상대 TD 학습의 안정성 및 민감도 분석
본 논문은 선형 함수 근사 하에서 상대 Temporal‑Difference (TD) 학습의 안정성을 이론적으로 규명하고, 베이스라인 분포 선택이 알고리즘 수렴에 미치는 영향을 분석한다. 특히 경험적 상태‑액션 분포를 베이스라인으로 사용할 때, 모든 할인 인자 γ∈
저자: Masoud S. Sakha, Rushikesh Kamalapurkar, Sean Meyn
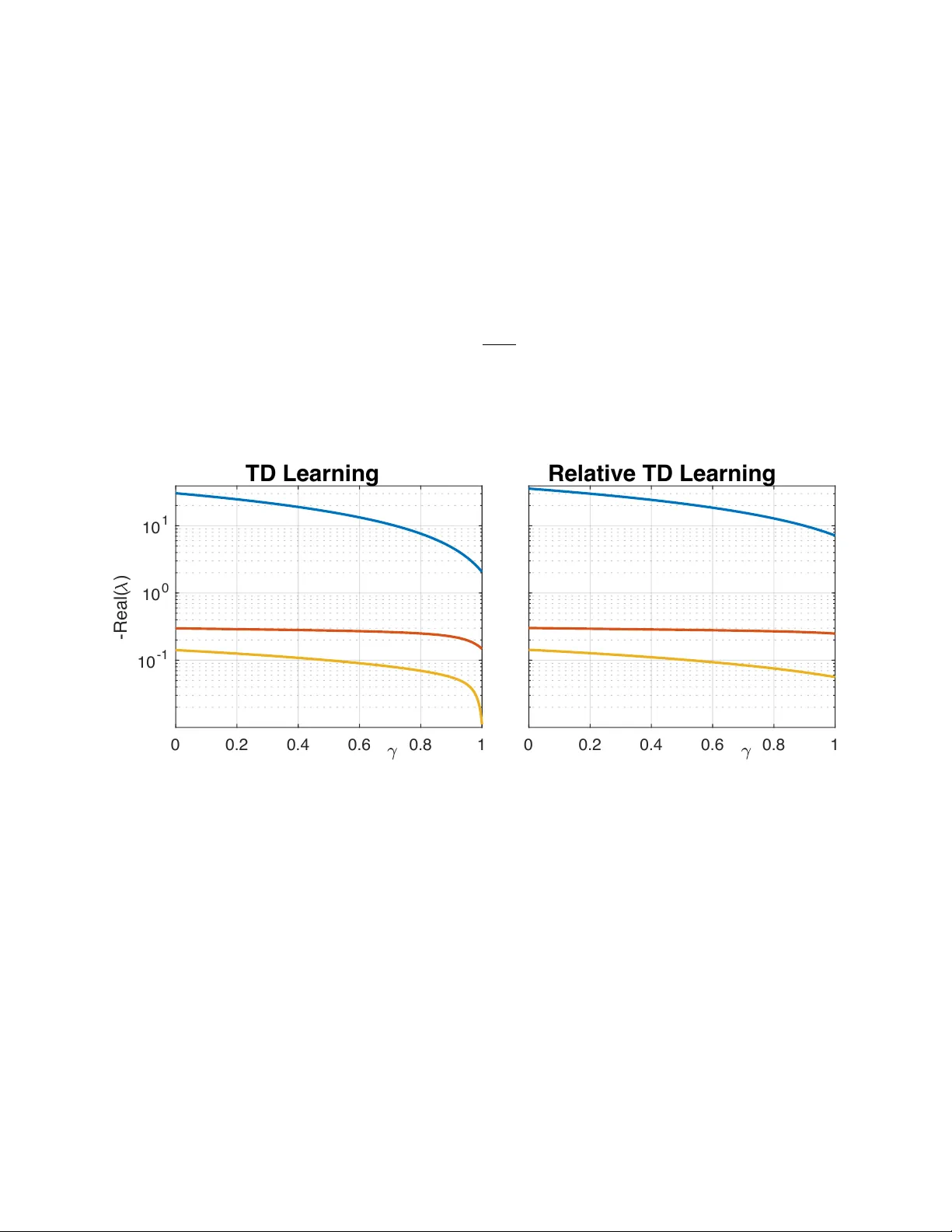
본 논문은 강화학습에서 널리 사용되는 Temporal‑Difference (TD) 학습이 할인 인자 γ가 1에 가까워질수록 수렴이 급격히 느려지는 문제를 해결하고자, “Relative TD”라는 변형을 선형 함수 근사와 결합한 이론적 분석을 제공한다.
1. **배경 및 문제 정의**
- MDP (X,U)와 정책 ϕ에 대해 Q‑함수 Q⋆는 Bellman 방정식 Q⋆(x,u)=c(x,u)+γE
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기