스무스 NPMLE를 이용한 경험적 베이즈 추정 및 최적 마진 커버리지
본 논문은 정상 평균 문제에서 기존 NPMLE가 갖는 이산성·느린 복원 속도 문제를 해결하고자, 혼합 분포를 Gaussian 위치 혼합으로 제한하는 계층적 스무딩 모델을 제안한다. 제안된 스무스 NPMLE는 볼록 최적화로 계산 가능하며, 다항식 수렴률을 보이며 최소극대(minimax) 최적성을 달성한다. 또한, 추정된 부드러운 사후분포를 이용해 최단 길이의 마진 커버리지 집합을 구성하고, 이 집합이 기대 길이 측면에서 최적임을 증명한다. 이론은…
저자: Taehyun Kim, Bodhisattva Sen
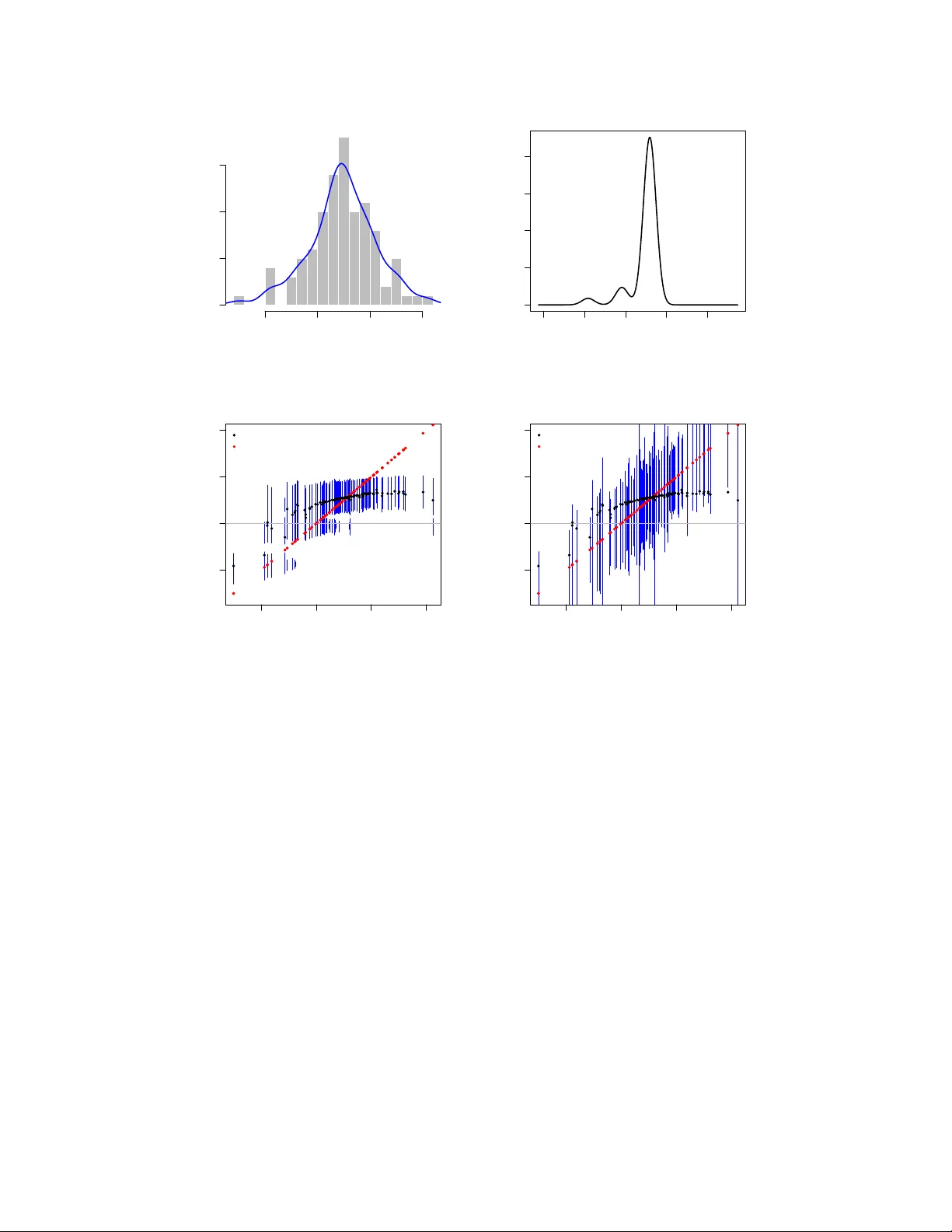
본 연구는 대규모 정상 평균 문제에서 경험적 베이즈(g‑modeling) 접근법이 직면한 두 가지 주요 한계, 즉 NPMLE가 반드시 이산적인 혼합분포를 반환함에 따라 사후 신뢰구간이 이산적 구조를 갖게 되고, 혼합분포 자체를 복원하는 deconvolution 속도가 로그 수준에 머무는 점을 해결하고자 한다. 이를 위해 저자들은 혼합분포 G* 를 Gaussian 위치 혼합 G = H ⋆ N(0,c²) 형태로 제한하는 계층적 정규‑정규 모델을 제안한다. 구체적으로 관측 X_i | θ_i ∼ N(θ_i,1), θ_i | ξ_i ∼ N(ξ_i,c²), ξ_i ∼ H 으로 구성된 3단계 계층을 도입한다. 여기서 c 는 스무딩 파라미터이며, H 은 아직 비모수적이지만, H에 대한 NPMLE를 정의함으로써 전체 모델을 완전히 비모수적으로 유지한다.
Ĥ는 다음과 같이 정의된다.
Ĥ ∈ arg max_{H∈𝒫(ℝ)} ∑_{i=1}^n log f_H(X_i)
여기서 f_H(x) = ∫ ϕ_{σ}(x−ξ) dH(ξ) 이며 σ² = 1 + c². 이 최적화는 무한 차원 볼록 문제이지만, 지원점 수를 n 으로 제한하면 유한 차원 선형 프로그램으로 근사 가능하고, 기존의 CVX 패키지로 효율적으로 해결된다. Ĥ는 최대 n 개의 지원점을 가지므로, Ĝ = Ĥ ⋆ N(0,c²) 는 유한 Gaussian 위치‑스케일 혼합으로 표현된다.
이러한 스무스 NPMLE는 기존 이산 NPMLE와 달리 다음과 같은 이론적 장점을 제공한다.
1. **Deconvolution 속도**: g_{Ĥ} (즉, Ĝ의 밀도)는 Sobolev 클래스에 대해 다항식 수렴률 O(n^{-α}) 을 달성한다(Thm 2.1). 이는 기존 로그 속도와 대비되는 결과이며, 최소극대(minimax) 하한과 일치한다(Thm 2.2).
2. **사후분포 수렴**: 추정된 사후밀도 π_{Ĥ}(·|x) 는 weighted total variation 거리에서 동일한 다항식 속도로 실제 사후 π_{H*}(·|x) 에 수렴한다(Thm 2.3).
3. **모델 오차에 대한 강건성**: 실제 마진밀도 f_{true} 가 제안된 모델 클래스 𝔽 에 포함되지 않을 경우, Ĥ는 KL 투영된 pseudo‑true 밀도 f_{Ĥ} 에 대해 거의 파라메트릭(로그 보정 포함) 수렴률을 보인다(Thm 2.4). 또한, pseudo‑true prior g_{Ĥ} 와 사후 π_{Ĥ} 도 다항식 속도로 수렴한다(Thm 2.5).
4. **최적 마진 커버리지 집합**: 마진 커버리지를 만족하는 집합 J_i 을 설계한다. 최적 집합은 고밀도 사후 집합(HPD)과 동일한 형태이며, 임계값 k* 를 고정해 (1‑β) 마진 커버리지를 보장한다(Thm 3.1). 플러그인 추정 Ĵ_i 은 기대 길이 측면에서 oracle I* 에 다항식 속도로 수렴하고, 실제 커버리지는 (1‑β) 수준에 근접한다(Thm 3.2, 3.3).
5. **이질적 잡음 확장**: 관측 X_i 가 서로 다른 분산 σ_i² 을 가질 경우에도, 동일한 스무스 NPMLE 프레임워크를 적용할 수 있다(섹션 4, 부록 D). 이 경우에도 prior g_{Ĥ} 와 사후 π_{Ĥ} 는 동일한 수렴 속도를 유지한다.
6. **식별 가능성 및 추정**: G* = H* ⋆ N(0,c*²) 에서 c*는 직접 식별되지 않는다. 대신, G*의 가장 큰 Gaussian 성분 c₀ (정의 (5.1))을 목표로 한다. 저자는 두 가지 추정 방법을 제안한다. 첫 번째는 Donoho의 아이디어를 차용한 이웃 기반 방법이며, 두 번째는 데이터 분할을 이용한 우도비 검정(분할 우도비, SLR)이다(섹션 5, 부록 F). 또한, c₀에 대한 유한표본 상한 신뢰구간을 제공한다.
7. **모델 적합도 검정**: H₀: H = δ_a (즉, 단일 Gaussian prior) 대 H₁: H ≠ δ_a 에 대한 검정을 제시한다. 검정은 분할 우도비 검정(SLR) 혹은 일반화 우도비 검정(GLRT)과 부트스트랩을 결합해 수행한다(섹션 6, 부록 G). 검정 결과에 따라 파라메트릭 경험적 베이즈(예: Morris)와 비파라메트릭 접근 중 선택할 수 있다.
8. **알고리즘 요약**: Algorithm 1은 전체 절차를 정리한다. (i) 데이터로부터 c₀를 추정, (ii) 스무스 NPMLE Ĥ 계산, (iii) 추정된 prior g_{Ĥ} 와 사후 π_{Ĥ} 구성, (iv) 최적 마진 커버리지 집합 Ĵ_i 생성, (v) 필요 시 모델 적합도 검정 수행.
실험에서는 두 가지 시뮬레이션 설정(두 개의 정규 혼합 prior와 Laplace prior)을 통해, 스무스 NPMLE가 실제 prior와 마진 밀도를 정확히 복원하고, 사후 밀도와 커버리지 집합이 이산 NPMLE에 비해 훨씬 부드럽고 정확함을 시각적으로 보여준다. 또한, c₀ 추정 정확도와 신뢰구간 커버리지를 검증한다.
결론적으로, 이 논문은 기존 NPMLE의 이산성·느린 복원 한계를 스무스 계층 모델과 볼록 최적화로 근본적으로 해결하고, 사후 추정과 마진 커버리지 양쪽에서 이론적 최적성을 동시에 달성한다. 이는 대규모 경험적 베이즈 분석에서 불확실성 정량화와 해석 가능성을 크게 향상시키는 중요한 진전이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기