좁은 레지듀얼 네트워크의 보편 근사 제한과 터널 현상
본 논문은 폭이 제한된 ResNet(레지듀얼 신경망)의 보편 근사 능력을 이론적으로 분석하고, 입력 공간을 확대하지 않을 경우 발생하는 ‘터널 현상’—즉, 중요한 임계점이 무한대로 이동하면서 발생하는 분류 오류—을 규명한다. 스킵 채널과 잔차 채널의 비율(α)에 따라 두 극단(α≪1, α≫1)에서 각각 신경 ODE와 전통적인 피드포워드 네트워크와 유사한 제한이 나타나며, 이를 정량적 근사 경계식으로 제시한다. 저차원 실험을 통해 이론적 결과를 …
저자: Christian Kuehn, Sara-Viola Kuntz, Tobias Wöhrer
본 연구는 폭이 제한된 Residual Neural Network(ResNet)의 보편 근사 능력을 이론적·수치적으로 분석한다. 먼저, 입력‑출력 매핑에 임계점(critical point)이 존재하지 않을 경우, 해당 함수 집합은 보편 근사 속성을 가질 수 없다는 정리(정리 2.3)를 소개한다. 이는 임계점이 없는 함수가 특정 2차형 함수와의 sup‑norm 차이를 일정 이하로 만들 수 없다는 사실에 기반한다.
논문은 ResNet을 일반화하여 각 레이어를
\(h_\ell = \varepsilon h_{\ell-1} + \delta f_\ell(h_{\ell-1},\theta_\ell)\)
형태로 기술하고, 스킵 파라미터 ε와 잔차 파라미터 δ의 비율 \(\alpha = \delta/\varepsilon\)를 핵심 제어 변수로 설정한다. 여기서 \(f_\ell\)는 가중치 행렬 \(W_\ell\), 편향 \(b_\ell\), 시그모이드 활성화 σ를 포함하는 비선형 변환이다.
**1. α ≪ 1 (신경 ODE 근접) 경우**
ε를 1로 고정하고 δ를 매우 작게 하면, 레이어 업데이트는 작은 시간 간격 α = δ에 대한 Euler 전진이 된다. 저자는 Lipschitz 상수 \(K_f\)와 파라미터 집합 Θ의 상한을 이용해, α가 \(K_f\)에 비해 충분히 작으면 입력 그래디언트 \(\nabla_x h_\ell\)가 영이 되지 않으며, 따라서 모든 출력 성분이 임계점을 갖지 못한다는 것을 증명한다. 이는 연속 신경 ODE와 동일한 위상적 제한을 의미한다. 정리 3.2에서는 근사 오차가 \(\mathcal{O}(\alpha)\) 수준으로 하한을 갖는 구체적 식을 제시한다.
**2. α ≫ 1 (전통적인 피드포워드 네트워크 근접) 경우**
ε를 거의 0에 가깝게 두면 스킵 연결이 사라지고, 네트워크는 순수 MLP 형태가 된다. 기존 연구에서 알려진 바와 같이, 입력 공간을 확대하지 않은 MLP는 임계점을 포함하는 함수를 정확히 재현할 수 없으며, 저자는 최소 Lipschitz 상수 \(k_f\)와 Θ의 하한을 이용해 α가 \(k_f\)에 비해 충분히 클 때 동일한 제한이 발생함을 보인다(정리 4.3).
**3. α ≈ 1 (균형 잡힌 ResNet) 경우**
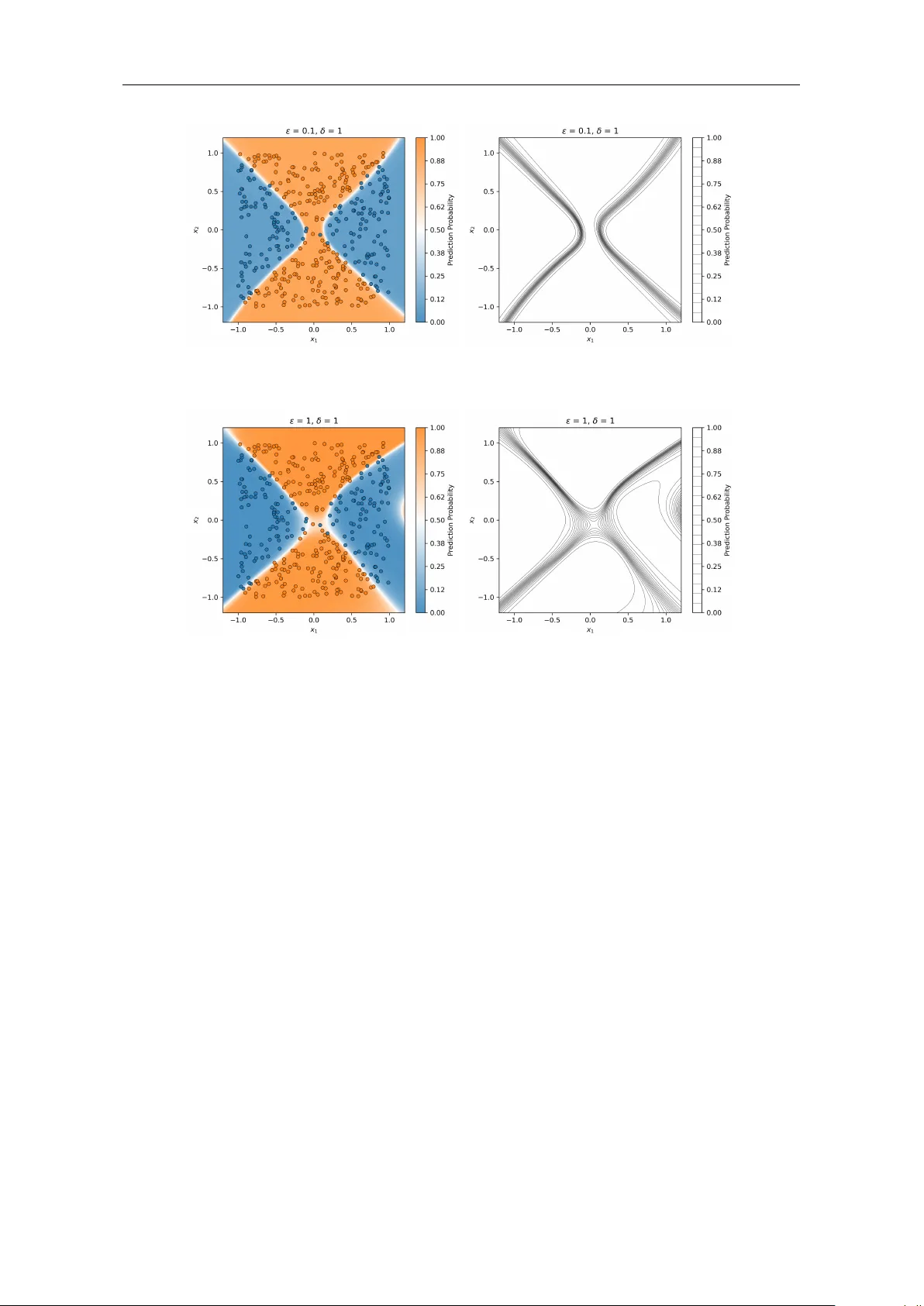
스킵과 잔차가 비슷한 규모일 때, 네트워크는 임계점을 정상적으로 삽입할 수 있다. 이는 실험에서 관찰된 바와 일치한다. 초기 가중치를 표준 정규분포에서 작은 스케일(α ≪ 1)이나 큰 스케일(α ≫ 1)로 설정하면 학습 후에도 “터널 현상”(임계점이 무한대로 이동해 레벨셋에 구멍이 생김)이 나타난다. 반면, 표준 스케일(α≈1)에서는 터널이 사라지고 정확한 분류가 가능하다.
**4. 수치 실험**
- 1‑D ResNet: 단일 레이어와 다중 레이어 구조에서 α를 변화시켜 입력‑출력 그래프를 시각화. α ≪ 1, ≫ 1에서는 출력이 단조함을 보이며, 목표 함수의 극값을 재현하지 못한다.
- 2‑D ResNet: 원형 데이터(클래스 A와 B)를 사용해 레벨셋을 플롯. α ≪ 1 또는 ≫ 1일 때 레벨셋에 “터널”이 형성돼 일부 샘플이 잘못 분류된다. α≈1에서는 매끄러운 경계가 형성된다.
**5. 이론적·실용적 함의**
- 채널 비율 α와 파라미터 범위 Θ는 ResNet의 위상적 표현력을 직접 결정한다.
- 입력 공간을 인위적으로 확대하지 않을 경우, α가 극단이면 임계점이 존재하지 않아 보편 근사 불가능 → 학습 시 “터널 현상” 발생.
- 설계 시 스킵과 잔차의 스케일을 균형 있게 맞추고, 가중치 초기화와 클리핑을 통해 Θ를 적절히 제한하면 임계점 삽입이 보장된다.
결론적으로, 본 논문은 “좁은” ResNet이 보편 근사를 달성하려면 스킵‑잔차 비율을 조절하고 파라미터를 적절히 제한해야 함을 수학적으로 증명하고, 이를 저차원 실험으로 직관적으로 보여준다. 이는 깊이와 폭이 제한된 현대 딥러닝 모델 설계에 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기