Optimizing LSTM Neural Networks for Resource-Constrained Retail Sales Forecasting: A Model Compression Study
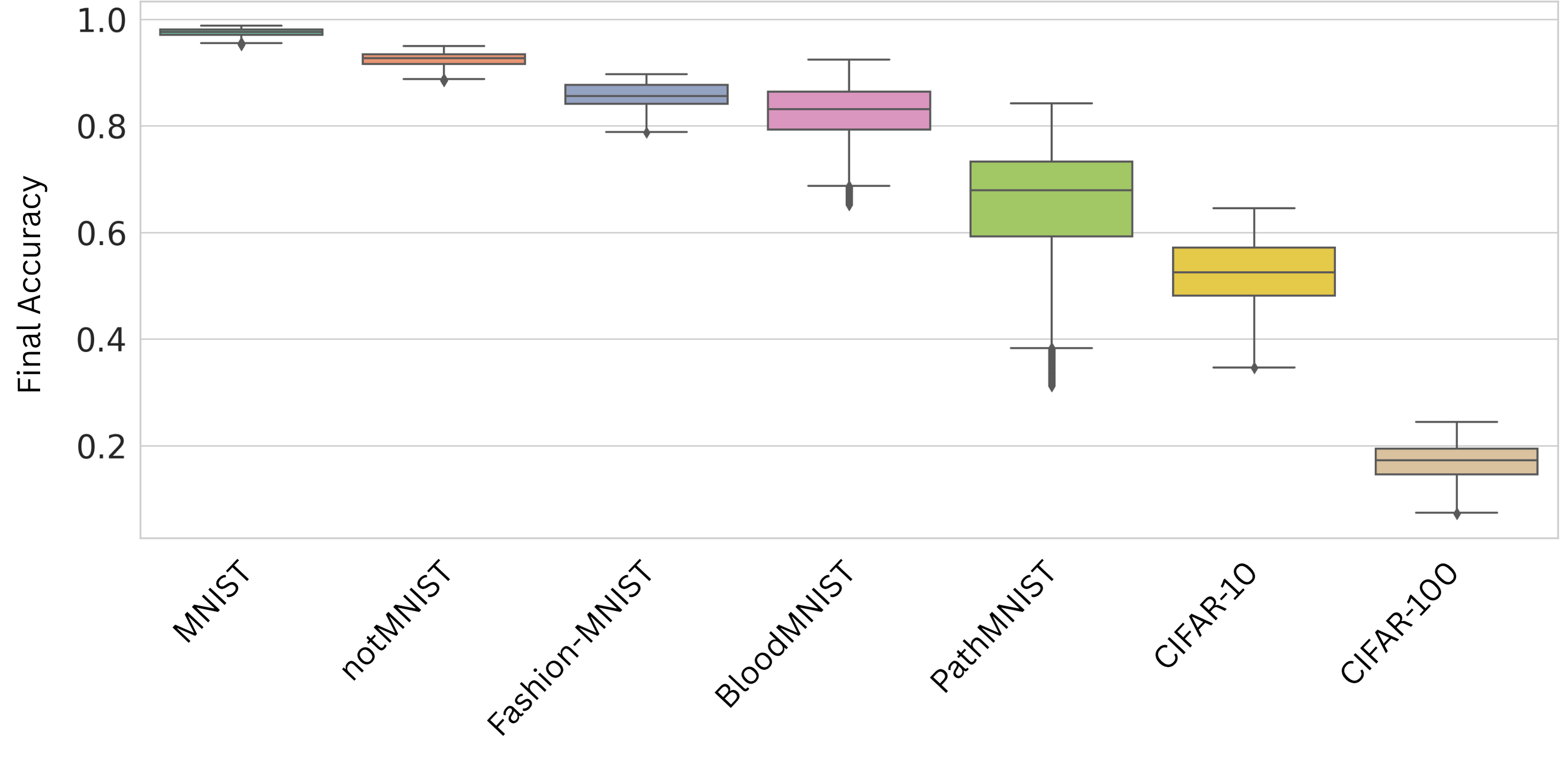
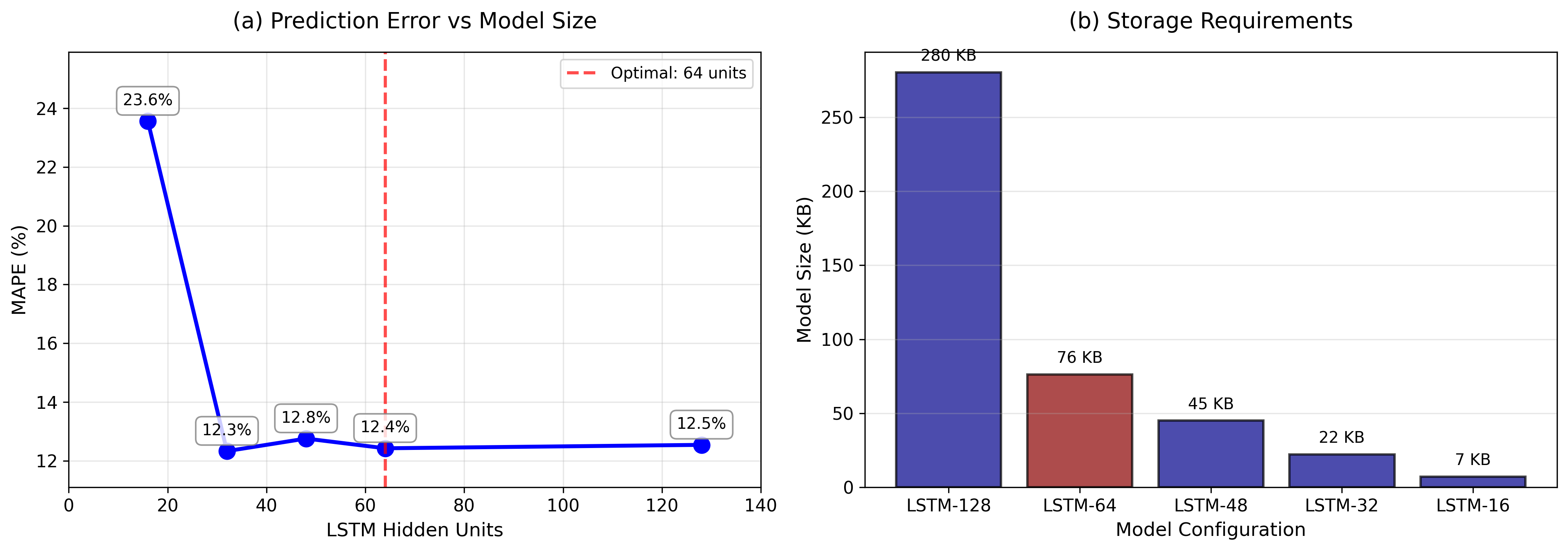
이 논문은 소매 판매 예측 분야에서 LSTM 네트워크의 효율성과 정확성을 극대화하는 방법에 대해 깊이 있게 탐구하고 있다. 특히, 이 연구는 자원 제약을 가진 소규모 및 중소 규모 매장에서도 효과적인 AI 기반 예측 시스템을 구축할 수 있도록 하는 모델 압축 기법의 중요성을 강조한다. 기술적 혁신성 이 논문은 LSTM 네트워크를 압축하는 다양한 방법론을 체계적으로 평가하고, 특히 64개 은닉 유닛을 가진 모델이 가장 높은 예측 정확도를 보이는 것을 발견했다. 이는 표준 LSTM(128개 은닉 유닛)보다 메모리 사용량을 줄이고 추론
Computer Science
Network
Machine Learning
Model