단일 파라미터로 단백질 생성 방향 제어하기
스톡캐스틱 어텐션 기반 단백질 생성 모델에 한 개의 스칼라 편향을 추가하면, 전체 패밀리 대신 사용자가 지정한 소수의 서브셋을 선호하도록 연속적으로 조정할 수 있다. 이 방법은 재학습이나 구조 변경 없이 작동하며, 서브셋의 기능적 특성(결합, 안정성 등)을 정확히 전달한다. 그러나 PCA 기반 차원 축소가 잔여 수준 변이를 충분히 보존하지 못하면, 내부 에너지 조절과 실제 서열 표현 사이에 ‘보정 격차’가 발생한다. 보정 격차는 Fisher 분…
저자: Jeffrey D. Varner
본 논문은 단백질 서열 생성에 사용되는 Stochastic Attention (SA) 모델에 기능적 서브셋을 강조하는 새로운 조정 메커니즘을 제안한다. 기존 SA는 작은 정렬(수십~수백 개)만으로도 에너지 함수를 정의하고 Langevin dynamics를 통해 새로운 서열을 샘플링한다. 그러나 모든 저장된 서열에 동일한 가중치를 부여하기 때문에, 특정 기능(예: 특정 효소 억제, 특정 리간드 결합)을 가진 서브셋을 별도로 선호하도록 만들 수 없었다.
저자들은 각 서열 k에 양의 multiplicity weight r_k를 할당하고, 어텐션 로짓에 log r_k를 더함으로써 지정된 서브셋의 에너지 우물을 깊게 만든다. 이때 전체 가중치 비율 ρ = r_designated / r_background 하나만 조절하면, ρ = 1이면 기존 SA와 동일하고, ρ를 크게 할수록 샘플링이 지정된 서브셋 쪽으로 편향된다. 이 방법은 모델 구조를 바꾸지 않으며, 추가 학습 없이도 적용 가능하다.
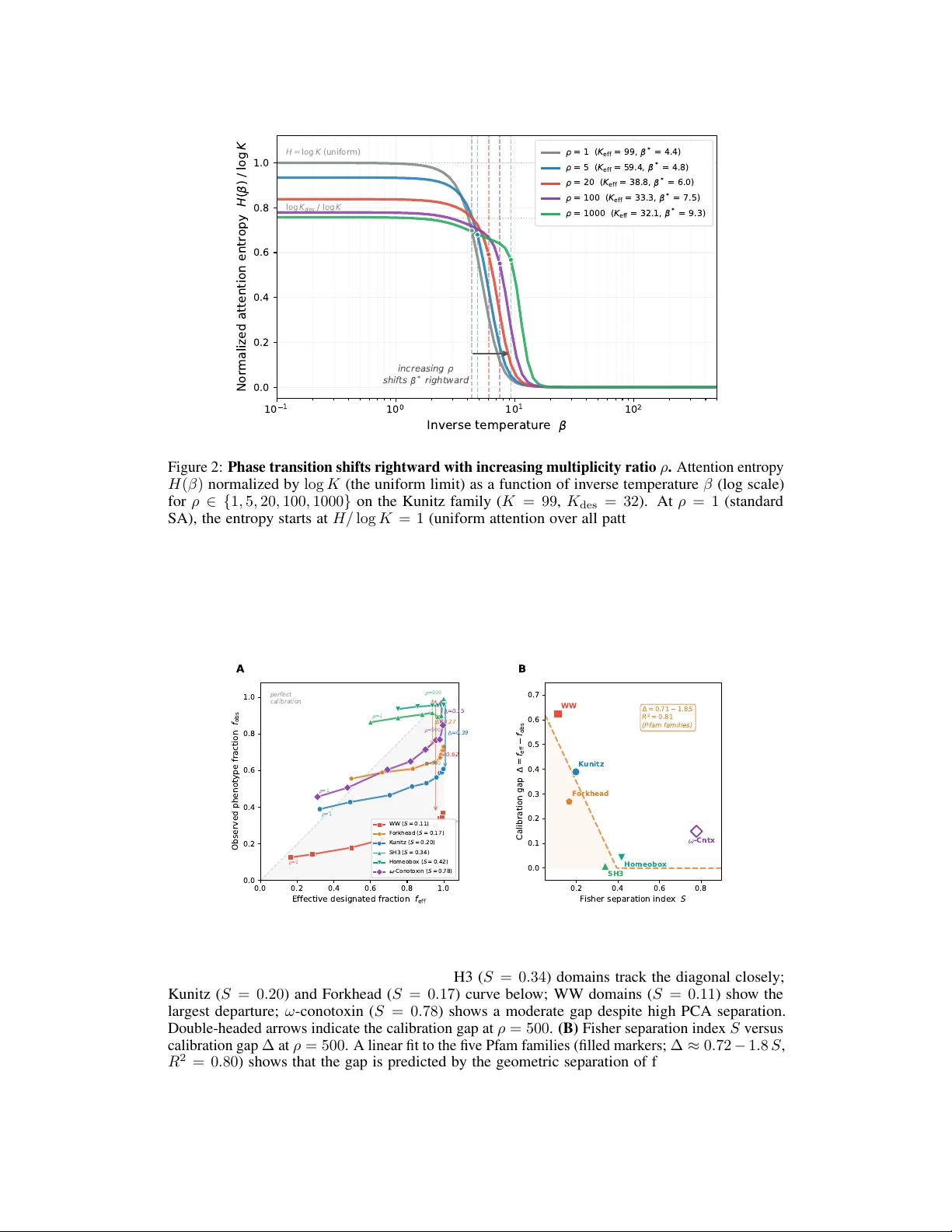
이론적으로, 로그 편향은 소프트맥스 어텐션에 선형적으로 작용해 연산 복잡도 O(dK)를 유지한다. 또한, Proposition 1에 의해 어텐션 평균 ⟨a_des⟩는 ρ에 따라 정확히 목표 비율에 수렴한다. 그러나 실제 디코딩 단계에서 기대한 페노타입 비율 f_obs와 차이가 발생한다. 이는 PCA 기반 차원 축소가 기능을 구분하는 핵심 잔기 변이를 충분히 보존하지 못하기 때문이다. 저자들은 이를 “calibration gap”이라 명명하고, 세 단계(어텐션, 연속 PCA 재구성, 하드 디코딩)에서 각각의 차이를 정량화한다.
보정 격차를 예측하기 위해 Fisher separation index S를 도입한다. S는 PCA 공간에서 지정된 서브셋과 배경 서브셋이 얼마나 잘 구분되는지를 측정한다. 실험 결과, S가 클수록(>0.3) gap이 작아져 거의 완전한 페노타입 전이가 이루어진다. 반대로 S가 작을수록(≈0.1) gap이 크게 나타나며, 이 경우에는 메모리 행렬을 서브셋 전용으로 재구성하는 hard curation이 필요하다.
실험은 다섯 개 Pfam 패밀리(Kunitz, SH3, WW, Homeobox, Forkhead)와 ω‑conotoxin 펩타이드에 대해 수행되었다. 각 패밀리마다 지정된 기능적 마커(예: Kunitz의 P1 잔기, SH3의 트립톤, WW의 루프 잔기 등)를 기준으로 서브셋을 정의하고, ρ를 1부터 1,000까지 변화시키며 30개의 Langevin 체인을 5,000 스텝씩 실행했다.
Kunitz 도메인에서는 ρ = 1,000에서도 어텐션 평균이 99.8%에 도달했지만, 디코딩된 P1 K/R 비율은 최대 63%에 머물렀다. 이는 PCA 차원(d = 80)에서 P1 변이가 충분히 포착되지 않았기 때문이다. Fisher S는 0.20이었으며, 이는 중간 정도의 격차를 설명한다.
다른 패밀리에서는 S가 0.42(홈박스)와 0.34(SH3) 정도로 높아, multiplicity weighting만으로도 95% 이상 페노타입 전이가 이루어졌다. 반면 WW 도메인(S = 0.11)에서는 gap이 0.64로 크게 나타났으며, hard curation을 적용해야만 100% 전이가 가능했다.
또한, ω‑conotoxin O‑superfamily에 대해 두 가지 시드를 사용했다. 전체 패밀리(74개)와 강력한 Cav2.2 바인더(23개)만을 각각 메모리 행렬에 넣고 샘플링했을 때, 강력한 바인더 전용 시드에서는 Tyr13 보존율이 98.3%에 달했으며, 기본 잔기(Lys/Arg) 비율도 입력과 거의 동일하게 유지되었다. 반면 전체 패밀리 시드에서는 Tyr13 보존율이 46.9%에 그쳤다. 이는 지정된 서브셋이 PCA에서 잘 구분될수록 multiplicity weighting이 효과적임을 다시 한 번 확인시킨다.
실용적인 가이드라인도 제시한다. (1) 서브셋이 PCA에서 충분히 분리되지 않을 경우, hard curation을 선택한다. (2) S > 0.3이면 작은 수(3~10개)의 실험적 서열만으로도 수백 개의 다양하고 기능적 후보를 생성할 수 있다. (3) ρ와 온도 파라미터 β/β*를 공동으로 조정하면, 페노타입 보존률과 서열 다양성 사이의 트레이드오프를 미세하게 제어할 수 있다. 예를 들어 Kunitz에서 ρ = 200, β = 3β*로 설정하면 P1 K/R 비율이 0.71까지 상승하지만, 서열 다양성은 0.46으로 감소한다.
결론적으로, 단일 스칼라 파라미터를 어텐션 로짓에 더하는 간단한 조작만으로도, 사전 학습이 필요 없는 SA 모델을 사용해 기능적 서브셋을 효과적으로 강조할 수 있다. 이 방법은 GPU 없이도 노트북 수준의 컴퓨팅 자원으로 실행 가능하며, 실험실에서 소규모 시퀀스 데이터를 기반으로 빠르게 후보 라이브러리를 구축하고자 하는 연구자들에게 매우 유용한 도구가 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기