양자 스타일 기반 워셔스틴 GAN을 활용한 신약 설계
본 논문은 변분 오토인코더(VAE)로 SMILES 문자열을 저차원 잠재공간에 압축하고, 그 잠재벡터를 입력으로 하는 스타일 기반 양자 생성적 적대 신경망(QGAN)을 제안한다. 회전 게이트마다 노이즈를 인코딩하고 WGAN‑GP 손실에 그래디언트 페널티를 적용해 모드 붕괴를 완화한다. 15‑qubit 시뮬레이터와 156‑qubit IBM Heron 실제 하드웨어에서 실험을 수행했으며, MOSES 벤치마크와 비교해 파라미터 수는 크게 줄이면서도 경…
저자: Julien Baglio, Yacine Haddad, Richard Polifka
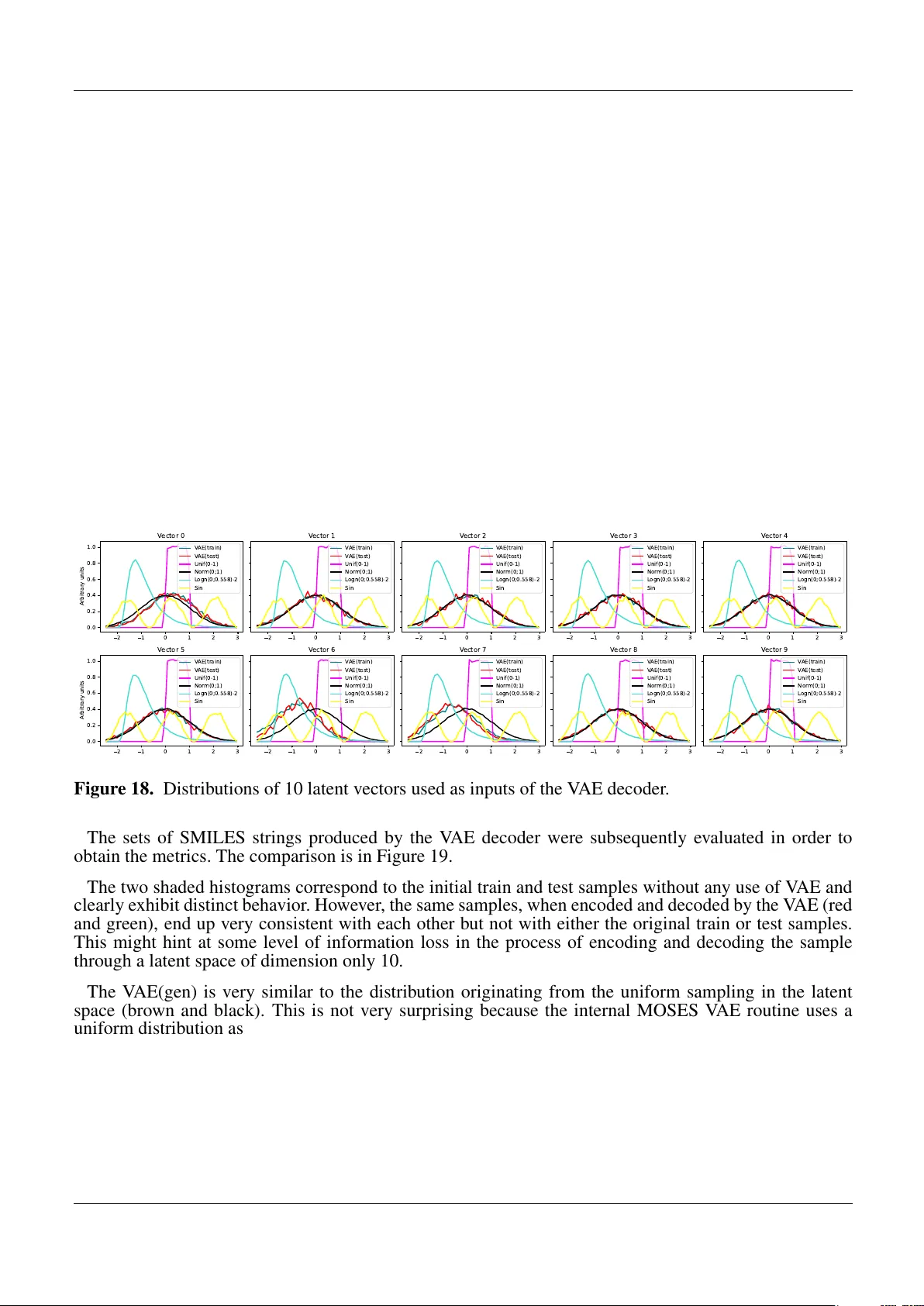
본 논문은 신약 설계 과정에서 인공지능 기반 생성 모델이 직면한 학습 불안정성과 높은 파라미터 요구량을 양자 컴퓨팅으로 완화하고자 한다. 연구팀은 먼저 MOSES 데이터셋(1.9 M SMILES)에서 무작위로 12 000개의 분자를 훈련용, 4 087개를 검증용으로 추출하였다. SMILES 문자열은 RDKit을 통해 분자 특성(분자량, LogP 등)으로 변환된 뒤, 변분 오토인코더(VAE)에 입력된다. VAE는 양방향 GRU와 선형 레이어로 구성돼, 256‑dimensional hidden state를 64‑dimensional 잠재공간으로 압축하고, 역으로 디코더가 잠재벡터를 SMILES 문자열로 복원한다. 이때 VAE는 MOSES 벤치마크에서 기본 설정을 그대로 사용했으며, 드롭아웃은 기본값(0)으로 두었다.
생성 단계에서는 전통적인 GAN 구조를 차용하되, 생성기(generator)를 파라미터화된 양자 회로(PQC)로 교체한다. 회로는 최대 15개의 큐비트를 사용해 여러 레이어로 구성되며, 각 회전 게이트(RY, RZ)마다 독립적인 가우시안 노이즈를 삽입한다. 이러한 ‘노이즈 인코딩’은 스타일 기반(Style‑Based) 아키텍처와 결합돼, 입력 잡음이 네트워크 전 층에 재업로드되는 형태를 만든다. 이는 기존 QGAN이 초기 레이어에만 잡음을 주입하는 한계를 극복하고, 양자 파라미터 공간을 보다 풍부하게 탐색하도록 돕는다.
판별기(discriminator)는 클래식 신경망으로 유지했으며, WGAN‑GP 손실을 적용한다. 구체적으로, 실제 데이터의 잠재벡터와 양자 생성기의 출력 잠재벡터 사이의 Wasserstein 거리를 최소화하고, 판별기의 그래디언트가 1에 가까워지도록 하는 페널티 항을 추가한다. 이 방식은 판별기의 과도한 학습을 억제하고, 생성기가 바레인 플래토에 빠지는 현상을 완화한다.
실험은 두 단계로 진행되었다. 첫 번째는 노이즈 없는 양자 시뮬레이터에서 30 000개의 분자를 샘플링해 MOSES 벤치마크 지표(Internal Diversity, Novelty, Validity, Uniqueness, Molecular Weight, LogP, QED 등)를 평가하였다. 두 번째는 IBM Heron(156‑qubit) 양자 컴퓨터의 5‑qubit 서브셋에서 실제 하드웨어 추론을 수행해 2 500개의 유효한 SMILES를 생성했다. 시뮬레이터 결과는 파라미터 수가 10배 이상 적은 양자 생성기가 기존 클래식 GAN과 동등하거나 일부 지표에서 우수함을 보여준다. 특히 내부 다양성 및 약물 유사도(QED)에서 통계적으로 유의미한 개선이 관찰되었다.
논문의 주요 기여는 다음과 같다. (1) 스타일 기반 양자 GAN에 노이즈 인코딩을 도입해 모드 붕괴를 완화하고, 파라미터 효율성을 높였다. (2) VAE‑ 기반 잠재공간을 활용해 고차원 SMILES 데이터를 양자 회로가 다룰 수 있는 저차원 형태로 변환하였다. (3) 15‑qubit 시뮬레이터와 156‑qubit 실제 하드웨어에서 실험을 수행해 양자 모델의 실용성을 검증하였다. (4) MOSES 벤치마크와 비교해 파라미터 수는 크게 줄이면서도 경쟁력 있는 분자 품질을 달성했다.
한계점으로는 현재 양자 하드웨어의 노이즈와 큐비트 수 제한으로 인해 전체 15‑qubit 회로를 직접 실행하지 못했으며, VAE와 디코더가 여전히 클래식 모델에 의존한다는 점이다. 향후 연구에서는 완전 양자형 인코더‑디코더 파이프라인 구축, 오류 정정 및 노이즈 억제 기술 적용, 그리고 대규모 데이터셋에서의 확장성을 검증하는 것이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기