근사 HJB와 제어 장벽 함수로 구현하는 비선형 시스템의 제한 최적 피드백 제어
본 논문은 입력‑affine 비선형 시스템에 대해, 오프라인에서 근사 HJB 방정식을 풀어 얻은 가치함수를 활용하고, 온라인에서는 제어 장벽 함수(CBF)를 이용해 안전 제약을 만족시키는 2단계 피드백 제어 프레임워크를 제안한다. 제안 방법은 성능 최적화와 제약 강제화를 완전히 분리하여, 제약이 변경되더라도 가치함수를 재계산할 필요가 없으며, 선형 2‑state 호버크래프트와 비선형 9‑state 우주선 자세 제어 실험을 통해 거의 최적에 근접…
저자: Milad Alipour Shahraki, Laurent Lessard
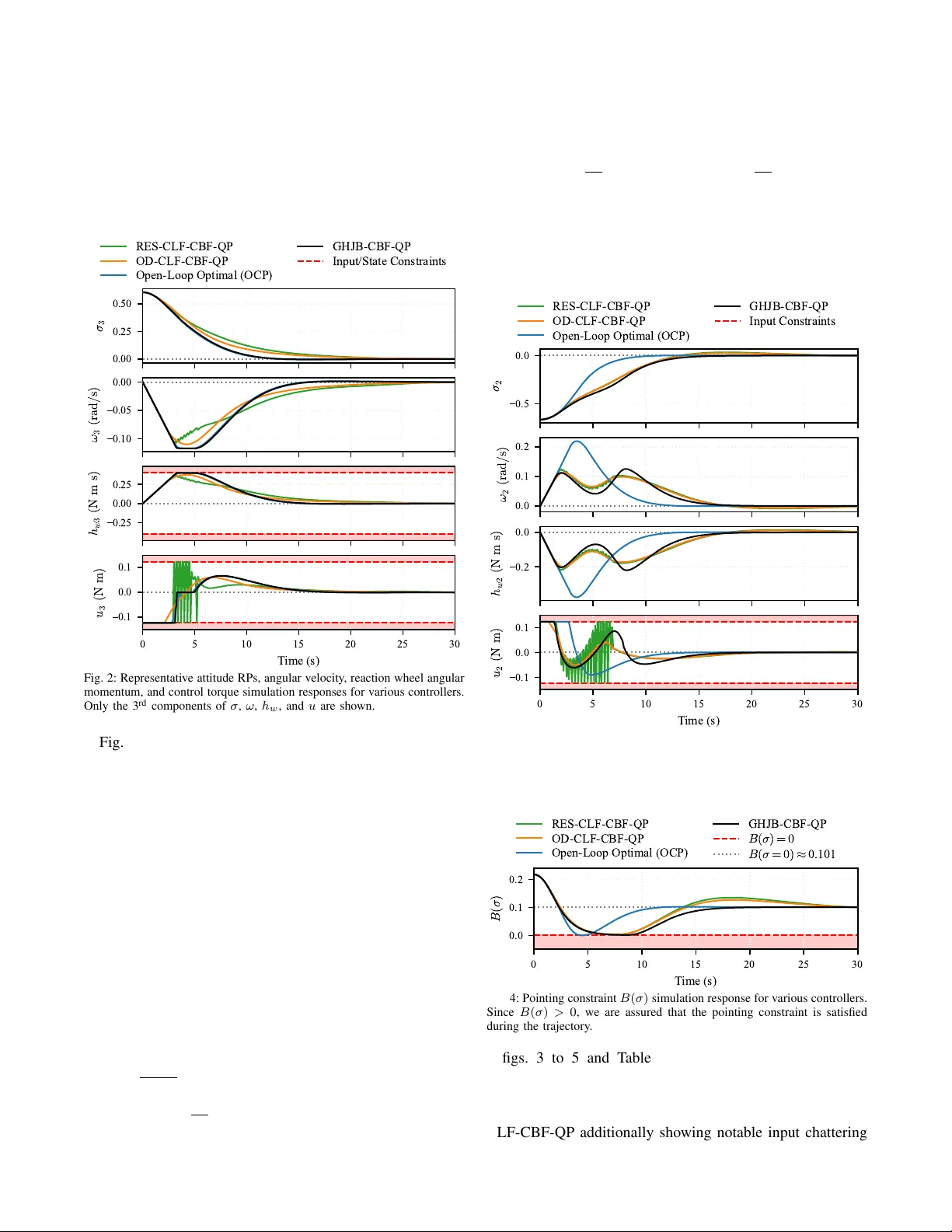
본 논문은 입력‑affine 비선형 시스템 \(\dot x = f(x)+g(x)u\) 에 대해, 최적 피드백 제어와 안전 제약을 동시에 만족시키는 새로운 두 단계 프레임워크를 제안한다. 첫 번째 단계는 제약이 없는 무한‑시간 최적 제어 문제를 풀어 근사 가치함수 \(\hat V(x)\) 를 얻는 과정이다. 저자는 일반화 HJB(GHJB) 방정식을 이용해 정책 반복(policy iteration) 방식을 적용한다. 구체적으로, 선형 시스템에는 Successive Galerkin Approximation(SGA)을 사용해 다항식 기반의 선형 방정식 집합을 풀어 근사값을 구하고, 비선형 시스템에는 Sum‑of‑Squares(SOS) 프로그래밍을 통해 비선형 부정성 조건을 반감형 제약으로 변환한다. 이 과정은 오프라인에서 수행되며, 근사 가치함수의 정확도 \(\Delta_{\text{approx}}\) 가 최종 제어 성능에 직접적인 영향을 미친다.
두 번째 단계는 온라인 제어기로, 앞서 얻은 \(\hat V\) 의 그래디언트를 사용해 근사 Hamiltonian \(J_{\text{GHJB}}(u)=\nabla\hat V^\top g(x)u+u^\top Ru\) 를 최소화한다. 여기서 제약은 제어 장벽 함수(CBF)와 고차 CBF(HOCBF)를 통해 선형 부등식 형태로 QP에 삽입된다. CBF는 상태 제약 \(h_i(x)\le0\) 와 입력 구간 \(u_{\min}\le u\le u_{\max}\) 을 실시간으로 강제한다. Theorem 2에 따라, CBF가 만족되는 한 안전 집합은 전방 불변성을 유지하므로, 가치함수의 정확도와 무관하게 안전이 보장된다.
핵심 이론적 결과는 다음과 같다. (1) Proposition 1은 제약이 비활성화된 경우 QP 해가 오프라인에서 얻은 근사 최적 정책 \(u=-\frac12R^{-1}g^\top\nabla\hat V\) 와 동일함을 증명한다. (2) Proposition 2는 제약이 존재하더라도 안전성은 가치함수와 독립적으로 보장되며, 가치함수가 \(V^*\) 에 수렴하면 제약이 없는 경우와 동일한 최적 성능을 회복한다는 ‘Safety‑Performance Decoupling’을 제시한다. (3) Proposition 3은 적분형 상태 제약(예: \(\dot x_i=g_i(x)u\) 형)에서는 CBF 보수성 \(\Delta_{\text{CBF}}\) 가 0에 수렴함을 보이며, 이는 CBF 파라미터 \(\alpha\) 를 충분히 크게 잡으면 실제 제약과 동일하게 동작함을 의미한다.
전체 서브옵티멀리티는 \(\Delta_{\text{approx}}+\Delta_{\text{proj}}+\Delta_{\text{CBF}}\) 로 분해된다. \(\Delta_{\text{approx}}\) 는 가치함수 근사의 정확도, \(\Delta_{\text{proj}}\) 는 제약이 활성화될 때 무제한 정책을 안전 집합에 투사하면서 발생하는 손실, \(\Delta_{\text{CBF}}\) 는 CBF 자체의 보수성이다. 각각은 별도로 개선 가능하며, 특히 \(\Delta_{\text{CBF}}\) 는 적분형 제약에서는 사라진다.
실험에서는 두 가지 사례를 다룬다. 첫 번째는 1‑D 호버크래프트(선형 2‑state)로, 상태 제약은 속도 제한이며, 속도는 입력에 직접 연결된 적분형이다. SGA를 이용해 \(\hat V\) 를 4번의 정책 반복 후 0.4 초 만에 얻었으며, α=10, 입력·속도 제한을 적용한 CBF‑QP는 제한 LQR, MPC, 직접 최적화(OCP)와 거의 동일한 궤적과 비용을 기록했다. 두 번째는 9‑state 우주선 자세 제어로, 비선형 다항식 시스템이며, 두 종류의 제약(상대 차수 1과 2)을 적용했다. SOS 기반 정책 반복을 통해 근사 가치함수를 얻었고, GHJB‑CBF‑QP는 기존 CLF‑CBF‑QP(Optimal‑Decay, RES) 대비 10‑15 % 낮은 비용을 달성했으며, 제약이 바뀌어도 오프라인 가치함수를 재계산할 필요가 없었다. 특히 고차 제약이 포함된 경우에도 CBF 보수성은 제한적이었으며, α를 적절히 조정하면 실질적인 보수성을 최소화할 수 있었다.
결론적으로, 이 연구는 ‘성능 최적화와 안전 제약을 완전히 분리’하는 새로운 설계 패러다임을 제시한다. 오프라인에서 고품질 근사 가치함수를 얻고, 온라인에서는 간단한 QP와 CBF만으로 실시간 안전을 보장한다. 이는 제약이 자주 변하거나 고차 비선형 시스템에 적용할 때 특히 유리하며, 기존 CLF‑CBF 기반 방법이 안고 있던 감쇠 함수 설계, 슬랙 변수 도입, 입력 진동 문제 등을 근본적으로 해소한다. 향후 연구는 더 높은 차원의 시스템에 대한 확장, 학습 기반 가치함수 근사와의 결합, 그리고 적응형 CBF 파라미터 튜닝 등을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기