지역 고유 차원 추정에 대한 배깅 활용
본 논문은 지역 고유 차원(LID) 추정의 높은 분산 문제를 해결하기 위해 서브배깅을 적용한 앙상블 방법을 제안한다. 샘플링 비율 r, 이웃 크기 k, 앙상블 수 B가 편향·분산·MSE에 미치는 영향을 이론적으로 분석하고, 다양한 벤치마크에서 실험적으로 검증한다. 또한 이웃 스무딩과 결합한 두 단계 기법을 도입해 추정 정확도를 추가로 향상시킨다.
저자: Kristóf Péter, Ricardo J. G. B. Campello, James Bailey
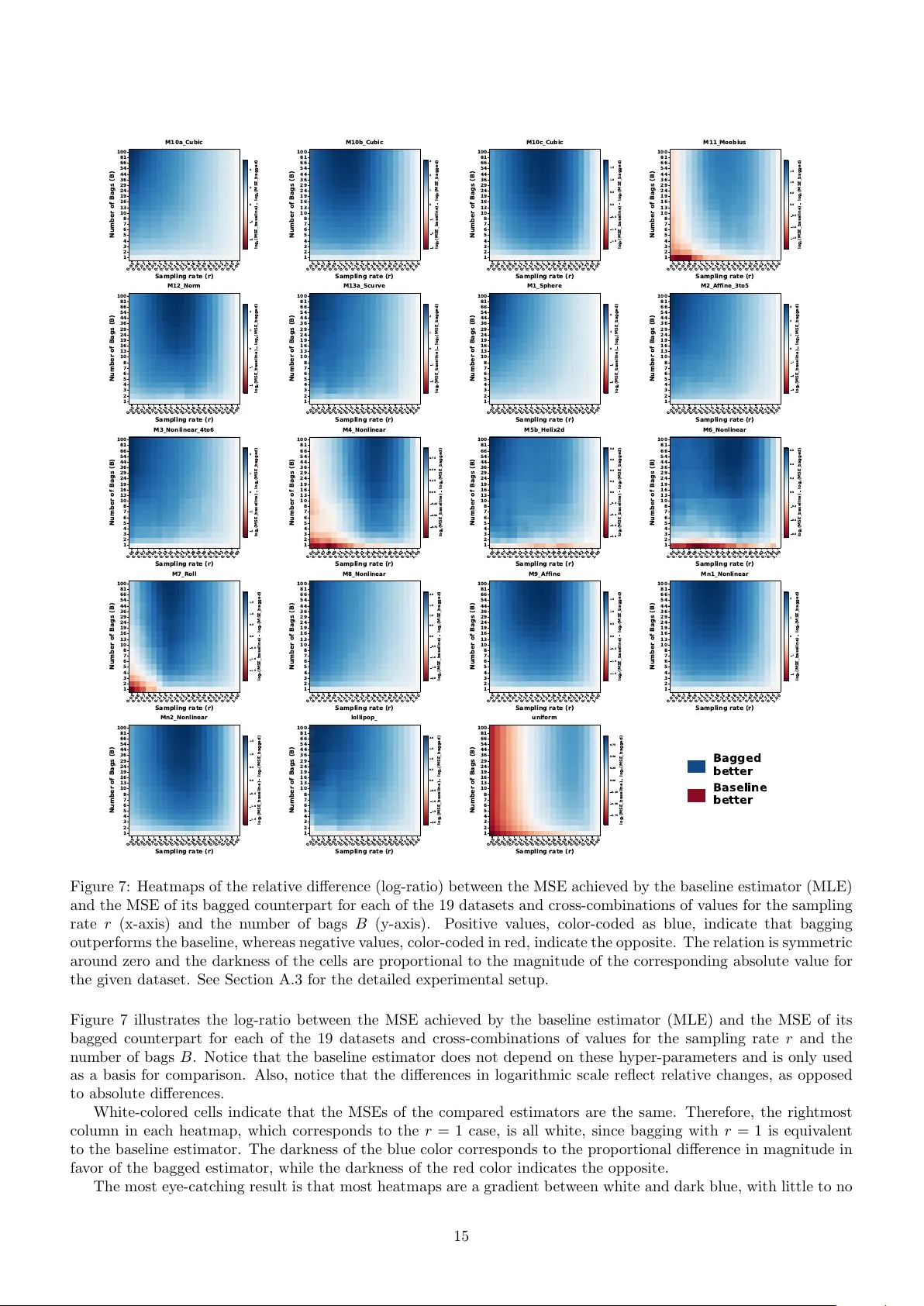
본 연구는 지역 고유 차원(Local Intrinsic Dimensionality, LID) 추정의 실용적 한계인 높은 분산 문제를 해결하고자, 서브배깅(subbagging) 기반의 앙상블 기법을 제안한다. LID는 데이터 매니폴드의 국부 차원을 정량화하는 개념으로, 이상치 탐지, 유사도 검색, 적대적 공격 분석 등 다양한 머신러닝 응용 분야에서 활용된다. 기존 LID 추정기는 k‑Nearest Neighbor(k‑NN) 기반의 거리 분포를 이용해 EVT(Extreme Value Theory) 모델을 적합하지만, 작은 반경을 유지하려면 충분한 이웃 샘플이 필요하고, 데이터가 제한적일 경우 분산이 급증한다. 반대로 반경을 넓히면 비국부 구조가 섞여 편향이 증가한다는 전형적인 bias‑variance trade‑off가 발생한다.
이러한 딜레마를 극복하기 위해 저자들은 부트스트랩의 변형인 서브배깅을 도입한다. 서브배깅은 각 bag을 전체 데이터에서 무복원으로 r·n개의 샘플을 추출해 구성한다. 이때 r∈(0,1)인 샘플링 비율이 핵심 파라미터가 된다. 각 bag에서 동일한 k값을 사용하면, 전체 데이터 대비 샘플 수가 감소하므로 실제 이웃 반경이 확대된다. 이는 LID 추정에 있어 “낮은 꼬리(threshold)와 샘플 크기” 사이의 복합적인 관계를 형성한다. 저자는 이 현상을 수학적으로 모델링하고, 다음과 같은 이론적 결과를 도출한다.
1. **편향 유지**: bagged estimator ˆθ_{B,m}의 기대값은 개별 bag estimator와 동일하므로, 평균적으로 편향은 변하지 않는다.
2. **분산 감소**: B→∞일 때 Var(ˆθ_{B,m})는 Var(E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기