소비자 카메라로 만든 3D 머리 메쉬, 개인 HRTF 합성 가능성 탐구
본 연구는 iPhone XS와 Apple Object Capture API를 이용해 150명의 머리와 귀를 72장의 사진으로 포토그래메트리 재구성한 후, Mesh2HR TF를 사용해 개인 HRTF를 합성한다. 합성 HRTF는 측정된 HRTF와 고해상도 스캔 기반 HRTF와 비교했을 때 ITD는 보존하지만 ILD와 고주파 스펙트럼에서 큰 오류를 보이며, 청각 모델 및 실제 청취 실험에서 위치 정확도가 크게 떨어진다. 현재 소비자용 포토그래메트리 …
저자: Ludovic Pirard, Lorenzo Picinali, Katarina C. Poole
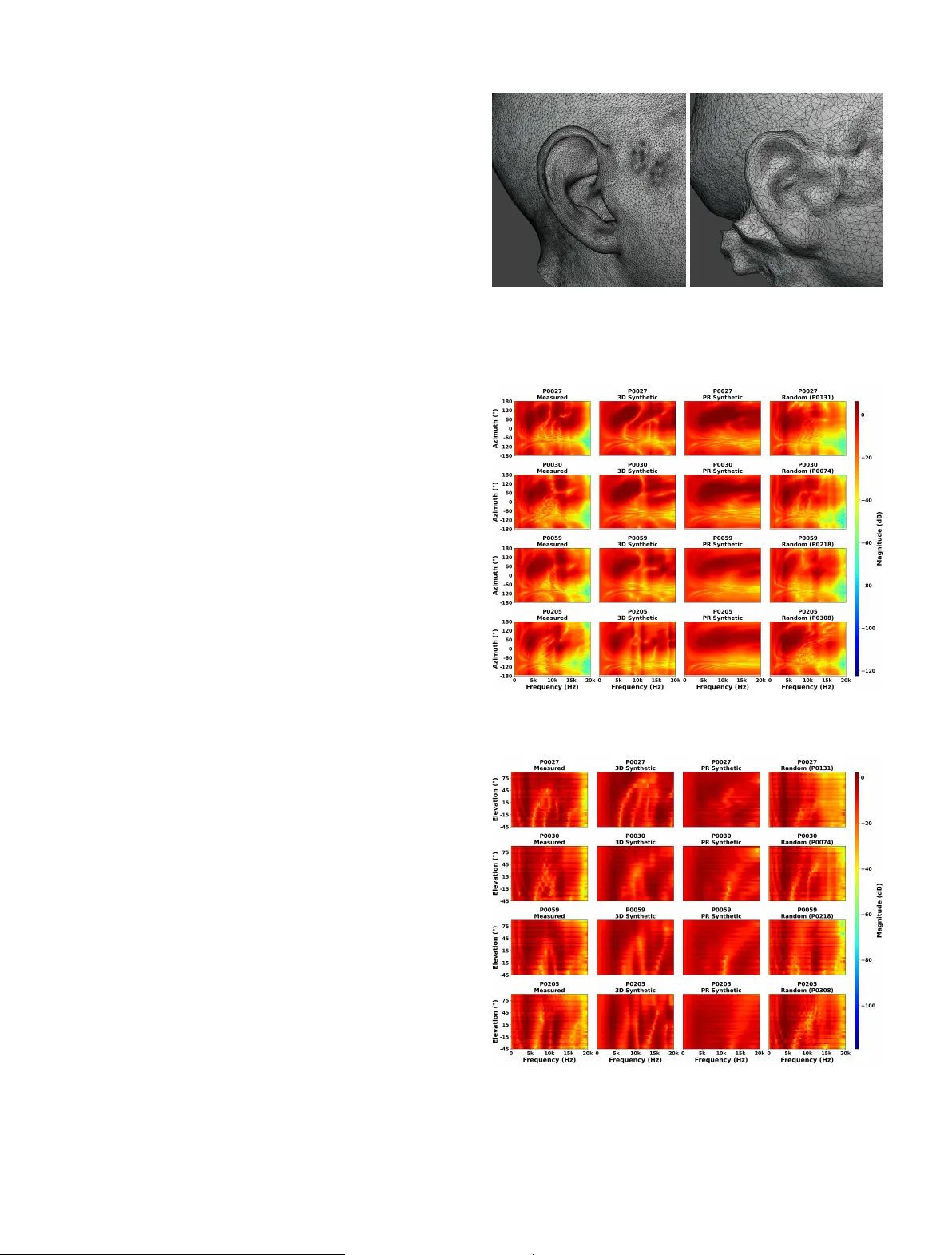
본 논문은 개인화된 3차원 공간음향 구현을 위한 비용‑효율적인 방법으로, 일반 소비자용 스마트폰(iPhone XS)과 Apple의 Object Capture API를 이용해 150명의 피험자 머리와 귀를 포토그래메트리 방식으로 재구성하고, 이를 기반으로 Mesh2HR TF를 사용해 개인 HRTF를 합성하는 전 과정을 상세히 검증한다. 연구는 크게 네 단계로 구성된다. 첫 번째 단계에서는 SONICOM 데이터베이스에 포함된 72장의 RGB‑D 사진을 촬영하고, iPhone의 TrueDepth 기술을 활용해 깊이 맵을 확보한다. 두 번째 단계에서는 다양한 포토그래메트리 소프트웨어를 비교한 결과, Apple Object Capture API가 가장 낮은 잡음과 일관된 토르소·헤드 형태를 제공함을 확인하고, 이를 자동화된 Swift 파이프라인으로 150개의 STL 메쉬를 생성한다. 세 번째 단계에서는 생성된 메쉬를 고해상도 레퍼런스 스캔(ExScan Pro)과 프랑크푸르트 평면 기준으로 정렬·ICP 보정하고, 토르소를 베헤드 처리한 뒤, 고곡률 영역(특히 귓바퀴)에 커브‑어댑티브 메쉬 그레이딩을 적용해 해상도를 높이며, 비다양체·자기교차 등을 제거한다. 네 번째 단계에서는 정제된 메쉬를 Mesh2HR TF에 입력해 0 ~ 24 kHz, 150 Hz 간격의 BEM 시뮬레이션을 수행한다. 합성된 HRIR은 KEMAR 기준에 맞춰 시간 정렬, 윈도윙, 레벨 정규화, ITD 제거 과정을 거쳐 SOFA 파일로 저장된다.
수치 평가에서는 ITD, ILD, 그리고 단일 귀 스펙트럼을 나타내는 Log‑Spectral Distortion(LSD) 세 가지 핵심 지표를 사용했다. ITD는 평균 절대 오류가 0.07 ms 이하로, 고해상도 스캔 기반 합성 및 실제 측정값과 거의 차이가 없었다. 반면 ILD는 평균 2.1 dB의 오류를 보였으며, 특히 8 kHz 이상 고주파에서 큰 편차가 나타났다. LSD 역시 평균 3.8 dB로, 고해상도 기반(1.1 dB)보다 크게 악화되었다. 이러한 수치 차이는 포토그래메트리 메쉬가 머리 전체 형태는 잘 재현하지만, 귓바퀴와 같은 미세 구조를 충분히 포착하지 못함을 의미한다.
청각 모델(두 가지 신경생리학적 모델)과 인간 청취 실험을 통해 이러한 수치 차이가 실제 인지에 미치는 영향을 검증하였다. 모델 기반 예측에서는 PR‑HRTF가 평균 사분면 오류 38°를 기록했으며, 전후 혼동 비율이 45%에 달했다. 실제 청취 실험(27명, VR 환경)에서도 PR‑HRTF는 평균 사분면 오류 42°, 고도 RMS 12°를 보였으며, 이는 측정 HRTF(10°/5°)와 비교해 크게 떨어지는 성능이다. 흥미롭게도 무작위 HRTF와의 차이는 미미했으며, 경우에 따라 랜덤 HRTF가 전후 구분에서 더 나은 결과를 보이기도 했다.
연구는 현재 소비자용 포토그래메트리 파이프라인이 개인 HRTF 합성에 제한적임을 명확히 제시한다. 주요 한계는 (1) 귓바퀴 디테일 부족으로 인한 고주파 ILD·LSD 오류, (2) 턱·목 부위 잡음이 메쉬 정밀도에 미치는 영향, (3) 모든 피험자에 동일한 물성 파라미터를 적용한 점, (4) 오프라인 처리에 머무르는 시뮬레이션 속도이다. 향후 연구 방향으로는 고해상도 RGB‑D 센서(LiDAR·구조광 결합) 도입, 머신러닝 기반 메쉬 보정(특히 귀 부분), 그리고 딥러닝을 활용한 스펙트럼 보정 또는 GPU 가속 BEM을 통한 실시간 합성 등이 제시된다. 최종적으로, 본 연구는 “소비자 하드웨어만으로는 충분히 정확한 개인 HRTF를 제공하기 어렵다”는 결론을 내리며, 고주파 단일 귀 단서 확보가 개인화된 공간음향 구현의 핵심 과제임을 강조한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기