AutoStan 베이지안 모델 자동 개선 프레임워크
AutoStan은 명령줄 인터페이스(CLI) 기반 코딩 에이전트를 활용해 Stan 코드의 베이지안 모델을 자동으로 작성·수정하고, 보유 데이터와 샘플러 진단 정보를 이용해 예측 성능(NLPD)과 추론 안정성을 동시에 최적화한다. 다섯 개의 서로 다른 데이터셋에서 인간 개입 없이 모델 구조를 점진적으로 개선해 해석 가능한 베이지안 모델을 얻으며, 최신 블랙박스 방법인 TabPFN과 경쟁하거나 이를 능가한다.
저자: Oliver Dürr
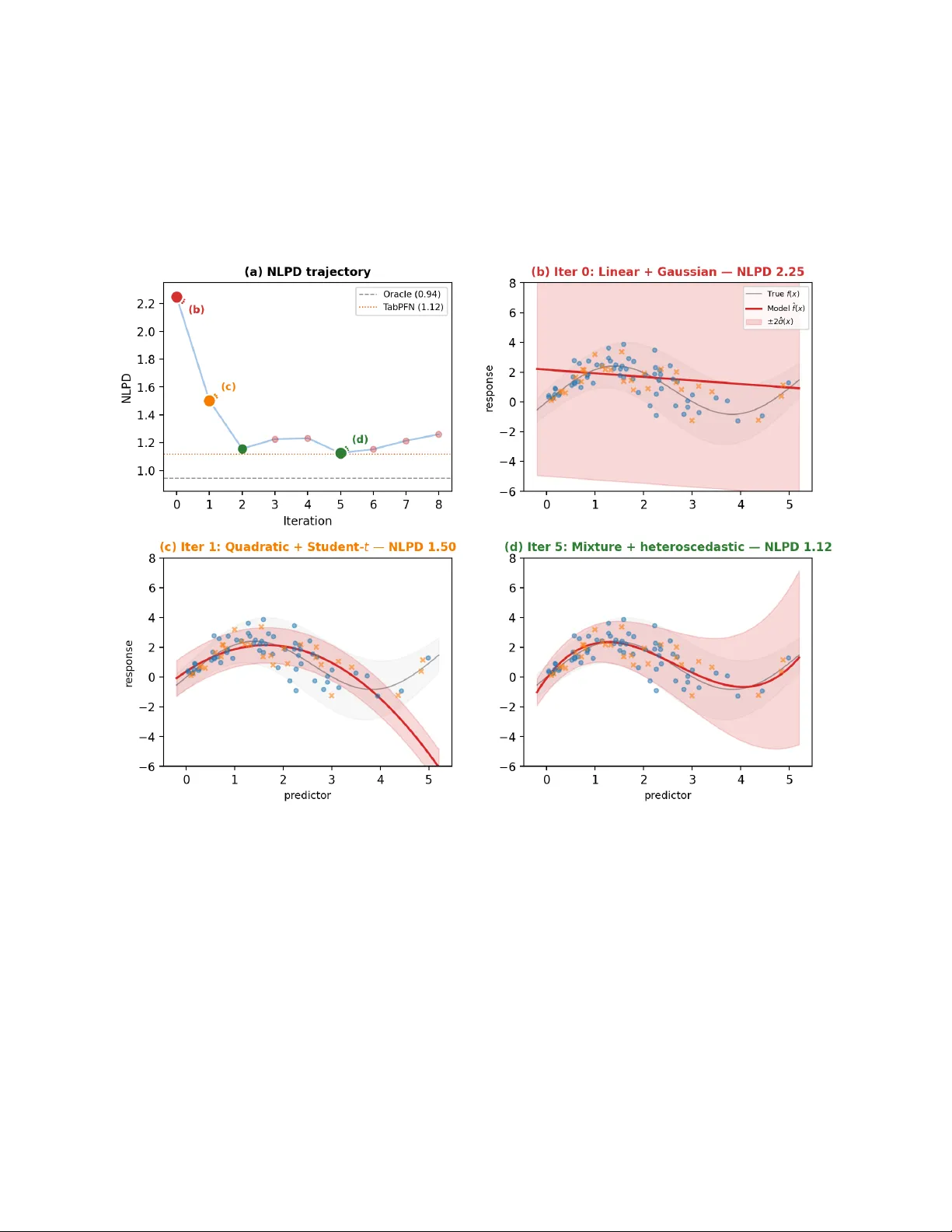
본 연구는 “AutoStan”이라는 새로운 프레임워크를 제안한다. AutoStan은 명령줄 인터페이스(CLI) 코딩 에이전트를 활용해 베이지안 모델을 자동으로 설계·수정하고, MCMC 기반 추론 결과와 보유되지 않은 테스트 데이터에 대한 부정 로그 예측 밀도(NLPD)를 동시에 최적화한다. 기존 베이지안 워크플로우는 모델 정의, 샘플링, 진단, 재설계라는 반복적인 과정을 인간 전문가가 직접 수행해야 했지만, AutoStan은 이 전체 사이클을 LLM 기반 에이전트에게 위임한다.
에이전트는 초기 프롬프트(‘program.md’와 ‘dataset.md’)만을 받고, 데이터 파일을 읽어 요약 통계와 시각화를 스스로 수행한다. 이후 Stan 모델 파일(model.stan)을 자유롭게 편집한다. 모델은 반드시 생성량량(‘generated quantities’) 블록에 로그 가능도 벡터를 출력하도록 해야 하며, 이는 평가 스크립트(evaluate.py)에서 NLPD를 계산하는 데 사용된다. MCMC는 cmdstanpy를 통해 4개의 체인, 1 000 개의 사후 샘플(대규모 회귀는 30 000)으로 실행된다.
AutoStan의 핵심 의사결정은 두 가지 피드백 신호에 기반한다. 첫 번째는 NLPD로, 이는 예측 분포가 실제 데이터와 얼마나 잘 맞는지를 정량화하는 strict proper scoring rule이다. 두 번째는 샘플러 자체 진단(다이버전스, R‑hat, ESS)으로, 모델이 수치적으로 안정적인지를 판단한다. 에이전트는 각 반복에서 “변경 유지” 혹은 “변경 되돌리기”를 선택하고, 연속 3번 비향상 혹은 총 20회 반복 시 학습을 종료한다.
실험은 다섯 개 데이터셋을 대상으로 수행되었다. 첫 번째는 아웃라이어와 이질분산을 포함한 1차원 회귀 데이터(대규모 n=500, 소규모 n=68)이다. 초기에는 선형·가우시안 모델(NLPD≈2.16)에서 시작해, 1차 변형으로 Student‑t와 3차 다항식(mean) 도입으로 NLPD가 0.84 감소한다. 이어 사인 기반 비선형(mean)과 로그형 이질분산을 차례로 추가하고, 마지막으로 외부 오염 혼합 모델을 도입해 최종 NLPD 1.23을 달성한다. 이는 최신 블랙박스 방법인 TabPFN(1.25)보다 우수하며, 모델 구조가 완전히 해석 가능하고 각 파라미터의 사후 불확실성을 제공한다.
두 번째와 세 번째 실험은 계층적 8‑School 모델(소규모 그룹 8, 대규모 그룹 20)이다. 에이전트는 즉시 부분 풀링 구조를 선택해 NLPD 1.50(소규모)·1.40(대규모) 수준을 기록한다. 이후 비중심화 파라미터화, 그룹별 분산, Student‑t 등 다양한 변형을 시도하고, 실제 성능 향상이 없는 경우 자동으로 되돌린다. 대규모 실험에서는 네 차례 연속 개선을 통해 최종 NLPD 1.4014를 얻으며, 오라클(1.4039)과 거의 동일한 수준에 도달한다.
네 번째 실험은 변동 기울기 모델이다. 15개의 그룹이 각각 다른 기울기를 갖는 구조에서 에이전트는 첫 번째 반복에 변동 기울기를 발견해 NLPD를 0.51 크게 감소시킨다. 이후 추가적인 복잡도(조각화, 노드 위치 학습)를 시도하지만, 다이버전스와 R‑hat 악화로 자동 거부한다. 최종 모델은 오라클(NLPD = 1.2627)과 근접한 1.2748을 기록한다.
마지막으로 실제 축구 경기 데이터(Bundesliga 2024/25)를 사용했다. 도메인 라벨이 제공된 경우와 제공되지 않은 경우 두 가지 설정을 실험했으며, 에이전트는 “공격‑방어” 포아송 모델을 즉시 구현한다. 이후 계층적 사전, 비중심화, 홈 어드밴티지 등을 단계적으로 추가해 NLPD를 0.020, 0.003씩 개선한다. 네거티브 바이노미얼, Dixon‑Coles 보정, Bradley‑Terry 품질 파라미터 등은 모두 실험적으로 검증 후 배제되었다.
관련 연구와 비교했을 때, AutoStan은 별도의 검색 알고리즘이나 비평 모듈 없이도 LLM 기반 에이전트 하나만으로 모델 설계·수정·평가 전체 과정을 수행한다는 점에서 차별화된다. 그러나 테스트 세트에 대한 반복적인 피드백이 과적합을 초래할 가능성, 복잡한 혼합 모델에서 라벨 스위칭 병목, 현재 Claude Sonnet에 종속된 구현 등 몇 가지 제한점이 있다. 향후 연구에서는 교차 검증 기반 보상 설계, 다양한 베이지안 언어와의 연동, 대규모 벤치마크를 통한 일반화 평가가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기