구조 인식이 리더보드를 뒤집다 CHANRG가 밝힌 RNA 2차 구조 예측의 일반화 한계
CHANRG는 Rfam 15.0에서 10 백만 개 이상의 서열을 구조‑인식 중복제거와 유전체‑인식 분할 설계로 정제해 170 천 개의 비중복 RNA를 구축한 새로운 벤치마크이다. 29개 모델을 평가한 결과, 사전학습 기반 파운데이션 모델은 동일 분포 테스트에서는 최고 성능을 보였지만, 아키텍처, 클랜, 유전체 희소성 등 세 가지 OOD(Out‑of‑Distribution) 상황에서는 성능이 급격히 떨어졌다. 반면 구조 디코더와 직접 신경망 모델…
저자: Zhiyuan Chen, Zhenfeng Deng, Pan Deng
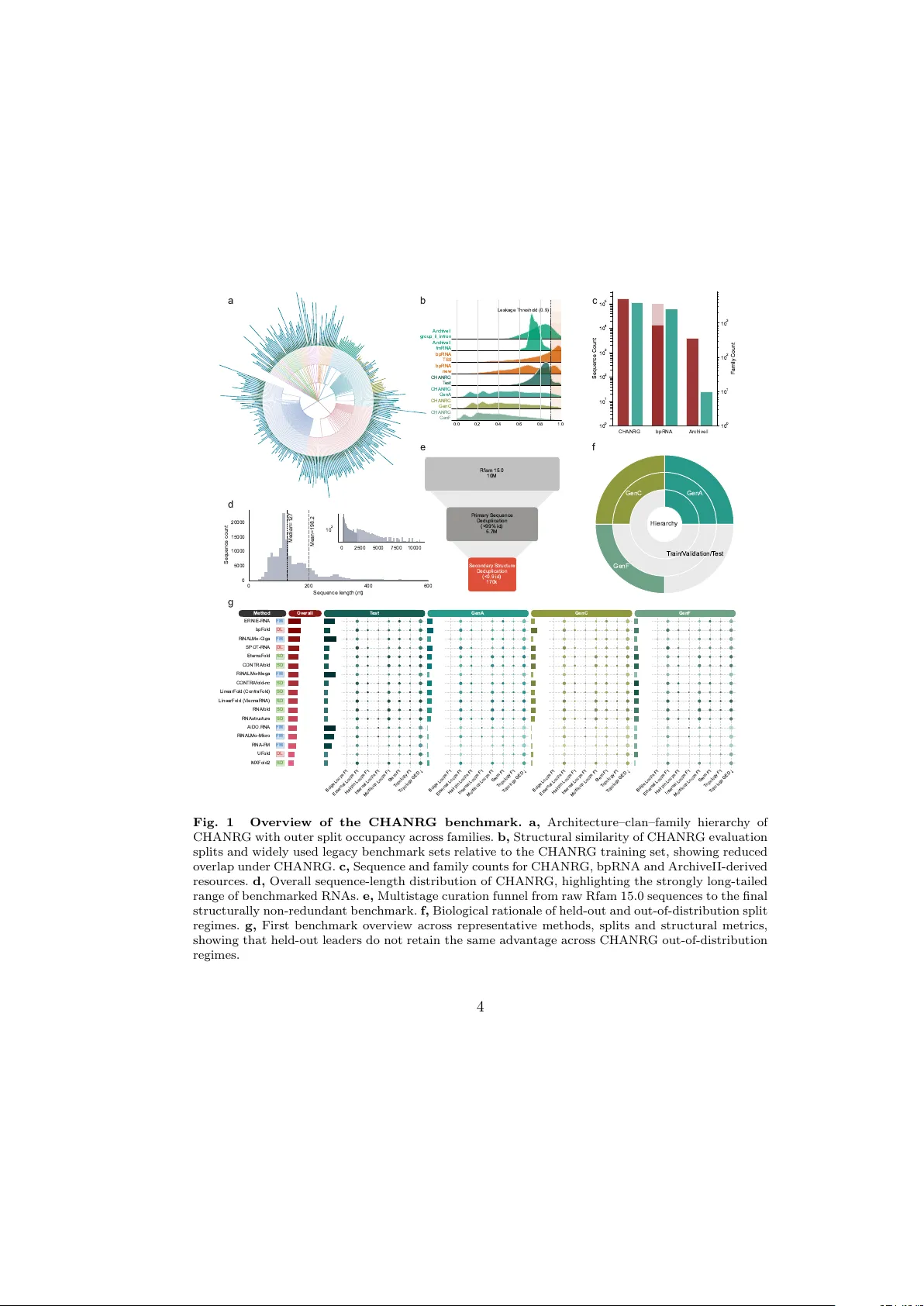
본 연구는 RNA 2차 구조 예측 분야에서 최근 급부상한 딥러닝 및 파운데이션 모델의 일반화 능력을 재평가하기 위해, 기존 벤치마크가 가지고 있던 구조적 중복과 평가 편향을 근본적으로 해결한 새로운 벤치마크 CHANRG(Comprehensive Hierarchical Annotation of Non‑coding RNA Groups)를 제안한다. CHANRG는 Rfam 15.0에서 10 백만 개 이상의 서열을 출발점으로, 99 % 이상의 서열 중복을 먼저 제거하고, 이어서 bpRNA‑CosMoS 기반 구조‑인식 중복제거를 적용해 최종 170 083개의 구조적으로 비중복 RNA를 확보하였다. 이 과정에서 서열이 다르더라도 동일하거나 매우 유사한 이차 구조를 갖는 RNA가 33배 가량 추가로 제거돼, 평가 시 실제 구조적 신선도가 크게 향상되었다.
데이터 분할은 RNA 아키텍처‑클랜‑패밀리 계층을 활용해, 동일 유전체 내에서 학습·평가가 겹치지 않도록 설계되었다. 기본적인 In‑Distribution(IVD) 검증·테스트 셋 외에 세 가지 Out‑of‑Distribution(OOD) 시나리오를 정의했다. GenA는 “complex unclassified” 아키텍처를 포함해 기존 학습에 없던 구조적 복잡성을 테스트하고, GenC는 학습에 포함되지 않은 클랜을 대상으로 진화적 거리에서의 일반화를 측정한다. GenF는 유전체 다양성이 부족한 패밀리를 모아 데이터 양 자체가 제한된 상황에서의 강인성을 평가한다. 이러한 설계는 모델이 단순히 서열 유사도에 의존하는 것이 아니라, 실제 새로운 구조적·진화적 환경에서도 성능을 유지할 수 있는지를 검증한다.
평가 지표는 베이스‑페어 F1, 스템 F1, 토폴로지 F1, 그리고 토폴로지 GED(구조 편집 거리) 등 4단계로 계층화하였다. 베이스‑페어 F1은 전통적인 접촉 예측 정확도를, 스템 F1은 헬릭스 수준의 정확도를, 토폴로지 F1은 멀티루프·교차점 등 고차 구조 연결성을, GED는 전체 구조의 편집 거리를 측정해, 단순히 접촉을 맞추는 것만으로는 드러나지 않는 고차 오류를 포착한다.
29개의 모델을 평가했으며, 모델은 크게 구조 디코더(SD), 직접 신경망(DL), 파운데이션 모델(FM) 세 그룹으로 나뉜다. SD는 전통적인 동역학·통계적 최적화를, DL은 사전학습 없이 순수하게 시퀀스‑투‑구조 변환을, FM은 사전학습된 RNA 언어 모델에 구조 헤드를 결합한다. IVD 테스트에서 FM은 베이스‑페어 F1 0.673으로 최고 성능을 기록했지만, OOD 평균에서는 0.180으로 급락해 유지율이 26 %에 불과했다. 반면 DL은 테스트 0.350→OOD 0.288(82 % 유지), SD는 테스트 0.302→OOD 0.279(92 % 유지)로, 구조 디코더와 직접 신경망이 OOD 상황에서도 견고함을 보였다. 이는 FM이 학습 데이터의 구조적 편향에 과도하게 적합했으며, 새로운 아키텍처·클랜·유전체 환경에 대한 표현력이 부족함을 의미한다.
또한 논문은 가변 길이 입력에 대해 패딩을 제거하고 대칭성을 고려한 연산 그래프를 구현한 “패딩‑프리, 대칭‑인식(reference) 구현”을 제공한다. 이는 기존 벤치마크가 긴 서열에 대해 패딩을 사용해 메모리·연산 비용을 크게 늘리고, 배치 구성이 결과에 영향을 미치는 문제를 해결한다. 실험적으로 패딩‑프리 구현이 메모리 사용량을 크게 절감하고, 배치 의존성을 없앰으로써 재현성을 높였다.
결론적으로 CHANRG는 구조‑인식 중복제거, 계층적 OOD 분할, 다중 스케일 평가라는 세 축을 결합해 RNA 2차 구조 예측 모델의 진정한 일반화 능력을 측정할 수 있는 엄격하고 배치‑불변적인 프레임워크를 제공한다. 파운데이션 모델이 현재 데이터셋에 과적합되는 경향을 보이는 반면, 전통적인 구조 디코더와 직접 신경망은 고차 토폴로지와 새로운 아키텍처에 대해 더 강인한 특성을 보인다. 향후 연구는 파운데이션 모델에 고차 구조 정보를 효과적으로 통합하고, 다양한 진화적·유전체적 환경에서도 일관된 성능을 유지할 수 있는 방법론 개발에 초점을 맞춰야 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기