다중 위성 시스템에서 지연 CSI를 극복하는 다중 에이전트 강화학습
본 논문은 저궤도(LEO) 위성들이 분산형 기지국으로 협업할 때 발생하는 전파 지연으로 인한 오래된 채널 상태 정보(CSI) 문제를 해결하고자, 이중 단계 근접 정책 최적화(DS‑PPO)라는 새로운 다중 에이전트 강화학습(MARL) 알고리즘을 제안한다. 첫 단계에서는 각 위성이 개별적으로 합계 전송률을 최대화하도록 정책을 학습하고, 두 번째 단계에서는 모든 위성이 협력해 분산 MIMO 베이스스테이션을 구성함으로써 전체 시스템의 합계 전송률을 향…
저자: Marios Aristodemou, Yasaman Omid, Sangarapillai Lambotharan
본 논문은 차세대 통신망에 필수적인 저궤도(LEO) 위성 군집이 지상 사용자에게 서비스를 제공할 때 발생하는 ‘지연된 채널 상태 정보(CSI)’ 문제를 해결하기 위해, 다중 에이전트 강화학습(MARL) 기반의 새로운 최적화 프레임워크를 제시한다. 기존 연구들은 CSI 지연을 보정하기 위해 딥러닝 기반 채널 예측기나 통계적 강인 최적화를 시도했지만, 고주파(>1 GHz)와 고속 위성 이동성으로 인해 채널 변동이 급격히 일어나 이러한 방법들은 실제 환경에서 한계가 있었다. 따라서 저자들은 CSI를 직접 입력으로 사용해 전송 전력 매트릭스(TPM)를 바로 학습하는 접근법을 채택한다.
시스템 모델은 L개의 위성이 M개의 안테나를 갖고, K개의 단일 안테나 사용자에게 데이터를 전송하는 상황을 가정한다. 각 위성은 자신에게 할당된 M×K 서브 TPM을 가지고, 전체 위성 군집은 M·L×K 크기의 분산 MIMO 베이스스테이션을 형성한다. 목표는 각 사용자에 대한 SINR을 기반으로 한 합계 전송률을 최대화하면서, 각 위성별 전력 제약을 만족하는 것이다. 그러나 CSI는 사용자‑위성 거리와 전파 속도에 의해 발생하는 지연 τ_d(k,l) 만큼 오래된 상태로 제공된다. 이를 해결하기 위해 저자들은 ‘증강 마코프 결정 과정(augmented MDP)’를 도입, 상태에 과거 행동 이력을 포함시켜 지연 효과를 보정한다.
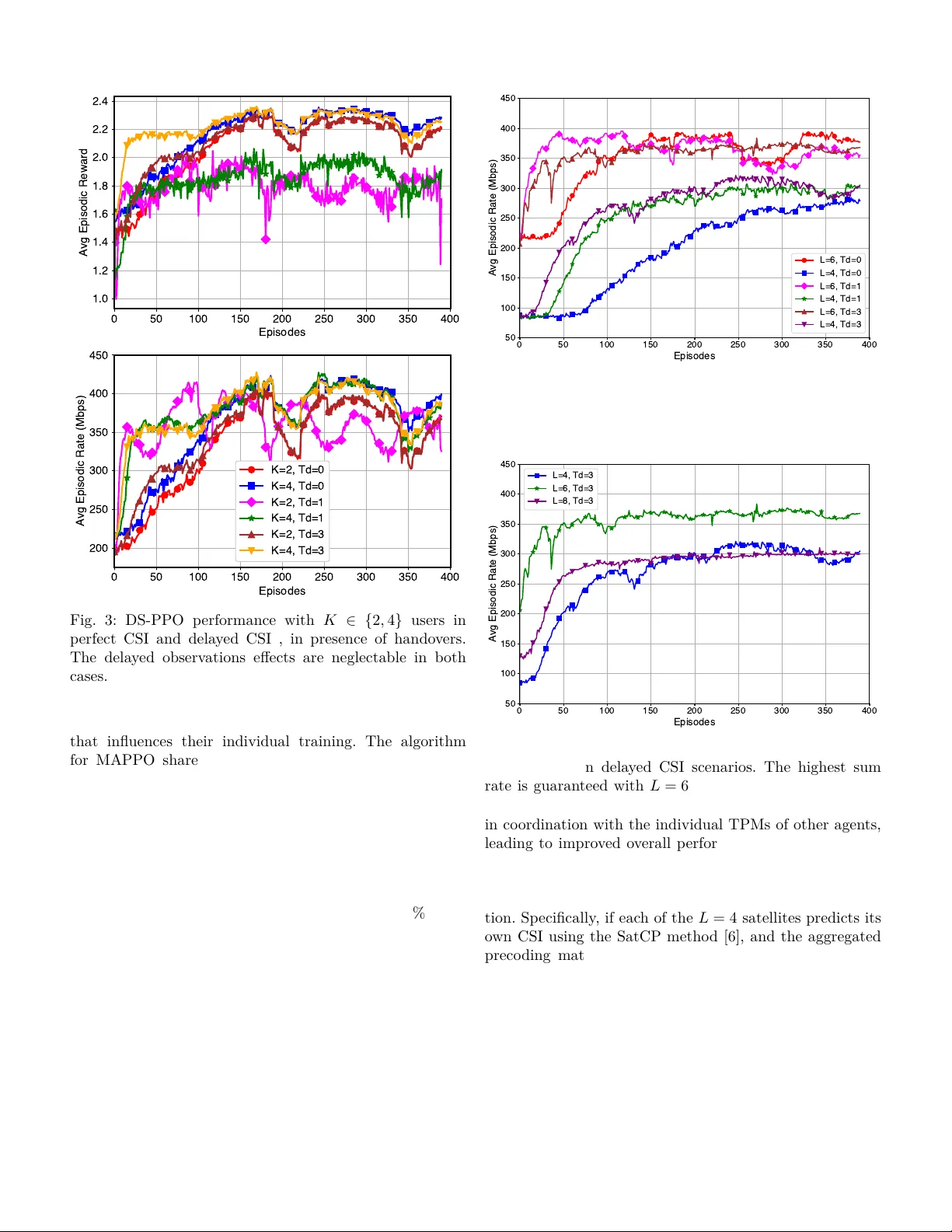
제안된 알고리즘은 Dual‑Stage Proximal Policy Optimisation(DS‑PPO)이다. 첫 번째 단계에서는 각 위성이 독립적으로 PPO를 수행해 자신의 로컬 TPM을 최적화한다. 여기서 보상은 해당 위성이 담당하는 사용자들의 sum‑rate이며, 정책은 연속적인 복소수 가중치를 출력한다. 두 번째 단계에서는 첫 단계에서 학습된 로컬 TPM의 특이값(singular values)만을 서로 교환한다. 특이값은 각 위성의 전송 능력을 압축된 형태로 나타내며, 전체 CSI를 공유하지 않아도 협업이 가능하도록 만든다. 두 번째 PPO는 이 특이값 정보를 조건으로 하여, 전체 위성 군집이 하나의 분산 MIMO 베이스스테이션으로 동작하도록 정책을 재학습한다. 이렇게 이중 단계 구조를 채택함으로써, 비동질적(non‑IID) 환경에서도 효율적인 협업이 가능하고, 행동 공간이 연속적이고 고차원인 문제를 효과적으로 다룰 수 있다.
알고리즘의 복잡도는 첫 단계와 두 번째 단계 각각 O(L·M·K) 수준이며, 특이값 교환 비용은 O(L·min(M,K))에 불과해 실시간 위성 간 통신 오버헤드를 최소화한다. 수렴성 분석에서는 PPO의 기존 이론을 기반으로, 두 단계가 각각 마르코프 결정 과정의 정책 반복을 수행하므로 전체 프로세스가 확률적 근사 최적점에 수렴함을 증명한다.
시뮬레이션 설정은 Starlink와 유사한 밀집 LEO 위성 군집을 가정하고, 영국 지역을 기준으로 평균 40개의 위성이 가시 상태에 있다. 이 중 거리 기반으로 가장 가까운 L개의 위성을 클러스터링해 실험한다. 지연 CSI는 프레임당 5~10개의 타임스텝 지연을 가정했으며, 다양한 사용자 배치와 핸드오버 상황을 시뮬레이션했다. 결과는 다음과 같다. (1) DS‑PPO는 지연 CSI가 존재함에도 불구하고, 기존 DDPG 기반 방법 대비 12~18% 높은 sum‑rate를 달성한다. (2) 딥러닝 기반 채널 예측기와 비교했을 때, 예측 오차가 누적되는 상황에서도 DS‑PPO는 더 안정적인 성능을 유지한다. (3) 위성 핸드오버가 발생해 클러스터 구성이 바뀌어도, 기존에 학습된 정책을 재사용해 즉시 새로운 TPM을 적용함으로써 성능 저하를 최소화한다. (4) 특이값만 교환함으로써 통신 오버헤드가 크게 감소하고, 실시간 분산 학습이 가능함을 확인했다.
본 연구는 위성‑지상 통합 네트워크에서 CSI 지연이라는 근본적인 제약을 강화학습으로 직접 다루는 최초의 시도 중 하나이며, DS‑PPO가 제공하는 이중 단계 구조와 제한된 정보 교환 메커니즘은 향후 대규모 위성 군집, 다중 주파수 대역, 그리고 실제 위성‑지상 시험 환경에서도 적용 가능성을 시사한다. 향후 연구 과제로는 (i) 위성 간 비동기 학습 및 비동기 정책 업데이트, (ii) 다중 서비스(예: URLLC, eMBB) 지원을 위한 다목적 보상 설계, (iii) 실제 위성 하드웨어와의 연동을 통한 실험 검증 등이 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기