분배망 고장 예측을 위한 최적 특징 선택
본 논문은 현장 데이터 부족과 비효율적인 특징 선택 문제를 해결하기 위해 시뮬레이션 기반 대체 과제를 제안한다. 20 kV 배전망 모델에서 20 000개의 시뮬레이션을 생성하고 1 556개의 후보 특징 중 374개를 최적화하였다. 실제 3개 변전소 데이터에 적용한 결과, F1‑score 0.80을 달성하며 기존 주파수·웨이브렛 기반 방법보다 우수함을 보였다.
저자: Georg Kordowich, Julian Oelhaf, Siming Bayer
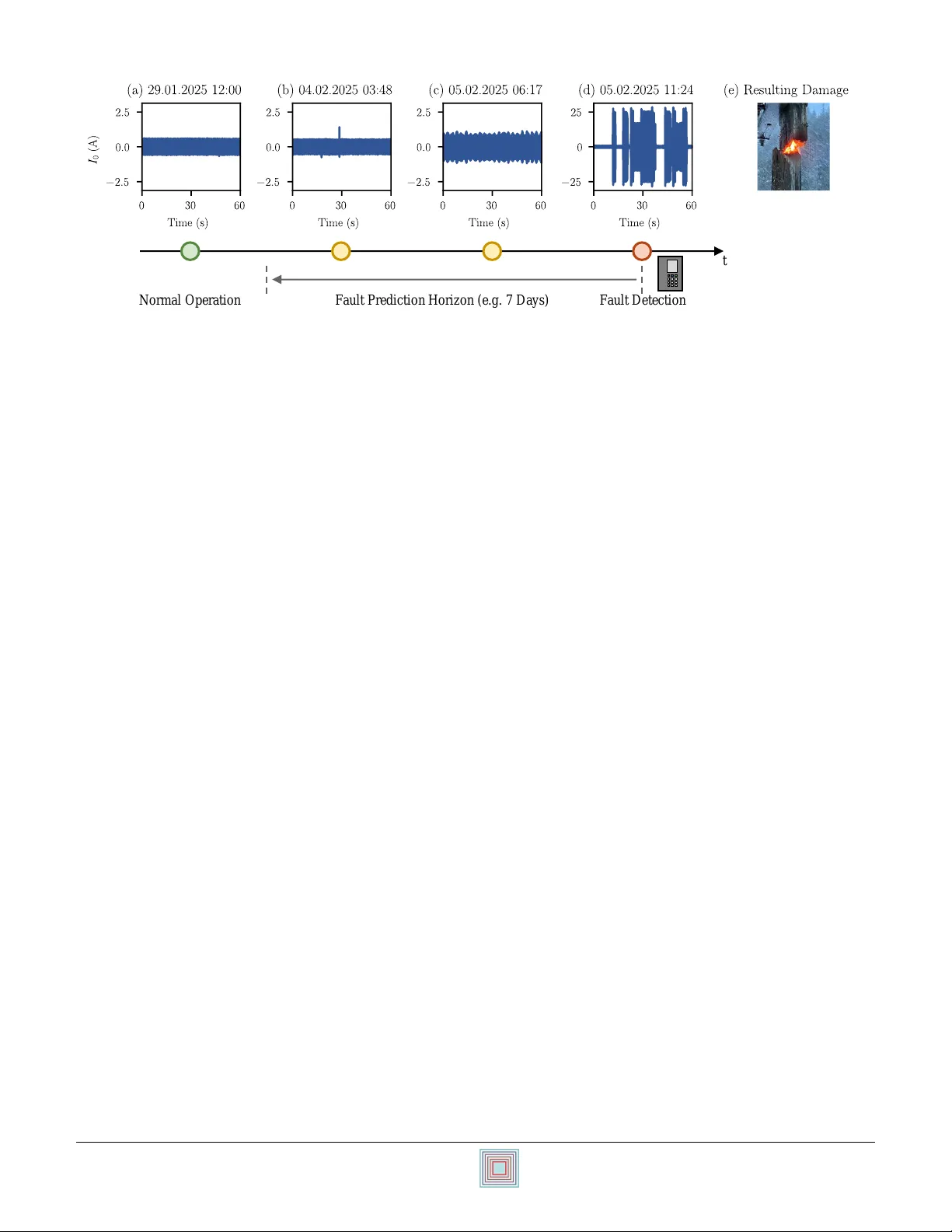
본 논문은 배전망 고장 예측(FP) 시스템의 실용화를 가로막는 두 가지 핵심 문제, 즉 현장 라벨링 데이터의 부족과 비효율적인 특징 선택을 동시에 해결하고자 한다. 저자들은 먼저 기존 연구가 제시한 ‘전이 사건 분류(transient event classification)’를 FP의 대체 과제로 설정한다. 이 대체 과제는 시뮬레이션 기반으로 손쉽게 대량 데이터를 생성할 수 있으며, 실제 FP 성능과 r = 0.92라는 높은 상관관계를 보임을 실험적으로 입증한다.
시뮬레이션 데이터는 DIgSILENT PowerFactory를 이용해 CIGRE 22 kV 배전망을 모델링하고, 스위치 상태를 무작위로 변형해 다양한 메싱 구조와 운영 조건을 재현한다. 17가지 전이 이벤트(인라시, 부하 스위칭, 고임피던스 고장, 아크 고장 등)를 포함해 34개의 세부 클래스와 20 000개의 시뮬레이션 샘플을 생성함으로써, 특징 선택 단계에서 과적합 위험을 최소화한다.
특징 추출 단계에서는 각 샘플에서 500 ms 길이의 두 개 윈도우(연속 변화와 순간 변동)를 선택한다. 연속 변화 윈도우는 트렌드·시즌성·잔차 분해를 통해 RMS가 최대인 구간을, 순간 변동 윈도우는 크레스트 팩터가 최대인 구간을 선정한다. 이렇게 선택된 윈도우는 8채널(3상 전압·전류, 0‑시퀀스 전압·전류) 데이터를 포함하며, 시간 영역 통계량, 파워 스펙트럼, 웨이브렛 계수, 비선형 비율 등 총 1 556개의 후보 특징을 만든다.
특징 선택은 상관계수 기반 전처리, 변수 중요도(랜덤 포레스트), 순차 전진 선택을 결합한 하이브리드 방법을 적용한다. 이 과정을 통해 374개의 최적 특징이 도출되며, 이들 특징은 고장 전조 신호와 높은 연관성을 보이는 트렌드 변화, 고주파 성분, 비선형 전압·전류 비율 등을 포함한다. 선택된 특징은 시간당 최소·최대·평균·표준편차로 집계해 1 496개의 최종 입력 벡터를 만든다.
분류 모델은 랜덤 포레스트(RF)를 사용한다. RF는 잡음에 강하고 변수 중요도 해석이 용이해 FP에 적합하다. 실제 22 kV 변전소 3곳에서 14 TB(14.4 kHz) 규모의 전압·전류 데이터를 수집하고, 7일 예측 창을 기준으로 라벨링한 뒤 모델을 학습·검증하였다. 실험 결과, 제안된 특징 집합을 사용한 RF는 F1‑score 0.80을 달성했으며, 기존 주파수·웨이브렛 기반 특징을 사용한 모델 대비 약 8 %p 향상되었다. 또한, 특징 수를 374개에서 100개 이하로 축소해도 성능 저하가 미미했으나, 50개 이하로 줄이면 급격히 감소하는 경향을 보여, 충분한 특징 다양성이 모델 일반화에 핵심임을 확인한다.
논문의 주요 기여는 다음과 같다. (1) 시뮬레이션 기반 대체 과제를 통해 현장 데이터 의존도를 낮추고, 특징 선택을 위한 대규모 학습 환경을 제공한다. (2) 1 556개의 후보 특징 중 374개를 체계적으로 선택해 FP 성능을 크게 향상시킨다. (3) 실제 변전소 데이터에 적용해 기존 방법을 능가하는 성능을 입증한다.
한계점으로는 시뮬레이션과 현장 데이터 간 도메인 차이, 고정된 7일 예측 창, 전압·전류 외 추가 센서 활용 미비 등이 있다. 향후 연구에서는 도메인 적응 기법, 예측 창의 동적 최적화, 온도·습도·진동 등 멀티모달 데이터 융합을 통해 FP 시스템의 신뢰성을 더욱 강화할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기