대장내시경 영상 밀집 병변 주석을 위한 에이전트 기반 워크플로우 Colon‑Bench
Colon‑Bench는 전체 절차 대장내시경 영상 528개에 대해 14종 병변을 300 k개 이상의 바운딩 박스와 213 k개의 세그멘테이션 마스크, 133 k 단어에 달하는 임상 설명으로 밀집 주석을 제공한다. 다단계 에이전트 파이프라인(시간 제안 → 트래킹 → AI 확인 → 인간 검수)을 통해 비용 효율적으로 고품질 데이터를 구축했으며, 이를 바탕으로 최신 멀티모달 대형 언어 모델(MLLM)의 병변 분류, 개방형 비디오 객체 세그멘테이션(O…
저자: Abdullah Hamdi, Changchun Yang, Xin Gao
본 논문은 대장내시경 영상 분석을 위한 데이터와 평가 인프라가 현저히 부족한 현실을 직시하고, 이를 해결하기 위한 ‘Colon‑Bench’라는 대규모 밀집 주석 데이터셋과 그 구축 파이프라인을 제안한다. 기존 데이터셋은 주로 단일 병변(폴립) 검출에 초점을 맞추고, 영상 길이가 짧거나 정적 이미지에 국한되는 경우가 많아, 최신 멀티모달 대형 언어 모델(MLLM)의 시공간·언어 복합 추론 능력을 평가하기에 한계가 있었다.
### 1. 데이터셋 구축 파이프라인
- **다단계 에이전트 워크플로우**: (①) VLM 기반 시간 제안 → (②) 필터링 에이전트 → (③) 바운딩 박스 트래킹(EdgeTAM) → (④) AI‑driven 시각적 확인 → (⑤) 인간 검수.
- **자동화 단계**: VLM은 1,325개의 후보 윈도우를 생성하고, 필터링 에이전트는 시간적 연속성과 신뢰도 점수로 30% 정도를 제거한다. EdgeTAM은 고속 트래킹을 수행해 314 k 박스를 생성하고, SAM‑3 기반 마스크 추적으로 227 k 세그멘테이션을 만든다. AI 확인 단계에서는 박스 내부 픽셀 분포, 색상 히스토그램, 혈관 패턴 등을 분석해 거짓 양성을 추가로 배제한다.
- **인간 검수**: 웹 기반 인터페이스에 자동 주석을 시각화하고, 전문 내시경 의사가 69개의 윈도우만을 거부, 최종 528개의 고품질 클립(총 464 035 프레임) 확보. 검수 후 정밀도 55.4%, 특이도 94.4% 달성.
### 2. 데이터셋 특성
- **규모**: 528개의 전체 절차 영상(총 12.9 시간), 14종 병변, 300 132 바운딩 박스, 213 067 세그멘테이션 마스크, 133 k 단어의 임상 설명.
- **병변 분포**: 폴립(411), 출혈(252), 궤양(160), 홍반(112) 등 장기적 롱테일 형태.
- **텍스트 라벨**: 자유형 임상 서술(평균 252.4단어/윈도우)로, 다중 병변 동시 기술 가능.
### 3. 평가 벤치마크 설계
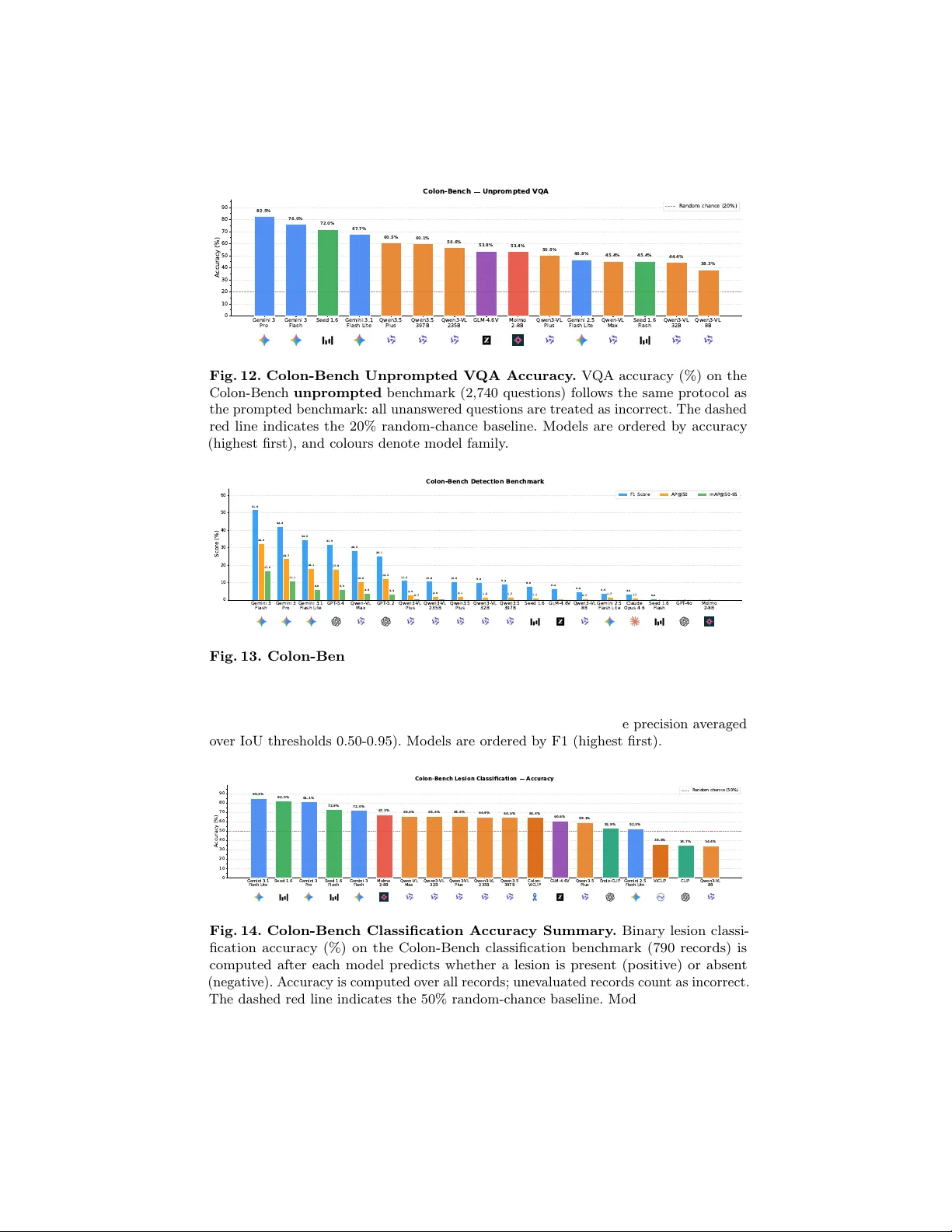
- **태스크**: (i) 이진 병변 존재 여부 분류(790 클립), (ii) 검출(272 클립, 61 538 프레임당 박스), (iii) 인스턴스 세그멘테이션(264 클립, 57 550 프레임당 마스크), (iv) VQA(프롬프트 기반 1 485 질문, 비프롬프트 2 740 질문).
- **VQA 설계**: 각 클립당 5개의 4선다형 질문을 Gemini‑3으로 자동 생성하고, 적대적 디스트랙터와 텍스트‑전용 스트레스 테스트를 통해 편향을 최소화.
### 4. 실험 결과
- **MLLM 성능**: Gemini 3 Pro와 Gemini 3 Flash가 전반적으로 최고 성능을 보이며, VQA 정확도 78.6%/76.0%, IoU 45.3%/Dice 51.3%를 기록. Qwen 3.5 Plus는 VQA에서는 강하지만 이진 분류에서는 거의 0% 재현율을 보여, 모델이 양성 병변을 무시하는 경향을 드러냄.
- **전통 모델 대비**: Endo‑CLIP 등 특화 모델 대비 MLLM이 30% 이상 높은 F1 점수를 기록, SAM‑3은 단독 사용 시 낮은 IoU(2.5%)를 보였지만, MLLM이 박스 프롬프트와 결합될 경우 성능 격차가 크게 감소.
- **Colon‑Skill 프롬프트**: 오류 패턴(위치 오인식, 형태 혼동, 해부학적 부위 오류 등)을 정리한 도메인‑특화 프롬프트를 추가하면, 대부분의 MLLM에서 VQA 정확도가 6~9% 포인트 상승, 특히 Gemini 3 Flash에서 9.7% 상승.
### 5. 기여 및 의의
1. **에이전트 기반 자동‑수동 주석 파이프라인**을 제시해 대규모 의료 영상에 대한 비용 효율적 밀집 라벨링 가능성을 입증.
2. **Colon‑Bench**라는 최초의 개방형 비디오 객체 세그멘테이션(OV‑VOS) 데이터셋을 구축, 14종 병변과 풍부한 텍스트 라벨을 제공함으로써 멀티모달 모델 연구에 새로운 벤치마크 제공.
3. 최신 **MLLM**들의 의료 영상 이해 능력을 체계적으로 평가하고, 기존 특화 모델 대비 경쟁력을 정량화.
4. **도메인‑특화 프롬프트(Colon‑Skill)**를 통해 사전 학습 없이도 제로샷 성능을 크게 향상시킬 수 있음을 실증, 프롬프트 엔지니어링의 실용적 가치를 강조.
결론적으로, 본 연구는 대장내시경 영상 분석에 필요한 데이터와 평가 인프라를 크게 확장하고, 멀티모달 AI가 실제 임상 현장에서 활용될 수 있는 기반을 마련하였다. 데이터와 코드가 공개됨에 따라, 향후 다양한 의료 영상·언어 멀티모달 연구에 폭넓은 파급 효과가 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기