멀티칩렛 기반 MoE 추론을 위한 완전 샤딩 전문가 데이터 병렬화
본 논문은 고대역폭 다이‑투‑다이(D2D) 인터커넥트를 활용해, 저배치 환경에서의 Mixture‑of‑Experts(MoE) 추론에 최적화된 ‘Fully Sharded Expert Data Parallelism(FSE‑DP)’을 제안한다. 전문가 가중치를 칩렛 전체에 하나만 복제하고, 전문가 슬라이스를 동적 궤적으로 스트리밍함으로써 온칩 메모리 사용량을 최대 78.8% 절감하고, 기존 최첨단 대비 1.22‑2.00배의 속도 향상을 달성한다.
저자: Songchen Ma, Hongyi Li, Weihao Zhang
**1. 서론 및 배경**
최근 대형 언어 모델(LLM)의 에지 배포 수요가 급증하면서, 저배치 실시간 추론이 핵심 과제로 떠올랐다. MoE 구조는 전체 파라미터 중 일부 전문가만 활성화해 연산량을 크게 줄이면서도 모델 용량을 유지할 수 있어, 에지 AI에 적합한 설계로 주목받고 있다. 그러나 기존 GPU‑기반 클라우드 환경에서 설계된 EP·TP·DP 혼합 병렬화는 온칩 SRAM 용량이 제한된 칩렛 기반 에지 디바이스에 그대로 적용하기 어렵다. 특히, (1) 전문가 가중치가 칩렛마다 복제돼 메모리 낭비가 심하고, (2) 저배치 상황에서 토큰‑전문가 매핑이 불균형해 외부 DRAM 접근이 빈번해지며, (3) 롱테일 토큰 분포가 부하 불균형을 가중시킨다.
**2. 기존 연구와 한계**
클라우드‑스케일 MoE 최적화는 주로 all‑to‑all 토큰‑전문가 교환을 최소화하고, 전문가 균형을 위한 손실 함수나 탄력적 컨테이너를 활용한다. 반면, 에지 디바이스는 메모리·대역폭 제약이 크고 배치가 작아 이러한 기법이 효과적이지 않다. 최근 멀티칩렛 가속기 설계가 진행되고 있으나, 대부분은 전문가 배치를 고정하거나, CAM 기반 토큰 라우팅을 시도하는 수준에 머물러 있다.
**3. FSE‑DP 설계 원칙**
- **완전 샤딩(Full Sharding)**: 전문가 가중치를 칩렛 전체에 하나만 저장하고, 토큰 배치는 모든 칩렛이 공유하는 가상 버퍼 풀에 할당한다.
- **동적 전문가 궤적**: 각 전문가 슬라이스는 고대역폭 D2D 링크를 따라 ‘궤적’ 형태로 이동한다. 슬라이스는 현재 부하와 토큰 수에 따라 다음 칩렛으로 전달 경로가 실시간 재조정된다.
- **경량 스케줄링**: QoS‑pressure 기반 큐잉과 공간적 전문가‑궤적 계획을 결합한 알고리즘이 하드웨어 스케줄러에 구현된다. 스케줄러는 (i) 현재 D2D 대역폭 사용량, (ii) 각 칩렛의 연산 대기열 길이, (iii) 메모리 접근 압력을 입력으로 받아 전문가 흐름을 최적화한다.
- **가상화 규칙**: (1) 슬라이스 수신 → 로컬 토큰 배치 연산 → 즉시 전송, (2) 모든 메모리·통신 상태를 하드웨어가 자동 추적, (3) 각 칩렛은 독립적인 MIMD 제어 흐름을 유지한다. 이 규칙은 복잡한 소프트웨어 제어를 최소화하고, 하드웨어가 ‘자율적’으로 전문가 흐름을 관리하도록 만든다.
**4. 시스템 구현**
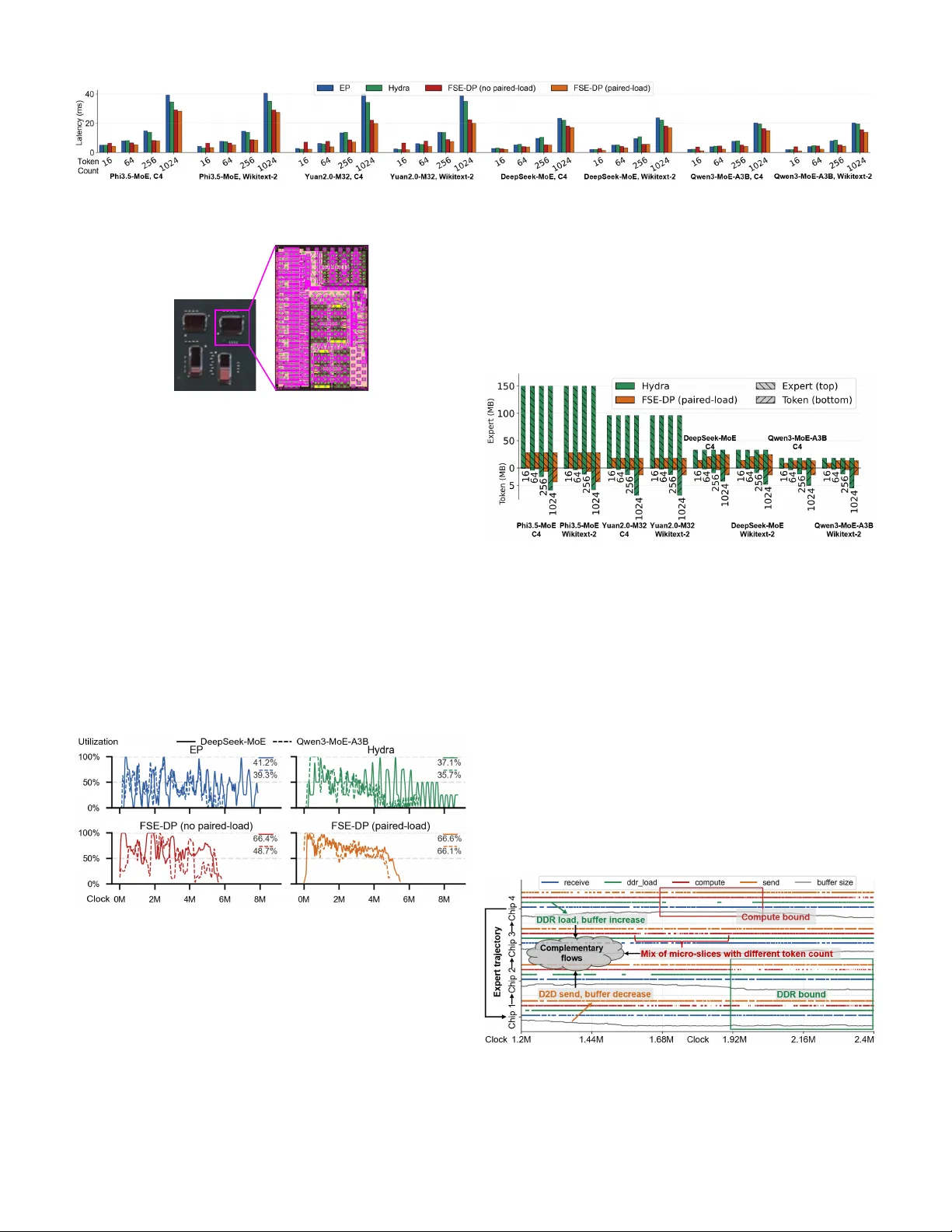
논문에서는 5nm 2×2 멀티칩렛 MCM을 제작하고, UCIe‑준수 고속 D2D 인터커넥트를 탑재하였다. 각 칩렛은 32KB SRAM과 8GB 외부 DRAM에 연결되며, D2D 대역폭은 100 GB/s, 지연은 20 ns 수준이다. 스케줄러는 RTL 수준에서 구현된 경량 모듈이며, 기존 메모리 컨트롤러와 통합돼 전문가 슬라이스 전송을 담당한다.
**5. 평가**
- **벤치마크**: DeepSeek‑MoE‑16B, Qwen‑3‑30B‑A3B, OL‑MoE 등 최신 MoE 모델을 사용해 저배치(16‑64 토큰)와 중배치(128‑256 토큰) 상황을 테스트하였다.
- **성능**: 전체 추론 지연이 1.22‑2.00배 감소했으며, 특히 배치가 16일 때 1.95배 가량 향상되었다.
- **메모리 효율**: 온칩 SRAM 사용량이 최대 78.8% 절감돼, 동일 메모리 용량에서 더 많은 전문가를 수용할 수 있었다.
- **부하 균형**: 동적 궤적 스케줄링 덕분에 ‘핫’ 전문가와 ‘콜드’ 전문가 간 실행 시간 차이가 1.1배 이하로 수렴했으며, 기존 EP 기반 방법에서 관찰되는 3‑5배 차이를 크게 줄였다.
- **에너지**: D2D 전송 에너지 효율이 0.29 pJ/bit 수준으로, 외부 DRAM 접근을 최소화함에 따라 전체 에너지 소비도 15‑20% 감소하였다.
**6. 논의 및 한계**
FSE‑DP는 고대역폭 D2D가 전제된 환경에서 최적화되었으며, D2D 대역폭이 제한된 구형 멀티칩렛에서는 이득이 감소할 수 있다. 또한, 현재 구현은 정적인 전문가 수와 고정된 Top‑K(2) 가정에 기반하므로, Top‑K가 동적으로 변하거나 전문가 수가 급격히 변동하는 경우 추가 연구가 필요하다.
**7. 결론**
본 연구는 고대역폭 다이‑투‑다이 인터커넥트를 활용해, 저배치 MoE 추론에 특화된 ‘Fully Sharded Expert Data Parallelism’을 제시한다. 온칩 메모리 중복을 원천 차단하고, 동적 전문가 궤적과 경량 스케줄링으로 계산‑통신 겹침과 부하 균형을 동시에 달성함으로써, 차세대 에지 AI 가속기에 필수적인 고성능·저전력 MoE 추론을 구현한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기