자동 자기검증 기반 품질 게이트: LLM 애플리케이션 릴리즈 관리
LLM 기반 서비스는 비결정적 출력과 지속적인 모델 변동으로 전통적인 테스트만으로는 릴리즈 품질을 보장하기 어렵다. 저자는 다섯 가지 핵심 지표(작업 성공률, 연구 컨텍스트 보존, P95 지연, 안전 통과율, 증거 커버리지)를 활용한 자동 자기검증 프레임워크를 제안하고, 이를 내부 다중 에이전트 대화 시스템에 적용해 38회 평가·20여 차례 릴리즈를 검증하였다. 증거 커버리지가 가장 강력한 회귀 탐지 지표임을 확인했으며, 인간‑LLM 평가와의 …
저자: Alex, re Cristovão Maiorano
본 논문은 대규모 언어 모델(LLM) 기반 애플리케이션이 전통적인 소프트웨어 테스트 기법으로는 품질 보증이 어려운 문제점을 인식하고, 자동 자기검증(Automated Self‑Testing) 기반 품질 게이트 프레임워크를 설계·평가한다. 연구는 먼저 LLM 애플리케이션의 비결정적 출력, 컨텍스트 의존성, 그리고 안전·사실성 요구사항이 기존 단위·통합 테스트와는 다른 차원의 회귀 위험을 내포한다는 점을 강조한다. 이를 해결하기 위해 저자는 다섯 가지 핵심 품질 차원을 정의한다.
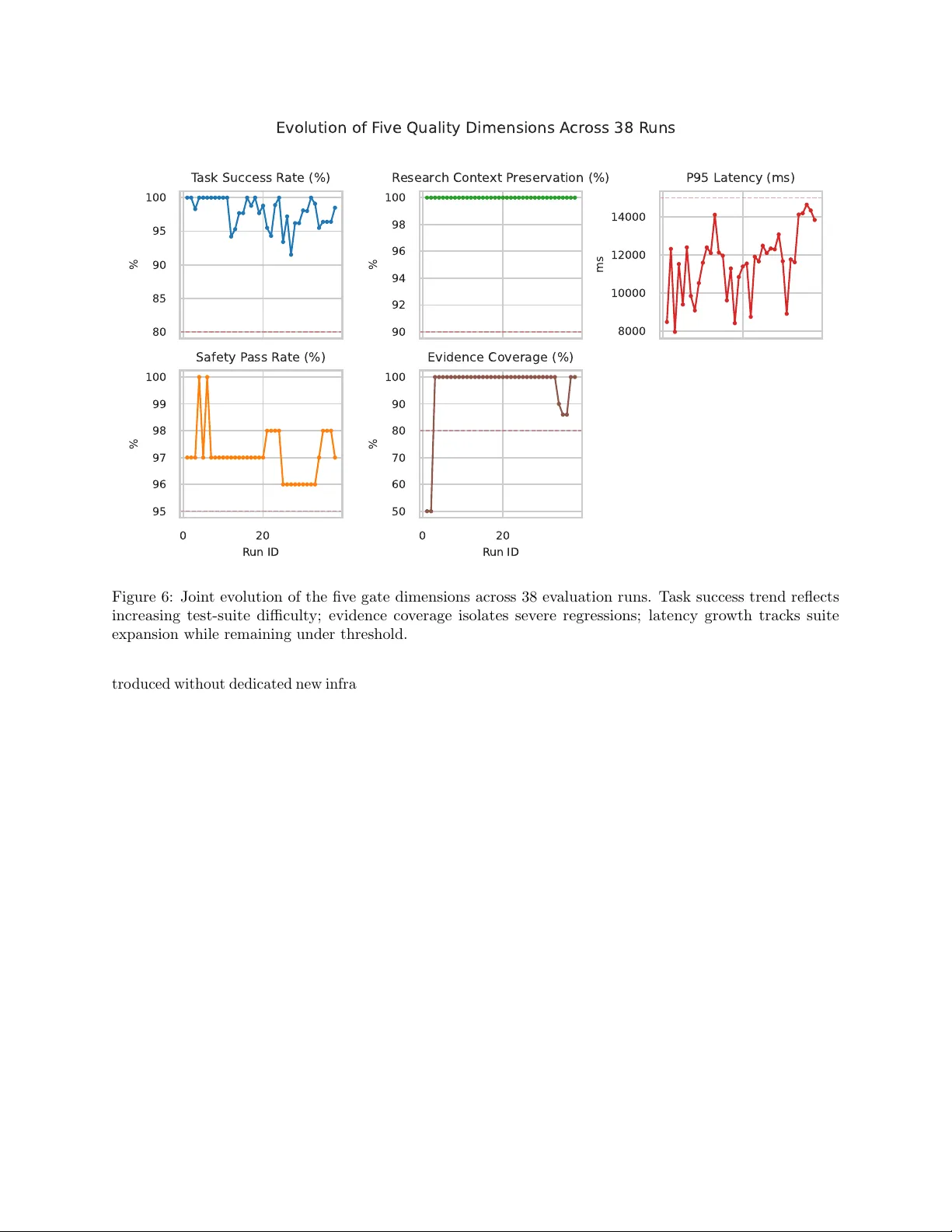
1. **작업 성공률(Task Success Rate, ≥80%)** – 테스트 케이스가 사용자의 의도를 정확히 해결하고, 의미 있는 응답을 생성하는 비율을 측정한다.
2. **연구 컨텍스트 보존(Research Context Preservation, ≥90%)** – 멀티턴 대화 흐름에서 컨텍스트가 손실되지 않고 유지되는 비율을 평가한다.
3. **P95 지연(P95 Latency, <15,000 ms)** – 95번째 퍼센타일 응답 시간이 15초 이하인지 확인해 실시간 사용자 경험을 보장한다.
4. **안전 통과율(Safety Pass Rate, ≥95%)** – 프롬프트 인젝션, 유해 콘텐츠 등 위험 요소를 차단하는 가드레일이 정상 작동하는 비율을 측정한다.
5. **증거 커버리지(Evidence Coverage, ≥80%)** – 외부 지식 검색이 필요한 작업에서 응답이 권위 있는 출처를 인용하는 비율을 평가한다.
각 차원에 대해 임계값은 사전 파일럿 실험과 운영 요구사항을 바탕으로 경험적으로 설정되었다. 특히 증거 커버리지는 마케팅 분석 시나리오에서 사용자가 결과의 신뢰성을 판단하는 핵심 요소로, 80% 이상을 목표로 삼았다.
프레임워크는 정적·동적 “질문 은행”을 활용한다. 질문 은행은 실제 내부 dogfooding 로그, 스테이징에서 발견된 에지 케이스, 그리고 개발팀이 설계한 적대적 프롬프트를 포함한다. CI/CD 파이프라인에 통합된 평가 엔진은 코드 머지 시 자동으로 질문 은행을 로드하고, 전체 테스트 스위트를 실행한다. 실행 과정에서 각 대화 트레이스와 메타데이터(응답 시간, 상태 전이, 외부 검색 결과 등)를 수집하고, 사전에 정의된 메트릭을 계산한다. 최종적으로 5차원 점수가 모두 임계값을 만족하면 **PROMOTE**, 하나라도 임계값 이하이면 **HOLD**, 특정 차원이 70% 이하(임계값의 70%)로 급락하면 **ROLLBACK** 결정을 내린다.
실증 연구는 내부 다중 에이전트 오케스트레이션 시스템(마케팅 자동화 및 분석 기능 포함)에 적용되었다. 4주간의 스테이징 기간 동안 38번의 평가 실행과 20여 차례의 내부 릴리즈가 진행되었다. 결과적으로 두 차례의 ROLLBACK이 발생했으며, 이는 모두 증거 커버리지 급락에 기인했다. 나머지 실행에서는 대부분 PROMOTE가 이루어졌고, 시간에 따라 작업 성공률은 질문 은행이 확대됨에 따라 약간 감소했지만, 안전 통과율과 지연은 안정적인 수준을 유지했다.
통계 분석에서는 Mann‑Kendall 추세 검정으로 각 차원의 장기 변화를 확인했으며, Spearman 상관분석으로 증거 커버리지와 전체 릴리즈 결정 간 강한 양의 상관관계를 발견했다. 부트스트랩을 이용한 신뢰구간은 증거 커버리지가 회귀 탐지에 가장 민감한 지표임을 재확인한다. 또한, 차원별 Ablation 실험을 통해 증거 커버리지를 제외하면 ROLLBACK 발생 빈도가 크게 감소함을 보여, 이 지표가 ‘심각 회귀’ 판별에 핵심임을 입증한다.
인간 평가와 LLM‑as‑judge 교차 검증 실험도 수행되었다. 60개의 샘플을 두 명의 독립 평가자가 검토하고, LLM‑judge가 동일한 샘플을 평가했다. Cohen’s κ는 0.13으로 낮았으며, 이는 두 평가 체계가 서로 다른 오류 유형을 포착한다는 의미다. 구체적으로 LLM‑judge는 텍스트 내용상의 사실성·안전성 오류를 주로 지적했으며, 시스템 게이트는 지연 초과, 라우팅 실패와 같은 구조적 오류를 탐지했다. 이러한 결과는 다차원 품질 게이트가 단일 텍스트 기반 평가보다 포괄적인 리스크 커버리지를 제공함을 뒷받침한다.
프레임워크의 확장성도 검증되었다. 질문 은행 규모를 59개에서 133개로 확대했을 때 실행 시간은 선형적으로 증가했으며, 전체 파이프라인 지연은 5분 이하로 유지되었다. 이는 자동화된 테스트 스위트가 실제 CI/CD 흐름에 큰 부하를 주지 않으면서도 지속적인 회귀 탐지를 가능하게 함을 의미한다.
논문은 또한 기존 관련 연구와 차별점을 명확히 제시한다. HELM·MMLU·BIG‑bench 등은 모델 수준 벤치마크에 초점을 맞추지만, 본 연구는 애플리케이션 수준에서 실제 사용자 흐름과 비기능 요구사항을 동시에 검증한다. STELLAR·MA‑Committees와 같은 자동 테스트 프레임워크는 테스트 입력 생성이나 합의 기반 회귀 탐지에 강점이 있으나, 다차원 품질 게이트와 자동 릴리즈 결정 로직을 제공하지 않는다.
결론적으로, 자동 자기검증 기반 품질 게이트는 LLM 애플리케이션의 복합적인 품질 요구를 정량화하고, CI/CD 파이프라인에 직접 삽입함으로써 릴리즈 관리의 신뢰성을 크게 향상시킨다. 특히 증거 커버리지는 심각 회귀를 조기에 탐지하는 핵심 지표로 확인되었으며, 인간·LLM 평가와의 상보적 관계는 다차원 접근법의 필요성을 강조한다. 논문은 프레임워크 구현 코드, 질문 은행 샘플, 그리고 교차 검증 데이터셋을 공개함으로써 연구 재현성과 산업 적용을 촉진한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기