불완전 양자 데이터 학습을 위한 클래식 섀도우 기반 무감독 도메인 적응
본 논문은 양자 상태를 클래식 섀도우로 변환한 후, 라벨이 있는 소스 도메인과 라벨이 없는 타깃 도메인 사이의 분포 차이를 무감독 도메인 적응(UDA) 기법으로 극복하는 방법을 제안한다. 파울리 클래식 섀도우를 이용해 완전한 양자 상태 복원 없이도 다중 다운스트림 작업에 재사용 가능한 클래식 데이터셋을 만들고, CDAN 기반의 도메인 적대 학습을 통해 특징 추출기를 학습한다. 양자 상전이 분류와 얽힘 분류 두 벤치마크에서 기존 소스‑전용 및 타…
저자: Kosuke Ito, Akira Tanji, Hiroshi Yano
본 논문은 “불완전 양자 데이터”라는 현실적인 문제를 다루며, 라벨이 충분히 제공되지 않는 목표 영역에서 양자 상태를 이용한 머신러닝을 어떻게 수행할 수 있는지를 제시한다. 먼저, 양자 상태 ρ를 직접 다루는 대신 파울리 클래식 섀도우(클래식 그림자) 기법을 이용해 T번의 무작위 파울리 측정을 수행하고, 각 측정 결과를 역변환하여 클래식 스냅샷을 만든다. 이 스냅샷들의 집합 S_T(ρ) 은 순수히 클래식 데이터이며, 양자 메모리를 필요로 하지 않는다. 또한, 동일한 섀도우 데이터로 여러 물리량을 추정할 수 있어 데이터 재사용성이 뛰어나다.
그 다음, 저자는 두 종류의 데이터셋을 정의한다. (1) 라벨이 있는 소스 도메인 D_s = {(S_T(ρ_s^i), y_s^i)}_{i=1}^{N_s} 은 비교적 깨끗하고 라벨링이 쉬운 실험 혹은 시뮬레이션 환경에서 얻는다. (2) 라벨이 없는 타깃 도메인 D_t = {S_T(ρ_t^j)}_{j=1}^{N_t} 은 목표 시스템에서 얻으며, 여기에는 상태 준비 오류, 측정 노이즈, 하드웨어 잡음 등이 포함되어 분포가 크게 달라진다. 두 도메인은 마진 분포 Q_s^ρ ≠ Q_t^ρ 일 뿐 아니라, 같은 관측된 섀도우가 서로 다른 이상 상태 ρ_ideal 에서 유도될 수 있기 때문에 라벨-조건부 분포 Q_s(Y|ρ) ≠ Q_t(Y|ρ) 라는 개념 이동(concept shift)도 존재한다.
이러한 상황을 해결하기 위해 무감독 도메인 적응(UDA) 프레임워크를 도입한다. 저자는 CDAN(Conditional Domain Adversarial Network)을 기반으로 한 파이프라인을 설계한다. 구체적으로, 각 섀도우 레코드 z는 도메인별 어댑터 A_d^w 를 거쳐 고정된 형태 ˜z 로 변환되고, 이후 CNN 기반 특징 추출기 G_θ_f 로 매핑된다. 특징 h = G_θ_f(˜z) 는 두 가지 목적을 동시에 만족한다. (i) 라벨 예측기 C_θ_Y 를 통해 소스 라벨 손실 L_Y 를 최소화한다. (ii) 도메인 판별기 D_θ_dom 은 특징과 라벨 확률 분포의 크로네커 곱을 입력으로 받아 도메인 라벨 d∈{s,t} 를 예측하고, 손실 L_dom 를 최소화한다. 특징 추출기와 라벨 예측기는 GRL(Gradient Reversal Layer)을 통해 L_dom 를 최대화하도록 학습되어, 두 도메인의 라벨-조건부 특징 분포를 일치시키면서 라벨 구분 능력은 유지한다.
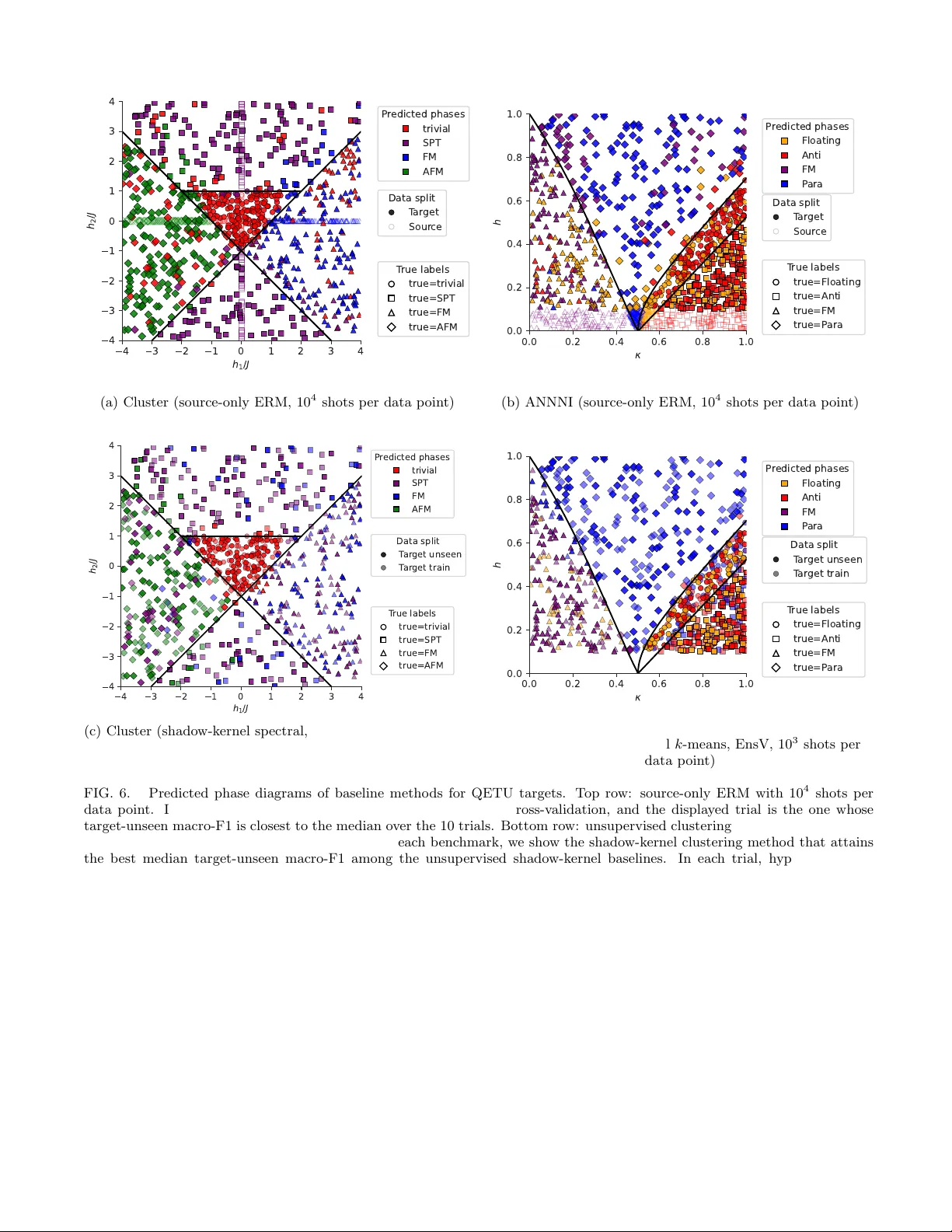
실험은 두 주요 벤치마크로 구성된다. 첫 번째는 양자 상전이 분류이다. 여기서는 1D 이징 모델과 2D 토폴로지컬 모델의 파라미터 공간을 두 구간으로 나누어 소스와 타깃을 정의하고, 타깃에서는 디포징 채널과 랜덤 측정 오류를 추가한다. 두 번째는 얽힘 분류이다. 여기서는 서로 다른 시스템 크기(N=6 vs N=8)와 서브시스템 파티션을 달리하여, 동일한 얽힘 라벨(예: 고양이 상태 vs 무작위 상태)이라도 관측된 섀도우가 크게 달라지는 상황을 만든다. 각 실험에서 (a) 소스‑전용 비적응 CNN, (b) 타깃‑전용 무감독 클러스터링(예: k‑means on raw shadows), (c) 제안된 UDA 모델을 비교한다. 결과는 UDA가 소스‑전용 모델 대비 정확도를 5~15% 향상시키며, 특히 타깃‑전용 무감독 방법이 거의 학습에 실패하는 경우에도 안정적인 성능을 보인다. 이는 도메인 적대 학습이 라벨-관련 구조를 보존하면서 잡음과 분포 이동을 효과적으로 억제함을 의미한다.
또한, 섀도우 기반 데이터는 측정 횟수 T와 시스템 규모 n에 따라 선형적인 메모리·시간 복잡도를 가지므로, 현재의 NISQ 디바이스에서도 실용적으로 적용 가능하다. 저자는 향후 (i) Clifford 섀도우와 같은 더 강력한 섀도우 기법, (ii) 다중 복제 섀도우를 이용한 고차원 특성 추출, (iii) 양자 회로 설계와 결합한 메타러닝 등으로 확장할 가능성을 제시한다. 최종적으로, 본 연구는 양자 데이터 학습이 실험적 제약과 잡음에 강인하도록 만드는 새로운 패러다임을 제시하며, 클래식 섀도우와 무감독 도메인 적응의 결합이 양자‑클래식 하이브리드 워크플로우에서 핵심적인 역할을 할 수 있음을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기