자동화된 조기 질병 예측: 구조화·비구조화 임상 데이터 통합
본 연구는 퇴원 요약문과 같은 비구조화 텍스트를 자연어 처리(NLP)로 추출해 구조화된 전자의무기록(EHR)과 결합함으로써, 코호트 선정, 데이터셋 생성, 라벨링을 전자동으로 수행하는 파이프라인을 제안한다. 심방세동(AF) 진행 예측 사례에서, 텍스트 기반 변수 추가가 모델 정확도와 임상 점수 대비 성능을 크게 향상시켰으며, 수작업 라벨링 비용을 크게 절감한다.
저자: Ane G Domingo-Aldama, Marcos Merino Prado, Alain García Olea
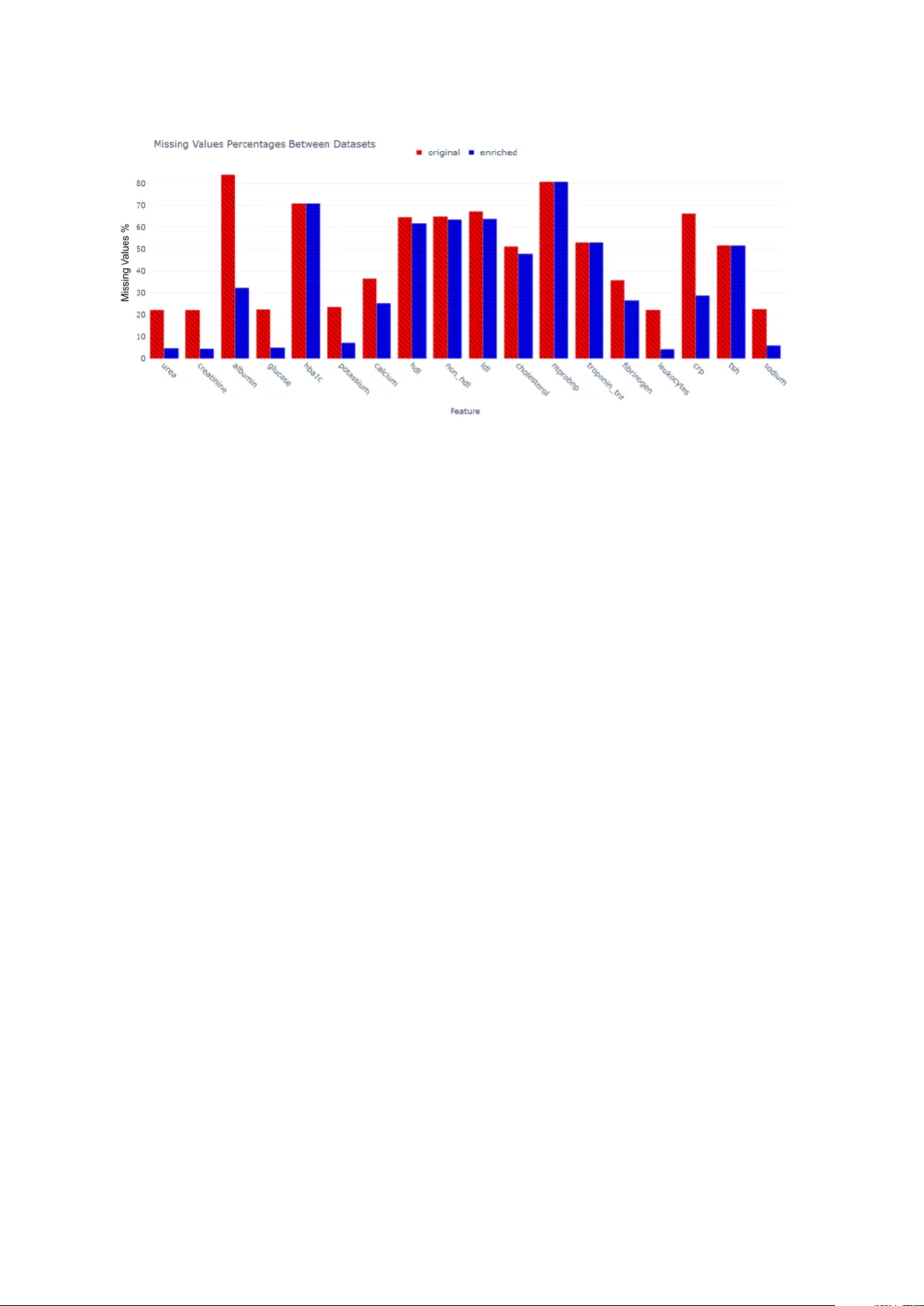
본 논문은 조기 질병 예측(early disease prediction) 연구에서 흔히 겪는 세 가지 핵심 과제—코호트 선정, 데이터셋 생성, 라벨링—를 전자동화하는 종합 파이프라인을 제안한다. 기존 연구들은 주로 구조화된 전자의무기록(EHR) 데이터에 의존했으며, 코딩 오류, 결측값, 정보 부족 등으로 인해 모델 성능이 제한되는 경우가 많았다. 이를 극복하기 위해 저자들은 퇴원 요약문과 같은 비구조화 임상 텍스트를 자연어 처리(NLP) 기술로 정형화하고, 구조화된 EHR 데이터와 결합하는 방식을 채택했다.
파이프라인은 크게 네 단계로 구성된다. 첫 번째 단계인 자동 코호트 선정에서는 구조화된 EHR 데이터를 이용해 초기 AF(심방세동) 발병 환자를 추출하고, 이후 두 단계의 NLP 검증(사전학습된 EriBERT 모델 기반 텍스트 분류와 정규표현식 기반 품질 검사)을 통해 퇴원 보고서에서 실제 AF 발병 여부를 재확인한다. 두 번째 단계인 데이터셋 생성·보강에서는 Report2Vector(R2V) 모듈이 퇴원 보고서에서 섹션 구분, 의료 엔티티 인식, 부정 탐지, 정규표현식 매칭을 차례로 수행해 84개의 임상 변수를 추출한다. 동시에 Structured2Vector(S2V) 모듈이 기존 BI 시스템(OBI)에서 동일한 84개 변수를 추출한다. 세 번째 단계인 VectorMerger는 두 데이터 소스를 환자 단위로 병합해 완전한 특성 벡터를 만든다.
네 번째 단계인 자동 라벨링에서는 R2V와 동일한 파이프라인을 적용해 각 환자의 퇴원 보고서에서 AF 진행 상황을 추적한다. 첫 번째 AF 에피소드(발병 시점)를 기준으로 1개월에서 2년 사이에 새로운 AF 에피소드가 기록되면 ‘AF 진행(1)’ 라벨을, 그렇지 않으면 ‘비진행(0)’ 라벨을 부여한다. 이렇게 생성된 라벨은 ‘Silver 라벨’이라 불리며, 소수의 전문의 검증을 거친 ‘Gold 라벨’과 비교했을 때 높은 일치도를 보였다.
실험에서는 TabPFN이라는 최신 테이블 기반 트랜스포머 모델을 사용해 예측 성능을 평가했다. 구조화 데이터만 사용한 베이스라인 모델은 AUROC 0.84, AUPRC 0.71을 기록했으며, 텍스트 보강 데이터를 추가한 모델은 AUROC 0.91, AUPRC 0.79로 크게 향상되었다. 또한, 기존 임상 점수(예: CHA₂DS₂‑VASc, HAS‑BLED)와 비교했을 때, 제안 모델은 정확도와 재현율 모두 10~12%p 이상 우수한 결과를 보였다.
연구 질문에 대한 답변은 다음과 같다. (RQ1) 구조화·비구조화 데이터를 결합함으로써 조기 예측 모델 개발을 자동화하고 성능을 향상시킬 수 있다. (RQ2) NLP 기반 텍스트 추출이 구조화 데이터의 결측·오류를 보완한다. (RQ3) 자동 생성된 Silver 라벨이 Gold 라벨과 거의 동등한 예측 신호를 제공한다. (RQ4) 최종 모델이 기존 임상 점수를 능가한다.
이 논문의 주요 기여는(1) 전자동 파이프라인 설계, (2) 비구조화 텍스트를 활용한 데이터 품질 보강, (3) 라벨링 비용 절감, (4) 실제 임상 시나리오(AF 진행)에서 기존 점수를 뛰어넘는 모델 성능 입증이다. 저자들은 이 방법론이 다른 질환 예측에도 일반화 가능하다고 주장하며, 향후 다기관, 다언어 데이터셋에 대한 확장 연구를 계획하고 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기