다중 모델 클래스와 하이퍼파라미터를 아우르는 효율적 라쇼몬 집합 탐색
** 본 논문은 기존 라쇼몬 집합을 단일 모델 클래스에 국한하지 않고, 알고리즘 선택과 하이퍼파라미터 최적화를 동시에 고려하는 CASH(CASH) 설정으로 확장한 **CASHomon 집합**을 정의한다. 이를 효율적으로 탐색하기 위해 제안된 **TruVaRImp** 알고리즘은 암시적 임계값을 이용한 레벨‑셋 추정(active learning) 기법으로, 가우시안 프로세스 기반의 불확실성 감소 전략과 최소화 후보 추적을 결합한다. 이론적 수렴…
저자: Fiona Katharina Ewald, Martin Binder, Matthias Feurer
**
본 논문은 라쇼몬 집합(Rashomon set)이라는 개념을 기존의 단일 모델 클래스에 국한된 접근에서 벗어나, 알고리즘 선택과 하이퍼파라미터 최적화를 동시에 고려하는 **CASH (Combined Algorithm Selection and Hyperparameter optimization)** 설정으로 확장한다. 이를 **CASHomon 집합**이라 명명하고, 데이터 D와 하이퍼파라미터 조합 λ를 입력받아 모델 f=I(D,λ)를 생성하는 전체 인덕터 I_CASH를 정의한다. CASHomon 집합은 모든 모델 클래스와 그 하이퍼파라미터 공간을 포괄하는 H_D^CASH에서, 위험(Risk)값이 최적 모델 f_ref의 위험보다 ε 이하인 모델들의 집합 C_S(ε, f_ref, H_D^CASH)으로 정의된다.
CASHomon 집합을 찾는 문제는 “임계값이 암묵적으로 정의된 레벨‑셋 추정(Level‑Set Estimation, LSE)” 문제와 동등하다. 즉, 최적 모델 f_ref 자체가 아직 알려지지 않은 상황에서, 위험값이 최적값에 가깝게 위치한 영역을 효율적으로 탐색해야 한다. 기존 LSE 방법은 명시적 임계값을 전제로 하여 후보 점들을 분류하지만, 여기서는 임계값이 최적 위험값 + ε 로 동적으로 변한다는 점이 핵심 난관이다.
이를 해결하기 위해 저자들은 **TruVaRImp** 알고리즘을 제안한다. TruVaRImp은 기존 TruVaR(LSE) 알고리즘을 확장하여, (1) **잠재 최소화 후보 집합 M_t**를 유지하면서 현재 관측된 위험값 중 최소값에 대한 불확실성을 최소화하고, (2) **미분류 집합 U_t**를 유지하며 각 후보 λ에 대해 가우시안 프로세스(GP)로부터 사후 평균 μ(λ)와 분산 σ²(λ)를 이용해 임계값 주변의 불확실성을 평가한다. 알고리즘은 매 반복마다 “전체 미분류 후보에 대한 불확실성 감소량”을 최대화하는 λ를 선택하고, 해당 λ에 대한 실제 위험을 평가한다. 평가 결과가 현재 임계값(최소 위험 + ε)보다 명확히 위/아래에 있으면 각각 L_t(낮은 집합) 혹은 H_t(높은 집합)으로 이동시키고, 그렇지 않은 경우는 계속 U_t에 남겨 두어 다음 라운드에서 재평가한다.
TruVaRImp은 두 가지 트랙을 동시에 운영함으로써 (i) 최적 모델을 빠르게 찾아 임계값을 구체화하고, (ii) 임계값 주변의 불확실성을 효율적으로 감소시켜 라쇼몬 영역을 정확히 구분하도록 만든다. 이론적으로는 GP의 수렴 성질과 불확실성 감소 전략을 이용해, 일정 횟수의 평가 후에 모든 후보가 ε‑레벨 안팎으로 확정될 것임을 증명한다.
실험에서는 9개의 공개 데이터셋(분류·회귀 모두 포함)과 합성 데이터에 대해 TruVaRImp을 적용하였다. 비교 대상은 (i) 무작위 샘플링, (ii) 전통적인 베이지안 최적화(Bayesian Optimization), (iii) 기존 레벨‑셋 알고리즘(LSE, Gotovos 등), (iv) 모델‑특화 라쇼몬 구축 도구(TreeFARMS 등)이다. 결과는 TruVaRImp이 동일한 평가 예산 하에서 더 높은 재현율(Recall)과 정밀도(Precision)를 달성했으며, 특히 다중 모델 클래스가 혼재된 CASH 공간에서 기존 방법이 놓치기 쉬운 “클래스 간 교차 라쇼몬”을 효과적으로 포착함을 보여준다.
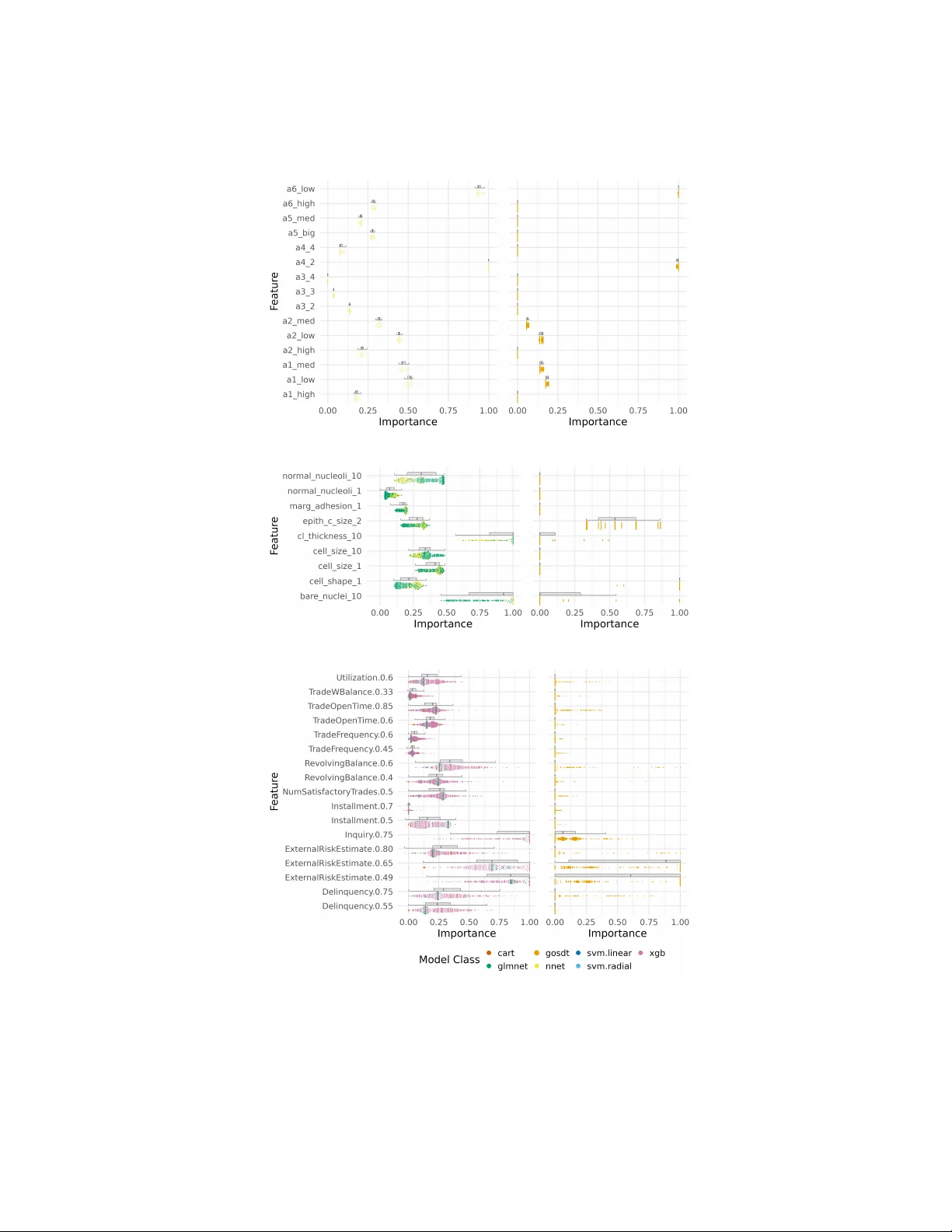
추가 분석에서는 **예측 다중성**을 라쇼몬 용량(Rashomon capacity) 지표로 정량화하고, 모델 클래스별 특성 중요도(FI) 분포를 시각화한 **Variable Importance Clouds(VICs)**를 제시한다. 결과는 동일 데이터에 대해 서로 다른 모델 클래스가 상당히 다른 FI 패턴을 보이며, 단일 모델 클래스에 기반한 해석이 편향될 위험이 있음을 강조한다. 또한, CASHomon 집합 내에서는 라쇼몬 용량이 클래스 제한 라쇼몬 집합보다 크게 증가하는데, 이는 모델 클래스 선택 자체가 예측 다중성에 큰 영향을 미친다는 실증적 증거가 된다.
전반적으로 이 논문은 (1) 라쇼몬 개념을 CASH 설정으로 일반화한 이론적 프레임워크, (2) 암시적 임계값을 효율적으로 다루는 TruVaRImp 알고리즘 및 그 수렴 보장, (3) 실험을 통한 알고리즘 우수성 입증, (4) 모델 클래스 간 예측 다중성 및 특성 중요도 변동성에 대한 실증적 통찰을 제공한다. 이는 AutoML 시스템이 단순히 최고 성능 모델을 찾는 것을 넘어, 해석 가능성·공정성·도메인 제약을 만족하는 다양한 후보 모델을 제공할 수 있는 기반을 마련한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기