학생 역량의 경계에서 학습을 가속하는 Paced
PACED는 학생 모델의 통과율(pass rate)을 이용해 학습 효율이 가장 높은 ‘근접 발달 영역’에 집중하도록 가중치를 부여하는 LLM 증류 프레임워크이다. 베타 커널 w(p)=p^α(1‑p)^β 로 정의된 가중치는 이론적으로 증류 그래디언트의 신호‑대‑노이즈 비율이 두 극단(p≈0, p≈1)에서 사라지는 구조에서 도출되며, 경계 근처의 무의미한 연산을 자동 억제한다. 실험에서는 전방 KL 기반 교사‑학생 증류와 역방 KL 기반 자기‑증류…
저자: Yu, a Xu, Hejian Sang
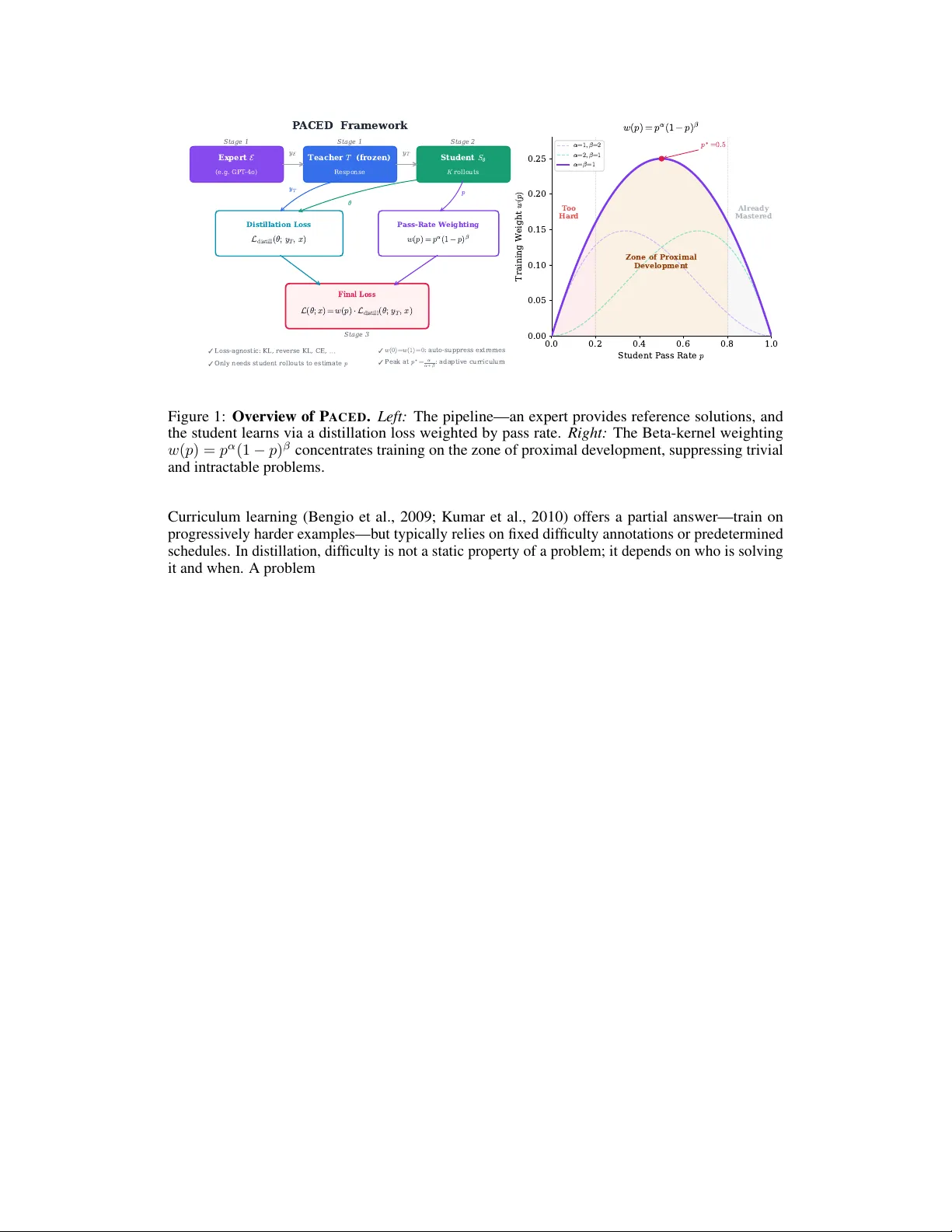
본 논문은 대규모 언어 모델(LLM) 증류 과정에서 발생하는 비효율성을 이론적으로 분석하고, 이를 해결하기 위한 새로운 프레임워크인 PACED(Profiency‑Adaptive Competence‑Enhanced Distillation)를 제안한다. 기존 증류는 학생 모델이 이미 마스터한 문제와 아직 풀지 못하는 문제 모두에 동일한 학습 예산을 할당한다. 저자는 이러한 현상이 단순한 경험적 현상이 아니라, 증류 손실의 그래디언트가 두 극단(p≈0, p≈1)에서 신호‑대‑노이즈 비율(SNR)이 0으로 수렴하는 구조적 특성에 기인한다는 것을 정리한다(Prop. 2).
이를 바탕으로, SNR이 p^α(1‑p)^β 형태의 베타 커널로 근사될 수 있음을 보이며(Prop. 3), 이 커널이 학습 효율을 최대로 하는 가중치 함수임을 증명한다. 베타 커널은 p=0과 p=1에서 0이 되므로, 학생이 전혀 풀 수 없는 문제와 이미 완전히 마스터한 문제에 대한 학습을 자동으로 억제한다. 기본 파라미터 α=β=1을 사용하면 w(p)=p(1‑p) 로, 이는 통과율이 0.5일 때 가장 큰 가중치를 부여한다. 또한, 실제 SNR이 베타 형태와 약간 차이날 경우에도 최악의 효율 손실이 O(δ²) 수준으로 제한되는 최소극대(minimax) 강건성을 제공한다(Theorem 6).
구현 측면에서 PACED는 다음과 같은 절차를 따른다. 1) 각 프롬프트에 대해 학생 모델이 K번 롤아웃을 수행해 통과율 p를 추정한다. 2) p를 베타 커널에 대입해 가중치 w(p)를 계산하고, 평균이 1이 되도록 정규화한다. 3) 증류 손실에 w(p)를 곱해 가중된 손실을 최적화한다. 전방 KL(교사 → 학생)과 역방 KL(학생 → 교사) 두 가지 손실을 모두 지원한다. 전방 KL은 교사의 로그잇을 직접 사용해 모드 커버리지를 확대하고, 역방 KL은 학생 자체 롤아웃을 교사 로그잇과 비교해 고신뢰 모드로 수렴하도록 한다.
실험에서는 두 가지 설정을 평가한다. (1) Qwen3‑14B→Qwen3‑8B 전방 KL 증류에서는 MATH‑500 점수가 +7.5, AIME 2025에서 +14.8 상승했으며, MMLU에서의 망각은 0.2%에 불과했다. (2) Qwen2.5‑Math‑7B‑Instruct에 역방 KL 자기‑증류를 적용했을 때는 각각 +9.8, +13.6의 점수 향상을 기록했다. 특히 전방 KL 후 역방 KL 순서로 두 단계 스케줄링을 적용하면 MATH‑500, AIME 2024, AIME 2025에서 각각 +9.1, +15.2, +16.7이라는 최고 성과를 얻었다. 모든 실험은 학생 롤아웃만 필요하고, 모델 구조 변경이나 추가 파라미터 튜닝 없이 적용 가능하였다.
이 논문은 교육학의 “근접 발달 영역”(Zone of Proximal Development)을 수학적으로 정량화하고, LLM 증류에 실용적인 커리큘럼을 제공한다는 점에서 큰 의의를 가진다. 기존 증류가 모든 샘플을 균등하게 학습해 효율을 낭비하고 망각을 초래하는 문제를 근본적으로 해결하면서, 동시에 두 KL 방향을 보완적으로 활용해 모드 커버리지와 모드 수렴을 동시에 달성한다는 점이 특히 주목할 만하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기