스트리밍 시계열 테스트‑시 적응을 위한 레짐 기반 메타 제어
RG‑TTA는 스트리밍 시계열에서 발생하는 분포 변화에 대해 사전 학습된 모델이 동일한 적응 강도를 적용하는 문제를 해결한다. 5차원 분포 특징과 KS, Wasserstein‑1, 특징 거리, 변동 비율 네 가지 지표를 결합해 현재 배치와 기존 레짐 메모리 간 유사도를 계산하고, 이 유사도에 따라 학습률을 연속적으로 스케일링하며, 손실 기반 조기 종료와 손실‑게이트 체크포인트 재사용을 통해 배치별 최적의 적응 양을 자동으로 할당한다. 모델‑ag…
저자: Indar Kumar, Akanksha Tiwari, Sai Krishna Jasti
본 논문은 스트리밍 시계열 예측 환경에서 테스트‑시 적응(Test‑Time Adaptation, TTA)의 한계를 극복하기 위해 Regime‑Guided Test‑Time Adaptation(RG‑TTA)이라는 메타‑컨트롤러를 제안한다. 기존 TTA는 매 배치마다 고정된 학습률과 스텝 수를 적용해 새로운 데이터 분포에 적응한다. 그러나 실제 서비스에서는 동일한 레짐(분포)이 반복 등장하거나, 급격히 새로운 레짐이 나타나는 등 다양한 상황이 존재한다. 이러한 상황을 구분하지 않고 동일한 적응 강도를 적용하면, 이미 학습된 레짐에 대해서는 불필요한 연산이 소모되고, 새로운 레짐에 대해서는 적응이 부족할 수 있다.
RG‑TTA는 이러한 문제를 해결하기 위해 세 가지 핵심 구성요소를 도입한다.
1. **레짐 유사도 측정**
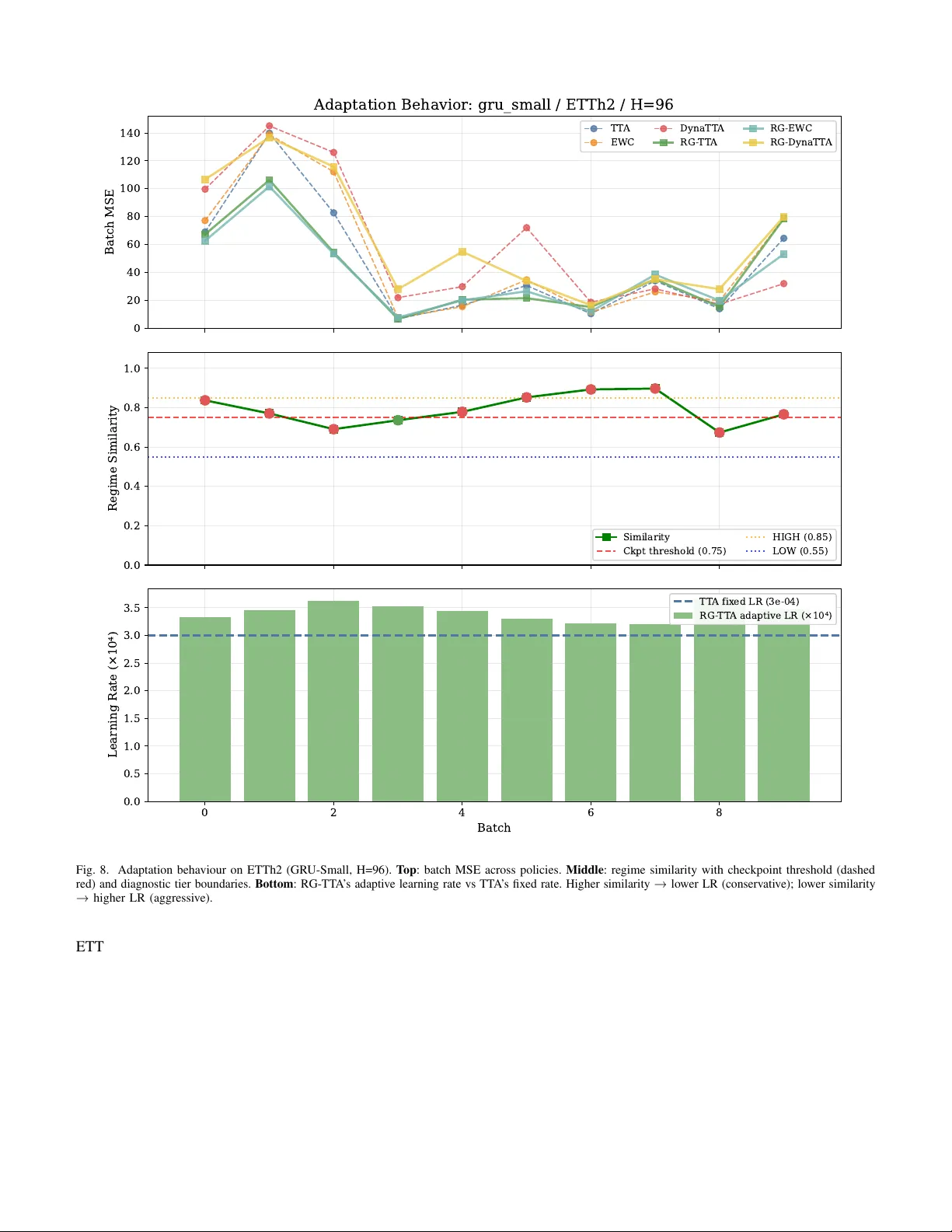
- 각 배치에 대해 최근 3·시즌 길이(예: 24시간)의 데이터를 이용해 5차원 분포 특징(평균, 표준편차, 왜도, 초과 첨도, 1‑lag 자기상관)을 추출한다.
- 추출된 특징과 저장된 레짐(체크포인트) 간 유사도는 네 가지 비모수적 지표(Kolmogorov‑Smirnov, Wasserstein‑1, 특징 거리, 변동 비율)를 가중 평균(0.3, 0.3, 0.2, 0.2)하여 0~1 사이의 점수로 변환한다.
- 이 유사도 점수는 현재 배치가 기존 레짐과 얼마나 비슷한지를 연속적인 신호로 제공한다.
2. **연속적인 적응 강도 조절**
- **학습률 스케일링**: α = α_base·(1 + γ·(1‑sim)) (γ=0.67) 로, 레짐이 완전히 새롭다면 학습률을 최대 1.67배까지 증가시키고, 기존 레짐이면 기본 학습률을 유지한다.
- **손실 기반 체크포인트 재사용**: 유사도 sim≥0.75인 레짐 중, 해당 체크포인트를 현재 배치에 적용했을 때 손실이 현재 모델보다 30% 이상 감소하면(ℓ_ckpt < 0.70·ℓ_curr) 모델을 교체한다. 이는 “전문가 모델”을 재활용해 불필요한 재학습을 방지한다.
- **손실‑드리븐 조기 종료**: 최대 25 스텝까지 gradient descent를 수행하되, 연속 3번의 상대 손실 감소율이 0.5% 미만이면 학습을 중단한다. 이를 통해 친숙한 레짐은 빠르게 수렴하고, 새로운 레짐은 전체 예산을 활용한다.
3. **모델‑agnostic 및 전략‑composable 설계**
- RG‑TTA는 train/predict/save/load 인터페이스만 있으면 어떤 forecaster에도 적용 가능하도록 설계되었다.
- 기존 TTA, Elastic Weight Consolidation(EWC), DynaTTA와 같은 gradient‑based 적응 방법에 레짐‑가이드 레이어를 “래핑”함으로써 RG‑EWC, RG‑DynaTTA와 같은 변형을 손쉽게 생성한다.
- RG‑EWC는 Fisher 정보 행렬을 온라인으로 업데이트하고, 레짐 전환 시 앵커 파라미터를 재설정해 catastrophic forgetting을 방지한다.
- RG‑DynaTTA는 레짐‑가이드 체크포인트 재사용과 손실‑드리븐 조기 종료를 유지하면서, DynaTTA의 동적 학습률 조절을 추가한다.
**실험 설정 및 결과**
- **데이터·모델**: 14개 데이터셋(6개 실제 멀티베리어트 + 8개 합성 레짐 시나리오), 4가지 경량 모델(GRU, iTransformer, PatchTST, DLinear), 4가지 horizon(96,192,336,720), 3개의 랜덤 시드 → 총 672개의 실험.
- **비교 정책**: 기본 TTA, EWC, DynaTTA + 각각의 레짐‑가이드 변형(RG‑TTA, RG‑EWC, RG‑DynaTTA).
- **주요 지표**: 평균 MSE, 연산 시간, 승률.
결과는 레짐‑가이드 정책이 69.6%(156/224) 경우에서 최저 MSE를 기록했으며, RG‑EWC가 30.4%, RG‑TTA가 29.0%의 승률을 차지했다. 평균적으로 RG‑TTA는 기존 TTA 대비 MSE를 5.7% 감소시키고, 실행 시간은 5.5% 단축했다. RG‑EWC는 standalone EWC 대비 MSE를 14.1% 감소시키고, 승률은 75.4%에 달했다. 전체 재학습(full retraining)과 비교했을 때 레짐‑가이드 정책은 평균 27% MSE 감소와 15‑30배 빠른 학습 속도를 달성했다.
**한계 및 향후 연구**
- 5차원 특징이 복잡한 비선형 레짐을 충분히 포착하지 못할 가능성.
- FIFO 기반 레짐 메모리 관리가 오래된 레짐을 조기에 삭제해 급격한 레짐 전환에 취약할 수 있음.
- DynaTTA와 통합 시 EMA 파라미터가 스트리밍 프로토콜과 맞지 않아 초기 학습률이 과소 평가되는 문제.
- 향후 고차원 임베딩 기반 특징, 적응형 메모리 정책, 멀티‑모달 시계열 확장 등을 연구할 필요가 있다.
**결론**
RG‑TTA는 “레짐 인식 → 적응 강도 조절 → 체크포인트 재활용”이라는 삼위일체 메커니즘을 통해 테스트‑시 적응의 효율성과 정확성을 동시에 개선한 혁신적인 프레임워크이다. 모델‑agnostic하고 기존 적응 전략과 자연스럽게 결합할 수 있어, 실시간 예측 시스템에 바로 적용 가능한 실용성을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기