복합표본 설계에서 k최근접이웃 회귀의 일관성
본 논문은 복합표본 설계 하에서 k‑최근접이웃(k‑NN) 회귀 추정기가 일관성을 갖는 조건을 제시하고, 수렴 속도에 대한 하한을 도출한다. 설계 기반(superpopulation) 프레임워크와 표본 설계의 두 가지 무작위성을 모두 고려하여, 기존 i.i.d. 가정 하의 결과를 일반화한다. 시뮬레이션 및 실제 데이터 실험을 통해 이론적 결과를 실증적으로 확인한다.
저자: Caren Hasler
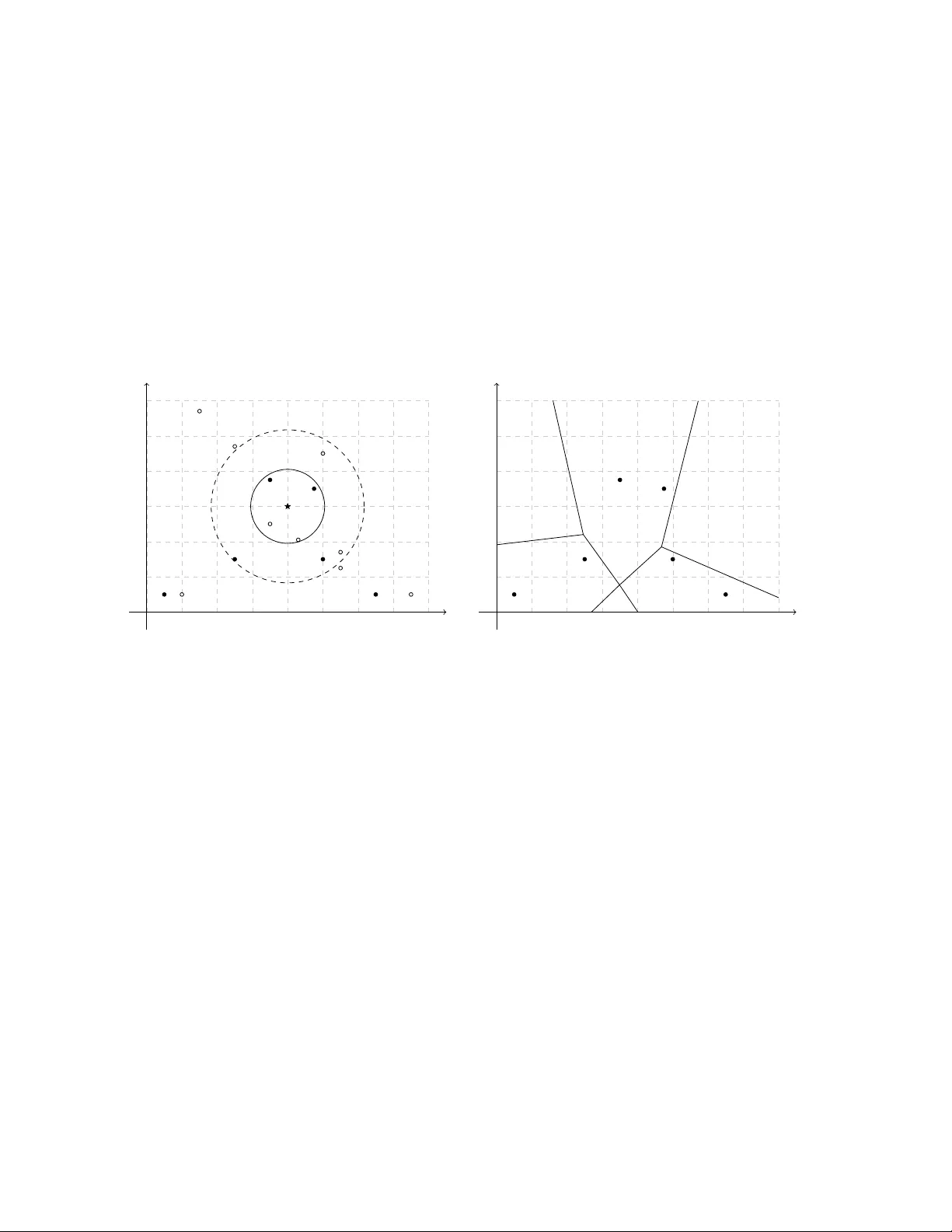
본 논문은 복합표본 설계 하에서 널리 사용되는 비모수 회귀 방법인 k‑최근접이웃(k‑NN) 회귀 추정기의 일관성(consistency)을 이론적으로 검증하고, 수렴 속도에 대한 하한을 제시한다. 전통적인 k‑NN 이론은 데이터가 독립·동일분포(i.i.d.)라는 가정에 기반하지만, 실제 설문·조사 데이터는 복합 설계(비동등 확률, 비복원 추출 등)로 인해 i.i.d. 가정이 깨진다. 따라서 설계 기반(framework)에서의 일관성 결과가 필요하지만, 기존 연구는 1‑NN imputation이나 공간 보간 등 제한된 상황에만 적용돼 왔다.
**1. 연구 배경 및 목적**
저자는 설계 기반 접근법과 초모수(superpopulation) 모델을 동시에 고려한다. 모집단 Uₙ은 유한 크기 Nₙ을 갖고, 각 단위 i는 (X_i, Y_i, Z_i) 라는 삼중벡터를 가진다. (X_i, Y_i) 는 초모수 모델 ξ에 의해 i.i.d. 생성되며, Z_i는 설계 변수다. 표본 Sₙ은 복합 설계 p(·)에 따라 추출되며, 포함확률(π_i, π_{ij})을 통해 설계 정보를 표현한다.
**2. 추정량 정의**
전체 모집단을 이용한 전통적 k‑NN 추정량은
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기