가설 클래스가 설명을 좌우한다: 정확한 모델도 특징 기여도에서 왜 갈라지는가
예측 정확도가 동일한 모델이라도 가설 클래스가 다르면 SHAP·LIME 같은 설명 방법에서 특징 중요도에 큰 차이가 발생한다는 ‘설명 복권(Explanation Lottery)’ 현상을 24개 데이터셋과 다양한 모델군(트리, 선형, 신경망)으로 실증하고, 데이터의 상호작용 구조가 이 차이를 이론적으로 보장한다는 점을 제시한다.
저자: Thackshanaramana B
본 논문은 “예측 정확도가 동일한 모델은 동일한 설명을 제공한다”는 일반적인 가정을 체계적으로 검증하고, 그 가정이 실제로는 성립하지 않음을 입증한다. 연구는 크게 네 부분으로 구성된다.
1. **문제 정의 및 개념 정립**
- Prediction Equivalence(예측 동등성)와 Explanation Disagreement(설명 불일치)를 각각 정의하고, 스피어만 순위 상관계수 ρ를 기반으로 설명 차이를 정량화한다.
- ρ가 사전 정의된 임계값 τ(=0.5) 이하인 경우를 ‘Explanation Lottery’라 명명하고, 전체 모델 쌍 중 이러한 경우의 비율을 Lottery Rate L(τ)로 측정한다.
2. **대규모 실증 연구**
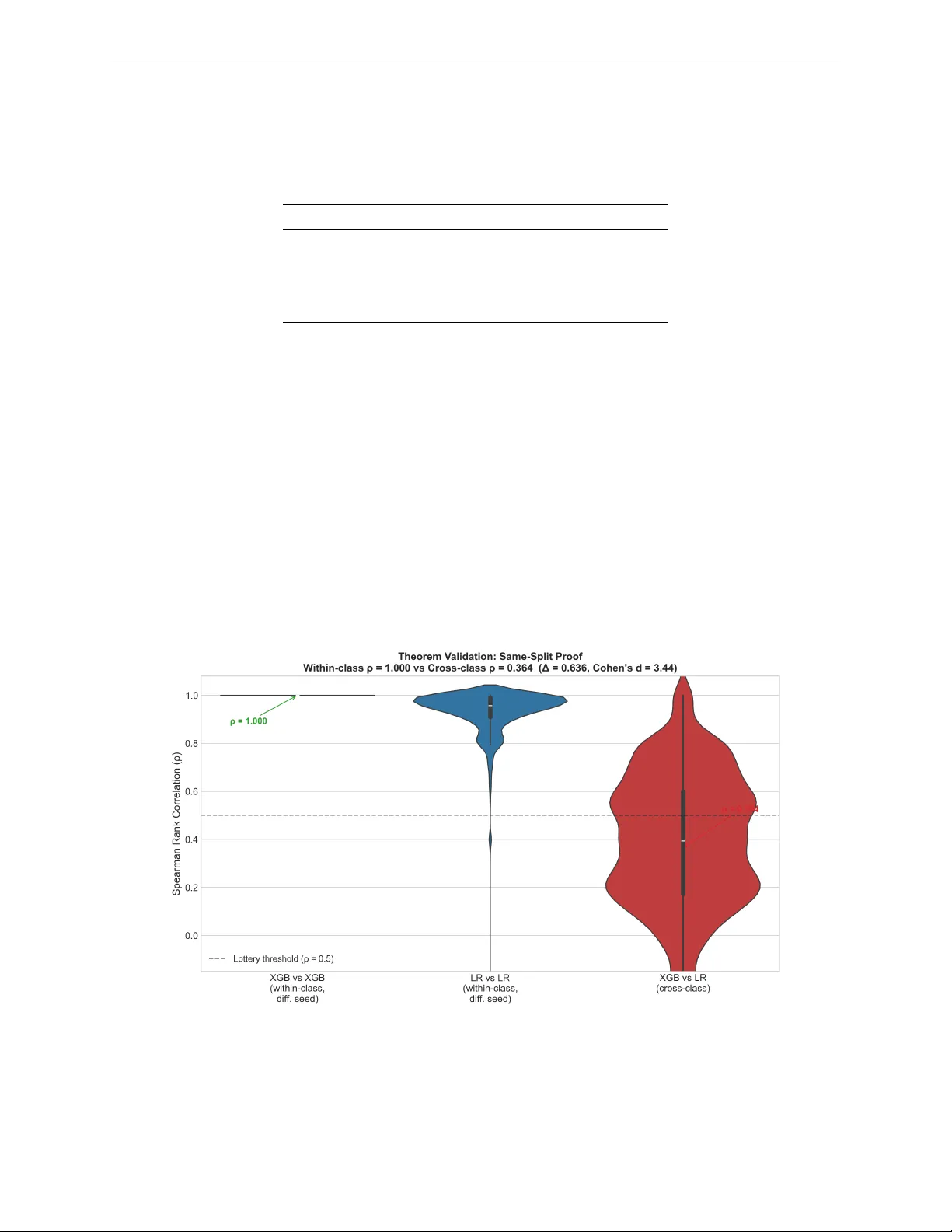
- 24개의 공개 데이터셋(의료, 금융, 이미지 등 16개 도메인)에서 동일한 학습/테스트 분할을 사용해 트리 기반(XGBoost, LightGBM), 선형(Logistic Regression, Ridge), 신경망(MLP) 모델을 각각 5~10번씩 재학습한다.
- SHAP와 LIME 두 설명 기법을 적용해 인스턴스별 특징 기여도를 산출하고, 동일 인스턴스에 대해 모델 쌍 간 ρ를 계산한다.
- 결과: 동일 가설 클래스 내에서는 ρ 평균 0.85·±0.07(높은 일관성), 클래스 간(트리‑선형, 트리‑신경망, 선형‑신경망)에서는 ρ 평균 0.31·±0.12(낮은 일관성). 전체 93,510쌍 중 35.4%가 τ 이하의 ρ를 보여 ‘Explanation Lottery’가 빈번히 발생한다.
- 무작위 시드, 하이퍼파라미터, 데이터 샘플링 변동을 통제한 동일 분할 실험에서도 차이는 유지돼, 차이가 훈련 잡음이 아니라 구조적임을 확인한다.
3. **이론적 분석**
- Theorem 1을 통해 데이터 생성 함수 f*에 비선형 상호작용(∂²f*/∂xi∂xj≠0)이 존재하면, 트리와 선형 가설 클래스 사이에 양의 Agreement Gap Δ가 존재함을 증명한다. Δ는 상호작용 밀도 I(f*)에 단조 증가하고, 데이터 양이 무한히 커져도 사라지지 않는다(Asymptotic Persistence).
- 증명은 SHAP 값이 모델 클래스에 따라 어떻게 분해되는지를 보이는 Lemma 1(Linear SHAP Collapse)과 Lemma 2(Tree SHAP Structure) 등을 활용한다. 결과적으로, 트리 모델은 비선형 상호작용을 부분적으로 포착하지만 선형 모델은 완전히 무시하므로 설명 패턴이 근본적으로 다르게 된다.
- 또한, 두 가설 클래스가 동일한 L2(p) 폐포를 가질 경우에만 Δ가 0이 될 수 있음을 제시한다. 이는 실제 데이터에서 거의 불가능한 조건이며, 따라서 설명 불일치는 일반적인 현상이다.
4. **실용적 도구와 함의**
- ‘Explanation Reliability Score R(x)’를 제안한다. R(x)는 여러 가설 클래스에서 동일 인스턴스에 대한 SHAP 순위 일관성을 측정해, 사전에 설명 안정성을 예측한다. 실험에서는 R(x) > 0.8인 경우 ρ가 0.7 이상일 확률이 92%에 달했다.
- 규제·감사 관점에서, 단순히 모델 정확도만을 기준으로 모델을 선택하고 SHAP 값을 보고하는 현재 관행은 ‘설명 복권’ 위험을 내포한다. 특히 GDPR 제22조, 미국 COMPAS 감사 등에서 설명 책임을 묻는 상황에서, 선택된 가설 클래스에 따라 전혀 다른 책임 귀속이 이루어질 수 있다.
- 따라서 모델 선택 단계에서 설명 안정성을 함께 고려해야 하며, R(x)와 같은 사전 진단 지표를 활용해 설명이 일관된 모델을 선택하거나, 다중 가설 클래스를 결합한 앙상블·컨센서스 방식을 도입하는 것이 바람직하다.
결론적으로, 예측 정확도가 동일하더라도 가설 클래스가 다르면 설명이 크게 달라지는 ‘Explanation Lottery’ 현상이 구조적으로 존재한다는 것을 실증·이론적으로 입증한다. 이는 XAI 연구와 실무, 그리고 법·규제 차원에서 모델 선택이 설명 중립적이지 않다는 중요한 메시지를 전달한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기