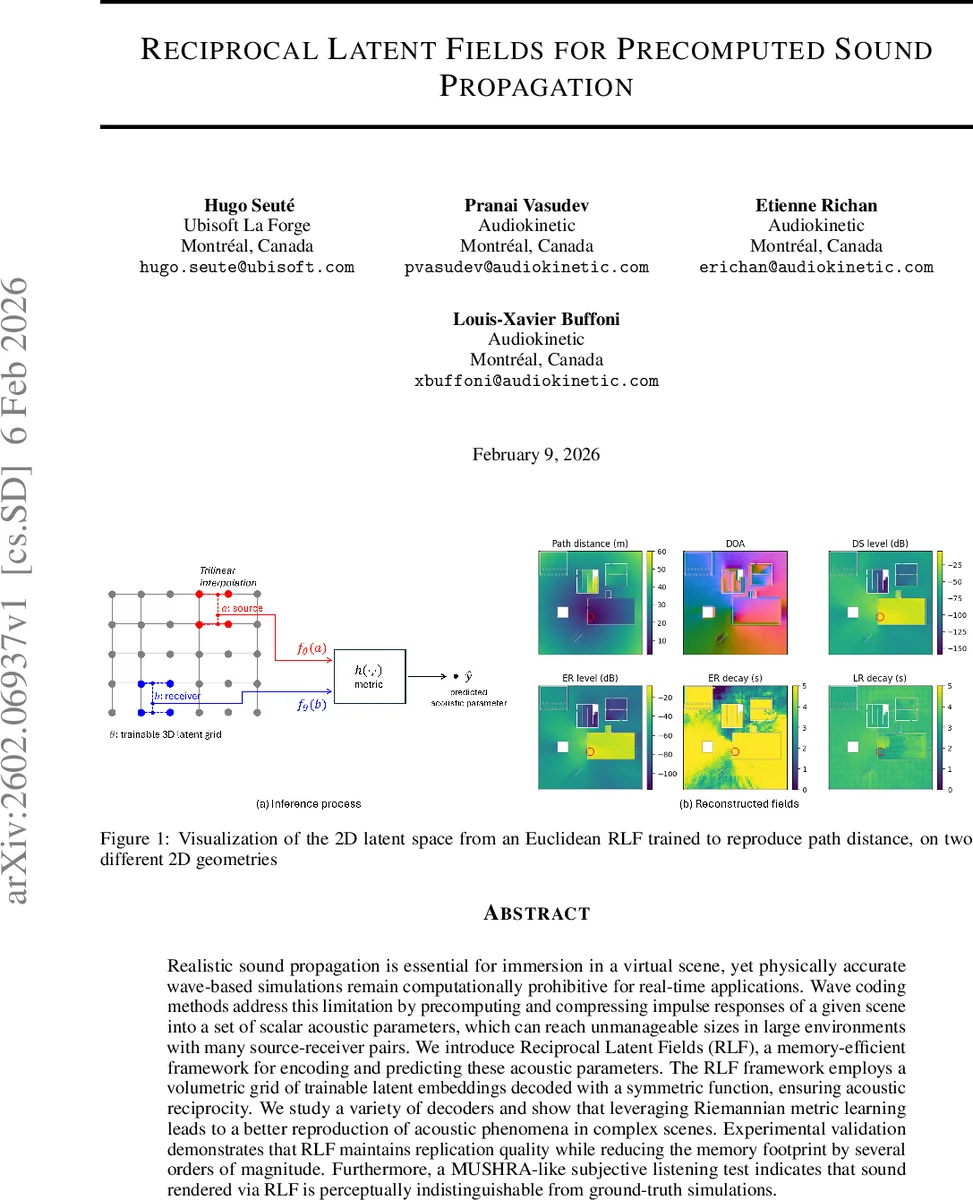
Reciprocal Latent Fields for Precomputed Sound Propagation

Automatic Detection and Analysis of Singing Mistakes for Music Pedagogy

Misophonia Trigger Sound Detection on Synthetic Soundscapes Using a Hybrid Model with a Frozen Pre-Trained CNN and a Time-Series Module
