인도 언어 다양성을 포괄하는 멀티모달 데이터셋 VAANI
VAANI 프로젝트는 165개 구역에서 112개 언어·방언을 대상으로 이미지·음성·텍스트 삼중항 데이터를 수집·검증해 31,270시간 규모의 음성 및 2,067시간의 전사본을 공개한다. 자동·수동 품질 검증을 거쳐 289 K 이미지와 함께 제공되며, 지역·성별·다중언어 메타데이터가 포함돼 인도 전역의 언어 포용형 AI 연구에 활용될 수 있다.
저자: Sujith Pulikodan, Abhayjeet Singh, Agneedh Basu
본 논문은 인도 내 언어·문화 다양성을 포괄하는 멀티모달 데이터셋 ‘VAANI’를 소개한다. 인도는 1,369개의 모국어가 존재하고, 121개의 주요 언어가 5개 어족에 속한다는 점에서 세계에서 가장 언어적으로 복합적인 국가 중 하나이다. 이러한 배경에서 저자들은 기존 음성 데이터셋이 주로 주요 22개 공식 언어와 대도시 중심의 데이터를 다루어 저자원 언어·지역 변이를 충분히 반영하지 못한다는 한계를 지적한다.
VAANI는 2단계에 걸쳐 165개 구역(28개 주·3개 연방 직할구역)에서 데이터를 수집했으며, 총 24,009,427개의 음성 세그먼트와 289,838개의 이미지, 약 31,270시간의 음성, 2,067시간의 전사본을 확보했다. 각 구역당 약 200시간의 음성을 목표로 하여, 지역별·성별·다중언어 사용 현황을 메타데이터(주, 구역, 성별, 핀코드, 주장 언어, 구사 언어)와 함께 기록했다.
데이터 수집 방식은 ‘이미지 기반 프롬프트’이다. 사전에 수집된 다양한 주제의 이미지를 피험자에게 제시하고, 피험자는 자신이 가장 편안하게 사용하는 언어로 이미지를 자유롭게 설명한다. 이 과정은 자발적·자연스러운 발화를 유도함으로써, 읽기식 데이터가 갖는 인위적 억양·문법적 제한을 극복한다. 또한, 이미지 자체가 별도 수집 과정을 통해 확보되었으며, 이는 멀티모달 연구(음성‑이미지‑텍스트 연계)에도 활용 가능하도록 설계되었다.
품질 관리에서는 자동화된 음성 품질 검사(노이즈, 길이, 샘플링 레이트 등)와 수동 전사 검증을 다단계로 수행했다. 전사본은 전체 음성의 약 6.6%에 해당하는 2,067시간에 대해 인간 청취자가 직접 라벨링했으며, 라벨링 정확성을 높이기 위해 언어 주장과 실제 구사 언어를 모두 기록했다. 이러한 메타데이터는 코드스위칭, 언어 접촉 현상 분석에 유용하게 활용될 수 있다.
데이터셋에 포함된 112개 언어·방언 중 다수는 기존 대규모 공개 데이터가 없던 저자원 언어이다. 특히, Angika, Korthha, Malvani, Shekhawati, Duruwa, Jaipuri, Bearybashe, Kurumuli, Kudukh, Bajjika, Agariya, Halbi 등은 처음으로 대규모 디지털 기록이 이루어졌다. 북동부 지역만 해도 34개의 희귀 언어가 포함돼, 이들 언어는 스크립트가 없거나 제한적인 문서화 수준에 머물러 있었으나, VAANI를 통해 음성 데이터가 확보됨으로써 언어 보전 및 연구에 큰 기여를 할 것으로 기대된다.
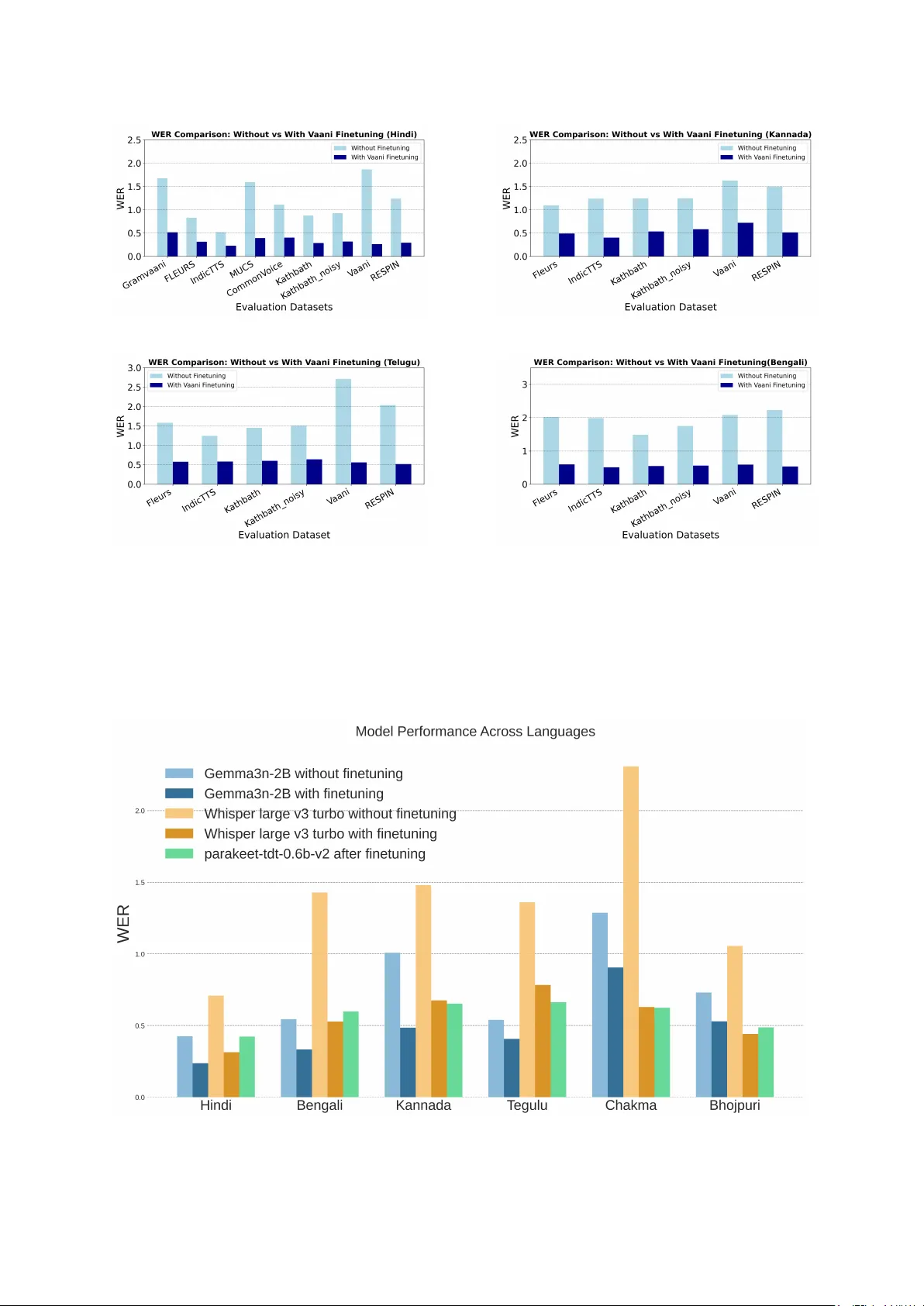
실험에서는 VAANI의 전사 데이터를 활용해 여러 최신 오픈소스 모델을 파인튜닝했다. Whisper‑small 모델을 힌디어(331시간), 칸나다(80.2시간), 텔루구(69.0시간), 벵골어(101시간) 각각에 파인튜닝한 결과, 기존 베이스라인 대비 일관된 성능 향상이 관찰되었다. 다국어 파인튜닝 실험에서는 Gemma‑3n‑2B, Whisper‑large‑v3‑turbo, Parakeet‑tdt‑0.6b‑v2를 사용해 힌디어, 칸나다, 텔루구, 벵골어 외에 저자원 언어인 Chakma(31.6시간)와 Bhojpuri(23.7시간)까지 포함한 멀티링구얼 설정으로 학습하였다. LoRA 기반 파라미터 효율 파인튜닝을 적용한 Gemma‑3n‑2B는 특히 저자원 언어에서 눈에 띄는 개선을 보였으며, 전체적으로 데이터의 다양성과 품질이 모델 일반화에 긍정적인 영향을 미침을 증명했다.
VAANI는 (1) 이미지‑음성‑텍스트 삼중항 멀티모달 구조, (2) 광범위한 지리·언어 커버리지, (3) 엄격한 다단계 품질 검증, (4) 풍부한 메타데이터 제공이라는 네 가지 핵심 특징을 갖는다. 데이터는 웹 포털 및 Hugging Face를 통해 공개되어, 연구자들이 주·구역 단위로 다운로드하거나 전체 데이터를 활용할 수 있다. 이는 인도 내 언어 포용형 AI 모델 개발뿐 아니라, 언어학, 문화인류학, 사회과학 등 다양한 분야에서 지역·언어 변이 분석, 언어 보전, 다언어 인터페이스 설계 등에 활용될 수 있다.
결론적으로 VAANI는 인도라는 초다양성 국가의 언어·문화적 특성을 반영한 최초 규모의 멀티모달 데이터셋으로, 기존 데이터셋이 갖는 언어·지리적 편향을 크게 해소한다. 향후 데이터 확대와 지속적인 품질 관리, 추가 언어·방언 포함을 통해 더욱 포괄적인 리소스로 성장할 가능성이 크며, 전 세계적인 다언어·다문화 AI 연구에 중요한 벤치마크가 될 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기