다중인구 사망률 예측을 위한 텐서 흐름장 모델
본 논문은 인간 사망률 데이터베이스(HMD)의 성·연령·국가·연도 4차원 텐서를 Tucker 분해하여 저차원 점수 공간을 만든 뒤, 그 공간에서 사망률 전이가 일차원 흐름으로 진행된다는 사실을 발견한다. 수준 점수 s₁의 변화 속도를 나타내는 스피드 함수와, s₁에 대응하는 구조 점수 s₂‑s₅를 매핑하는 트래젝터리 함수를 학습해 미래의 전체 사망률 스케줄을 재구성하고, 기대수명 e₀을 계산한다. 시대 가중 스피드 함수와 국가별 구조 점수의 경…
저자: Samuel J. Clark
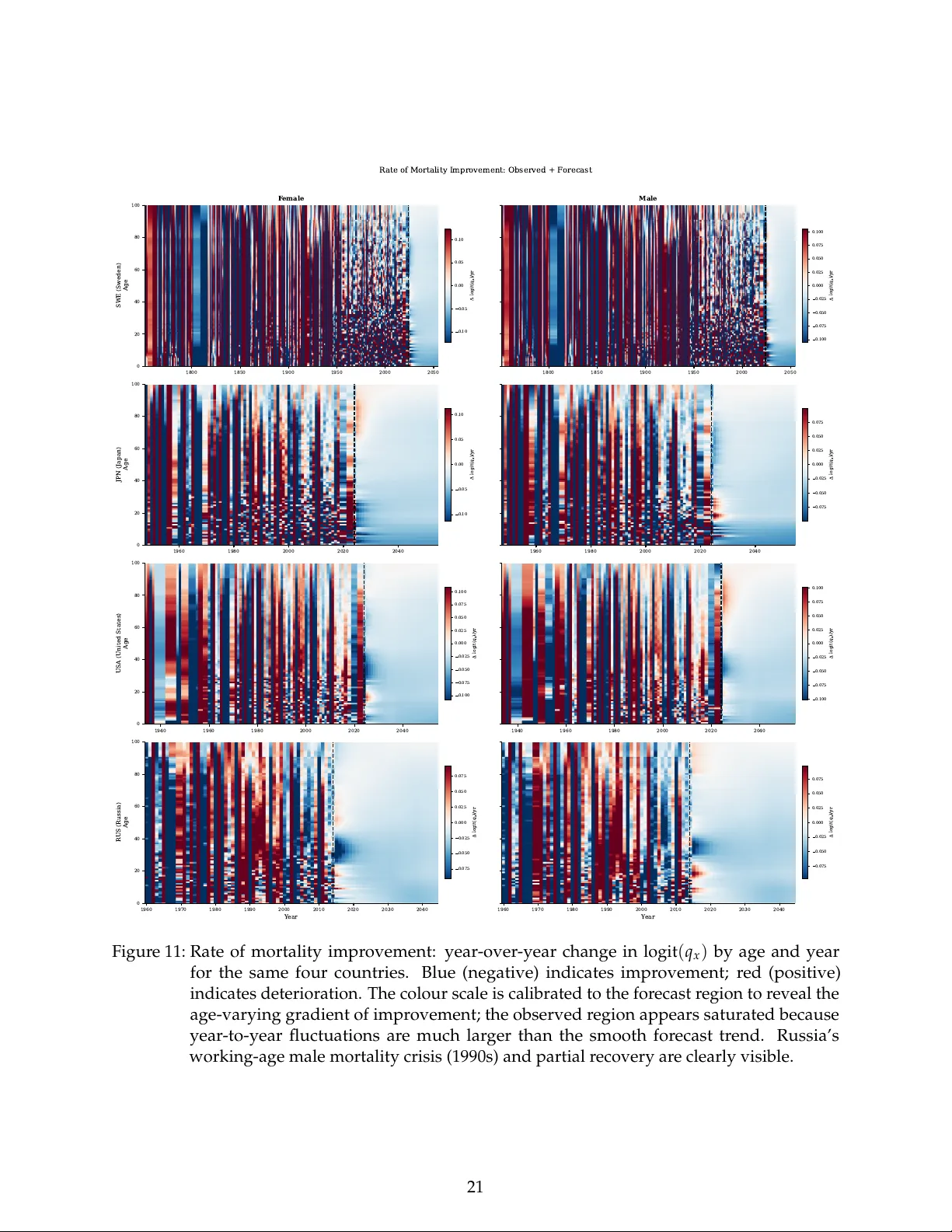
본 논문은 인간 사망률 데이터베이스(HMD)에서 제공하는 성·연령·국가·연도 4차원 사망률 텐서를 Tucker 분해하여 저차원 점수 공간을 구축하고, 그 공간에서 사망률 전이가 일차원 흐름으로 진행된다는 새로운 관점을 제시한다.
1. **데이터와 Tucker 분해**
- 원본 텐서는 로그오즈(qₓ) 형태이며 차원은 성 2 × 연령 110 × 국가 48 × 연도 274이다.
- Tucker 분해는 차원 축소를 위해 (r₁,r₂,r₃,r₄) = (2,42,46,100) 의 랭크를 선택하고, 각각 성, 연령, 국가, 연도에 대한 팩터 행렬 S, A, C, T와 핵 텐서 G를 도출한다.
- 각 국가·연도에 대한 핵 매트릭스 G_ct는 팩터 행렬 C와 T를 통해 선형 결합된 2 × 42 차원의 효과 코어이며, 이를 다시 S와 A와 곱해 전체 사망률 스케줄을 재구성한다.
2. **점수 공간과 PCA**
- G_ct를 벡터화한 뒤 전 세계 관측치에 대해 PCA를 수행하면 5개의 주성분이 전체 변동의 97%를 설명한다.
- 첫 번째 주성분(PC1)은 91.8%의 분산을 차지해 사망률 수준(level)을 거의 완전히 대변한다. 나머지 4개는 연령·성·국가별 구조적 차이를 포착한다.
3. **일차원 흐름 발견**
- 각 국가·연도에 대한 5차원 점수 s = (s₁,…,s₅)를 구하고, LOWESS로 스무딩한 뒤 전진 차분을 통해 변화율 Δs를 계산한다.
- Δs₁와 Δs₂‑Δs₅ 사이의 상관계수가 –0.92, –0.55, 0.50, 0.57 등 매우 높아, 점수 변화가 사실상 하나의 스칼라 s₁에 의해 동기화된다는 것을 확인한다.
- 따라서 사망률 전이는 “스피드 함수 g*(s₁)=ds₁/dt”와 “트래젝터리 함수 f*_k(s₁) (k=2…5)”로 완전히 기술될 수 있다.
4. **스피드 함수와 트래젝터리 함수 추정**
- **스피드 함수**: 각 국가별로 LOWESS(프랙션 0.25)를 적용해 연도별 s₁ 의 변화를 평활화하고, 그 차분을 다시 전 국가에 대해 LOWESS 회귀한다. 이렇게 하면 전쟁·전염병·경제 위기 등 단기 충격을 억제하면서도 전 세계적인 수준‑의 개선 패턴을 포착한다.
- **시대 가중**: 최근 데이터에 더 큰 가중치를 주기 위해 반감기 τ와 하드 윈도우 W를 갖는 지수 가중 함수를 도입한다. 교차 검증을 통해 τ = 12년, W = 40년이 최적임을 확인했다. 이는 과거 급격한 개선 속도가 현재와 동일하게 적용되는 것을 방지한다.
- **트래젝터리 함수**: 각 구조 점수 s_k (k=2…5)를 원시 s₁에 대해 LOWESS 회귀한다. 결과는 s₁ (또는 e₀) 에 대한 연속적인 모델 라이프테이블 시스템을 제공한다.
5. **구조 점수의 수렴 속도**
- 국가별 s₂‑s₅ 가 전역적인 표준 궤적 f*_k(s₁) 에서 벗어나는 정도를 측정하고, AR(1) 모델을 적용해 반감기를 12–32년 사이로 추정한다. 이는 각 국가가 고유한 사망률 구조를 유지하다가 점차 평균 전이 궤적으로 회귀한다는 가정을 정량화한 것이다.
6. **예측 절차**
- 주어진 출발점 s₁(t₀) 에 스피드 함수를 적분해 s₁(t₀+h) 를 얻는다.
- s₁(t₀+h) 을 트래젝터리 함수에 대입해 s₂‑s₅ 를 계산하고, 5차원 점수를 이용해 Tucker 재구성을 수행한다.
- 재구성된 사망률 표면에서 기대수명 e₀를 직접 계산한다. 이 방식은 e₀ 누적 방식에서 발생하는 비선형 편향을 완전히 제거한다.
7. **성능 평가**
- **Leave‑Country‑Out** 교차 검증: 48개 국가를 제외하고 50년 예측(총 9,529 테스트 포인트) 수행.
- **MAE**: 4.46년 (Lee‑Carter 5.53년, Hyndman‑Ullah 5.76년 대비 각각 19%·23% 감소).
- **편향**: –0.05년(거의 무편향) vs. Lee‑Carter –4.33년, Hyndman‑Ullah –4.67년.
- **시간 구간별 정확도**: 1–10년 구간에서는 기존 방법이 약간 우수하지만, 12년 이후부터는 오차 감소율이 급격히 상승해 26–50년 구간에서는 36%–41%까지 개선.
8. **추가 실험 및 적용**
- 비 HMD 국가(예: 개발도상국)에도 동일한 흐름 모델을 적용해도 합리적인 예측이 가능함을 보이며, 모델 라이프테이블 시스템을 자동으로 생성한다는 부가적 가치를 강조한다.
- 성·연령·국가 간의 일관성을 자연스럽게 보장하고, 별도의 성별 별 모델을 별도로 추정할 필요 없이 하나의 통합 프레임워크에서 동시에 예측한다.
9. **논의와 한계**
- 모델의 주요 강점은 파라미터가 매우 적고(스피드 함수와 트래젝터리 함수만) 해석이 용이하다는 점이다.
- 한계로는 매우 낮은 사망률(극단적 고령사회)에서 스피드 함수가 데이터 부족으로 불안정해질 수 있으며, 급격한 구조 변화(예: 대규모 전염병) 발생 시 즉각적인 적응이 어려울 수 있다. 향후 연구에서는 베이지안 프레임워크와 실시간 가중 업데이트를 도입해 이러한 문제를 보완하고자 한다.
**결론**
본 연구는 사망률 전이가 저차원 구조에 의해 강하게 제약된다는 사실을 실증하고, 이를 “점수 공간의 일차원 흐름”으로 모델링함으로써 장기 인구 예측에서 기존 시계열 기반 방법을 크게 능가한다는 중요한 결과를 제시한다. 또한, 사망률 전반을 하나의 통합 프레임워크에서 동시에 예측함으로써 성·연령·국가 간 일관성을 자연스럽게 확보하고, 모델 라이프테이블을 자동 생성하는 실용적인 부가가치를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기