메타‑하니스: 모델 하니스 자동 최적화 시스템
본 논문은 대형 언어 모델(LLM)의 성능을 좌우하는 ‘하니스’(코드 기반 컨텍스트 관리)를 자동으로 설계·탐색하는 메타‑하니스 시스템을 제안한다. 파일시스템에 저장된 과거 하니스 코드·점수·실행 로그를 코딩 에이전트가 자유롭게 조회·수정하도록 함으로써, 기존 텍스트 최적화 기법보다 훨씬 풍부한 피드백을 활용한다. 온라인 텍스트 분류, 수학 추론, 에이전트 코딩 등 세 분야에서 인간이 만든 베이스라인을 크게 능가하는 결과를 보인다.
저자: Yoonho Lee, Roshen Nair, Qizheng Zhang
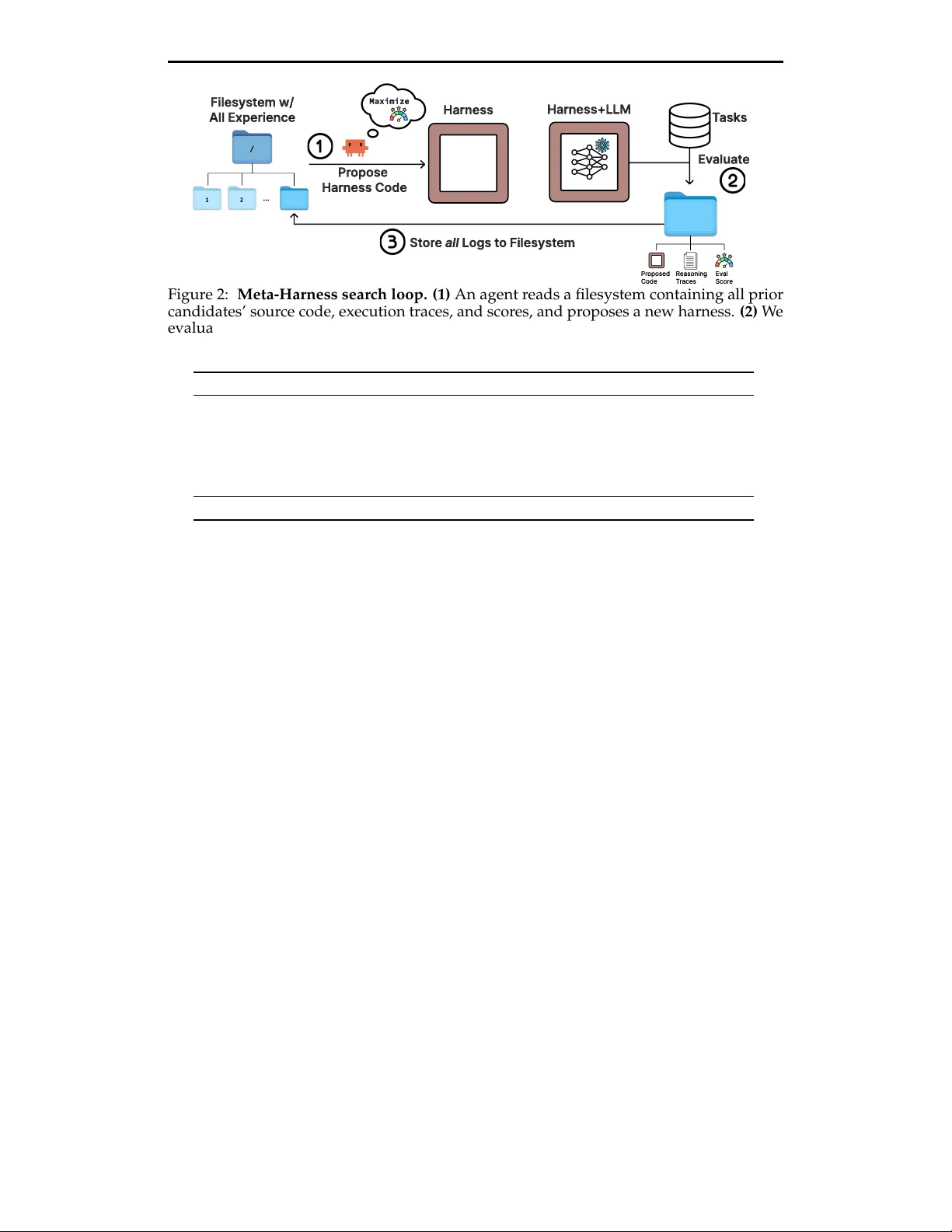
본 논문은 대형 언어 모델(LLM)의 실제 응용에서 성능을 좌우하는 “하니스”(model harness)라는 개념을 체계적으로 조명하고, 이를 자동으로 설계·탐색하는 Meta‑Harness 시스템을 제안한다. 하니스는 LLM 주위에 위치하는 파이썬 코드로, 어떤 정보를 저장하고 언제 검색하며, 어떻게 프롬프트에 삽입할지를 정의한다. 기존 연구에서는 하니스를 수작업으로 튜닝하거나, 짧은 스칼라 점수·요약된 피드백에 기반한 텍스트 최적화 기법을 적용했지만, 이러한 접근은 하니스가 갖는 장기적 인과관계를 충분히 포착하지 못한다.
Meta‑Harness는 두 가지 핵심 설계 원칙을 따른다. 첫째, 모든 후보 하니스의 소스 코드, 평가 점수, 실행 트레이스를 파일시스템에 로그로 남겨 “전역 히스토리”를 구축한다. 둘째, 코딩 에이전트(Claude Code Opus‑4.6)를 프로포저로 사용해, 파일시스템에 저장된 로그를 터미널 명령(`grep`, `cat` 등)으로 자유롭게 조회·분석하게 한다. 이 방식은 에이전트가 “어떤 파일을 열어볼지”, “어떤 실패 사례를 집중 분석할지”를 스스로 판단하도록 하여, 압축된 피드백이 놓치는 세부 원인과 해결책을 직접 탐색하게 만든다.
Meta‑Harness의 외부 루프는 다음과 같이 진행된다. (1) 초기 하니스 집합 H를 정의하고, 각 하니스를 평가해 파일시스템 D에 (코드, 점수, 트레이스) 쌍을 저장한다. (2) 지정된 반복 횟수 N 동안, 프로포저 P가 D를 탐색해 과거 로그를 검토하고, 새로운 하니스 후보 k개를 생성한다. (3) 각 후보를 인터페이스 검증 후 평가하고, 결과를 다시 D에 기록한다. 전체 과정에서 파레토 프론티어를 유지해 다중 목표(정확도, 컨텍스트 비용) 간 균형을 탐색한다.
실험은 세 가지 도메인에서 수행되었다.
1) 온라인 텍스트 분류: GPT‑OSS‑120B를 사용해 5개 데이터셋에 대해 순차적 라벨링·메모리 업데이트 환경을 구축했다. Meta‑Harness는 기존 ACE(Agentic Context Engineering)보다 7.7%p 정확도 향상을 달성했으며, 컨텍스트 토큰 사용량을 4배 절감했다. 또한, OpenEvolve 등 텍스트 최적화 기법이 60번의 제안을 필요로 하는 반면, Meta‑Harness는 4번만에 동일 수준에 도달했다.
2) 수학 추론: 200개의 IMO 수준 문제에 대해 Retrieval‑augmented 방식으로 5개 서로 다른 수학 모델을 테스트했다. 단일 발견된 하니스가 평균 4.7%p 정확도 상승을 보였으며, 이는 기존 하니스 설계보다 일관된 개선을 의미한다.
3) 에이전트 코딩(TerminalBench‑2): 코드 실행 환경에서 LLM이 터미널 명령을 수행하도록 하는 하니스를 최적화했다. Meta‑Harness가 만든 하니스는 Claude Haiku 4.5 기반 에이전트들을 모두 앞서며, 최고 성능을 기록했다.
비교 대상인 OpenEvolve, GEP‑A, TTT‑Discover 등은 한 번에 100~30 000 토큰 수준의 피드백만 활용했지만, Meta‑Harness는 한 평가당 최대 10 000 000 토큰에 달하는 실행 로그를 자유롭게 접근한다. 이는 검색 공간이 크게 확대되면서도, 코딩 모델이 “알고리즘적 일관성”을 유지하도록 자연스럽게 정규화되는 효과를 만든다.
논문의 한계로는 현재 파일시스템 기반 로그가 텍스트 중심이며, 대규모 바이너리 데이터나 비정형 로그에 대한 효율적 검색이 미흡할 수 있다는 점이다. 또한, 프로포저 모델의 능력에 크게 의존하므로, 코딩 에이전트가 더욱 강력해질 때 전체 시스템의 성능도 비례해 향상될 것으로 예상된다. 향후 연구 방향으로는 구조화된 데이터베이스 기반 로그 저장, 멀티‑에이전트 협업 탐색, 하니스 외에도 툴 호출 전략까지 포괄하는 통합 메타‑학습 프레임워크 구축 등이 제시된다.
결론적으로, Meta‑Harness는 풍부한 과거 경험을 파일시스템을 통해 직접 활용함으로써, 하니스 설계라는 복합적인 최적화 문제를 자동화하고, 기존 인간 설계 및 기존 텍스트 최적화 기법을 능가하는 성과를 입증했다. 이는 LLM 기반 시스템의 성능을 한 단계 끌어올리는 중요한 진전으로 평가될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기