카운트 노출의 역확률 가중치와 결측 데이터 처리: 시뮬레이션 연구
본 연구는 심리적 고통 증상 수와 중년기의 만성 질환 발생 사이의 인과관계를 추정하기 위해, 결측 데이터가 존재할 때 카운트형 노출에 적용 가능한 다섯 가지 역확률 가중치(IPTW) 방법을 비교한다. 완전 데이터와 결측 데이터(MCAR, MAR) 상황에서 편향, 신뢰구간 커버리지, 유효 표본 크기 등을 평가한 결과, 다항형 구간화, CBPS, GBM, 에너지 밸런싱이 전반적으로 낮은 편향과 적절한 커버리지를 보였으며, 비파라메트릭 CBPS는 극…
저자: Martin N. Danka, Jessica K. Bone, George B. Ploubidis
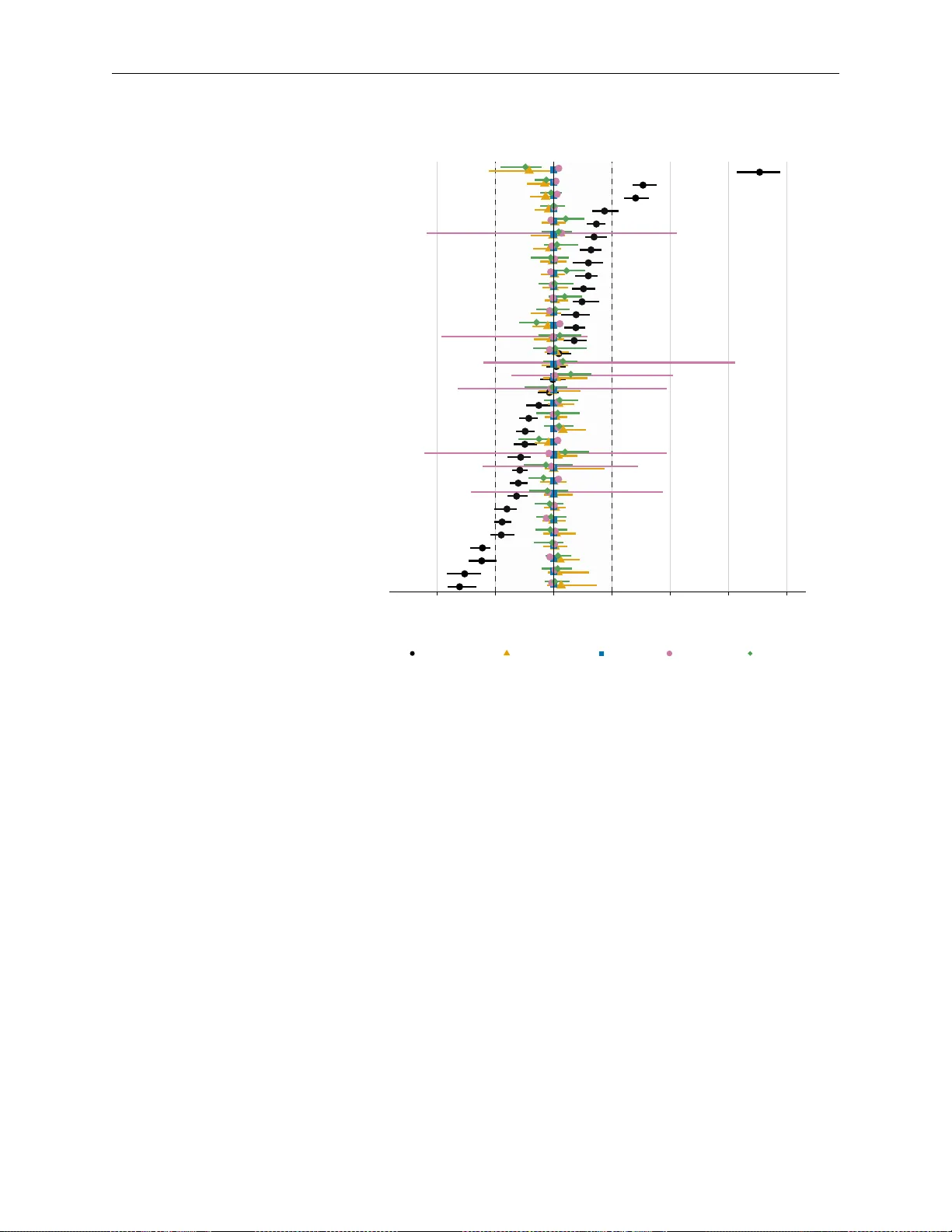
본 논문은 관찰 연구에서 카운트형 노출(예: 증상 수, 병원 방문 횟수 등)을 대상으로 인과 효과를 추정하기 위해 역확률 가중치(IPTW) 방법을 적용하고, 결측 데이터가 존재할 때 다중 임퓨테이션과 결합했을 때의 성능을 체계적으로 평가한다. 연구 동기는 기존 IPTW 연구가 대부분 이진 노출에 초점을 맞추었으며, 카운트형 노출의 특수한 분포(과분산, 영(0)값 다수, 오른쪽 절단 등)와 결측 데이터가 동시에 존재하는 실제 상황에 대한 가이드라인이 부족하다는 점에 있다.
연구는 크게 두 부분으로 구성된다. 첫 번째는 다섯 가지 가중치 추정 방법을 소개하고, 각각의 이론적 배경과 구현 방식을 설명한다.
1) **멀티노미얼 바이닝**: 카운트 노출을 K개의 구간(예: 사분위수)으로 나눈 뒤, 다항 로짓 모델을 사용해 각 구간에 대한 조건부 확률을 추정한다. 이는 노출 모델링의 복잡성을 완화하고, 안정적인 가중치를 제공한다.
2) **Parametric CBPS**: 노출을 표준화하고, 공변량과 노출 간의 상관을 0으로 만드는 제약조건을 포함한 일반화 모멘트 방법을 사용해 가중치를 추정한다. 여기서는 노출의 주변 분포를 정규(N(0,1))로 가정한다.
3) **Non‑parametric CBPS (npCBPS)**: 주변 분포와 조건부 분포를 명시적으로 가정하지 않고, 경험적 가능도(empirical likelihood)를 기반으로 가중치를 최적화한다. 제약조건은 총 가중치 합이 N, 평균 공변량과 노출이 0, 가중치가 양수인 점이다.
4) **Generalised Boosted Models (GBM)**: Gradient Boosting을 이용해 노출‑공변량 관계를 비선형적으로 추정한다. 트리 수(M)를 공변량‑노출 상관 최소화 기준으로 선택해, 가중치가 공변량 균형을 가장 잘 달성하도록 튜닝한다.
5) **Energy Balancing**: 두 변수 집합(노출과 공변량) 사이의 에너지 거리(거리 기반 통계량)를 최소화함으로써, 확률 모델 가정 없이도 균형을 달성한다.
두 번째는 시뮬레이션 설계와 결과 분석이다. 시뮬레이션은 1970 영국 코호트 연구(British Cohort Study) 데이터를 기반으로 설계되었으며, 심리적 고통 증상 수(카운트)와 42세 시점의 장기 질환 여부(이진) 사이의 인과 관계를 목표로 한다. 노출 분포는 (1) 오른쪽 절단된 음이항(Negative Binomial)과 (2) 포아송(Poisson) 두 가지 시나리오를 고려했으며, 공변량은 실제 코호트 데이터에서 추출한 10개의 잠재적 교란 변수로 구성하였다.
시뮬레이션은 다음 네 가지 상황을 포함한다.
- **완전 데이터**: 결측이 전혀 없는 경우.
- **MCAR**: 결측이 완전히 무작위로 발생, 결측 비율을 10%, 30%, 50%로 변동.
- **MAR**: 결측이 공변량에 의존, 동일한 비율로 변동.
- **임퓨테이션 모델**: 다중 임퓨테이션을 ‘within‑imputation’ 방식으로 적용, 각 임퓨테이션 데이터셋에서 가중치를 별도 추정 후 Rubin’s rules로 결과 통합.
평가 지표는 (1) 평균 편향(Bias), (2) 95% 신뢰구간 커버리지(Coverage), (3) 유효 표본 크기(Effective Sample Size, ESS), (4) 가중치 분포(극단값 비율) 등이다.
**주요 결과**는 다음과 같다.
- **완전 데이터**: 멀티노미얼 바이닝, 파라메트릭 CBPS, GBM, 에너지 밸런싱은 모두 평균 편향이 5% 이하이며, 커버리지는 94~96%로 명목 수준(95%)에 가깝다. ESS도 80~95% 수준으로 유지되었다. 반면 npCBPS는 가중치가 극단적으로 커져 ESS가 40% 이하로 떨어지고, 편향이 12%까지 증가했으며, 커버리지는 80% 미만으로 저조했다.
- **MCAR**: 결측 비율이 증가해도 위 네 방법은 편향과 커버리지에서 큰 변화를 보이지 않았다. 다만, 전체 표본 크기가 감소함에 따라 ESS가 약간 감소했지만, 여전히 70% 이상을 유지했다.
- **MAR**: 모든 방법에서 결측 비율이 50%에 달하면 평균 편향이 6~9%로 약간 상승했으며, 커버리지는 90%대로 약간 낮아졌다. 이는 임퓨테이션 모델이 오른쪽 절단된 과분산 카운트를 충분히 반영하지 못했기 때문이다. 특히, 파라메트릭 CBPS와 GBM은 이 상황에서도 비교적 안정적인 성능을 보였으며, 에너지 밸런싱도 비슷한 수준을 유지했다.
- **npCBPS**는 MAR 상황에서도 극단적인 가중치가 지속돼 편향이 15%에 육박하고, 커버리지는 75% 이하로 크게 악화되었다.
연구자는 이러한 결과를 바탕으로 다음과 같은 실무적 권고를 제시한다.
1) 카운트형 노출에 대해 IPTW를 적용할 때는 **멀티노미얼 바이닝**이나 **파라메트릭 CBPS**, **GBM**, **에너지 밸런싱**을 우선 고려한다.
2) **npCBPS**는 현재 구현 방식에서는 가중치가 과도하게 변동할 위험이 있어, 특별히 가중치 절단이나 추가 정규화가 필요하다.
3) 결측 데이터가 MAR일 경우, 임퓨테이션 모델에 카운트형 변수의 오른쪽 절단과 과분산을 명시적으로 포함시켜야 한다. 예를 들어, 트렁케이티드 네거티브 바이노미얼 회귀를 사용한 다중 임퓨테이션이 바람직하다.
4) 가중치 추정 후에는 **ESS**와 **가중치 분포**를 반드시 검토해, 극단값이 존재하면 추가적인 가중치 절단(weight trimming)이나 재추정이 필요하다.
마지막으로, 연구는 제한점도 명시한다. 시뮬레이션은 실제 코호트 데이터의 구조를 모사했지만, 영(0)값이 매우 많은 경우나 복합적인 제로인플레이션-과분산 혼합 모델을 고려하지 않았다. 또한, 결측 메커니즘이 MNAR(Not at Random)인 경우는 다루지 않았으며, 이는 향후 연구 과제로 남는다.
전반적으로, 본 논문은 카운트형 노출과 결측 데이터가 동시에 존재하는 현실적인 상황에서 IPTW 방법론을 선택하고 적용하는 데 필요한 실증적 근거를 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기