익명화된 LLM으로 포트폴리오 최적화: 블라인드 트레이드 연구
본 논문은 주식 티커와 기업명을 익명화한 뒤, 네 개의 특화된 LLM 에이전트가 점수와 이유를 출력하도록 설계하고, 이 이유를 임베딩해 그래프 신경망(GNN)으로 연결한 뒤 PPO‑DSR 강화학습 정책으로 포트폴리오를 구성한다. 2025년 연초부터 8월까지의 OOS 기간에서 연간 샤프 비율 1.40 ± 0.22를 달성했으며, 부정 실험과 정보계수(IC) 분석을 통해 신호가 실제 시장 패턴을 반영함을 검증한다.
저자: Joohyoung Jeon, Hongchul Lee
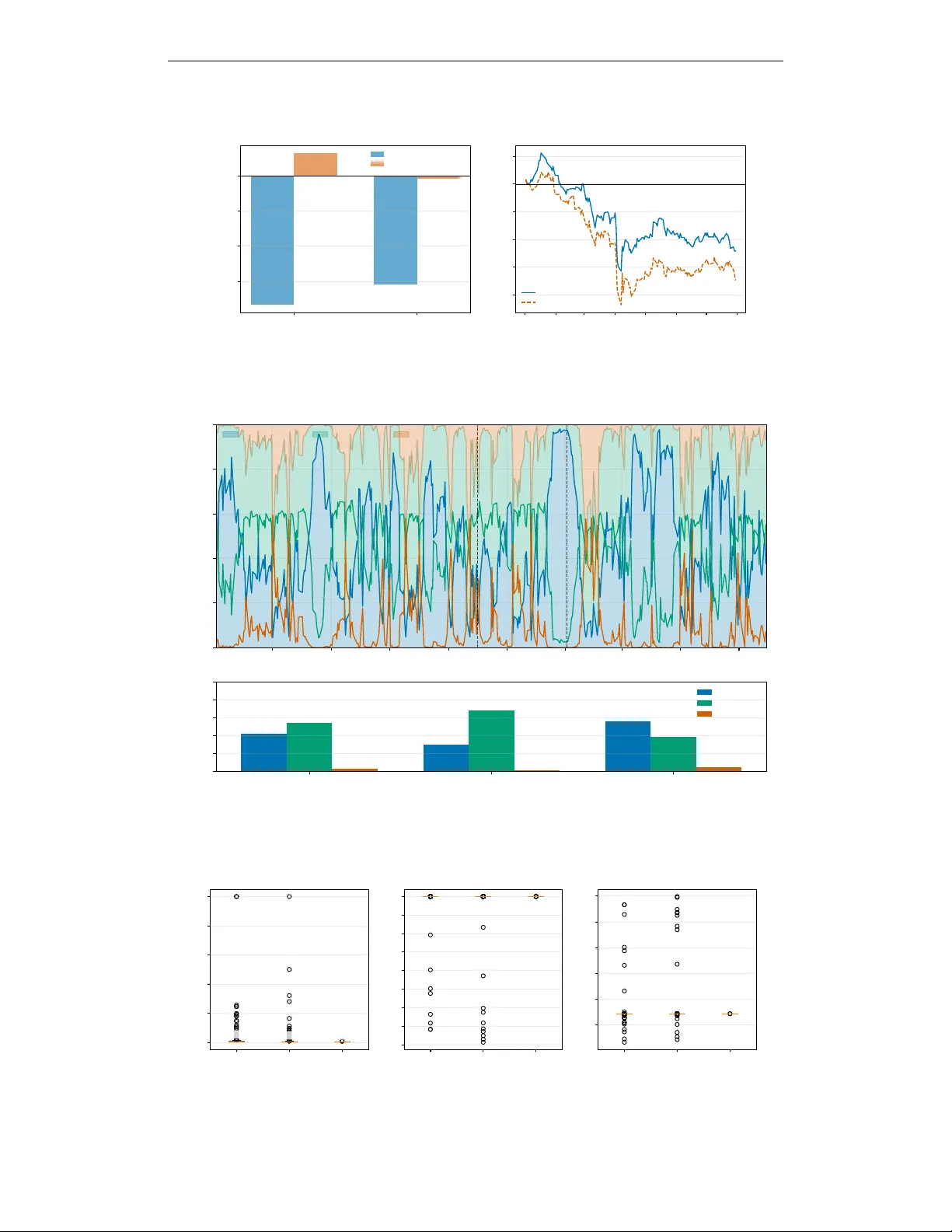
본 논문은 대형 언어 모델(LLM)이 금융 트레이딩에 활용될 때, 사전 학습 단계에서 축적된 티커‑기업 연관 기억이 실제 시장 이해와 혼동되는 문제를 해결하고자 한다. 이를 위해 ‘BlindTrade’라는 프레임워크를 제안한다. 프레임워크는 크게 여섯 단계로 구성된다.
첫 번째 단계는 데이터 익명화이다. 연구진은 매일 S&P 500 구성 종목을 수집하고, 티커·기업명·제품명·인물명 등을 무작위 식별자(예: “STOCK 0026”)와 같은 형태로 대체한다. 또한 뉴스 헤드라인에 등장하는 고유명사도 구글 Knowledge Graph API를 활용해 익명화한다. 이렇게 함으로써 LLM이 사전 학습 데이터에서 “Tesla stock surges”와 같은 문구를 직접 인식해 매수 결정을 내리는 것을 차단한다.
두 번째 단계는 네 개의 특화된 LLM 에이전트를 활용한 피처 생성이다. 각각의 에이전트는 (1) Momentum, (2) News‑Event, (3) Mean‑Reversion, (4) Risk‑Regime이라는 역할을 갖는다. 모든 에이전트는 동일한 시스템 프롬프트를 사용해 60일 이내의 가격·거래량·뉴스·시장 위험 지표만을 입력으로 받으며, 출력은 점수와 함께 이유 텍스트를 JSON 형태로 제공한다. 이유 텍스트는 이후 그래프 구축에 핵심적인 의미론적 정보를 제공한다.
세 번째 단계는 정보계수(IC) 검증이다. 각 에이전트가 산출한 점수와 이유 임베딩을 21일 뒤 수익률과 Spearman rank 상관관계로 측정한다. 결과는 News‑Event와 Risk‑Regime 에이전트가 양의 IC(+0.006, +0.011)를 보이며, Momentum과 Mean‑Reversion은 기존 원시 피처의 부정적 상관을 중화(ΔIC ≈ +0.02)한다는 점을 확인한다. 이는 LLM이 단순 기억이 아니라 실제 예측 가능한 신호를 제공함을 의미한다.
네 번째 단계는 의미론적 그래프 인코더(SemGAT)이다. 동일 섹터 종목은 완전 연결하고, 이유 임베딩 간 코사인 유사도가 0.75 이상인 경우 추가적인 의미론적 엣지를 만든다. 이렇게 구성된 그래프는 2‑계층 GATv2를 통해 128‑차원 노드 임베딩으로 변환된다. 각 노드에 대해 HL‑Gauss 분포 예측(101 빈)과 페어와이즈 랭킹 손실을 동시에 학습함으로써, 다음 날 수익률의 기대값뿐 아니라 불확실성까지 모델링한다.
다섯 번째 단계는 PPO‑DSR 강화학습 정책이다. 정책은 ‘Intent Head’를 통해 전역적인 시장 상태(네 에이전트의 집계 통계 + GNN 마켓 임베딩)를 입력받아 방어(0), 중립(1), 공격(2) 세 가지 모드 중 하나를 선택한다. 선택된 모드에 따라 온도 스케일링을 조정해 포트폴리오 다변화 정도를 제어한다. 주식별 스코어는 Intent와 노드 임베딩을 결합해 산출하고, Dirichlet 평균을 통해 최종 가중치를 결정한다. 액션 공간은 상위 20개 종목으로 제한해 차원을 축소하고, 거래 비용(10 bps)과 재조정 관성을 파라미터 η로 조절한다.
실험은 2020‑01‑02부터 2025‑08‑01까지 1,403일의 데이터를 사용해 훈련(2020‑01‑02 ~ 2024‑09‑30), 검증(2024‑10‑01 ~ 2024‑12‑31), OOS(2025‑01‑02 ~ 2025‑08‑01)로 구분하였다. OOS 기간에 20개 시드 평균 연간 샤프 비율은 1.40 ± 0.22, 누적 수익률은 32.22 ± 5.21%를 기록했으며, 이는 SPY(0.64), EQWL(0.74), 전통적 모멘텀(0.89) 등 모든 벤치마크를 크게 앞선다. 다만 현금 보유를 허용하지 않아 변동성(42.34%)과 최대 손실(MDD ‑31.66%)이 높아 위험 관리 측면에서 한계가 있다.
부정 실험으로는 LLM 피처를 제거하고 순수 원시 기술 지표만 사용했을 때 샤프가 1.40에서 0.96 이하로 급락함을 확인하였다. 또한 라벨 셔플링, 시계열 순서 뒤집기 등으로 신호가 사라지는 것을 보여, 모델이 실제 의미 있는 패턴을 학습했음을 입증한다.
확장 OOS(2024‑2025 전체, 397일) 분석에서는 변동성이 큰 시장 상황에서 정책이 높은 알파를 유지했지만, 상승 추세가 지속되는 bull market에서는 알파가 감소하는 ‘시장 레짐 의존성’이 관찰되었다. 이는 Risk‑Regime 에이전트가 시장 전반 위험을 감지해 모드 전환을 주도하지만, 급격한 트렌드 변화에 대한 적응 속도가 제한적임을 시사한다.
결론적으로, 이 논문은 ‘익명화 → LLM → 의미론적 그래프 → 강화학습’이라는 파이프라인을 통해 LLM이 단순 기억이 아니라 실제 시장 신호를 포착할 수 있음을 실증한다. 향후 연구 과제로는 현금 포지션 도입, 자산군 확대, 실시간 데이터 스트리밍 적용, 그리고 모드 전환 메커니즘의 정교화가 제시된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기