테스트 시점 적응을 위한 다중샷 프롬프트 활용 장점과 한계
본 논문은 테스트 시점에 파라미터를 변경하지 않고 LLM의 행동을 조정하는 방법으로 많은 수의 인‑컨텍스트 예시(다중샷 프롬프트)를 활용한다. 다양한 작업과 모델 크기에 대해 실험한 결과, 구조화된 태스크에서는 성능이 크게 향상되지만, 예시 선택 방식·순서·양에 따라 민감하게 변동한다. 동적 ICL과 강화 ICL 같은 대안적 업데이트 전략도 비교했으며, 이들은 초기에는 빠른 이득을 제공하지만 과도한 양은 오히려 성능을 저하시킨다. 결론적으로, …
저자: Shubhangi Upasani, Chen Wu, Jay Rainton
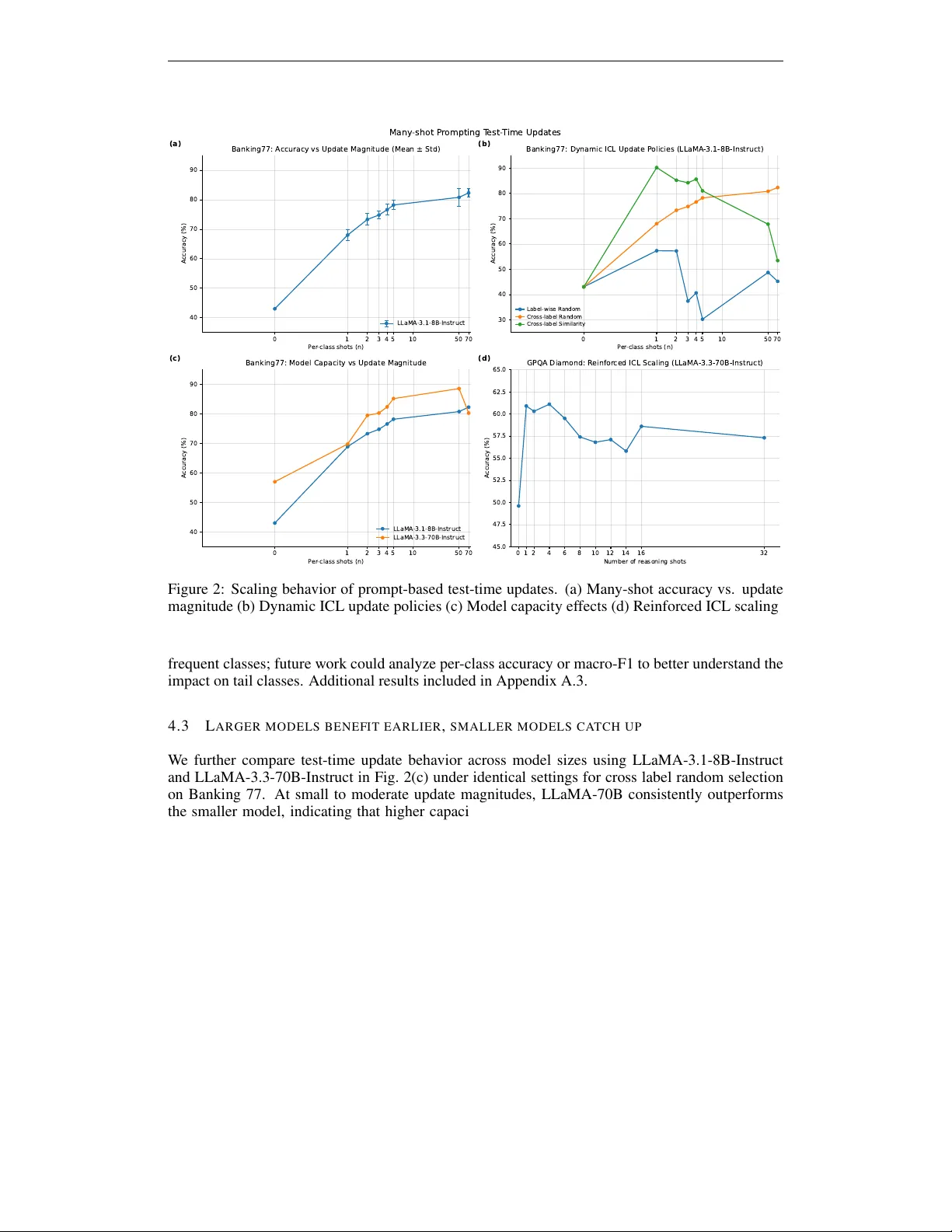
본 논문은 파라미터를 변경하지 않고 테스트 시점에 대형 언어 모델(LLM)의 행동을 조정하는 방법으로 ‘다중샷 프롬프트(many‑shot prompting)’를 체계적으로 분석한다. 기존 연구에서는 few‑shot 인‑컨텍스트 학습(ICL)이 제한된 컨텍스트 길이 때문에 성능 향상이 제한적이었다. 그러나 최신 롱‑컨텍스트 아키텍처(LLaMA‑3.1‑8B‑Instruct, LLaMA‑3.3‑70B‑Instruct 등)의 등장으로 수백에서 수천 개의 예시를 한 번에 삽입할 수 있게 되었으며, 이를 ‘업데이트 규모(update magnitude)’라는 변수로 정의한다.
**실험 설계**
- **데이터**: Banking77(77개 클래스 의도 분류)와 Evaluation Harness(추론, 정보 추출, QA, 기계 번역 등) 전반에 걸친 벤치마크를 사용하였다.
- **모델**: 파라미터 규모가 다른 두 가지 instruction‑tuned LLaMA 모델(8B와 70B)로 실험하였다.
- **프롬프트 구성**: 클래스당 n개의 샷을 제공해 총 N = n × C개의 예시를 삽입한다. 예시 순서, 템플릿, 지시문 형식 등을 다양하게 변형한다.
**주요 결과**
1. **업데이트 규모와 포화**
- 8B 모델은 클래스당 약 50~70개의 예시가 들어가면 정확도가 정체되는 포화 현상을 보였다. 이는 어텐션 메커니즘이 충분히 대표적인 패턴을 포착하면 추가 예시는 중복 정보가 되어 신호‑대‑노이즈 비율이 감소하기 때문이다.
- 70B 모델은 중간 규모(N≈300)에서는 8B보다 월등히 높은 정확도를 기록했지만, 매우 큰 N에서는 오버‑컨디셔닝으로 성능이 떨어졌다.
2. **예시 순서와 프롬프트 구조의 민감도**
- 동일한 n‑shot 설정을 10가지 무작위 순서로 반복했을 때 정확도 변동폭이 2~3%에 달했다. 이는 포지셔널 인코딩과 컨텍스트 내 상호작용이 순서에 크게 의존한다는 점을 시사한다. 평균화로 변동을 완화할 수 있지만, 실제 서비스에서는 순서 최적화가 필요하다.
3. **업데이트 정책(Selection Policy)의 영향**
- **라벨‑와이즈 vs. 크로스‑라벨**: 라벨‑와이즈는 각 클래스에 동일한 수의 예시를 강제해 다양성을 억제하고, 정보가 적은 예시가 과다하게 포함되는 부작용이 있다. 반면 크로스‑라벨은 전체 데이터에서 N개의 예시를 골라 클래스 불균형을 허용함으로써 더 높은 정확도를 달성했다.
- **무작위 vs. 유사도 기반**: 작은 N에서는 유사도 기반 선택이 높은 관련성으로 초기 이득을 제공하지만, N이 커지면 중복이 늘어나 성능이 감소한다. 무작위 선택은 다양성을 확보해 큰 N에서도 비교적 안정적인 성장세를 보인다.
4. **동적 ICL(Dynamic ICL)과 강화 ICL(Reinforced ICL)**
- 동적 ICL은 쿼리마다 유사도 기반 혹은 무작위로 예시를 선택해 컨텍스트를 구성한다. 실험에서는 크로스‑라벨 무작위 선택이 가장 안정적인 적응을 보여준다.
- 강화 ICL은 체인‑오브‑생각(CoT) 형태의 추론 트레이스를 예시로 제공한다. GPQA Diamond 데이터에서 4개의 CoT 예시까지는 급격히 정확도가 상승했지만, 그 이후에는 포화·감소가 나타났다. 이는 긴 추론 텍스트가 어텐션을 분산시켜 개별 샷의 효과가 희석되기 때문이다.
5. **작업 유형별 효과**
- **구조화된 작업(의도 분류, 정보 추출, 제한된 선택형 QA 등)**: 다중샷 프롬프트가 큰 이득을 제공한다. 특히 구조가 명확하고 정답 형태가 제한된 경우, 소수의 예시만으로도 성능을 크게 끌어올릴 수 있다.
- **복합 추론 작업(ARC‑Challenge, GSM8K)**: 초기 몇 개의 예시로 급격히 성능이 상승하고 이후 포화한다. 이는 모델이 작업 규칙을 빠르게 학습한다는 뜻이다.
- **개방형 생성 작업(기계 번역 등)**: 사전 학습 단계에서 이미 충분히 학습된 구조를 가지고 있어, 추가 컨텍스트는 미세한 개선만을 제공한다.
**결론 및 시사점**
- 다중샷 프롬프트는 ‘업데이트 규모’, ‘선택 정책’, ‘구조(코드/CoT 등)’가 상호작용하는 복합 시스템이며, 적절한 규모와 다양성을 확보한 크로스‑라벨 무작위 선택이 대부분의 구조화된 작업에 최적이다.
- 대형 모델은 중간 규모에서 이점을 살리지만, 과도한 컨텍스트는 오히려 해를 끼친다. 따라서 모델 용량에 맞는 프롬프트 길이 조절이 필요하다.
- 강화 ICL은 고품질 소수의 추론 예시가 핵심이며, 무분별한 확대는 비효율적이다.
- 개방형 생성 작업에서는 프롬프트 기반 테스트‑타임 어댑테이션의 기대 효과가 제한적이므로, 다른 적응 기법(예: 파라미터‑레벨 LoRA 등)과 병행하는 것이 바람직하다.
이러한 발견은 LLM을 실제 서비스에 적용할 때, “얼마나 많은 예시를, 어떤 방식으로, 어떤 모델에” 삽입할지에 대한 구체적인 설계 가이드를 제공한다. 향후 연구에서는 다양한 도메인·언어·데이터 규모에 대한 일반화 검증과, 자동화된 예시 선택/정렬 알고리즘 개발이 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기