인과‑잔차 부트스트래핑을 통한 데이터 증강
본 논문은 인과 구조와 독립 메커니즘 원리를 활용해 잔차를 재배열함으로써 데이터를 증강하는 “Causal‑Residual Bootstrapping(CRB)” 방법을 제안한다. 선형‑가우시안 SCM에서 이론적 이득을 증명하고, 비선형·비가우시안 상황에서도 실험적으로 회귀 성능과 인과 발견 정확도를 향상시킨다.
저자: Mateusz Gajewski, Sophia Xiao, Bijan Mazaheri
본 논문은 “Causal‑Residual Bootstrapping”(CRB)이라는 새로운 데이터 증강 기법을 제안한다. 기존 연구인 Teshima와 Sugiyama(2021)는 조건부 독립성을 이용해 변수 간 값을 자유롭게 섞어 데이터 양을 늘리는 방법을 제시했지만, 두 가지 주요 한계가 있었다. 첫째, 밀도 추정에 의존해 커널 반경 등 하이퍼파라미터를 튜닝해야 했으며, 이는 불안정성을 초래한다. 둘째, 조건부 독립성만을 활용했기 때문에 인과 방향, 즉 DAG 전체 구조를 활용하지 못했다.
저자들은 인과 구조와 독립 메커니즘 원리를 결합해 이러한 문제를 해결한다. 구조적 인과 모델을 SCM(Structural Causal Model) 형태로 가정하고, 각 변수 V_i는 V_i = f_i(PA(V_i)) + ε_i 로 표현한다. 여기서 PA(V_i)는 V_i의 직접 원인 집합이며, ε_i는 독립적인 외생 노이즈이다. 독립 메커니즘 원리에 따르면, 원인 X와 결과 Y 사이의 메커니즘 P(Y|X)는 X의 분포 P(X)와 독립한다. 따라서 Y의 잔차 ε_Y는 X와 통계적으로 독립한다는 특성을 이용한다.
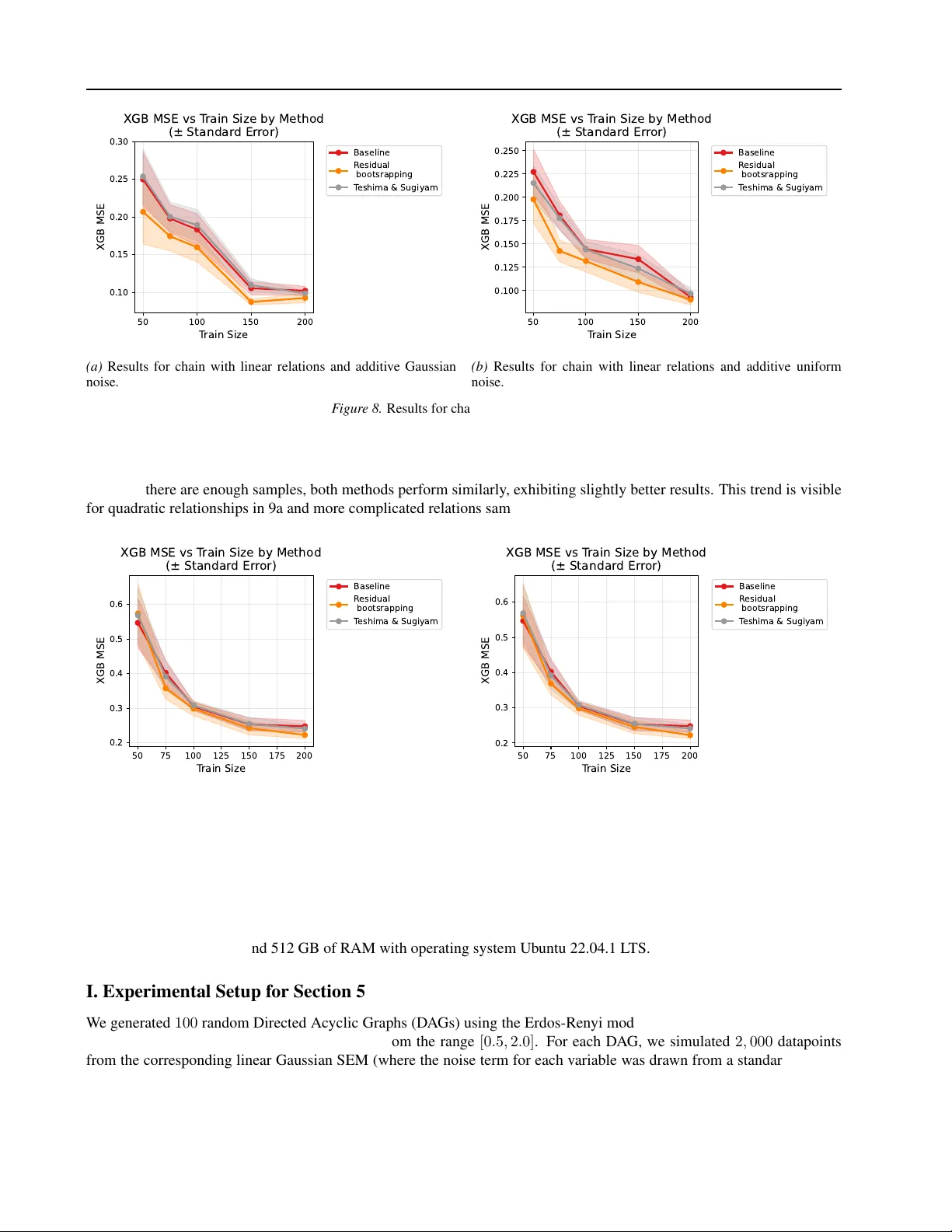
CRB는 두 단계로 진행된다. ① 학습 단계에서는 주어진 DAG의 위상 정렬에 따라 각 노드에 대해 회귀 모델(선형, 랜덤 포레스트, 신경망 등)을 학습한다. 이때 모델은 f_i 를 추정하고, 각 관측치에 대해 잔차 ε_i 를 계산한다. ② 증강 단계에서는 각 노드별 잔차 집합을 독립적으로 재샘플링한다. 재샘플링된 잔차 ε_i′ 를 원래 구조 방정식에 다시 삽입해 V_i′ = f_i(PA(V_i)) + ε_i′ 로 새로운 샘플을 만든다. 이 과정은 원래 데이터가 만족하던 인과적 독립성(조건부 독립 및 잔차 독립성)을 그대로 보존한다.
이론적 분석은 선형‑가우시안 SCM을 가정한다. 저자들은 무제한 다변량 가우시안 추정(공분산 행렬 Σ̂_full)과 DAG‑제약을 적용한 추정(Σ̂_DAG) 사이의 공분산 순서를 Loewner 순서로 비교한다. 결과적으로 Cov(Σ̂_DAG) ⪯ Cov(Σ̂_full) 가 성립하고, 이는 회귀 계수 β̂_DAG 가 β̂_full 보다 낮은 분산을 갖게 함을 의미한다. 예측 MSE 차이는 E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기